Java (485)
For PDF documents that contain confidential or sensitive information, you may want to password protect these documents to ensure that only the designated person can access the information. This article will demonstrate how to programmatically encrypt a PDF document and decrypt a password-protected document using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.7.0</version>
</dependency>
</dependencies>
Encrypt a PDF File with Password
There are two kinds of passwords for encrypting a PDF file - open password and permission password. The former is set to open the PDF file, while the latter is set to restrict printing, contents copying, commenting, etc. If a PDF file is secured with both types of passwords, it can be opened with either password.
The PdfDocument.getSecurity().encrypt(java.lang.String openPassword, java.lang.String permissionPassword, java.util.EnumSet<PdfPermissionsFlags> permissions, PdfEncryptionKeySize keySize) method offered by Spire.PDF for Java allows you to set both open password and permission password to encrypt PDF files. The detailed steps are as follows.
- Create a PdfDocument instance.
- Load a sample PDF file using PdfDocument.loadFromFile() method.
- Set open password, permission password, encryption key size and permissions.
- Encrypt the PDF file using PdfDocument.getSecurity().encrypt(java.lang.String openPassword, java.lang.String permissionPassword, java.util.EnumSet<PdfPermissionsFlags> permissions, PdfEncryptionKeySize keySize) method.
- Save the result file using PdfDocument.saveToFile () method.
- Java
import java.util.EnumSet;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.security.PdfEncryptionKeySize;
import com.spire.pdf.security.PdfPermissionsFlags;
public class EncryptPDF {
public static void main(String[] args) {
// Input file path
String input = "data/encryption.pdf";
// Output file path
String output = "output/encryption_output.pdf";
// Create a new PDF document object
PdfDocument doc = new PdfDocument();
// Load the PDF document from the input file path
doc.loadFromFile(input);
// Create a password-based security policy with open and permission passwords
PdfSecurityPolicy securityPolicy = new PdfPasswordSecurityPolicy("openPwd", "permissionPwd");
// Set the encryption algorithm to AES 256-bit
securityPolicy.setEncryptionAlgorithm(PdfEncryptionAlgorithm.AES_256);
// Set document privilege to forbid all actions
securityPolicy.setDocumentPrivilege(PdfDocumentPrivilege.getForbidAll());
// Allow degraded printing
securityPolicy.getDocumentPrivilege().setAllowDegradedPrinting(true);
// Allow modification of annotations
securityPolicy.getDocumentPrivilege().setAllowModifyAnnotations(true);
// Allow document assembly
securityPolicy.getDocumentPrivilege().setAllowAssembly(true);
