
En las aplicaciones modernas, JSON es uno de los formatos de datos más comunes para API, archivos de configuración e intercambio de datos. Sin embargo, aunque JSON es ideal para las máquinas, no siempre es legible por humanos. Exportar JSON a una tabla PDF puede ayudar a presentar información estructurada de forma clara en informes, paneles o documentación interna.
En este tutorial, aprenderá a convertir JSON a una tabla PDF bien formateada usando Python y Spire.XLS, incluyendo:
- Detección automática de conjuntos de datos para exportación a tablas
- Aplanamiento de campos JSON anidados
- Generación de PDF con aspecto profesional
También cubriremos la extracción manual de conjuntos de datos para estructuras profundamente anidadas, dándole control total sobre archivos JSON complejos.
Por Qué Convertir JSON a PDF No Siempre es Sencillo
JSON viene en todas las formas y tamaños:
- Arreglos planos: fáciles de convertir directamente en filas
- Objetos anidados: p. ej., un diccionario de especificaciones dentro de cada producto
- Arreglos dentro de arreglos: p. ej., una lista de productos dentro de un departamento
- Claves inconsistentes: algunos objetos tienen campos adicionales o faltantes
Por ejemplo, considere esta estructura para el inventario de una tienda:
{
"store": {
"departments": [
{
"name": "Computers",
"products": [{"id": 1, "name": "Laptop", "specs": {"CPU": "i7"}}]
},
{
"name": "Accessories",
"products": [{"id": 101, "name": "Mouse", "colors": ["Black", "White"]}]
}
]
}
}
Aplanar esto en una tabla no es trivial, porque los campos anidados deben convertirse en columnas, y los arreglos pueden necesitar ser expandidos o unidos en cadenas. Nuestra solución proporciona un manejo robusto para la mayoría de las estructuras JSON, al tiempo que ofrece una opción para la extracción manual en casos inusualmente complejos.
Para un repaso rápido sobre la sintaxis y estructura de JSON, consulte: Introducción a JSON
Paso 1 — Cargar Datos JSON
Antes de procesar, cargue su archivo JSON en Python. Usar el módulo incorporado json asegura que el contenido se analice en diccionarios y listas nativas de Python:
import json
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
Lo que hace este paso:
- Lee un archivo JSON del disco
- Lo convierte en objetos de Python (dict y list) para su posterior procesamiento
Consejo: Siempre especifique encoding="utf-8" para evitar problemas con caracteres que no son ASCII.
Paso 2 — Detectar Automáticamente el Conjunto de Datos a Exportar
Muchos archivos JSON contienen múltiples listas anidadas. A menudo, necesitamos la lista de objetos que representa la “tabla principal”, generalmente la lista más grande de diccionarios. La siguiente función busca automáticamente el conjunto de datos más parecido a una tabla:
def find_dataset(obj):
"""Busca recursivamente en el JSON y devuelve el conjunto de datos más parecido a una tabla."""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No se encontró ningún conjunto de datos adecuado.")
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# Uso
dataset = find_dataset(data)
Cómo funciona:
- Recorre recursivamente la estructura JSON
- Puntúa las listas candidatas según el número de claves × el número de elementos
- Elige el conjunto de datos más rico como la tabla principal
Limitaciones:
- No fusionará automáticamente listas profundamente anidadas (p. ej., productos de múltiples departamentos)
- Algunos campos pueden requerir extracción manual para una visibilidad completa
Opcional — Extracción Manual del Conjunto de Datos
Para conjuntos de datos profundamente anidados o personalizados, extraiga los datos manualmente:
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
Este enfoque garantiza que capture los campos exactos que necesita, incluida la adición de contexto como el departamento para cada producto.
Paso 3 — Aplanar y Normalizar JSON
Para convertir JSON a una tabla, las estructuras anidadas deben aplanarse:
def flatten_json(obj, parent_key="", sep="_"):
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
if not value:
items[new_key] = ""
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
def normalize_json(data):
flattened_rows = [flatten_json(item) for item in data]
all_keys_ordered, seen_keys = [], set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
rows, headers = normalize_json(dataset)
Lo que hace este paso:
- Convierte diccionarios anidados en nombres de columna como especs_CPU, especs_RAM
- Convierte listas de primitivos en cadenas separadas por comas
- Conserva la primera clave vista como la primera columna
Paso 4 — Exportar a PDF a través de Excel
Una vez que los datos están aplanados, expórtelos como PDF usando Spire.XLS para Python. En lugar de renderizar el PDF directamente, usamos Excel como una capa de diseño intermedia. Este enfoque proporciona un control total sobre la estructura de la tabla, el formato, los márgenes y el escalado antes de exportar a PDF.
