
Nelle applicazioni moderne, JSON è uno dei formati di dati più comuni per API, file di configurazione e scambio di dati. Tuttavia, sebbene JSON sia ideale per le macchine, non è sempre leggibile dall'uomo. L'esportazione di JSON in una tabella PDF può aiutare a presentare le informazioni strutturate in modo chiaro in report, dashboard o documentazione interna.
In questo tutorial imparerai come convertire JSON in una tabella PDF ben formattata utilizzando Python e Spire.XLS, tra cui:
- Rilevamento automatico dei set di dati per l'esportazione in tabelle
- Appiattimento dei campi JSON nidificati
- Generazione di PDF dall'aspetto professionale
Copriremo anche l'estrazione manuale dei set di dati per strutture profondamente nidificate, offrendoti il pieno controllo su file JSON complessi.
Perché la conversione da JSON a PDF non è sempre semplice
JSON è disponibile in tutte le forme e dimensioni:
- Array piatti: facili da convertire direttamente in righe
- Oggetti nidificati: ad es. un dizionario di specifiche all'interno di ciascun prodotto
- Array all'interno di array: ad es. un elenco di prodotti all'interno di un reparto
- Chiavi incoerenti: alcuni oggetti hanno campi aggiuntivi o mancanti
Ad esempio, considera questa struttura per l'inventario di un negozio:
{
"store": {
"departments": [
{
"name": "Computers",
"products": [{"id": 1, "name": "Laptop", "specs": {"CPU": "i7"}}]
},
{
"name": "Accessories",
"products": [{"id": 101, "name": "Mouse", "colors": ["Black", "White"]}]
}
]
}
}
Appiattire questo in una tabella non è banale, perché i campi nidificati devono essere convertiti in colonne e gli array potrebbero dover essere espansi o uniti in stringhe. La nostra soluzione fornisce una gestione solida per la maggior parte delle strutture JSON, offrendo al contempo un'opzione per l'estrazione manuale per casi insolitamente complessi.
Per un rapido ripasso della sintassi e della struttura JSON, vedere: Introduzione a JSON
Passaggio 1 — Carica i dati JSON
Prima dell'elaborazione, carica il tuo file JSON in Python. L'utilizzo del modulo json integrato garantisce che il contenuto venga analizzato in dizionari ed elenchi Python nativi:
import json
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
Cosa fa questo passaggio:
- Legge un file JSON dal disco
- Lo converte in oggetti Python (dict e list) per un'ulteriore elaborazione
Suggerimento: specificare sempre encoding="utf-8" per evitare problemi con caratteri non ASCII.
Passaggio 2 — Rileva automaticamente il set di dati da esportare
Molti file JSON contengono più elenchi nidificati. Spesso, abbiamo bisogno dell'elenco di oggetti che rappresenta la "tabella principale", di solito l'elenco più grande di dizionari. La seguente funzione cerca automaticamente il set di dati più simile a una tabella:
def find_dataset(obj):
"""Recursively search JSON and return the most table-like dataset."""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No suitable dataset found.")
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# Usage
dataset = find_dataset(data)
Come funziona:
- Attraversa ricorsivamente la struttura JSON
- Assegna un punteggio agli elenchi di candidati in base al numero di chiavi × numero di elementi
- Sceglie il set di dati più ricco come tabella principale
Limitazioni:
- Non unirà automaticamente elenchi profondamente nidificati (ad es. prodotti di più reparti)
- Alcuni campi potrebbero richiedere l'estrazione manuale per una visibilità completa
Opzionale — Estrazione manuale del set di dati
Per set di dati profondamente nidificati o personalizzati, estrai manualmente i dati:
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
Questo approccio garantisce di acquisire i campi esatti di cui hai bisogno, inclusa l'aggiunta di contesto come il reparto per ogni prodotto.
Passaggio 3 — Appiattisci e normalizza JSON
Per convertire JSON in una tabella, le strutture nidificate devono essere appiattite:
def flatten_json(obj, parent_key="", sep="_"):
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
if not value:
items[new_key] = ""
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
def normalize_json(data):
flattened_rows = [flatten_json(item) for item in data]
all_keys_ordered, seen_keys = [], set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
rows, headers = normalize_json(dataset)
Cosa fa questo passaggio:
- Converte i dizionari nidificati in nomi di colonna come specs_CPU, specs_RAM
- Converte elenchi di primitive in stringhe separate da virgole
- Conserva la prima chiave vista come prima colonna
Passaggio 4 — Esporta in PDF tramite Excel
Una volta che i dati sono stati appiattiti, esportali come PDF utilizzando Spire.XLS for Python. Invece di eseguire il rendering diretto del PDF, utilizziamo Excel come livello di layout intermedio. Questo approccio fornisce il pieno controllo sulla struttura della tabella, sulla formattazione, sui margini e sul ridimensionamento prima dell'esportazione in PDF.
