
Java에서 PDF 파일로 작업할 때 바이너리 데이터와 텍스트 기반 형식 간에 변환해야 하는 경우가 많습니다. Base64 인코딩을 사용하면 PDF 콘텐츠를 일반 텍스트로 나타낼 수 있으며, 이는 문서를 JSON으로 전송하거나, 양식 제출을 통해 보내거나, 텍스트 기반 시스템에 저장할 때 유용합니다. Java의 표준 라이브러리는 java.util.Base64를 제공하여 추가 종속성 없이 Base64를 PDF로 및 PDF를 Base64로 변환하는 작업을 간단하게 구현할 수 있습니다.
이 튜토리얼에서는 JDK만 사용하여 이러한 변환을 처리하는 방법과 Base64 이미지로 작업하고 이를 PDF에 포함하는 방법을 살펴봅니다. Base64로 받은 PDF를 편집하고 다시 내보내는 것과 같은 고급 작업의 경우 Free Spire.PDF for Java를 사용하는 방법을 시연합니다.
목차
- Java에서 Base64를 PDF로 변환 (JDK만 사용)
- Java에서 PDF를 Base64로 변환 (JDK만 사용)
- 유효성 검사 및 안전 팁
- Java에서 Base64 이미지를 PDF로 저장
- Base64 PDF 로드, 수정 및 Base64로 다시 저장
- 성능 및 메모리 고려 사항
- FAQ
Java에서 Base64를 PDF로 변환 (JDK만 사용)
가장 간단한 방법은 Base64 문자열을 메모리로 읽어들인 다음, 선택적 접두사(예: data:application/pdf;base64,)를 제거하고 PDF로 디코딩하는 것입니다. 이 방법은 중소 규모 파일에 적합합니다.
import java.nio.file.*;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
public class Base64ToPdf {
public static void main(String[] args) throws Exception {
// 파일(또는 다른 소스)에서 Base64 텍스트 읽기
String base64 = Files.readString(Paths.get("sample.pdf.b64"), StandardCharsets.UTF_8);
// 존재하는 경우 일반적인 데이터 URI 접두사 제거
base64 = stripDataPrefix(base64);
// Base64를 원시 PDF 바이트로 디코딩
// MIME 디코더는 줄 바꿈 및 줄 바꿈된 텍스트를 허용합니다
byte[] pdfBytes = Base64.getMimeDecoder().decode(base64);
// 디코딩된 바이트를 PDF 파일에 쓰기
Files.write(Paths.get("output.pdf"), pdfBytes);
}
/** "data:application/pdf;base64," 접두사를 제거하는 유틸리티 */
private static String stripDataPrefix(String src) {
String s = src.trim();
int comma = s.indexOf(',');
if (comma > 0 && s.substring(0, comma).toLowerCase().contains("base64")) {
return s.substring(comma + 1).trim();
}
return s;
}
}
설명 이 예제는 메모리에 편안하게 맞는 Base64 콘텐츠에 대해 간단하고 신뢰할 수 있습니다. Base64.getMimeDecoder()는 이메일 시스템이나 API에서 내보낸 Base64 텍스트에서 흔히 볼 수 있는 줄 바꿈을 정상적으로 처리하기 때문에 선택되었습니다. Base64 문자열에 줄 바꿈이 없다는 것을 알고 있다면 Base64.getDecoder()를 사용할 수도 있습니다.
디코딩하기 전에 데이터 URI 접두사(data:application/pdf;base64,)를 제거해야 합니다. 이는 Base64 페이로드의 일부가 아니기 때문입니다. 도우미 메서드 stripDataPrefix()가 이를 자동으로 수행합니다.
스트리밍 변형 (메모리에 전체 문자열 없음)
대용량 PDF의 경우 Base64를 스트리밍 방식으로 처리하는 것이 좋습니다. 이렇게 하면 전체 Base64 문자열을 한 번에 메모리에 로드하는 것을 피할 수 있습니다.
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class Base64ToPdfStreamed {
public static void main(String[] args) throws Exception {
// 입력: Base64로 인코딩된 PDF가 포함된 텍스트 파일
Path in = Paths.get("sample.pdf.b64");
// 출력: 디코딩된 PDF 파일
Path out = Paths.get("output.pdf");
// 입력 스트림 주위에 Base64 디코더 래핑
try (InputStream b64In = Base64.getMimeDecoder().wrap(Files.newInputStream(in));
OutputStream pdfOut = Files.newOutputStream(out)) {
// 디코딩된 바이트를 PDF 출력으로 직접 스트리밍
b64In.transferTo(pdfOut);
}
}
}
설명 이 스트리밍 기반 접근 방식은 전체 문자열을 버퍼링하는 대신 데이터를 즉시 디코딩하므로 메모리 효율성이 더 높습니다. 대용량 파일이나 연속적인 스트림(예: 네트워크 소켓)에 권장되는 방법입니다.
