
최신 애플리케이션은 구조화된 JSON 데이터를 반환하는 API에 크게 의존합니다. 이 데이터는 소프트웨어 시스템에 이상적이지만 이해 관계자와 비즈니스 팀은 종종 읽기 쉽고 공유 가능한 형식으로 제공되는 정보가 필요하며 PDF 보고서는 문서화, 감사 및 배포를 위해 가장 널리 사용되는 표준 중 하나로 남아 있습니다.
온라인 도구를 사용하여 JSON 파일을 수동으로 변환하는 대신 개발자는 실시간 API 데이터 검색에서 구조화된 PDF 보고서 생성에 이르기까지 전체 워크플로를 자동화할 수 있습니다.
이 자습서에서는 Python을 사용하여 엔드투엔드 자동화 파이프라인을 구축하는 방법을 배웁니다.
이 접근 방식은 예약된 보고, SaaS 대시보드, 분석 내보내기 및 백엔드 자동화 시스템에 이상적입니다.
온라인 JSON-PDF 변환기가 충분하지 않은 이유
온라인 변환기는 빠르고 일회성 작업에 유용할 수 있습니다. 그러나 라이브 API 또는 자동화된 워크플로로 작업할 때 종종 부족합니다.
일반적인 제한 사항은 다음과 같습니다.
- API에서 직접 데이터를 가져올 수 없음
- 자동화 또는 예약 지원 부족
- 제한된 서식 및 보고서 레이아웃 제어
- 중첩된 JSON 구조 처리의 어려움
- 민감한 데이터를 업로드할 때의 개인 정보 보호 문제
- 백엔드 파이프라인 또는 CI/CD 시스템과의 통합 없음
자동화된 보고 시스템을 구축하는 개발자에게 프로그래밍 방식 워크플로는 훨씬 더 많은 유연성, 확장성 및 제어 기능을 제공합니다. Python 및 Spire.XLS를 사용하면 수동 개입 없이 API 응답에서 직접 구조화된 보고서를 생성할 수 있습니다.
전제 조건 및 아키텍처 개요: JSON API → Excel → PDF 파이프라인
자동화 워크플로를 구축하기 전에 환경이 준비되었는지 확인하십시오.
pip install spire.xls requests
Excel을 중간 계층으로 사용하는 이유는 무엇입니까?
이 자습서에서는 JSON을 PDF로 직접 변환하는 대신 Excel을 구조화된 보고 계층으로 사용합니다. 이 접근 방식은 몇 가지 이점을 제공합니다.
- 구조화되지 않은 JSON을 깔끔한 표 형식 레이아웃으로 변환
- 쉬운 서식 및 열 제어 가능
- 일관된 PDF 출력 보장
- 차트 및 요약과 같은 향후 개선 사항 지원
파이프라인 아키텍처
자동화 프로세스는 구조화된 변환 파이프라인을 따릅니다.
- API 계층 : 백엔드 서비스에서 라이브 JSON 데이터 검색
- 데이터 처리 계층 : JSON 구조 정규화 및 평탄화
- 보고서 레이아웃 계층(Excel) : 데이터를 읽기 쉬운 표로 구성
- 내보내기 계층(PDF) : 공유 가능한 최종 보고서 생성
이 계층화된 접근 방식은 확장성을 향상시키고 보고 논리를 향후 자동화 시나리오에 유연하게 유지합니다.
1단계 — API에서 JSON 데이터 검색
대부분의 자동화된 보고 워크플로는 API에서 라이브 데이터를 수집하는 것으로 시작됩니다. 파일을 수동으로 내보내는 대신 스크립트가 백엔드 서비스, 분석 플랫폼 또는 SaaS 애플리케이션에서 최신 레코드를 직접 가져옵니다. 이렇게 하면 다음이 보장됩니다.
- 보고서에는 항상 최신 데이터가 포함됩니다.
