
Program Guide (86)
Children categories
PDFs often use a variety of fonts and there are situations where you may need to get or replace these fonts. For instance, getting fonts allows you to inspect details such as font name, size, type, and style, which is especially useful for maintaining design consistency or adhering to specific standards. On the other hand, replacing fonts can help address compatibility issues, particularly when the original fonts are not supported on certain devices or software. In this article, we will explain how to get and replace the used fonts in PDF in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Get Used Fonts in PDF in Python
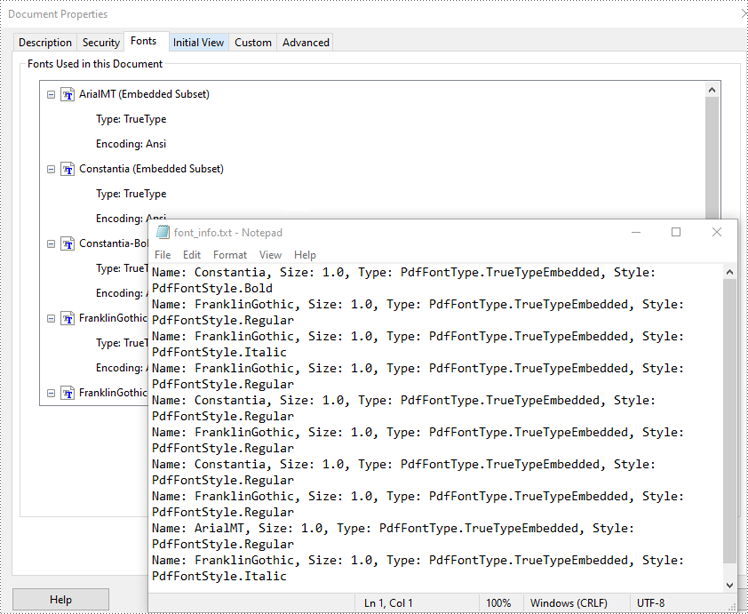
Spire.PDF for Python provides the PdfDocument.UsedFonts property to retrieve a list of all fonts used in a PDF. By iterating through this list, you can easily access detailed font information such as the font name, size, type and style using the PdfUsedFont.Name, PdfUsedFont.Size, PdfUsedFont.Type and PdfUsedFont.Style properties. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the list of fonts used in this document using the PdfDocument.UsedFonts property.
- Create a text file to save the extracted font information.
- Iterate through the font list.
- Get the information of each font, such as font name, size, type and style using the PdfUsedFont.Name, PdfUsedFont.Size, PdfUsedFont.Type and PdfUsedFont.Style properties, and save it to the text file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Input1.pdf")
# Get the list of fonts used in this document
usedFonts = pdf.UsedFonts
# Create a text file to save the extracted font information
with open("font_info.txt", "w") as file:
# Iterate through the font list
for font in usedFonts:
# Get the information of each font, such as font name, size, type and style
font_info = f"Name: {font.Name}, Size: {font.Size}, Type: {font.Type}, Style: {font.Style}\n"
file.write(font_info)
pdf.Close()
Replace Used Fonts in PDF in Python
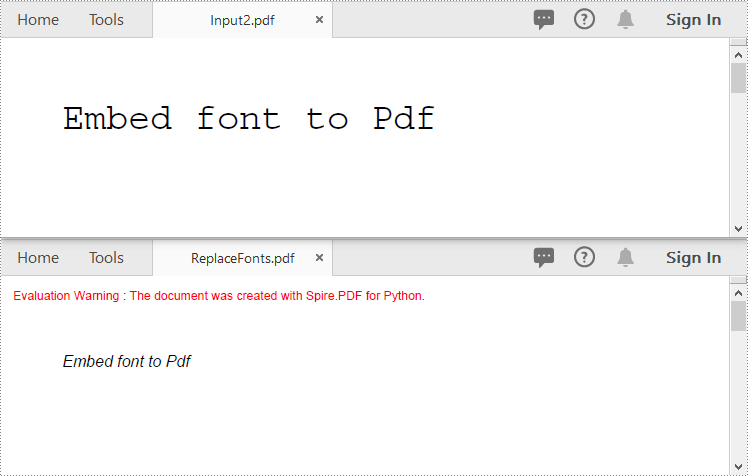
You can replace the fonts used in a PDF with the desired font using the PdfUsedFont.Replace() method. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile() method.
- Get the list of fonts used in this document using the PdfDocument.UsedFonts property.
- Create a new font using the PdfTrueTypeFont class.
- Iterate through the font list.
- Replace each used font with the new font using the PdfUsedFont.Replace() method.
- Save the resulting document to a new PDF using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Input2.pdf")
# Get the list of fonts used in this document
usedFonts = pdf.UsedFonts
# Create a new font
newFont = PdfTrueTypeFont("Arial", 13.0, PdfFontStyle.Italic ,True)
# Iterate through the font list
for font in usedFonts:
# Replace each font with the new font
font.Replace(newFont)
# Save the resulting document to a new PDF
pdf.SaveToFile("ReplaceFonts.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Using Python to manipulate text formatting in PDFs provides a powerful way to automate and customize documents. With the Spire.PDF for Python library, developers can efficiently find text with advanced search options to retrieve and modify text properties like font, size, color, and style, enabling users to find and update text formatting across large document sets, saving time and reducing manual work. This article will demonstrate how to use Spire.PDF for Python to retrieve and modify text formatting in PDF documents with Python code.
- Find Text and Retrieve the Font Information in PDFs
- Find and Modify Text Formatting in PDF Documents
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Find Text and Retrieve Formatting Information in PDFs
Developers can use the PdfTextFinder and PdfTextFindOptions classes provided by Spire.PDF for Python to precisely search for specific text in a PDF document and obtain a collection of PdfTextFragment objects representing the search results. Then, developers can access the format information of the specified search result text through properties such as FontName, FontSize, and FontFamily, under PdfTextFragment.TextStates[] property.
The detailed steps for finding text in PDF and retrieving its font information are as follows:
- Create an instance of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create a PdfTextFinder object using the page.
- Create a PdfTextFindOptions object, set the search options, and apply the search options through PdfTextFinder.Options property.
- Find specific text on the page using PdfTextFinder.Find() method and get a collection of PdfTextFragment objects.
- Get the formatting of the first finding result through PdfTextFragment.TextStates property.
- Get the font name, font size, and font family of the result through PdfTextStates[0].FontName, PdfTextStates[0].FontSize, and PdfTextStates[0].FontFamily properties.
- Print the result.
