Spire.XLS for C++ 15.5.0 supports setting page size when converting Excel to PDF
We're pleased to announce the release of Spire.XLS for C++ 15.5.0. This release adds a list of new features, such as supports setting page size during Excel to PDF conversion, embedding images into cells, grouping shapes, and enabling revision mode. Details are shown below.
Here is a list of changes made in this release
| Category | ID | Description |
| Adjustment | - | Upgrades SkiaSharp->3.116.1 |
| New feature | - | Supports setting page size when converting Excel to PDF.
intrusive_ptr workbook = new Workbook(); intrusive_ptr sheet = workbook->GetWorksheets()->Add(L""0""); intrusive_ptr a1 = sheet->GetRange(L""A1""); a1->SetValue(L""taatat""); sheet->GetPageSetup()->SetPaperSize(PaperSizeType::PaperA0); workbook->SaveToFile(outputFile.c_str(), ExcelVersion::Version2013); workbook->Dispose(); |
| New feature | - | Supports grouping Shapes.
intrusive_ptr book = new Workbook(); book->GetWorksheets()->Clear(); intrusive_ptr sheet = book->GetWorksheets()->Add(L""0""); intrusive_ptr shape1 = sheet->GetPrstGeomShapes()->AddPrstGeomShape(1, 3, 50, 50, PrstGeomShapeType::RoundRect); intrusive_ptr shape2 = sheet->GetPrstGeomShapes()->AddPrstGeomShape(5, 3, 50, 50, PrstGeomShapeType::Triangle); wcout << sheet->GetName() << endl; intrusive_ptr groupShapeCollection = sheet->GetGroupShapeCollection(); vector> shapes; shapes.push_back(shape1); shapes.push_back(shape2); groupShapeCollection->Group(shapes); book->SaveToFile(outputFile.c_str(), ExcelVersion::Version2013); book->Dispose(); |
| New feature | - | Supports retrieving all shapes in an Excel document.
intrusive_ptr book = new Workbook();
book->LoadFromFile(inputFile.c_str());
intrusive_ptr sheet = dynamic_pointer_cast(book->GetWorksheets()->Get(0));
std::vector> images;
for (int i = 0; i < sheet->GetShapes()->GetCount(); ++i)
{
intrusive_ptr shape = dynamic_pointer_cast(sheet->GetShapes()->Get(i));
intrusive_ptr image = shape->SaveToImage();
shape->SaveToImage((outputFile + L""Bug_out_"" + std::to_wstring(i) + L"".png"").c_str());
}
|
| New feature | - | Supports enabling revision mode.
intrusive_ptr workbook = new Workbook(); workbook->LoadFromFile(inputFile.c_str()); workbook->TrackedChanges(true); workbook->SaveToFile(outputFile.c_str(), ExcelVersion::Version2013); |
| New feature | - | Supports embedding images into cells.
intrusive_ptr workbook = new Workbook(); workbook->LoadFromFile(inputFile.c_str()); intrusive_ptr sheet = dynamic_pointer_cast(workbook->GetWorksheets()->Get(0)); intrusive_ptr range = dynamic_pointer_cast(sheet->GetRange(L""D1"")); intrusive_ptr fs = new Stream(inputFile_Img.c_str()); range->InsertOrUpdateCellImage(fs, true); workbook->SaveToFile(outputFile.c_str(), ExcelVersion::Version2013); workbook->Dispose(); |
| New feature | - | Supports grouping PivotTables.
intrusive_ptr workbook(new Workbook()); workbook->LoadFromFile(inputFile.c_str()); intrusive_ptr pivotSheet = workbook->GetWorksheets()->Get(0); intrusive_ptr pivot = dynamic_pointer_cast(pivotSheet->GetPivotTables()->Get(0)); intrusive_ptr dateBaseField = pivot->GetPivotFields()->Get(L""number""); dateBaseField->CreateGroup(3000, 3800, 1); pivot->CalculateData(); workbook->SaveToFile(outputFile.c_str()); |
Spire.XLS for Python 15.5.0 supports grouping Shapes
We're pleased to announce the release of Spire.XLS for Python 15.5.0. This version supports grouping Shapes. Besides, some known bugs are fixed successfully, such as the issue where saving a chart to an image caused the program to report a "SpireException: Arg_InvalidCastException" error. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREXLS-4191 | Supports grouping Shapes.
workbook = Workbook() workbook.LoadFromFile(inputFile) worksheet = workbook.Worksheets[0] shape1 = worksheet.PrstGeomShapes[0] shape2 = worksheet.PrstGeomShapes[1] groupShapeCollection = worksheet.GetGroupShapeCollection() groupShapeCollection.Group([shape1, shape2]) workbook.SaveToFile(outputFile, ExcelVersion.Version2013) workbook.Dispose() |
| New feature | SPIREXLS-4460 | Supports replacing the font.
wb = Workbook()
wb.LoadFromFile(inputFile)
sheet = wb.Worksheets[0]
# Create a cell style and set the color
style = wb.Styles.Add("Mystyle")
style.Font.FontName = "Arial"
style2 = wb.Styles.Add("Mystyle1")
style2.Font.FontName = "Times New Roman"
style3 = wb.Styles.Add("Mystyle2")
style3.Font.FontName = "Calibri"
wb.Worksheets[0].ReplaceAll("Brillux", style,"e-iceblue", style2)
wb.Worksheets[0].ReplaceAll("3342sdf",style, "text", style3)
wb.SaveToFile(outputFile)
wb.Dispose()
|
| New feature | SPIREXLS-4857 | Supported customizing PivotTable field names.
workbook = Workbook()
workbook.LoadFromFile(inputFile)
sheet = workbook.Worksheets.get_Item("Tabular Pivot")
table = sheet.PivotTables.get_Item(0)
table.PivotFields[1].CustomName = "fieldName1"
table.PivotFields[2].CustomName = "fieldName2"
table.RowFields[0].CustomName = "rowName"
table.ColumnFields[0].CustomName = "colName"
table.PivotFields[0].CustomName = "fieldName0"
table.DataFields[0].CustomName = "DataName"
table.CalculateData()
workbook.SaveToFile(outputFile, ExcelVersion.Version2013)
workbook.Dispose()
|
| New feature | SPIREXLS-5254 | Supports enabling revision mode.
workbook = Workbook() workbook.LoadFromFile(inputFile) workbook.TrackedChanges(True); workbook.SaveToFile(outputFile, ExcelVersion.Version2013); workbook.Dispose() |
| New feature | SPIREXLS-5482 | Supports embedding images into cells.
workbook = Workbook() workbook.LoadFromFile(inputFile) sheet = workbook.Worksheets[0] sheet.Range["D1"].InsertOrUpdateCellImage(inputFile_Img,True) workbook.SaveToFile(outputFile,ExcelVersion.Version2013) workbook.Dispose() |
| Adjustment | / | Upgrades SkiaSharp->3.116.1. |
| Adjustment | / | Adding support for the Linux ARM platform. |
| Bug | SPIREXLS-5643 SPIREXLS-5677 | Fixes the issue where saving a chart to an image caused the program to report a "SpireException: Arg_InvalidCastException" error. |
| Bug | SPIREXLS-5755 | Fixes the issue where loading a specific XLSM document caused the program to report a "SpireException: Arg_NullReferenceException" error. |
| Bug | SPIREXLS-5783 | Fixes the issue where loading a specific XLSX document caused the program to report an "Arg_IndexOutOfRangeException" error. |
How to Convert TXT to Excel in C#

In data processing and management scenarios, efficiently transforming raw text (TXT) files into structured Excel spreadsheets is a common requirement. For developers who are automating reports or processing log files, converting TXT to Excel using C# streamlines data organization and analysis. This guide explores how to achieve this using Spire.XLS for .NET, a powerful library designed to handle Excel XLS or XLSX files without requiring Microsoft Office.
- Why Convert TXT to Excel Programmatically?