- 수동 다운로드 또는 변환 단계 없음
- 예약된 자동화 파이프라인에 쉽게 통합
다음은 Python을 사용하여 JSON 데이터를 검색하는 방법을 보여주는 예입니다.
import requests
# Example API endpoint
url = "https://api.example.com/employees"
headers = {
"Authorization": "Bearer YOUR_API_TOKEN"
}
response = requests.get(url, headers=headers, timeout=30)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
api_data = response.json()
print("Records retrieved:", len(api_data))
주요 관행:
- 항상 HTTP 상태 코드 유효성 검사
- 필요할 때 인증 헤더 포함
- 속도 제한 및 API 조절 처리
- 데이터 세트가 클 때 페이지 매김 준비
이 자습서의 예에서는 널리 사용되는 Python 요청 라이브러리를 사용하여 HTTP 통신을 처리합니다. 고급 인증 및 세션 관리 패턴은 공식 요청 설명서를 참조하십시오.
2단계 — JSON 응답 구문 분석 및 구조화
모든 JSON 파일이 동일한 구조를 공유하는 것은 아닙니다. 일부 API는 간단한 레코드 목록을 반환하는 반면 다른 API는 데이터를 객체 내에 래핑하거나 중첩된 배열 및 하위 필드를 포함합니다. 복잡한 JSON을 Excel에 직접 작성하면 종종 오류가 발생하거나 읽을 수 없는 보고서가 생성됩니다.
다양한 JSON 구조 이해
| JSON 유형 | 예제 구조 | 직접 Excel 내보내기 |
|---|---|---|
| 단순 목록 | [ {…}, {…} ] | 직접 작동 |
| 래핑된 목록 | { "employees": [ {…} ] } | ⚠ 먼저 목록 추출 |
| 중첩된 객체 | { "address": { "city": "NY" } } | ⚠ 필드 평탄화 |
| 중첩된 배열 | { "skills": ["Python", "SQL"] } | ⚠ 문자열로 변환 |
정규화된 구조는 다음과 같아야 합니다.
[
{"id":1,"name":"Alice","city":"NY","skills":"Python, SQL"}
]
이 형식은 Excel 행에 직접 쓸 수 있습니다. 중첩된 객체와 배열이 어떻게 구조화되어 있는지 잘 모르는 경우 공식 JSON 데이터 형식 사양을 검토하면 복잡한 API 응답이 어떻게 구성되어 있는지 명확히 하는 데 도움이 될 수 있습니다.
보고서 생성 전 JSON 정규화
모든 API에 대해 JSON을 수동으로 수정하는 대신 자동으로 다음을 수행할 수 있습니다.
- 래핑된 목록 감지
- 중첩된 객체 평탄화
- 배열을 읽기 쉬운 문자열로 변환
- 보고용 데이터 표준화
다음은 재사용 가능한 정규화 도우미입니다.
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
참고: 깊이 중첩된 다단계 JSON 구조는 API 복잡성에 따라 추가적인 재귀적 평탄화가 필요할 수 있습니다.
사용 예:
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
structured_data = normalize_json(raw_data)
이렇게 하면 JSON 복잡성에 관계없이 데이터 세트가 Excel 내보내기에 안전합니다.
3단계 — 구조화된 JSON 데이터를 Excel 워크시트에 로드
Excel은 JSON 정규화 후 구조화된 보고 계층 역할을 합니다. 복잡한 JSON 구조가 간단한 사전 목록으로 평탄화되면 데이터를 행과 열에 직접 작성하여 추가 서식 지정 및 PDF 내보내기를 할 수 있습니다.
Spire.XLS for Python을 사용하면 개발자는 Microsoft Excel 없이도 코드를 통해 전적으로 Excel 보고서를 빌드, 수정 및 서식 지정할 수 있으므로 고급 스프레드시트 작업을 자동화된 보고 워크플로에 쉽게 통합할 수 있습니다.
통합 문서 및 워크시트 만들기
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
작동 방식:
- 메모리에 새 Excel 파일을 초기화합니다.
- 첫 번째 워크시트에 액세스합니다.
- 구조화된 데이터를 작성하기 위한 캔버스를 준비합니다.
머리글 및 데이터 행 쓰기
headers = list(structured_data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
for row_idx, row in enumerate(structured_data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = str(row.get(key, ""))
작동 방식:
- 구조화된 데이터에서 열 머리글을 추출합니다.
- 먼저 머리글 행을 씁니다.
- 레코드를 반복하고 행을 순차적으로 채웁니다.
