
Dans les applications modernes, le JSON est l'un des formats de données les plus courants pour les API, les fichiers de configuration et l'échange de données. Cependant, bien que le JSON soit idéal pour les machines, il n'est pas toujours lisible par l'homme. L'exportation de JSON dans un tableau PDF peut aider à présenter des informations structurées de manière claire dans des rapports, des tableaux de bord ou de la documentation interne.
Dans ce tutoriel, vous apprendrez à convertir du JSON en un tableau PDF bien formaté en utilisant Python et Spire.XLS, y compris :
- Détecter automatiquement les ensembles de données pour l'exportation en tableau
- Aplatir les champs JSON imbriqués
- Générer des PDF d'aspect professionnel
Nous aborderons également l'extraction manuelle d'ensembles de données pour les structures profondément imbriquées, vous donnant un contrôle total sur les fichiers JSON complexes.
Pourquoi la conversion de JSON en PDF n'est pas toujours simple
Le JSON se présente sous toutes les formes et tailles :
- Tableaux plats : faciles à convertir directement en lignes
- Objets imbriqués : par ex., un dictionnaire de spécifications à l'intérieur de chaque produit
- Tableaux dans des tableaux : par ex., une liste de produits à l'intérieur d'un département
- Clés incohérentes : certains objets ont des champs supplémentaires ou manquants
Par exemple, considérez cette structure pour l'inventaire d'un magasin :
{
"store": {
"departments": [
{
"name": "Computers",
"products": [{"id": 1, "name": "Laptop", "specs": {"CPU": "i7"}}]
},
{
"name": "Accessories",
"products": [{"id": 101, "name": "Mouse", "colors": ["Black", "White"]}]
}
]
}
}
Aplatir cela en un tableau n'est pas trivial, car les champs imbriqués doivent être convertis en colonnes, et les tableaux peuvent avoir besoin d'être développés ou joints en chaînes de caractères. Notre solution offre une gestion robuste pour la plupart des structures JSON tout en proposant une option d'extraction manuelle pour les cas exceptionnellement complexes.
Pour un rappel rapide sur la syntaxe et la structure JSON, voir : Introduction à JSON
Étape 1 — Charger les données JSON
Avant le traitement, chargez votre fichier JSON dans Python. L'utilisation du module json intégré garantit que le contenu est analysé en dictionnaires et listes natifs de Python :
import json
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
Ce que fait cette étape :
- Lit un fichier JSON depuis le disque
- Le convertit en objets Python (dict et list) pour un traitement ultérieur
Conseil : Spécifiez toujours encoding="utf-8" pour éviter les problèmes avec les caractères non-ASCII.
Étape 2 — Détecter automatiquement l'ensemble de données à exporter
De nombreux fichiers JSON contiennent plusieurs listes imbriquées. Souvent, nous avons besoin de la liste d'objets qui représente le « tableau principal » — généralement la plus grande liste de dictionnaires. La fonction suivante recherche automatiquement l'ensemble de données le plus semblable à un tableau :
def find_dataset(obj):
"""Recursively search JSON and return the most table-like dataset."""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No suitable dataset found.")
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# Usage
dataset = find_dataset(data)
Comment ça marche :
- Parcourt récursivement la structure JSON
- Note les listes candidates en fonction du nombre de clés × le nombre d'éléments
- Choisit l'ensemble de données le plus riche comme tableau principal
Limites :
- Ne fusionnera pas automatiquement les listes profondément imbriquées (par ex., les produits de plusieurs départements)
- Certains champs peuvent nécessiter une extraction manuelle pour une visibilité complète
Optionnel — Extraction manuelle de l'ensemble de données
Pour les ensembles de données profondément imbriqués ou personnalisés, extrayez manuellement les données :
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
Cette approche garantit que vous capturez les champs exacts dont vous avez besoin, y compris l'ajout de contexte tel que le département pour chaque produit.
Étape 3 — Aplatir et normaliser le JSON
Pour convertir du JSON en tableau, les structures imbriquées doivent être aplaties :
def flatten_json(obj, parent_key="", sep="_"):
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
if not value:
items[new_key] = ""
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
def normalize_json(data):
flattened_rows = [flatten_json(item) for item in data]
all_keys_ordered, seen_keys = [], set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
rows, headers = normalize_json(dataset)
Ce que fait cette étape :
- Convertit les dictionnaires imbriqués en noms de colonnes comme specs_CPU, specs_RAM
- Convertit les listes de primitives en chaînes de caractères séparées par des virgules
- Préserve la première clé rencontrée comme première colonne
Étape 4 — Exporter en PDF via Excel
Une fois les données aplaties, exportez-les en PDF à l'aide de Spire.XLS for Python. Plutôt que de rendre le PDF directement, nous utilisons Excel comme une couche de mise en page intermédiaire. Cette approche offre un contrôle total sur la structure du tableau, le formatage, les marges et la mise à l'échelle avant l'exportation en PDF.