- Python
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the first page
page = pdf.Pages.get_Item(0)
# Create a PdfTextFinder instance
finder = PdfTextFinder(page)
# Create a PdfTextFindOptions instance and set the search options
options = PdfTextFindOptions()
options.CaseSensitive = True
options.WholeWords = True
# Apply the options
finder.Options = options
# Find the specified text
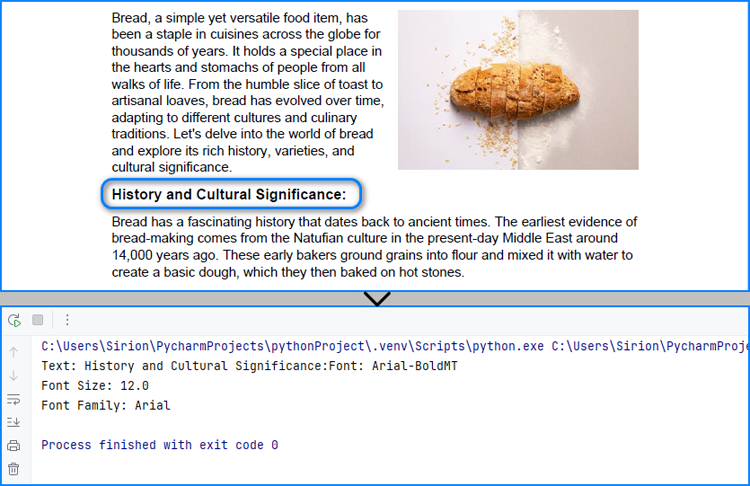
fragments = finder.Find("History and Cultural Significance:")
# Get the formatting of the first fragment
formatting = fragments[0].TextStates
# Get the formatting information
fontInfo = ""
fontInfo += "Text: " + fragments[0].Text
fontInfo += "Font: " + formatting[0].FontName
fontInfo += "\nFont Size: " + str(formatting[0].FontSize)
fontInfo += "\nFont Family: " + formatting[0].FontFamily
# Output font information
print(fontInfo)
# Release resources
pdf.Dispose()
Find and Modify Text Formatting in PDF Documents
After finding specific text, developers can overlay it with a rectangle in the same color as the background and then redraw the text in a new format at the same position, thus achieving text format modification of simple PDF text fragments on solid color pages. The detailed steps are as follows:
- Create an instance of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create a PdfTextFinder object using the page.
- Create a PdfTextFindOptions object, set the search options, and apply the search options through PdfTextFinder.Options property.
- Find specific text on the page using PdfTextFinder.Find() method and get the first result.
- Get the color of the page background through PdfPageBase.BackgroundColor property and change the color to white if the background is empty.
- Draw rectangles with the obtained color in the position of the found text using PdfPageBase.Canvas.DrawRectangle() method.
- Create a new font, brush, and string format and calculate the text frame.
- Draw the text in the new format in the same position using PdfPageBase.Canvas.DrawString() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the first page
page = pdf.Pages.get_Item(0)
# Create a PdfTextFinder instance
finder = PdfTextFinder(page)
# Create a PdfTextFindOptions instance and set the search options
options = PdfTextFindOptions()
options.CaseSensitive = True
options.WholeWords = True
finder.Options = options
# Find the specified text
fragments = finder.Find("History and Cultural Significance:")
# Get the first result
fragment = fragments[0]
# Get the background color and change it to white if its empty
backColor = page.BackgroundColor
if backColor.ToArgb() == 0:
backColor = Color.get_White()
# Draw a rectangle with the background color to cover the text
for i in range(len(fragment.Bounds)):
page.Canvas.DrawRectangle(PdfSolidBrush(PdfRGBColor(backColor)), fragment.Bounds[i])
# Create a new font and a new brush
font = PdfTrueTypeFont("Times New Roman", 16.0, 3, True)
brush = PdfBrushes.get_Brown()
# Create a PdfStringFormat instance
stringFormat = PdfStringFormat()
stringFormat.Alignment = PdfTextAlignment.Left
# Calculate the rectangle that contains the text
point = fragment.Bounds[0].Location
size = SizeF(fragment.Bounds[-1].Right, fragment.Bounds[-1].Bottom)
rect = RectangleF(point, size)
# Draw the text with the specified format in the same rectangle
page.Canvas.DrawString("History and Cultural Significance", font, brush, rect, stringFormat)
# Save the document
pdf.SaveToFile("output/FindModifyTextFormat.pdf")
# Release resources
pdf.Close()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
PDF format has now become a standard for sharing and preserving documents. When working with PDF files, you may sometimes need to copy specific pages in the PDF to extract valuable content, create summaries, or simply share relevant sections without distributing the entire document. In this article, you will learn how to copy pages in PDF in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python. It can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Copy Pages within the Same PDF in Python
To duplicate PDF pages, you can first create template based on a specified page in PDF, and then draw the template on a newly added page through the PdfPageBase.Canvas.DrawTemplate() method. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Get the size of the page using PdfPageBase.Size property.
- Create a template based on the page using PdfPageBase.CreateTemplate() method.
- Add a new page of the same size at the end using PdfDocument.Pages.Add(size: SizeF, margins: PdfMargins) method. Or you can insert a new page of the same size at a specified location using PdfDocument.Pages.Insert(index: int, size: SizeF, margins: PdfMargins) method.
