
Java (485)
A table represents information or data in the form of horizontal rows and vertical columns. Creating tables is often more efficient than describing the data in the paragraph text, especially when the data is numerical or large. The tabular data presentation makes it easier to read and understand. In this article, you will learn how to create tables in a PDF document in Java using Spire.PDF for Java.
Spire.PDF for Java offers the PdfTable and the PdfGrid class to work with the tables in a PDF document. The PdfTable class is used to quickly create simple, regular tables without too much formatting, while the PdfGrid class is used to create more complex tables.
The table below lists the differences between these two classes.
| PdfTable | PdfGrid | |
| Formatting | ||
| Row | Can be set through events. No API support. | Can be set through API. |
| Column | Can be set through API. | Can be set through API. |
| Cell | Can be set through events. No API support. | Can be set through API. |
| Others | ||
| Column span | Not support. | Can be set through API. |
| Row span | Can be set through events. No API support. | Can be set through API. |
| Nested table | Can be set through events. No API support. | Can be set through API. |
| Events | BeginCellLayout, EndCellLayout, BeginRowLayout, EndRowLayout, BeginPageLayout, EndPageLayout. | BeginPageLayout, EndPageLayout. |
The following sections demonstrate how to create a table in PDF using the PdfTable class and the PdfGrid class, respectively.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.7.0</version>
</dependency>
</dependencies>
Create a Table in PDF Using PdfTable Class
The following are the steps to create a table using the PdfTable class using Spire.PDF for Java.
- Create a PdfDocument object.
- Add a page to it using PdfDocument.getPages().add() method.
- Create a Pdftable object.
- Set the table style using the methods under PdfTableStyle object which is returned by PdfTable.getTableStyle() method.
- Insert data to table using PdfTable.setDataSource() method.
- Set row height and row color through BeginRowLayout event.
- Draw table on the PDF page using PdfTable.draw() method.
- Save the document to a PDF file using PdfDocument.saveToFile() method.
- Java
import com.spire.data.table.DataTable;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.PdfPageSize;
import com.spire.pdf.graphics.*;
import com.spire.pdf.tables.*;
import java.awt.*;
import java.awt.geom.Point2D;
public class CreateTable {
public static void main(String[] args) {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Add a page
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, new PdfMargins(40));
//Create a PdfTable object
PdfTable table = new PdfTable();
//Set font for header and the rest cells
table.getStyle().getDefaultStyle().setFont(new PdfTrueTypeFont(new Font("Times New Roman", Font.PLAIN, 12), true));
table.getStyle().getHeaderStyle().setFont(new PdfTrueTypeFont(new Font("Times New Roman", Font.BOLD, 12), true));
//Define data
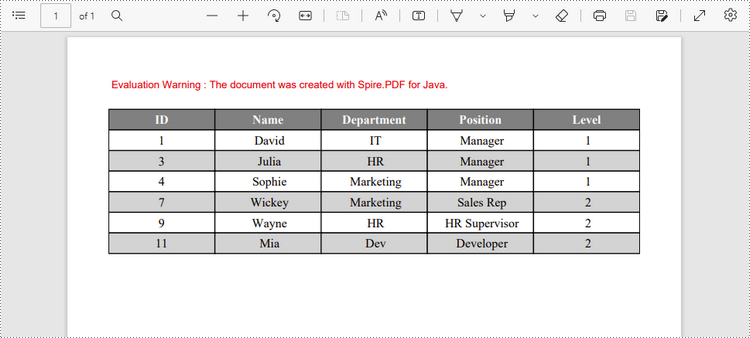
String[] data = {"ID;Name;Department;Position;Level",
"1; David; IT; Manager; 1",
"3; Julia; HR; Manager; 1",
"4; Sophie; Marketing; Manager; 1",
"7; Wickey; Marketing; Sales Rep; 2",
"9; Wayne; HR; HR Supervisor; 2",
"11; Mia; Dev; Developer; 2"};
String[][] dataSource = new String[data.length][];
