
Файлы PDF широко используются для обмена документами, но не все PDF-файлы ведут себя как отсканированные документы. Многие PDF-файлы содержат редактируемые текстовые слои, векторную графику и выбираемый контент, что позволяет легко изменять, копировать или повторно использовать их.
В реальных сценариях, таких как архивирование, публичное распространение или окончательная обработка документов, вам может понадобиться, чтобы PDF-файл выглядел и вел себя как отсканированный файл. Преобразование PDF в отсканированный PDF удаляет его редактируемую структуру и превращает каждую страницу в представление на основе изображения.
В этом руководстве объясняется, что такое отсканированный PDF-файл, зачем он может вам понадобиться и как преобразовать PDF-файл в отсканированный документ с помощью онлайн-инструментов или автоматизации на Python.
Быстрая навигация
- Что такое отсканированный PDF?
- Зачем конвертировать PDF в отсканированный PDF?
- Метод 1: Конвертируйте PDF в отсканированный PDF с помощью онлайн-инструмента
- Метод 2: Конвертируйте PDF в отсканированный PDF с помощью Python
- PDF и отсканированный PDF: ключевые различия
- Можно ли редактировать отсканированные PDF-файлы?
- Часто задаваемые вопросы
Что такое отсканированный PDF?
Отсканированный PDF — это PDF-документ, в котором каждая страница хранится в виде изображения, а не в виде редактируемого текста или векторных объектов. Он очень похож на документ, созданный путем сканирования бумаги на физическом сканере.
Ключевые характеристики отсканированных PDF-файлов включают:
- Текст не подлежит выделению и редактированию
- Страницы основаны на изображениях
- Макет и внешний вид визуально зафиксированы
- Размер файла обычно больше, чем у текстовых PDF-файлов
- Поиск по тексту недоступен, если не применено оптическое распознавание символов (OCR)
Когда вы конвертируете PDF в отсканированный PDF, вы, по сути, «сплющиваете» его содержимое и удаляете его внутреннюю структуру.
Зачем конвертировать PDF в отсканированный PDF?
Превращение PDF в отсканированный документ полезно во многих ситуациях:
- Предотвращение случайного редактирования или повторного использования контента
- Подготовка документов к архивированию
- Распространение окончательных отчетов или уведомлений
- Имитация бумажных рабочих процессов
- Стандартизация внешнего вида документов на разных платформах
По сравнению с защитой на основе разрешений, отсканированные PDF-файлы полагаются на структурное преобразование, а не на правила, применяемые средством просмотра, что делает их более устойчивыми к случайным изменениям.
Метод 1: Конвертируйте PDF в отсканированный PDF с помощью онлайн-инструмента
Онлайн-конвертеры PDF подходят для быстрых одноразовых преобразований неконфиденциальных документов.
Шаги:
-
Откройте надежный веб-сайт для конвертации PDF в отсканированный PDF (например, SafePDFKit).
-
Загрузите PDF-файл, который хотите конвертировать.
-
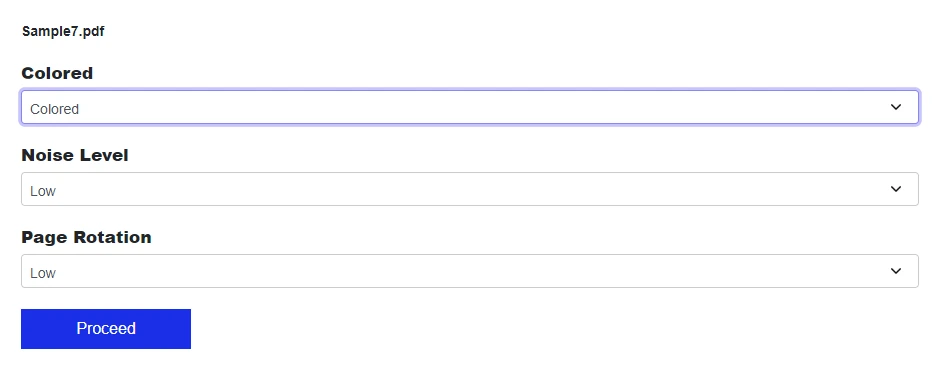
Настройте параметры, такие как цветовой режим, уровень шума и поворот страницы.
-
Конвертируйте и загрузите отсканированный PDF.
Лучше всего подходит для:
- Разовых преобразований
- Публичных документов или документов с низким уровнем риска
- Пользователей, предпочитающих инструменты на основе браузера
Примечание: избегайте загрузки конфиденциальных файлов, если сервис четко не объясняет, как обрабатываются и удаляются загруженные документы.
Если вы хотите ограничить редактирование, копирование или печать с помощью защиты паролем, вы можете обратиться к руководству о том, как шифровать PDF-файлы.
Метод 2: Конвертируйте PDF в отсканированный PDF с помощью Python
Для пакетной обработки или автоматизированных рабочих процессов Python предлагает надежный способ преобразования PDF-файлов в отсканированные документы на основе изображений.
