
В современных приложениях JSON является одним из самых распространенных форматов данных для API, файлов конфигурации и обмена данными. Однако, хотя JSON идеально подходит для машин, он не всегда удобен для чтения человеком. Экспорт JSON в таблицу PDF может помочь четко представить структурированную информацию в отчетах, панелях мониторинга или внутренней документации.
В этом руководстве вы узнаете, как преобразовать JSON в хорошо отформатированную таблицу PDF с помощью Python и Spire.XLS, включая:
- Автоматическое определение наборов данных для экспорта в таблицу
- Выравнивание вложенных полей JSON
- Создание профессионально выглядящих PDF-файлов
Мы также рассмотрим ручное извлечение наборов данных для глубоко вложенных структур, что даст вам полный контроль над сложными файлами JSON.
Почему преобразование JSON в PDF не всегда просто
JSON бывает всех форм и размеров:
- Плоские массивы: легко конвертировать непосредственно в строки
- Вложенные объекты: например, словарь спецификаций внутри каждого продукта
- Массивы внутри массивов: например, список продуктов внутри отдела
- Несогласованные ключи: некоторые объекты имеют дополнительные или отсутствующие поля
Например, рассмотрим эту структуру для инвентаря магазина:
{
"store": {
"departments": [
{
"name": "Computers",
"products": [{"id": 1, "name": "Laptop", "specs": {"CPU": "i7"}}]
},
{
"name": "Accessories",
"products": [{"id": 101, "name": "Mouse", "colors": ["Black", "White"]}]
}
]
}
}
Выровнять это в таблицу непросто, потому что вложенные поля необходимо преобразовать в столбцы, а массивы, возможно, потребуется расширить или объединить в строки. Наше решение обеспечивает надежную обработку большинства структур JSON, предлагая при этом возможность ручного извлечения для особо сложных случаев.
Для краткого обзора синтаксиса и структуры JSON см.: Введение в JSON
Шаг 1 — Загрузка данных JSON
Перед обработкой загрузите ваш файл JSON в Python. Использование встроенного модуля json гарантирует, что содержимое будет проанализировано в нативные словари и списки Python:
import json
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
Что делает этот шаг:
- Читает файл JSON с диска
- Преобразует его в объекты Python (dict и list) для дальнейшей обработки
Совет: Всегда указывайте encoding="utf-8", чтобы избежать проблем с символами, не относящимися к ASCII.
Шаг 2 — Автоматическое определение набора данных для экспорта
Многие файлы JSON содержат несколько вложенных списков. Часто нам нужен список объектов, который представляет «основную таблицу» — обычно это самый большой список словарей. Следующая функция автоматически ищет наиболее похожий на таблицу набор данных:
def find_dataset(obj):
"""Recursively search JSON and return the most table-like dataset."""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No suitable dataset found.")
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# Usage
dataset = find_dataset(data)
Как это работает:
- Рекурсивно обходит структуру JSON
- Оценивает списки-кандидаты на основе количества ключей × количества элементов
- Выбирает самый богатый набор данных в качестве основной таблицы
Ограничения:
- Не будет автоматически объединять глубоко вложенные списки (например, продукты нескольких отделов)
- Некоторые поля могут потребовать ручного извлечения для полной видимости
Необязательно — Ручное извлечение набора данных
Для глубоко вложенных или настраиваемых наборов данных извлекайте данные вручную:
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
Этот подход гарантирует, что вы захватите именно те поля, которые вам нужны, включая добавление контекста, такого как отдел для каждого продукта.
Шаг 3 — Выравнивание и нормализация JSON
Чтобы преобразовать JSON в таблицу, вложенные структуры должны быть выровнены:
def flatten_json(obj, parent_key="", sep="_"):
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
if not value:
items[new_key] = ""
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
def normalize_json(data):
flattened_rows = [flatten_json(item) for item in data]
all_keys_ordered, seen_keys = [], set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
rows, headers = normalize_json(dataset)
Что делает этот шаг:
- Преобразует вложенные словари в имена столбцов, такие как specs_CPU, specs_RAM
- Преобразует списки примитивов в строки, разделенные запятыми
- Сохраняет первый встреченный ключ в качестве первого столбца
Шаг 4 — Экспорт в PDF через Excel
После того, как данные выровнены, экспортируйте их в PDF с помощью Spire.XLS for Python. Вместо того, чтобы рендерить PDF напрямую, мы используем Excel в качестве промежуточного слоя макета. Этот подход обеспечивает полный контроль над структурой таблицы, форматированием, полями и масштабированием перед экспортом в PDF.