- How to Convert Text Files to Excel in C# (Step-by-Step Guide)
- Pro Tips for TXT to Excel Conversion
Why Convert TXT to Excel Programmatically?
Text files are simple but lack the analytical power of Excel. Key advantages of converting TXT to XLS or XLSX format include:
- Automation: Process large or recurring files without manual intervention.
- Data Structuring: Organize raw text into rows, columns, and sheets.
- Advanced Features: Leverage Excel formulas, charts, and pivot tables.
- Integration: Embed conversion feature into .NET applications or APIs.
How to Convert Text Files to Excel in C# (Step-by-Step Guide)
Install Spire.XLS for .NET
Spire.XLS for .NET is a professional Excel document processing component, provides efficient and convenient APIs that allow developers to achieve TXT to Excel conversion through simple code.
Before getting started, you can choose one of these methods to install the library:
Method 1: NuGet Package Manager
- Open your project in Visual Studio.
- Right-click on the project in the Solution Explorer and select "Manage NuGet Packages."
- Search for "Spire.XLS" and click "Install".
Method 2: Package Manager Console
- Go to "Tools > NuGet Package Manager > Package Manager Console."
- Run the following command in the console:
PM> Install-Package Spire.XLS
Method 3: Manual Installation with DLL Files
- Visit the Spire.XLS Download Page and get the latest version.
- Extract the files and then add the Spire.Xls.dll to your project.
Import a Text File into Excel Using C#
Follow the below steps to write the data in a txt file into an Excel worksheet:
- Read TXT File: use the File.ReadAllLines() method to read all lines in a text file and returns them as an array of strings.
- Parse each line:
- Use the string.Trim() method to remove the leading/trailing whitespaces.
- Use the string.Split() method to split the data based on specified delimiters.
- Add the split text data to a list.
- Create a Workbook instance and get a worksheet
- Write Data to specified cells:
- Iterate through the rows and columns in the list.
- Assign the data in the list to the corresponding Excel cells through the Worksheet.Range[].Value property.
- Save the Excel File.
Code Example:
- C#
using Spire.Xls;
using System.IO;
using System.Collections.Generic;
class TxtToExcelConverter
{
static void Main()
{
// Open a text file and read all lines in it
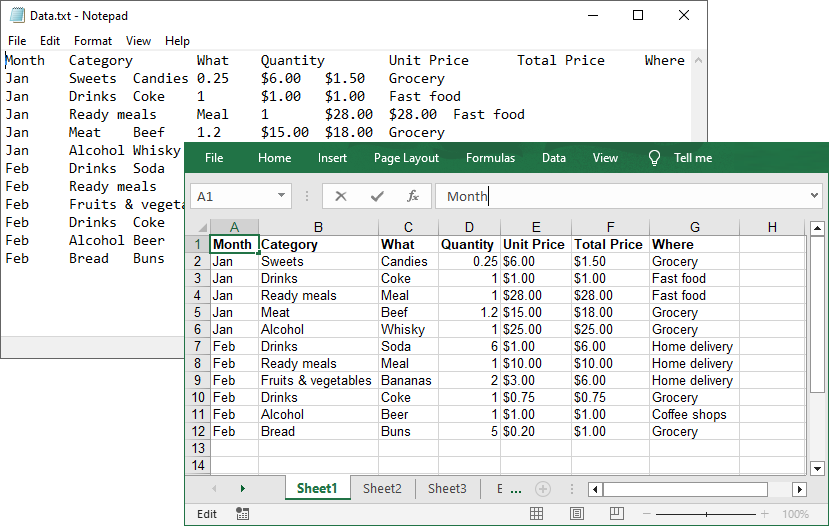
string[] lines = File.ReadAllLines("Data.txt");
// Create a list to store the data in text file
List data = new List();
// Split data into rows and columns and add to the list
foreach (string line in lines)
{
data.Add(line.Trim().Split('\t')); // Adjust delimiter as needed
}
// Create a Workbook object
Workbook workbook = new Workbook();
// Get the first worksheet
Worksheet sheet = workbook.Worksheets[0];
// Iterate through the rows and columns in the data list
for (int row = 0; row < data.Count; row++)
{
for (int col = 0; col < data[row].Length; col++)
{
// Write the text data in specified cells
sheet.Range[row + 1, col + 1].Value = data[row][col];
// Set the header row to Bold
sheet.Range[1, col + 1].Style.Font.IsBold = true;
}
}
// Autofit columns
sheet.AllocatedRange.AutoFitColumns();
// Save the Excel file
workbook.SaveToFile("TXTtoExcel.xlsx", ExcelVersion.Version2016);
workbook.Dispose();
}
}Result:
Pro Tips for TXT to Excel Conversion
- Handling Different Delimiters:
If your TXT file uses a different delimiter (e.g., space, comma, semicolon), modify the parameter of the Split(params char[] separator) method.
- Format Cells:
After a text file being converted to an Excel file, you can take advantage of the Spire.XLS library’s rich features to format cells, such as setting the background colors, adding cell borders, applying number formats, etc.
Conclusion
By following this step-by-step guide, you can efficiently transform unstructured text data into organized Excel spreadsheets, which is ideal for data analysis, reporting, and management. Remember to optimize your implementation for your specific delimiters and leverage Spire.XLS's advanced features for complex conversion scenarios.
Get a Free License
To fully experience the capabilities of Spire.XLS for .NET without any evaluation limitations, you can request a free 30-day trial license.
Spire.XLS for JavaScript 15.5.0 supports multiple new features
We are excited to announce the release of Spire.XLS for JavaScript 15.5.0. This version adds 19 new features, such as grouping Shapes, enabling revision mode, and embedding images into cells. Moreover, it also upgrades SkiaSharp and enhances the conversion from Shape to images. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - |
Supports 19 new features, including: Groupe Shapes. const workbook = wasmModule.Workbook.Create(); const sheet = workbook.Worksheets.get(0); const shape1 = sheet.PrstGeomShapes.AddPrstGeomShape(1, 3, 50, 50, spirexls.PrstGeomShapeType.RoundRect); const shape2 = sheet.PrstGeomShapes.AddPrstGeomShape(5, 3, 50, 50, spirexls.PrstGeomShapeType.Triangle); const groupShapeCollection = sheet.GroupShapeCollection; groupShapeCollection.Group([shape1, shape2]); workbook.SaveToFile(outputFileName,spirexls.ExcelVersion.Version2013); Enable revision mode. const workbook = wasmModule.Workbook.Create(); workbook.LoadFromFile(inputFileName); workbook.TrackedChanges = true; const outputFileName = "out.xlsx"; workbook.SaveToFile(outputFileName, spirexls.ExcelVersion.Version2013); Embed images into cells. const workbook = wasmModule.Workbook.Create();
workbook.LoadFromFile(inputFileName);
const params = {
fileName: imageName,
scale: true
}
const sheet = workbook.Worksheets.get(0);
sheet.Range.get("B1").InsertOrUpdateCellImage(params);
const outputFileName="out.xlsx";
workbook.SaveToFile(outputFileName);
|
| Adjustment | - | Upgrades SkiaSharp to version 3.116.1. |
| Bug | SPIREXLS-5726 | Fixes the issue that the text overflowed when converting Shape to images. |
Generate Word Documents from Templates in Java

In modern software development, generating dynamic Word documents from templates is a common requirement for applications that produce reports, contracts, invoices, or other business documents. Java developers seeking efficient solutions for document automation can leverage Spire.Doc for Java, a robust library for processing Word files without requiring Microsoft Office.
This guide explores how to use Spire.Doc for Java to create Word documents from templates. We will cover two key approaches: replacing text placeholders and modifying bookmark content.
- Java Libray for Creating Word Documents
- Generate a Word Document by Replacing Text Placeholders
- Generate a Word Document by Modifying Bookmark Content
- Conclusion
- FAQs
Java Library for Generating Word Documents
Spire.Doc for Java is a powerful library that enables developers to create, manipulate, and convert Word documents. It provides an intuitive API that allows for various operations, including the modification of text, images, and bookmarks in existing documents.
