
Em aplicações modernas, JSON é um dos formatos de dados mais comuns para APIs, arquivos de configuração e troca de dados. No entanto, embora o JSON seja ideal para máquinas, nem sempre é legível por humanos. Exportar JSON para uma tabela PDF pode ajudar a apresentar informações estruturadas de forma clara em relatórios, painéis ou documentação interna.
Neste tutorial, você aprenderá como converter JSON para uma tabela PDF bem formatada usando Python e Spire.XLS, incluindo:
- Detectar automaticamente conjuntos de dados para exportação de tabelas
- Achatar campos JSON aninhados
- Gerar PDFs com aparência profissional
Também abordaremos a extração manual de conjuntos de dados para estruturas profundamente aninhadas, dando a você controle total sobre arquivos JSON complexos.
Por que converter JSON para PDF nem sempre é simples
O JSON vem em todas as formas e tamanhos:
- Matrizes planas: fáceis de converter diretamente em linhas
- Objetos aninhados: por exemplo, um dicionário de especificações dentro de cada produto
- Matrizes dentro de matrizes: por exemplo, uma lista de produtos dentro de um departamento
- Chaves inconsistentes: alguns objetos têm campos adicionais ou ausentes
Por exemplo, considere esta estrutura para o inventário de uma loja:
{
"store": {
"departments": [
{
"name": "Computers",
"products": [{"id": 1, "name": "Laptop", "specs": {"CPU": "i7"}}]
},
{
"name": "Accessories",
"products": [{"id": 101, "name": "Mouse", "colors": ["Black", "White"]}]
}
]
}
}
Achatar isso em uma tabela não é trivial, porque campos aninhados precisam ser convertidos em colunas, e matrizes podem precisar ser expandidas ou unidas em strings. Nossa solução oferece um tratamento robusto para a maioria das estruturas JSON, ao mesmo tempo que oferece uma opção para extração manual em casos excepcionalmente complexos.
Para uma rápida atualização sobre a sintaxe e estrutura do JSON, consulte: Introdução ao JSON
Passo 1 — Carregar dados JSON
Antes de processar, carregue seu arquivo JSON no Python. Usar o módulo json integrado garante que o conteúdo seja analisado em dicionários e listas nativos do Python:
import json
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
O que este passo faz:
- Lê um arquivo JSON do disco
- Converte-o em objetos Python (dict e list) para processamento posterior
Dica: Sempre especifique encoding="utf-8" para evitar problemas com caracteres não-ASCII.
Passo 2 — Detectar automaticamente o conjunto de dados a ser exportado
Muitos arquivos JSON contêm várias listas aninhadas. Frequentemente, precisamos da lista de objetos que representa a “tabela principal” — geralmente a maior lista de dicionários. A função a seguir procura automaticamente o conjunto de dados mais semelhante a uma tabela:
def find_dataset(obj):
"""Recursively search JSON and return the most table-like dataset."""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No suitable dataset found.")
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# Usage
dataset = find_dataset(data)
Como funciona:
- Percorre recursivamente a estrutura JSON
- Pontua listas candidatas com base no número de chaves × número de itens
- Escolhe o conjunto de dados mais rico como a tabela principal
Limitações:
- Não mesclará automaticamente listas profundamente aninhadas (por exemplo, produtos de vários departamentos)
- Alguns campos podem exigir extração manual para visibilidade total
Opcional — Extração manual de conjunto de dados
Para conjuntos de dados profundamente aninhados ou personalizados, extraia os dados manualmente:
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
Essa abordagem garante que você capture exatamente os campos de que precisa, incluindo a adição de contexto, como o departamento de cada produto.
Passo 3 — Achatar e normalizar o JSON
Para converter JSON em uma tabela, as estruturas aninhadas devem ser achatadas:
def flatten_json(obj, parent_key="", sep="_"):
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
if not value:
items[new_key] = ""
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
def normalize_json(data):
flattened_rows = [flatten_json(item) for item in data]
all_keys_ordered, seen_keys = [], set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
rows, headers = normalize_json(dataset)
O que este passo faz:
- Converte dicionários aninhados em nomes de colunas como specs_CPU, specs_RAM
- Converte listas de primitivos em strings separadas por vírgulas
- Preserva a primeira chave vista como a primeira coluna
Passo 4 — Exportar para PDF via Excel
Depois que os dados são achatados, exporte-os como um PDF usando Spire.XLS para Python. Em vez de renderizar o PDF diretamente, usamos o Excel como uma camada de layout intermediária. Essa abordagem oferece controle total sobre a estrutura da tabela, formatação, margens e dimensionamento antes de exportar para PDF.