- Draw template on the newly added page using PdfPageBase.Canvas.DrawTemplate(template: PdfTemplate, location: PointF) method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file from disk
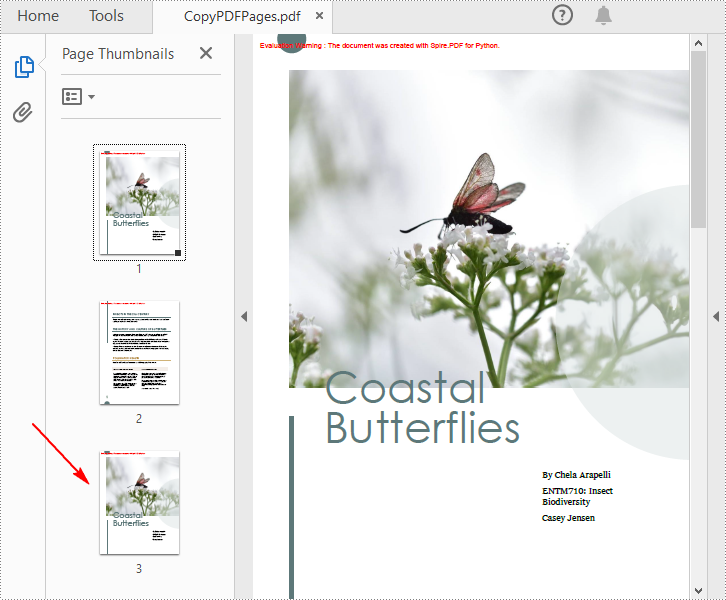
pdf.LoadFromFile("Butterflies.pdf")
# Get the first page
page = pdf.Pages[0]
# Get the size of the page
size = page.Size
# Create a template based on the page
template = page.CreateTemplate()
# Add a new page of the same size at the end
page = pdf.Pages.Add(size, PdfMargins(0.0))
# Insert a new page at the specified location
# page = pdf.Pages.Insert(1, size, PdfMargins(0.0))
# Draw the template on the newly added page
page.Canvas.DrawTemplate(template, PointF(0.0, 0.0))
# Save the PDF file
pdf.SaveToFile("CopyPDFPages.pdf");
pdf.Close()
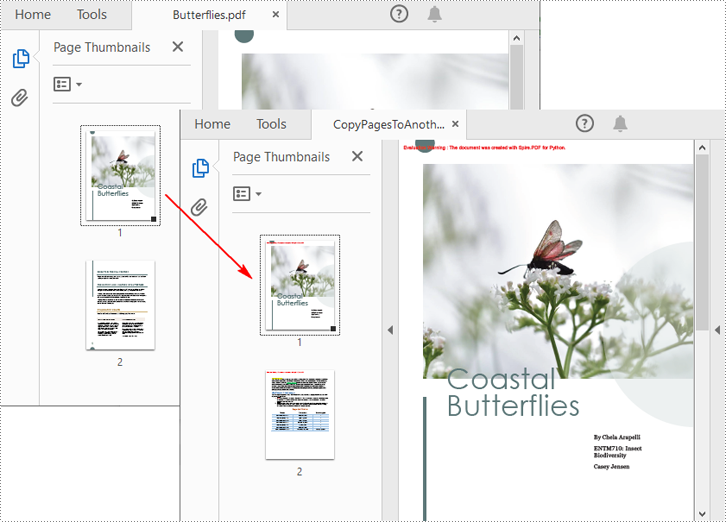
Copy Pages from One PDF to Another in Python
Spire.PDF for Python also allows you to load two PDF files, create templates based on the pages in one PDF file, and then draw them onto the pages in another PDF file. The following are the detailed steps.
- Create a PdfDocument instance.
- Load two PDF files using PdfDocument.LoadFromFile() method.
- Get a specified page in the first PDF using PdfDocument.Pages[] property.
- Get the size of the page using PdfPageBase.Size property.
- Create a template based on the page using PdfPageBase.CreateTemplate() method.
- Insert a new page of the same size at a specified location in the second PDF using PdfDocument.Pages.Insert(index: int, size: SizeF, margins: PdfMargins) method. Or you can add a new page of the same size at the end of the second PDF using PdfDocument.Pages.Add(size: SizeF, margins: PdfMargins) method.
- Draw template on the newly added page using PdfPageBase.Canvas.DrawTemplate(template: PdfTemplate, location: PointF) method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Load the first PDF file
pdf1 = PdfDocument()
pdf1.LoadFromFile("Butterflies.pdf")
# Load the second PDF file
pdf2 = PdfDocument()
pdf2.LoadFromFile("SamplePDF.pdf")
# Get the first page in the first PDF file
page = pdf1.Pages[0]
# Get the size of the page
size = page.Size
# Create a template based on the page
template = page.CreateTemplate()
# Insert a new page at a specified location in the second PDF file
newPage = pdf2.Pages.Insert(0, size, PdfMargins(0.0))
# Add a new page at the end of the second PDF file
# newPage = pdf2.Pages.Add(size, PdfMargins(0.0))
# Draw the template on the newly added page
newPage.Canvas.DrawTemplate(template, PointF(0.0, 0.0))
# Save the result file
pdf2.SaveToFile("CopyPagesToAnotherPDF.pdf")
pdf2.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
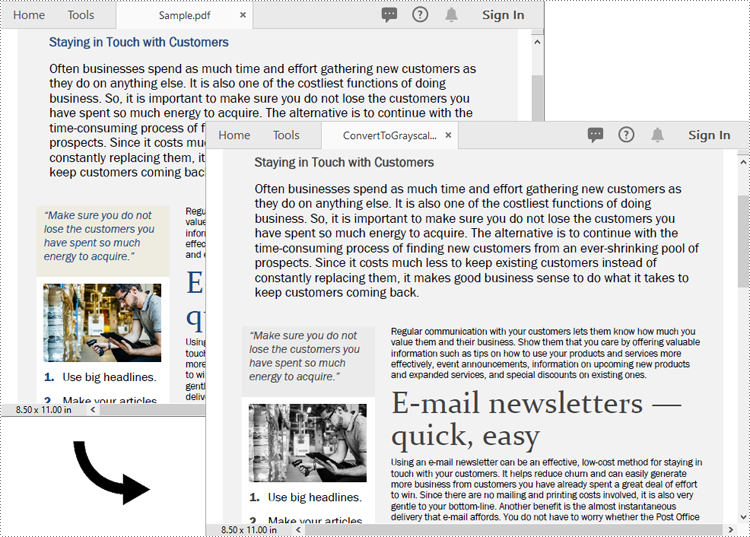
Converting a PDF to grayscale reduces file size by removing unnecessary color data, turning the content into shades of gray. This is especially useful for documents where color isn’t critical, such as text-heavy reports or forms, resulting in more efficient storage and faster transmission. On the other hand, linearization optimizes the PDF’s internal structure for web use. It enables users to start viewing the first page while the rest of the file is still loading, providing a faster and smoother experience, particularly for online viewing. In this article, we will demonstrate how to convert PDF files to grayscale or linearized PDFs in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert PDF to Grayscale in Python
Converting a PDF document to grayscale can be achieved by using the PdfGrayConverter.ToGrayPdf() method. The detailed steps are as follows.
- Load a PDF document using the PdfGrayConverter class.
- Convert the PDF document to grayscale using the PdfGrayConverter.ToGrayPdf() method.
- Python
from spire.pdf.common import * from spire.pdf import * # Specify the input and output PDF file paths inputFile = "Sample.pdf" outputFile = "Output/ConvertToGrayscale.pdf" # Load a PDF document using the PdfGrayConverter class converter = PdfGrayConverter(inputFile) # Convert the PDF document to grayscale converter.ToGrayPdf(outputFile)
Convert PDF to Linearized in Python
To convert a PDF to linearized, you can use the PdfToLinearizedPdfConverter.ToLinearizedPdf() method. The detailed steps are as follows.
