
Le applicazioni moderne si basano molto su API che restituiscono dati JSON strutturati. Sebbene questi dati siano ideali per i sistemi software, gli stakeholder e i team aziendali hanno spesso bisogno di informazioni presentate in un formato leggibile e condivisibile — e i report PDF rimangono uno degli standard più ampiamente accettati per la documentazione, l'auditing e la distribuzione.
Invece di convertire manualmente i file JSON utilizzando strumenti online, gli sviluppatori possono automatizzare l'intero flusso di lavoro — dal recupero dei dati API in tempo reale alla generazione di report PDF strutturati.
In questo tutorial, imparerai come creare una pipeline di automazione end-to-end utilizzando Python:
- Recuperare i dati JSON da un'API
- Analizzare e strutturare la risposta
- Caricare i dati in un foglio di lavoro Excel
- Esportare il foglio di lavoro come un report PDF ben formattato
Questo approccio è ideale per la reportistica pianificata, i dashboard SaaS, le esportazioni di analisi e i sistemi di automazione del backend.
Perché i convertitori online da JSON a PDF non sono sufficienti
I convertitori online possono essere utili per attività rapide e occasionali. Tuttavia, spesso non sono all'altezza quando si lavora con API in tempo reale o flussi di lavoro automatizzati.
Le limitazioni comuni includono:
- Nessuna capacità di estrarre dati direttamente dalle API
- Mancanza di automazione o supporto alla pianificazione
- Controllo limitato della formattazione e del layout del report
- Difficoltà nella gestione di strutture JSON nidificate
- Preoccupazioni sulla privacy durante il caricamento di dati sensibili
- Nessuna integrazione con pipeline di backend o sistemi CI/CD
Per gli sviluppatori che creano sistemi di reportistica automatizzati, un flusso di lavoro programmatico offre molta più flessibilità, scalabilità e controllo. Utilizzando Python e Spire.XLS, è possibile generare report strutturati direttamente dalle risposte API senza intervento manuale.
Prerequisiti e panoramica dell'architettura: pipeline da API JSON a Excel a PDF
Prima di creare il flusso di lavoro di automazione, assicurati che il tuo ambiente sia preparato:
pip install spire.xls requests
Perché usare Excel come livello intermedio?
Invece di convertire JSON direttamente in PDF, questo tutorial utilizza Excel come livello di reportistica strutturata. Questo approccio offre diversi vantaggi:
- Converte JSON non strutturato in layout tabulari puliti
- Consente una facile formattazione e controllo delle colonne
- Garantisce un output PDF coerente
- Supporta miglioramenti futuri come grafici e riepiloghi
Architettura della pipeline
Il processo di automazione segue una pipeline di trasformazione strutturata:
- Livello API : recupera i dati JSON in tempo reale dai servizi di backend
- Livello di elaborazione dati : normalizza e appiattisce le strutture JSON
- Livello di layout del report (Excel) : organizza i dati in tabelle leggibili
- Livello di esportazione (PDF) : genera un report finale condivisibile
Questo approccio a più livelli migliora la scalabilità e mantiene la logica di reporting flessibile per futuri scenari di automazione.
Passaggio 1 — Recuperare i dati JSON da un'API
La maggior parte dei flussi di lavoro di reportistica automatizzata inizia con la raccolta di dati in tempo reale da un'API. Invece di esportare manualmente i file, il tuo script estrae direttamente i record più recenti dai servizi di backend, dalle piattaforme di analisi o dalle applicazioni SaaS. Ciò garantisce:
- I report contengono sempre dati aggiornati
- Nessun passaggio di download o conversione manuale
- Facile integrazione nelle pipeline di automazione pianificate
Di seguito è riportato un esempio che mostra come recuperare i dati JSON utilizzando Python:
import requests
# Example API endpoint
url = "https://api.example.com/employees"
headers = {
"Authorization": "Bearer YOUR_API_TOKEN"
}
response = requests.get(url, headers=headers, timeout=30)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
api_data = response.json()
print("Records retrieved:", len(api_data))
Pratiche chiave:
- Convalida sempre il codice di stato HTTP
- Includi le intestazioni di autenticazione quando necessario
- Gestisci i limiti di velocità e la limitazione delle API
- Preparati per la paginazione quando i set di dati sono di grandi dimensioni
Gli esempi in questo tutorial utilizzano la popolare libreria Python requests per la gestione della comunicazione HTTP; fare riferimento alla documentazione ufficiale di Requests per modelli avanzati di autenticazione e gestione delle sessioni.
Passaggio 2 — Analizzare e strutturare la risposta JSON
Non tutti i file JSON condividono la stessa struttura. Alcune API restituiscono un semplice elenco di record, mentre altre racchiudono i dati all'interno di oggetti o includono array e sottocampi nidificati. La scrittura diretta di JSON complessi in Excel porta spesso a errori o report illeggibili.
