
초안을 정리할 때 PDF 파일에서 하이라이트를 제거하는 방법을 아는 것은 필수적인 기술입니다. 하이라이트는 핵심 사항을 강조하는 데 도움이 되지만, 복잡한 마크업은 가독성을 저해할 수 있습니다. 이 가이드에서는 온라인 도구, Adobe Acrobat 및 Python 자동화를 사용하여 PDF의 모든 하이라이트를 한 번에 삭제하거나 특정 마크업을 선택적으로 지우는 가장 효과적인 방법을 살펴봅니다.
온라인에서 무료로 PDF 하이라이트 제거: 빠른 웹 해결책
Acrobat 없이 PDF 하이라이트를 제거해야 하는 사용자에게 온라인 플랫폼은 PDF 파일을 정리하는 가장 빠른 솔루션입니다. 이러한 도구는 장치에 소프트웨어를 설치하지 않고 일회성 작업에 이상적입니다.
이를 처리하는 가장 직관적인 방법 중 하나는 Smallpdf를 이용하는 것입니다. 하이라이트를 대화형 개체로 취급하여 하이라이트 제거 프로세스를 원활하게 만듭니다.
온라인에서 하이라이트를 지우는 빠른 단계:
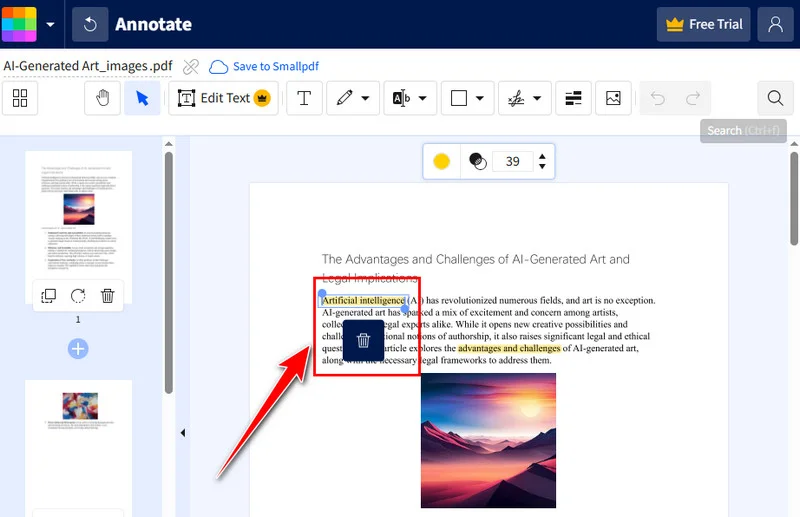
- 편집기 액세스: Smallpdf 홈페이지에서 PDF 편집기 도구로 이동합니다.
- 파일 업로드: 장치 또는 클라우드 저장소에서 문서를 끌어다 놓습니다.
- 마크업 선택: 노란색 하이라이트를 직접 클릭하여 선택 상자를 활성화합니다.
- 삭제 실행: 선택되면 키보드의 Delete 키를 누르거나 텍스트 위에 나타나는 휴지통 아이콘을 클릭하기만 하면 됩니다.
- 마무리 및 내보내기: 다운로드를 클릭하여 파일을 즉시 저장합니다. 또는 마무리를 선택하여 미리보기 모드로 들어가 Microsoft Word 또는 Excel과 같은 다른 형식으로 다운로드하거나 다른 이름으로 내보내기를 선택할 수 있습니다.
프로 팁: "고집스러운" 하이라이트 문제 해결
하이라이트가 선택되지 않는 경우 편집기가 "주석 모드"로 특별히 전환되었는지 확인하십시오. 하이라이트가 이미지 자체에 병합된 스캔된 문서의 경우 흰색 모양 오버레이를 사용하여 하이라이트 색상을 수동으로 가릴 수 있습니다.
