
PDF 파일은 문서 교환에 널리 사용되지만 모든 PDF가 스캔된 문서처럼 작동하는 것은 아닙니다. 많은 PDF에는 편집 가능한 텍스트 레이어, 벡터 그래픽 및 선택 가능한 콘텐츠가 포함되어 있어 쉽게 수정, 복사 또는 재사용할 수 있습니다.
보관, 공개 배포 또는 문서 최종화와 같은 실제 시나리오에서는 PDF가 스캔된 파일처럼 보이고 작동하기를 원할 수 있습니다. PDF를 스캔된 PDF로 변환하면 편집 가능한 구조가 제거되고 각 페이지가 이미지 기반 표현으로 바뀝니다.
이 가이드에서는 스캔된 PDF가 무엇인지, 왜 필요한지, 온라인 도구나 Python 자동화를 사용하여 PDF를 스캔된 문서로 변환하는 방법을 설명합니다.
빠른 탐색
- 스캔된 PDF란 무엇인가?
- PDF를 스캔된 PDF로 변환하는 이유
- 방법 1: 온라인 도구를 사용하여 PDF를 스캔된 PDF로 변환
- 방법 2: Python으로 PDF를 스캔된 PDF로 변환
- PDF와 스캔된 PDF: 주요 차이점
- 스캔된 PDF를 여전히 편집할 수 있나요?
- 자주 묻는 질문
스캔된 PDF란 무엇인가?
스캔된 PDF는 각 페이지가 편집 가능한 텍스트나 벡터 객체가 아닌 이미지로 저장되는 PDF 문서입니다. 실제 스캐너로 종이를 스캔하여 만든 문서와 매우 유사합니다.
스캔된 PDF의 주요 특징은 다음과 같습니다.
- 텍스트를 선택하거나 편집할 수 없음
- 페이지가 이미지 기반임
- 레이아웃과 모양이 시각적으로 고정됨
- 파일 크기가 일반적으로 텍스트 기반 PDF보다 큼
- OCR을 적용하지 않으면 텍스트 검색을 사용할 수 없음
PDF를 스캔된 PDF로 변환하면 본질적으로 콘텐츠를 평탄화하고 내부 구조를 제거하는 것입니다.
PDF를 스캔된 PDF로 변환하는 이유
PDF를 스캔된 문서로 바꾸는 것은 여러 상황에서 유용합니다.
- 임의의 편집이나 콘텐츠 재사용 방지
- 보관용 문서 준비
- 최종 보고서 또는 공지 배포
- 종이 기반 워크플로우 시뮬레이션
- 플랫폼 간 문서 모양 표준화
권한 기반 보호와 비교할 때 스캔된 PDF는 뷰어에서 강제하는 규칙이 아닌 구조적 변환에 의존하므로 임의의 수정에 더 강합니다.
방법 1: 온라인 도구를 사용하여 PDF를 스캔된 PDF로 변환
온라인 PDF 변환기는 민감하지 않은 문서의 빠르고 일회성 변환에 적합합니다.
단계:
-
신뢰할 수 있는 PDF를 스캔된 PDF로 변환하는 웹사이트(예: SafePDFKit)를 엽니다.
-
변환하려는 PDF 파일을 업로드합니다.
-
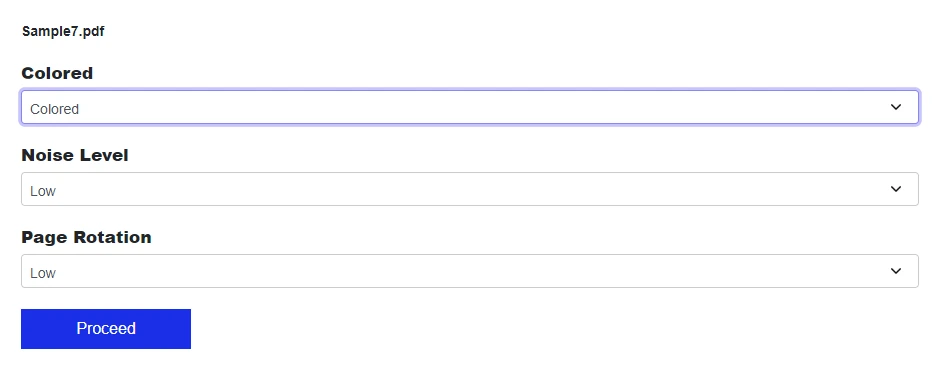
색상 모드, 노이즈 수준 및 페이지 회전과 같은 설정을 구성합니다.
-
스캔된 PDF를 변환하고 다운로드합니다.
가장 적합한 경우:
- 가끔씩 하는 변환
- 공개 또는 저위험 문서
- 브라우저 기반 도구를 선호하는 사용자
참고: 서비스가 업로드된 문서의 처리 및 삭제 방법을 명확하게 설명하지 않는 한 기밀 파일을 업로드하지 마십시오.
암호 보호를 통해 편집, 복사 또는 인쇄를 제한하려면 PDF를 암호화하는 방법에 대한 자세한 가이드를 참조할 수 있습니다.
방법 2: Python으로 PDF를 스캔된 PDF로 변환
일괄 처리 또는 자동화된 워크플로우의 경우 Python은 PDF를 스캔된 이미지 기반 문서로 변환하는 신뢰할 수 있는 방법을 제공합니다.
Spire.PDF for Python과 같은 라이브러리를 사용하면 각 PDF 페이지를 이미지로 렌더링하고 해당 이미지를 사용하여 새 PDF를 다시 빌드할 수 있습니다.