// Allow modification of document contents
securityPolicy.getDocumentPrivilege().setAllowModifyContents(true);
// Allow filling form fields
securityPolicy.getDocumentPrivilege().setAllowFillFormFields(true);
// Allow printing
securityPolicy.getDocumentPrivilege().setAllowPrint(true);
// Allow printing
doc.encrypt(securityPolicy);
// Save the encrypted document to the output file path
doc.saveToFile(output, FileFormat.PDF);
// Dispose of the document resources
doc.dispose();
}
}
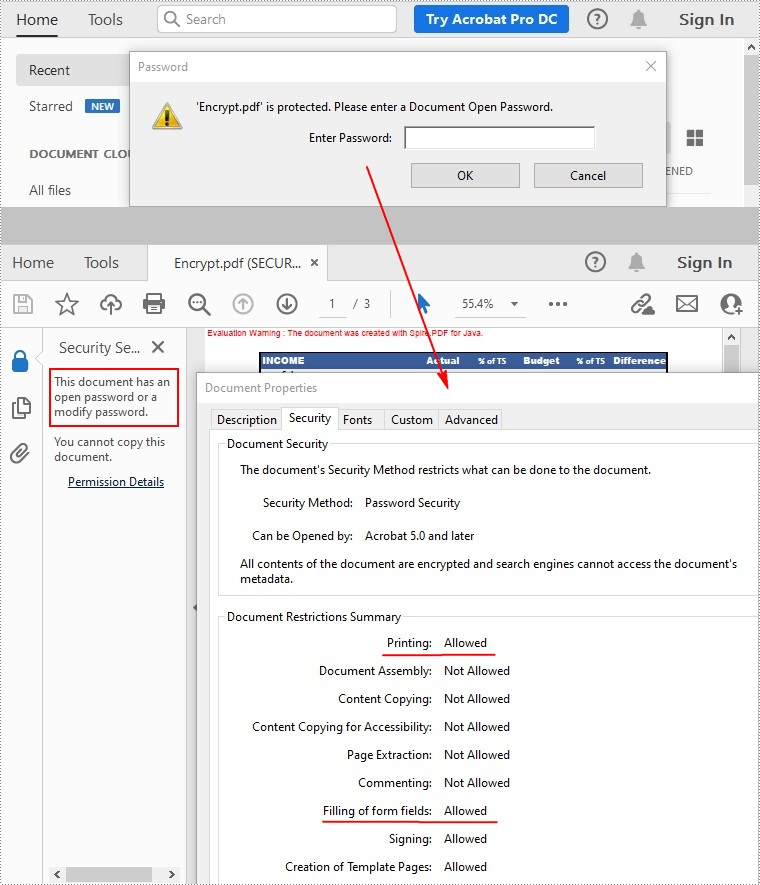
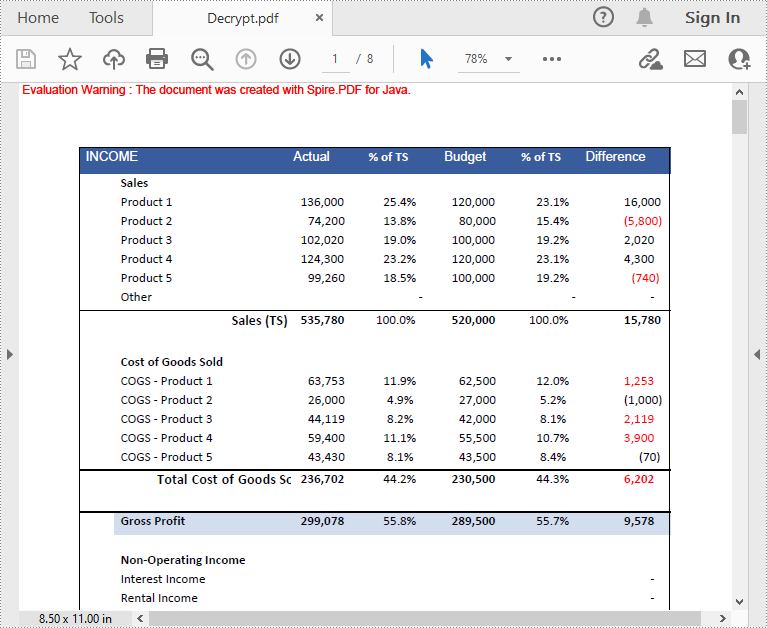
Remove Password to Decrypt a PDF File
When you need to remove the password from a PDF file, you can set the open password and permission password to empty while calling the PdfDocument.getSecurity().encrypt(java.lang.String openPassword, java.lang.String permissionPassword, java.util.EnumSet<PdfPermissionsFlags> permissions, PdfEncryptionKeySize keySize, java.lang.String originalPermissionPassword) method. The detailed steps are as follows.
- Create a PdfDocument object.
- Load the encrypted PDF file with password using PdfDocument.loadFromFile(java.lang.String filename, java.lang.String password) method.
- Decrypt the PDF file by setting the open password and permission password to empty using PdfDocument.getSecurity().encrypt(java.lang.String openPassword, java.lang.String permissionPassword, java.util.EnumSet<PdfPermissionsFlags> permissions, PdfEncryptionKeySize keySize, java.lang.String originalPermissionPassword) method.
- Save the result file using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.security.PdfEncryptionKeySize;
import com.spire.pdf.security.PdfPermissionsFlags;
public class DecryptPDF {
public static void main(String[] args) throws Exception {
// Specify the input and output file paths
String input = "data/decryption.pdf";
String output = "output/decryption_result.pdf";
//load the pdf document.
PdfDocument doc = new PdfDocument();
doc.loadFromFile(input, "test");
//decrypt the document
doc.decrypt();
//save the file
doc.saveToFile(output, FileFormat.PDF);
// Close the PDF document to release resources
doc.close();
// Dispose of the PDF document to free up system resources
doc.dispose();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Adding Watermarks to PDF in Java: Text, Images & Custom Styling
2023-02-06 07:02:00 Written by Koohji
Watermarking PDF documents serves as an essential measure for intellectual property protection, document status identification, and brand reinforcement. Java developers can efficiently automate this process using specialized libraries like Spire.PDF for Java, which offers comprehensive solutions for applying both text-based watermarks (such as "CONFIDENTIAL" labels) and graphical watermarks (including corporate logos).
