
Las aplicaciones modernas dependen en gran medida de las API que devuelven datos JSON estructurados. Si bien estos datos son ideales para los sistemas de software, las partes interesadas y los equipos de negocios a menudo necesitan información presentada en un formato legible y compartible, y los informes en PDF siguen siendo uno de los estándares más aceptados para la documentación, auditoría y distribución.
En lugar de convertir manualmente archivos JSON utilizando herramientas en línea, los desarrolladores pueden automatizar todo el flujo de trabajo, desde recuperar datos de API en vivo hasta generar informes PDF estructurados.
En este tutorial, aprenderá a construir una canalización de automatización de extremo a extremo utilizando Python:
- Recuperar datos JSON de una API
- Analizar y estructurar la respuesta
- Cargar los datos en una hoja de cálculo de Excel
- Exportar la hoja de cálculo como un informe PDF bien formateado
Este enfoque es ideal para informes programados, paneles de SaaS, exportaciones de análisis y sistemas de automatización de backend.
Por Qué los Conversores de JSON a PDF en Línea no son Suficientes
Los conversores en línea pueden ser útiles para tareas rápidas y únicas. Sin embargo, a menudo se quedan cortos cuando se trabaja con API en vivo o flujos de trabajo automatizados.
Las limitaciones comunes incluyen:
- Sin capacidad para extraer datos directamente de las API
- Falta de automatización o soporte de programación
- Control limitado del formato y diseño del informe
- Dificultad para manejar estructuras JSON anidadas
- Preocupaciones de privacidad al cargar datos confidenciales
- Sin integración con canalizaciones de backend o sistemas CI/CD
Para los desarrolladores que construyen sistemas de informes automatizados, un flujo de trabajo programático proporciona mucha más flexibilidad, escalabilidad y control. Usando Python y Spire.XLS, puede generar informes estructurados directamente desde las respuestas de la API sin intervención manual.
Requisitos Previos y Descripción General de la Arquitectura: Canalización de API JSON → Excel → PDF
Antes de construir el flujo de trabajo de automatización, asegúrese de que su entorno esté preparado:
pip install spire.xls requests
¿Por Qué Usar Excel como Capa Intermedia?
En lugar de convertir JSON directamente a PDF, este tutorial utiliza Excel como una capa de informes estructurada. Este enfoque proporciona varias ventajas:
- Convierte JSON no estructurado en diseños tabulares limpios
- Permite un formato y control de columnas sencillos
- Asegura una salida de PDF consistente
- Admite mejoras futuras como gráficos y resúmenes
Arquitectura de la Canalización
El proceso de automatización sigue una canalización de transformación estructurada:
- Capa de API : Recupera datos JSON en vivo de los servicios de backend
- Capa de Procesamiento de Datos : Normaliza y aplana las estructuras JSON
- Capa de Diseño de Informe (Excel) : Organiza los datos en tablas legibles
- Capa de Exportación (PDF) : Genera un informe final compartible
Este enfoque por capas mejora la escalabilidad y mantiene la lógica de los informes flexible para futuros escenarios de automatización.
Paso 1 — Recuperar Datos JSON de una API
La mayoría de los flujos de trabajo de informes automatizados comienzan recopilando datos en vivo de una API. En lugar de exportar archivos manualmente, su script extrae directamente los últimos registros de los servicios de backend, plataformas de análisis o aplicaciones SaaS. Esto asegura:
- Los informes siempre contienen datos actualizados
- Sin pasos de descarga o conversión manual
- Fácil integración en canalizaciones de automatización programadas
A continuación se muestra un ejemplo de cómo recuperar datos JSON usando Python:
import requests
# Punto final de API de ejemplo
url = "https://api.example.com/employees"
headers = {
"Authorization": "Bearer YOUR_API_TOKEN"
}
response = requests.get(url, headers=headers, timeout=30)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
api_data = response.json()
print("Registros recuperados:", len(api_data))
Prácticas Clave:
- Valide siempre el código de estado HTTP
- Incluya encabezados de autenticación cuando sea necesario
- Maneje los límites de velocidad y la regulación de la API
- Prepárese para la paginación cuando los conjuntos de datos son grandes
Los ejemplos de este tutorial utilizan la popular biblioteca de Python requests para manejar la comunicación HTTP; consulte la documentación oficial de Requests para patrones avanzados de autenticación y gestión de sesiones.