Comprendere le diverse strutture JSON
| Tipo JSON | Struttura di esempio | Esportazione diretta in Excel |
|---|---|---|
| Elenco semplice | [ {…}, {…} ] | Funziona direttamente |
| Elenco incapsulato | { "employees": [ {…} ] } | ⚠ Estrarre prima l'elenco |
| Oggetti nidificati | { "address": { "city": "NY" } } | ⚠ Appiattire i campi |
| Array nidificati | { "skills": ["Python", "SQL"] } | ⚠ Converti in stringa |
Una struttura normalizzata dovrebbe assomigliare a:
[
{"id":1,"name":"Alice","city":"NY","skills":"Python, SQL"}
]
Questo formato può essere scritto direttamente nelle righe di Excel. Se non hai familiarità con la struttura di oggetti e array nidificati, la revisione della specifica ufficiale del formato dati JSON può aiutare a chiarire come sono organizzate le risposte API complesse.
Normalizza JSON prima di generare i report
Invece di modificare manualmente JSON per ogni API, puoi automaticamente:
- Rileva elenchi incapsulati
- Appiattisci oggetti nidificati
- Converti array in stringhe leggibili
- Standardizza i dati per la reportistica
Di seguito è riportato un helper di normalizzazione riutilizzabile:
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
Nota: le strutture JSON a più livelli profondamente nidificate potrebbero richiedere un appiattimento ricorsivo aggiuntivo a seconda della complessità dell'API.
Esempio di utilizzo:
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
structured_data = normalize_json(raw_data)
Ciò garantisce che il set di dati sia sicuro per l'esportazione in Excel indipendentemente dalla complessità del JSON.
Passaggio 3 — Caricare i dati JSON strutturati in un foglio di lavoro Excel
Excel funge da livello di reporting strutturato dopo la normalizzazione JSON. Una volta che le strutture JSON complesse sono state appiattite in un semplice elenco di dizionari, i dati possono essere scritti direttamente in righe e colonne per un'ulteriore formattazione ed esportazione in PDF.
Utilizzando Spire.XLS per Python, gli sviluppatori possono creare, modificare e formattare report di Excel interamente tramite codice, senza richiedere Microsoft Excel, rendendo facile l'integrazione di operazioni avanzate sui fogli di calcolo nei flussi di lavoro di reporting automatizzati.
Crea cartella di lavoro e foglio di lavoro
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
Come funziona:
- Inizializza un nuovo file Excel in memoria.
- Accede al primo foglio di lavoro.
- Prepara un'area di disegno per la scrittura di dati strutturati.
Scrivi intestazioni e righe di dati
headers = list(structured_data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
for row_idx, row in enumerate(structured_data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = str(row.get(key, ""))
Come funziona:
- Estrae le intestazioni di colonna dai dati strutturati.
- Scrive prima la riga di intestazione.
- Scorre i record e riempie le righe in sequenza.
- Converte i valori in stringhe per garantire un output coerente.
Prepara la formattazione prima dell'esportazione
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
Poiché il foglio di lavoro definisce già layout e formattazione, l'esportazione in PDF preserva la struttura visiva senza logica di rendering aggiuntiva.
Passaggio 4 — Esportare il foglio di lavoro come report PDF
Una volta che i dati sono strutturati e formattati in Excel, l'esportazione in PDF crea un report portatile e professionale adatto per:
- Distribuzione agli stakeholder
- Documentazione di conformità
- Pipeline di reporting automatizzate
- Archiviazione
Salva foglio di lavoro Excel come report PDF
sheet.SaveToPdf("output.pdf")
Il tuo report PDF strutturato viene ora generato automaticamente dai dati dell'API.
Output:
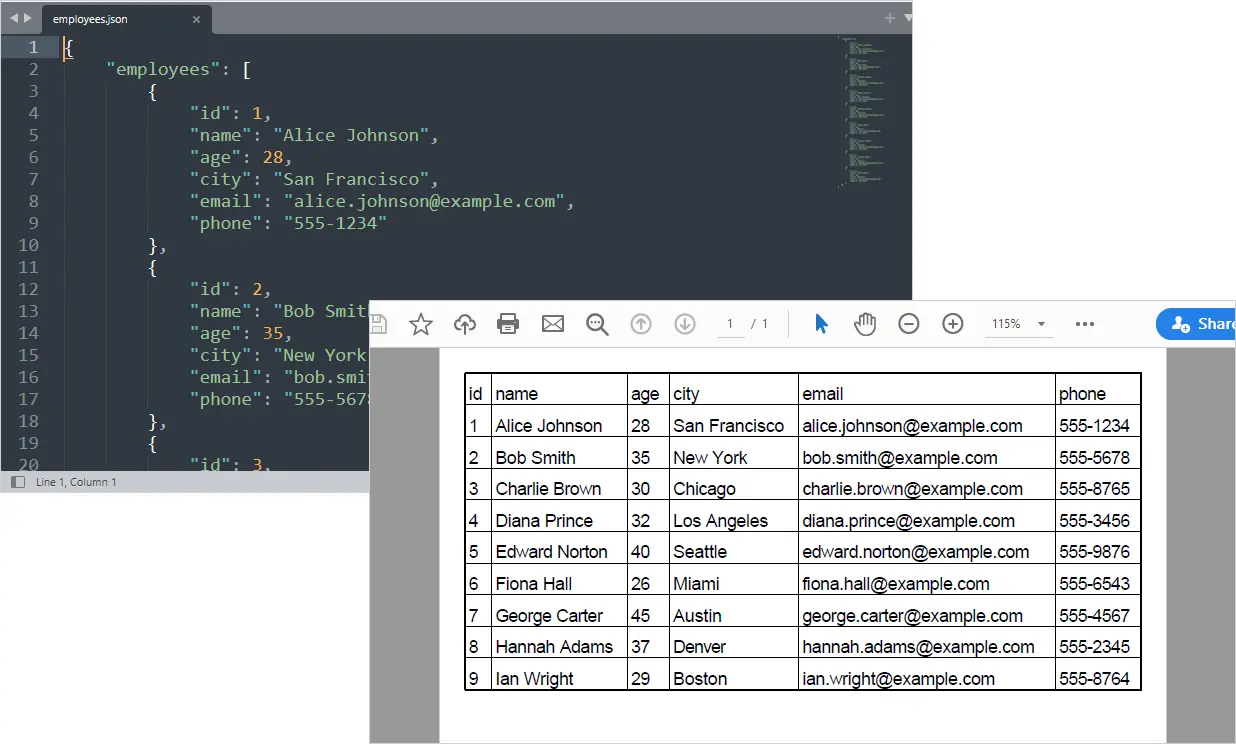
Potrebbe piacerti anche: Converti Excel in PDF in Python
Script completo — Dall'API JSON al report PDF strutturato
from spire.xls import *
from spire.xls.common import *
import json
import requests
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
