
스크린샷, 스캔한 PDF 또는 문서 사진의 텍스트를 편집해야 한 적이 있습니까? 모든 것을 수동으로 다시 입력하는 것은 지루하고 오류가 발생하기 쉬운 프로세스입니다. 다행히도 광학 문자 인식(OCR)이라는 강력한 기술을 사용하여 이미지를 텍스트로 변환할 수 있습니다.
이 종합 가이드에서는 일반 사용자와 개발자 모두를 위해 이미지에서 텍스트를 추출하는 최고의 무료 도구와 방법을 즉시 살펴보겠습니다.
- 이미지를 TXT로 변환하는 이유? 주요 사용 사례
- 이미지-텍스트 변환기 작동 방식: OCR의 기본
- 온라인에서 이미지를 텍스트로 변환하는 최고의 무료 도구
- 사진-텍스트 무료 데스크톱 변환기: Microsoft OneNote
- Python OCR 라이브러리: Spire.OCR을 사용하여 이미지에서 텍스트 추출
- 자주 묻는 질문 (FAQ)
이미지를 TXT로 변환하는 이유? 주요 사용 사례
PNG 또는 JPG와 같은 이미지를 TXT 파일로 변환하는 기능은 생각보다 유용합니다. 다음은 몇 가지 일반적인 시나리오입니다.
- 스캔한 문서 편집: 오래된 종이 문서, 계약서 또는 편지를 편집 가능한 Word 또는 Google Docs 파일로 변환합니다.
- 스크린샷에서 텍스트 캡처: 다시 입력하지 않고도 소프트웨어 튜토리얼, 소셜 미디어 게시물 또는 오류 메시지에서 텍스트를 빠르게 가져옵니다.
- 이미지 속 텍스트 번역: OCR 도구를 사용하여 텍스트를 추출한 다음 Google 번역과 같은 번역기에 붙여넣습니다.
- 접근성 향상: 시각 장애가 있는 사용자를 위해 스크린 리더가 이미지 내의 텍스트를 읽을 수 있도록 합니다.
이미지-텍스트 변환기 작동 방식: OCR의 기본
대부분의 무료 도구는 클라우드 기반 OCR(소프트웨어 다운로드 필요 없음) 또는 경량 데스크톱 앱을 사용합니다. 과정은 간단합니다.

최신 OCR 도구는 여러 언어(영어, 스페인어, 중국어 등), 필기 텍스트(정확도 다양)를 지원하며 저화질 이미지도 처리할 수 있습니다. 물론 선명한 이미지일수록 더 나은 결과를 얻을 수 있습니다.
전문가 팁: 최상의 OCR 결과를 얻으려면 조명이 좋고 눈부심이 적으며 텍스트가 똑바른(기울어진 사진 피하기) 고해상도 이미지를 사용하십시오.
온라인에서 이미지를 텍스트로 변환하는 최고의 무료 도구
비싼 소프트웨어가 필요하지 않습니다. 브라우저에서 직접 작동하는 최고의 무료 온라인 OCR 도구는 다음과 같습니다.
1. Google Drive (Google Docs)
이것은 가장 강력하면서도 종종 간과되는 무료 OCR 솔루션 중 하나입니다.
사용 방법:
- drive.google.com으로 이동합니다.
- 이미지(JPG, PNG) 또는 스캔한 PDF를 Drive에 업로드합니다.
- 파일을 마우스 오른쪽 버튼으로 클릭하고 “연결 프로그램 > Google Docs”를 선택합니다.
- Google Docs가 즉시 새 문서를 만듭니다. 추출된 텍스트는 삽입된 이미지 하단에 표시됩니다.
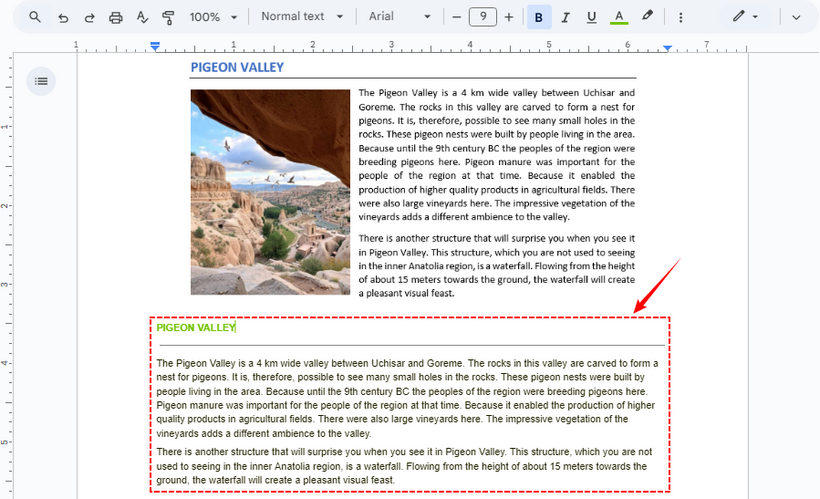
✔ 장점: 매우 정확하고 Google 생태계와 원활하게 통합되며 여러 페이지를 처리합니다.
✘ 단점: 서식이 때때로 불완전할 수 있습니다.
2. 온라인 OCR 도구
Online OCR은 무료 이미지-텍스트 변환을 위한 전용 웹 도구입니다. JPG, PNG, TIFF 및 PDF(무료 파일당 최대 15MB)를 지원합니다.
사용 방법:
- Online OCR로 이동합니다(가입 필요 없음).
- 이미지를 업로드하거나 도구로 드래그 앤 드롭합니다.
- 소스 언어(예: 영어, 프랑스어)와 출력 형식(Word, TXT, Excel)을 선택합니다.
- “변환”을 클릭하고 추출된 텍스트가 포함된 편집 가능한 파일을 다운로드합니다.

✔ 장점: 기본 사용에 등록이 필요하지 않음; 다양한 언어와 출력 형식을 지원합니다.
✘ 단점: 무료 버전에는 파일 크기 제한이 있습니다. 사이트에 광고가 있습니다.
텍스트를 PDF로 내보내야 합니까? 참조: 텍스트를 PDF로 쉽게 변환: 4가지 빠르고 전문적인 방법
사진-텍스트 무료 데스크톱 변환기: Microsoft OneNote
Windows 또는 Microsoft Office를 사용하는 경우 OneNote의 내장 OCR 도구는 원활하고 무료입니다. 이미지, 스캔한 PDF, 노트에 붙여넣는 스크린샷에서도 작동합니다.
사용 방법:
- Microsoft OneNote를 열고 새 페이지를 만듭니다.
- 페이지에 이미지를 붙여넣거나 “삽입 > 그림”을 통해 삽입합니다.
- 이미지를 마우스 오른쪽 버튼으로 클릭하고 “그림에서 텍스트 복사”를 선택합니다.
- 추출된 텍스트를 아무 곳에나(Word, Excel 등) 붙여넣습니다.
참고: 다른 언어를 인식해야 하는 경우 이미지를 마우스 오른쪽 버튼으로 클릭하고 “이미지에서 텍스트를 검색 가능하게 만들기”를 선택한 다음 텍스트의 정확한 언어를 선택해야 합니다.

✔ 장점: Office와 완벽하게 통합됩니다. 필기 텍스트를 지원합니다. 오프라인으로 작동합니다.
✘ 단점: 데스크톱 앱을 설치해야 합니다. Mac 사용자에게는 덜 직관적입니다.
Python OCR 라이브러리: Spire.OCR을 사용하여 이미지에서 텍스트 추출
기본적인 Python 기술을 가진 사용자를 위해 Spire.OCR for Python 라이브러리는 자동화된 이미지-텍스트 변환을 가능하게 합니다. 일괄 처리, 여러 언어 및 이미지 형식(JPG, PNG, BMP 등)을 지원하므로 반복적인 OCR 작업(예: 한 번에 100개 제품 이미지에서 텍스트 추출)을 간소화하는 데 적합합니다.
1. Spire.OCR 라이브러리 설치: 명령 프롬프트 또는 터미널을 열고 다음 pip 명령을 실행합니다.
pip install spire.ocr
2. OCR 모델 다운로드: 아래 링크에서 운영 체제에 맞는 사전 훈련된 모델을 다운로드하고 알려진 디렉터리(예: F:\OCR\win-x64)에 파일의 압축을 풉니다.
3. Python 스크립트 작성
새 Python 파일(예: image_to_text.py)을 만들고 다음 코드를 붙여넣습니다. 이 스크립트는 이미지를 로드하고 OCR을 수행한 다음 추출된 텍스트를 파일에 저장합니다.
from spire.ocr import *
# OCR 스캐너 인스턴스 생성
scanner = OcrScanner()
# OCR 모델 경로 및 언어 구성
configureOptions = ConfigureOptions()
configureOptions.ModelPath = "F:\\OCR Model\\win-x64"
configureOptions.Language = "English"
scanner.ConfigureDependencies(configureOptions)
# 이미지에서 OCR 수행
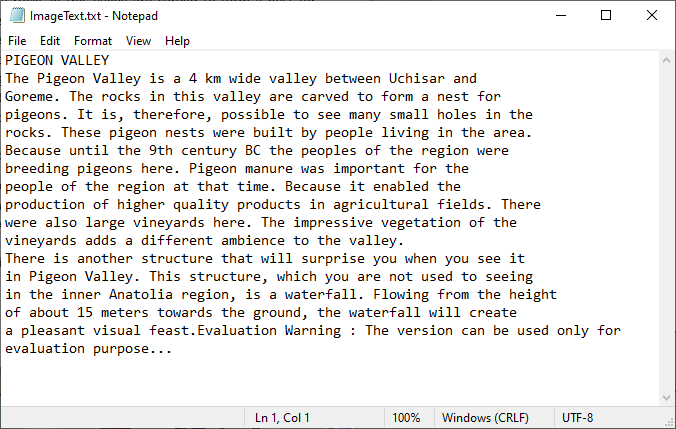
scanner.Scan("Sample.png")
# 추출된 텍스트를 파일에 저장
text = scanner.Text.ToString()
with open("ImageText.txt", "a", encoding="utf-8") as file:
file.write(text)
주요 단계:
- OCR 스캐너 생성: 모든 OCR 관련 작업(구성, 이미지 스캔, 텍스트 추출)을 담당하는 핵심 OcrScanner 개체를 초기화합니다.
- 모델 경로 및 언어 구성:
- ConfigureOptions: OCR 매개변수를 설정하는 클래스입니다.
- ModelPath: 추출된 OCR 모델 파일의 경로(정확한 텍스트 인식을 위해 중요).
- Language: 텍스트 인식 언어를 지정합니다(영어, 중국어, 프랑스어 등 지원).
- 이미지에서 OCR 수행: Scan() 메서드를 사용하여 대상 이미지를 처리하고 OCR 엔진을 트리거하여 이미지에서 텍스트를 추출합니다.
추출된 텍스트:
✔ 장점: 자동화 및 일괄 처리에 적합합니다. 코드를 통해 고도로 사용자 정의할 수 있습니다.
✘ 단점: 기본적인 Python 지식과 초기 설정이 필요합니다.
스캔한 PDF의 경우 다음을 확인하십시오: Python으로 PDF OCR 수행 (스캔한 PDF에서 텍스트 추출)
마지막 생각들
이미지를 텍스트로 무료로 변환하는 것은 더 이상 전문가에게만 국한된 복잡한 작업이 아닙니다. Google Drive, OnlineOCR, 및 Microsoft OneNote와 같은 강력하고 접근 가능한 도구를 사용하면 모든 이미지에서 몇 초 만에 텍스트를 추출할 수 있습니다. 반복적인 작업을 자동화하려는 개발자와 고급 사용자를 위해 Python OCR 라이브러리는 강력하고 확장 가능한 솔루션을 제공합니다.
자주 묻는 질문 (FAQ)
Q: 이 도구들이 필기 노트에서 텍스트를 추출할 수 있습니까?
A: 예, 하지만 정확도는 다양합니다. 인쇄된 텍스트는 높은 정밀도로 인식되는 반면, 필기 성공 여부는 선명도와 도구의 기능에 따라 달라집니다.
Q: 무료 온라인 OCR 도구는 사용하기에 안전한가요?
A: Google Drive 및 OnlineOCR과 같은 평판이 좋은 도구는 일반적으로 민감하지 않은 문서에 대해 안전합니다. 그러나 기밀 파일의 경우 OneNote와 같은 데스크톱 도구나 로컬 Python 스크립트를 사용하는 것이 데이터를 서버에 업로드하지 않으므로 더 안전합니다.
Q: 오프라인에서 이미지를 텍스트로 변환할 수 있나요?
A: 예. 인터넷 연결 없이 Microsoft OneNote 또는 Spire.OCR for Python 라이브러리를 사용할 수 있습니다.
Q: Spire.OCR이 이미지에서 텍스트 좌표를 추출할 수 있나요?
A: 예. Spire.OCR은 인식된 각 텍스트 영역의 경계 상자 정보를 반환하여 텍스트 좌표를 캡처합니다.
# 위치와 함께 블록 수준 텍스트 추출
block_text = ""
for block in text.Blocks:
rectangle = block.Box
block_info = f'{block.Text} -> x: {rectangle.X}, y: {rectangle.Y}, w: {rectangle.Width}, h: {rectangle.Height}'
block_text += block_info + '\n'