for (int i = 0; i < data.length; i++) {
dataSource[i] = data[i].split("[;]", -1);
}
//Set data as the table data
table.setDataSource(dataSource);
//Set the first row as header row
table.getStyle().setHeaderSource(PdfHeaderSource.Rows);
table.getStyle().setHeaderRowCount(1);
//Show header(the header is hidden by default)
table.getStyle().setShowHeader(true);
//Set font color and background color of header row
table.getStyle().getHeaderStyle().setBackgroundBrush(PdfBrushes.getGray());
table.getStyle().getHeaderStyle().setTextBrush(PdfBrushes.getWhite());
//Set text alignment in header row
table.getStyle().getHeaderStyle().setStringFormat(new PdfStringFormat(PdfTextAlignment.Center, PdfVerticalAlignment.Middle));
//Set text alignment in other cells
for (int i = 0; i < table.getColumns().getCount(); i++) {
table.getColumns().get(i).setStringFormat(new PdfStringFormat(PdfTextAlignment.Center, PdfVerticalAlignment.Middle));
}
//Register with BeginRowLayout event
table.addBeginRowLayoutEventHandler(new BeginRowLayoutEventHandler() {
public void invoke(Object sender, BeginRowLayoutEventArgs args) {
Table_BeginRowLayout(sender, args);
}
});
//Draw table on the page
table.draw(page, new Point2D.Float(0, 30));
//Save the document to a PDF file
doc.saveToFile("output/PdfTable.pdf");
}
//Event handler
private static void Table_BeginRowLayout(Object sender, BeginRowLayoutEventArgs args) {
//Set row height
args.setMinimalHeight(20f);
//Alternate color of rows except the header row
if (args.getRowIndex() == 0) {
return;
}
if (args.getRowIndex() % 2 == 0) {
args.getCellStyle().setBackgroundBrush(PdfBrushes.getLightGray());
} else {
args.getCellStyle().setBackgroundBrush(PdfBrushes.getWhite());
}
}
}
Create a Table in PDF Using PdfGrid Class
Below are the steps to create a table in PDF using the PdfGrid class using Spire.PDF for Java.
- Create a PdfDocument object.
- Add a page to it using PdfDocument.getPages().add() method.
- Create a PdfGrid object.
- Set the table style using the methods under the PdfGridStyle object which is returned by PdfGrid.getStyle() method.
- Add rows and columns to the table using PdfGrid.getRows().add() method and PdfGrid.getColumns().add() method.
- Insert data to specific cells using PdfGridCell.setValue() method.
- Span cells across columns or rows using PdfGridCell.setRowSpan() method or PdfGridCell.setColumnSpan() method.
- Set the formatting of a specific cell using PdfGridCell.setStringFormat() method and the methods under PdfGridCellStyle object.
- Draw table on the PDF page using PdfGrid.draw() method.
- Save the document to a PDF file using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import com.spire.pdf.grid.PdfGrid;
import com.spire.pdf.grid.PdfGridRow;
import java.awt.*;
import java.awt.geom.Point2D;
public class CreateGrid {
public static void main(String[] args) {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Add a page
PdfPageBase page = doc.getPages().add(PdfPageSize.A4,new PdfMargins(40));
//Create a PdfGrid
PdfGrid grid = new PdfGrid();
//Set cell padding
grid.getStyle().setCellPadding(new PdfPaddings(1, 1, 1, 1));
//Set font
grid.getStyle().setFont(new PdfTrueTypeFont(new Font("Times New Roman", Font.PLAIN, 13), true));
//Add rows and columns
PdfGridRow row1 = grid.getRows().add();
PdfGridRow row2 = grid.getRows().add();
PdfGridRow row3 = grid.getRows().add();
