
Les applications modernes dépendent fortement des API qui renvoient des données JSON structurées. Bien que ces données soient idéales pour les systèmes logiciels, les parties prenantes et les équipes commerciales ont souvent besoin d'informations présentées dans un format lisible et partageable — et les rapports PDF restent l'une des normes les plus largement acceptées pour la documentation, l'audit et la distribution.
Au lieu de convertir manuellement les fichiers JSON à l'aide d'outils en ligne, les développeurs peuvent automatiser l'ensemble du flux de travail — de la récupération des données d'API en direct à la génération de rapports PDF structurés.
Dans ce tutoriel, vous apprendrez à créer un pipeline d'automatisation de bout en bout en utilisant Python :
- Récupérer les données JSON d'une API
- Analyser et structurer la réponse
- Charger les données dans une feuille de calcul Excel
- Exporter la feuille de calcul en tant que rapport PDF bien formaté
Cette approche est idéale pour les rapports planifiés, les tableaux de bord SaaS, les exportations d'analyses et les systèmes d'automatisation backend.
Pourquoi les convertisseurs JSON vers PDF en ligne ne suffisent pas
Les convertisseurs en ligne peuvent être utiles pour des tâches rapides et ponctuelles. Cependant, ils sont souvent insuffisants lorsqu'il s'agit de travailler avec des API en direct ou des flux de travail automatisés.
Les limitations courantes incluent :
- Aucune capacité à extraire des données directement des API
- Manque de prise en charge de l'automatisation ou de la planification
- Contrôle limité du formatage et de la mise en page des rapports
- Difficulté à gérer les structures JSON imbriquées
- Préoccupations en matière de confidentialité lors du téléchargement de données sensibles
- Aucune intégration avec les pipelines backend ou les systèmes CI/CD
Pour les développeurs qui créent des systèmes de rapports automatisés, un flux de travail programmatique offre beaucoup plus de flexibilité, d'évolutivité et de contrôle. En utilisant Python et Spire.XLS, vous pouvez générer des rapports structurés directement à partir des réponses de l'API sans intervention manuelle.
Prérequis et aperçu de l'architecture : Pipeline API JSON → Excel → PDF
Avant de créer le flux de travail d'automatisation, assurez-vous que votre environnement est préparé :
pip install spire.xls requests
Pourquoi utiliser Excel comme couche intermédiaire ?
Au lieu de convertir directement le JSON en PDF, ce tutoriel utilise Excel comme une couche de rapport structurée. Cette approche offre plusieurs avantages :
- Convertit le JSON non structuré en mises en page tabulaires propres
- Permet un formatage et un contrôle des colonnes faciles
- Assure une sortie PDF cohérente
- Prend en charge les améliorations futures comme les graphiques et les résumés
Architecture du pipeline
Le processus d'automatisation suit un pipeline de transformation structuré :
- Couche API : Récupère les données JSON en direct des services backend
- Couche de traitement des données : Normalise et aplatit les structures JSON
- Couche de mise en page du rapport (Excel) : Organise les données en tableaux lisibles
- Couche d'exportation (PDF) : Génère un rapport final partageable
Cette approche en couches améliore l'évolutivité et maintient la logique de reporting flexible pour les futurs scénarios d'automatisation.
Étape 1 — Récupérer les données JSON d'une API
La plupart des flux de travail de reporting automatisés commencent par la collecte de données en direct à partir d'une API. Au lieu d'exporter manuellement des fichiers, votre script extrait directement les derniers enregistrements des services backend, des plateformes d'analyse ou des applications SaaS. Cela garantit :
- Les rapports contiennent toujours des données à jour
- Aucune étape de téléchargement ou de conversion manuelle
- Intégration facile dans les pipelines d'automatisation planifiés
Voici un exemple montrant comment récupérer des données JSON en utilisant Python :
import requests
# Example API endpoint
url = "https://api.example.com/employees"
headers = {
"Authorization": "Bearer YOUR_API_TOKEN"
}
response = requests.get(url, headers=headers, timeout=30)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
api_data = response.json()
print("Enregistrements récupérés :", len(api_data))
Pratiques clés :
- Validez toujours le code de statut HTTP
- Incluez les en-têtes d'authentification si nécessaire
- Gérez les limites de débit et la limitation des API
- Préparez-vous à la pagination lorsque les ensembles de données sont volumineux
Les exemples de ce tutoriel utilisent la populaire bibliothèque Python requests pour gérer la communication HTTP ; consultez la documentation officielle de Requests pour les modèles d'authentification et de gestion de session avancés.
