
PDF 파일의 표를 CSV 형식으로 변환하는 것은 보고, 분석 및 데이터 통합 워크플로에서 일반적인 요구 사항입니다. CSV 파일은 가볍고 널리 지원되며 자동화에 적합하여 표 형식 데이터를 재사용해야 할 때 정적 PDF보다 훨씬 유용합니다.
그러나 실제로 PDF 표를 CSV로 변환하는 것은 간단하지 않은 경우가 많습니다. PDF 파일은 논리적 구조보다는 시각적 모양을 보존하도록 설계되었습니다. 화면에서 완벽하게 정렬된 것처럼 보이는 표가 내부적으로는 행과 열로 존재하지 않을 수 있으며, 이것이 바로 순진한 변환 방법이 종종 실패하는 이유입니다.
이 문서는 실용적인 PDF 표를 CSV로 변환하는 방법에 중점을 둡니다. 모든 이론적 옵션을 다루는 대신 가장 일반적으로 사용되는 접근 방식, 실제 작동 방식 및 각 방법이 적절한 시기를 설명합니다.
목차
- PDF 표를 CSV로 변환하는 일반적인 실용적인 방법
- 방법 1: Acrobat을 사용하여 PDF를 스프레드시트로 내보내기
- 방법 2: 온라인 PDF 표를 CSV로 변환
- 방법 3: Python을 사용한 프로그래밍 방식 PDF 표 추출
- 실제 PDF 표 시나리오 처리
- 주요 내용: PDF 표를 CSV로 변환하기
- 자주 묻는 질문
PDF 표를 CSV로 변환하는 일반적인 실용적인 방법
대부분의 실제 워크플로에서 PDF 표를 CSV로 변환하는 것은 다음 범주 중 하나에 속합니다.
- PDF를 스프레드시트 도구(예: Acrobat)로 표 내보내기
- 온라인 PDF 표를 CSV로 변환하는 변환기 사용
- Python 코드를 사용하여 프로그래밍 방식으로 표 추출
단순한 복사-붙여넣기 기술은 일반적으로 표를 일반 텍스트로 평탄화하고 광범위한 수동 재구성이 필요하기 때문에 의도적으로 제외되었습니다.