Библиотеки, такие как Spire.PDF for Python, позволяют вам отображать каждую страницу PDF как изображение и создавать новый PDF, используя эти изображения.
Шаг 1: Установите библиотеку
pip install spire.pdf
Вы также можете скачать Spire.PDF for Python и добавить его в свой проект вручную.
Шаг 2: Преобразуйте страницы PDF в изображения и соберите PDF заново
from spire.pdf import *
# Load the original PDF
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a new PDF for the scanned output
scanned_pdf = PdfDocument()
# Convert each page to an image
for i in range(pdf.Pages.Count):
image_stream = pdf.SaveAsImage(i)
image = PdfImage.FromStream(image_stream)
page = scanned_pdf.Pages.Add(
SizeF(float(image.Width), float(image.Height)),
PdfMargins(0.0, 0.0)
)
page.Canvas.DrawImage(
image,
RectangleF.FromLTRB(0.0, 0.0, float(image.Width), float(image.Height))
)
# Save the scanned PDF
scanned_pdf.SaveToFile("ScannedPDF.pdf")
pdf.Dispose()
scanned_pdf.Dispose()
Предварительный просмотр преобразованного отсканированного PDF:
В этом отсканированном PDF-файле каждая страница отображается и встраивается как полностраничное изображение. Это преобразование удаляет исходный текстовый слой и структуру документа, делая содержимое нередактируемым и невыделяемым.
Преимущества программного преобразования:
- Стабильное качество вывода
- Поддержка пакетной обработки
- Без ручного вмешательства
- Простая интеграция в конвейеры обработки документов
Для более гибких пакетных рабочих процессов Python также поддерживает прямое преобразование PDF в изображения или шифрование PDF для дальнейшего снижения риска редактирования и повторного использования контента.
PDF и отсканированный PDF: ключевые различия
| Характеристика | Стандартный PDF | Отсканированный PDF |
|---|---|---|
| Редактируемый текст | Да | Нет |
| Выделение текста | Да | Нет |
| Поисковый контент | Да | Нет (без OCR) |
| Размер файла | Меньше | Больше |
| Лучший вариант использования | Редактирование и повторное использование | Распространение и архивирование |
Краткий совет: Если пользователи должны только просматривать документ, а не повторно использовать или изменять его содержимое, отсканированный PDF часто является лучшим выбором.
Можно ли редактировать отсканированные PDF-файлы?
Отсканированные PDF-файлы значительно сложнее редактировать, чем стандартные PDF-файлы, но они не являются абсолютно нередактируемыми.
- Продвинутые редакторы могут заменять изображения
- Инструменты OCR могут извлекать текст
- Содержимое можно перепечатать вручную
Однако для большинства пользователей и повседневных рабочих процессов отсканированные PDF-файлы эффективно препятствуют редактированию и повторному использованию контента.
Лучшая практика:
- Надежно храните оригинальные редактируемые PDF-файлы
- Используйте отсканированные PDF-файлы для распространения или архивирования
- Сочетайте с OCR только в том случае, если требуется поиск по тексту
Заключение
Преобразование PDF в отсканированный PDF — это практичный способ превратить редактируемые документы в визуально зафиксированные файлы на основе изображений. Удаляя текстовую структуру и «сплющивая» каждую страницу в изображение, отсканированные PDF-файлы лучше подходят для обмена окончательным контентом и сохранения целостности документа.
Независимо от того, используете ли вы онлайн-конвертер PDF в отсканированный PDF для быстрых задач или автоматизацию на Python для крупномасштабных рабочих процессов, выбор правильного подхода гарантирует, что ваши документы останутся единообразными, профессиональными и устойчивыми к случайным изменениям.
Часто задаваемые вопросы
Удаляет ли преобразование PDF в отсканированный PDF текст, доступный для поиска?
Да. Когда PDF преобразуется в отсканированный PDF, каждая страница сохраняется как изображение, поэтому исходный текстовый слой удаляется. В результате текст нельзя искать или выделять, если после этого не будет применено оптическое распознавание символов (OCR).
Увеличит ли преобразование PDF в отсканированный документ размер файла?
В большинстве случаев да. Отсканированные PDF-файлы основаны на изображениях, а данные изображений обычно требуют больше места для хранения, чем текстовое и векторное содержимое. Окончательный размер файла зависит от таких факторов, как разрешение изображения и настройки сжатия.
В чем разница между отсканированным PDF и экспортом PDF в виде изображений?
Экспорт PDF в виде изображений создает отдельные файлы изображений, в то время как отсканированный PDF встраивает эти изображения обратно в один документ PDF. Отсканированный PDF сохраняет формат контейнера PDF, что упрощает его совместное использование, просмотр и архивирование.
Могут ли отсканированные PDF-файлы полностью предотвратить редактирование или копирование?
Отсканированные PDF-файлы значительно сокращают возможность случайного редактирования и копирования, поскольку они не содержат редактируемого текста. Однако передовые инструменты или программное обеспечение для оптического распознавания символов (OCR) все еще могут извлекать содержимое, поэтому отсканированные PDF-файлы следует рассматривать как практическое средство устрашения, а не как абсолютную защиту.