PDF 파일은 여러 장치에서 레이아웃과 서식을 보존하기 때문에 문서 공유에 널리 사용됩니다. 그러나 일부 PDF에는 사용자가 텍스트를 복사하지 못하도록 하는 보안 권한이 포함되어 있습니다. 이러한 파일에서 콘텐츠를 선택하거나 복사하려고 하면 복사가 비활성화된 것을 볼 수 있습니다.
이러한 유형의 파일은 종종 보안, 보호 또는 제한된 PDF라고 합니다. 파일 열기를 차단하는 암호로 보호된 PDF와 달리 이러한 문서는 정상적으로 볼 수 있지만 텍스트 복사와 같은 특정 작업은 제한됩니다.
다행히도 보호된 PDF에서 텍스트를 추출하거나 복사할 수 있는 몇 가지 무료이고 실용적인 해결 방법이 있습니다. 이 가이드에서는 온라인 도구, 내장 시스템 기능 및 Python 자동화 접근 방식을 포함한 다섯 가지 쉬운 방법을 살펴보겠습니다.
빠른 탐색
- 방법 1 — Google 문서를 사용하여 보안 PDF에서 텍스트 복사
- 방법 2 — 제한된 PDF를 온라인에서 TXT로 변환
- 방법 3 — 스크린샷 + OCR로 텍스트 추출
- 방법 4 — 복사 방지된 PDF를 새 PDF로 인쇄
- 방법 5 — Python을 사용하여 보안 PDF에서 텍스트 추출
일부 PDF에서 텍스트를 복사할 수 없는 이유는 무엇입니까?
많은 PDF 작성자는 문서 사용 방법을 제어하기 위해 권한 제한을 적용합니다. 이러한 권한은 PDF의 보안 설정에서 지정되며 다음과 같은 작업을 비활성화할 수 있습니다.
- 텍스트 복사
- 문서 편집
- 파일 인쇄
- 주석 추가
이를 종종 복사 방지 또는 콘텐츠 제한이라고 합니다. 문서는 읽을 수 있지만 PDF 뷰어는 텍스트 선택이나 복사를 방지합니다.
이러한 제한은 일반적으로 지적 재산을 보호하거나 콘텐츠의 무단 재사용을 방지하는 데 사용됩니다. 그러나 연구, 문서화 또는 접근성 목적으로 텍스트를 합법적으로 재사용해야 하는 경우 콘텐츠를 추출하는 다른 방법이 필요할 수 있습니다.
다음은 도움이 될 수 있는 다섯 가지 방법입니다.
방법 1 — Google 문서를 사용하여 보안 PDF에서 텍스트 복사
보호된 PDF에서 텍스트를 복사하는 가장 간단한 방법 중 하나는 Google 문서로 여는 것입니다. PDF를 Google 드라이브에 업로드하고 Google 문서에서 열면 서비스가 자동으로 파일을 편집 가능한 문서로 변환합니다.
이 변환 과정에서 PDF의 콘텐츠는 텍스트와 단락으로 재해석되어 기본적인 복사 제한을 우회하는 경우가 많습니다. 변환이 완료되면 일반 문서에서처럼 텍스트를 쉽게 선택하고 복사할 수 있습니다.
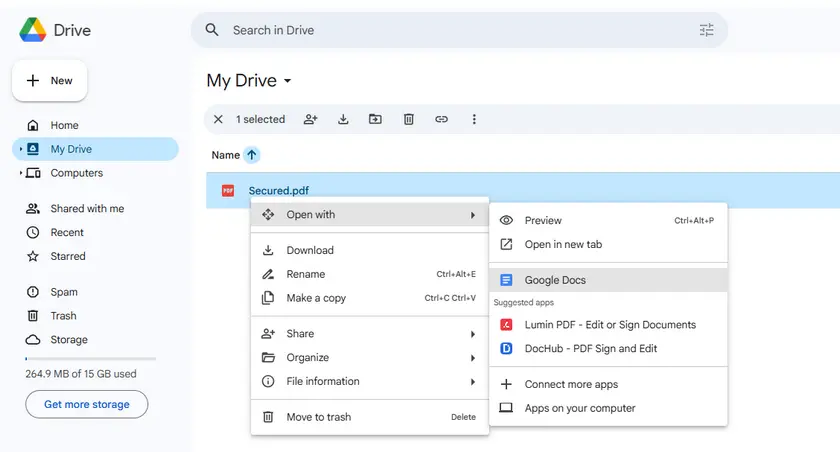
단계
- Google 드라이브를 엽니다.