This practical guide provides step-by-step instructions for implementing PDF watermarking in Java using Spire.PDF. You'll learn proven techniques to enhance document security and professional presentation through effective watermark implementation.
- Java Library for Watermarking PDF
- Steps to Add a Watermark to PDF in Java
- Add a Text Watermark to PDF
- Add an Image Watermark to PDF
- Conclusion
- FAQs
Java Library for Watermarking PDF
Spire.PDF for Java is a versatile library that simplifies PDF manipulation, including watermarking. Its intuitive API allows developers to add watermarks with minimal code while offering fine-grained control over appearance and placement.
To get started, download Spire.PDF for Java and reference it in your project. For Maven users, include the following in your pom.xml:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.7.0</version>
</dependency>
</dependencies>
Steps to Add a Watermark to PDF in Java
- Load the PDF using PdfDocument.
- Define the watermark (text with font/style or an image file).
- Set transparency (e.g., 0.3 for faint, 0.7 for stronger visibility).
- Calculate position (e.g., centered, custom location).
- Apply the watermark to all pages or specific ones.
- Save the modified document to a new file.
Add a Text Watermark to PDF
Text watermarks are ideal for adding labels like "DRAFT", "CONFIDENTIAL", or copyright notices. The implementation involves loading the PDF using PdfDocument , defining the font and brush for styling, and iterating through each page to apply the watermark text using a dedicated method that manages transparency, positioning, and drawing.
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.Dimension2D;
public class AddTextWatermark {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\AI.pdf");
// Create a font and a brush
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial Black", Font.PLAIN, 50), true);
PdfBrush brush = PdfBrushes.getBlue();
// Specify the watermark text
String watermarkText = "DO NOT COPY";
// Specify the opacity level
float opacity = 0.6f;
// Iterate through the pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
PdfPageBase page = doc.getPages().get(i);
// Draw watermark text on the page
addTextWatermark(page, watermarkText, font, brush, opacity);
}
// Save the changes to another file
doc.saveToFile("output/Watermark.pdf");
// Dispose resources
doc.dispose();
}
// Method to add a text watermark to a given page
private static void addTextWatermark(PdfPageBase page, String watermarkText, PdfTrueTypeFont font, PdfBrush brush, float opacity) {
// Set the transparency level for the watermark
page.getCanvas().setTransparency(opacity);
// Measure the size of the watermark text
Dimension2D textSize = font.measureString(watermarkText);
// Get the width and height of the page
double pageWidth = page.getActualSize().getWidth();
double pageHeight = page.getActualSize().getHeight();
// Calculate the position to center the watermark on the page
double x = (pageWidth - textSize.getWidth()) / 2;
double y = (pageHeight - textSize.getHeight()) / 2;
// Draw the watermark text on the page at the calculated position
page.getCanvas().drawString(watermarkText, font, brush, x, y);
}
}
Output:

Add an Image Watermark to PDF
Image watermarks, such as logos, can elevate the professionalism of a document. This process begins by loading the PDF and specifying the image path and opacity. We then iterate through each page, calling a method that loads the image, calculates its position, and draws it on the page with the specified transparency.
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
public class AddImageWatermark {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\AI.pdf");
// Specify the image path
String imagePath = "C:\\Users\\Administrator\\Desktop\\logo2.png";
// Specify the opacity level
float opacity = 0.3f;
// Iterate through the pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
// Draw watermark text on the current page
addImageWatermark(doc.getPages().get(i), imagePath, opacity);
}
// Save the changes to another file
doc.saveToFile("output/Watermark.pdf");
// Dispose resources
doc.dispose();
}
// Method to add an Image watermark to a given page
private static void addImageWatermark(PdfPageBase page, String imagePath, float opacity) {
// Load the image
PdfImage image = PdfImage.fromFile(imagePath);
// Get the width and height of the image
double imageWidth = (double)image.getWidth();
double imageHeight = (double)image.getHeight();
// Get the width and height of the page
double pageWidth = page.getActualSize().getWidth();
double pageHeight = page.getActualSize().getHeight();
// Calculate the position to center the watermark on the page
double x = (pageWidth - imageWidth) / 2;
double y = (pageHeight - imageHeight) / 2;
// Set the transparency level for the watermark
page.getCanvas().setTransparency(opacity);
// Draw the image on the page at the calculated position
page.getCanvas().drawImage(image, x, y);
}
}
Output:

Conclusion
In conclusion, adding watermarks to PDF documents in Java is a straightforward task with the right tools and techniques. By leveraging the Spire.PDF for Java library, developers can seamlessly integrate dynamic text watermarks (like copyright notices) or high-resolution image logos while maintaining optimal file performance.