방법 1: Acrobat을 사용하여 PDF를 스프레드시트로 내보내기
PDF를 스프레드시트 형식으로 내보낸 다음 CSV로 저장하는 것은 데스크톱 도구와 시각적 검사를 선호하는 사용자에게 일반적인 선택입니다.
이 방법이 잘 작동하는 경우
- PDF가 텍스트 기반이고 잘 구조화되어 있음
- 표에 명확한 행 및 열 경계가 있음
- 수동 검토 및 수정이 허용됨
일반적인 Acrobat 기반 워크플로
-
Acrobat에서 PDF 파일 열기
-
PDF 내보내기를 선택하고 출력 형식으로 스프레드시트를 선택합니다.
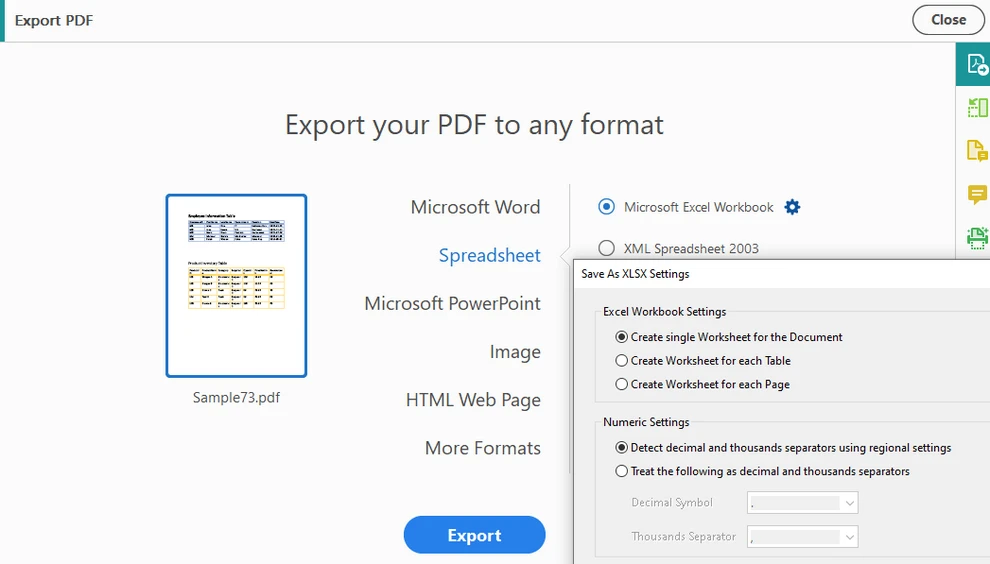
-
문서를 Excel 형식으로 내보내기
-
필요한 경우 표 구조 검토 및 조정
-
스프레드시트를 CSV 파일로 저장 또는 내보내기
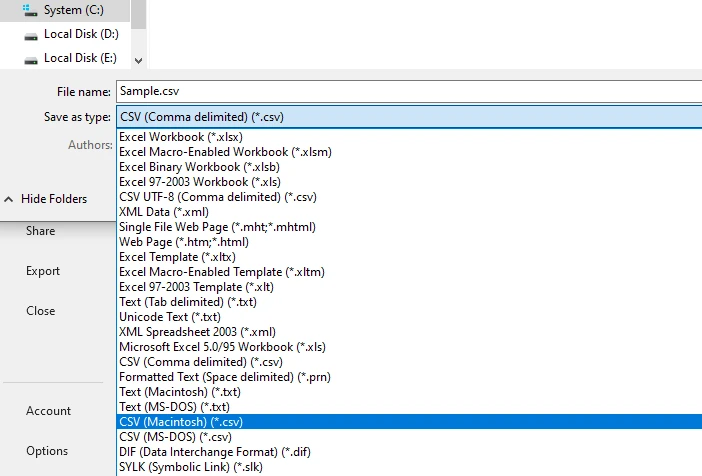
이 워크플로는 특히 단일 페이지 또는 일관된 형식의 표에 대해 직접 복사하는 것보다 더 나은 구조적 결과를 생성하는 경우가 많습니다.
실용적인 제한 사항
- 복잡하거나 여러 페이지에 걸친 표가 여러 시트에 걸쳐 분할될 수 있음
- 병합된 셀로 인해 CSV 출력에서 열이 잘못 정렬될 수 있음
- 내보내기 전에 수동 정리가 필요한 경우가 많음
- 일괄 또는 자동화된 처리에 적합하지 않음
이 접근 방식은 시각적 유효성 검사가 중요한 가끔의 변환에는 효과적이지만 확장성은 좋지 않습니다.
CSV로 저장하기 전에 PDF 표를 Excel로 변환하기 위한 Acrobat의 무료 대안을 찾는 사용자는 PDF를 Excel로 무료로 변환하는 방법을 참조하십시오.
방법 2: 온라인 PDF 표를 CSV로 변환
온라인 변환기는 설치가 필요 없고 빠른 결과를 제공하기 때문에 널리 사용됩니다.