To get started, download the library from our official website and import it into your Java project. If you're using Maven, include the following dependency in your pom.xml file:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.7.0</version>
</dependency>
</dependencies>
Generate a Word Document by Replacing Text Placeholders
This method uses a template document containing marked placeholders (e.g., #name#, #date#) that are dynamically replaced with real data. Spire.Doc's Document.replace() method handles text substitutions efficiently, while additional APIs enable advanced replacements like inserting images at specified locations.
Steps to generate Word documents from templates by replacing text placeholders:
- Initialize Document: A new Document object is created to work with the Word file.
- Load the template: The template document with placeholders is loaded.
- Create replacement mappings: A HashMap is created to store placeholder-replacement pairs.
- Perform text replacement: The replace() method finds and replaces all instances of each placeholder.
- Handle image insertion: The custom replaceTextWithImage() method replaces a text placeholder with an image.
- Save the result: The modified document is saved to a specified path.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.documents.TextSelection;
import com.spire.doc.fields.DocPicture;
import com.spire.doc.fields.TextRange;
import java.util.HashMap;
import java.util.Map;
public class ReplaceTextPlaceholders {
public static void main(String[] args) {
// Initialize a new Document object
Document document = new Document();
// Load the template Word file
document.loadFromFile("C:\\Users\\Administrator\\Desktop\\template.docx");
// Map to hold text placeholders and their replacements
Map<String, String> replaceDict = new HashMap<>();
replaceDict.put("#name#", "John Doe");
replaceDict.put("#gender#", "Male");
replaceDict.put("#birthdate#", "January 15, 1990");
replaceDict.put("#address#", "123 Main Street");
replaceDict.put("#city#", "Springfield");
replaceDict.put("#state#", "Illinois");
replaceDict.put("#postal#", "62701");
replaceDict.put("#country#", "United States");
// Replace placeholders in the document with corresponding values
for (Map.Entry<String, String> entry : replaceDict.entrySet()) {
document.replace(entry.getKey(), entry.getValue(), true, true);
}
// Path to the image file
String imagePath = "C:\\Users\\Administrator\\Desktop\\portrait.png";
// Replace the placeholder “#photo#” with an image
replaceTextWithImage(document, "#photo#", imagePath);
// Save the modified document
document.saveToFile("output/ReplacePlaceholders.docx", FileFormat.Docx);
// Release resources
document.dispose();
}
// Method to replace a placeholder in the document with an image
static void replaceTextWithImage(Document document, String stringToReplace, String imagePath) {
// Load the image from the specified path
DocPicture pic = new DocPicture(document);
pic.loadImage(imagePath);
// Find the placeholder in the document
TextSelection selection = document.findString(stringToReplace, false, true);
// Get the range of the found text
TextRange range = selection.getAsOneRange();
int index = range.getOwnerParagraph().getChildObjects().indexOf(range);
// Insert the image and remove the placeholder text
range.getOwnerParagraph().getChildObjects().insert(index, pic);
range.getOwnerParagraph().getChildObjects().remove(range);
}
}Output:

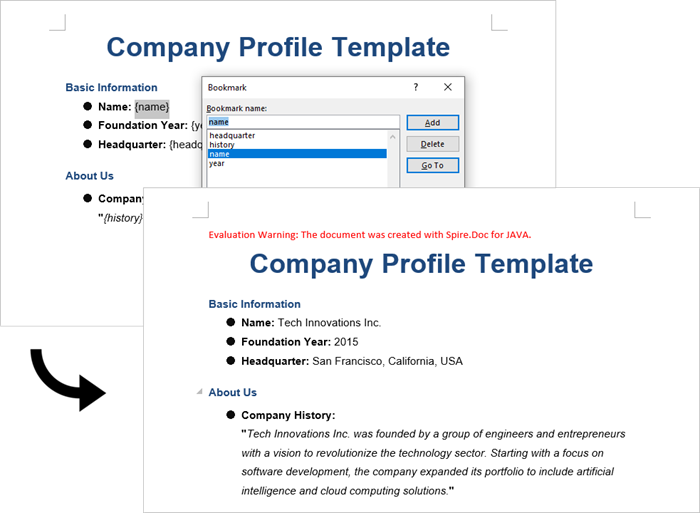
Generate a Word Document by Modifying Bookmark Content
This approach uses Word bookmarks to identify locations in the document where content should be inserted or modified. The BookmarksNavigator class in Spire.Doc streamlines the process by enabling direct access to bookmarks, allowing targeted content replacement while automatically preserving the document's original structure and formatting.
Steps to generate Word documents from templates by modifying bookmark content:
- Initialize Document: A new Document object is initialized.
- Load the template: The template document with predefined bookmarks is loaded.
- Set up replacements: A HashMap is created to map bookmark names to their replacement values.
- Navigate to bookmarks: A BookmarksNavigator is instantiated to navigate through bookmarks in the document.
- Replace content: The replaceBookmarkContent() method updates the bookmark's content.
- Save the result: The modified document is saved to a specified path.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import java.util.HashMap;
import java.util.Map;
public class ModifyBookmarkContent {
public static void main(String[] args) {
// Initialize a new Document object
Document document = new Document();
// Load the template Word file
document.loadFromFile("C:\\Users\\Administrator\\Desktop\\template.docx");
// Define bookmark names and their replacement values
Map<String, String> replaceDict = new HashMap<>();
replaceDict.put("name", "Tech Innovations Inc.");
replaceDict.put("year", "2015");
replaceDict.put("headquarter", "San Francisco, California, USA");
replaceDict.put("history", "Tech Innovations Inc. was founded by a group of engineers and " +
"entrepreneurs with a vision to revolutionize the technology sector. Starting " +
"with a focus on software development, the company expanded its portfolio to " +
"include artificial intelligence and cloud computing solutions.");
// Create a BookmarksNavigator to manage bookmarks in the document
BookmarksNavigator bookmarkNavigator = new BookmarksNavigator(document);
// Iterate through the bookmarks
for (Map.Entry<String, String> entry : replaceDict.entrySet()) {
// Navigate to a specific bookmark
bookmarkNavigator.moveToBookmark(entry.getKey());
// Replace content
bookmarkNavigator.replaceBookmarkContent(entry.getValue(), true);
}
// Save the modified document
document.saveToFile("output/ReplaceBookmarkContent.docx", FileFormat.Docx);
// Release resources
document.dispose();
}
}Output:
Conclusion
Both methods provide effective ways to generate documents from templates, but they suit different scenarios:
Text Replacement Method is best when:
- You need simple text substitutions
- You need to insert images at specific locations
- You want to replace text anywhere in the document (not just specific locations)
Bookmark Method is preferable when:
- You're working with complex documents where precise location matters
- You need to replace larger sections of content or paragraphs
- You want to preserve bookmarks for future updates
Spire.Doc also offers Mail Merge capabilities, enabling high-volume document generation from templates. This feature excels at producing personalized documents like mass letters or reports by merging template fields with external data sources like databases.
FAQs
Q1: Can I convert the generated Word document to PDF?
A: Yes, Spire.Doc for Java supports converting documents to PDF and other formats. Simply use saveToFile() with FileFormat.PDF.
Q2: How can I handle complex formatting in generated documents?
A: Prepare your template with all required formatting in Word, then use placeholders or bookmarks in locations where dynamic content should appear. The formatting around these markers will be preserved.
Q3: What's the difference between mail merge and text replacement?
A: Mail merge is specifically designed for merging database-like data with documents and supports features like repeating sections for records. Text replacement is simpler but doesn't handle tabular data as elegantly.
Get a Free License
To fully experience the capabilities of Spire.Doc for Java without any evaluation limitations, you can request a free 30-day trial license.
How to Generate Barcode in Python (Step-by-Step Guide)

Barcodes are essential in inventory management, retail systems, logistics, and many other data-driven fields. For Python developers, generating barcodes in Python can be complex—especially when working with multiple formats or large-scale automation. That’s why a reliable Python barcode generator library is necessary to ensure flexible and efficient barcode creation, with support for various barcode types and batch processing.
