
Convertir una tabla de PDF a Word parece simple, pero cualquiera que lo haya intentado sabe que el proceso puede ser sorprendentemente inconsistente. Los archivos PDF están diseñados principalmente para su visualización, no para la edición estructurada, lo que a menudo conduce a diseños de tabla corruptos al convertir o copiar. Los usuarios frecuentemente encuentran filas rotas, columnas combinadas, bordes perdidos, espaciado de celdas inconsistente o tablas que se exportan como imágenes en lugar de tablas de Word editables.
Esta guía completa explica métodos fiables para convertir tablas de PDF a tablas de Word. Aprenderá sobre herramientas en línea, enfoques manuales y soluciones programáticas de alta precisión. Si necesita convertir tablas de PDF a Word, extraer datos estructurados de un PDF o producir tablas de Word totalmente editables para flujos de trabajo profesionales o automatizados, este artículo le proporciona el conocimiento práctico y los conocimientos técnicos que necesita.
1. Por qué es difícil convertir tablas de PDF a Word
Antes de explorar los métodos de conversión, es importante entender por qué las tablas en los PDF son difíciles de interpretar. Esto le ayudará a seleccionar la herramienta adecuada según la complejidad del diseño.
1.1 Los PDF no contienen tablas reales
A diferencia de Word o HTML, los archivos PDF no almacenan estructuras de tabla. En su lugar, almacenan:
- texto usando posiciones absolutas
- líneas y bordes como trazados de dibujo
- filas/columnas solo como alineación visual, no como datos de cuadrícula estructurados
Como resultado:
- Las filas y columnas no se reconocen como celdas
- Los elementos de línea pueden no corresponder a los límites reales de la tabla
- Seleccionar texto o copiar a menudo interrumpe el diseño
Es por eso que el simple copiar y pegar casi siempre falla.
1.2 Word requiere elementos de tabla estructurados
Microsoft Word espera:
- un elemento
<table>definido - recuentos consistentes de filas/columnas
- límites de celda verdaderos
- anchos de columna ajustables
Si el contenido del PDF no se puede interpretar en esta estructura, Word crea resultados impredecibles o exporta la tabla como una imagen.
Comprender estas limitaciones aclara por qué la extracción fiable de tablas de PDF requiere un análisis inteligente que va más allá de la simple detección visual.
2. Resumen de Métodos Fiables
Esta guía cubre tres formas prácticas de convertir tablas de PDF en tablas de Word:
- Convertidores de PDF a Word en línea – los más rápidos, con control mínimo
- Software de escritorio – más estable, con mejor precisión
- Extracción programática y reconstrucción de tablas – la más alta precisión y resultados totalmente editables
Consejo: La mayoría de las soluciones no programáticas convierten todo el PDF en un archivo de Word. Si solo necesita las tablas, es posible que deba eliminar manualmente el contenido circundante después.
El método más preciso es extraer los datos de la tabla mediante programación y reconstruir la tabla de Word; esto evita pérdidas de formato y garantiza una salida de tabla limpia y totalmente editable.
3. Método 1: Convertir tabla de PDF a Word usando herramientas en línea (el más rápido y fácil)
Los convertidores de PDF a Word en línea son convenientes para conversiones rápidas. Estas herramientas intentan detectar estructuras de tabla automáticamente y exportarlas a un documento de Word.
Flujo de trabajo típico
-
Abra un convertidor en línea (por ejemplo, Free PDF Converter).
-
Suba su PDF.
-
Espere la conversión automática.
-
Descargue el archivo de Word.
-
Ajuste el formato de la tabla manualmente si es necesario.
Ventajas
- Sin instalación
- Funciona en cualquier dispositivo
- Muy rápido
Desventajas
- Precisión deficiente para tablas complejas
- Preocupaciones de privacidad (subida a la nube)
- Puede generar tablas como imágenes
- Personalización limitada
Las herramientas en línea son las mejores para conversiones simples y únicas.
4. Método 2: Convertir tablas de PDF usando software de escritorio (más estable y seguro)
Las aplicaciones de escritorio procesan archivos localmente, ofreciendo mayor precisión y privacidad. Microsoft Word, Acrobat y el software de PDF dedicado a menudo proporcionan una extracción de tablas aceptable para diseños estándar.
Flujo de trabajo general
-
Instale el software (por ejemplo, Microsoft Word).
-
Abra el archivo PDF en la aplicación.
-
Confirme la conversión haciendo clic en .
-
Espere el procesamiento.
-
Edite y guarde el resultado como un archivo .docx.
Ventajas
- Mayor precisión de detección
- Admite archivos grandes y de varias páginas
- Sin riesgos relacionados con la carga
Desventajas
- Algunos programas son de pago
- Todavía poco fiable para tablas irregulares
- Las características difieren entre herramientas
Las herramientas de escritorio funcionan bien para una complejidad moderada, pero no para datos estructurados que deben permanecer perfectamente editables.