- Load a PDF document using the PdfToLinearizedPdfConverter class.
- Convert the PDF document to linearized using the PdfToLinearizedPdfConverter.ToLinearizedPdf() method.
- Python
from spire.pdf.common import * from spire.pdf import * # Specify the input and output PDF file paths inputFile = "Sample.pdf" outputFile = "Output/ConvertToLinearizedPdf.pdf" # Load a PDF document using the PdfToLinearizedPdfConverter class converter = PdfToLinearizedPdfConverter(inputFile) # Convert the PDF document to a linearized PDF converter.ToLinearizedPdf(outputFile)
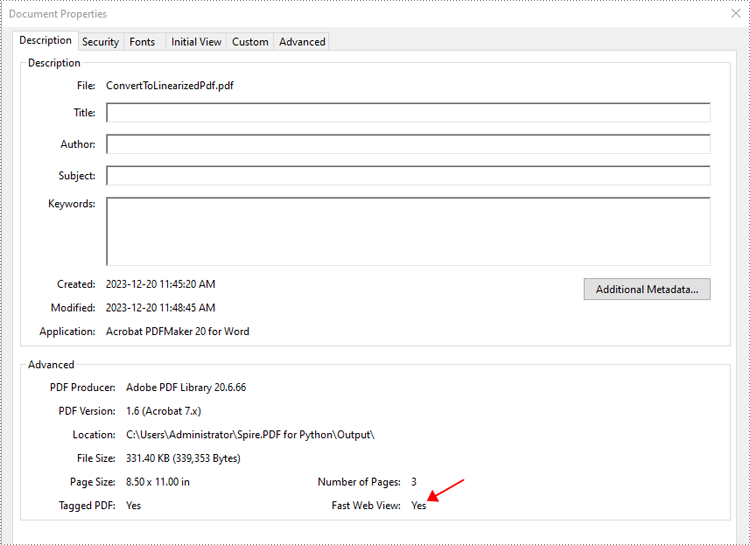
Open the result file in Adobe Acrobat and check the document properties. You will see that the value for "Fast Web View" is set to "Yes", indicating that the file has been linearized.
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Setting view preferences in PDF documents is a crucial feature that can significantly enhance user experience. By configuring options like page layout, display mode, and zoom level, you ensure recipients view the document as intended, without manual adjustments. This is especially useful for business reports, design plans, or educational materials, where consistent presentation is crucial for effectively delivering information and leaving a professional impression. This article will show how to set view preferences of PDF documents with Python code using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Set PDF Viewer Preferences with Python
Viewer preferences allow document creators to define how a PDF document is displayed when opened, including page layout, window layout, and display mode. Developers can use the properties under ViewerPreferences class to set those display options. The detailed steps are as follows:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the ViewerPreferences through using PdfDocument.ViewerPreferences property.
- Set the viewer preferences using properties under ViewerPreferences class.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the viewer preferences
preferences = pdf.ViewerPreferences
# Set the viewer preferences
preferences.FitWindow = True
preferences.CenterWindow = True
preferences.HideMenubar = True
preferences.HideToolbar = True
preferences.DisplayTitle = True
preferences.HideWindowUI = True
preferences.PageLayout = PdfPageLayout.SinglePage
preferences.BookMarkExpandOrCollapse = True
preferences.PrintScaling = PrintScalingMode.AppDefault
preferences.PageMode = PdfPageMode.UseThumbs
# Save the document
pdf.SaveToFile("output/ViewerPreferences.pdf")
pdf.Close()
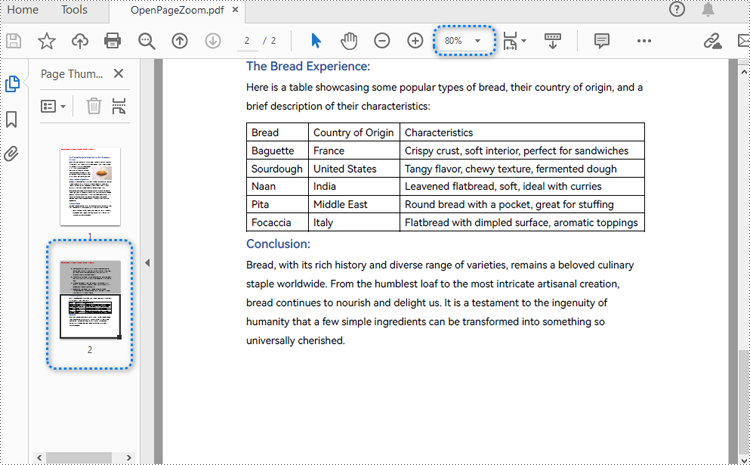
Set the Opening Page and Zoom Level with Python
By creating PDF actions and setting them to be executed when the document is opened, developers can configure additional viewer preferences, such as the initial page display and zoom level. Here are the steps to follow:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create a PdfDestination object and set the location and zoom factor of the destination.
- Create a PdfGoToAction object using the destination.