1단계: 라이브러리 설치
pip install spire.pdf
또한 Spire.PDF for Python을 다운로드하여 프로젝트에 수동으로 추가할 수도 있습니다.
2단계: PDF 페이지를 이미지로 변환하고 PDF 다시 빌드
from spire.pdf import *
# 원본 PDF 로드
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# 스캔된 출력을 위한 새 PDF 생성
scanned_pdf = PdfDocument()
# 각 페이지를 이미지로 변환
for i in range(pdf.Pages.Count):
image_stream = pdf.SaveAsImage(i)
image = PdfImage.FromStream(image_stream)
page = scanned_pdf.Pages.Add(
SizeF(float(image.Width), float(image.Height)),
PdfMargins(0.0, 0.0)
)
page.Canvas.DrawImage(
image,
RectangleF.FromLTRB(0.0, 0.0, float(image.Width), float(image.Height))
)
# 스캔된 PDF 저장
scanned_pdf.SaveToFile("ScannedPDF.pdf")
pdf.Dispose()
scanned_pdf.Dispose()
변환된 스캔된 PDF 미리보기:
이 스캔된 PDF에서는 모든 페이지가 전체 페이지 이미지로 렌더링되고 포함됩니다. 이 변환은 원본 텍스트 레이어와 문서 구조를 제거하여 콘텐츠를 편집할 수 없고 선택할 수 없게 만듭니다.
프로그래밍 방식 변환의 장점:
- 일관된 출력 품질
- 일괄 처리 지원
- 수동 개입 없음
- 문서 파이프라인에 쉽게 통합
보다 유연한 일괄 워크플로우를 위해 Python은 PDF를 이미지로 직접 변환하거나 PDF를 암호화하여 편집 및 콘텐츠 재사용의 위험을 더욱 줄이는 것을 지원합니다.
PDF와 스캔된 PDF: 주요 차이점
| 기능 | 표준 PDF | 스캔된 PDF |
|---|---|---|
| 편집 가능한 텍스트 | 예 | 아니요 |
| 텍스트 선택 | 예 | 아니요 |
| 검색 가능한 콘텐츠 | 예 | 아니요 (OCR 제외) |
| 파일 크기 | 더 작음 | 더 큼 |
| 최적 사용 사례 | 편집 및 재사용 | 배포 및 보관 |
빠른 팁: 사용자가 문서를 보기만 하고 콘텐츠를 재사용하거나 수정해서는 안 되는 경우 스캔된 PDF가 더 나은 선택인 경우가 많습니다.
스캔된 PDF를 여전히 편집할 수 있나요?
스캔된 PDF는 표준 PDF보다 편집하기가 훨씬 어렵지만 절대적으로 편집할 수 없는 것은 아닙니다.
- 고급 편집기는 이미지를 교체할 수 있음
- OCR 도구는 텍스트를 추출할 수 있음
- 콘텐츠를 수동으로 다시 입력할 수 있음
그러나 대부분의 사용자와 일상적인 워크플로우에서 스캔된 PDF는 편집 및 콘텐츠 재사용을 효과적으로 방지합니다.
모범 사례:
- 원본 편집 가능한 PDF를 안전하게 보관
- 배포 또는 보관을 위해 스캔된 PDF 사용
- 텍스트 검색이 필요한 경우에만 OCR과 결합
결론
PDF를 스캔된 PDF로 변환하는 것은 편집 가능한 문서를 시각적으로 고정된 이미지 기반 파일로 바꾸는 실용적인 방법입니다. 텍스트 구조를 제거하고 각 페이지를 이미지로 평탄화함으로써 스캔된 PDF는 최종 콘텐츠를 공유하고 문서 무결성을 보존하는 데 더 적합합니다.
빠른 작업을 위해 온라인 PDF를 스캔된 PDF 변환기를 사용하든 대규모 워크플로우를 위해 Python 자동화를 사용하든 올바른 접근 방식을 선택하면 문서가 일관되고 전문적이며 임의의 수정에 강하게 유지됩니다.
자주 묻는 질문
PDF를 스캔된 PDF로 변환하면 검색 가능한 텍스트가 제거되나요?
예. PDF가 스캔된 PDF로 변환되면 각 페이지가 이미지로 저장되므로 원본 텍스트 레이어가 제거됩니다. 결과적으로 OCR을 나중에 적용하지 않으면 텍스트를 검색하거나 선택할 수 없습니다.
PDF를 스캔된 문서로 변환하면 파일 크기가 증가하나요?
대부분의 경우 그렇습니다. 스캔된 PDF는 이미지 기반이며 이미지 데이터는 일반적으로 텍스트 및 벡터 콘텐츠보다 더 많은 저장 공간을 필요로 합니다. 최종 파일 크기는 이미지 해상도 및 압축 설정과 같은 요소에 따라 다릅니다.
스캔된 PDF와 PDF를 이미지로 내보내는 것의 차이점은 무엇인가요?
PDF를 이미지로 내보내면 별도의 이미지 파일이 생성되지만 스캔된 PDF는 해당 이미지를 단일 PDF 문서에 다시 포함합니다. 스캔된 PDF는 PDF 컨테이너 형식을 유지하므로 공유, 보기 및 보관이 더 쉽습니다.
스캔된 PDF가 편집이나 복사를 완전히 방지할 수 있나요?
스캔된 PDF는 편집 가능한 텍스트가 없기 때문에 임의의 편집 및 복사를 크게 줄입니다. 그러나 고급 도구나 OCR 소프트웨어는 여전히 콘텐츠를 추출할 수 있으므로 스캔된 PDF는 절대적인 보호가 아닌 실용적인 억제책으로 보아야 합니다.