Étape 2 — Analyser et structurer la réponse JSON
Tous les fichiers JSON n'ont pas la même structure. Certaines API renvoient une simple liste d'enregistrements, tandis que d'autres encapsulent les données dans des objets ou incluent des tableaux et des sous-champs imbriqués. L'écriture directe de JSON complexe dans Excel entraîne souvent des erreurs ou des rapports illisibles.
Comprendre les différentes structures JSON
| Type de JSON | Structure d'exemple | Exportation directe vers Excel |
|---|---|---|
| Liste simple | [ {…}, {…} ] | Fonctionne directement |
| Liste encapsulée | { "employees": [ {…} ] } | ⚠ Extraire la liste d'abord |
| Objets imbriqués | { "address": { "city": "NY" } } | ⚠ Aplatir les champs |
| Tableaux imbriqués | { "skills": ["Python", "SQL"] } | ⚠ Convertir en chaîne |
Une structure normalisée devrait ressembler à :
[
{"id":1,"name":"Alice","city":"NY","skills":"Python, SQL"}
]
Ce format peut être écrit directement dans les lignes Excel. Si vous n'êtes pas familier avec la structure des objets et des tableaux imbriqués, la consultation de la spécification officielle du format de données JSON peut aider à clarifier comment les réponses complexes des API sont organisées.
Normaliser le JSON avant de générer des rapports
Au lieu de modifier manuellement le JSON pour chaque API, vous pouvez automatiquement :
- Détecter les listes encapsulées
- Aplatir les objets imbriqués
- Convertir les tableaux en chaînes lisibles
- Standardiser les données pour les rapports
Voici un assistant de normalisation réutilisable :
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
Remarque : Les structures JSON profondément imbriquées à plusieurs niveaux peuvent nécessiter un aplatissement récursif supplémentaire en fonction de la complexité de l'API.
Exemple d'utilisation :
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
structured_data = normalize_json(raw_data)
Cela garantit que l'ensemble de données est sûr pour l'exportation vers Excel, quelle que soit la complexité du JSON.
Étape 3 — Charger les données JSON structurées dans une feuille de calcul Excel
Excel agit comme une couche de rapport structurée après la normalisation JSON. Une fois que les structures JSON complexes ont été aplaties en une simple liste de dictionnaires, les données peuvent être écrites directement dans des lignes et des colonnes pour un formatage ultérieur et une exportation en PDF.
En utilisant Spire.XLS for Python, les développeurs peuvent créer, modifier et formater des rapports Excel entièrement par le code, sans nécessiter Microsoft Excel, ce qui facilite l'intégration d'opérations de feuille de calcul avancées dans des flux de travail de reporting automatisés.
Créer un classeur et une feuille de calcul
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
Comment ça marche :
- Initialise un nouveau fichier Excel en mémoire.
- Accède à la première feuille de calcul.
- Prépare une zone de dessin pour l'écriture de données structurées.
Écrire les en-têtes et les lignes de données
headers = list(structured_data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
for row_idx, row in enumerate(structured_data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = str(row.get(key, ""))
Comment ça marche :
- Extrait les en-têtes de colonne des données structurées.
- Écrit d'abord la ligne d'en-tête.
- Itère à travers les enregistrements et remplit les lignes séquentiellement.
- Convertit les valeurs en chaînes pour assurer une sortie cohérente.
