
최신 애플리케이션에서 JSON은 API, 구성 파일 및 데이터 교환을 위한 가장 일반적인 데이터 형식 중 하나입니다. 그러나 JSON은 기계에 이상적이지만 항상 사람이 읽을 수 있는 것은 아닙니다. JSON을 PDF 테이블로 내보내면 보고서, 대시보드 또는 내부 문서에서 구조화된 정보를 명확하게 표시하는 데 도움이 될 수 있습니다.
이 튜토리얼에서는 Python과 Spire.XLS를 사용하여 JSON을 잘 형식화된 PDF 테이블로 변환하는 방법을 배우게 됩니다. 포함된 내용:
또한 깊이 중첩된 구조에 대한 수동 데이터 세트 추출을 다루어 복잡한 JSON 파일을 완벽하게 제어할 수 있도록 합니다.
JSON을 PDF로 변환하는 것이 항상 간단하지 않은 이유
JSON은 모든 모양과 크기로 제공됩니다:
- 플랫 배열: 행으로 직접 변환하기 쉬움
- 중첩된 객체: 예: 각 제품 내부의 사양 사전
- 배열 내 배열: 예: 부서 내 제품 목록
- 일관성 없는 키: 일부 객체에는 추가 필드 또는 누락된 필드가 있음
예를 들어, 상점의 재고에 대한 다음 구조를 고려하십시오:
{
"store": {
"departments": [
{
"name": "Computers",
"products": [{"id": 1, "name": "Laptop", "specs": {"CPU": "i7"}}]
},
{
"name": "Accessories",
"products": [{"id": 101, "name": "Mouse", "colors": ["Black", "White"]}]
}
]
}
}
중첩된 필드를 열로 변환해야 하고 배열을 확장하거나 문자열로 결합해야 할 수 있으므로 이를 테이블로 평탄화하는 것은 간단하지 않습니다. 저희 솔루션은 대부분의 JSON 구조에 대한 강력한 처리를 제공하는 동시에 매우 복잡한 경우를 위한 수동 추출 옵션을 제공합니다.
JSON 구문 및 구조에 대한 빠른 복습은 다음을 참조하십시오: JSON 소개
1단계 — JSON 데이터 로드
처리하기 전에 JSON 파일을 Python으로 로드하십시오. 내장된 json 모듈을 사용하면 콘텐츠가 기본 Python 사전 및 목록으로 구문 분석됩니다:
import json
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
이 단계의 역할:
- 디스크에서 JSON 파일 읽기
- 추가 처리를 위해 Python 객체(dict 및 list)로 변환
팁: 비 ASCII 문자와의 문제를 피하려면 항상 encoding="utf-8"을 지정하십시오.
2단계 — 내보낼 데이터 세트 자동 감지
많은 JSON 파일에는 여러 개의 중첩된 목록이 포함되어 있습니다. 종종 "기본 테이블"을 나타내는 객체 목록이 필요합니다. 이는 일반적으로 가장 큰 사전 목록입니다. 다음 함수는 가장 테이블과 유사한 데이터 세트를 자동으로 검색합니다:
def find_dataset(obj):
"""Recursively search JSON and return the most table-like dataset."""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No suitable dataset found.")
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# Usage
dataset = find_dataset(data)
작동 방식:
- JSON 구조를 재귀적으로 순회
- 키 수 × 항목 수를 기준으로 후보 목록 점수 매기기
- 가장 풍부한 데이터 세트를 기본 테이블로 선택
제한 사항:
- 깊이 중첩된 목록(예: 여러 부서의 제품)을 자동으로 병합하지 않음
- 일부 필드는 전체 가시성을 위해 수동 추출이 필요할 수 있음
선택 사항 — 수동 데이터 세트 추출
깊이 중첩되거나 사용자 정의된 데이터 세트의 경우 데이터를 수동으로 추출하십시오:
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
이 접근 방식은 각 제품에 대한 부서와 같은 컨텍스트를 추가하는 것을 포함하여 필요한 정확한 필드를 캡처하도록 보장합니다.