Instalar dependência:
pip install spire.xls
Exportar JSON para PDF usando Spire.XLS:
from spire.xls import Workbook
import os
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write data rows
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatting
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF saved: {output_path}")
Dicas para formatação de PDF:
- Ajustar colunas automaticamente ao conteúdo
- Definir margens para legibilidade
- Habilitar linhas de grade para melhor visualização da tabela
Você também pode gostar: Converter Excel para PDF em Python
Passo 5 — Exemplo: Exportar produtos de um arquivo JSON complexo
Combine os passos anteriores:
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1: Automatic detection
dataset = find_dataset(data)
rows, headers = normalize_json(dataset)
# Option 2: Manual extraction for nested structure
# dataset = []
# for dept in data["store"]["departments"]:
# for prod in dept["products"]:
# prod["department"] = dept["name"]
# dataset.append(prod)
# rows, headers = normalize_json(dataset)
export_to_pdf(rows, headers, "output/Products.pdf")
Pontos chave:
- A detecção automática funciona para a maioria das matrizes JSON
- A extração manual garante controle sobre conjuntos de dados aninhados e hierárquicos
Saída:
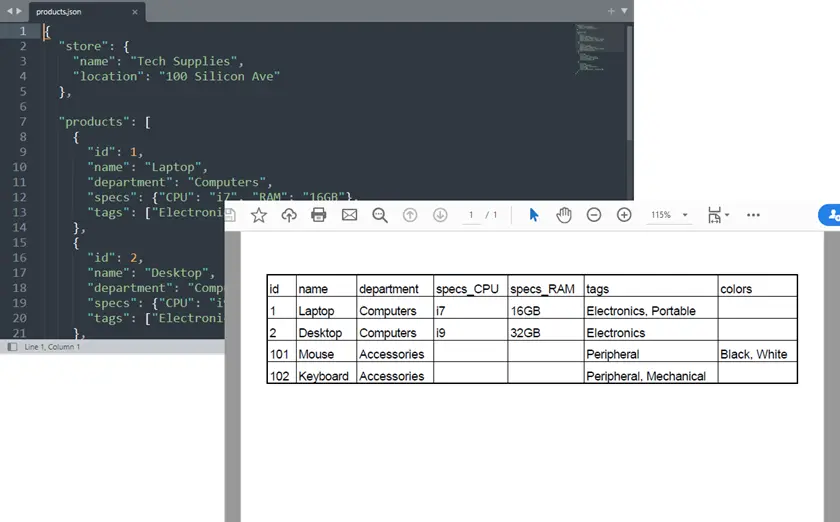
Exemplo completo em Python: JSON para PDF
from spire.xls import Workbook
import json
import os
# ---------------------------
# Atoumatically Detect dataset
# ---------------------------
def find_dataset(obj):
"""
Recursively search JSON and return the most table-like dataset.
Strategy:
- Find lists containing dictionaries
- Score datasets based on number of fields
- Choose the dataset with the richest structure
"""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
# Count unique keys across objects
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No suitable dataset found.")
# choose best scored dataset
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# ---------------------------
# Robust Recursive JSON Flattener
# ---------------------------
def flatten_json(obj, parent_key="", sep="_"):
"""
Recursively flattens nested dictionaries and lists.
Rules:
- Nested dict → key_subkey
- List of primitives → comma-separated string
- List of dicts → indexed columns (key_0_name, key_1_name)
- Mixed lists / arrays-of-arrays → recursively indexed (key_0_0, key_0_1)
"""
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
# Empty list
if not value:
items[new_key] = ""
# List of primitives
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
# Mixed or nested lists
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
# Top-level lists
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
# ---------------------------
# Normalize JSON Data (First-Seen Column Order)
# ---------------------------
def normalize_json(data):
"""
Flatten JSON objects and align headers, preserving the first-seen order.
The first key in the first JSON object will be the first column.
"""
if not isinstance(data, list):
raise ValueError("Data must be a list of objects.")
flattened_rows = [flatten_json(item) for item in data]
# Track headers in first-seen order
all_keys_ordered = []
seen_keys = set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
# Align all rows to include all keys
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
# ---------------------------
# Export to PDF via Excel
# ---------------------------
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write header
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write data rows
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatting
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF saved: {output_path}")
# ===========================
# Example: Complex JSON Dataset
# ===========================
# Load JSON from file
with open(r"C:\Users\Administrator\Desktop\Products.json", "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1. Automatically detect dataset (work for most cases)
dataset = find_dataset(data)
'''
# Option 2. Manually extract dataset (work for complex unusual structures)
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
'''
# Normalize (first-seen key becomes first column)
rows, headers = normalize_json(dataset)
# Export to PDF
export_to_pdf(rows, headers, "output/Products.pdf")
Conclusão
Converter JSON para uma tabela PDF pode ser complicado, especialmente com estruturas aninhadas ou chaves inconsistentes. Usando Python e Spire.XLS, você pode achatar automaticamente o JSON e preservar uma ordem lógica de colunas, transformando conjuntos de dados complexos em tabelas limpas e legíveis, adequadas para relatórios ou documentação.
A detecção automática de conjuntos de dados lida com a maioria dos arquivos JSON, enquanto a extração manual permite capturar dados aninhados específicos quando necessário. Essa abordagem oferece uma maneira flexível e confiável de converter JSON em tabelas PDF profissionais sem perder estrutura ou contexto.
Perguntas frequentes
Isso pode lidar com qualquer arquivo JSON?
A detecção automática funciona para a maioria, mas a extração manual pode ser necessária para dados profundamente aninhados.
Como a ordem das colunas é determinada?
As colunas aparecem na ordem da primeira aparição nos objetos JSON.
Vários conjuntos de dados podem ser mesclados?
Sim, você pode concatenar conjuntos de dados antes de achatar.
Como lidar com campos ausentes?
Valores ausentes são representados automaticamente como células vazias.
Posso personalizar o layout do PDF?
Sim, margens, linhas de grade e opções de ajuste automático são totalmente configuráveis via Spire.XLS.