Paso 2 — Analizar y Estructurar la Respuesta JSON
No todos los archivos JSON comparten la misma estructura. Algunas API devuelven una lista simple de registros, mientras que otras envuelven los datos dentro de objetos o incluyen matrices anidadas y subcampos. Escribir JSON complejo directamente en Excel a menudo conduce a errores o informes ilegibles.
Comprender las Diferentes Estructuras JSON
| Tipo de JSON | Estructura de Ejemplo | Exportación Directa a Excel |
|---|---|---|
| Lista Simple | [ {…}, {…} ] | Funciona directamente |
| Lista Envuelva | { "employees": [ {…} ] } | ⚠ Extraer la lista primero |
| Objetos Anidados | { "address": { "city": "NY" } } | ⚠ Aplanar campos |
| Matrices Anidadas | { "skills": ["Python", "SQL"] } | ⚠ Convertir a cadena |
Una estructura normalizada debería verse así:
[
{"id":1,"name":"Alice","city":"NY","skills":"Python, SQL"}
]
Este formato se puede escribir directamente en las filas de Excel. Si no está familiarizado con cómo se estructuran los objetos y matrices anidados, revisar la especificación oficial del formato de datos JSON puede ayudar a aclarar cómo se organizan las respuestas complejas de la API.
Normalizar JSON Antes de Generar Informes
En lugar de modificar manualmente el JSON para cada API, puede automáticamente:
- Detectar listas envueltas
- Aplanar objetos anidados
- Convertir matrices en cadenas legibles
- Estandarizar datos para informes
A continuación se muestra un ayudante de normalización reutilizable:
def normalize_json(input_json):
# Paso 1: detectar lista envuelta
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# aplanar diccionario anidado
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convertir listas a cadena
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
Nota: Las estructuras JSON de varios niveles profundamente anidadas pueden requerir un aplanamiento recursivo adicional según la complejidad de la API.
Ejemplo de Uso:
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
structured_data = normalize_json(raw_data)
Esto asegura que el conjunto de datos sea seguro para la exportación a Excel independientemente de la complejidad del JSON.
Paso 3 — Cargar Datos JSON Estructurados en una Hoja de Cálculo de Excel
Excel actúa como una capa de informes estructurada después de la normalización de JSON. Una vez que las estructuras JSON complejas se han aplanado en una lista simple de diccionarios, los datos se pueden escribir directamente en filas y columnas para un formato posterior y exportación a PDF.
Usando Spire.XLS para Python, los desarrolladores pueden construir, modificar y formatear informes de Excel completamente a través de código, sin requerir Microsoft Excel, lo que facilita la integración de operaciones avanzadas de hojas de cálculo en flujos de trabajo de informes automatizados.
Crear Libro y Hoja de Cálculo
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
Cómo Funciona:
- Inicializa un nuevo archivo de Excel en la memoria.
- Accede a la primera hoja de cálculo.
- Prepara un lienzo para escribir datos estructurados.
Escribir Encabezados y Filas de Datos
headers = list(structured_data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
for row_idx, row in enumerate(structured_data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = str(row.get(key, ""))
Cómo Funciona:
- Extrae los encabezados de las columnas de los datos estructurados.
- Escribe primero la fila de encabezado.
- Itera a través de los registros y llena las filas secuencialmente.
- Convierte los valores en cadenas para garantizar una salida consistente.
Preparar el Formato Antes de Exportar
# Ajustar columnas automáticamente
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Establecer una altura de fila predeterminada para todas las filas
sheet.DefaultRowHeight = 18
# Establecer márgenes uniformes para la hoja
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Habilitar la impresión de líneas de cuadrícula
sheet.PageSetup.IsPrintGridlines = True
Debido a que la hoja de cálculo ya define el diseño y el formato, la exportación a PDF conserva la estructura visual sin lógica de renderizado adicional.
