스프레드시트 데이터를 웹 애플리케이션에 업로드하거나, REST API를 구축하거나, NoSQL 데이터베이스로 데이터를 마이그레이션해야 했던 경험이 있다면, 일반적인 문제에 직면했을 것입니다. Excel은 데이터를 JSON으로 저장하는 내장 기능을 제공하지 않습니다.
다행히도 빠른 온라인 변환기부터 Python의 프로그래밍 방식 솔루션까지 Excel을 JSON으로 내보내는 여러 가지 방법이 있습니다. 가장 좋은 방법은 파일 크기, 보안 요구 사항, 여러 워크시트나 수식 결과와 같은 통합 문서 구조를 유지해야 하는지에 따라 달라집니다.
이 가이드에서는 가장 실용적인 접근 방식을 비교하고 시나리오에 맞는 올바른 솔루션을 선택하도록 도와드리겠습니다.
빠른 탐색
- Excel을 JSON으로 내보내야 하는 이유
- JSON 형식의 Excel 데이터는 어떻게 보이나요?
- 방법 1: Excel을 JSON으로 온라인에서 내보내기
- 방법 2: Pandas를 사용하여 Python에서 Excel을 JSON으로 내보내기
- 방법 3: Spire.XLS를 사용하여 Python에서 Excel을 JSON으로 내보내기
- Excel을 JSON으로 변환할 때 일반적인 문제
- 어떤 방법을 선택해야 할까요?
- 자주 묻는 질문
Excel을 JSON으로 내보내야 하는 이유
Excel은 구조화된 데이터를 저장하는 데 가장 널리 사용되는 도구이지만, 최신 애플리케이션은 JSON으로 통신합니다. 스프레드시트 데이터가 웹 컨텍스트로 이동해야 할 때마다 이러한 형식 간의 변환이 필수적입니다.
일반적인 사용 사례는 다음과 같습니다.
- 웹 애플리케이션으로 스프레드시트 데이터 전송
- REST API로 데이터 가져오기
- React, Vue 또는 Angular와 같은 JavaScript 프레임워크 작업
- MongoDB와 같은 NoSQL 데이터베이스로 데이터 마이그레이션
- 통합 파이프라인에서 시스템 간 데이터 교환
Excel에는 기본 "JSON으로 저장" 옵션이 없으므로 이 간극을 메우기 위해 외부 도구나 라이브러리가 필요합니다.
JSON 형식의 Excel 데이터는 어떻게 보이나요?
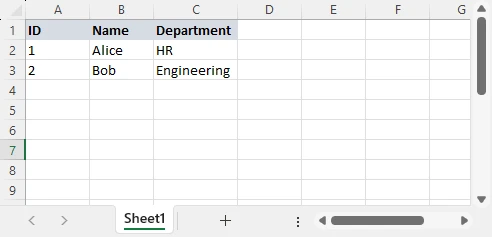
Excel 행은 일반적으로 JSON 객체로 변환되고, 열 헤더는 객체 키가 됩니다.
Excel 데이터:
JSON 출력:
[
{"ID": 1, "Name": "Alice", "Department": "HR"},
{"ID": 2, "Name": "Bob", "Department": "Engineering"}
]
각 행은 JSON 객체가 되고, 각 열 헤더는 키가 되며, 전체 워크시트는 배열이 됩니다. XLS 및 XLSX 파일 모두 동일한 매핑 패턴을 따릅니다.
방법 1: Excel을 JSON으로 온라인에서 내보내기
온라인 Excel-to-JSON 변환기는 소프트웨어 설치나 프로그래밍 지식 없이 일회성 변환을 위한 가장 빠른 솔루션을 제공합니다.
Excel을 JSON으로 온라인에서 변환하는 단계
-
Excel 파일 업로드: 로컬 저장소에서 .xlsx 또는 .xls 파일을 선택합니다. 대부분의 플랫폼은 드래그 앤 드롭을 지원합니다.
-
옵션 구성: 헤더 포함 여부, 특정 워크시트 선택 또는 출력 형식 지정 여부를 지정합니다.
