
Современные приложения в значительной степени зависят от API, которые возвращают структурированные данные JSON. Хотя эти данные идеально подходят для программных систем, заинтересованным сторонам и бизнес-командам часто требуется информация, представленная в читаемом, удобном для совместного использования формате — и отчеты в формате PDF остаются одним из наиболее широко распространенных стандартов для документирования, аудита и распространения.
Вместо того, чтобы вручную преобразовывать файлы JSON с помощью онлайн-инструментов, разработчики могут автоматизировать весь рабочий процесс — от получения данных API в реальном времени до создания структурированных отчетов в формате PDF.
В этом руководстве вы узнаете, как создать сквозной конвейер автоматизации с использованием Python:
- Получение данных JSON из API
- Разбор и структурирование ответа
- Загрузка данных на лист Excel
- Экспорт листа в виде хорошо отформатированного отчета PDF
Этот подход идеально подходит для плановой отчетности, информационных панелей SaaS, экспорта аналитики и систем автоматизации бэкэнда.
Почему онлайн-конвертеров JSON в PDF недостаточно
Онлайн-конвертеры могут быть полезны для быстрых, разовых задач. Однако они часто оказываются неэффективными при работе с живыми API или автоматизированными рабочими процессами.
Общие ограничения включают:
- Нет возможности получать данные напрямую из API
- Отсутствие поддержки автоматизации или планирования
- Ограниченный контроль над форматированием и макетом отчета
- Сложность обработки вложенных структур JSON
- Проблемы с конфиденциальностью при загрузке конфиденциальных данных
- Нет интеграции с бэкэнд-конвейерами или системами CI/CD
Для разработчиков, создающих автоматизированные системы отчетности, программный рабочий процесс обеспечивает гораздо большую гибкость, масштабируемость и контроль. Используя Python и Spire.XLS, вы можете создавать структурированные отчеты непосредственно из ответов API без ручного вмешательства.
Предварительные требования и обзор архитектуры: конвейер JSON API → Excel → PDF
Прежде чем создавать рабочий процесс автоматизации, убедитесь, что ваша среда подготовлена:
pip install spire.xls requests
Зачем использовать Excel в качестве промежуточного слоя?
Вместо прямого преобразования JSON в PDF, в этом руководстве Excel используется в качестве структурированного слоя отчетности. Этот подход дает несколько преимуществ:
- Преобразует неструктурированный JSON в чистые табличные макеты
- Обеспечивает простое форматирование и управление столбцами
- Обеспечивает согласованный вывод в PDF
- Поддерживает будущие улучшения, такие как диаграммы и сводки
Архитектура конвейера
Процесс автоматизации следует структурированному конвейеру преобразования:
- Уровень API : получает данные JSON в реальном времени из бэкэнд-сервисов
- Уровень обработки данных : нормализует и выравнивает структуры JSON
- Уровень макета отчета (Excel) : организует данные в читаемые таблицы
- Уровень экспорта (PDF) : создает окончательный отчет для совместного использования
Этот многоуровневый подход повышает масштабируемость и сохраняет гибкость логики отчетности для будущих сценариев автоматизации.
Шаг 1 — Получение данных JSON из API
Большинство автоматизированных рабочих процессов отчетности начинаются со сбора данных в реальном времени из API. Вместо того, чтобы вручную экспортировать файлы, ваш скрипт напрямую извлекает последние записи из бэкэнд-сервисов, аналитических платформ или SaaS-приложений. Это гарантирует:
- Отчеты всегда содержат актуальные данные
- Никаких ручных шагов по загрузке или преобразованию
- Простая интеграция в запланированные конвейеры автоматизации
Ниже приведен пример, показывающий, как получить данные JSON с помощью Python:
import requests
# Example API endpoint
url = "https://api.example.com/employees"
headers = {
"Authorization": "Bearer YOUR_API_TOKEN"
}
response = requests.get(url, headers=headers, timeout=30)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
api_data = response.json()
print("Records retrieved:", len(api_data))
Ключевые практики:
- Всегда проверяйте код состояния HTTP
- Включайте заголовки аутентификации при необходимости
- Обрабатывайте ограничения скорости и регулирование API
- Подготовьтесь к постраничной навигации при работе с большими наборами данных
В примерах этого руководства используется популярная библиотека Python requests для обработки HTTP-коммуникаций; обратитесь к официальной документации Requests для получения информации о расширенных шаблонах аутентификации и управления сеансами.