- 보호된 PDF를 업로드합니다.
- 파일을 마우스 오른쪽 버튼으로 클릭하고 연결 프로그램 → Google 문서를 선택합니다.
- Google 문서가 PDF를 편집 가능한 문서로 변환합니다.
- 문서에서 추출된 텍스트를 복사합니다.
장점
- 무료이며 사용하기 쉽습니다.
- 소프트웨어 설치가 필요 없습니다.
- 텍스트 기반 문서에서 잘 작동합니다.
제한 사항
- 스캔/이미지 기반 PDF는 텍스트로 변환되지 않습니다 (OCR 없음).
- 복잡한 레이아웃에서는 서식이 지저분해질 수 있습니다.
- Google 계정과 인터넷 연결이 필요합니다.
방법 2 — 제한된 PDF를 온라인에서 TXT로 변환
또 다른 빠른 해결책은 온라인 변환기를 사용하여 제한된 PDF를 일반 텍스트 파일로 변환하는 것입니다. 문서가 TXT 형식으로 변환되면 텍스트는 완전히 편집 가능해지며 제한 없이 복사할 수 있습니다.
이 목적에 편리한 무료 도구는 브라우저 기반 PDF to TXT 변환기를 제공하는 PDF24 도구입니다. 이 방법은 추가 소프트웨어를 설치하지 않고 텍스트를 빠르게 추출해야 할 때 잘 작동합니다.
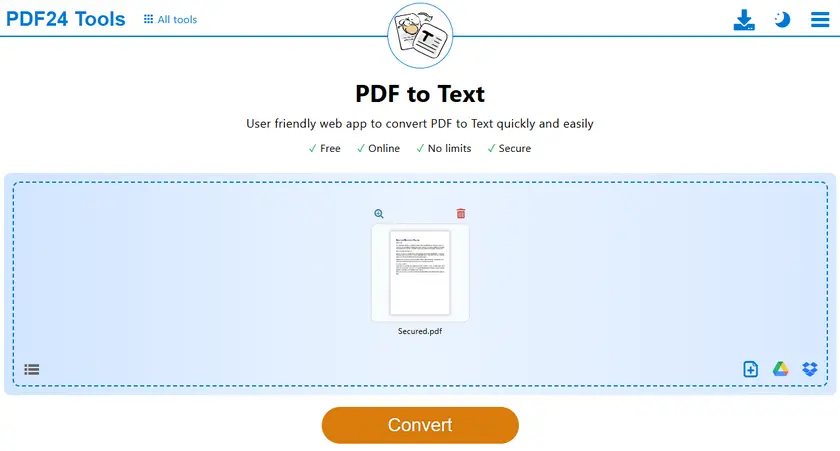
단계
- PDF-to-TXT 도구를 엽니다.
- 보호된 PDF 파일을 업로드합니다.
- 변환 프로세스를 시작합니다.
- 생성된 TXT 파일을 다운로드합니다.
- TXT 파일을 열고 텍스트를 자유롭게 복사합니다.
장점
- 빠르고 간단한 워크플로.
- 설치가 필요 없습니다.
제한 사항
- 개인 정보 보호 위험 — 민감한 문서가 타사 서버에 업로드됩니다.
- 하루에 몇 번의 무료 변환으로 제한되는 경우가 많습니다.
- 대부분의 무료 도구에서는 OCR을 지원하지 않습니다 (이미지 기반 PDF는 작동하지 않음).
방법 3 — 스크린샷 + OCR로 텍스트 추출
PDF에 강력한 복사 제한이 있거나 스캔된 페이지가 포함된 경우 OCR(광학 문자 인식)을 사용하여 표시되는 텍스트를 검색할 수 있습니다. OCR 기술은 문서의 이미지를 분석하고 감지된 문자를 편집 가능한 텍스트로 변환합니다.
