
При работе с PDF-файлами на Java часто необходимо преобразовывать двоичные данные в текстовые форматы. Кодирование Base64 позволяет представлять содержимое PDF в виде простого текста, что полезно при передаче документов в JSON, отправке через формы или хранении в текстовых системах. Стандартная библиотека Java предоставляет java.util.Base64, что упрощает реализацию преобразований как из Base64 в PDF, так и из PDF в Base64 без дополнительных зависимостей.
В этом руководстве мы рассмотрим, как выполнять эти преобразования, используя только JDK, а также как работать с изображениями в формате Base64 и встраивать их в PDF. Для более сложных операций, таких как редактирование PDF, полученного в виде Base64, и экспорт его обратно, мы продемонстрируем использование Free Spire.PDF for Java.
Оглавление
- Преобразование Base64 в PDF на Java (только JDK)
- Преобразование PDF в Base64 на Java (только JDK)
- Советы по проверке и безопасности
- Сохранение изображений Base64 в формате PDF на Java
- Загрузка PDF в Base64, изменение и сохранение обратно в Base64
- Вопросы производительности и памяти
- Часто задаваемые вопросы
Преобразование Base64 в PDF на Java (только JDK)
Самый простой подход — прочитать строку Base64 в память, удалить необязательные префиксы (например, data:application/pdf;base64,), а затем декодировать ее в PDF. Это хорошо работает для файлов малого и среднего размера.
import java.nio.file.*;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
public class Base64ToPdf {
public static void main(String[] args) throws Exception {
// Чтение текста Base64 из файла (или любого другого источника)
String base64 = Files.readString(Paths.get("sample.pdf.b64"), StandardCharsets.UTF_8);
// Удаление общих префиксов Data URI, если они есть
base64 = stripDataPrefix(base64);
// Декодирование Base64 в необработанные байты PDF
// MIME-декодер допускает разрывы строк и перенос текста
byte[] pdfBytes = Base64.getMimeDecoder().decode(base64);
// Запись декодированных байтов в файл PDF
Files.write(Paths.get("output.pdf"), pdfBytes);
}
/** Утилита для удаления "data:application/pdf;base64,", если он включен */
private static String stripDataPrefix(String src) {
String s = src.trim();
int comma = s.indexOf(',');
if (comma > 0 && s.substring(0, comma).toLowerCase().contains("base64")) {
return s.substring(comma + 1).trim();
}
return s;
}
}
Объяснение Этот пример прост и надежен для содержимого Base64, которое удобно помещается в памяти. Base64.getMimeDecoder() выбран потому, что он корректно обрабатывает разрывы строк, которые часто встречаются в тексте Base64, экспортированном из почтовых систем или API. Если вы знаете, что ваша строка Base64 не содержит новых строк, вы также можете использовать Base64.getDecoder().
Перед декодированием обязательно удалите любой префикс Data URI (data:application/pdf;base64,), так как он не является частью полезной нагрузки Base64. Вспомогательный метод stripDataPrefix() делает это автоматически.
Потоковый вариант (без полной строки в памяти)
Для больших PDF-файлов лучше обрабатывать Base64 в потоковом режиме. Это позволяет избежать загрузки всей строки Base64 в память за один раз.
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class Base64ToPdfStreamed {
public static void main(String[] args) throws Exception {
// Вход: текстовый файл, содержащий PDF в кодировке Base64
Path in = Paths.get("sample.pdf.b64");
// Выход: декодированный PDF-файл
Path out = Paths.get("output.pdf");
// Обернуть декодер Base64 вокруг входного потока
try (InputStream b64In = Base64.getMimeDecoder().wrap(Files.newInputStream(in));
OutputStream pdfOut = Files.newOutputStream(out)) {
// Потоковая передача декодированных байтов непосредственно в выходной файл PDF
b64In.transferTo(pdfOut);
}
}
}
Объяснение Этот потоковый подход более эффективен с точки зрения использования памяти, так как он декодирует данные на лету, а не буферизует всю строку. Это рекомендуемый метод для больших файлов или непрерывных потоков (например, сетевых сокетов).
- Base64.getMimeDecoder() используется для обработки разрывов строк во входных данных.
- Метод transferTo() эффективно копирует декодированные байты из входа в выход без ручной обработки буфера.
- В реальных условиях рекомендуется добавить обработку исключений для управления ошибками доступа к файлам или частичной записи.
Преобразование PDF в Base64 на Java (только JDK)
Кодирование PDF в Base64 так же просто. Для небольших файлов достаточно прочитать весь PDF в память:
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64 {
public static void main(String[] args) throws Exception {
// Чтение PDF-файла в массив байтов
byte[] pdfBytes = Files.readAllBytes(Paths.get("input.pdf"));
// Кодирование байтов PDF в строку Base64
String base64 = Base64.getEncoder().encodeToString(pdfBytes);
// Запись строки Base64 в текстовый файл
Files.writeString(Paths.get("output.pdf.b64"), base64);
}
}
Объяснение Этот подход прост и хорошо работает для файлов малого и среднего размера. Весь PDF считывается в массив байтов и кодируется в одну строку Base64. Эту строку можно хранить, передавать в JSON или встраивать в Data URI.