5. Método 3: Extraer y convertir tablas de PDF mediante programación (el método más preciso)
Para los usuarios que necesitan una reconstrucción de tablas consistente, automatizada y de alta fidelidad, el enfoque programático es el más fiable. Permite:
- extracción precisa del contenido de la tabla
- control total sobre la construcción de la tabla de Word
- procesamiento por lotes
- formato consistente
Este método puede convertir con éxito incluso tablas de PDF complejas o no estándar en tablas de Word perfectamente editables.
5.1 Opción A: Convertir todo el PDF a Word automáticamente
Usando Free Spire.PDF for Python, puede convertir un PDF directamente en un documento de Word. La biblioteca intenta inferir las estructuras de las tablas analizando los elementos de línea, la posición del texto y la alineación de las columnas.
Instale Free Spire.PDF for Python usando pip:
pip install spire.pdf.free
Ejemplo de código Python para la conversión de PDF a Word
from spire.pdf import PdfDocument, FileFormat
input_pdf = "sample.pdf"
output_docx = "output/pdf_to_docx.docx"
# Open a PDF document
pdf = PdfDocument()
pdf.LoadFromFile(input_pdf)
# Save the PDF to a Word document
pdf.SaveToFile(output_docx, FileFormat.DOCX)
A continuación se muestra una vista previa del resultado de la conversión de PDF a Word:
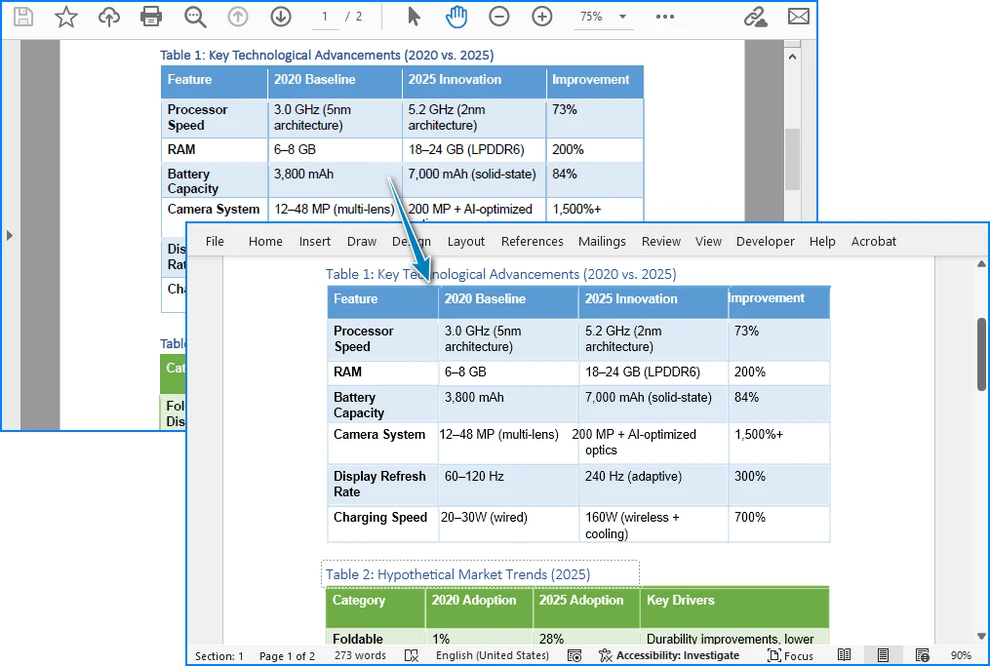
Cuándo usar
- Tablas con líneas de cuadrícula claras
- Diseños de simples a moderadamente complejos
- Cuando la fidelidad de la tabla no necesita ser 100% perfecta
Limitaciones
- Las celdas complejas o combinadas pueden no representarse con precisión
- Las tablas sin bordes pueden malinterpretarse
- Para opciones de conversión más avanzadas, consulte Cómo convertir PDF a Doc/Docx con Python.