Préparer le formatage avant l'exportation
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
Comme la feuille de calcul définit déjà la mise en page et le formatage, l'exportation PDF préserve la structure visuelle sans logique de rendu supplémentaire.
Étape 4 — Exporter la feuille de calcul en tant que rapport PDF
Une fois les données structurées et formatées dans Excel, l'exportation au format PDF crée un rapport portable et professionnel adapté pour :
- Distribution aux parties prenantes
- Documentation de conformité
- Pipelines de reporting automatisés
- Stockage d'archives
Enregistrer la feuille de calcul Excel en tant que rapport PDF
sheet.SaveToPdf("output.pdf")
Votre rapport PDF structuré est maintenant généré automatiquement à partir des données de l'API.
Sortie :
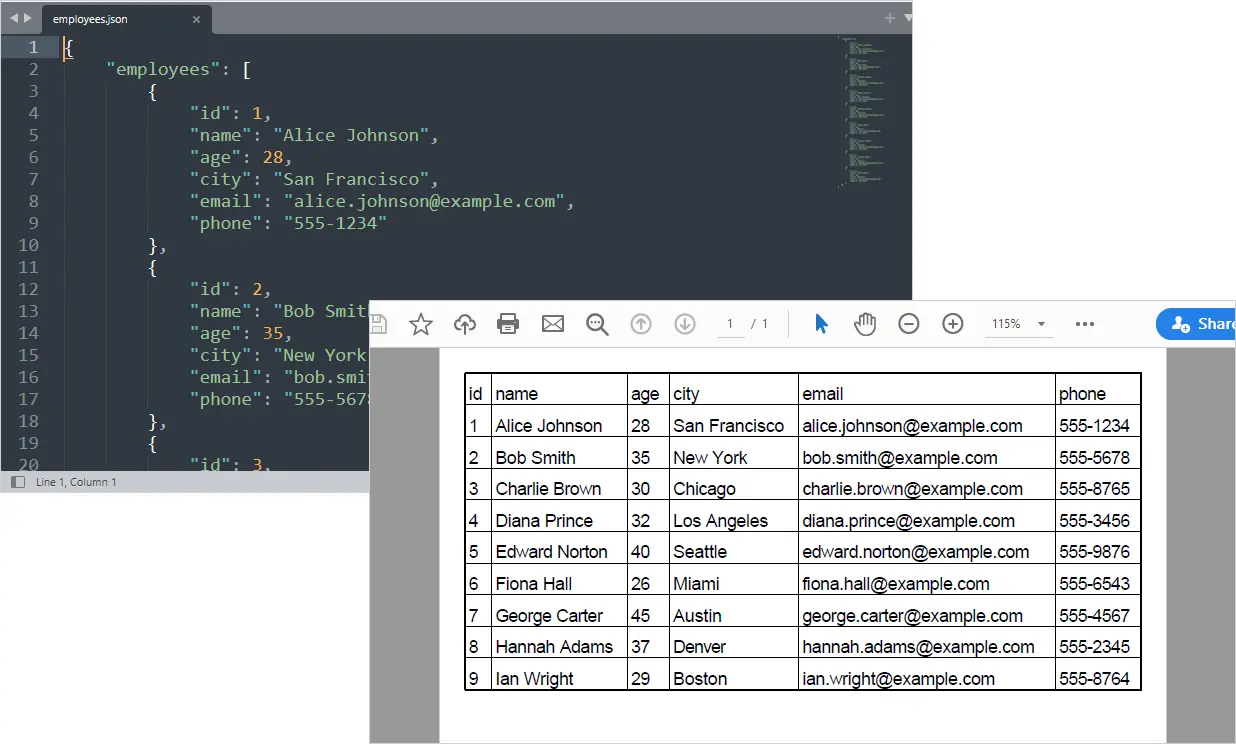
Vous pourriez aussi aimer : Convertir Excel en PDF en Python
Script complet — De l'API JSON au rapport PDF structuré
from spire.xls import *
from spire.xls.common import *
import json
import requests
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
# =========================
# Step 1: Get JSON from API
# =========================
api_url = "https://api.example.com/employees"
response = requests.get(api_url)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
raw_data = response.json()
# =========================
# Step 2: Normalize JSON
# =========================
data = normalize_json(raw_data)
# =========================
# Step 3: Create Workbook
# =========================
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
headers = list(data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write rows
for row_idx, row in enumerate(data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row.get(key, "")
# =========================
# Step 4: Format worksheet
# =========================
# Set conversion settings to adjust sheet layout
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True # Retain paper size during conversion
workbook.ConverterSetting.SheetFitToWidth = True # Fit sheet to width during conversion
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# =========================
# Step 5: Export to PDF
# =========================
sheet.SaveToPdf("output.pdf")
workbook.Dispose()
Si votre source de données est un fichier JSON local plutôt qu'une API en direct, vous pouvez charger les données directement depuis le disque avant de générer le rapport PDF.