Windows 11에는 캡처 도구에 내장된 OCR 기능이 포함되어 있어 화면의 일부를 캡처하고 이미지에서 텍스트를 즉시 추출할 수 있습니다.
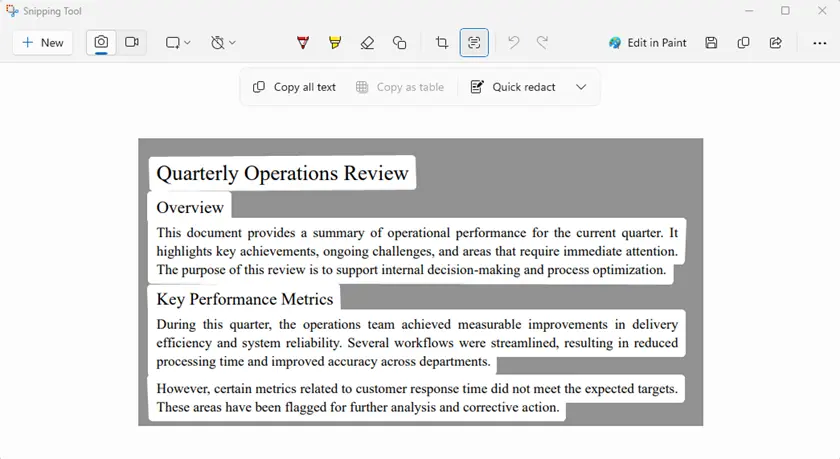
단계
- 화면에서 보호된 PDF를 엽니다.
- 캡처 도구를 실행합니다.
- 텍스트가 포함된 영역을 캡처합니다.
- 텍스트 작업 → 모든 텍스트 복사를 사용합니다.
- 추출된 텍스트를 문서에 붙여넣습니다.
장점
- 화면을 캡처하므로 거의 모든 복사 방지를 우회합니다.
- 스캔/이미지 기반 PDF에서 작동합니다.
제한 사항
- 페이지가 많으면 시간이 많이 걸립니다.
- OCR 오류 — 정확도는 이미지 품질과 글꼴에 따라 다릅니다.
- 스크립트로 자동화하지 않으면 수동 프로세스입니다.
방법 4 — 복사 방지된 PDF를 새 PDF로 인쇄
일부 보호된 PDF는 복사를 차단하지만 인쇄는 허용합니다. 이러한 경우 문서를 새 PDF 파일로 인쇄하면 복사 제한이 제거될 수 있습니다.
이 작업은 Google Chrome의 내장 인쇄 기능을 사용하여 쉽게 수행할 수 있습니다. 파일의 인쇄된 버전을 저장한 후 새 PDF에서 일반 텍스트 선택 및 복사가 허용될 수 있습니다.
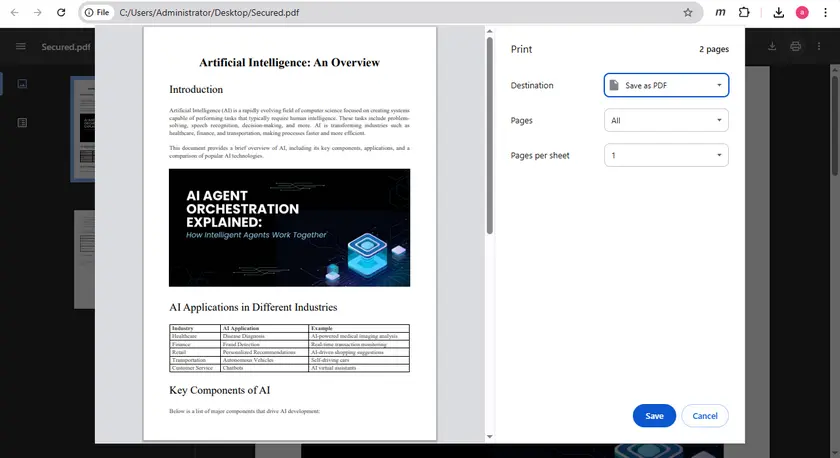
단계
- Google Chrome에서 PDF를 엽니다.