Paso 4 — Exportar la Hoja de Cálculo como un Informe PDF
Una vez que los datos están estructurados y formateados en Excel, la exportación a PDF crea un informe portátil y profesional adecuado para:
- Distribución a las partes interesadas
- Documentación de cumplimiento
- Canalizaciones de informes automatizados
- Almacenamiento de archivo
Guardar Hoja de Cálculo de Excel como Informe PDF
sheet.SaveToPdf("output.pdf")
Su informe PDF estructurado ahora se genera automáticamente a partir de los datos de la API.
Salida:
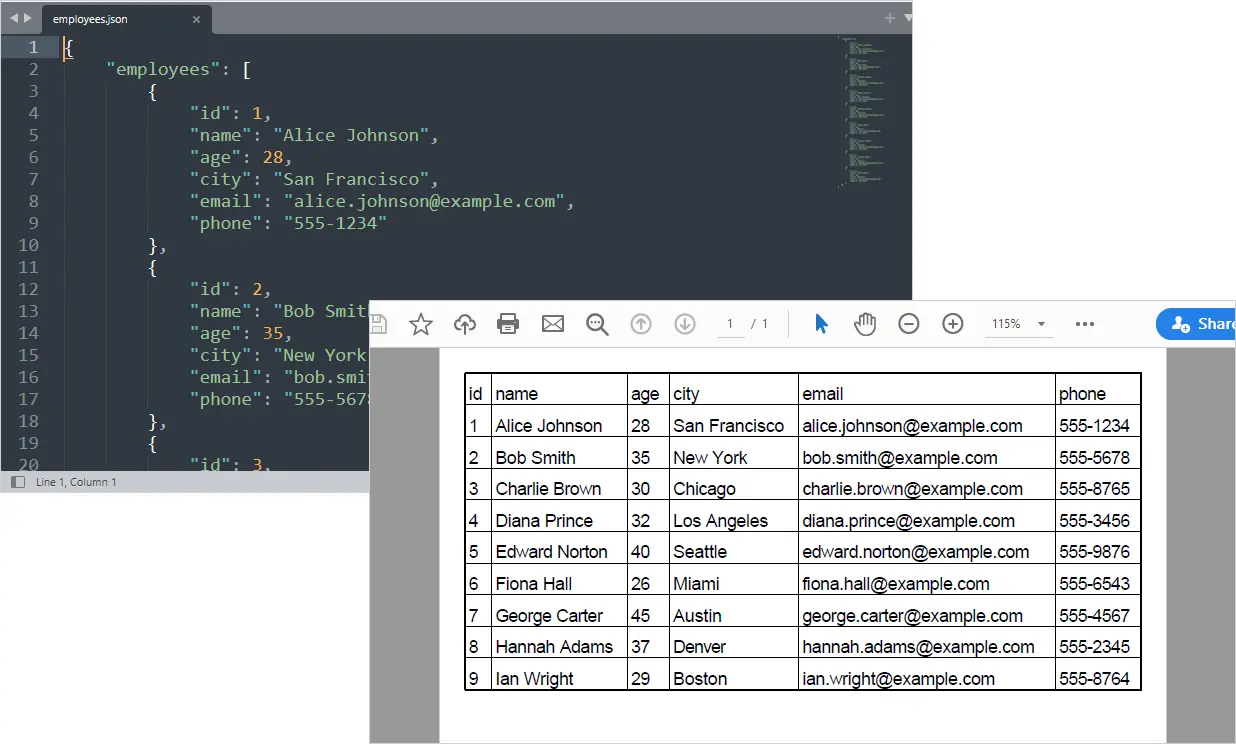
También te puede interesar: Convertir Excel a PDF en Python
Script Completo — De JSON de API a Informe PDF Estructurado
from spire.xls import *
from spire.xls.common import *
import json
import requests
def normalize_json(input_json):
# Paso 1: detectar lista envuelta
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# aplanar diccionario anidado
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convertir listas a cadena
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
# =========================
# Paso 1: Obtener JSON de la API
# =========================
api_url = "https://api.example.com/employees"
response = requests.get(api_url)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
raw_data = response.json()
# =========================
# Paso 2: Normalizar JSON
# =========================
data = normalize_json(raw_data)
# =========================
# Paso 3: Crear Libro
# =========================
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Escribir encabezados
headers = list(data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Escribir filas
for row_idx, row in enumerate(data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row.get(key, "")
# =========================
# Paso 4: Formatear hoja de cálculo
# =========================
# Establecer la configuración de conversión para ajustar el diseño de la hoja
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True # Conservar el tamaño del papel durante la conversión
workbook.ConverterSetting.SheetFitToWidth = True # Ajustar la hoja al ancho durante la conversión
# Ajustar columnas automáticamente
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Establecer márgenes uniformes para la hoja
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Habilitar la impresión de líneas de cuadrícula
sheet.PageSetup.IsPrintGridlines = True
# Establecer una altura de fila predeterminada para todas las filas
sheet.DefaultRowHeight = 18
# =========================
# Paso 5: Exportar a PDF
# =========================
sheet.SaveToPdf("output.pdf")
workbook.Dispose()
Si su fuente de datos es un archivo JSON local en lugar de una API en vivo, puede cargar los datos directamente desde el disco antes de generar el informe PDF.
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
Casos de Uso Prácticos