참고: 보안 및 저장소 대부분의 온라인 무료 도구는 파일 저장을 위한 세션 창이 제한되어 있으므로 항상 사본을 즉시 다운로드하십시오. 또한 민감하거나 기밀인 데이터에 주의하십시오. 이러한 서비스는 파일을 타사 서버에 업로드할 수 있으므로 개인 정보 보호를 위해 Free Spire.PDF 및 Adobe Acrobat과 같은 로컬 방법을 사용하는 것이 좋습니다.
전문적인 정밀도: Adobe Acrobat에서 PDF 하이라이트를 제거하는 방법
복잡한 법률 문서의 경우 Adobe Acrobat Pro가 업계 표준입니다. 복잡한 텍스트 마크업을 관리하는 데 필요한 정밀도를 제공합니다. 전용 "주석" 창에서 모든 주석 관리를 지원합니다.
이 방법은 원본 문서 생성 중에 추가되었을 수 있는 하이라이트와 배경 채우기를 구별해야 할 때 적합합니다.
단계별 지침:
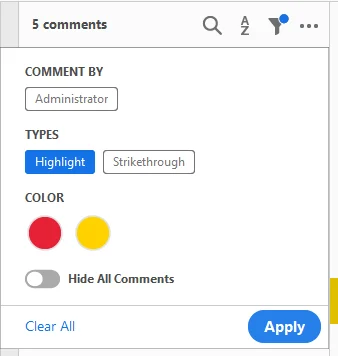
- 주석 창 열기: 오른쪽 도구 모음에서 주석 도구를 선택합니다. 그러면 모든 마크업이 시간순으로 나열됩니다.
- 필터링 및 찾기: 유형, 작성자 또는 색상별로 정렬할 수 있습니다. 이것은 다른 주석은 그대로 유지하면서 PDF에서 하이라이트만 제거하려는 경우에 특히 유용합니다.
-
일괄 또는 단일 삭제:
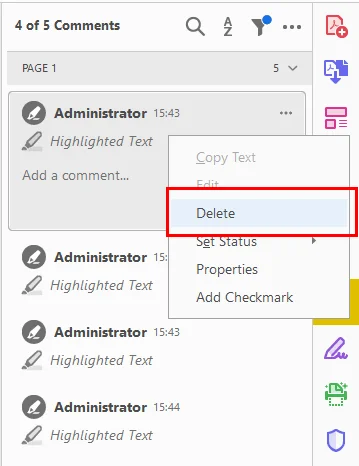
- 하나를 제거하려면: 페이지 또는 목록의 하이라이트를 마우스 오른쪽 버튼으로 클릭하고 삭제를 선택합니다.
- PDF의 모든 하이라이트를 한 번에 삭제하려면: Ctrl 키를 누른 상태에서 제거하려는 목록의 각 주석을 수동으로 클릭한 다음 마우스 오른쪽 버튼을 클릭하고 삭제를 선택합니다.
- 시스템 대안: Mac을 사용하는 경우 하이라이트를 선택하고 백스페이스를 눌러 Mac 미리보기를 통해 기본 제거를 수행하거나 매우 간단한 주석 레이어의 경우 Chrome의 PDF 뷰어를 통해서도 가능합니다.
참고: 필요한 경우 원본 문서의 메타데이터를 보존하기 위해 편집 후 새 버전으로 "다른 이름으로 저장"해야 합니다.
또한 읽기: PDF에서 텍스트를 하이라이트하는 방법: 5가지 쉬운 방법
개발자의 선택: Free Spire.PDF for Python으로 자동화
대량의 데이터를 처리하는 개발자에게 수동 클릭은 비효율적입니다. Free Spire.PDF for Python과 같은 라이브러리를 사용하면 전체 디렉토리에서 PDF 파일의 하이라이트를 몇 초 만에 프로그래밍 방식으로 제거할 수 있습니다.
기본 구현: 한 번에 모든 마크업 지우기
Free Spire.PDF는 하이라이터가 PdfTextMarkupAnnotationWidget 개체로 저장되는 Annotations 컬렉션에 대한 액세스를 제공합니다. 이 클래스는 취소선 및 밑줄과 같은 다른 텍스트 마크업도 포함하므로, 저희 구현에는 하이라이트만 대상으로 지정하고 제거되도록 TextMarkupAnnotationType에 대한 특정 검사가 포함됩니다.