- Ctrl + P를 눌러 인쇄 대화 상자를 엽니다.
- 대상을 PDF로 저장으로 설정합니다.
- 새로 생성된 PDF를 저장합니다.
- 새 파일을 열고 텍스트 복사를 시도합니다.
장점
- 간단한 해결 방법.
- 추가 도구가 필요 없습니다.
제한 사항
- PDF 권한에서 인쇄가 비활성화된 경우 이 방법은 작동하지 않습니다.
- 일부 서식 차이가 나타날 수 있습니다.
방법 5 — Python을 사용하여 보안 PDF에서 텍스트 추출
여러 문서를 처리해야 하는 개발자나 사용자에게는 프로그래밍 방식으로 텍스트를 추출하는 것이 가장 효율적인 솔루션일 수 있습니다. 콘텐츠를 수동으로 복사하는 대신 스크립트가 자동으로 PDF 구조를 읽고 각 페이지에서 텍스트를 검색할 수 있습니다.
Python용 무료 Spire.PDF를 사용하면 단 몇 줄의 코드로 PDF 문서에서 텍스트를 쉽게 추출할 수 있습니다. 이 접근 방식은 자동화, 일괄 처리 또는 문서 처리 워크플로 구축에 특히 유용합니다.
작은 문서(문서당 10페이지 이내)로 작업하거나 추출 워크플로를 테스트하는 경우 무료 버전이 잘 작동합니다. 더 큰 파일의 경우 문서를 먼저 분할하거나 전체 버전을 사용할 수 있습니다.
라이브러리 설치
pip install spire.pdf.free
예: 각 페이지에서 텍스트 추출
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Secured.pdf")
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Create a PdfTextExtractor object
textExtractor = PdfTextExtractor(page)
# Create a PdfTextExtractOptions object
extractOptions = PdfTextExtractOptions()
# Set IsExtractAllText to True
extractOptions.IsExtractAllText = True
# Extract text from the page keeping white spaces
text = textExtractor.ExtractText(extractOptions)
# Write text to a txt file
with open('output/TextOfPage-{}.txt'.format(i + 1), 'w', encoding='utf-8') as file:
lines = text.split("\n")
for line in lines:
if line != '':
file.write(line)
doc.Close()
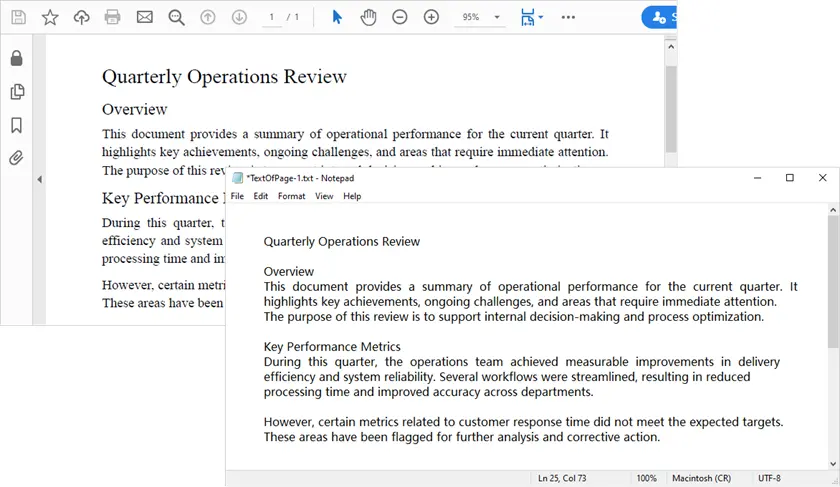
이 스크립트의 기능
- PDF 문서를 로드합니다.
- 각 페이지를 반복합니다.
- 공백을 유지하면서 텍스트를 추출합니다.
- 추출된 텍스트를 TXT 파일에 저장합니다.
장점
- 추출 프로세스에 대한 완전한 제어.
- 일괄 처리를 위해 자동화할 수 있습니다.
