
В нашей повседневной работе и жизни мы часто сталкиваемся с необходимостью подсчитать слова в документе PDF. В отличие от Microsoft Word, файлы PDF не имеют встроенной функции подсчета слов, а большинство программ для чтения PDF предлагают лишь ограниченную поддержку подсчета слов. Это связано с тем, что файлы PDF рассматривают текст как фиксированные визуальные элементы, а не как непрерывный поток слов. Если вы задаетесь вопросом, как легко подсчитать слова в документах PDF, вы попали по адресу. Это руководство представит 3 высокоэффективных решения этой проблемы, охватывающих все: от простых, прямых онлайн-инструментов до автоматизированных скриптов, которые могут обрабатывать сотни документов одновременно.
- Подсчет слов с помощью онлайн-инструментов
- Подсчет слов с помощью Adobe Acrobat и MS Word
- Подсчет слов в PDF с помощью Python
- Сравнение методов
Подсчет слов в PDF с помощью онлайн-счетчика слов
Когда дело доходит до подсчета слов в PDF, онлайн-счетчики обычно являются первым решением, которое приходит на ум. Они невероятно легкие, не требуют установки и отлично работают на всех ваших устройствах. Вместо того чтобы загромождать свой компьютер тяжелым программным обеспечением, вы можете быстро получить ответ прямо в веб-браузере и перейти к другим задачам.
Как это сделать:
- Шаг 1. Откройте веб-браузер и найдите надежный бесплатный онлайн-инструмент для подсчета слов в PDF.
- Шаг 2. Перетащите ваш PDF-файл прямо в поле загрузки.
- Шаг 3. После загрузки и обработки файла веб-сайт отобразит общее количество слов.
Результат подсчета слов с помощью онлайн-инструмента для PDF: 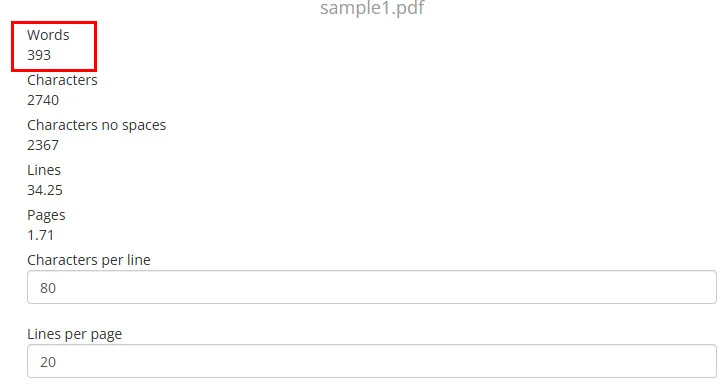
Предупреждение о конфиденциальности и безопасности: Не рекомендуется загружать конфиденциальные PDF-файлы на бесплатные онлайн-сайты. Если ваш документ содержит коммерческие тайны, личные удостоверения или финансовые данные, полностью пропустите этот метод. Бесплатные инструменты безопасны только для общедоступных, неконфиденциальных статей.
Подсчет слов в PDF с помощью Adobe Acrobat и MS Word
Если вы работаете с юридическими документами, переводческими проектами или академическими работами, точность часто важнее скорости. В этих случаях настольный рабочий процесс может быть более безопасным и надежным выбором, чем полагаться на онлайн-инструменты.
В отличие от Microsoft Word, Adobe Acrobat не предоставляет выделенной функции подсчета слов во всех своих версиях. Распространенным обходным путем является преобразование PDF в Word, а затем использование встроенной функции Word для проверки количества слов.
Пошаговое руководство:
- Шаг 1. Откройте ваш PDF-файл в Adobe Acrobat (или используйте официальный онлайн-конвертер Adobe Acrobat).
- Шаг 2. Нажмите Экспорт PDF в правой панели и выберите Microsoft Word (.docx) в качестве формата вывода.
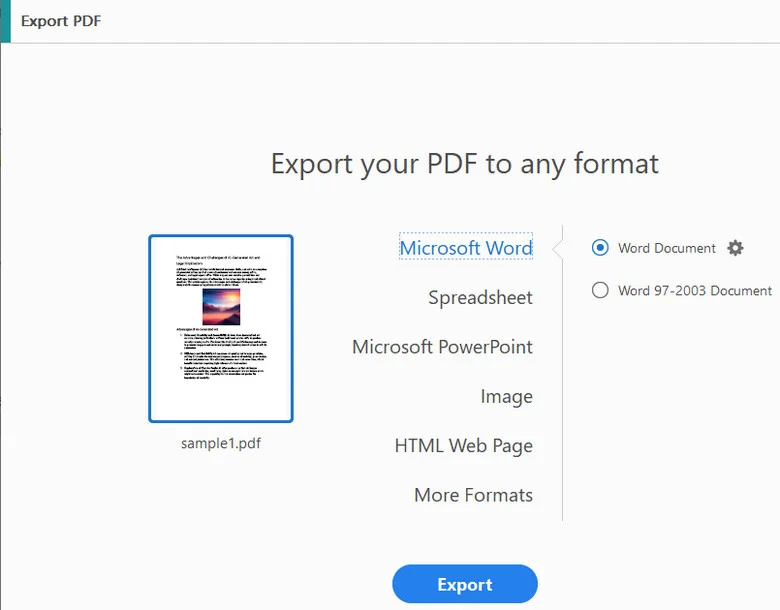
- Шаг 3. Сохраните вновь созданный файл на свой локальный компьютер.