다음은 PDF에서 모든 하이라이트를 한 번에 삭제하는 방법을 보여주는 코드 예제입니다.
from spire.pdf.common import *
from spire.pdf import *
# Initialize the PdfDocument object
pdf = PdfDocument()
# Load the PDF file
pdf.LoadFromFile("/input/sample.pdf")
# Iterate through each page in the document
for i in range(pdf.Pages.Count):
page = pdf.Pages[i]
# Access the collection of annotations for the current page
annotations = page.Annotations
# Iterate through annotations in reverse order
for j in range(annotations.Count - 1, -1, -1):
annot = annotations[j]
# Check if the annotation is a text markup type (highlights, underlines, etc.)
if isinstance(annot, PdfTextMarkupAnnotationWidget):
# Verify if the specific markup type is a Highlight
if annot.TextMarkupAnnotationType == PdfTextMarkupAnnotationType.Highlight:
# Remove the highlight annotation from the collection
annotations.RemoveAt(j)
# Save the modified document
pdf.SaveToFile("/output/HighlightsRemoved.pdf")
pdf.Close()
다음은 원본 PDF와 정리된 PDF의 미리보기입니다.
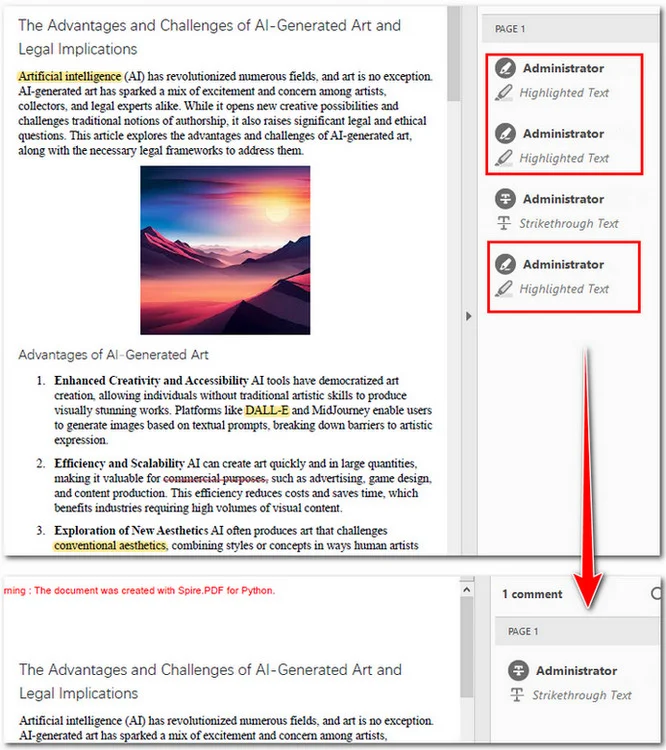
PDF의 세 가지 하이라이트가 삭제되고 취소선은 보존된 것을 볼 수 있습니다.
고급 제어: 인덱스 또는 속성별 선택적 제거
때로는 전체 삭제가 불필요할 수 있습니다. 페이지의 두 번째 하이라이트와 같이 특정 주석만 제거하거나 작성자 또는 내용과 같은 메타데이터를 기반으로 하이라이트를 필터링하고 싶을 수 있습니다.
먼저 주석을 목록으로 필터링하여 특정 인스턴스를 대상으로 지정할 수 있습니다. 다음은 첫 페이지에서 발견된 두 번째 하이라이트를 제거하는 구현입니다.