PdfGridRow row4 = grid.getRows().add();
grid.getColumns().add(4);
//Set column width
for (int i = 0; i < grid.getColumns().getCount(); i++) {
grid.getColumns().get(i).setWidth(120);
}
//Write data into specific cells
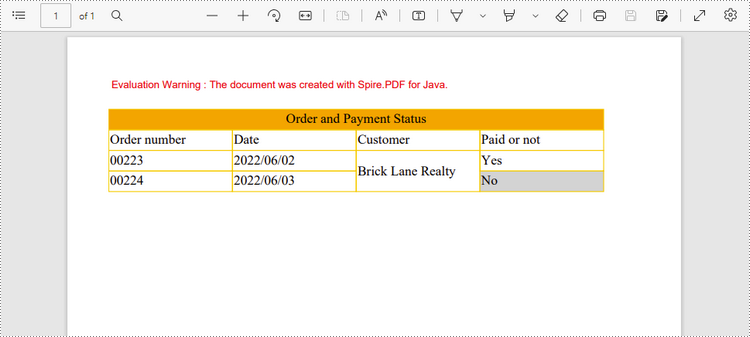
row1.getCells().get(0).setValue("Order and Payment Status");
row2.getCells().get(0).setValue("Order number");
row2.getCells().get(1).setValue("Date");
row2.getCells().get(2).setValue ("Customer");
row2.getCells().get(3).setValue("Paid or not");
row3.getCells().get(0).setValue("00223");
row3.getCells().get(1).setValue("2022/06/02");
row3.getCells().get(2).setValue("Brick Lane Realty");
row3.getCells().get(3).setValue("Yes");
row4.getCells().get(0).setValue("00224");
row4.getCells().get(1).setValue("2022/06/03");
row4.getCells().get(3).setValue("No");
//Span cell across columns
row1.getCells().get(0).setColumnSpan(4);
//Span cell across rows
row3.getCells().get(2).setRowSpan(2);
//Set text alignment of specific cells
row1.getCells().get(0).setStringFormat(new PdfStringFormat(PdfTextAlignment.Center));
row3.getCells().get(2).setStringFormat(new PdfStringFormat(PdfTextAlignment.Left, PdfVerticalAlignment.Middle));
//Set background color of specific cells
row1.getCells().get(0).getStyle().setBackgroundBrush(PdfBrushes.getOrange());
row4.getCells().get(3).getStyle().setBackgroundBrush(PdfBrushes.getLightGray());
//Format cell border
PdfBorders borders = new PdfBorders();
borders.setAll(new PdfPen(new PdfRGBColor(Color.ORANGE), 0.8f));
for (int i = 0; i < grid.getRows().getCapacity(); i++) {
PdfGridRow gridRow = grid.getRows().get(i);
gridRow.setHeight(20f);
for (int j = 0; j < gridRow.getCells().getCount(); j++) {
gridRow.getCells().get(j).getStyle().setBorders(borders);
}
}
//Draw table on the page
grid.draw(page, new Point2D.Float(0, 30));
//Save the document to a PDF file
doc.saveToFile("output/PdfGrid.pdf");
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Merge PDF Files in Java: Full, Partial, and Stream-Based Merging
2022-06-09 07:47:00 Written by hayes Liu
Merging PDFs in Java is a critical requirement for document-intensive applications, from consolidating financial reports to automating archival systems. However, developers face significant challenges in preserving formatting integrity or managing resource efficiency across diverse PDF sources. Spire.PDF for Java provides a robust and straightforward solution to streamline the PDF merging task.
This comprehensive guide explores how to combine PDFs in Java, complete with practical examples to merge multiple files, selected pages, or stream-based merging.
- Setting Up the Java PDF Merge Library
- Merge Multiple PDF Files in Java
- Merge Specific Pages from Multiple PDFs in Java
- Merge PDF Files by Streams in Java
- Conclusion
- FAQs
Setting Up the Java PDF Merge Library
Why Choose Spire.PDF for Java?
- No External Dependencies: Pure Java implementation.
- Rich Features: Merge, split, encrypt, and annotate PDFs.
- Cross-Platform: Works on Windows, Linux, and macOS.
Installation
Before using Spire.PDF for Java, you need to add it to your project.
Option 1: Maven
Add the repository and dependency to pom.xml:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.7.0</version>
</dependency>
</dependencies>
Option 2: Manual JAR
Download the JAR from the E-iceblue website and add it to your project's build path.