Потоковый кодировщик (эффективно обрабатывает большие файлы)
Для больших PDF-файлов можно избежать излишней нагрузки на память, кодируя непосредственно в виде потока:
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64Streamed {
public static void main(String[] args) throws Exception {
// Вход: двоичный PDF-файл
try (InputStream pdfIn = Files.newInputStream(Paths.get("input.pdf"));
// Необработанный выходной поток для текстового файла Base64
OutputStream rawOut = Files.newOutputStream(Paths.get("output.pdf.b64"));
// Обернуть выходной поток кодировщиком Base64
OutputStream b64Out = Base64.getEncoder().wrap(rawOut)) {
// Потоковая передача байтов PDF непосредственно в закодированный вывод Base64
pdfIn.transferTo(b64Out);
}
}
}
Объяснение Потоковый кодировщик эффективно обрабатывает большие файлы, кодируя данные по частям, а не загружая все в память. Метод Base64.getEncoder().wrap() превращает обычный выходной поток в поток, который автоматически записывает текст в формате Base64.
Такая конструкция лучше масштабируется для больших PDF-файлов, сетевых потоков или сервисов, которые должны обрабатывать много документов одновременно, не испытывая проблем с памятью.
Советы по проверке и безопасности
- Обнаружение Data URI: пользователи могут отправлять префиксы data:application/pdf;base64,. Удаляйте их перед декодированием.
- Разрывы строк: при декодировании текста, который может содержать перенесенные строки (электронные письма, журналы), используйте Base64.getMimeDecoder().
- Быстрая проверка на вшивость: после декодирования первые байты действительного PDF обычно начинаются с %PDF-. Вы можете проверить это для раннего обнаружения сбоев.
- Кодировка символов: рассматривайте текст Base64 как UTF-8 (или US-ASCII) при чтении/записи файлов .b64.
- Обработка ошибок: оберните декодирование/кодирование в блоки try/catch и выводите информативные сообщения (например, о размере, несоответствии заголовка).
Сохранение изображений Base64 в формате PDF на Java
Иногда вы получаете изображения (например, PNG или JPEG) в виде строк Base64 и вам нужно встроить их в PDF. Хотя стандартная библиотека Java не имеет API для работы с PDF, Free Spire.PDF for Java делает это простым.
Вы можете скачать Free Spire.PDF for Java и добавить его в свой проект или установить Free Spire.PDF for Java из репозитория Maven.
Ключевые концепции Spire.PDF
- PdfDocument — контейнер для одной или нескольких страниц PDF.
- PdfPageBase — представляет страницу, на которой можно рисовать.
- PdfImage.fromImage() — загрузка BufferedImage или потока в рисуемое изображение PDF.
- drawImage() — размещение изображения в указанных координатах и с указанным размером.
- Система координат — Spire.PDF использует систему координат, где (0,0) — это верхний левый угол.
Пример: Преобразование изображения Base64 в PDF с помощью Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImage;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.*;
import java.util.Base64;
public class Base64ImageToPdf {
public static void main(String[] args) throws Exception {
// 1) Прочитать файл Base64 и декодировать (удалить префикс data URI, если есть)
String base64Image = Files.readString(Paths.get("G:/Document/image.b64"), StandardCharsets.UTF_8).trim();
int comma = base64Image.indexOf(',');
if (comma > 0 && base64Image.substring(0, comma).toLowerCase().contains("base64")) {
base64Image = base64Image.substring(comma + 1).trim();
}
byte[] imageBytes = Base64.getMimeDecoder().decode(base64Image);
// 2) Создать PDF и вставить изображение
PdfDocument pdf = new PdfDocument();
try (ByteArrayInputStream in = new ByteArrayInputStream(imageBytes)) {
PdfImage img = PdfImage.fromStream(in);
pdf.getPageSettings().setWidth(img.getWidth());
pdf.getPageSettings().setHeight(img.getHeight());
pdf.getPageSettings().setMargins(0, 0, 0, 0);
PdfPageBase page = pdf.getPages().add();
page.getCanvas().drawImage(img, 0, 0);
}
// 3) Сохранить PDF-файл
pdf.saveToFile("output/image.pdf");
}
}
Следующий пример декодирует изображение Base64 и встраивает его на страницу PDF. Вывод выглядит так:
Этот рабочий процесс идеально подходит для встраивания отсканированных документов или подписей, которые поступают в формате Base64.
Для векторной графики вы также можете ознакомиться с нашим руководством по преобразованию SVG в PDF на Java.