- Set the action as the document open action through PdfDocument.AfterOpenAction property.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample1.pdf")
# Get the second page
page = pdf.Pages.get_Item(1)
# Create a PdfDestination object
dest = PdfDestination(page)
# Set the location and zoom factor of the destination
dest.Mode = PdfDestinationMode.Location
dest.Location = PointF(0.0, page.Size.Height / 2)
dest.Zoom = 0.8
# Create a PdfGoToAction object
action = PdfGoToAction(dest)
# Set the action as the document open action
pdf.AfterOpenAction = action
# Save the document
pdf.SaveToFile("output/OpenPageZoom.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
When dealing with PDF files, you might sometimes need to crop pages in the PDF to remove unnecessary margins, borders, or unwanted content. By doing so, you can make the document conform to specific design requirements or page sizes, ensuring a more aesthetically pleasing or functionally optimized output. This article will introduce how to crop pages in PDF in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python. It can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
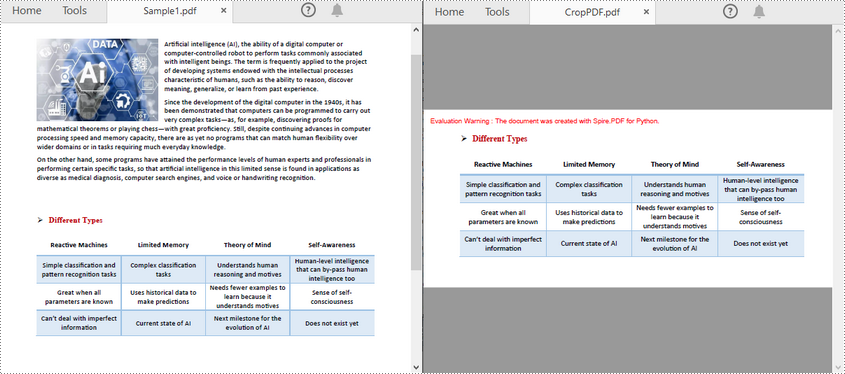
Crop a PDF Page in Python
Spire.PDF for Python allows you specify a rectangular area, and then use the PdfPageBase.CropBox property to crop page to the specified area. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Crop the page to the specified area using PdfPageBase.CropBox property.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file from disk
pdf.LoadFromFile("Sample1.pdf")
# Get the first page
page = pdf.Pages[0]
# Crop the page by the specified area
page.CropBox = RectangleF(0.0, 300.0, 600.0, 260.0)
# Save the result file
pdf.SaveToFile("CropPDF.pdf")
pdf.Close()
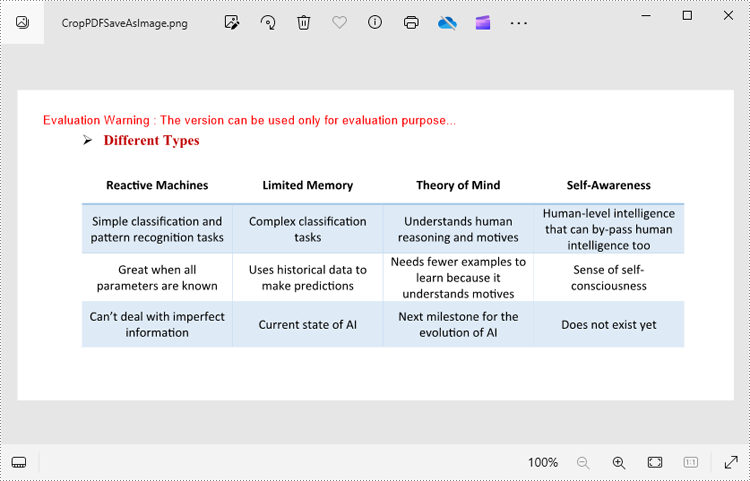
Crop a PDF Page and Export as an Image in Python
To accomplish this task, you can use the PdfDocument.SaveAsImage(pageIndex: int) method to convert a cropped PDF page to an image stream. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Crop the page to the specified area using PdfPageBase.CropBox property.
- Convert the cropped page to an image stream using PdfDocument.SaveAsImage() method.
- Save the image as a PNG, JPG or BMP file using Stream.Save() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file from disk
pdf.LoadFromFile("Sample1.pdf")
# Get the first page
page = pdf.Pages[0]
# Crop the page by the specified area
page.CropBox = RectangleF(0.0, 300.0, 600.0, 260.0)
# Convert the page to an image
with pdf.SaveAsImage(0) as imageS:
# Save the image as a PNG file
imageS.Save("CropPDFSaveAsImage.png")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Setting the transparency of images in PDF documents is crucial for achieving professional-grade output, which allows for layering images without hard edges and creating a seamless integration with the background or underlying content. This not only enhances the visual appeal but also creates a polished and cohesive look, especially in graphics-intensive documents. This article will demonstrate how to effectively set the transparency of PDF images using Spire.PDF for Python in Python programs.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Add Images with Specified Transparency to PDF
Developers can utilize the PdfPageBase.Canvas.DrawImage() method in Spire.PDF for Python to draw an image at a specified location on a PDF page. Before drawing, developers can set the transparency of the canvas using PdfPageBase.Canvas.SetTransparency() method, which in turn sets the transparency level of the image being drawn. Below are the detailed steps:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page in the document using PdfDocument.Pages.get_Item() method.
- Load an image using PdfImage.FromFile() method.
- Set the transparency of the canvas using PdfPageBase.Canvas.SetTransparency() method.
- Draw the image on the page using PdfPageBase.Canvas.DrawImage() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the first page
page = pdf.Pages.get_Item(0)
# Load an image
image = PdfImage.FromFile("Screen.jpg")
# Set the transparency of the canvas
page.Canvas.SetTransparency(0.2)
# Draw the image at the specified location
page.Canvas.DrawImage(image, PointF(80.0, 80.0))
# Save the document
pdf.SaveToFile("output/AddTranslucentPicture.pdf")
pdf.Close()

Adjust the Transparency of Existing Images in PDF
To adjust the transparency of an existing image on a PDF page, developers can retrieve the image along with its bounds, delete the image, and finally redraw the image in the same location with the specified transparency. This process allows for the adjustment of the image's opacity while maintaining its original placement. The detailed steps are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page in the document using PdfDocument.Pages.get_Item() method.
- Get an image on the page as a stream through PdfPageBase.ImagesInfo[].Image property and get the bounds of the image through PdfPageBase.ImagesInfo[].Bounds property.
- Remove the image from the page using PdfPageBase.DeleteImage() method.
- Create a PdfImage instance with the stream using PdfImage.FromStream() method.
- Set the transparency of the canvas using PdfPageBase.Canvas.SetTransparency() method.
- Redraw the image in the same location with the specified transparency using PdfPageBase.Canvas.DrawImage() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample1.pdf")
# Get the first page
page = pdf.Pages.get_Item(0)
# Get the first image on the page as a stream and the bounds of the image
imageStream = page.ImagesInfo[0].Image
bounds = page.ImagesInfo[0].Bounds
# Delete the original image
page.DeleteImage(0)
# Create a PdfImage instance using the image stream
image = PdfImage.FromStream(imageStream)
# Set the transparency of the canvas
page.Canvas.SetTransparency(0.3)
# Draw the new image at the same location using the canvas
page.Canvas.DrawImage(image, bounds)
# Save the document
pdf.SaveToFile("output/SetExistingImageTransparency.pdf")
pdf.Close()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Handling PDF documents using bytes and bytearray provides an efficient and flexible approach within applications. By processing PDFs directly as byte streams, developers can manage documents in memory or transfer them over networks without the need for temporary file storage, optimizing space and improving overall application performance. This method also facilitates seamless integration with web services and APIs. Additionally, using bytearray allows developers to make precise byte-level modifications to PDF documents.