온라인 변환이 적합한 경우
- PDF에 선택 가능한(스캔되지 않은) 텍스트가 포함되어 있음
- 표 레이아웃이 비교적 단순함
- 소수의 파일만 변환하면 됨
일반적인 온라인 PDF 표를 CSV로 변환하는 워크플로
대부분의 온라인 도구는 유사한 프로세스를 따릅니다(Zamzar 예):
-
온라인 PDF를 CSV로 변환하는 변환기 열기
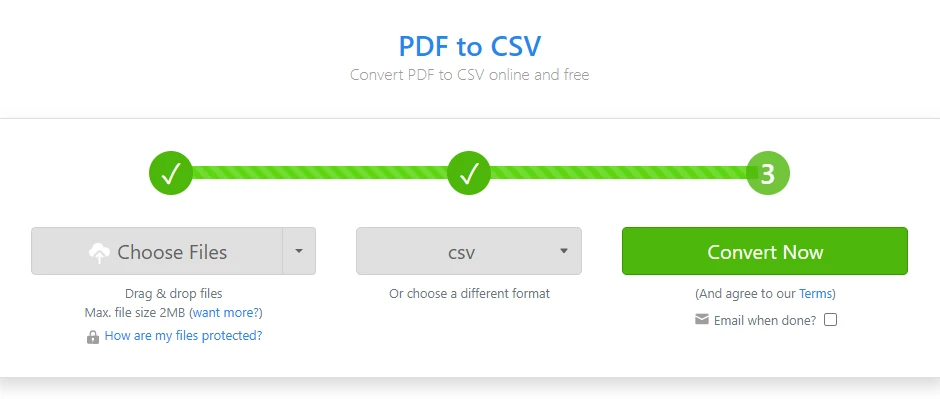
-
표가 포함된 PDF 파일 업로드
-
사용 가능한 경우 페이지 범위 또는 표 감지 옵션 구성
-
변환 프로세스 시작
-
생성된 CSV 파일 다운로드
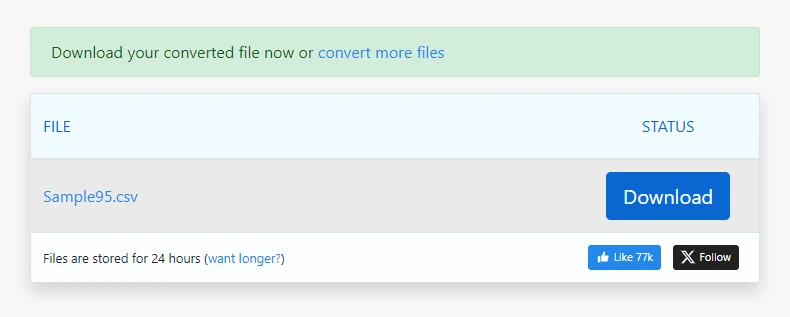
간단한 PDF의 경우 이 프로세스는 몇 초 만에 사용 가능한 CSV 출력을 생성할 수 있습니다.
온라인 변환기 사용 시 일반적인 고려 사항
- 간격이 일치하지 않으면 열이 이동할 수 있음
- 변환기는 종종 표뿐만 아니라 전체 PDF를 CSV로 내보냄
- 셀 내부의 줄 바꿈으로 인해 추가 행이 생성될 수 있음
- 출력 품질은 문서 레이아웃에 따라 다름
- 파일 크기 제한 및 개인 정보 보호 문제가 적용될 수 있음
온라인 도구는 예측 가능하거나 재사용 가능한 솔루션이라기보다는 편의 옵션으로 취급하는 것이 가장 좋습니다.
방법 3: Python을 사용한 프로그래밍 방식 PDF 표 추출
정확성, 일관성 또는 자동화가 필요한 경우 프로그래밍 방식 추출은 종종 PDF 표를 CSV로 변환하는 가장 신뢰할 수 있는 방법입니다.
프로그래밍 방식 추출이 선호되는 이유
- 표를 페이지별로 처리할 수 있음
- 여러 페이지에 걸친 표를 일관되게 처리할 수 있음
- 동일한 추출 논리를 일괄 작업에서 재사용할 수 있음
- 출력이 재현 가능하고 검증하기 쉬움
이 접근 방식은 대규모로 PDF를 처리하는 데이터 파이프라인, 보고 시스템 및 백엔드 서비스에서 일반적입니다. Spire.PDF for Python을 사용하면 개발자는 PDF 문서에서 표를 정확하게 추출하고, 여러 페이지 및 복잡한 레이아웃을 처리하며, 최소한의 수동 개입으로 CSV로의 변환을 자동화할 수 있습니다.
PDF 표를 CSV로 변환하는 일반적인 프로그래밍 워크플로
대부분의 프로그래밍 솔루션은 유사한 상위 수준 프로세스를 따릅니다.
- PDF 문서 로드
- 각 페이지 반복
- 각 페이지에서 표 구조 감지
- 행과 열을 구조화된 데이터로 추출
- 필요한 경우 추출된 텍스트 정규화
- 구조화된 데이터를 CSV 파일에 쓰기
Python은 가독성과 강력한 데이터 처리 기능을 결합하기 때문에 이 작업에 널리 사용됩니다.
