
As aplicações modernas dependem muito de APIs que retornam dados JSON estruturados. Embora esses dados sejam ideais para sistemas de software, as partes interessadas e as equipes de negócios geralmente precisam de informações apresentadas em um formato legível e compartilhável — e os relatórios em PDF continuam sendo um dos padrões mais amplamente aceitos para documentação, auditoria e distribuição.
Em vez de converter manualmente arquivos JSON usando ferramentas online, os desenvolvedores podem automatizar todo o fluxo de trabalho — desde a recuperação de dados da API ao vivo até a geração de relatórios em PDF estruturados.
Neste tutorial, você aprenderá a construir um pipeline de automação de ponta a ponta usando Python:
- Recuperar dados JSON de uma API
- Analisar e estruturar a resposta
- Carregar os dados em uma planilha do Excel
- Exportar a planilha como um relatório em PDF bem formatado
Essa abordagem é ideal para relatórios agendados, painéis de SaaS, exportações de análises e sistemas de automação de backend.
Por que os conversores online de JSON para PDF não são suficientes
Os conversores online podem ser úteis para tarefas rápidas e únicas. No entanto, eles geralmente deixam a desejar ao trabalhar com APIs ao vivo ou fluxos de trabalho automatizados.
As limitações comuns incluem:
- Nenhuma capacidade de extrair dados diretamente de APIs
- Falta de automação ou suporte a agendamento
- Controle limitado de formatação e layout de relatório
- Dificuldade em lidar com estruturas JSON aninhadas
- Preocupações com a privacidade ao carregar dados confidenciais
- Nenhuma integração com pipelines de backend ou sistemas de CI/CD
Para desenvolvedores que criam sistemas de relatórios automatizados, um fluxo de trabalho programático oferece muito mais flexibilidade, escalabilidade e controle. Usando Python e Spire.XLS, você pode gerar relatórios estruturados diretamente das respostas da API sem intervenção manual.
Pré-requisitos e visão geral da arquitetura: Pipeline de JSON API → Excel → PDF
Antes de construir o fluxo de trabalho de automação, certifique-se de que seu ambiente esteja preparado:
pip install spire.xls requests
Por que usar o Excel como uma camada intermediária?
Em vez de converter JSON diretamente para PDF, este tutorial usa o Excel como uma camada de relatório estruturada. Essa abordagem oferece várias vantagens:
- Converte JSON não estruturado em layouts tabulares limpos
- Permite fácil formatação e controle de colunas
- Garante uma saída de PDF consistente
- Suporta melhorias futuras, como gráficos e resumos
Arquitetura do Pipeline
O processo de automação segue um pipeline de transformação estruturado:
- Camada de API: recupera dados JSON ao vivo de serviços de backend
- Camada de processamento de dados: normaliza e achata estruturas JSON
- Camada de layout de relatório (Excel): organiza os dados em tabelas legíveis
- Camada de exportação (PDF): gera um relatório final compartilhável
Essa abordagem em camadas melhora a escalabilidade e mantém a lógica de relatório flexível para cenários de automação futuros.
Etapa 1 — Recuperar dados JSON de uma API
A maioria dos fluxos de trabalho de relatórios automatizados começa com a coleta de dados ao vivo de uma API. Em vez de exportar arquivos manualmente, seu script extrai diretamente os registros mais recentes de serviços de backend, plataformas de análise ou aplicativos SaaS. Isso garante:
- Os relatórios sempre contêm dados atualizados
- Nenhuma etapa manual de download ou conversão
- Fácil integração em pipelines de automação agendados
Abaixo está um exemplo mostrando como recuperar dados JSON usando Python:
import requests
# Example API endpoint
url = "https://api.example.com/employees"
headers = {
"Authorization": "Bearer YOUR_API_TOKEN"
}
response = requests.get(url, headers=headers, timeout=30)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
api_data = response.json()
print("Registros recuperados:", len(api_data))
Práticas principais:
- Sempre valide o código de status HTTP
- Inclua cabeçalhos de autenticação quando necessário
- Lide com limites de taxa e limitação de API
- Prepare-se para paginação quando os conjuntos de dados forem grandes
Os exemplos neste tutorial usam a popular biblioteca Python requests para lidar com a comunicação HTTP; consulte a documentação oficial do Requests para padrões avançados de autenticação e gerenciamento de sessão.
Etapa 2 — Analisar e estruturar a resposta JSON
Nem todos os arquivos JSON compartilham a mesma estrutura. Algumas APIs retornam uma lista simples de registros, enquanto outras envolvem dados dentro de objetos ou incluem matrizes aninhadas e subcampos. Escrever JSON complexo diretamente no Excel geralmente leva a erros ou relatórios ilegíveis.