- Base64.getMimeDecoder()는 입력의 줄 바꿈을 허용하는 데 사용됩니다.
- transferTo() 메서드는 수동 버퍼 처리 없이 디코딩된 바이트를 입력에서 출력으로 효율적으로 복사합니다.
- 실제 사용 시에는 파일 접근 오류나 부분 쓰기를 관리하기 위해 예외 처리를 추가하는 것을 고려하십시오.
Java에서 PDF를 Base64로 변환 (JDK만 사용)
PDF를 Base64로 인코딩하는 것도 마찬가지로 간단합니다. 작은 파일의 경우 전체 PDF를 메모리로 읽는 것이 좋습니다.
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64 {
public static void main(String[] args) throws Exception {
// PDF 파일을 바이트 배열로 읽기
byte[] pdfBytes = Files.readAllBytes(Paths.get("input.pdf"));
// PDF 바이트를 Base64 문자열로 인코딩
String base64 = Base64.getEncoder().encodeToString(pdfBytes);
// Base64 문자열을 텍스트 파일에 쓰기
Files.writeString(Paths.get("output.pdf.b64"), base64);
}
}
설명 이 접근 방식은 간단하며 중소 규모 파일에 적합합니다. 전체 PDF 파일이 바이트 배열로 읽혀 단일 Base64 문자열로 인코딩됩니다. 이 문자열은 저장하거나 JSON으로 전송하거나 데이터 URI에 포함할 수 있습니다.
스트리밍 인코더 (대용량 파일을 효율적으로 처리)
대용량 PDF의 경우 스트림으로 직접 인코딩하여 메모리 오버헤드를 피할 수 있습니다.
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64Streamed {
public static void main(String[] args) throws Exception {
// 입력: 바이너리 PDF 파일
try (InputStream pdfIn = Files.newInputStream(Paths.get("input.pdf"));
// Base64 텍스트 파일을 위한 원시 출력 스트림
OutputStream rawOut = Files.newOutputStream(Paths.get("output.pdf.b64"));
// 출력 스트림을 Base64 인코더로 래핑
OutputStream b64Out = Base64.getEncoder().wrap(rawOut)) {
// PDF 바이트를 Base64로 인코딩된 출력으로 직접 스트리밍
pdfIn.transferTo(b64Out);
}
}
}
설명 스트리밍 인코더는 모든 것을 메모리에 로드하는 대신 데이터를 점진적으로 인코딩하여 대용량 파일을 효율적으로 처리합니다. Base64.getEncoder().wrap() 메서드는 일반 출력 스트림을 자동으로 Base64 텍스트를 쓰는 스트림으로 변환합니다.
이 디자인은 대용량 PDF, 네트워크 스트림 또는 메모리 부담 없이 동시에 많은 문서를 처리해야 하는 서비스에 더 잘 확장됩니다.
유효성 검사 및 안전 팁
- 데이터 URI 감지: 사용자가 data:application/pdf;base64, 접두사를 보낼 수 있습니다. 디코딩하기 전에 제거하십시오.
- 줄 바꿈: 줄 바꿈된 줄이 포함될 수 있는 텍스트(이메일, 로그)를 디코딩할 때는 Base64.getMimeDecoder()를 사용하십시오.
- 빠른 온전성 검사: 디코딩 후 유효한 PDF의 첫 번째 바이트는 일반적으로 %PDF-로 시작합니다. 조기 실패 감지를 위해 이를 확인할 수 있습니다.
- 문자 인코딩: .b64 파일을 읽고 쓸 때 Base64 텍스트를 UTF-8(또는 US-ASCII)로 처리하십시오.
- 오류 처리: 디코드/인코드 작업을 try/catch로 감싸고 실행 가능한 메시지(예: 크기, 헤더 불일치)를 표시하십시오.
Java에서 Base64 이미지를 PDF로 저장
때때로 이미지(예: PNG 또는 JPEG)를 Base64 문자열로 받고 이를 PDF로 래핑해야 하는 경우가 있습니다. Java의 표준 라이브러리에는 PDF API가 없지만 Free Spire.PDF for Java를 사용하면 간단하게 할 수 있습니다.