-
변환 및 다운로드: 서버에서 파일을 처리하고 JSON 출력을 생성합니다. 변환된 파일을 검색하거나 결과를 복사합니다.
권장 온라인 Excel-to-JSON 변환기
다양한 도구가 다양한 시나리오에 적합합니다.
| 도구 | 가장 적합한 용도 | 파일 크기 제한 | 특수 기능 |
|---|---|---|---|
| TableConvert | 테이블 기반 JSON 구조 | 10MB | 사용자 지정 JSON 형식, 중첩 객체 |
| Data Formatter Pro | 브라우저에서 빠른 변환 | 5MB | 브라우저 측 변환, 업로드 불필요 |
| JSON Editor Online | 변환 후 시각적 편집 | 5MB | 내장 JSON 유효성 검사기 및 형식 지정기 |
장점 및 제한 사항
장점:
- 설치 불필요 — 모든 브라우저에서 액세스 가능
- 5MB 미만의 작은 파일에 대해 빠름
- 그래픽 인터페이스로 초보자 친화적
제한 사항:
- 파일 크기 제한: 대부분의 무료 변환기는 5-10MB로 업로드를 제한합니다.
- 개인 정보 보호 문제: 외부 서버에 비즈니스 데이터를 업로드하면 규정 준수 위험이 발생합니다.
- 수식 처리: 온라인 변환기는 수식 결과를 정적 값으로 내보냅니다.
- 여러 워크시트: 많은 도구가 활성 워크시트만 내보내거나 시트 구조를 잃습니다.
온라인 변환기는 빠르고 민감하지 않은 변환에 적합합니다. 대용량 파일, 기밀 데이터 또는 복잡한 통합 문서와 관련된 모든 작업에는 프로그래밍 방식 솔루션이 필요합니다.
방법 2: Pandas를 사용하여 Python에서 Excel을 JSON으로 내보내기
Pandas는 Python에서 가장 인기 있는 데이터 분석 라이브러리로, DataFrame API를 통해 간단한 Excel-to-JSON 변환을 제공합니다. 이 방법은 이미 데이터 조작에 Pandas를 사용하는 데이터 과학자 및 분석가에게 적합합니다.
Pandas 및 종속성 설치
pip install pandas openpyxl
이전 .xls 파일의 경우 xlrd도 설치합니다.
pip install xlrd
Excel 읽기 및 JSON 내보내기
import pandas as pd
# Excel 파일을 DataFrame으로 로드
df = pd.read_excel("sales_report.xlsx")
# DataFrame을 JSON으로 내보내기
df.to_json(
"sales_report.json",
orient="records",
indent=4
)
print("Excel 데이터가 JSON으로 성공적으로 내보내졌습니다.")
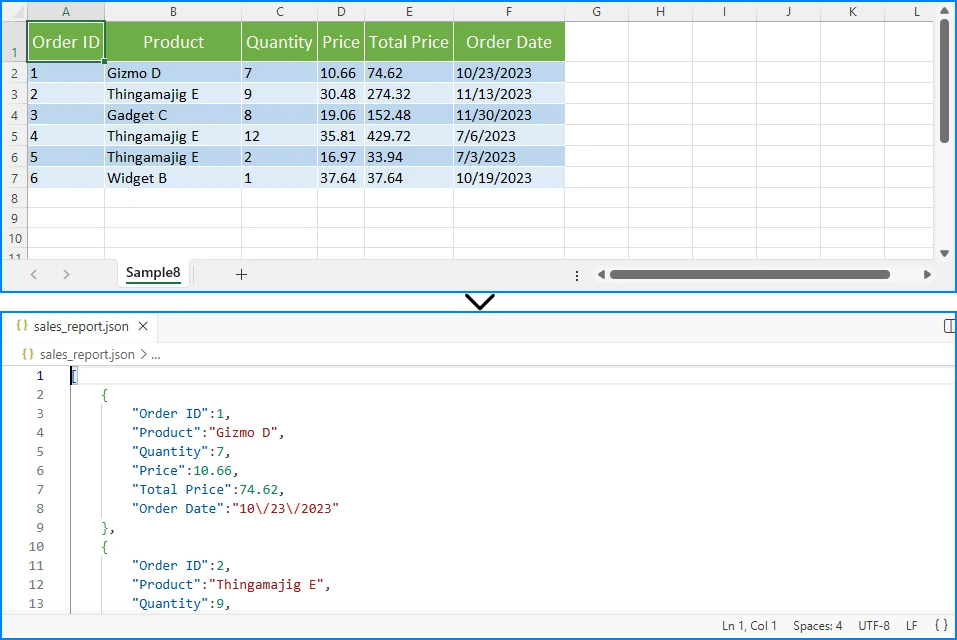
아래는 Excel 워크시트와 JSON 출력의 예시입니다.