5.2 Opción B: Extraer datos de la tabla y reconstruir las tablas de Word manualmente (la mejor precisión)
También puede extraer datos de tablas de PDF usando Free Spire.PDF for Python y construir tablas de Word usando Free Spire.Doc for Python. Este método es el más fiable y preciso para convertir tablas de PDF en documentos de Word. Proporciona:
- Editabilidad completa de la tabla
- Estructura predecible
- Control de formato completo
- Automatización fiable
Instale Free Spire.Doc for Python:
pip install spire.doc.free
El flujo de trabajo:
- Extraer datos de la tabla del PDF
- Crear un documento de Word mediante programación
- Insertar una tabla usando los datos extraídos
- Aplicar formato
Ejemplo de código Python para extraer tablas de PDF y construir tablas de Word
from spire.pdf import PdfDocument, PdfTableExtractor
from spire.doc import Document, FileFormat, DefaultTableStyle, AutoFitBehaviorType, BreakType
input_pdf = "sample.pdf"
output_docx = "output/pdf_table_to_docx.docx"
# Open a PDF document
pdf = PdfDocument()
pdf.LoadFromFile(input_pdf)
# Create a Word document
doc = Document()
section = doc.AddSection()
# Extract table data from the PDF
table_extractor = PdfTableExtractor(pdf)
for i in range(pdf.Pages.Count):
tables = table_extractor.ExtractTable(i)
if tables is not None and len(tables) > 0:
for i in range(len(tables)):
table = tables[i]
# Create a table in the Word document
word_table = section.AddTable()
word_table.ApplyStyle(DefaultTableStyle.ColorfulGridAccent4)
word_table.ResetCells(table.GetRowCount(), table.GetColumnCount())
for j in range(table.GetRowCount()):
for k in range(table.GetColumnCount()):
cell_text = table.GetText(j, k).replace("\n", " ")
# Write the cell text to the corresponding cell in the Word table
tr = word_table.Rows[j].Cells[k].AddParagraph().AppendText(cell_text)
tr.CharacterFormat.FontName = "Arial"
tr.CharacterFormat.FontSize = 11
# Auto-fit the table
word_table.AutoFit(AutoFitBehaviorType.AutoFitToContents)
section.AddParagraph().AppendBreak(BreakType.LineBreak)
# Save the Word document
doc.SaveToFile(output_docx, FileFormat.Docx)
A continuación se muestra una vista previa de las tablas de Word reconstruidas:

Por qué este método es superior
- Las tablas de salida son siempre editables
- Ideal para automatización y procesamiento por lotes
- Funciona incluso sin líneas de tabla visibles
- Permite formato, fuentes, bordes y estilos personalizados
Esta es la solución recomendada para casos de uso profesional.
Si necesita exportar tablas de PDF en otros formatos, consulte Cómo extraer tablas de PDF usando Python.
6. Comparación de precisión de todos los métodos
| Método | Precisión | Editable | Control de formato | Ideal para |
|---|---|---|---|---|
| Convertidores en línea | ★★★★☆ | Sí | Bajo | Uso rápido y único |
| Software de escritorio | ★★★★☆ | Sí | Medio | Documentos profesionales estándar |
| Extracción programática + reconstrucción | ★★★★★ | Sí | Completo | Automatización, flujos de trabajo empresariales |
| Conversión completa de PDF a Word (automática) | ★★★★☆ | Sí | Medio | PDF limpios y bien estructurados |
7. Mejores prácticas para una conversión de alta calidad
Para garantizar los mejores resultados, siga estas mejores prácticas:
Preparación de archivos
- Prefiera los PDF originales basados en texto (no escaneados)
- Ejecute OCR antes de la extracción de la tabla si el PDF está escaneado
Consejos de diseño de tablas
- Mantenga la alineación de las columnas de forma consistente
- Evite las celdas combinadas innecesarias
- Mantenga un espaciado claro entre las columnas
Recomendaciones técnicas
- Use la extracción programática para flujos de trabajo por lotes
- Reconstruya las tablas de Word para un formato exacto
- Valide siempre la precisión de los datos extraídos
8. Preguntas frecuentes
1. ¿Cómo convierto una tabla de PDF a una tabla de Word editable sin perder el formato?
Use convertidores de escritorio de alta calidad o una biblioteca programática como Spire.PDF + Spire.Doc. La extracción programática proporciona los resultados más consistentes.
2. ¿Puedo extraer solo la tabla (no todo el PDF) a Word?
Sí. Extraiga solo los datos de la tabla y reconstruya la tabla mediante programación. Esto produce tablas de Word totalmente editables.
3. ¿Por qué mi tabla de PDF apareció como una imagen en Word?
El convertidor no pudo interpretar la estructura y exportó el contenido como una imagen. Use una herramienta que admita la reconstrucción de tablas.
4. ¿Cuál es el método más preciso para tablas complejas o irregulares?
Extracción programática combinada con la construcción manual de tablas en Word.
9. Conclusión
La conversión de tablas de PDF a tablas de Word varía de simple a muy compleja según la estructura del PDF original. Las herramientas rápidas en línea y las aplicaciones de escritorio funcionan bien para diseños simples, pero a menudo tienen dificultades con celdas combinadas, espaciado irregular o estructuras de varias filas.
Para los usuarios que requieren una salida precisa, editable y fiable, especialmente en la automatización empresarial y el procesamiento de documentos a gran escala, el enfoque programático proporciona una precisión inigualable. Permite la verdadera reconstrucción de tablas en Word con control total sobre el formato, el estilo y la estructura de las celdas.
Ya sea que necesite una conversión rápida en línea o un proceso automatizado profundamente preciso, los métodos de esta guía le aseguran que puede convertir de manera fiable tablas de PDF a tablas de Word totalmente editables en todos los niveles de complejidad.