Free Spire.PDF for Java를 다운로드하여 프로젝트에 추가하거나 Maven 저장소에서 Free Spire.PDF for Java를 설치할 수 있습니다.
주요 Spire.PDF 개념
- PdfDocument — 하나 이상의 PDF 페이지를 담는 컨테이너입니다.
- PdfPageBase — 그릴 수 있는 페이지를 나타냅니다.
- PdfImage.fromImage() — BufferedImage 또는 스트림을 그릴 수 있는 PDF 이미지로 로드합니다.
- drawImage() — 지정된 좌표와 크기로 이미지를 배치합니다.
- 좌표계 — Spire.PDF는 (0,0)이 왼쪽 상단 모서리인 좌표계를 사용합니다.
예제: Java를 사용하여 Base64 이미지를 PDF로 변환
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImage;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.*;
import java.util.Base64;
public class Base64ImageToPdf {
public static void main(String[] args) throws Exception {
// 1) Base64 파일 읽기 및 디코딩 (데이터 URI 접두사가 있는 경우 제거)
String base64Image = Files.readString(Paths.get("G:/Document/image.b64"), StandardCharsets.UTF_8).trim();
int comma = base64Image.indexOf(',');
if (comma > 0 && base64Image.substring(0, comma).toLowerCase().contains("base64")) {
base64Image = base64Image.substring(comma + 1).trim();
}
byte[] imageBytes = Base64.getMimeDecoder().decode(base64Image);
// 2) PDF 생성 및 이미지 삽입
PdfDocument pdf = new PdfDocument();
try (ByteArrayInputStream in = new ByteArrayInputStream(imageBytes)) {
PdfImage img = PdfImage.fromStream(in);
pdf.getPageSettings().setWidth(img.getWidth());
pdf.getPageSettings().setHeight(img.getHeight());
pdf.getPageSettings().setMargins(0, 0, 0, 0);
PdfPageBase page = pdf.getPages().add();
page.getCanvas().drawImage(img, 0, 0);
}
// 3) PDF 파일 저장
pdf.saveToFile("output/image.pdf");
}
}
다음 예제는 Base64 이미지를 디코딩하여 PDF 페이지에 포함시킵니다. 출력은 다음과 같습니다.
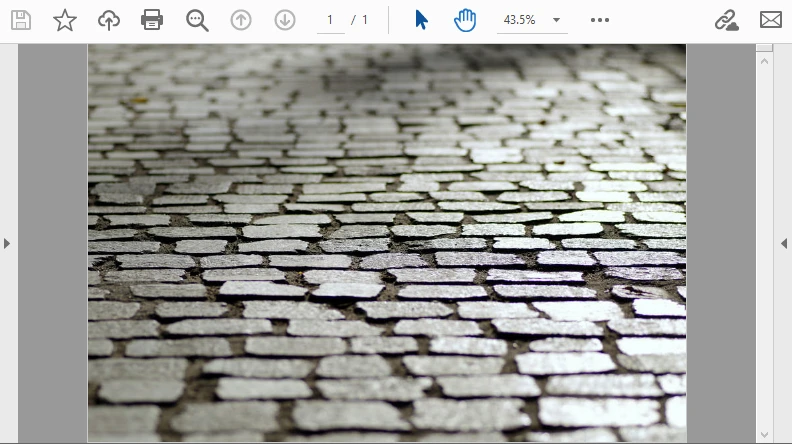
이 워크플로는 Base64로 도착하는 스캔된 문서나 서명을 포함하는 데 이상적입니다.
벡터 그래픽의 경우 Java에서 SVG를 PDF로 변환하는 가이드를 참조할 수도 있습니다.
Base64 PDF 로드, 수정 및 Base64로 다시 저장
많은 API에서 PDF는 Base64로 도착합니다. Spire.PDF를 사용하면 이를 로드하고, 페이지에 그림(텍스트/워터마크)을 그리고, 다시 Base64를 반환할 수 있어 서버리스 함수나 마이크로서비스에 이상적입니다.
여기서 사용되는 주요 Spire.PDF 개념
- PdfDocument.loadFromBytes(byte[]) — 디코딩된 바이트에서 직접 문서를 구성합니다.
- PdfPageBase#getCanvas() — 텍스트, 도형 또는 이미지를 배치할 그리기 표면을 가져옵니다.
- 글꼴 및 브러시 — 예: PdfTrueTypeFont 또는 PdfFont를 통한 내장 글꼴, 색칠을 위한 PdfSolidBrush.