# =========================
# Step 1: Get JSON from API
# =========================
api_url = "https://api.example.com/employees"
response = requests.get(api_url)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
raw_data = response.json()
# =========================
# Step 2: Normalize JSON
# =========================
data = normalize_json(raw_data)
# =========================
# Step 3: Create Workbook
# =========================
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
headers = list(data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write rows
for row_idx, row in enumerate(data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row.get(key, "")
# =========================
# Step 4: Format worksheet
# =========================
# Set conversion settings to adjust sheet layout
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True # Retain paper size during conversion
workbook.ConverterSetting.SheetFitToWidth = True # Fit sheet to width during conversion
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# =========================
# Step 5: Export to PDF
# =========================
sheet.SaveToPdf("output.pdf")
workbook.Dispose()
Se la tua origine dati è un file JSON locale anziché un'API in tempo reale, puoi caricare i dati direttamente dal disco prima di generare il report PDF.
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
Casi d'uso pratici
Questo flusso di lavoro di automazione può essere applicato a un'ampia gamma di scenari di reporting basati sui dati:
- Pipeline di reporting API automatizzate — Genera report PDF giornalieri o settimanali dai servizi di backend senza esportazioni manuali.
- Riepiloghi sull'utilizzo e l'attività SaaS — Converti le API di analisi delle applicazioni in report strutturati per clienti o interni.
- Esportazioni di report finanziari e delle risorse umane — Trasforma i dati API strutturati in documenti PDF standardizzati per la distribuzione interna.
- Istantanee del dashboard di analisi — Acquisisci metriche basate su API e convertile in report esecutivi condivisibili.
- Report di business intelligence pianificati — Crea automaticamente riepiloghi PDF da data warehouse o API di analisi.
- Documentazione di conformità e audit — Produci record PDF coerenti e con timestamp da set di dati API strutturati.
Considerazioni finali
L'automazione della generazione di report PDF dalle risposte API JSON consente agli sviluppatori di creare pipeline di reporting scalabili che eliminano l'elaborazione manuale. Combinando le funzionalità API di Python con le funzionalità di esportazione Excel e PDF di Spire.XLS per Python, è possibile creare report strutturati e professionali direttamente da origini dati in tempo reale.
Che tu stia generando report aziendali settimanali, dashboard interni o risultati finali per i clienti, questo flusso di lavoro offre flessibilità, automazione e pieno controllo sul processo di generazione dei report.
Da JSON a PDF: domande frequenti
Posso convertire JSON direttamente in PDF senza Excel?
Sì, ma l'utilizzo di Excel come livello intermedio semplifica la strutturazione di tabelle, il controllo dei layout e la generazione di una formattazione di report coerente e professionale.
Come gestisco risposte API di grandi dimensioni o paginate?
Scorri le pagine o i token forniti dall'API e unisci tutti i risultati in un unico set di dati prima di generare il report PDF.
Questo flusso di lavoro può essere eseguito automaticamente in base a una pianificazione?
Sì. Puoi automatizzare lo script utilizzando cron job, Utilità di pianificazione di Windows, pipeline CI/CD o servizi di backend per generare report regolarmente.
Come posso personalizzare il layout del report PDF?
Formatta il foglio di lavoro di Excel prima di esportare: regola la larghezza delle colonne, applica stili, blocca le intestazioni o aggiungi grafici. Queste impostazioni verranno mantenute nel PDF.
Cosa succede se l'API restituisce campi mancanti o incoerenti?
Utilizza metodi di estrazione sicuri come .get() con valori predefiniti durante l'analisi di JSON per prevenire errori e mantenere strutture di tabella coerenti.