This article will demonstrate how to save PDFs as bytes and bytearray and load PDFs from bytes and bytearray using Spire.PDF for Python, offering practical examples for Python developers.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Create a PDF Document and Save It to Bytes and Bytearray
Developers can create PDF documents using the classes and methods provided by Spire.PDF for Python, save them to a Stream object, and then convert it to an immutable bytes object or a mutable bytearray object. The Stream object can also be used to perform byte-level operations.
The detailed steps are as follows:
- Create an object of PdfDocument class to create a PDF document.
- Add a page to the document and draw text on the page.
- Save the document to a Stream object using PdfDocument.SaveToStream() method.
- Convert the Stream object to a bytes object using Stream.ToArray() method.
- The bytes object can be directly converted to a bytearray object.
- Afterward, the byte streams can be used for further operations, such as writing them to a file using the BinaryIO.write() method.
- Python
from spire.pdf import *
# Create an instance of PdfDocument class
pdf = PdfDocument()
# Set the page size and margins of the document
pageSettings = pdf.PageSettings
pageSettings.Size = PdfPageSize.A4()
pageSettings.Margins.Top = 50
pageSettings.Margins.Bottom = 50
pageSettings.Margins.Left = 40
pageSettings.Margins.Right = 40
# Add a new page to the document
page = pdf.Pages.Add()
# Create fonts and brushes for the document content
titleFont = PdfTrueTypeFont("HarmonyOS Sans SC", 16.0, PdfFontStyle.Bold, True)
titleBrush = PdfBrushes.get_Brown()
contentFont = PdfTrueTypeFont("HarmonyOS Sans SC", 13.0, PdfFontStyle.Regular, True)
contentBrush = PdfBrushes.get_Black()
# Draw the title on the page
titleText = "Brief Introduction to Cloud Services"
titleSize = titleFont.MeasureString(titleText)
page.Canvas.DrawString(titleText, titleFont, titleBrush, PointF(0.0, 30.0))
# Draw the body text on the page
contentText = ("Cloud computing is a service model where computing resources are provided over the internet on a pay-as-you-go basis. "
"It is a type of infrastructure-as-a-service (IaaS), platform-as-a-service (PaaS), and software-as-a-service (SaaS) model. "
"Cloud computing is typically offered througha subscription-based model, where users pay for access to the cloud resources on a monthly, yearly, or other basis.")
# Set the string format of the body text
contentFormat = PdfStringFormat()
contentFormat.Alignment = PdfTextAlignment.Justify
contentFormat.LineSpacing = 20.0
# Create a TextWidget object with the body text and apply the string format
textWidget = PdfTextWidget(contentText, contentFont, contentBrush)
textWidget.StringFormat = contentFormat
# Create a TextLayout object and set the layout options
textLayout = PdfTextLayout()
textLayout.Layout = PdfLayoutType.Paginate
textLayout.Break = PdfLayoutBreakType.FitPage
# Draw the TextWidget on the page
rect = RectangleF(PointF(0.0, titleSize.Height + 50.0), page.Canvas.ClientSize)
textWidget.Draw(page, rect, textLayout)
# Save the PDF document to a Stream object
pdfStream = Stream()
pdf.SaveToStream(pdfStream)
# Convert the Stream object to a bytes object
pdfBytes = pdfStream.ToArray()
# Convert the Stream object to a bytearray object
pdfBytearray = bytearray(pdfStream.ToArray())
# Write the byte stream to a file
with open("output/PDFBytearray.pdf", "wb") as f:
f.write(pdfBytearray)

Load a PDF Document from Byte Streams
Developers can use a bytes object of a PDF file to create a stream and load it using the PdfDocument.LoadFromStream() method. Once the PDF document is loaded, various operations such as reading, modifying, and converting the PDF can be performed. The following is an example of the steps:
- Create a bytes object with a PDF file.
- Create a Stream object using the bytes object.
- Load the Stream object as a PDF document using PdfDocument.LoadFromStream() method.
- Extract the text from the first page of the document and print the text.
- Python
from spire.pdf import *
# Create a byte array from a PDF file
with open("Sample.pdf", "rb") as f:
byteData = f.read()
# Create a Stream object from the byte array
stream = Stream(byteData)
# Load the Stream object as a PDF document
pdf = PdfDocument(stream)
# Get the text from the first page
page = pdf.Pages.get_Item(0)
textExtractor = PdfTextExtractor(page)
extractOptions = PdfTextExtractOptions()
extractOptions.IsExtractAllText = True
text = textExtractor.ExtractText(extractOptions)
# Print the text
print(text)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Adding page numbers to a PDF enhances its organization and readability, making it easier for readers to navigate the document. Whether for reports, manuals, or e-books, page numbers provide a professional touch and help maintain the flow of information. This process involves determining the placement, alignment, and style of the numbers within the footer or header.
In this article, you will learn how to add page numbers to the PDF footer using Spire.PDF for Python.
- Add Left-Aligned Page Numbers to PDF Footer
- Add Center-Aligned Page Numbers to PDF Footer
- Add Right-Aligned Page Numbers to PDF Footer
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
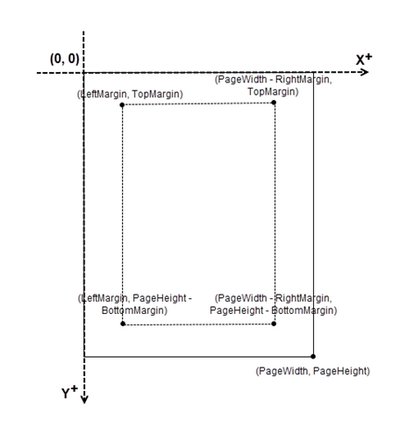
Coordinate System in PDF
When using Spire.PDF for Python to modify a PDF document, the coordinate system's origin is at the top-left corner of the page. The x-axis extends to the right, while the y-axis extends downward.
Page numbers are usually positioned in the header or footer. Thus, it's important to consider the page size and margins when determining the placement of the page numbers.
Classes and Methods for Creating Page Numbers
Spire.PDF for Python provides the PdfPageNumberField and PdfPageCountField classes to retrieve the current page number and total page count. These can be merged into a single PdfCompositeField that formats the output as "Page X of Y", where X represents the current page number and Y indicates the total number of pages.
To position the PdfCompositeField on the page, use the Location property, and render it with the Draw() method.