Installer la dépendance :
pip install spire.xls
Exporter du JSON en PDF avec Spire.XLS :
from spire.xls import Workbook
import os
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write data rows
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatting
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF saved: {output_path}")
Conseils pour le formatage PDF :
- Ajuster automatiquement les colonnes au contenu
- Définir les marges pour la lisibilité
- Activer le quadrillage pour une meilleure visualisation du tableau
Vous aimerez peut-être aussi : Convertir Excel en PDF en Python
Étape 5 — Exemple : Exporter des produits à partir d'un fichier JSON complexe
Combinez les étapes précédentes :
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1: Automatic detection
dataset = find_dataset(data)
rows, headers = normalize_json(dataset)
# Option 2: Manual extraction for nested structure
# dataset = []
# for dept in data["store"]["departments"]:
# for prod in dept["products"]:
# prod["department"] = dept["name"]
# dataset.append(prod)
# rows, headers = normalize_json(dataset)
export_to_pdf(rows, headers, "output/Products.pdf")
Points clés :
- La détection automatique fonctionne pour la plupart des tableaux JSON
- L'extraction manuelle assure le contrôle sur les ensembles de données imbriqués et hiérarchiques
Sortie :
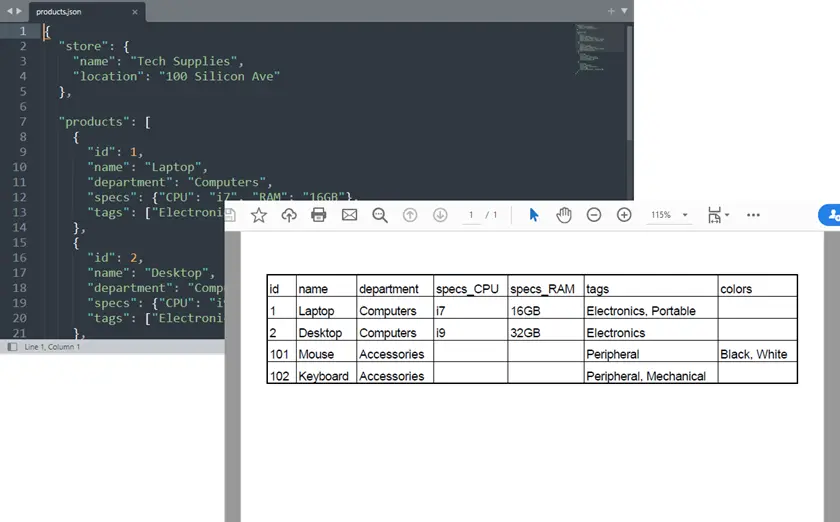
Exemple Python complet : JSON en PDF
from spire.xls import Workbook
import json
import os
# ---------------------------
# Atoumatically Detect dataset
# ---------------------------
def find_dataset(obj):
"""
Recursively search JSON and return the most table-like dataset.
Strategy:
- Find lists containing dictionaries
- Score datasets based on number of fields
- Choose the dataset with the richest structure
"""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
# Count unique keys across objects
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No suitable dataset found.")
# choose best scored dataset
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# ---------------------------
# Robust Recursive JSON Flattener
# ---------------------------
def flatten_json(obj, parent_key="", sep="_"):
"""
Recursively flattens nested dictionaries and lists.
Rules:
- Nested dict → key_subkey
- List of primitives → comma-separated string
- List of dicts → indexed columns (key_0_name, key_1_name)
- Mixed lists / arrays-of-arrays → recursively indexed (key_0_0, key_0_1)
"""
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
# Empty list
if not value:
items[new_key] = ""
# List of primitives
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
# Mixed or nested lists
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
# Top-level lists
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
# ---------------------------
# Normalize JSON Data (First-Seen Column Order)
# ---------------------------
def normalize_json(data):
"""
Flatten JSON objects and align headers, preserving the first-seen order.
The first key in the first JSON object will be the first column.
"""
if not isinstance(data, list):
raise ValueError("Data must be a list of objects.")
flattened_rows = [flatten_json(item) for item in data]
# Track headers in first-seen order
all_keys_ordered = []
seen_keys = set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
# Align all rows to include all keys
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
# ---------------------------
# Export to PDF via Excel
# ---------------------------
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write header
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write data rows
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatting
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF saved: {output_path}")
# ===========================
# Example: Complex JSON Dataset
# ===========================
# Load JSON from file
with open(r"C:\Users\Administrator\Desktop\Products.json", "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1. Automatically detect dataset (work for most cases)
dataset = find_dataset(data)
'''
# Option 2. Manually extract dataset (work for complex unusual structures)
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
'''
# Normalize (first-seen key becomes first column)
rows, headers = normalize_json(dataset)
# Export to PDF
export_to_pdf(rows, headers, "output/Products.pdf")
Conclusion
La conversion de JSON en tableau PDF peut être délicate, en particulier avec des structures imbriquées ou des clés incohérentes. En utilisant Python et Spire.XLS, vous pouvez automatiquement aplatir le JSON et préserver un ordre de colonnes logique, transformant des ensembles de données complexes en tableaux propres et lisibles, adaptés aux rapports ou à la documentation.
La détection automatique d'ensembles de données gère la plupart des fichiers JSON, tandis que l'extraction manuelle permet de capturer des données imbriquées spécifiques si nécessaire. Cette approche offre un moyen flexible et fiable de convertir du JSON en tableaux PDF professionnels sans perdre la structure ni le contexte.
FAQ
Cela peut-il gérer n'importe quel fichier JSON ?
La détection automatique fonctionne pour la plupart, mais une extraction manuelle peut être nécessaire pour les données profondément imbriquées.
Comment l'ordre des colonnes est-il déterminé ?
Les colonnes apparaissent dans l'ordre de leur première apparition dans les objets JSON.
Plusieurs ensembles de données peuvent-ils être fusionnés ?
Oui, vous pouvez concaténer les ensembles de données avant l'aplatissement.
Comment gérer les champs manquants ?
Les valeurs manquantes sont automatiquement représentées par des cellules vides.
Puis-je personnaliser la mise en page du PDF ?
Oui, les marges, le quadrillage et les options d'ajustement automatique sont entièrement configurables via Spire.XLS.