- Шаг 4. Откройте документ в Microsoft Word, перейдите на вкладку Рецензирование и нажмите Число слов.
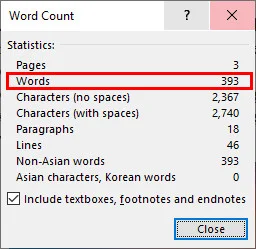
Примечание: Не беспокойтесь о своем исходном файле, этот процесс просто создает совершенно новый документ Word, оставляя ваш исходный PDF нетронутым.
Как автоматически подсчитать слова в PDF с помощью Python
Ручное преобразование файлов подходит для одного или двух документов. Но что, если вы разработчик или аналитик данных с папкой, содержащей 500 отчетов? Ручная обработка большого количества файлов может занять много времени, что делает автоматизацию более практичным решением.
Для разработчиков программное извлечение текста часто является наиболее эффективным способом подсчета слов в PDF-файлах. Вы можете автоматизировать подсчет слов в PDF с помощью короткого скрипта Python. С помощью бесплатного Spire.PDF для Python вы можете программно извлекать необработанный текст и использовать регулярные выражения для мгновенного подсчета слов.
Пример кода Python
Приведенный ниже код показывает, как подсчитать слова в нескольких PDF-документах за один раз:
import os
import re
from spire.pdf.common import *
from spire.pdf import *
# 1. Определите каталог входной папки
folder_path = "/input/pdfs/"
# 2. Настройте параметры извлечения текста один раз
extractOptions = PdfTextExtractOptions()
extractOptions.IsExtractAllText = True
print("--- Отчет о подсчете слов ---")
# 3. Переберите все файлы в каталоге
for file_name in os.listdir(folder_path):
# Обрабатывайте только PDF-файлы
if file_name.lower().endswith('.pdf'):
file_path = os.path.join(folder_path, file_name)
# Инициализируйте объект Document и загрузите текущий PDF
doc = PdfDocument()
doc.LoadFromFile(file_path)
# Извлеките текст со всех страниц текущего файла
total_text = ""
for i in range(doc.Pages.Count):
page = doc.Pages.get_Item(i)
textExtractor = PdfTextExtractor(page)
text = textExtractor.ExtractText(extractOptions)
if text:
total_text += text + "\n"
doc.Close()
# Подсчитайте английские слова в извлеченном тексте
word_count = len(re.findall(r"\b[a-zA-Z]+(?:['-][a-zA-Z]+)*\b", total_text))
# Выведите имя файла и соответствующее количество слов
print(f"Файл: {file_name} | Количество слов: {word_count}")
Ниже представлен предварительный просмотр результатов пакетного подсчета слов, выведенных скриптом:

Примечание: Подсчет слов выполняется с помощью сопоставления регулярных выражений с извлеченным текстом. Поскольку разные приложения используют разные правила для обработки чисел, слов с дефисами, знаков препинания, колонтитулов и другого специального содержимого, результат может незначительно отличаться от количества слов, сообщаемого Microsoft Word, Adobe Acrobat или онлайн-счетчиками слов PDF.
Зачем это использовать?
Этот метод быстр и безопасен, поскольку ваши данные никогда не покидают ваш компьютер. Если вы имеете дело с крупномасштабными проектами, использование бесплатного Spire.PDF для Python дает несколько технических преимуществ по сравнению со стандартными инструментами с открытым исходным кодом:
- Высокоточное извлечение текста: В отличие от базовых парсеров PDF, которые часто перемешивают порядок текста или путают многоколоночные макеты, он точно захватывает текстовые потоки на основе визуального макета, гарантируя, что ваш окончательный подсчет будет максимально приближен к реальному человеческому чтению.
- Отличная производительность на больших файлах: Он плавно обрабатывает огромные многостраничные документы, не расходуя много системной памяти, благодаря оптимизированным механизмам освобождения внутренней памяти.
- Расширяемость «все в одном»: Если ваш рабочий процесс обработки PDF расширится в будущем, вам не придется менять инструменты. Он полностью поддерживает расширенные функции, такие как добавление аннотаций, подписание документов или преобразование форматов файлов в рамках единой унифицированной кодовой базы.
Просто имейте в виду, что если ваш PDF содержит отсканированные изображения вместо текста, вам потребуется добавить шаг OCR (оптическое распознавание символов) для предварительного чтения текста.
Какой счетчик слов в PDF выбрать?
Выбор правильного метода зависит от вашей текущей ситуации и типа документа. Вот краткий обзор, который поможет вам выбрать лучший инструмент для вашей задачи:
| Метод | Точность | Скорость | Безопасность конфиденциальности | Лучше всего подходит для |
|---|---|---|---|---|
| Онлайн-инструменты | Средняя | Быстро | Низкая | Быстрые, общедоступные и неконфиденциальные статьи |
| Adobe в Word | Высокая | Средняя | Высокая (100% локально) | Официальные документы, юридические документы и файлы с высокой степенью конфиденциальности |
| Скрипт Python | Высокая | Быстро (пакетная обработка) | Высокая (100% локально) | Разработчики, аналитики данных и автоматизированная пакетная обработка |
Заключение
Подсчет слов в файлах PDF не обязательно должен быть сложным. Независимо от того, нужен ли вам быстрый ответ от онлайн-инструмента, надежный подсчет путем преобразования в Word или автоматизированное решение Python для пакетной обработки, существует вариант для каждого сценария. Выберите подход, который соответствует вашим потребностям, и начните анализировать свои PDF-документы более эффективно.