3단계 — JSON 평탄화 및 정규화
JSON을 테이블로 변환하려면 중첩된 구조를 평탄화해야 합니다:
def flatten_json(obj, parent_key="", sep="_"):
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
if not value:
items[new_key] = ""
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
def normalize_json(data):
flattened_rows = [flatten_json(item) for item in data]
all_keys_ordered, seen_keys = [], set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
rows, headers = normalize_json(dataset)
이 단계의 역할:
- 중첩된 사전을 specs_CPU, specs_RAM과 같은 열 이름으로 변환
- 기본 형식 목록을 쉼표로 구분된 문자열로 변환
- 처음 본 키를 첫 번째 열로 유지
4단계 — Excel을 통해 PDF로 내보내기
데이터가 평탄화되면 Spire.XLS for Python을 사용하여 PDF로 내보냅니다. PDF를 직접 렌더링하는 대신 Excel을 중간 레이아웃 레이어로 사용합니다. 이 접근 방식은 PDF로 내보내기 전에 테이블 구조, 서식, 여백 및 크기 조정을 완벽하게 제어할 수 있도록 합니다.
종속성 설치:
pip install spire.xls
Spire.XLS를 사용하여 JSON을 PDF로 내보내기:
from spire.xls import Workbook
import os
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write data rows
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatting
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF saved: {output_path}")
PDF 서식 지정 팁:
- 내용에 맞게 열 자동 맞춤
- 가독성을 위해 여백 설정
- 더 나은 테이블 시각화를 위해 눈금선 활성화
관심 있을 만한 다른 글: Python에서 Excel을 PDF로 변환
5단계 — 예: 복잡한 JSON 파일에서 제품 내보내기
이전 단계를 결합합니다:
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1: Automatic detection
dataset = find_dataset(data)
rows, headers = normalize_json(dataset)
# Option 2: Manual extraction for nested structure
# dataset = []
# for dept in data["store"]["departments"]:
# for prod in dept["products"]:
# prod["department"] = dept["name"]
# dataset.append(prod)
# rows, headers = normalize_json(dataset)
export_to_pdf(rows, headers, "output/Products.pdf")
핵심 사항:
- 자동 감지는 대부분의 JSON 배열에서 작동합니다
- 수동 추출은 중첩되고 계층적인 데이터 세트에 대한 제어를 보장합니다
출력:
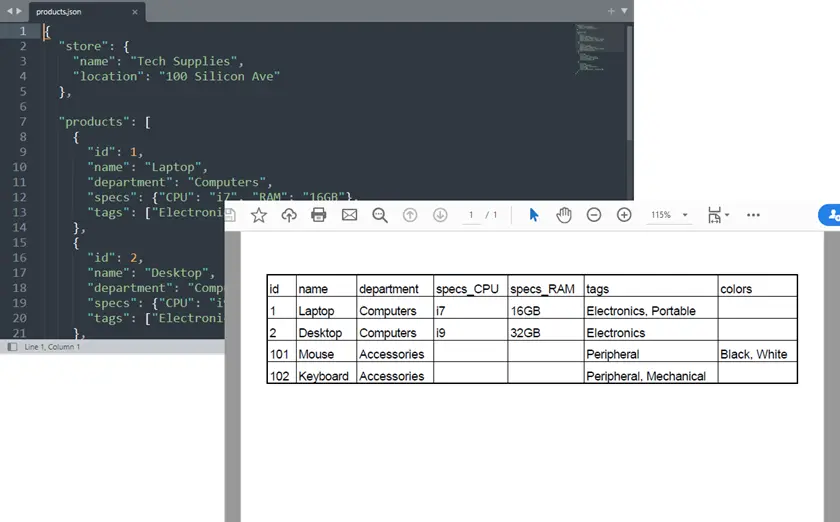
전체 Python 예제: JSON을 PDF로
from spire.xls import Workbook
import json
import os
# ---------------------------
# Atoumatically Detect dataset
# ---------------------------
def find_dataset(obj):
"""
Recursively search JSON and return the most table-like dataset.