Instalar dependencia:
pip install spire.xls
Exportar JSON a PDF usando Spire.XLS:
from spire.xls import Workbook
import os
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Escribir encabezados
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Escribir filas de datos
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formato
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF guardado: {output_path}")
Consejos para el formato de PDF:
- Ajustar automáticamente las columnas al contenido
- Establecer márgenes para la legibilidad
- Habilitar líneas de cuadrícula para una mejor visualización de la tabla
También te puede interesar: Convertir Excel a PDF en Python
Paso 5 — Ejemplo: Exportar Productos desde un Archivo JSON Complejo
Combine los pasos anteriores:
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
# Opción 1: Detección automática
dataset = find_dataset(data)
rows, headers = normalize_json(dataset)
# Opción 2: Extracción manual para estructura anidada
# dataset = []
# for dept in data["store"]["departments"]:
# for prod in dept["products"]:
# prod["department"] = dept["name"]
# dataset.append(prod)
# rows, headers = normalize_json(dataset)
export_to_pdf(rows, headers, "output/Products.pdf")
Puntos clave:
- La detección automática funciona para la mayoría de los arreglos JSON
- La extracción manual asegura el control sobre conjuntos de datos anidados y jerárquicos
Salida:
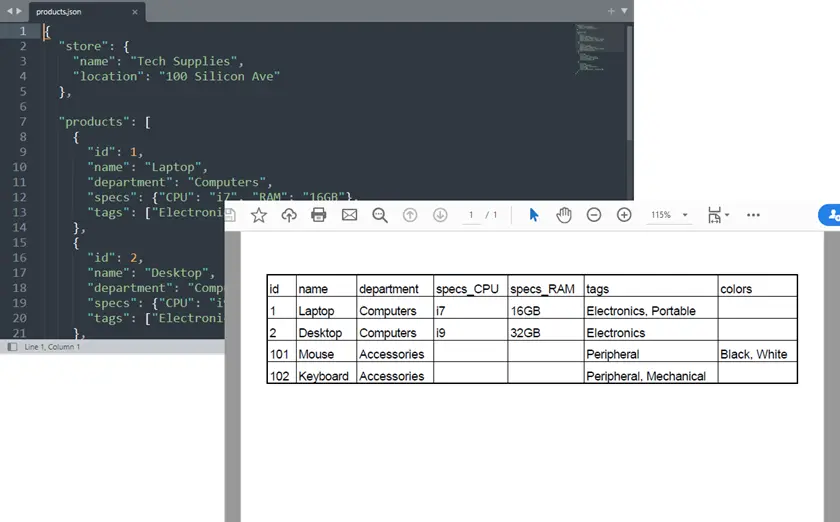
Ejemplo Completo de Python: JSON a PDF
from spire.xls import Workbook
import json
import os
# ---------------------------
# Detectar Automáticamente el Conjunto de Datos
# ---------------------------
def find_dataset(obj):
"""
Busca recursivamente en el JSON y devuelve el conjunto de datos más parecido a una tabla.
Estrategia:
- Encontrar listas que contienen diccionarios
- Puntuar conjuntos de datos según el número de campos
- Elegir el conjunto de datos con la estructura más rica
"""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
# Contar claves únicas en todos los objetos
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No se encontró ningún conjunto de datos adecuado.")
# elegir el conjunto de datos con la mejor puntuación
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# ---------------------------
# Aplanador JSON Recursivo Robusto
# ---------------------------
def flatten_json(obj, parent_key="", sep="_"):
"""
Aplana recursivamente diccionarios y listas anidados.
Reglas:
- Dict anidado → clave_subclave
- Lista de primitivos → cadena separada por comas
- Lista de dicts → columnas indexadas (clave_0_nombre, clave_1_nombre)
- Listas mixtas / arreglos de arreglos → indexados recursivamente (clave_0_0, clave_0_1)
"""
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
# Lista vacía
if not value:
items[new_key] = ""
# Lista de primitivos
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
# Listas mixtas o anidadas
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
# Listas de nivel superior
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
# ---------------------------
# Normalizar Datos JSON (Orden de Columnas según Primera Aparición)
# ---------------------------
def normalize_json(data):
"""
Aplanar objetos JSON y alinear encabezados, conservando el orden de la primera aparición.
La primera clave en el primer objeto JSON será la primera columna.
"""
if not isinstance(data, list):
raise ValueError("Los datos deben ser una lista de objetos.")
flattened_rows = [flatten_json(item) for item in data]
# Rastrear encabezados en el orden de primera aparición
all_keys_ordered = []
seen_keys = set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
# Alinear todas las filas para incluir todas las claves
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
# ---------------------------
# Exportar a PDF a través de Excel
# ---------------------------
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Escribir encabezado
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Escribir filas de datos
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formato
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF guardado: {output_path}")
# ===========================
# Ejemplo: Conjunto de Datos JSON Complejo
# ===========================
# Cargar JSON desde archivo
with open(r"C:\Users\Administrator\Desktop\Products.json", "r", encoding="utf-8") as f:
data = json.load(f)
# Opción 1. Detectar automáticamente el conjunto de datos (funciona para la mayoría de los casos)
dataset = find_dataset(data)
'''
# Opción 2. Extraer manualmente el conjunto de datos (funciona para estructuras complejas e inusuales)
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
'''
# Normalizar (la primera clave vista se convierte en la primera columna)
rows, headers = normalize_json(dataset)
# Exportar a PDF
export_to_pdf(rows, headers, "output/Products.pdf")
Conclusión
Convertir JSON a una tabla PDF puede ser complicado, especialmente con estructuras anidadas o claves inconsistentes. Usando Python y Spire.XLS, puede aplanar automáticamente JSON y preservar un orden lógico de columnas, convirtiendo conjuntos de datos complejos en tablas limpias y legibles adecuadas para informes o documentación.
La detección automática de conjuntos de datos maneja la mayoría de los archivos JSON, mientras que la extracción manual permite capturar datos anidados específicos cuando es necesario. Este enfoque ofrece una forma flexible y confiable de convertir JSON en tablas PDF profesionales sin perder estructura ni contexto.
Preguntas Frecuentes
¿Puede manejar cualquier archivo JSON?
La detección automática funciona para la mayoría, pero puede ser necesaria la extracción manual para datos profundamente anidados.
¿Cómo se determina el orden de las columnas?
Las columnas aparecen en el orden de su primera aparición en los objetos JSON.
¿Se pueden fusionar múltiples conjuntos de datos?
Sí, puede concatenar conjuntos de datos antes de aplanarlos.
¿Cómo manejar los campos faltantes?
Los valores faltantes se representan automáticamente como celdas vacías.
¿Puedo personalizar el diseño del PDF?
Sí, los márgenes, las líneas de cuadrícula y las opciones de autoajuste son totalmente configurables a través de Spire.XLS.