- 일관된 출력을 보장하기 위해 값을 문자열로 변환합니다.
내보내기 전 서식 준비
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
워크시트가 이미 레이아웃과 서식을 정의했기 때문에 PDF 내보내기는 추가 렌더링 논리 없이 시각적 구조를 유지합니다.
4단계 — 워크시트를 PDF 보고서로 내보내기
데이터가 Excel에서 구조화되고 서식이 지정되면 PDF로 내보내면 다음에 적합한 휴대용 전문 보고서가 생성됩니다.
- 이해 관계자에게 배포
- 규정 준수 문서
- 자동화된 보고 파이프라인
- 보관 저장소
Excel 워크시트를 PDF 보고서로 저장
sheet.SaveToPdf("output.pdf")
이제 구조화된 PDF 보고서가 API 데이터에서 자동으로 생성됩니다.
출력:
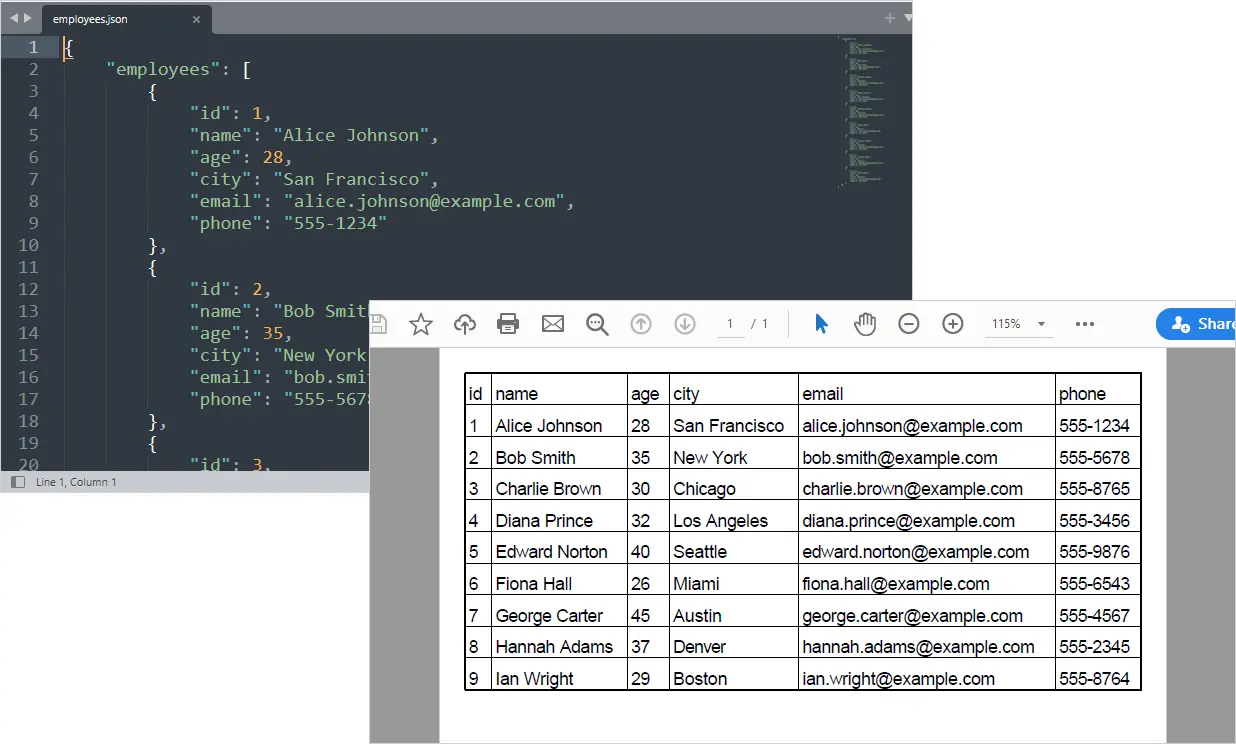
관심 있을 만한 다른 글: Python에서 Excel을 PDF로 변환
전체 스크립트 — API JSON에서 구조화된 PDF 보고서까지
from spire.xls import *
from spire.xls.common import *
import json
import requests
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
# =========================
# Step 1: Get JSON from API
# =========================
api_url = "https://api.example.com/employees"
response = requests.get(api_url)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
raw_data = response.json()
# =========================
# Step 2: Normalize JSON
# =========================
data = normalize_json(raw_data)
# =========================
# Step 3: Create Workbook
# =========================
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
headers = list(data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write rows
for row_idx, row in enumerate(data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row.get(key, "")
# =========================
# Step 4: Format worksheet
# =========================
# Set conversion settings to adjust sheet layout
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True # Retain paper size during conversion
workbook.ConverterSetting.SheetFitToWidth = True # Fit sheet to width during conversion
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# =========================
# Step 5: Export to PDF
# =========================
sheet.SaveToPdf("output.pdf")
workbook.Dispose()
데이터 소스가 라이브 API가 아닌 로컬 JSON 파일인 경우 PDF 보고서를 생성하기 전에 디스크에서 직접 데이터를 로드할 수 있습니다.