Entenda as diferentes estruturas JSON
| Tipo de JSON | Estrutura de exemplo | Exportação direta para o Excel |
|---|---|---|
| Lista Simples | [ {…}, {…} ] | Funciona diretamente |
| Lista Envolvida | { "employees": [ {…} ] } | ⚠ Extraia a lista primeiro |
| Objetos Aninhados | { "address": { "city": "NY" } } | ⚠ Achatar campos |
| Matrizes Aninhadas | { "skills": ["Python", "SQL"] } | ⚠ Converter para string |
Uma estrutura normalizada deve se parecer com:
[
{"id":1,"name":"Alice","city":"NY","skills":"Python, SQL"}
]
Este formato pode ser escrito diretamente nas linhas do Excel. Se você não estiver familiarizado com a forma como objetos e matrizes aninhados são estruturados, revisar a especificação oficial do formato de dados JSON pode ajudar a esclarecer como as respostas complexas da API são organizadas.
Normalize o JSON antes de gerar relatórios
Em vez de modificar manualmente o JSON para cada API, você pode automaticamente:
- Detectar listas envolvidas
- Achatar objetos aninhados
- Converter matrizes em strings legíveis
- Padronizar dados para relatórios
Abaixo está um auxiliar de normalização reutilizável:
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
Observação: estruturas JSON de vários níveis profundamente aninhadas podem exigir achatamento recursivo adicional, dependendo da complexidade da API.
Exemplo de uso:
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
structured_data = normalize_json(raw_data)
Isso garante que o conjunto de dados seja seguro para exportação para o Excel, independentemente da complexidade do JSON.
Etapa 3 — Carregar dados JSON estruturados em uma planilha do Excel
O Excel atua como uma camada de relatório estruturada após a normalização do JSON. Uma vez que as estruturas JSON complexas tenham sido achatadas em uma lista simples de dicionários, os dados podem ser escritos diretamente em linhas e colunas para formatação adicional e exportação para PDF.
Usando o Spire.XLS para Python, os desenvolvedores podem construir, modificar e formatar relatórios do Excel inteiramente por meio de código — sem exigir o Microsoft Excel — facilitando a integração de operações avançadas de planilha em fluxos de trabalho de relatórios automatizados.
Criar pasta de trabalho e planilha
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
Como funciona:
- Inicializa um novo arquivo do Excel na memória.
- Acessa a primeira planilha.
- Prepara uma tela para escrever dados estruturados.
Escrever cabeçalhos e linhas de dados
headers = list(structured_data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
for row_idx, row in enumerate(structured_data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = str(row.get(key, ""))
Como funciona:
- Extrai cabeçalhos de coluna de dados estruturados.
- Escreve a linha de cabeçalho primeiro.
- Itera através dos registros e preenche as linhas sequencialmente.
- Converte valores em strings para garantir uma saída consistente.
Preparar formatação antes da exportação
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
Como a planilha já define o layout e a formatação, a exportação para PDF preserva a estrutura visual sem lógica de renderização adicional.
Etapa 4 — Exportar a planilha como um relatório em PDF
Uma vez que os dados são estruturados e formatados no Excel, a exportação para PDF cria um relatório portátil e profissional adequado para:
- Distribuição para as partes interessadas
- Documentação de conformidade
- Pipelines de relatórios automatizados
- Armazenamento de arquivamento
Salvar planilha do Excel como relatório em PDF
sheet.SaveToPdf("output.pdf")
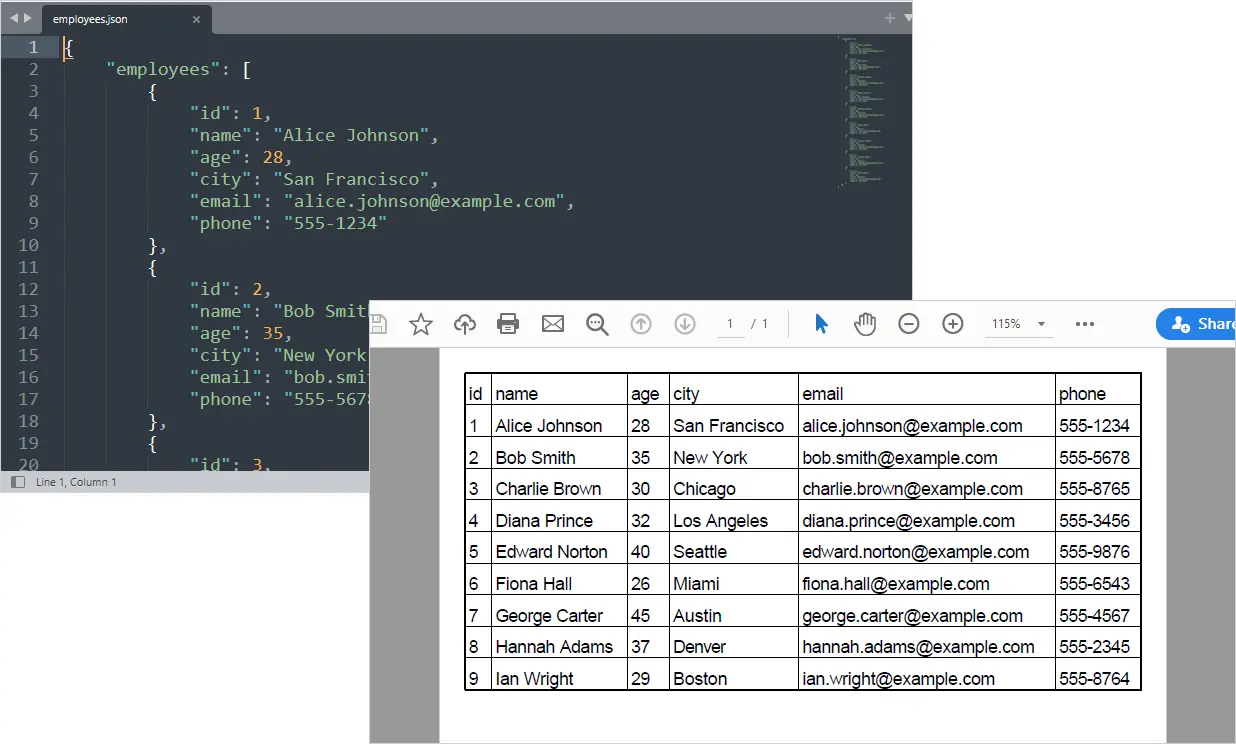
Seu relatório em PDF estruturado agora é gerado a partir de dados da API automaticamente.