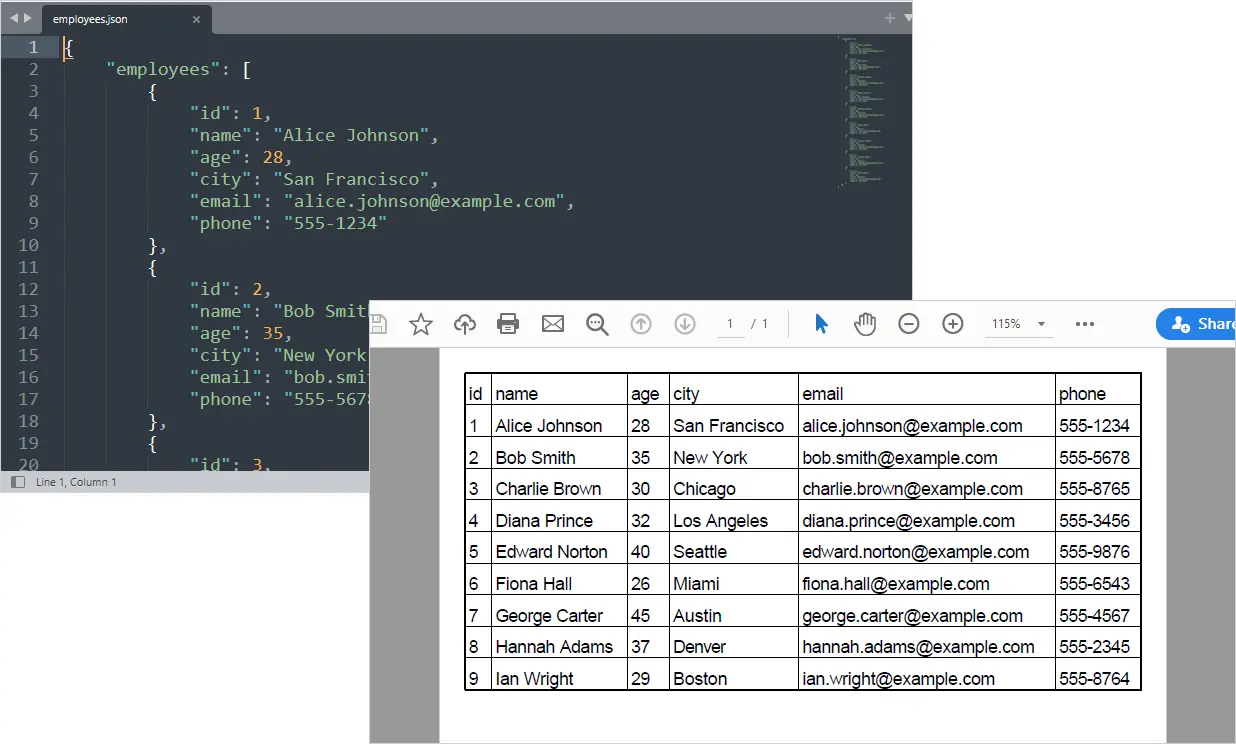
Шаг 2 — Разбор и структурирование ответа JSON
Не все файлы JSON имеют одинаковую структуру. Некоторые API возвращают простой список записей, в то время как другие заключают данные в объекты или включают вложенные массивы и подполя. Прямая запись сложного JSON в Excel часто приводит к ошибкам или нечитаемым отчетам.
Понимание различных структур JSON
| Тип JSON | Пример структуры | Прямой экспорт в Excel |
|---|---|---|
| Простой список | [ {…}, {…} ] | Работает напрямую |
| Обернутый список | { "employees": [ {…} ] } | ⚠ Сначала извлеките список |
| Вложенные объекты | { "address": { "city": "NY" } } | ⚠ Выровнять поля |
| Вложенные массивы | { "skills": ["Python", "SQL"] } | ⚠ Преобразовать в строку |
Нормализованная структура должна выглядеть так:
[
{"id":1,"name":"Alice","city":"NY","skills":"Python, SQL"}
]
Этот формат можно записывать непосредственно в строки Excel. Если вы не знакомы со структурой вложенных объектов и массивов, просмотр официальной спецификации формата данных JSON может помочь прояснить, как организованы сложные ответы API.
Нормализация JSON перед созданием отчетов
Вместо того, чтобы вручную изменять JSON для каждого API, вы можете автоматически:
- Обнаруживать обернутые списки
- Выравнивать вложенные объекты
- Преобразовывать массивы в читаемые строки
- Стандартизировать данные для отчетности
Ниже приведен многоразовый помощник по нормализации:
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
Примечание: Глубоко вложенные многоуровневые структуры JSON могут потребовать дополнительного рекурсивного выравнивания в зависимости от сложности API.
Пример использования:
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
structured_data = normalize_json(raw_data)
Это гарантирует, что набор данных безопасен для экспорта в Excel независимо от сложности JSON.
Шаг 3 — Загрузка структурированных данных JSON на лист Excel
Excel действует как структурированный слой отчетности после нормализации JSON. Как только сложные структуры JSON будут выровнены в простой список словарей, данные можно будет записывать непосредственно в строки и столбцы для дальнейшего форматирования и экспорта в PDF.
Используя Spire.XLS для Python, разработчики могут создавать, изменять и форматировать отчеты Excel полностью с помощью кода — без необходимости в Microsoft Excel — что упрощает интеграцию расширенных операций с электронными таблицами в автоматизированные рабочие процессы отчетности.
Создание книги и листа
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
Как это работает:
- Инициализирует новый файл Excel в памяти.
- Получает доступ к первому листу.