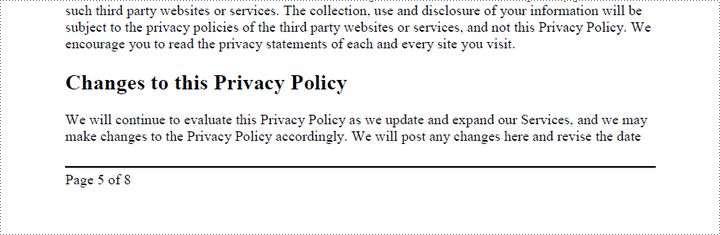
Add Left-Aligned Page Numbers to PDF Footer
To add left-aligned page numbers in the footer, you need to consider the left and bottom page margins as well as the page height. For example, you can use coordinates such as (LeftMargin, PageHeight – BottomMargin + SmallNumber). This ensures that the page numbers align with the left side of the text while keeping a comfortable distance from both the content and the edges of the page.
The steps to add left-aligned page numbers to PDF footer are as follows:
- Create a PdfDocument object.
- Load a PDF file from a specified path.
- Create a PdfPageNumberField object and a PdfPageCountField object.
- Create a PdfCompositeField object to combine page count field and page number field in a single string.
- Set the position of the composite field through PdfCompositeField.Location property to ensure the page number aligns with the left side of the text.
- Iterate through the pages in the document, and draw the composite field on each page at the specified location.
- Save the document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Privacy Policy.pdf")
# Create font, brush and pen
font = PdfTrueTypeFont("Times New Roman", 12.0, PdfFontStyle.Regular, True)
brush = PdfBrushes.get_Black()
pen = PdfPen(brush, 1.0)
# Create a PdfPageNumberField object and a PdfPageCountField object
pageNumberField = PdfPageNumberField()
pageCountField = PdfPageCountField()
# Create a PdfCompositeField object to combine page count field and page number field in a single string
compositeField = PdfCompositeField(font, brush, "Page {0} of {1}", [pageNumberField, pageCountField])
# Get the page size
pageSize = doc.Pages[0].Size
# Specify the blank areas around the page
leftMargin = 54.0
rightMargin = 54.0
bottomMargin = 72.0
# Set the location of the composite field
compositeField.Location = PointF(leftMargin, pageSize.Height - bottomMargin + 18.0)
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Draw a line at the specified position
page.Canvas.DrawLine(pen, leftMargin, pageSize.Height - bottomMargin + 15.0, pageSize.Width - rightMargin, pageSize.Height - bottomMargin + 15.0)
# Draw the composite field on the page
compositeField.Draw(page.Canvas, 0.0, 0.0)
# Save to a different PDF file
doc.SaveToFile("Output/LeftAlignedPageNumbers.pdf")
# Dispose resources
doc.Dispose()
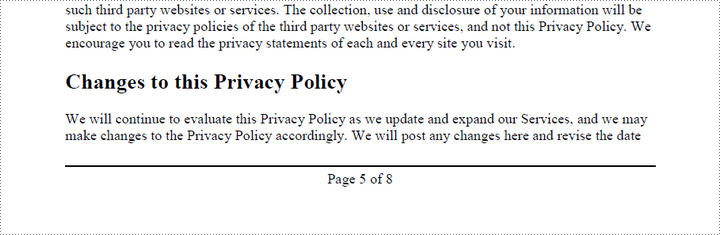
Add Center-Aligned Page Numbers to PDF Footer
To position the page number in the center of the footer, you first need to measure the width of the page number itself. Once you have this measurement, you can calculate the appropriate X coordinate by using the formula (PageWidth - PageNumberWidth) / 2. This ensures the page number is horizontally centered within the footer.
The steps to add center-aligned page numbers to PDF footer are as follows:
- Create a PdfDocument object.
- Load a PDF file from a specified path.
- Create a PdfPageNumberField object and a PdfPageCountField object.
- Create a PdfCompositeField object to combine page count field and page number field in a single string.
- Set the position of the composite field through PdfCompositeField.Location property to ensure the page number is perfectly centered in the footer.
- Iterate through the pages in the document, and draw the composite field on each page at the specified location.
- Save the document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Privacy Policy.pdf")
# Create font, brush and pen
font = PdfTrueTypeFont("Times New Roman", 12.0, PdfFontStyle.Regular, True)
brush = PdfBrushes.get_Black()
pen = PdfPen(brush, 1.0)
# Specify the blank margins around the page
leftMargin = 54.0
rightMargin = 54.0
bottomMargin = 72.0
# Create a PdfPageNumberField object and a PdfPageCountField object
pageNumberField = PdfPageNumberField()
pageCountField = PdfPageCountField()
# Create a PdfCompositeField object to combine page count field and page number field in a single field
compositeField = PdfCompositeField(font, brush, "Page {0} of {1}", [pageNumberField, pageCountField])
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Get the page size
pageSize = doc.Pages[i].Size
# Draw a line at the specified position
page.Canvas.DrawLine(pen, leftMargin, pageSize.Height - bottomMargin + 15.0, pageSize.Width - rightMargin, pageSize.Height - bottomMargin + 15.0)
# Measure the size the "Page X of Y"
pageNumberSize = font.MeasureString("Page {} of {}".format(i + 1, doc.Pages.Count))
# Set the location of the composite field
compositeField.Location = PointF((pageSize.Width - pageNumberSize.Width)/2, pageSize.Height - bottomMargin + 18.0)
# Draw the composite field on the page
compositeField.Draw(page.Canvas, 0.0, 0.0)
# Save to a different PDF file
doc.SaveToFile("Output/CenterAlignedPageNumbers.pdf")
# Dispose resources
doc.Dispose()
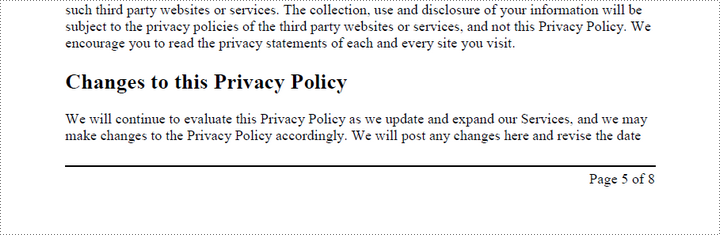
Add Right-Aligned Page Numbers to PDF Footer
To add a right-aligned page number in the footer, measure the width of the page number. Then, calculate the X coordinate using the formula PageWidth - PageNumberWidth - RightMargin. This ensures that the page number aligns with the right side of the text.
The following are the steps to add right-aligned page numbers to PDF footer:
- Create a PdfDocument object.
- Load a PDF file from a specified path.
- Create a PdfPageNumberField object and a PdfPageCountField object.
- Create a PdfCompositeField object to combine page count field and page number field in a single string.