Saída:
Você também pode gostar: Converter Excel para PDF em Python
Script completo — Do JSON da API para um relatório em PDF estruturado
from spire.xls import *
from spire.xls.common import *
import json
import requests
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
# =========================
# Step 1: Get JSON from API
# =========================
api_url = "https://api.example.com/employees"
response = requests.get(api_url)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
raw_data = response.json()
# =========================
# Step 2: Normalize JSON
# =========================
data = normalize_json(raw_data)
# =========================
# Step 3: Create Workbook
# =========================
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
headers = list(data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write rows
for row_idx, row in enumerate(data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row.get(key, "")
# =========================
# Step 4: Format worksheet
# =========================
# Set conversion settings to adjust sheet layout
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True # Retain paper size during conversion
workbook.ConverterSetting.SheetFitToWidth = True # Fit sheet to width during conversion
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# =========================
# Step 5: Export to PDF
# =========================
sheet.SaveToPdf("output.pdf")
workbook.Dispose()
Se sua fonte de dados for um arquivo JSON local em vez de uma API ao vivo, você pode carregar os dados diretamente do disco antes de gerar o relatório em PDF.
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
Casos de uso práticos
Este fluxo de trabalho de automação pode ser aplicado em uma ampla gama de cenários de relatórios orientados por dados:
- Pipelines de relatórios de API automatizados — Gere relatórios em PDF diários ou semanais de serviços de backend sem exportações manuais.
- Resumos de uso e atividade de SaaS — Converta APIs de análise de aplicativos em relatórios estruturados de clientes ou internos.
- Exportações de relatórios financeiros e de RH — Transforme dados de API estruturados em documentos PDF padronizados para distribuição interna.
- Instantâneos de painel de análise — Capture métricas orientadas por API e converta-as em relatórios executivos compartilháveis.
- Relatórios de inteligência de negócios agendados — Crie automaticamente resumos em PDF a partir de APIs de data warehouse ou de análise.
- Documentação de conformidade e auditoria — Produza registros em PDF consistentes e com carimbo de data/hora a partir de conjuntos de dados de API estruturados.
Considerações finais
A automação da geração de relatórios em PDF a partir de respostas da API JSON permite que os desenvolvedores criem pipelines de relatórios escaláveis que eliminam o processamento manual. Ao combinar os recursos de API do Python com os recursos de exportação para Excel e PDF do Spire.XLS para Python, você pode criar relatórios estruturados e profissionais diretamente de fontes de dados ao vivo.
Esteja você gerando relatórios de negócios semanais, painéis internos ou entregas para clientes, este fluxo de trabalho oferece flexibilidade, automação e controle total sobre o processo de geração de relatórios.
JSON para PDF: perguntas frequentes
Posso converter JSON diretamente para PDF sem o Excel?
Sim, mas usar o Excel como uma camada intermediária facilita a estruturação de tabelas, o controle de layouts e a geração de uma formatação de relatório consistente e profissional.
Como lido com respostas de API grandes ou paginadas?
Itere pelas páginas ou tokens fornecidos pela API e mescle todos os resultados em um único conjunto de dados antes de gerar o relatório em PDF.
Este fluxo de trabalho pode ser executado automaticamente em um cronograma?
Sim. Você pode automatizar o script usando cron jobs, Agendador de Tarefas do Windows, pipelines de CI/CD ou serviços de backend para gerar relatórios regularmente.
Como personalizo o layout do relatório em PDF?
Formate a planilha do Excel antes de exportar — ajuste a largura das colunas, aplique estilos, congele cabeçalhos ou adicione gráficos. Essas configurações serão preservadas no PDF.
E se a API retornar campos ausentes ou inconsistentes?
Use métodos de extração seguros como .get() com valores padrão ao analisar JSON para evitar erros e manter estruturas de tabela consistentes.