This guide provided a step-by-step approach, from initial setup to final implementation, ensuring that you can protect your documents effectively. Whether for personal use or professional needs, watermarking is an essential skill that adds a layer of professionalism and integrity to your work.
FAQs
Q1. Can I rotate the watermark text?
Yes, use page.getCanvas().rotateTransform(angle) before drawing the text.
Q2. How do I adjust the position of the watermark?
You can modify the x and y coordinates in the addTextWatermark and addImageWatermark methods to change the watermark position.
Q3. Is it possible to add multiple watermarks to the same PDF?
Yes, by calling drawString() or drawImage() multiple times with different parameters.
Q4. Can I use a transparent PNG as a watermark?
Yes, Spire.PDF preserves the transparency of PNG images.
Q5. How do I apply watermarks to specific pages only?
Modify the loop to target specific pages, e.g., if (i == 0) applies the watermark only to the first page.
Get a Free License
To fully experience the capabilities of Spire.PDF for Java without any evaluation limitations, you can request a free 30-day trial license.
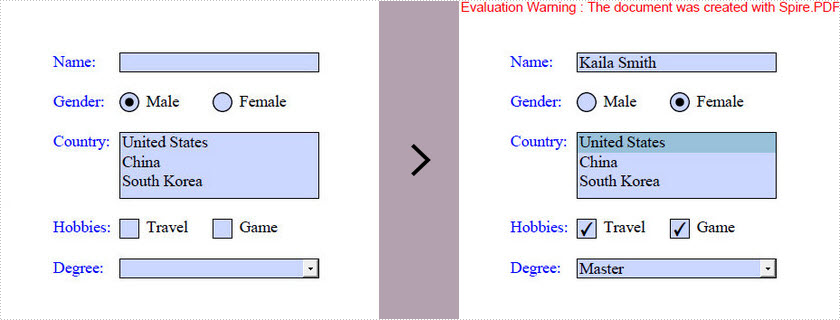
The tutorial shows you how to access the form fields in a PDF document and how to fill each form field with value by using Spire.PDF for Java.
Entire Code:
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.fields.PdfField;
import com.spire.pdf.widget.*;
public class FillFormField{
public static void main(String[] args){
//create a PdfDocument object
PdfDocument doc = new PdfDocument();
//load a sample PDF containing forms
doc.loadFromFile("G:\\java-workspace\\Spire.Pdf\\Forms.pdf");
//get the form fields from the document
PdfFormWidget form = (PdfFormWidget) doc.getForm();
//get the form widget collection
PdfFormFieldWidgetCollection formWidgetCollection = form.getFieldsWidget();
//loop through the widget collection and fill each field with value
for (int i = 0; i < formWidgetCollection.getCount(); i++) {
PdfField field = formWidgetCollection.get(i);
if (field instanceof PdfTextBoxFieldWidget) {
PdfTextBoxFieldWidget textBoxField = (PdfTextBoxFieldWidget) field;
textBoxField.setText("Kaila Smith");
}
if (field instanceof PdfRadioButtonListFieldWidget) {
PdfRadioButtonListFieldWidget radioButtonListField = (PdfRadioButtonListFieldWidget) field;
radioButtonListField.setSelectedIndex(1);
}
if (field instanceof PdfListBoxWidgetFieldWidget) {
PdfListBoxWidgetFieldWidget listBox = (PdfListBoxWidgetFieldWidget) field;
listBox.setSelectedIndex(0);
}
if (field instanceof PdfCheckBoxWidgetFieldWidget) {
PdfCheckBoxWidgetFieldWidget checkBoxField = (PdfCheckBoxWidgetFieldWidget) field;
switch(checkBoxField.getName()){
case "checkbox1":
checkBoxField.setChecked(true);
break;
case "checkbox2":
checkBoxField.setChecked(true);
break;
}
}
if (field instanceof PdfComboBoxWidgetFieldWidget) {
PdfComboBoxWidgetFieldWidget comboBoxField = (PdfComboBoxWidgetFieldWidget) field;
comboBoxField.setSelectedIndex(1);
}
}
//Save the file
doc.saveToFile("FillFormFields.pdf", FileFormat.PDF);
}
}
Output: