Les fichiers PDF sont largement utilisés pour le partage de documents car ils préservent la mise en page et le formatage sur tous les appareils. Cependant, certains PDF incluent des autorisations de sécurité qui empêchent les utilisateurs de copier du texte. Lorsque vous essayez de sélectionner ou de copier du contenu à partir de ces fichiers, vous pouvez constater que la copie est désactivée.
Ce type de fichier est souvent appelé un PDF sécurisé, protégé ou restreint. Contrairement aux PDF protégés par mot de passe qui bloquent l'ouverture du fichier, ces documents peuvent toujours être consultés normalement, mais certaines actions telles que la copie de texte sont restreintes.
Heureusement, il existe plusieurs solutions de contournement gratuites et pratiques qui vous permettent d'extraire ou de copier du texte à partir de PDF protégés. Dans ce guide, nous explorerons cinq méthodes simples, notamment des outils en ligne, des fonctionnalités système intégrées et une approche d'automatisation avec Python.
Navigation rapide
- Méthode 1 — Copier du texte à partir d'un PDF sécurisé à l'aide de Google Docs
- Méthode 2 — Convertir un PDF restreint en TXT en ligne
- Méthode 3 — Capture d'écran + OCR pour extraire le texte
- Méthode 4 — Imprimer un PDF protégé contre la copie dans un nouveau PDF
- Méthode 5 — Extraire du texte d'un PDF sécurisé à l'aide de Python
Pourquoi ne pouvez-vous pas copier de texte à partir de certains PDF ?
De nombreux créateurs de PDF appliquent des restrictions d'autorisation pour contrôler la manière dont le document peut être utilisé. Ces autorisations sont définies dans les paramètres de sécurité du PDF et peuvent désactiver des actions telles que :
- Copie de texte
- Modification du document
- Impression du fichier
- Ajout d'annotations
Ceci est souvent appelé protection contre la copie ou restriction de contenu. Bien que le document reste lisible, la visionneuse PDF empêche la sélection ou la copie de texte.
Ces restrictions sont généralement utilisées pour protéger la propriété intellectuelle ou empêcher la réutilisation non autorisée du contenu. Cependant, lorsque vous avez légitimement besoin de réutiliser du texte, par exemple à des fins de recherche, de documentation ou d'accessibilité, vous pouvez avoir besoin de moyens alternatifs pour extraire le contenu.
Voici cinq méthodes qui peuvent vous aider.
Méthode 1 — Copier du texte à partir d'un PDF sécurisé à l'aide de Google Docs
L'une des façons les plus simples de copier du texte à partir d'un PDF protégé est de l'ouvrir avec Google Docs. Lorsqu'un PDF est téléchargé sur Google Drive et ouvert dans Google Docs, le service convertit automatiquement le fichier en un document modifiable.
Au cours de ce processus de conversion, le contenu du PDF est réinterprété en texte et en paragraphes, ce qui contourne souvent les restrictions de copie de base. Une fois la conversion terminée, vous pouvez facilement sélectionner et copier le texte comme dans un document normal.
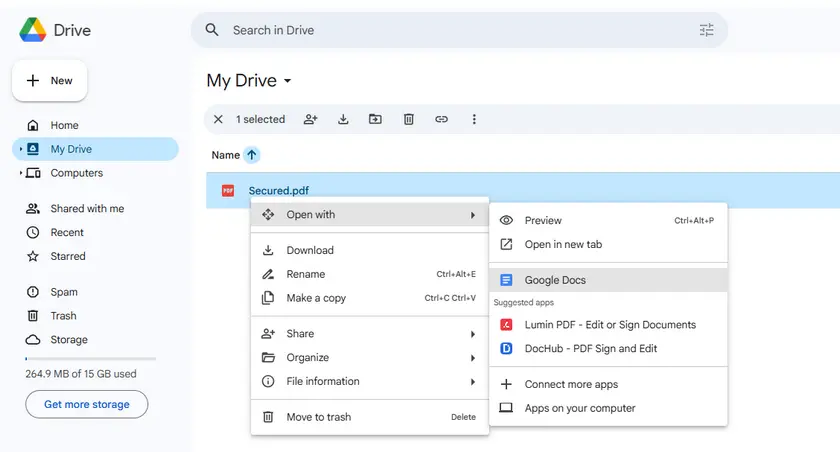
Étapes
- Ouvrez Google Drive.
- Téléchargez le PDF protégé.
- Faites un clic droit sur le fichier et sélectionnez Ouvrir avec → Google Docs.
- Google Docs convertira le PDF en un document modifiable.
- Copiez le texte extrait du document.
Avantages
- Gratuit et facile à utiliser.
- Aucune installation de logiciel requise.
- Fonctionne bien avec les documents textuels.
Limites
- Les PDF numérisés/basés sur des images ne seront pas convertis en texte (pas d'OCR).
- La mise en forme peut devenir désordonnée avec des mises en page complexes.
- Nécessite un compte Google et une connexion Internet.
Méthode 2 — Convertir un PDF restreint en TXT en ligne
Une autre solution rapide consiste à convertir le PDF restreint en un fichier texte brut à l'aide d'un convertisseur en ligne. Une fois le document converti au format TXT, le texte devient entièrement modifiable et peut être copié sans restrictions.
Un outil gratuit pratique à cet effet est PDF24 Tools, qui fournit un convertisseur PDF en TXT basé sur un navigateur. Cette méthode fonctionne bien lorsque vous avez besoin d'extraire du texte rapidement sans installer de logiciel supplémentaire.
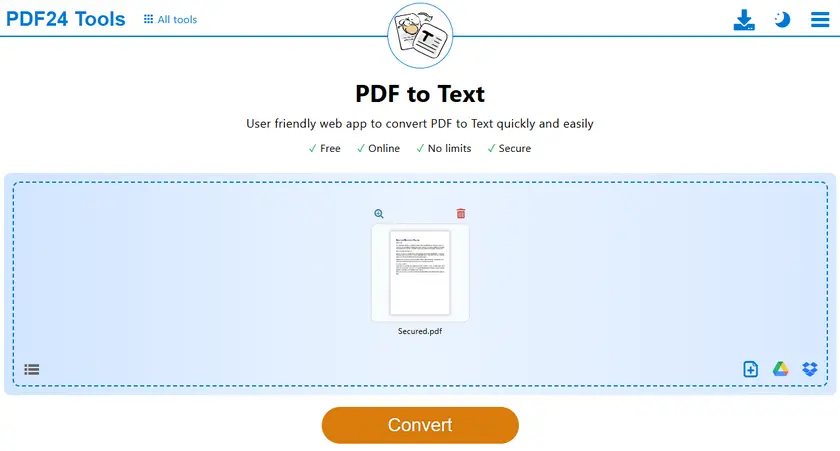
Étapes
- Ouvrez l'outil PDF-en-TXT.
- Téléchargez votre fichier PDF protégé.
- Démarrez le processus de conversion.
- Téléchargez le fichier TXT généré.
- Ouvrez le fichier TXT et copiez le texte librement.
Avantages
- Flux de travail rapide et simple.
- Aucune installation requise.
Limites
- Risque de confidentialité — les documents sensibles sont téléchargés sur des serveurs tiers.
- Souvent limité à quelques conversions gratuites par jour.
- Pas de prise en charge de l'OCR dans la plupart des outils gratuits (les PDF basés sur des images ne fonctionneront pas).
Méthode 3 — Capture d'écran + OCR pour extraire le texte
Si le PDF a de fortes restrictions de copie ou contient des pages numérisées, l'OCR (Reconnaissance Optique de Caractères) peut toujours récupérer le texte visible. La technologie OCR analyse l'image du document et convertit les caractères détectés en texte modifiable.
Windows 11 inclut une fonctionnalité OCR intégrée dans l'Outil Capture d'écran, vous permettant de capturer une partie de l'écran et d'extraire instantanément le texte de l'image.
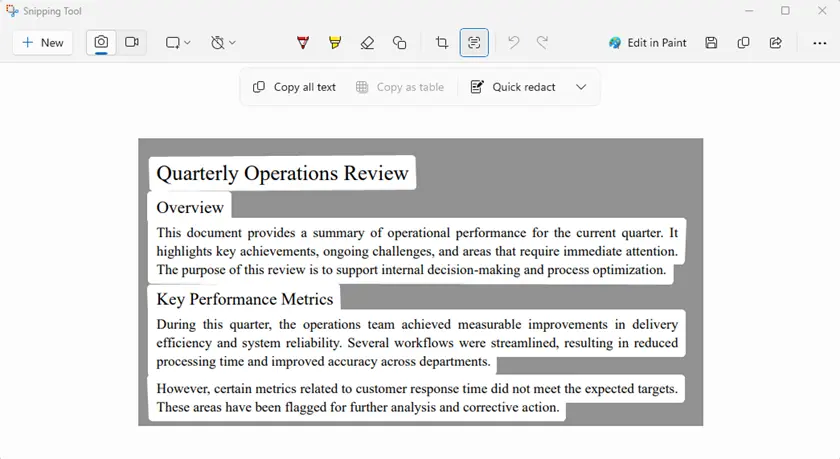
Étapes
- Ouvrez le PDF protégé sur votre écran.
- Lancez l'Outil Capture d'écran.
- Capturez la zone contenant le texte.
- Utilisez Actions de texte → Copier tout le texte.
- Collez le texte extrait dans un document.
Avantages
- Contourne presque toutes les protections contre la copie car il capture l'écran.
- Fonctionne avec les PDF numérisés/basés sur des images.
Limites
- Prend du temps s'il y a beaucoup de pages.
- Erreurs d'OCR — la précision dépend de la qualité de l'image et de la police.
- Processus manuel sauf s'il est automatisé avec des scripts.
Méthode 4 — Imprimer un PDF protégé contre la copie dans un nouveau PDF
Certains PDF protégés bloquent la copie mais autorisent toujours l'impression. Dans de tels cas, vous pouvez imprimer le document dans un nouveau fichier PDF, ce qui peut supprimer la restriction de copie.
Cela peut être fait facilement en utilisant la fonction d'impression intégrée de Google Chrome. Après avoir enregistré la version imprimée du fichier, le nouveau PDF peut autoriser la sélection et la copie de texte normales.
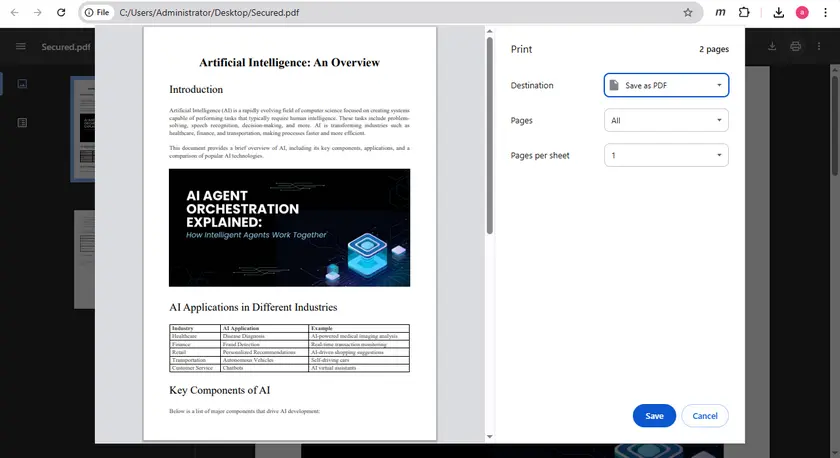
Étapes
- Ouvrez le PDF dans Google Chrome.
- Appuyez sur Ctrl + P pour ouvrir la boîte de dialogue d'impression.
- Définissez la destination sur Enregistrer au format PDF.
- Enregistrez le PDF nouvellement généré.
- Ouvrez le nouveau fichier et essayez de copier le texte.
Avantages
- Solution de contournement simple.
- Aucun outil supplémentaire requis.
Limites
- Si l'impression est désactivée dans les autorisations du PDF, cela ne fonctionnera pas.
- Certaines différences de formatage peuvent apparaître.
Méthode 5 — Extraire du texte d'un PDF sécurisé à l'aide de Python
Pour les développeurs ou les utilisateurs qui ont besoin de traiter plusieurs documents, l'extraction de texte par programmation peut être la solution la plus efficace. Au lieu de copier manuellement le contenu, un script peut lire automatiquement la structure du PDF et récupérer le texte de chaque page.
En utilisant Free Spire.PDF for Python, vous pouvez facilement extraire du texte de documents PDF avec seulement quelques lignes de code. Cette approche est particulièrement utile pour l'automatisation, le traitement par lots ou la création de flux de travail de traitement de documents.
Si vous travaillez avec de petits documents (moins de 10 pages par document) ou si vous testez des flux d'extraction, la version gratuite fonctionne bien. Pour les fichiers plus volumineux, vous pouvez soit diviser le document d'abord, soit utiliser la version complète.
Installer la bibliothèque
pip install spire.pdf.free
Exemple : Extraire le texte de chaque page
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Secured.pdf")
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Create a PdfTextExtractor object
textExtractor = PdfTextExtractor(page)
# Create a PdfTextExtractOptions object
extractOptions = PdfTextExtractOptions()
# Set IsExtractAllText to True
extractOptions.IsExtractAllText = True
# Extract text from the page keeping white spaces
text = textExtractor.ExtractText(extractOptions)
# Write text to a txt file
with open('output/TextOfPage-{}.txt'.format(i + 1), 'w', encoding='utf-8') as file:
lines = text.split("\n")
for line in lines:
if line != '':
file.write(line)
doc.Close()
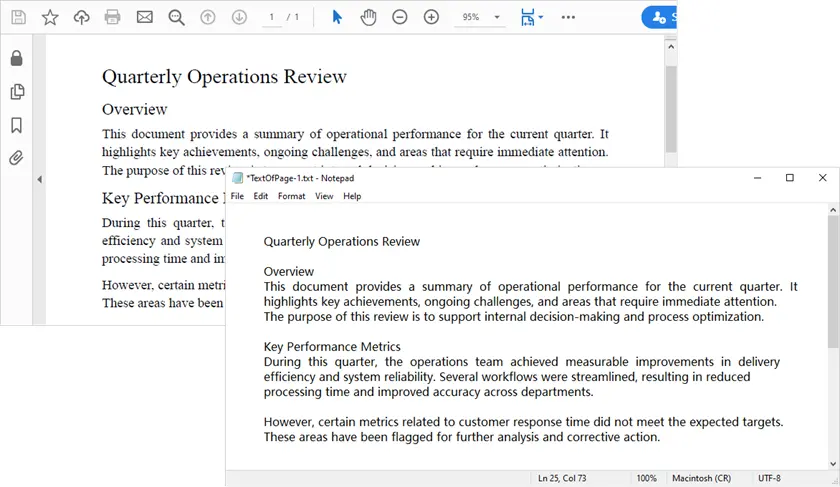
Ce que fait ce script
- Charge le document PDF.
- Itère à travers chaque page.
- Extrait le texte tout en préservant les espaces.
- Enregistre le texte extrait dans des fichiers TXT.
Avantages
- Contrôle total sur le processus d'extraction.
- Peut être automatisé pour le traitement par lots.
- Fonctionne bien avec les PDF textuels.
Limites
- Nécessite des connaissances en programmation.
- Ne peut pas traiter les PDF basés sur des images à moins qu'une bibliothèque OCR supplémentaire ne soit utilisée.
Vous aimerez peut-être aussi : Effectuer l'OCR de PDF avec Python (Extraire le texte d'un PDF numérisé)
Tableau comparatif : Quelle méthode choisir ?
| Méthode | Niveau de compétence | Facilité d'utilisation | Idéal pour | Fonctionne avec les PDF numérisés | Fonctionne sous de fortes restrictions | Traitement par lots |
|---|---|---|---|---|---|---|
| Google Docs | Débutant | Très facile | Extraction rapide dans le navigateur | Non | Oui | Non |
| Convertisseur en ligne | Débutant | Très facile | Conversion TXT rapide | Non | Oui | Non |
| Capture d'écran + OCR | Débutant | Facile | PDF numérisés ou basés sur des images | Oui | Oui | Non |
| Imprimer en PDF | Débutant | Facile | Suppression des restrictions simples | Non | Conditionnel (L'impression doit être autorisée) | Non |
| Python (Spire.PDF) | Développeur | Modéré | Automatisation et flux de travail par lots | Repose sur des bibliothèques OCR supplémentaires | Oui | Oui |
Conclusion
Les restrictions de copie dans les PDF peuvent être frustrantes, surtout lorsque vous n'avez besoin de réutiliser qu'une partie du texte. Heureusement, plusieurs méthodes gratuites peuvent aider à extraire le contenu de PDF protégés.
Pour les tâches rapides, des outils comme Google Docs ou les convertisseurs en ligne peuvent être la solution la plus simple. Si le document contient du contenu numérisé ou des restrictions strictes, les méthodes basées sur l'OCR peuvent toujours récupérer le texte. Pour les flux de travail à grande échelle ou les scénarios d'automatisation, l'utilisation de bibliothèques Python telles que Free Spire.PDF for Python offre une approche puissante et flexible.
En choisissant la méthode qui correspond le mieux à vos besoins, vous pouvez récupérer efficacement le texte des PDF restreints tout en maintenant un flux de travail efficace.
FAQ (Foire aux questions)
Q1 : Qu'est-ce qu'un PDF sécurisé ou restreint ?
Un PDF protégé ou restreint est un document qui peut être ouvert et consulté normalement mais qui dispose de paramètres de sécurité empêchant la copie, l'impression ou la modification de son contenu. Ces autorisations sont définies par le propriétaire du document.
Q2 : Puis-je copier du texte de tous les PDF sécurisés ?
Pas toujours. Certains PDF ont un cryptage fort ou une gestion des droits numériques (DRM) qui empêche complètement la copie. Dans de tels cas, des outils d'OCR ou des bibliothèques professionnelles peuvent être nécessaires.
Q3 : Quelle est la meilleure méthode pour les PDF numérisés ?
Pour les PDF numérisés, l'extraction par capture d'écran + OCR ou l'automatisation Python avec des bibliothèques OCR est généralement le moyen le plus fiable de récupérer le texte.
Q4 : Puis-je automatiser l'extraction de texte pour plusieurs PDF ?
Oui. En utilisant des bibliothèques Python comme Spire.PDF, vous pouvez extraire automatiquement le texte de plusieurs fichiers PDF, ce qui le rend idéal pour le traitement par lots ou l'automatisation des flux de travail.
Q5 : Dois-je payer pour l'une de ces méthodes ?
Toutes les méthodes répertoriées dans l'article sont gratuites. Cependant, certains outils (comme Spire.PDF) ont des versions gratuites avec des limitations, telles qu'une restriction du nombre de pages. Pour les fichiers plus volumineux, vous pourriez avoir besoin de la version complète.