This article provides an accurate and efficient approach to generating barcodes in Python using Spire.Barcode for Python.
- Get Started with Spire.Barcode for Python
- How to Generate Barcode in Python
- Supported Barcode Types
- Frequently Asked Questions
Get Started with Spire.Barcode for Python
Why Choose Spire.Barcode?
Spire.Barcode for Python is a professional and user-friendly Python Barcode API designed for developers who want to add barcode generation or reading features to their Python applications. Here’s why it stands out:
- Supports multiple barcode symbologies including Code 128, QR Code, EAN-13, UPC, and more
- High-quality image output with complete customization settings
- Comprehensive and easy-to-integrate API
- No need for third-party dependencies
- One library to generate and scan barcodes
Installation and Importing
To install Spire.Barcode for Python, simply run:
pip install spire.barcodeYou can also install Free Spire.Barcode for Python for simple barcode generating tasks:
pip install spire.barcode.freeHow to Generate Barcode in Python
To generate a barcode in Python, you typically need to define the barcode type (such as Code 128 or QR Code) and the content to encode. Using a library like Spire.Barcode, you can configure them in just a few lines of code.
Key Classes and Methods:
- BarcodeSettings: Defines properties such as type, data, color, text, etc.
- BarCodeGenerator: Generates barcode images based on settings.
- GenerateImage(): Outputs barcode as an image stream.
Step 1: Import the Required Modules
To start coding your Python barcode generator, import the necessary classes.
- Python
from spire.barcode import BarcodeSettings, BarCodeType, BarCodeGenerator, Code128SetMode, FontStyle, ColorStep2: Configure Barcode Settings
Create a BarcodeSettings object and define barcode properties:
- Python
# Create a BarcodeSettings object
barcodeSettings = BarcodeSettings()
# Set the barcode type
barcodeSettings.Type = BarCodeType.Code128
# Set the barcode data
barcodeSettings.Data = "ABC123456789"
# Set the barcode code128 set mode
barcodeSettings.Code128SetMode = Code128SetMode.Auto
# Choose the data display position
barcodeSettings.ShowTextOnBottom = True
# Set the bottom text and style
barcodeSettings.BottomText = "Code 128 Example"
barcodeSettings.SetTextFont("Arial", 12.0, FontStyle.Regular)
barcodeSettings.ShowBottomText = True
# Set the background color
barcodeSettings.BackColor = Color.get_Beige()Step 3: Generate the Barcode Image
Create a BarCodeGenerator object using the configured BarcodeSettings, then generate the barcode image as a stream and save it to a local file:
- Python
# Create a BarCodeGenerator object
barcodeGenerator = BarCodeGenerator(barcodeSettings)
# Generate the barcode image
barcodeImage = barcodeGenerator.GenerateImage()
# Save the image
with open("output/Code 128.png", "wb") as fp:
fp.write(barcodeImage)The generated barcode:

This script allows you to generate a Code 128 barcode and save it as an image. Just replace the BarCodeType and Data value to customize.
Generating Other Barcode Types
Spire.Barcode for Python supports a wide range of barcode symbologies, including the most commonly used types such as Code 39, UPC, QR Code, and EAN-13. This ensures developers can generate barcodes for various applications with compatibility and ease.
Barcode Type Support Overview
| Barcode Category | Barcode Types (Examples) | Free Version | Paid Version |
| 1D Linear Barcodes | Codabar, Code11, Code25, Interleaved25, Code39, Code39Extended, Code93, Code93Extended, Code128, EAN8, EAN13, EAN128, EAN14, UPCA, UPCE, MSI, PostNet, Planet, SCC14, SSCC18, ITF14, ITF6, PZN, OPC | ✅ (Partial) | ✅ (All) |
| 2D Barcodes | QRCode, DataMatrix, Pdf417, Pdf417Macro, Aztec, MicroQR | ✅ (QRCode only) | ✅ (All) |
| Stacked/Composite Codes | RSS14, RSS14Truncated, RSSLimited, RSSExpanded | ❌ | ✅ |
| Postal Barcodes | USPS, SwissPostParcel, DeutschePostIdentcode, DeutschePostLeitcode, RoyalMail4State, SingaporePost4State | ❌ | ✅ |
Advanced: Generate Barcodes in Bulk
You can easily generate multiple barcodes in bulk using Spire.Barcode for Python. This is especially useful for inventory management, batch labeling, or automated systems where each item requires a unique barcode.
Code Example
- Python
# Create a list of barcode data
data = ["Barcode 1", "Barcode 2", "Barcode 3"]
# Loop through the data to generate barcodes
for barcode_data in data:
# Create a BarcodeSettings object
settings = BarcodeSettings()
# Set the barcode type and data
settings.Type = BarCodeType.Code39
settings.Data = barcode_data
# Create a BarCodeGenerator object
generator = BarCodeGenerator(settings)
# Save the barcode image
barcode_stream = generator.GenerateImage()
with open(f"output/{barcode_data}.png", "wb") as file:
file.write(barcode_stream)This Python script generates and saves a barcode image for each entry in the list, streamlining barcode creation workflow.
Conclusion
Generating barcodes in Python is simple and efficient with Spire.Barcode for Python. Whether you’re creating a single Code 128 barcode or automating batch QR code generation, this robust and flexible library gives you the control and quality needed for professional barcode integration. From supporting various symbologies to delivering high-quality output with minimal code, this Python barcode generator is an excellent tool for developers across industries.
Frequently Asked Questions
Q: How to create a barcode in Python?
You can create a barcode using libraries like Spire.Barcode for Python, which supports a variety of symbologies like Code 128, QR Code, and more. Just install the package, configure barcode settings, and save the output image.
Q: How is barcode generated?
Barcodes are generated by encoding data into a visual pattern of bars or modules. With Python, this is done through barcode libraries like Spire.Barcode, which translate string input into a corresponding image.
Q: How to create a code generator in Python?
If you're referring to a barcode generator, define the barcode type (e.g., Code 128), provide the data, and use a library like Spire.Barcode to generate and save the image. You can automate this process using loops and functions.
Q: How to generate QR code by Python?
You can use Spire.Barcode for Python to generate QR codes quickly and efficiently. Here's a full example that creates a QR code with embedded data:
- Python
from spire.barcode import BarcodeSettings, BarCodeGenerator, BarCodeType
# Create a BarcodeSettings object
barcodeSettings = BarcodeSettings()
# Set the barcode type to QRCode
barcodeSettings.Type = BarCodeType.QRCode
# Set the barcode data
barcodeSettings.Data = "ABC123456"
# Generate the barcode
barcodeGenerator = BarCodeGenerator(barcodeSettings)
barcodeGenerator.GenerateImage()
with open("output/QRCode.png", "wb") as f:
f.write(barcodeGenerator.GenerateImage())Result:

This enables you to embed URLs, text, or IDs into scannable QR images.
See Also: How to Generate and Scan QR Codes with Python
Get a Free License
Spire.Barcode for Python offers a free trial license that removes limitations and watermarking. Get a free license today and explore the full capabilities of this powerful Python barcode library.
Edit PDF Using Python: A Practical Guide to PDF Modification

PDFs are widely used in reports, invoices, and digital forms due to their consistent formatting across platforms. However, their fixed layout makes editing difficult without specialized tools. For developers looking to edit PDF using Python, Spire.PDF for Python provides a comprehensive and easy-to-use solution. This Python PDF editor enables you to modify PDF files programmatically—changing text, replacing images, adding annotations, handling forms, and securing files—without relying on Adobe Acrobat or any external software.
In this article, we will explore how to use Spire.PDF for Python to programmatically edit PDFs in Python applications.
- Why Use Python and Spire.PDF to Edit PDF Documents?
- Getting Started with Spire.PDF for Python
- How to Edit an Existing PDF Using Spire.PDF for Python
- Frequently Asked Questions
Why Use Python and Spire.PDF to Edit PDF Documents?