Installa dipendenza:
pip install spire.xls
Esporta JSON in PDF utilizzando Spire.XLS:
from spire.xls import Workbook
import os
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write data rows
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatting
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF saved: {output_path}")
Suggerimenti per la formattazione PDF:
- Adatta automaticamente le colonne al contenuto
- Imposta i margini per la leggibilità
- Abilita le linee della griglia per una migliore visualizzazione della tabella
Potrebbe piacerti anche: Converti Excel in PDF in Python
Passaggio 5 — Esempio: esporta prodotti da un file JSON complesso
Combina i passaggi precedenti:
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1: Automatic detection
dataset = find_dataset(data)
rows, headers = normalize_json(dataset)
# Option 2: Manual extraction for nested structure
# dataset = []
# for dept in data["store"]["departments"]:
# for prod in dept["products"]:
# prod["department"] = dept["name"]
# dataset.append(prod)
# rows, headers = normalize_json(dataset)
export_to_pdf(rows, headers, "output/Products.pdf")
Punti chiave:
- Il rilevamento automatico funziona per la maggior parte degli array JSON
- L'estrazione manuale garantisce il controllo su set di dati nidificati e gerarchici
Output:
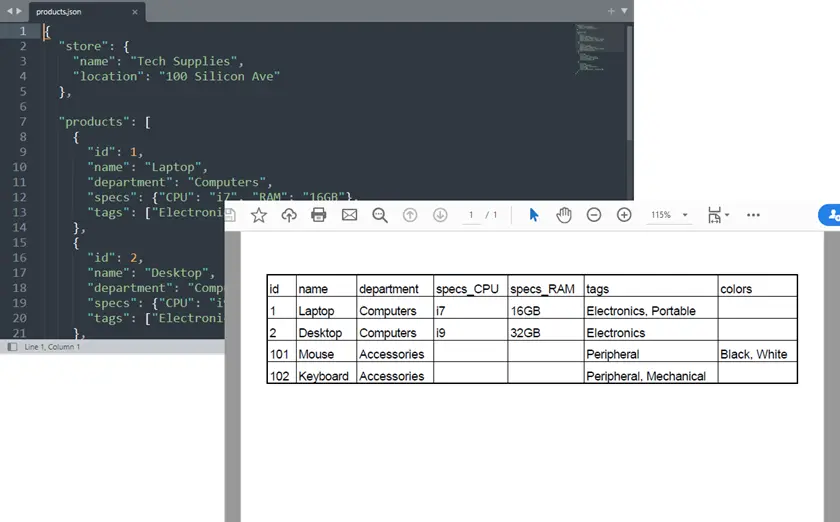
Esempio completo di Python: da JSON a PDF
from spire.xls import Workbook
import json
import os
# ---------------------------
# Atoumatically Detect dataset
# ---------------------------
def find_dataset(obj):
"""
Recursively search JSON and return the most table-like dataset.
Strategy:
- Find lists containing dictionaries
- Score datasets based on number of fields
- Choose the dataset with the richest structure
"""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
# Count unique keys across objects
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No suitable dataset found.")
# choose best scored dataset
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# ---------------------------
# Robust Recursive JSON Flattener
# ---------------------------
def flatten_json(obj, parent_key="", sep="_"):
"""
Recursively flattens nested dictionaries and lists.
Rules:
- Nested dict → key_subkey
- List of primitives → comma-separated string
- List of dicts → indexed columns (key_0_name, key_1_name)
- Mixed lists / arrays-of-arrays → recursively indexed (key_0_0, key_0_1)
"""
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
# Empty list
if not value:
items[new_key] = ""
# List of primitives
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
# Mixed or nested lists
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
# Top-level lists
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
# ---------------------------
# Normalize JSON Data (First-Seen Column Order)
# ---------------------------
def normalize_json(data):
"""
Flatten JSON objects and align headers, preserving the first-seen order.
The first key in the first JSON object will be the first column.
"""
if not isinstance(data, list):
raise ValueError("Data must be a list of objects.")
flattened_rows = [flatten_json(item) for item in data]
# Track headers in first-seen order
all_keys_ordered = []
seen_keys = set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
# Align all rows to include all keys
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
# ---------------------------
# Export to PDF via Excel
# ---------------------------
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write header
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write data rows
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatting
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF saved: {output_path}")
# ===========================
# Example: Complex JSON Dataset
# ===========================
# Load JSON from file
with open(r"C:\Users\Administrator\Desktop\Products.json", "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1. Automatically detect dataset (work for most cases)
dataset = find_dataset(data)
'''
# Option 2. Manually extract dataset (work for complex unusual structures)
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
'''
# Normalize (first-seen key becomes first column)
rows, headers = normalize_json(dataset)
# Export to PDF
export_to_pdf(rows, headers, "output/Products.pdf")
Conclusione
La conversione di JSON in una tabella PDF può essere complicata, specialmente con strutture nidificate o chiavi incoerenti. Utilizzando Python e Spire.XLS, puoi appiattire automaticamente JSON e preservare un ordine logico delle colonne, trasformando set di dati complessi in tabelle pulite e leggibili adatte per report o documentazione.
Il rilevamento automatico del set di dati gestisce la maggior parte dei file JSON, mentre l'estrazione manuale consente di acquisire dati nidificati specifici quando necessario. Questo approccio offre un modo flessibile e affidabile per convertire JSON in tabelle PDF professionali senza perdere struttura o contesto.
Domande frequenti
Può gestire qualsiasi file JSON?
Il rilevamento automatico funziona per la maggior parte, ma potrebbe essere necessaria l'estrazione manuale per dati profondamente nidificati.
Come viene determinato l'ordine delle colonne?
Le colonne vengono visualizzate nell'ordine della prima apparizione negli oggetti JSON.
È possibile unire più set di dati?
Sì, è possibile concatenare i set di dati prima dell'appiattimento.
Come gestire i campi mancanti?
I valori mancanti vengono rappresentati automaticamente come celle vuote.
Posso personalizzare il layout del PDF?
Sì, margini, linee della griglia e opzioni di adattamento automatico sono completamente configurabili tramite Spire.XLS.