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
Cas d'utilisation pratiques
Ce flux de travail d'automatisation peut être appliqué à un large éventail de scénarios de reporting basés sur les données :
- Pipelines de reporting API automatisés — Générez des rapports PDF quotidiens ou hebdomadaires à partir de services backend sans exportations manuelles.
- Résumés d'utilisation et d'activité SaaS — Convertissez les API d'analyse d'applications en rapports clients ou internes structurés.
- Exportations de rapports financiers et RH — Transformez les données d'API structurées en documents PDF standardisés pour une distribution interne.
- Instantanés de tableaux de bord d'analyse — Capturez des métriques pilotées par API et convertissez-les en rapports exécutifs partageables.
- Rapports de veille économique planifiés — Créez automatiquement des résumés PDF à partir d'entrepôts de données ou d'API d'analyse.
- Documentation de conformité et d'audit — Produisez des enregistrements PDF cohérents et horodatés à partir d'ensembles de données d'API structurés.
Réflexions finales
L'automatisation de la génération de rapports PDF à partir des réponses de l'API JSON permet aux développeurs de créer des pipelines de reporting évolutifs qui éliminent le traitement manuel. En combinant les capacités de l'API de Python avec les fonctionnalités d'exportation Excel et PDF de Spire.XLS for Python, vous pouvez créer des rapports structurés et professionnels directement à partir de sources de données en direct.
Que vous génériez des rapports d'activité hebdomadaires, des tableaux de bord internes ou des livrables clients, ce flux de travail offre flexibilité, automatisation et contrôle total sur le processus de génération de rapports.
JSON vers PDF : FAQ
Puis-je convertir directement le JSON en PDF sans Excel ?
Oui, mais l'utilisation d'Excel comme couche intermédiaire facilite la structuration des tableaux, le contrôle des mises en page et la génération d'un formatage de rapport cohérent et professionnel.
Comment gérer les réponses d'API volumineuses ou paginées ?
Itérez à travers les pages ou les jetons fournis par l'API et fusionnez tous les résultats dans un seul ensemble de données avant de générer le rapport PDF.
Ce flux de travail peut-il s'exécuter automatiquement selon un calendrier ?
Oui. Vous pouvez automatiser le script à l'aide de tâches cron, du Planificateur de tâches Windows, de pipelines CI/CD ou de services backend pour générer régulièrement des rapports.
Comment personnaliser la mise en page du rapport PDF ?
Formatez la feuille de calcul Excel avant d'exporter — ajustez la largeur des colonnes, appliquez des styles, figez les en-têtes ou ajoutez des graphiques. Ces paramètres seront conservés dans le PDF.
Que se passe-t-il si l'API renvoie des champs manquants ou incohérents ?
Utilisez des méthodes d'extraction sûres comme .get() avec des valeurs par défaut lors de l'analyse du JSON pour éviter les erreurs et maintenir des structures de tableau cohérentes.