Python is a highly versatile programming language that provides an excellent platform for automating and managing PDF documents. When it comes to edit PDF Python tasks, Spire.PDF for Python stands out as a comprehensive and easy-to-use solution for all your PDF manipulation needs.
Benefits of Using Python for PDF Editing
- Automation and Batch Processing: Streamline repetitive PDF editing tasks efficiently.
- Cost-Effective: Reduce manual work, saving time and resources when you Python-edit PDF files.
- Integration: Seamlessly incorporate PDF editing into existing Python-based systems and workflows.
Advantages of Spire.PDF for Python
Spire.PDF for Python is a standalone library that enables developers to create, read, edit, convert, and save PDF files without relying on external software. As a trusted Python PDF editor, it offers powerful features such as:
- Text and Image Editing
- Annotations and Bookmark Management
- Form Field Handling
- Security Settings (Encryption and Permissions)
- Conversion to Word, Excel, HTML, and Images
To learn more about these specific features, visit the Spire.PDF for Python tutorials.
With its intuitive API design, Spire.PDF makes it easier than ever to edit PDF files in Python quickly and effectively, ensuring a smooth development experience.
Getting Started with Spire.PDF for Python
Installation:
To install Spire.PDF for Python, simply run the following pip command:
pip install spire.pdf
Alternatively, you can install Free Spire.PDF for Python, a free version suitable for small projects, by running:
pip install spire.pdf.free
You can also download the library manually from the links.
Basic Setup Example:
The following example demonstrates how to create a simple PDF using Spire.PDF for Python:
- Python
from spire.pdf import PdfDocument, PdfFont, PdfBrushes, PdfFontFamily, PdfFontStyle
# Create a new PDF document
pdf = PdfDocument()
# Add a new page to the document
page = pdf.Pages.Add()
# Create a font
font = PdfFont(PdfFontFamily.TimesRoman, 28.0, PdfFontStyle.Bold)
# Create a brush
brush = PdfBrushes.get_Black()
# Draw the string using the font and brush
page.Canvas.DrawString("Hello, World", font, brush, 100.0, 100.0)
# Save the document
pdf.SaveToFile("output/NewPDF.pdf")
pdf.Close()
Result: The generated PDF displays the text "Hello, World" using Times Roman Bold.

With Spire.PDF installed, you're now ready to edit PDFs using Python. The sections below explain how to manipulate structure, content, security, and metadata.
How to Edit an Existing PDF Using Spire.PDF for Python
Spire.PDF for Python provides a simple yet powerful way to edit PDF using Python. With its intuitive API, developers can automate a wide range of PDF editing tasks including modifying document structure, page content, security settings, and properties. This section outlines the core categories of editing and their typical use cases.
Edit PDF Pages and Structure with Python
Structure editing lets you manipulate PDF page order, merge files, or insert/delete pages—ideal for document assembly workflows.
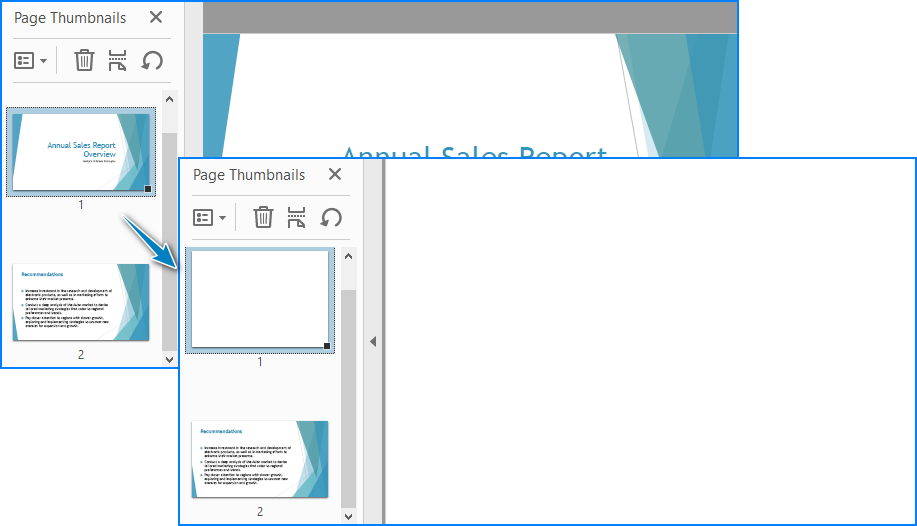
- Insert or Delete Pages
Use the Pages.Insert() and Pages.RemoveAt() methods of the PdfDocument class to insert or delete pages at specific positions.
Code Example
- Python
from spire.pdf import PdfDocument, PdfPageSize, PdfMargins, PdfPageRotateAngle
# Load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Insert and delete pages
# Insert at beginning
pdf.Pages.Insert(0, PdfPageSize.A4(), PdfMargins(50.0, 60.0), PdfPageRotateAngle.RotateAngle90)
# Delete second page
pdf.Pages.RemoveAt(1)
# Save the document
pdf.SaveToFile("output/InsertDeletePage.pdf")
pdf.Close()
Result:
- Merge Two PDF Files
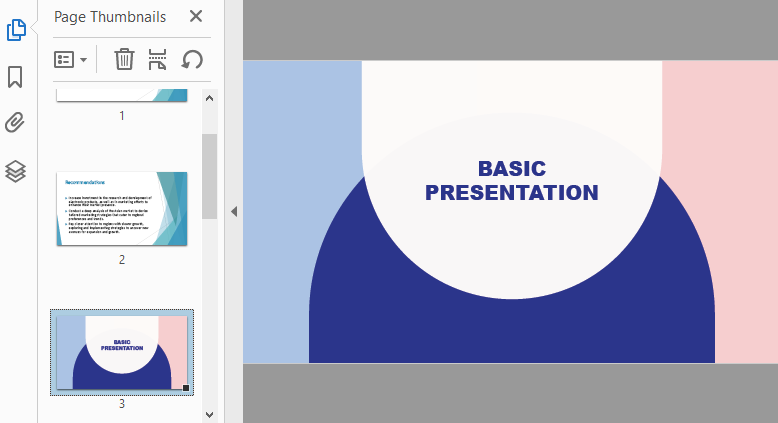
The AppendPage() method allows you to combine PDFs by inserting pages from one document into another.
Code Example
- Python
import os
from spire.pdf import PdfDocument
# Specify the PDF file path
pdfPath = "PDFs/"
# Read the PDF file names from the path and add them to a list
files = [pdfPath + file for file in os.listdir(pdfPath) if file.endswith(".pdf")]
# Load the first PDF file
pdf = PdfDocument()
pdf.LoadFromFile(files[0])
# Iterate through the other PDF files
for i in range(1, len(files)):
# Load the current PDF file
pdf2 = PdfDocument()
pdf2.LoadFromFile(files[i])
# Append the pages from the current PDF file to the first PDF file
pdf.AppendPage(pdf2)
# Save the merged PDF file
pdf.SaveToFile("output/MergePDFs.pdf")
pdf.Close()
Result:
You may also like: Splitting PDF Files with Python Code
Edit PDF Content with Python
As a Python PDF editor, Spire.PDF supports a variety of content-level operations, including modifying text, images, annotations, and interactive forms.
- Replace Text in a PDF
The PdfTextReplacer class can be used to find and replace text from a page. Note that precise replacement may require case and layout-aware handling.
Code Example
- Python
from spire.pdf import PdfDocument, PdfTextReplacer, ReplaceActionType, Color
# Load the PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Iterate through the pages
for i in range(pdf.Pages.Count):
page = pdf.Pages.get_Item(i)
# Create a PdfTextReplacer object
replacer = PdfTextReplacer(page)
# Set the replacement options
replacer.Options.ReplaceType = ReplaceActionType.IgnoreCase
# Replace the text
replacer.ReplaceAllText("drones", "ROBOTS", Color.get_Aqua()) # Setting the color is optional
# Save the merged PDF file
pdf.SaveToFile("output/ReplaceText.pdf")
pdf.Close()
Result:

- Replace Images in a PDF
Spire.PDF for Python provides the PdfImageHelper class to help you replace images in a PDF file with ease. By retrieving image information from a specific page, you can use the ReplaceImage() method to directly substitute the original image with a new one.