Merge Multiple PDF Files in Java
This example is ideal when you want to merge two or more PDF documents entirely. It’s simple, straightforward, and perfect for batch processing.
How It Works:
- Define File Paths: Create an array of strings containing the full paths to the source PDFs.
- Merge Files: The mergeFiles() method takes the array of paths, combines the PDFs, and returns a PdfDocumentBase object representing the merged file.
- Save the Result: The merged PDF is saved to a new file using the save() method.
Java code to combine PDFs:
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfDocumentBase;
public class MergePdfs {
public static void main(String[] args) {
// Get the paths of the PDF documents to be merged
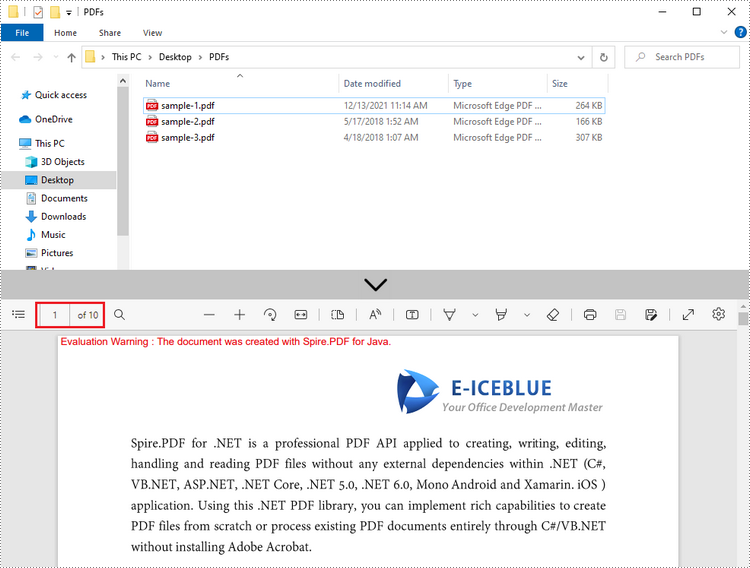
String[] files = new String[] {"sample-1.pdf", "sample-2.pdf", "sample-3.pdf"};
// Merge these PDF documents
PdfDocumentBase pdf = PdfDocument.mergeFiles(files);
// Save the merged PDF file
pdf.save("MergePDF.pdf", FileFormat.PDF);
}
}
Best For:
- Merging entire PDFs stored locally.
- Simple batch operations where no page selection is needed.
Result: Combine three PDF files (a total of 10 pages) into one PDF file.
Merging PDFs often results in large file sizes. To reduce the size, refer to: Compress PDF Files in Java.
Merge Specific Pages from Multiple PDFs in Java
Sometimes, you may only want to merge specific pages from different PDFs (e.g., pages 1-3 from File A and pages 2-5 from File B). This example gives you granular control over which pages to include from each source PDF.
How It Works:
- Load PDFs: Load each source PDF into a PdfDocument object and store them in an array.
- Create a New PDF: A blank PDF document is initialized to serve as the container for merged pages.
- Insert Specific Pages:
- insertPage(): Insert a specified page into the new PDF.
- insertPageRange(): Inserts a range of pages into the new PDF.
- Save the Result: The merged PDF is saved using the saveToFile() method.
Java code to combine selected PDF pages:
import com.spire.pdf.PdfDocument;
public class MergeSelectedPages {
public static void main(String[] args) {
// Get the paths of the PDF documents to be merged
String[] files = new String[] {"sample-1.pdf", "sample-2.pdf", "sample-3.pdf"};
// Create an array of PdfDocument
PdfDocument[] pdfs = new PdfDocument[files.length];
// Loop through the documents
for (int i = 0; i < files.length; i++)
{
// Load a specific document
pdfs[i] = new PdfDocument(files[i]);
}
// Create a new PDF document
PdfDocument pdf = new PdfDocument();
// Insert the selected pages from different PDFs to the new PDF
pdf.insertPage(pdfs[0], 0);
pdf.insertPageRange(pdfs[1], 1,3);
pdf.insertPage(pdfs[2], 0);
// Save the merged PDF
pdf.saveToFile("MergePdfPages.pdf");
}
}
Best For:
- Creating custom PDFs with selected pages (e.g., extracting key sections from reports).