예: Python을 사용하여 PDF 표를 CSV로 변환
아래 예제를 실행하기 전에 필요한 PDF 처리 라이브러리가 설치되어 있는지 확인하십시오.
pip를 사용하여 Spire.PDF for Python을 설치할 수 있습니다.
pip install spire.pdf
설치가 완료되면 표 추출 예제를 진행할 수 있습니다.
다음 예제는 Spire.PDF for Python을 사용하여 PDF 표를 CSV로 변환하는 방법을 보여줍니다.
import os
import csv
from spire.pdf import PdfDocument, PdfTableExtractor
# PDF 문서 로드
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# 테이블 추출기 생성
extractor = PdfTableExtractor(pdf)
# PDF 합자 및 PUA 문자를 처리하기 위해 텍스트 정규화
def normalize_text(text: str) -> str:
if not text:
return text
if not any('\uE000' <= ch <= '\uF8FF' for ch in text):
return text
ligatures = {
'\uE000': 'ff',
'\uE001': 'fi',
'\uE002': 'fl',
'\uE003': 'ffl',
'\uE004': 'ffi',
'\uE005': 'ft',
'\uE006': 'st',
}
for lig, repl in ligatures.items():
text = text.replace(lig, repl)
return text
# 페이지별로 테이블 추출
for page_index in range(pdf.Pages.Count):
tables = extractor.ExtractTable(page_index)
if tables:
for table_index, table in enumerate(tables):
rows = []
for r in range(table.GetRowCount()):
row = []
for c in range(table.GetColumnCount()):
cell = normalize_text(table.GetText(r, c)).replace("\n", " ")
row.append(cell)
rows.append(row)
os.makedirs("output/Tables", exist_ok=True)
with open(
f"output/Tables/Page{page_index + 1}-Table{table_index + 1}.csv",
"w",
newline="",
encoding="utf-8",
) as f:
writer = csv.writer(f)
writer.writerows(rows)
pdf.Close()
아래는 PDF 표를 CSV로 변환한 결과 미리보기입니다.
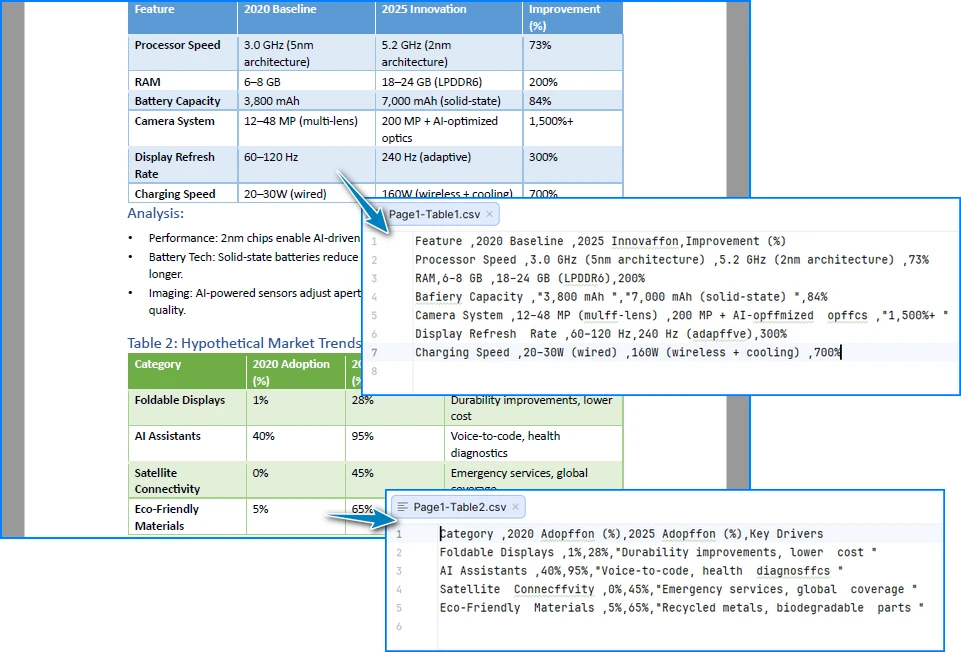
이 구현의 작동 방식
이 구현은 텍스트 위치에서 레이아웃을 추론하는 대신 표 구조를 보존하는 데 중점을 둡니다.