주요 매개변수:
-
orient="records": 출력을 객체 배열(가장 일반적인 형식)으로 구조화합니다. -
indent=4: 4칸 들여쓰기로 JSON을 보기 좋게 출력합니다.
JSON 출력 옵션 이해
Pandas는 orient 매개변수를 통해 여러 출력 방향을 제공합니다.
orient="records" (API에 권장):
[
{"ID": 1, "Name": "Alice", "Department": "HR"},
{"ID": 2, "Name": "Bob", "Department": "Engineering"}
]
orient="index":
{
"0": {"ID": 1, "Name": "Alice", "Department": "HR"},
"1": {"ID": 2, "Name": "Bob", "Department": "Engineering"}
}
orient="split":
{
"columns": ["ID", "Name", "Department"],
"index": [0, 1],
"data": [[1, "Alice", "HR"], [2, "Bob", "Engineering"]]
}
records 방향은 REST API 및 JavaScript 애플리케이션에 가장 널리 호환되는 형식입니다.
특정 워크시트 처리
import pandas as pd
# 특정 워크시트를 이름으로 읽기
df = pd.read_excel("workbook.xlsx", sheet_name="Q4_Sales")
# 특정 워크시트를 인덱스로 읽기 (0부터 시작)
df = pd.read_excel("workbook.xlsx", sheet_name=0)
df.to_json("q4_sales.json", orient="records", indent=4)
Pandas는 필터링, 집계 또는 변환 후 내보내기가 필요한 데이터 분석에 탁월합니다. 그러나 전체 파일을 메모리로 로드하고 수식 논리를 유지할 수 없으므로 대용량 파일이나 엔터프라이즈 시나리오에는 적합하지 않습니다.
Excel-to-JSON 변환은 종종 데이터 워크플로의 한 단계일 뿐입니다. JSON 데이터를 다시 스프레드시트로 가져와야 하는 경우, 완전한 양방향 데이터 교환 솔루션을 위해 JSON을 Excel로 변환하는 방법에 대한 튜토리얼을 참조하십시오.
방법 3: Spire.XLS를 사용하여 Python에서 Excel을 JSON으로 내보내기
Spire.XLS for Python은 Pandas가 부족한 시나리오를 위해 설계된 전문 Excel 처리 라이브러리를 제공합니다. 복잡한 통합 문서 구조를 처리하고, 수식 계산을 유지하며, 전체 데이터 세트를 메모리로 로드하지 않고 대용량 파일을 효율적으로 처리합니다.
Spire.XLS for Python 설치
pip install Spire.XLS
Excel 데이터를 JSON으로 내보내기
from spire.xls import Workbook
import json
# 통합 문서 인스턴스 생성
workbook = Workbook()
workbook.LoadFromFile("sales_data.xlsx")
# 첫 번째 워크시트 가져오기
sheet = workbook.Worksheets[0]
# 데이터를 구조화된 형식으로 추출
data = []
headers = []
# 첫 번째 행에서 헤더 읽기
for col in range(sheet.AllocatedRange.Columns.Count):
cell = sheet.AllocatedRange.Rows[0].Cells[col]
headers.append(cell.Value)
# 데이터 행 읽기
for row_idx in range(1, sheet.AllocatedRange.Rows.Count):
row_data = {}
row = sheet.AllocatedRange.Rows[row_idx]
for col_idx in range(len(headers)):
cell = row.Cells[col_idx]
row_data[headers[col_idx]] = cell.Value
data.append(row_data)
# JSON 파일로 내보내기
with open("sales_data.json", "w", encoding="utf-8") as f:
json.dump(data, f, indent=4, ensure_ascii=False)
print(f"{len(data)}개의 레코드가 JSON으로 내보내졌습니다.")