- 텍스트 기반 PDF에서 잘 작동합니다.
제한 사항
- 프로그래밍 지식이 필요합니다.
- 추가 OCR 라이브러리를 사용하지 않으면 이미지 기반 PDF를 처리할 수 없습니다.
관심 있을 만한 글: Python으로 PDF OCR 수행 (스캔된 PDF에서 텍스트 추출)
비교표: 어떤 방법을 선택해야 할까요?
| 방법 | 기술 수준 | 사용 용이성 | 최적 대상 | 스캔된 PDF에서 작동 | 강력한 제한 하에서 작동 | 일괄 처리 |
|---|---|---|---|---|---|---|
| Google 문서 | 초보자 | 매우 쉬움 | 브라우저에서 빠른 추출 | 아니요 | 예 | 아니요 |
| 온라인 변환기 | 초보자 | 매우 쉬움 | 빠른 TXT 변환 | 아니요 | 예 | 아니요 |
| 스크린샷 + OCR | 초보자 | 쉬움 | 스캔 또는 이미지 기반 PDF | 예 | 예 | 아니요 |
| PDF로 인쇄 | 초보자 | 쉬움 | 간단한 제한 제거 | 아니요 | 조건부 (인쇄가 허용되어야 함) | 아니요 |
| Python (Spire.PDF) | 개발자 | 보통 | 자동화 및 일괄 워크플로 | 추가 OCR 라이브러리에 의존 | 예 | 예 |
결론
PDF의 복사 제한은 특히 텍스트의 일부만 재사용해야 할 때 답답할 수 있습니다. 다행히도 보호된 PDF에서 콘텐츠를 추출하는 데 도움이 되는 몇 가지 무료 방법이 있습니다.
빠른 작업을 위해 Google 문서나 온라인 변환기와 같은 도구가 가장 쉬운 해결책일 수 있습니다. 문서에 스캔된 콘텐츠나 엄격한 제한이 포함된 경우 OCR 기반 방법으로 텍스트를 복구할 수 있습니다. 대규모 워크플로나 자동화 시나리오의 경우 Python용 무료 Spire.PDF와 같은 Python 라이브러리를 사용하면 강력하고 유연한 접근 방식을 제공합니다.
자신의 필요에 가장 적합한 방법을 선택하면 효율적인 워크플로를 유지하면서 제한된 PDF에서 텍스트를 효율적으로 검색할 수 있습니다.
자주 묻는 질문 (FAQ)
Q1: 보안 또는 제한된 PDF란 무엇입니까?
보호 또는 제한된 PDF는 정상적으로 열고 볼 수 있지만 콘텐츠 복사, 인쇄 또는 편집을 방지하는 보안 설정이 있는 문서입니다. 이러한 권한은 문서 소유자가 설정합니다.
Q2: 모든 보안 PDF에서 텍스트를 복사할 수 있습니까?
항상 그런 것은 아닙니다. 일부 PDF에는 복사를 완전히 방지하는 강력한 암호화 또는 DRM이 있습니다. 이러한 경우 OCR 도구나 전문 라이브러리가 필요할 수 있습니다.
Q3: 스캔된 PDF에 가장 적합한 방법은 무엇입니까?
스캔된 PDF의 경우 스크린샷 + OCR 추출 또는 OCR 라이브러리를 사용한 Python 자동화가 일반적으로 텍스트를 검색하는 가장 신뢰할 수 있는 방법입니다.
Q4: 여러 PDF에 대한 텍스트 추출을 자동화할 수 있습니까?
예. Spire.PDF와 같은 Python 라이브러리를 사용하면 여러 PDF 파일에서 자동으로 텍스트를 추출할 수 있으므로 일괄 처리나 워크플로 자동화에 이상적입니다.
Q5: 이 방법들 중 비용을 지불해야 하는 것이 있습니까?
기사에 나열된 모든 방법은 무료로 사용할 수 있습니다. 그러나 일부 도구(예: Spire.PDF)에는 페이지 수 제한과 같은 제한이 있는 무료 버전이 있습니다. 더 큰 파일의 경우 전체 버전이 필요할 수 있습니다.