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object and load a PDF file
doc = PdfDocument()
doc.LoadFromFile("/input/sample.pdf")
# Get the annotations collection of the first page
annotations = doc.Pages[0].Annotations
# Loop through annotations collection and get the highlights
highlights = []
for i in range(annotations.Count):
if isinstance(annotations[i], PdfTextMarkupAnnotationWidget):
highlights.append(annotations[i])
# Remove the second highlight
annotations.Remove(highlights[1])
# Save the document
doc.SaveToFile("/output/RemoveSecondHighlight.pdf")
doc.Close()
다음은 원본 PDF와 출력 파일의 미리보기입니다.
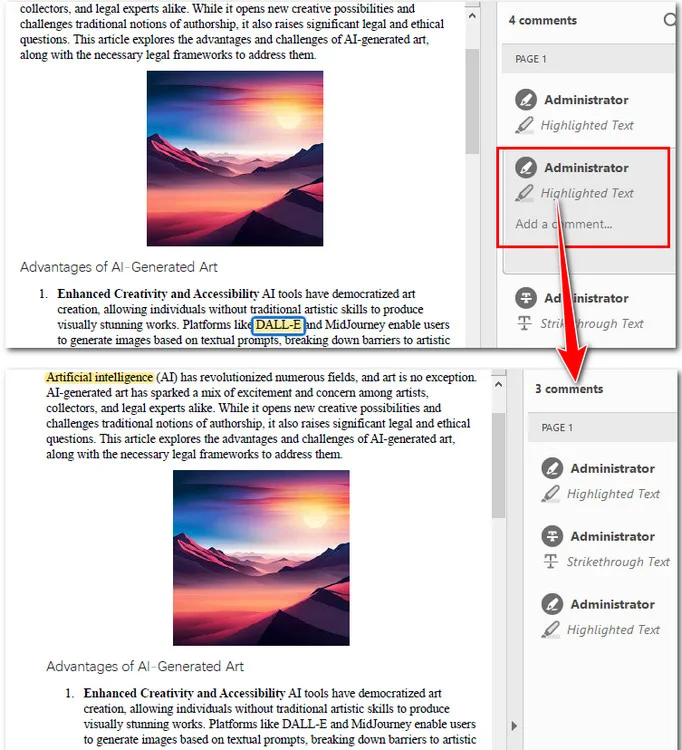
참고: 프로그래밍 라이브러리는 "주석" 레이어만 감지할 수 있습니다. 하이라이트가 콘텐츠 스트림에 병합된 경우 PDF를 OCR하거나 좌표 기반 화이트아웃 기술을 사용해야 합니다.
최종 비교: 어떤 방법을 선택해야 할까요?
우리가 살펴본 바와 같이, PDF 파일에서 하이라이트를 제거하는 이상적인 방법은 특정 워크플로, 문서의 양 및 기술 수준에 따라 다릅니다. 다음 표는 필요에 가장 효율적인 도구를 선택하는 데 도움이 되는 병렬 분석을 제공합니다.
| 기능 | 온라인 도구 | Adobe Acrobat | Free Spire.PDF (Python) |
|---|---|---|---|
| 노력 | 낮음 (일회성) | 중간 (수동) | 높음 (초기 설정) |
| 속도 | 빠름 | 일괄 처리 시 느림 | 일괄 처리 시 매우 빠름 |
| 비용 | 무료 (일반적으로) | 유료 구독 | 무료 |
| 개인 정보 보호 | 낮음 (클라우드) | 높음 (로컬) | 가장 높음 (로컬/암호화) |
결론
이 가이드에서는 PDF 파일에서 하이라이트를 제거하는 세 가지 방법을 설명했습니다. Smallpdf와 같은 온라인 도구는 빠른 작업에 적합하며, Adobe Acrobat은 전문적인 문서 관리에 필요한 수동 정밀도를 제공합니다. 개발자에게는 Free Spire.PDF for Python이 대용량 자동화 및 데이터 개인 정보 보호에 이상적입니다.
이러한 다양한 접근 방식을 이해함으로써 복잡하게 마크업된 문서를 몇 초 만에 깨끗하고 전문적인 PDF로 변환할 수 있습니다. 생산성을 유지하고 체계적으로 작업하기 위해 워크플로에 가장 적합한 방법을 실험해 보십시오.