- 셀 수준 추출은 행과 열이 간격에서 재구성되는 대신 논리적 단위로 보존되도록 보장합니다.
- 페이지별 처리는 페이지 경계를 넘어 표가 잘못 병합되는 것을 방지합니다.
- 명시적 텍스트 정규화는 합자 및 개인용 유니코드 문자와 같은 일반적인 PDF 문제를 처리하여 CSV 출력을 조용히 손상시킬 수 있습니다.
- 직접 CSV 쓰기는 추가적인 서식 아티팩트를 유발할 수 있는 중간 형식을 피합니다.
결과적으로 생성된 CSV 파일은 더 안정적이고 자동화된 처리에 적합합니다. PDF 문서에서 표를 추출하는 단계별 가이드는 상세 가이드: PDF에서 표 추출을 참조하십시오.
실제 PDF 표 시나리오 처리
실제 워크플로에서 PDF 표는 종종 화면에 보이는 것과 다르게 동작합니다. 일반적인 문제점은 다음과 같습니다.
- 반복되거나 누락된 헤더가 있는 여러 페이지에 걸친 표
- 페이지 간 약간의 열 위치 이동
- 비어 있거나, 줄 바꿈되거나, 불규칙한 셀이 있는 행
- 유사하지만 동일하지 않은 레이아웃을 가진 대량의 PDF
이러한 요소는 일반적으로 일반 내보내기 도구 및 온라인 변환기가 일관성 없는 CSV 출력을 생성하기 시작하는 부분입니다.
실용적인 관점에서 프로그래밍 방식 추출은 다음을 허용하기 때문에 이러한 경우에 더 적합합니다.
- 관련 없는 표를 실수로 병합하지 않고 페이지별 처리
- 여러 페이지에 걸친 표의 제어된 처리
- 레이아웃이 완벽하게 균일하지 않은 경우에도 안정적인 열 정렬
주목할 만한 추가적인 사용성 세부 정보는 CSV 인코딩입니다.
- 추출된 데이터에 비 ASCII 문자가 포함된 경우 Excel에서 직접 연 CSV 파일에 깨진 텍스트가 표시될 수 있습니다.
- CSV 출력을 BOM이 있는 UTF-8(UTF-8-SIG)로 저장하면 수동 가져오기 단계 없이 올바른 문자 표시를 보장하는 데 도움이 됩니다.
이러한 고려 사항은 이상적인 예제가 아닌 실제 PDF로 작업할 때 특히 관련이 있습니다.
주요 내용: PDF 표를 CSV로 변환하기
실제로 PDF 표를 CSV로 변환하는 것은 일반적으로 세 가지 옵션으로 귀결됩니다.
- Acrobat 내보내기는 단일 페이지 송장이나 보고서와 같이 가끔 시각적으로 확인된 변환에 적합합니다.
- 온라인 변환기는 간단한 표가 있는 간단한 일회성 작업에 편리합니다.
- 프로그래밍 방식 추출은 복잡하거나 여러 페이지에 걸친 또는 반복적인 워크플로, 특히 자동화된 파이프라인에서 가장 신뢰할 수 있는 결과를 제공합니다.
올바른 방법을 선택하는 것은 도구 자체보다는 추출된 데이터를 어떻게 사용할 것인지에 더 많이 좌우됩니다.
자주 묻는 질문
스캔한 PDF 표를 CSV로 직접 변환할 수 있습니까?
아니요. 스캔한 PDF는 표 추출이 가능하기 전에 OCR이 필요합니다. Python을 사용하여 스캔한 PDF에서 텍스트를 추출하는 단계별 가이드는 Python으로 스캔한 PDF에서 텍스트 추출을 참조하십시오.
추출된 PDF 표에 대해 CSV가 Excel보다 낫습니까? CSV는 더 간단하고 자동화에 더 적합하며, Excel은 종종 수동 검토에 선호됩니다.
Python은 일괄 PDF 표 변환에 적합합니까? 예. Python은 유연성과 가독성으로 인해 대규모 및 자동화된 PDF 표 추출에 널리 사용됩니다.