Este flujo de trabajo de automatización se puede aplicar en una amplia gama de escenarios de informes basados en datos:
- Canalizaciones de informes de API automatizadas — Genere informes PDF diarios o semanales desde servicios de backend sin exportaciones manuales.
- Resúmenes de uso y actividad de SaaS — Convierta las API de análisis de aplicaciones en informes estructurados para clientes o internos.
- Exportaciones de informes financieros y de RR. HH. — Transforme los datos estructurados de la API en documentos PDF estandarizados para distribución interna.
- Instantáneas de paneles de análisis — Capture métricas impulsadas por API y conviértalas en informes ejecutivos compartibles.
- Informes de inteligencia empresarial programados — Cree automáticamente resúmenes en PDF a partir de API de almacenes de datos o de análisis.
- Documentación de cumplimiento y auditoría — Produzca registros PDF consistentes y con marca de tiempo a partir de conjuntos de datos de API estructurados.
Consideraciones Finales
La automatización de la generación de informes PDF a partir de respuestas de API JSON permite a los desarrolladores crear canalizaciones de informes escalables que eliminan el procesamiento manual. Al combinar las capacidades de la API de Python con las funciones de exportación de Excel y PDF de Spire.XLS para Python, puede crear informes estructurados y profesionales directamente desde fuentes de datos en vivo.
Ya sea que esté generando informes comerciales semanales, paneles internos o entregables para clientes, este flujo de trabajo proporciona flexibilidad, automatización y control total sobre el proceso de generación de informes.
JSON a PDF: Preguntas Frecuentes
¿Puedo convertir JSON directamente a PDF sin Excel?
Sí, pero usar Excel como capa intermedia facilita la estructuración de tablas, el control de diseños y la generación de un formato de informe profesional y consistente.
¿Cómo manejo respuestas de API grandes o paginadas?
Itere a través de las páginas o tokens proporcionados por la API y combine todos los resultados en un único conjunto de datos antes de generar el informe PDF.
¿Puede este flujo de trabajo ejecutarse automáticamente en un horario?
Sí. Puede automatizar el script utilizando trabajos cron, el Programador de tareas de Windows, canalizaciones de CI/CD o servicios de backend para generar informes con regularidad.
¿Cómo personalizo el diseño del informe PDF?
Formatee la hoja de cálculo de Excel antes de exportar: ajuste el ancho de las columnas, aplique estilos, inmovilice los encabezados o agregue gráficos. Esta configuración se conservará en el PDF.
¿Qué pasa si la API devuelve campos faltantes o inconsistentes?
Utilice métodos de extracción seguros como .get() con valores predeterminados al analizar JSON para evitar errores y mantener estructuras de tabla consistentes.