Загрузка PDF в Base64, изменение и сохранение обратно в Base64
Во многих API PDF-файл поступает в формате Base64. С помощью Spire.PDF вы можете загрузить его, рисовать на страницах (текст/водяные знаки) и снова вернуть Base64 — идеально для бессерверных функций или микросервисов.
Ключевые концепции Spire.PDF, используемые здесь
- PdfDocument.loadFromBytes(byte[]) — создание документа непосредственно из декодированных байтов.
- PdfPageBase#getCanvas() — получение поверхности для рисования для размещения текста, фигур или изображений.
- Шрифты и кисти — например, PdfTrueTypeFont или встроенные шрифты через PdfFont, с PdfSolidBrush для раскрашивания.
- Сохранение в память — pdf.saveToStream(ByteArrayOutputStream) дает необработанные байты, которые можно повторно закодировать с помощью Base64.
Пример: Загрузка, изменение и сохранение PDF в Base64 на Java
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.io.*;
import java.util.Base64;
public class EditBase64Pdf {
public static void main(String[] args) throws Exception {
String base64Pdf = "..."; // входящая строка PDF в Base64
// Декодирование в байты
byte[] pdfBytes = Base64.getDecoder().decode(base64Pdf);
// Загрузка PDF
PdfDocument pdf = new PdfDocument();
pdf.loadFromBytes(pdfBytes);
// Добавление штампа на каждую страницу
for (PdfPageBase page : (Iterable<PdfPageBase>) pdf.getPages()) {
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial", Font.BOLD, 36));
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLUE));
page.getCanvas().drawString("Processed", font, brush, 100, 100);
}
// Сохранение в память и кодирование обратно в Base64
ByteArrayOutputStream output = new ByteArrayOutputStream();
pdf.saveToStream(output);
pdf.close();
String resultBase64 = Base64.getEncoder().encodeToString(output.toByteArray());
System.out.println(resultBase64);
}
}
В этом примере на каждую страницу PDF добавляется синий водяной знак «Processed» перед повторным кодированием в Base64. Результат выглядит так:
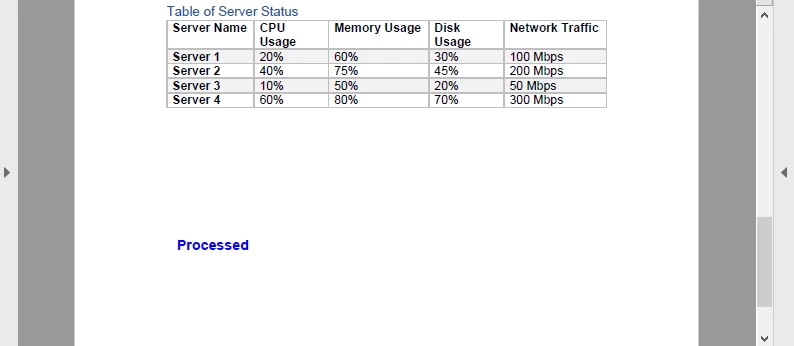
Этот круговой процесс (Base64 → PDF → Base64) полезен для конвейеров обработки документов, таких как проставление штампов на счетах-фактурах или добавление динамических подписей в облачном сервисе.
Связанные руководства:
Извлечение текста из PDF на Java | Создание PDF-документов на Java
Вопросы производительности и памяти
- Потоковая обработка против файлового ввода-вывода — при работе с Base64 предпочитайте ByteArrayInputStream и ByteArrayOutputStream, чтобы избежать ненужных временных файлов.
- PDF-файлы с большим количеством изображений — декодирование изображений Base64 может резко увеличить использование памяти; рассмотрите возможность масштабирования или сжатия перед встраиванием.
- Большие PDF-файлы — Spire.PDF обрабатывает PDF-файлы размером в несколько мегабайт, но для очень больших документов рассмотрите возможность постраничной обработки.
- Бессерверные функции — рабочие процессы с Base64 хорошо подходят, потому что вы избегаете зависимости от файловой системы и возвращаете результаты напрямую через ответы API.
Часто задаваемые вопросы
В: Могу ли я преобразовать Base64 в PDF, используя только JDK?
Да. Java SE предоставляет утилиты для работы с Base64 и файловым вводом-выводом, так что вы можете выполнять преобразование без дополнительных библиотек.
В: Могу ли я редактировать PDF с помощью стандартной библиотеки Java?
Нет. Java SE не поддерживает разбор структуры или рендеринг PDF. для редактирования используйте специальную библиотеку, такую как Spire.PDF for Java.
В: Достаточно ли Free Spire.PDF for Java?
Да. Free Spire.PDF for Java имеет ограничения по размеру документа, но достаточен для тестирования или небольших проектов.
В: Нужно ли мне сохранять PDF-файлы на диск?
Не всегда. Преобразование также может выполняться в памяти с использованием потоков, что часто предпочтительнее для API и облачных приложений.