Установить зависимость:
pip install spire.xls
Экспорт JSON в PDF с помощью Spire.XLS:
from spire.xls import Workbook
import os
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write data rows
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatting
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF saved: {output_path}")
Советы по форматированию PDF:
- Автоподбор ширины столбцов по содержимому
- Установите поля для удобства чтения
- Включите линии сетки для лучшей визуализации таблицы
Вам также может понравиться: Преобразование Excel в PDF на Python
Шаг 5 — Пример: Экспорт продуктов из сложного файла JSON
Объедините предыдущие шаги:
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1: Automatic detection
dataset = find_dataset(data)
rows, headers = normalize_json(dataset)
# Option 2: Manual extraction for nested structure
# dataset = []
# for dept in data["store"]["departments"]:
# for prod in dept["products"]:
# prod["department"] = dept["name"]
# dataset.append(prod)
# rows, headers = normalize_json(dataset)
export_to_pdf(rows, headers, "output/Products.pdf")
Ключевые моменты:
- Автоматическое определение работает для большинства массивов JSON
- Ручное извлечение обеспечивает контроль над вложенными и иерархическими наборами данных
Вывод:
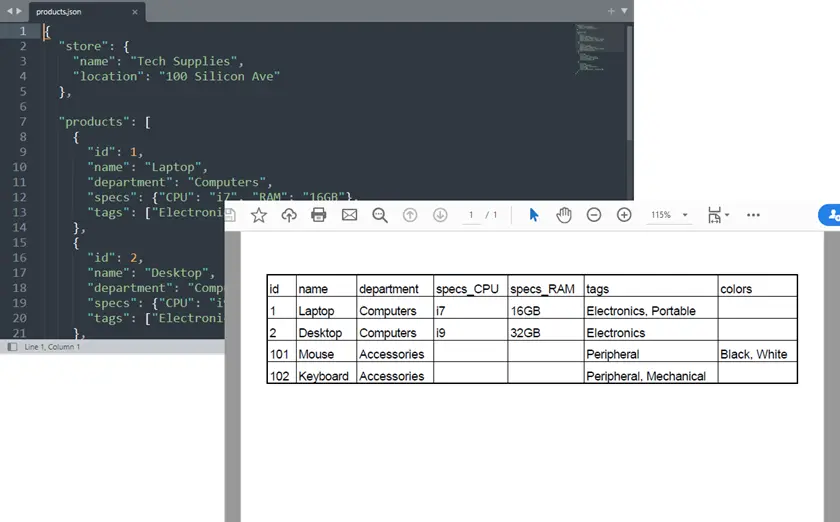
Полный пример на Python: JSON в PDF
from spire.xls import Workbook
import json
import os
# ---------------------------
# Atoumatically Detect dataset
# ---------------------------
def find_dataset(obj):
"""
Recursively search JSON and return the most table-like dataset.
Strategy:
- Find lists containing dictionaries
- Score datasets based on number of fields
- Choose the dataset with the richest structure
"""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
# Count unique keys across objects
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("No suitable dataset found.")
# choose best scored dataset
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# ---------------------------
# Robust Recursive JSON Flattener
# ---------------------------
def flatten_json(obj, parent_key="", sep="_"):
"""
Recursively flattens nested dictionaries and lists.
Rules:
- Nested dict → key_subkey
- List of primitives → comma-separated string
- List of dicts → indexed columns (key_0_name, key_1_name)
- Mixed lists / arrays-of-arrays → recursively indexed (key_0_0, key_0_1)
"""
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
# Empty list
if not value:
items[new_key] = ""
# List of primitives
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
# Mixed or nested lists
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
# Top-level lists
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
# ---------------------------
# Normalize JSON Data (First-Seen Column Order)
# ---------------------------
def normalize_json(data):
"""
Flatten JSON objects and align headers, preserving the first-seen order.
The first key in the first JSON object will be the first column.
"""
if not isinstance(data, list):
raise ValueError("Data must be a list of objects.")
flattened_rows = [flatten_json(item) for item in data]
# Track headers in first-seen order
all_keys_ordered = []
seen_keys = set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
# Align all rows to include all keys
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
# ---------------------------
# Export to PDF via Excel
# ---------------------------
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write header
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write data rows
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatting
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF saved: {output_path}")
# ===========================
# Example: Complex JSON Dataset
# ===========================
# Load JSON from file
with open(r"C:\Users\Administrator\Desktop\Products.json", "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1. Automatically detect dataset (work for most cases)
dataset = find_dataset(data)
'''
# Option 2. Manually extract dataset (work for complex unusual structures)
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
'''
# Normalize (first-seen key becomes first column)
rows, headers = normalize_json(dataset)
# Export to PDF
export_to_pdf(rows, headers, "output/Products.pdf")
Заключение
Преобразование JSON в таблицу PDF может быть сложным, особенно при наличии вложенных структур или несогласованных ключей. Используя Python и Spire.XLS, вы можете автоматически выравнивать JSON и сохранять логический порядок столбцов, превращая сложные наборы данных в чистые, читаемые таблицы, подходящие для отчетов или документации.
Автоматическое определение набора данных обрабатывает большинство файлов JSON, в то время как ручное извлечение позволяет при необходимости захватывать определенные вложенные данные. Этот подход предлагает гибкий и надежный способ преобразования JSON в профессиональные таблицы PDF без потери структуры или контекста.
Часто задаваемые вопросы
Может ли это обрабатывать любой файл JSON?
Автоматическое определение работает для большинства, но для глубоко вложенных данных может потребоваться ручное извлечение.
Как определяется порядок столбцов?
Столбцы появляются в порядке их первого появления в объектах JSON.
Можно ли объединить несколько наборов данных?
Да, вы можете объединить наборы данных перед выравниванием.
Как обрабатывать отсутствующие поля?
Отсутствующие значения автоматически представляются как пустые ячейки.
Могу ли я настроить макет PDF?
Да, поля, линии сетки и параметры автоподбора полностью настраиваются через Spire.XLS.