- Scenarios where you need to exclude irrelevant pages from source documents.
Result: Combine selected pages from three separate PDF files into a new PDF
Merge PDF Files by Streams in Java
In applications where PDFs are stored as streams (e.g., PDFs from network streams, in-memory data, or temporary files), Spire.PDF supports merging without saving files to disk.
How It Works:
- Create Input Streams: The FileInputStream objects read the raw byte data of each PDF file.
- Merge Streams: The mergeFiles() method accepts an array of streams, merges them, and returns a PdfDocumentBase object.
- Save and Clean Up: The merged PDF is saved, and all streams and documents are closed to free system resources (critical for preventing leaks).
Java code to merge PDFs via streams:
import com.spire.pdf.*;
import java.io.*;
public class mergePdfsByStream {
public static void main(String[] args) throws IOException {
// Create FileInputStream objects for each PDF document file
FileInputStream stream1 = new FileInputStream(new File("Template_1.pdf"));
FileInputStream stream2 = new FileInputStream(new File("Template_2.pdf"));
FileInputStream stream3 = new FileInputStream(new File("Template_3.pdf"));
// Initialize an array of InputStream objects containing the file input streams
InputStream[] streams = new FileInputStream[]{stream1, stream2, stream3};
// Merge the input streams into a single PdfDocumentBase object
PdfDocumentBase pdf = PdfDocument.mergeFiles(streams);
// Save the merged PDF file
pdf.save("MergePdfsByStream.pdf", FileFormat.PDF);
// Releases system resources used by the merged document
pdf.close();
pdf.dispose();
// Closes all input streams to free up resources
stream1.close();
stream2.close();
stream3.close();
}
}
Best For:
- Merging PDFs from non-file sources (e.g., network downloads, in-memory generation).
- Environments where direct file path access is restricted.
Conclusion
Spire.PDF for Java simplifies complex PDF merging tasks through its intuitive, user-friendly API. Whether you need to merge entire documents, create custom page sequences, or combine PDFs from stream sources, these examples enable efficient PDF merging in Java to address diverse document processing requirements.
To explore more features (e.g., encrypting merged PDFs, adding bookmarks), refer to the official documentation.
Frequently Asked Questions (FAQs)
Q1: Why do merged PDFs show "Evaluation Warning" watermarks?
A: The commercial version adds watermarks. Solutions:
- Request a 30-day trial license to test without any restrictions.
- Use the free version for documents ≤10 pages
Q2: How do I control the order of pages in the merged PDF?
A: The order of pages in the merged PDF is determined by the order of input files (or streams) and the pages you select. For example:
- In full-document merging, files in the input array are merged in the order they appear.
- In selective page merging, use insertPage() or insertPageRange() in the sequence you want pages to appear.
Q3: Can I merge password-protected PDFs?
A: Yes. Spire.PDF for Java supports merging encrypted PDFs, but you must provide the password when loading the file. Use the overloaded loadFromFile() method with the password parameter:
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample.pdf", "userPassword"); // Decrypt with password
Q4: How to merge scanned/image-based PDFs?
A: Spire.PDF handles image-PDFs like regular PDFs, but file sizes may increase significantly.
Spire.PDF for Java is a PDF API that enables Java applications to read, write and save PDF documents without using Adobe Acrobat. Using this Java PDF component, developers and programmers can implement rich capabilities to create PDF files from scratch or process existing PDF documents entirely on Java applications (J2SE and J2EE).
Many rich features can be supported by Spire.PDF for Java, such as security settings, extracting text/images, merging/spliting PDF, drawing text/image/shape/barcode to the PDF, create/filling in form fields, adding/deleting layers, overlaying PDF, inserting text/image watermark, adding/updating/deleting bookmarks, adding tables, adding annotations, adding actions and compressing PDF document etc.