workbook.Dispose()
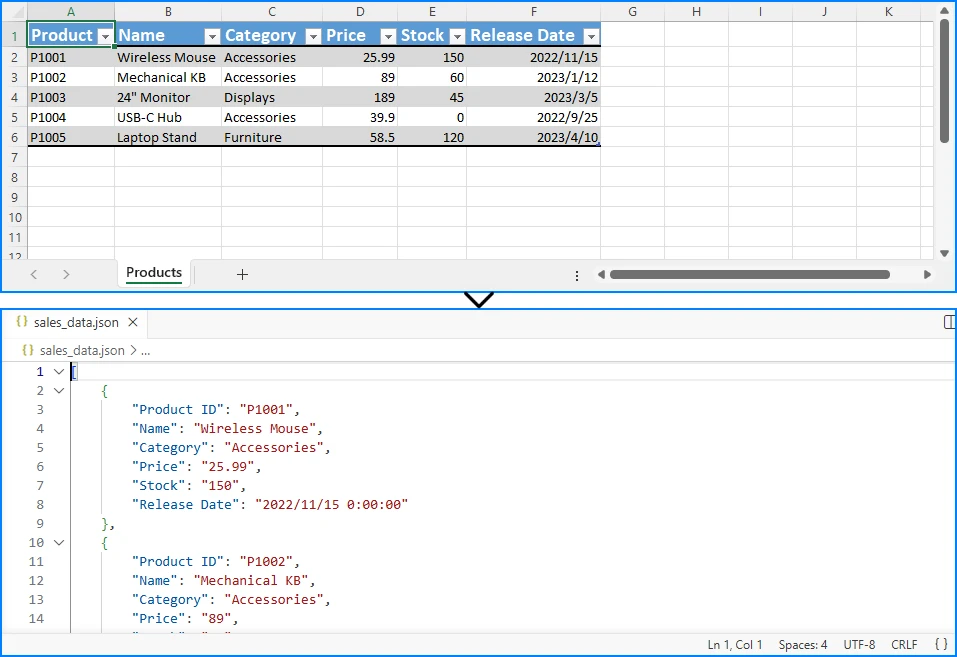
변환 결과는 다음과 같습니다.
주요 사항
-
통합 문서 로드:
Workbook.LoadFromFile()을 사용하여 Excel 파일을 메모리로 로드합니다. 이 메서드는 XLS 및 XLSX 형식을 모두 지원합니다. -
워크시트 액세스:
workbook.Worksheets[index]를 사용하여 특정 워크시트를 검색합니다. 여기서 index 0은 첫 번째 시트를 나타냅니다. -
헤더 추출: 할당된 범위의 첫 번째 행(
sheet.AllocatedRange.Rows[0])을 반복하여 열 헤더를 수집합니다. 이 헤더는 JSON 객체 키로 사용됩니다. -
데이터 행 읽기: 나머지 행(인덱스 1부터 시작)을 반복하고 셀 값을 추출합니다. 각 행에 대해 헤더와 셀 값을 매핑하는 사전을 만듭니다.
-
JSON으로 내보내기: Python의 내장
json.dump()함수를 사용하여 데이터 구조를 JSON 파일에 올바른 형식(indent=4)과 유니코드 지원(ensure_ascii=False)으로 씁니다.
JSON은 데이터 교환에 사용되는 유일한 형식은 아닙니다. 보고 또는 시스템 통합을 위해 더 간단한 테이블 형식으로 내보내려면 Python에서 Excel을 CSV로 변환하는 방법에 대한 가이드를 참조하십시오.