Code Example
- Python
from spire.pdf import PdfDocument, PdfImageHelper, PdfImage
# Load the PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Get a page
page = pdf.Pages.get_Item(0)
# Create a PdfImageHelper instance
imageHelper = PdfImageHelper()
# Get the image info of the first image on the page
imageInfo = imageHelper.GetImagesInfo(page)[0]
# Load a new image
newImage = PdfImage.FromFile("Image.png")
# Replace the image
imageHelper.ReplaceImage(imageInfo, newImage)
# Save the PDF file
pdf.SaveToFile("output/ReplaceImage.pdf")
pdf.Close()
Result:

- Add Comments or Notes
To add comments or notes with Python, use the PdfTextMarkupAnnotation class and add it to the page’s AnnotationsWidget collection.
Code Example
- Python
from spire.pdf import PdfDocument, PdfTextFinder, PdfTextMarkupAnnotation, PdfRGBColor, Color
# Load the PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Get a page
page = pdf.Pages.get_Item(0)
#Create a PdfTextFinder instance and set the options
finder = PdfTextFinder(page)
finder.Options.Parameter.IgnoreCase = False
finder.Options.Parameter.WholeWord = True
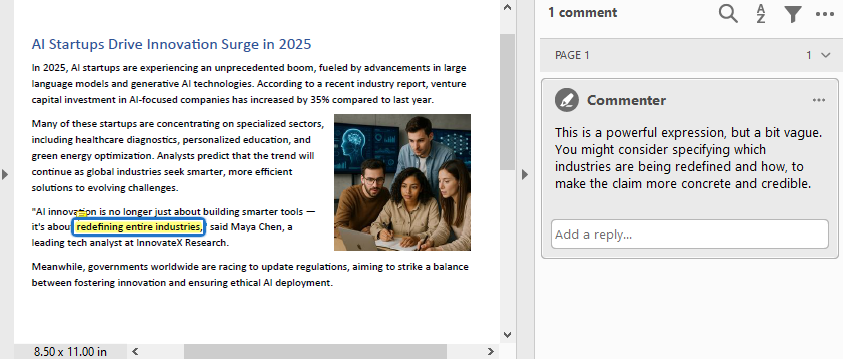
# Find the text to comment
text = finder.Find("redefining entire industries")[0]
# Get the bound of the text
bound = text.Bounds[0]
# Add comment
commentText = ("This is a powerful expression, but a bit vague. "
"You might consider specifying which industries are "
"being redefined and how, to make the claim more "
"concrete and credible.")
comment = PdfTextMarkupAnnotation("Commenter", commentText, bound)
comment.TextMarkupColor = PdfRGBColor(Color.get_Yellow())
page.AnnotationsWidget.Add(comment)
# Save the PDF file
pdf.SaveToFile("output/CommentNote.pdf")
pdf.Close()
Result:
- Edit or Read Form Fields
Spire.PDF for Python allows you to programmatically fill out and read form fields in a PDF document. By accessing the FieldsWidget property of a PdfFormWidget object, you can iterate through all interactive form elements, such as text boxes, combo boxes, and checkboxes, and update or extract their values.
Code Example
- Python
from spire.pdf import PdfDocument, PdfFormWidget, PdfComboBoxWidgetFieldWidget, PdfCheckBoxWidgetFieldWidget, PdfTextBoxFieldWidget
# Load the PDF file
pdf = PdfDocument()
pdf.LoadFromFile("EmployeeInformationForm.pdf")
forms = pdf.Form
formWidgets = PdfFormWidget(forms).FieldsWidget
# Fill the forms
for i in range(formWidgets.Count):
formField = formWidgets.get_Item(i)
if formField.Name == "FullName":
textBox = PdfTextBoxFieldWidget(formField)
textBox.Text = "Amanda Ray Thompson"
elif formField.Name == "DateOfBirth":
textBox = PdfTextBoxFieldWidget(formField)
textBox.Text = "01/01/1980"
elif formField.Name == "Gender":
comboBox = PdfComboBoxWidgetFieldWidget(formField)
comboBox.SelectedIndex = [ 1 ]
elif formField.Name == "Department":
formField.Value = "Human Resources"
elif formField.Name == "AgreeTerms":
checkBox = PdfCheckBoxWidgetFieldWidget(formField)
checkBox.Checked = True
# Read the forms
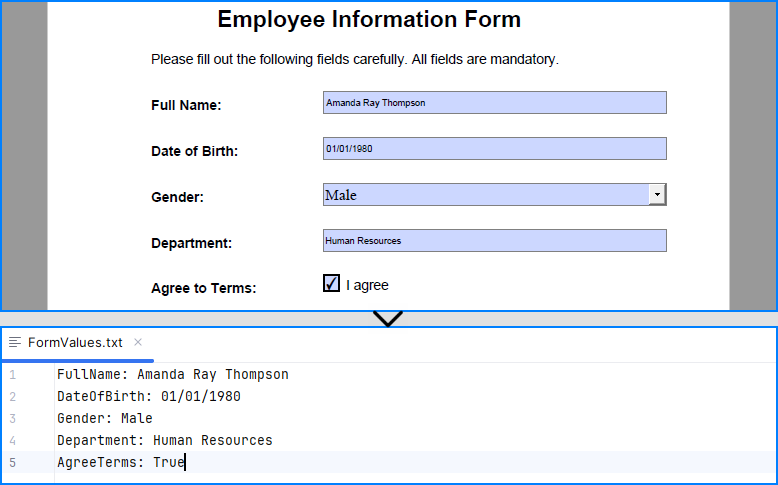
formValues = []
for i in range(formWidgets.Count):
formField = formWidgets.get_Item(i)
if isinstance(formField, PdfTextBoxFieldWidget):
formValues.append(formField.Name + ": " + formField.Text)
elif isinstance(formField, PdfComboBoxWidgetFieldWidget):
formValues.append(formField.Name + ": " + formField.SelectedValue)
elif isinstance(formField, PdfCheckBoxWidgetFieldWidget):
formValues.append(formField.Name + ": " + str(formField.Checked))
# Write the form values to a file
with open("output/FormValues.txt", "w") as file:
file.write("\n".join(formValues))
# Save the PDF file
pdf.SaveToFile("output/FilledForm.pdf")
pdf.Close()
Result:
Explore more: How to Insert Page Numbers to PDF Using Python
Manage PDF Security with Python
PDF security editing is essential when dealing with sensitive documents. Spire.PDF supports encryption, password protection, digital signature handling, and permission settings.
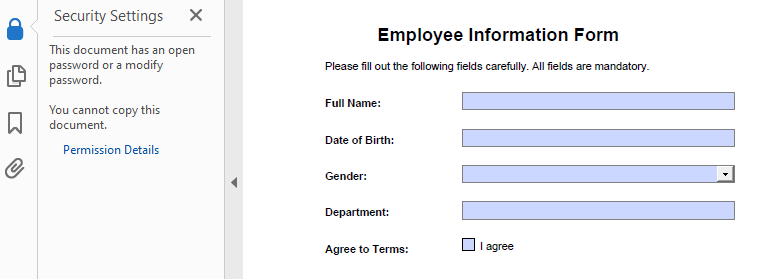
- Add a Password and Set Permissions
The Encrypt() method lets you secure a PDF with user/owner passwords and define allowed actions like printing or copying.