Strategy:
- Find lists containing dictionaries
- Score datasets based on number of fields
- Choose the dataset with the richest structure
"""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
# Count unique keys across objects
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No suitable dataset found.")
# choose best scored dataset
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# ---------------------------
# Robust Recursive JSON Flattener
# ---------------------------
def flatten_json(obj, parent_key="", sep="_"):
"""
Recursively flattens nested dictionaries and lists.
Rules:
- Nested dict → key_subkey
- List of primitives → comma-separated string
- List of dicts → indexed columns (key_0_name, key_1_name)
- Mixed lists / arrays-of-arrays → recursively indexed (key_0_0, key_0_1)
"""
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
# Empty list
if not value:
items[new_key] = ""
# List of primitives
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
# Mixed or nested lists
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
# Top-level lists
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
# ---------------------------
# Normalize JSON Data (First-Seen Column Order)
# ---------------------------
def normalize_json(data):
"""
Flatten JSON objects and align headers, preserving the first-seen order.
The first key in the first JSON object will be the first column.
"""
if not isinstance(data, list):
raise ValueError("Data must be a list of objects.")
flattened_rows = [flatten_json(item) for item in data]
# Track headers in first-seen order
all_keys_ordered = []
seen_keys = set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
# Align all rows to include all keys
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
# ---------------------------
# Export to PDF via Excel
# ---------------------------
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write header
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write data rows
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatting
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF saved: {output_path}")
# ===========================
# Example: Complex JSON Dataset
# ===========================
# Load JSON from file
with open(r"C:\Users\Administrator\Desktop\Products.json", "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1. Automatically detect dataset (work for most cases)
dataset = find_dataset(data)
'''
# Option 2. Manually extract dataset (work for complex unusual structures)
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
'''
# Normalize (first-seen key becomes first column)
rows, headers = normalize_json(dataset)
# Export to PDF
export_to_pdf(rows, headers, "output/Products.pdf")
결론
JSON을 PDF 테이블로 변환하는 것은 특히 중첩된 구조나 일관성 없는 키가 있는 경우 까다로울 수 있습니다. Python과 Spire.XLS를 사용하면 JSON을 자동으로 평탄화하고 논리적인 열 순서를 유지하여 복잡한 데이터 세트를 보고서나 문서에 적합한 깨끗하고 읽기 쉬운 테이블로 바꿀 수 있습니다.
자동 데이터 세트 감지는 대부분의 JSON 파일을 처리하는 반면, 수동 추출은 필요할 때 특정 중첩 데이터를 캡처할 수 있도록 합니다. 이 접근 방식은 구조나 컨텍스트를 잃지 않고 JSON을 전문적인 PDF 테이블로 변환하는 유연하고 신뢰할 수 있는 방법을 제공합니다.
자주 묻는 질문
이것으로 모든 JSON 파일을 처리할 수 있습니까?
자동 감지는 대부분의 경우에 작동하지만, 깊이 중첩된 데이터의 경우 수동 추출이 필요할 수 있습니다.
열 순서는 어떻게 결정됩니까?
열은 JSON 객체에서 처음 나타나는 순서대로 표시됩니다.
여러 데이터 세트를 병합할 수 있습니까?
예, 평탄화하기 전에 데이터 세트를 연결할 수 있습니다.
누락된 필드는 어떻게 처리합니까?
누락된 값은 자동으로 빈 셀로 표시됩니다.
PDF 레이아웃을 사용자 정의할 수 있습니까?
예, 여백, 눈금선 및 자동 맞춤 옵션은 Spire.XLS를 통해 완전히 구성할 수 있습니다.