- Подготавливает холст для записи структурированных данных.
Запись заголовков и строк данных
headers = list(structured_data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
for row_idx, row in enumerate(structured_data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = str(row.get(key, ""))
Как это работает:
- Извлекает заголовки столбцов из структурированных данных.
- Сначала записывает строку заголовков.
- Перебирает записи и последовательно заполняет строки.
- Преобразует значения в строки для обеспечения согласованного вывода.
Подготовка форматирования перед экспортом
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
Поскольку лист уже определяет макет и форматирование, экспорт в PDF сохраняет визуальную структуру без дополнительной логики рендеринга.
Шаг 4 — Экспорт листа в виде отчета PDF
После того, как данные структурированы и отформатированы в Excel, экспорт в PDF создает портативный, профессиональный отчет, подходящий для:
- Распространения среди заинтересованных сторон
- Документации по соответствию
- Автоматизированных конвейеров отчетности
- Архивного хранения
Сохранить лист Excel как отчет PDF
sheet.SaveToPdf("output.pdf")
Ваш структурированный отчет в формате PDF теперь создается из данных API автоматически.
Вывод:
Вам также может понравиться: Конвертировать Excel в PDF на Python
Полный скрипт — от JSON API до структурированного отчета PDF
from spire.xls import *
from spire.xls.common import *
import json
import requests
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
# =========================
# Step 1: Get JSON from API
# =========================
api_url = "https://api.example.com/employees"
response = requests.get(api_url)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
raw_data = response.json()
# =========================
# Step 2: Normalize JSON
# =========================
data = normalize_json(raw_data)
# =========================
# Step 3: Create Workbook
# =========================
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
headers = list(data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write rows
for row_idx, row in enumerate(data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row.get(key, "")
# =========================
# Step 4: Format worksheet
# =========================
# Set conversion settings to adjust sheet layout
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True # Retain paper size during conversion
workbook.ConverterSetting.SheetFitToWidth = True # Fit sheet to width during conversion
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# =========================
# Step 5: Export to PDF
# =========================
sheet.SaveToPdf("output.pdf")
workbook.Dispose()
Если вашим источником данных является локальный файл JSON, а не живой API, вы можете загрузить данные непосредственно с диска перед созданием отчета в формате PDF.
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
Практические примеры использования
Этот рабочий процесс автоматизации может применяться в широком диапазоне сценариев отчетности, основанных на данных:
- Автоматизированные конвейеры отчетности API — создавайте ежедневные или еженедельные отчеты в формате PDF из бэкэнд-сервисов без ручного экспорта.
- Сводки по использованию и активности SaaS — преобразуйте API аналитики приложений в структурированные отчеты для клиентов или для внутреннего использования.
- Экспорт финансовых и кадровых отчетов — преобразуйте структурированные данные API в стандартизированные документы PDF для внутреннего распространения.
- Снимки информационных панелей аналитики — собирайте метрики, управляемые API, и преобразуйте их в удобные для совместного использования отчеты для руководства.
- Запланированные отчеты бизнес-аналитики — автоматически создавайте сводки в формате PDF из хранилищ данных или API аналитики.
- Документация по соответствию и аудиту — создавайте согласованные записи в формате PDF с отметками времени из структурированных наборов данных API.
Заключительные мысли
Автоматизация создания отчетов в формате PDF из ответов JSON API позволяет разработчикам создавать масштабируемые конвейеры отчетности, которые исключают ручную обработку. Комбинируя возможности API Python с функциями экспорта в Excel и PDF Spire.XLS для Python, вы можете создавать структурированные, профессиональные отчеты непосредственно из источников данных в реальном времени.
Независимо от того, создаете ли вы еженедельные бизнес-отчеты, внутренние информационные панели или результаты для клиентов, этот рабочий процесс обеспечивает гибкость, автоматизацию и полный контроль над процессом создания отчетов.
JSON в PDF: часто задаваемые вопросы
Могу ли я конвертировать JSON напрямую в PDF без Excel?
Да, но использование Excel в качестве промежуточного слоя упрощает структурирование таблиц, управление макетами и создание согласованного, профессионального форматирования отчетов.
Как обрабатывать большие или постраничные ответы API?
Перебирайте страницы или токены, предоставляемые API, и объединяйте все результаты в один набор данных перед созданием отчета в формате PDF.
Может ли этот рабочий процесс выполняться автоматически по расписанию?
Да. Вы можете автоматизировать скрипт с помощью заданий cron, планировщика задач Windows, конвейеров CI/CD или бэкэнд-сервисов для регулярного создания отчетов.
Как настроить макет отчета PDF?
Отформатируйте лист Excel перед экспортом — настройте ширину столбцов, примените стили, закрепите заголовки или добавьте диаграммы. Эти настройки будут сохранены в PDF.
Что делать, если API возвращает отсутствующие или несогласованные поля?
Используйте безопасные методы извлечения, такие как .get() со значениями по умолчанию, при разборе JSON, чтобы предотвратить ошибки и поддерживать согласованные структуры таблиц.