Code Example
- Python
from spire.pdf import PdfDocument, PdfEncryptionAlgorithm, PdfDocumentPrivilege, PdfPasswordSecurityPolicy
# Load the PDF file
pdf = PdfDocument()
pdf.LoadFromFile("EmployeeInformationForm.pdf")
# Create a PdfSecurityPolicy object and set the passwords and encryption algorithm
securityPolicy = PdfPasswordSecurityPolicy("userPSD", "ownerPSD")
securityPolicy.EncryptionAlgorithm = PdfEncryptionAlgorithm.AES_128
# Set the document privileges
pdfPrivileges = PdfDocumentPrivilege.ForbidAll()
pdfPrivileges.AllowPrint = True
pdfPrivileges.AllowFillFormFields = True
# Apply the document privileges
securityPolicy.DocumentPrivilege = pdfPrivileges
# Encrypt the PDF with the security policy
pdf.Encrypt(securityPolicy)
# Save the PDF file
pdf.SaveToFile("output/EncryptedForm.pdf")
pdf.Close()
Result
- Remove the Password from a PDF
To open a protected file, provide the user password when calling LoadFromFile(), use Decrypt() to decrypt the document, and save it again unprotected.
Code Example
- Python
from spire.pdf import PdfDocument
# Load the encrypted PDF file with the owner password
pdf = PdfDocument()
pdf.LoadFromFile("output/EncryptedForm.pdf", "ownerPSD")
# Decrypt the PDF file
pdf.Decrypt()
# Save the PDF file
pdf.SaveToFile("output/DecryptedForm.pdf")
pdf.Close()
Recommended for you: Use Python to Add and Remove Digital Signature in PDF
Edit PDF Properties with Python
Use Spire.PDF to read and edit PDF metadata and viewer preferences—key features for document presentation and organization.
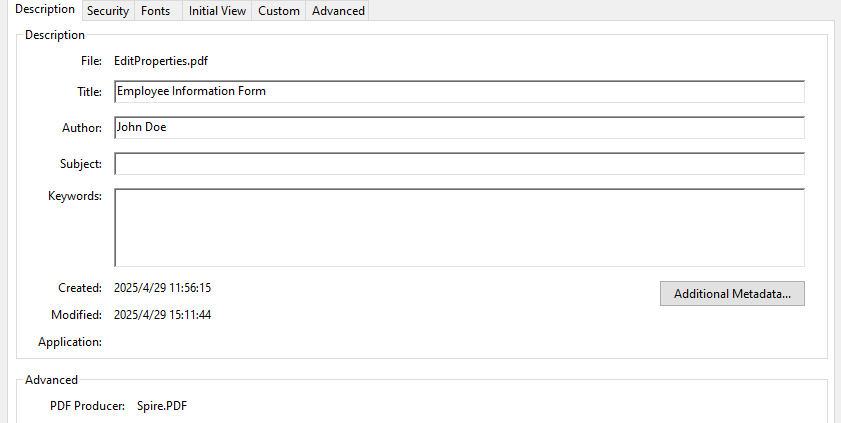
- Update Document Metadata
Update metadata such as title, author, or subject via the DocumentInformation property of the PDF document.
Code Example
- Python
from spire.pdf import PdfDocument
# Load the PDF file
pdf = PdfDocument()
pdf.LoadFromFile("EmployeeInformationForm.pdf")
# Set document metadata
pdf.DocumentInformation.Author = "John Doe"
pdf.DocumentInformation.Title = "Employee Information Form"
pdf.DocumentInformation.Producer = "Spire.PDF"
# Save the PDF file
pdf.SaveToFile("output/EditProperties.pdf")
pdf.Close()
Result:
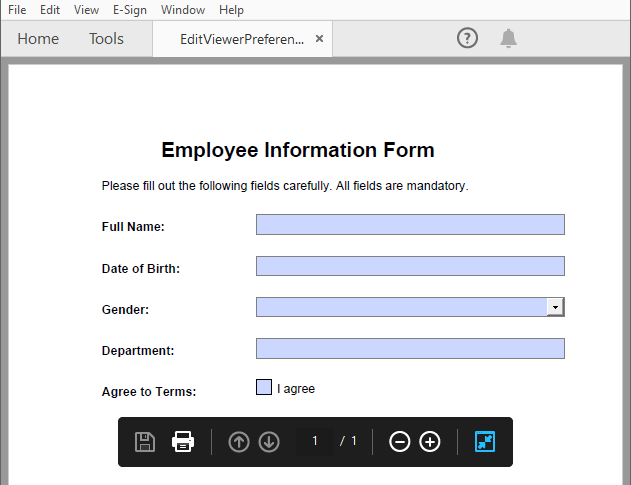
- Set View Preferences
The ViewerPreferences property allows you to customize the viewing mode of a PDF (e.g., two-column layout).
Code Example
- Python
from spire.pdf import PdfDocument, PdfPageLayout, PrintScalingMode
# Load the PDF file
pdf = PdfDocument()
pdf.LoadFromFile("EmployeeInformationForm.pdf")
# Set the viewer preferences
pdf.ViewerPreferences.DisplayTitle = True
pdf.ViewerPreferences.HideToolbar = True
pdf.ViewerPreferences.HideWindowUI = True
pdf.ViewerPreferences.FitWindow = False
pdf.ViewerPreferences.HideMenubar = True
pdf.ViewerPreferences.PrintScaling = PrintScalingMode.AppDefault
pdf.ViewerPreferences.PageLayout = PdfPageLayout.OneColumn
# Save the PDF file
pdf.SaveToFile("output/EditViewerPreference.pdf")
pdf.Close()
Result:
Similar topic: Change PDF Version Easily with Python Code
Conclusion
Editing PDFs using Python is both practical and efficient with Spire.PDF for Python. Whether you're building automation tools, editing digital forms, or securing sensitive reports, Spire.PDF equips you with a comprehensive suite of editing features—all accessible via clean and simple Python code.
With capabilities that span content editing, form interaction, document structuring, and security control, this Python PDF editor is a go-to solution for developers and organizations aiming to streamline their PDF workflows.
Frequently Asked Questions
Q: Can I edit a PDF using Python?
A: Yes, Python offers powerful libraries like Spire.PDF for Python that enable you to edit text, images, forms, annotations, and even security settings in a PDF file.
Q: How to edit a PDF using coding?
A: By using libraries such as Spire.PDF for Python, you can load an existing PDF, modify its content or structure programmatically, and save the changes with just a few lines of code.
Q: What is the Python library for PDF editor?
A: Spire.PDF for Python is a popular choice. It offers comprehensive functionalities for creating, reading, editing, converting, and securing PDF documents without the need for additional software.
Q: Can I modify a PDF for free?
A: Yes, you can use the free edition of Spire.PDF for Python to edit PDF files, although it comes with some limitations, such as processing up to 10 pages per document. Additionally, you can apply for a 30-day temporary license that removes all limitations and watermarks for full functionality testing.
Spire.PDF 11.4.10 supports printing using .NET Standard DLL
We're pleased to announce the release of Spire.PDF 11.4.10. This version supports printing using .NET Standard DLL and retrieving PdfHideAction in buttons. Moreover, some known issues that occurred when converting PDF to images and saving files have also been successfully fixed. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDF-7372 | Supports retrieving PdfHideAction in buttons.
//Initialize an instance of the PdfDocument instance
PdfDocument doc = new PdfDocument();
//Load a PDF document
doc.LoadFromFile(inputFile);
//Initialize an instance of the StringBuilder class
StringBuilder sb = new StringBuilder();
//Get the form from the document
PdfFormWidget formWidget = doc.Form as PdfFormWidget;
//Iterate through all fields in the form
for (int i = 0; i < formWidget.FieldsWidget.List.Count; i++)
{
PdfField field = formWidget.FieldsWidget.List[i] as PdfField;
//Get the ButtonField
if (field is PdfButtonWidgetFieldWidget)
{
PdfButtonWidgetFieldWidget buttonField = field as PdfButtonWidgetFieldWidget;
// Get the field name
string filename = buttonField.Name;
// Get the action
PdfAction action = buttonField.Actions.MouseDown;
if (buttonField.Actions.MouseDown != null && buttonField.Actions.MouseDown is PdfHideAction)
{
var btnAction = (PdfHideAction)buttonField.Actions.MouseDown;
sb.AppendLine(filename + "-MouseDown-Hide-" + btnAction.IsHide.ToString());
sb.AppendLine(filename + "-MouseDown-fname-" + btnAction.FieldName[0].ToString());
}
}
}
File.WriteAllText(outputFile, sb.ToString());
doc.Dispose();
|
| New feature | SPIREPDF-7376 SPIREPDF-7391 SPIREPDF-7467 | Supports printing on Windows and Linux systems using .NET Standard DLL.