- 메모리에 저장 — pdf.saveToStream(ByteArrayOutputStream)은 원시 바이트를 생성하며, 이를 Base64로 다시 인코딩할 수 있습니다.
예제: Java에서 Base64 PDF 로드, 수정 및 저장
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.io.*;
import java.util.Base64;
public class EditBase64Pdf {
public static void main(String[] args) throws Exception {
String base64Pdf = "..."; // 들어오는 Base64 PDF 문자열
// 바이트로 디코딩
byte[] pdfBytes = Base64.getDecoder().decode(base64Pdf);
// PDF 로드
PdfDocument pdf = new PdfDocument();
pdf.loadFromBytes(pdfBytes);
// 각 페이지에 스탬프 추가
for (PdfPageBase page : (Iterable) pdf.getPages()) {
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial", Font.BOLD, 36));
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLUE));
page.getCanvas().drawString("Processed", font, brush, 100, 100);
}
// 메모리에 저장하고 다시 Base64로 인코딩
ByteArrayOutputStream output = new ByteArrayOutputStream();
pdf.saveToStream(output);
pdf.close();
String resultBase64 = Base64.getEncoder().encodeToString(output.toByteArray());
System.out.println(resultBase64);
}
}
이 예제에서는 PDF의 각 페이지에 파란색 'Processed' 워터마크를 추가한 다음 다시 Base64로 인코딩합니다. 결과는 다음과 같습니다.
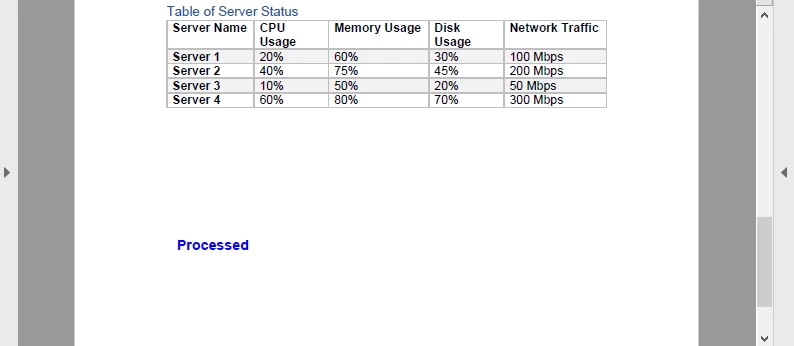
이 왕복(Base64 → PDF → Base64)은 송장 스탬핑이나 클라우드 서비스에서 동적 서명 추가와 같은 문서 파이프라인에 유용합니다.
관련 튜토리얼:
Java에서 PDF 텍스트 추출 | Java에서 PDF 문서 생성
성능 및 메모리 고려 사항
- 스트리밍 대 파일 I/O — Base64를 다룰 때 불필요한 임시 파일을 피하기 위해 ByteArrayInputStream 및 ByteArrayOutputStream을 선호합니다.
- 이미지가 많은 PDF — Base64 이미지 디코딩은 메모리 사용량을 급증시킬 수 있습니다. 포함하기 전에 크기를 조정하거나 압축하는 것을 고려하십시오.
- 대용량 PDF — Spire.PDF는 수 MB의 PDF를 처리하지만 매우 큰 문서의 경우 페이지별 처리를 고려하십시오.
- 서버리스 함수 — Base64 워크플로는 파일 시스템 종속성을 피하고 API 응답을 통해 직접 결과를 반환하기 때문에 잘 맞습니다.
FAQ
Q: JDK만 사용하여 Base64를 PDF로 변환할 수 있나요?
예. Java SE는 Base64 및 파일 I/O 유틸리티를 제공하므로 추가 라이브러리 없이 변환을 처리할 수 있습니다.
Q: 표준 Java 라이브러리로 PDF를 편집할 수 있나요?
아니요. Java SE는 PDF 구조 구문 분석이나 렌더링을 지원하지 않습니다. 편집을 위해서는 Spire.PDF for Java와 같은 전용 라이브러리를 사용하십시오.
Q: Free Spire.PDF for Java로 충분한가요?
예. Free Spire.PDF for Java는 문서 크기가 제한되지만 테스트나 소규모 프로젝트에는 충분합니다.
Q: PDF를 디스크에 저장해야 하나요?
항상 그런 것은 아닙니다. 변환은 종종 API 및 클라우드 앱에 선호되는 스트림을 사용하여 메모리 내에서 실행될 수도 있습니다.