- Set the position of the composite field through PdfCompositeField.Location property to ensure the page number aligns with the right side of the text.
- Iterate through the pages in the document, and draw the composite field on each page at the specified location.
- Save the document to a different PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Privacy Policy.pdf")
# Create font, brush and pen
font = PdfTrueTypeFont("Times New Roman", 12.0, PdfFontStyle.Regular, True)
brush = PdfBrushes.get_Black()
pen = PdfPen(brush, 1.0)
# Specify the blank margins around the page
leftMargin = 54.0
rightMargin = 54.0
bottomMargin = 72.0
# Create a PdfPageNumberField object and a PdfPageCountField object
pageNumberField = PdfPageNumberField()
pageCountField = PdfPageCountField()
# Create a PdfCompositeField object to combine page count field and page number field in a single string
compositeField = PdfCompositeField(font, brush, "Page {0} of {1}", [pageNumberField, pageCountField])
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Get the page size
pageSize = doc.Pages[i].Size
# Draw a line at the specified position
page.Canvas.DrawLine(pen, leftMargin, pageSize.Height - bottomMargin + 15.0, pageSize.Width - rightMargin, pageSize.Height - bottomMargin + 15.0)
# Measure the size the "Page X of Y"
pageNumberSize = font.MeasureString("Page {} of {}".format(i + 1, doc.Pages.Count))
# Set the location of the composite field
compositeField.Location = PointF(pageSize.Width - pageNumberSize.Width - rightMargin, pageSize.Height - bottomMargin + 18.0)
# Draw the composite field on the page
compositeField.Draw(page.Canvas, 0.0, 0.0)
# Save to a different PDF file
doc.SaveToFile("Output/RightAlignedPageNumbers.pdf")
# Dispose resources
doc.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Interactive forms in PDFs are valuable tools that allow users to fill in information, complete surveys, or sign documents electronically. However, these forms can also add layers of complexity to a PDF, impacting both file size and the overall user experience. When forms are no longer needed, or when a document needs to be simplified for distribution or archiving, removing these interactive elements can be beneficial. In this article, we will demonstrate how to remove forms from a PDF document in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
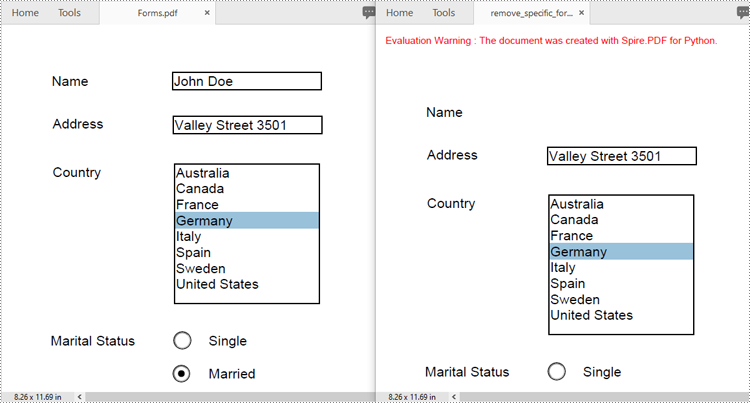
Remove a Specific Form from a PDF Document in Python
Spire.PDF for Python allows you to remove specific form fields from a PDF file by using either the indexes or the names of the form fields. The detailed steps are as follows.
- Create an instance of the PdfDocument class.
- Load a PDF document containing form fields using the PdfDocument.LoadFromFile() method.
- Get the form of the document using the PdfDocument.Form property.
- Get the form field collection using the PdfFormWidget.FieldsWidget property.
- Remove a specific form field by its index using the PdfFormFieldWidgetCollection.RemoveAt(index) method. Or retrieve a form field by its name using the PdfFormFieldWidgetCollection[name] property, and then remove it using the PdfFormFieldWidgetCollection.Remove(field) method.
- Save the resulting document using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an instance of the PdfDocument class
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Forms.pdf")
# Get the form of the document
pdfForm = doc.Form
formWidget = PdfFormWidget(pdfForm)
# Get the form field collection
field_collection = formWidget.FieldsWidget
# Remove a specific form field by its index
field_collection.RemoveAt(0)
# Or remove a specific form field by its name
# text_box = field_collection["Name"]
# field_collection.Remove(text_box)
# Save the resulting document
doc.SaveToFile("remove_specific_form.pdf")
doc.Close()
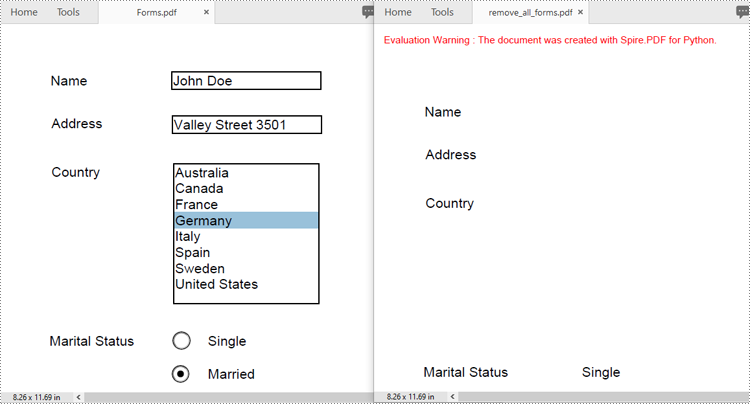
Remove All Forms from a PDF Document in Python
To remove all form fields from a PDF document, you need to iterate through the form field collection, and then remove each form field from the collection using the PdfFormFieldWidgetCollection.RemoveAt(index) method. The detailed steps are as follows.
- Create an instance of the PdfDocument class.
- Load a PDF document containing form fields using the PdfDocument.LoadFromFile() method.
- Get the form of the document using the PdfDocument.Form property.
- Get the form field collection using the PdfFormWidget.FieldsWidget property.
- Iterate through all form fields in the collection.
- Remove each form field from the collection using the PdfFormFieldWidgetCollection.RemoveAt(index) method.
- Save the resulting document using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an instance of the PdfDocument class
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("Forms.pdf")
# Get the form of the document
pdfForm = doc.Form
formWidget = PdfFormWidget(pdfForm)
# Get the form field collection
field_collection = formWidget.FieldsWidget
# Check if there are any form fields in the collection
if field_collection.Count > 0:
# Iterate through all form fields in the collection
for i in range(field_collection.Count - 1, -1, -1):
# Remove the current form field from the collection
field_collection.RemoveAt(i)
# Save the resulting document
doc.SaveToFile("remove_all_forms.pdf")
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