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(pdffile);
doc.PrintSettings.SelectPageRange(1, 5);
if(doc.PrintSettings.CanDuplex)
{
doc.PrintSettings.Duplex = PdfDuplex.Vertical;
}
doc.Print();
|
| Bug | SPIREPDF-7361 | Fixes the issue that adding PdfTextMarkupAnnotation produced incorrect effects. |
| Bug | SPIREPDF-7380 | Fixes the issue where the text was garbled when converting PDF to images. |
| Bug | SPIREPDF-7388 | Fixes the issue where the application threw the “NullReferenceException” when accessing PdfDocumentLinkAnnotationWidget.Destination. |
| Bug | SPIREPDF-7414 | Fixes the issue where the text was truncated when entering multi-line content into PdfTextBoxField. |
| Bug | SPIREPDF-7420 | Fixes the issue where the application threw the “PdfDocumentException” when using the PdfDocument.IsPasswordProtected() method. |
| Bug | SPIREPDF-7424 | Fixes the issue where the application threw the “ArgumentOutOfRangeException” when converting PDF to images. |
| Bug | SPIREPDF-7426 | Fixes the issue that the/DA structure was incorrect in TextBox fields. |
| Bug | SPIREPDF-7429 | Fixes the issue where the application threw the "Empty convert-string" error when saving PDF documents. |
| Bug | SPIREPDF-7431 | Fixes the issue where the result was incorrect when setting FieldsWidget.BorderColor = PdfRGBColor.Empty. |
Spire.Doc for Python 13.4.6 supports matching and finding all keywords within paragraphs
We are excited to announce the release of Spire.Doc for Python 13.4.6. The latest version supports matching and finding all keywords within paragraphs. Besides, some known bugs are fixed in this update, such as the issue that the text was garbled when converting Word to TXT. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREDOC-10348 SPIREDOC-11127 |
Supports matching and finding all keywords within paragraphs.
#Create word document
document = Document()
#Load the document from disk.
document.LoadFromFile(inputFile)
#Insert the paragraphs of document
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
textSelections = paragraph.FindAllString("The", False, True)
for selection in textSelections:
#highlight
selection.GetAsOneRange().CharacterFormat.HighlightColor = Color.get_Yellow()
#Save doc file.
document.SaveToFile(outputFile, FileFormat.Docx)
|
| New feature | SPIREDOC-10659 | Supports creating charts in Word.
def AppendCharts(section, chartType, width, heigh):
section.AddParagraph().AppendText("{0:s} chart.".format(chartType))
newPara = section.AddParagraph()
# Support adding the BarChart/LineChart/ColumnChart/Surface3DChart/BubbleChart/PieChart/ScatterChart type
shape = newPara.AppendChart(chartType, float(width), float(heigh))
chart = shape.Chart
chart.Series.Clear()
chart.Series.Add("E-iceblue Test Series 1", ["Word", "PDF", "Excel", "GoogleDocs", "Office"], [
float(1900000), float(850000), float(2100000), float(600000), float(1500000)])
chart.Series.Add("E-iceblue Test Series 2", ["Word", "PDF", "Excel", "GoogleDocs", "Office"], [
float(900000), float(50000), float(1100000), float(400000), float(2500000)])
chart.Series.Add("E-iceblue Test Series 3", ["Word", "PDF", "Excel", "GoogleDocs", "Office"], [
float(500000), float(820000), float(1500000), float(400000), float(100000)])
#Create word document
document = Document()
#Add section
section = document.AddSection()
AppendCharts(section, ChartType.Bar, 500, 300)
#Save
document.SaveToFile("AppendCharts.docx", FileFormat.Docx)
|
| New feature | SPIREDOC-10963 | Supports obtaining the line index position where the found content is located.
document = Document()
document.LoadFromFile(inputFile)
textSelections = document.FindAllString("Ceshi", True, True)
sb = []
ranges = []
for selection in textSelections:
tr = selection.GetAsOneRange()
ranges.append(tr)
layoutDoc = FixedLayoutDocument(document)
for tr in ranges:
spans = layoutDoc.GetLayoutEntitiesOfNode(tr)
for i in range(spans.Count):
tempSpan = spans[i]
fs = FixedLayoutSpan(tempSpan)
tempfl = fs.Parent
line = FixedLayoutLine(tempfl)
if line.Parent.Type == LayoutElementType.Column:
lines = line.Parent.Lines
index = lines.IndexOf(line)
# print(index)
sb.append("position:" + str(index))
File.AppendAllText(outputFile, sb)
|
| New feature | SPIREDOC-11001 | Supports enabling and disabling revision tracking mode.
document = Document()
#Load the file from disk.
document.LoadFromFile(inputFile)
document.TrackChanges = True
document.StartTrackRevisions("user")
range = document.LastParagraph.AppendText("Revise4")
range.InsertRevision.Author = "test01"
document.LastParagraph.Text = "remove"
range.DeleteRevision.Author = "test01"
document.StopTrackRevisions()
document.SaveToFile(outputFile)
|
| New feature | SPIREDOC-11015 | Supports setting "Document.LayoutOptions.UseHarfBuzzTextShaper" when converting Word to PDF.
Document doc = new Document();
doc.LoadFromFile("input.docx");
doc.LayoutOptions.UseHarfBuzzTextShaper = true;
doc.SaveToFile("result.pdf", Spire.Doc.FileFormat.PDF);
|
| New feature | SPIREDOC-11114 | Supports detecting whether a document is encrypted.
value1 = Document.IsEncrypted(inputFile_1) |
| New feature | SPIREDOC-11157 | Supports converting OfficeMath to MathMLCode.
doc = Document()
section=doc.AddSection()
officeMath = OfficeMath(doc)
officeMath.FromLatexMathCode("x^{2}+\\sqrt{{x^{2}+1}}+1")
officeMath.ToMathMLCode()
|
| Bug | SPIREDOC-10502 | Fixes the issue where adding and extracting formulas would throw an "Arg_InvalidCastException" exception. |
| Bug | SPIREDOC-10646 | Fixes the issue that the text was garbled when converting Word to TXT. |
| Bug | SPIREDOC-10860 | Fixes the issue where using FixedLayoutRow.Table would throw an "Arg_NullReferenceException" exception. |
| Bug | SPIREDOC-10886 | Fixes the issue that the return value of Document.IsContainMacro was incorrect. |
| Bug | SPIREDOC-10924 | Fixes the issue that "Cannot remove because there is no parent" exception occurred when converting HTML to Word. |
| Bug | SPIREDOC-10996 | Fixes the issue that "System.ArgumentNullException" occurred when converting Word to HTML. |
| Bug | SPIREDOC-11014 | Fixes the issue where PreserveFormFields=True did not take effect. |
| Bug | SPIREDOC-11077 SPIREDOC-11101 | Fixes the issue that list numbering was incorrect when converting Word to PDF. |
| Bug | SPIREDOC-11166 | Fixes the issue that the "'Document' is not defined" error occurred when using Span.ParentNode. |
| Bug | SPIREDOC-11168 | Fixes the issue that formulas were blurry when converting Word to HTML. |
Spire.PDF for Android via Java 10.4.0 adds a new feature
We are delighted to announce the release of Spire.PDF for Android via Java 10.4.0. This version supports setting 'PreserveAllowedMetadata=true' when using PdfStandardsConverter. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDF-6921 | Supports setting 'PreserveAllowedMetadata=true' when using PdfStandardsConverter.
PdfStandardsConverter converter = new PdfStandardsConverter(stream); converter.Options.PreserveAllowedMetadata = true; |