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
실용적인 사용 사례
이 자동화 워크플로는 광범위한 데이터 기반 보고 시나리오에 적용할 수 있습니다.
- 자동화된 API 보고 파이프라인 — 수동 내보내기 없이 백엔드 서비스에서 매일 또는 매주 PDF 보고서를 생성합니다.
- SaaS 사용 및 활동 요약 — 애플리케이션 분석 API를 구조화된 고객 또는 내부 보고서로 변환합니다.
- 재무 및 HR 보고 내보내기 — 구조화된 API 데이터를 내부 배포를 위한 표준화된 PDF 문서로 변환합니다.
- 분석 대시보드 스냅샷 — API 기반 메트릭을 캡처하고 공유 가능한 경영진 보고서로 변환합니다.
- 예약된 비즈니스 인텔리전스 보고서 — 데이터 웨어하우스 또는 분석 API에서 PDF 요약을 자동으로 빌드합니다.
- 규정 준수 및 감사 문서 — 구조화된 API 데이터 세트에서 일관되고 타임스탬프가 찍힌 PDF 레코드를 생성합니다.
최종 생각
JSON API 응답에서 PDF 보고서 생성을 자동화하면 개발자가 수동 처리를 제거하는 확장 가능한 보고 파이프라인을 구축할 수 있습니다. Python의 API 기능과 Spire.XLS for Python의 Excel 및 PDF 내보내기 기능을 결합하면 라이브 데이터 소스에서 직접 구조화된 전문 보고서를 만들 수 있습니다.
주간 비즈니스 보고서, 내부 대시보드 또는 고객 결과물을 생성하든 이 워크플로는 유연성, 자동화 및 보고서 생성 프로세스에 대한 완전한 제어를 제공합니다.
JSON을 PDF로: FAQ
Excel 없이 JSON을 PDF로 직접 변환할 수 있습니까?
예, 하지만 Excel을 중간 계층으로 사용하면 테이블을 구조화하고, 레이아웃을 제어하고, 일관되고 전문적인 보고서 서식을 생성하기가 더 쉽습니다.
크거나 페이지가 매겨진 API 응답은 어떻게 처리합니까?
API에서 제공하는 페이지 또는 토큰을 반복하고 PDF 보고서를 생성하기 전에 모든 결과를 단일 데이터 세트로 병합합니다.
이 워크플로를 일정에 따라 자동으로 실행할 수 있습니까?
예. cron 작업, Windows 작업 스케줄러, CI/CD 파이프라인 또는 백엔드 서비스를 사용하여 스크립트를 자동화하여 정기적으로 보고서를 생성할 수 있습니다.
PDF 보고서 레이아웃을 어떻게 사용자 정의합니까?
내보내기 전에 Excel 워크시트 서식을 지정합니다. 열 너비를 조정하고, 스타일을 적용하고, 머리글을 고정하거나, 차트를 추가합니다. 이러한 설정은 PDF에 유지됩니다.
API가 누락되거나 일관되지 않은 필드를 반환하면 어떻게 됩니까?
JSON을 구문 분석할 때 오류를 방지하고 일관된 테이블 구조를 유지하려면 기본값이 있는 .get()과 같은 안전한 추출 방법을 사용하십시오.