여러 워크시트를 JSON으로 내보내기
Spire.XLS의 주요 장점 중 하나는 구조를 유지하면서 다중 시트 통합 문서를 처리하는 것입니다.
from spire.xls import Workbook
import json
workbook = Workbook()
workbook.LoadFromFile("quarterly_reports.xlsx")
workbook_data = {}
for sheet_index in range(workbook.Worksheets.Count):
sheet = workbook.Worksheets[sheet_index]
sheet_name = sheet.Name
sheet_data = []
headers = []
last_row = sheet.LastRow
last_col = sheet.LastColumn
if last_row > 0 and last_col > 0:
# 헤더 읽기
for col in range(1, last_col + 1):
cell_value = sheet.Range[1, col].Value
headers.append(cell_value if cell_value else f"Column{col}")
# 데이터 행 읽기
for row in range(2, last_row + 1):
row_data = {}
has_data = False
for col in range(1, last_col + 1):
cell = sheet.Range[row, col]
value = cell.Value
# 수식 셀 처리 - 계산된 결과 내보내기
if cell.HasFormula:
value = cell.FormulaValue
row_data[headers[col - 1]] = value
if value is not None and str(value).strip():
has_data = True
if has_data:
sheet_data.append(row_data)
workbook_data[sheet_name] = sheet_data
print(f"처리됨: {sheet_name} ({len(sheet_data)} 행)")
with open("quarterly_reports.json", "w", encoding="utf-8") as f:
json.dump(workbook_data, f, indent=4, ensure_ascii=False)
print(f"{workbook.Worksheets.Count}개의 워크시트가 JSON으로 내보내졌습니다.")
workbook.Dispose()
출력 구조:
{
"Q1_Sales": [
{"Product": "Widget A", "Revenue": 15000, "Units": 500},
{"Product": "Widget B", "Revenue": 22000, "Units": 730}
],
"Q2_Sales": [
{"Product": "Widget A", "Revenue": 18000, "Units": 600},
{"Product": "Widget B", "Revenue": 25000, "Units": 830}
]
}
Spire.XLS 사용의 이점
- 통합 문서 구조 유지: JSON 출력에서 워크시트 구성을 유지합니다.
- 수식 올바르게 처리: 수식 셀에서 계산된 값을 내보냅니다.
- 메모리 효율적인 처리: 전체 파일을 메모리로 로드하지 않고 대용량 통합 문서를 처리합니다.
- Excel 종속성 없음: Microsoft Excel 설치 없이 파일을 처리합니다.
- 크로스 플랫폼: Windows, Linux 및 macOS에서 실행됩니다.
Pandas vs Spire.XLS 비교
| 기능 | Pandas | Spire.XLS |
|---|---|---|
| 오픈 소스 | ✓ | ✗ |
| 데이터 분석 | ✓ | ✓ |
| 수식 결과 | 제한적 | ✓ |
| 여러 워크시트 | 기본 | ✓ |
| 엔터프라이즈 자동화 | 제한적 | ✓ |
| 메모리 효율성 | 보통 | ✓ |
| 대용량 파일 지원 | 제한적 | ✓ |
계층적 또는 스키마 기반 데이터 교환이 필요한 시스템의 경우 Python에서 Excel을 XML로 변환하는 방법에 대한 가이드도 배울 수 있습니다.
Excel을 JSON으로 변환할 때 일반적인 문제
여러 워크시트
통합 문서는 종종 여러 관련 워크시트를 포함합니다. 모든 시트를 단일 평면 배열로 내보내면 구성 구조가 손실됩니다. Spire.XLS와 같은 라이브러리를 사용하여 JSON 출력에서 최상위 키로 워크시트 이름을 유지합니다.
수식 셀
Excel 수식은 동적으로 값을 계산합니다. JSON으로 내보낼 때 일반적으로 수식 문자열이 아닌 계산된 결과를 원합니다. Spire.XLS는 FormulaValue 속성을 제공하여 계산된 값을 내보내고, Pandas는 기본적으로 표시된 값을 읽습니다.
날짜 형식
Excel은 날짜를 숫자 일련 번호로 저장합니다. 명시적인 처리가 없으면 날짜가 "2026-05-01" 대신 45662와 같은 의미 없는 숫자로 내보내질 수 있습니다. JSON 호환성을 위해 날짜 열을 ISO 8601 문자열로 변환합니다.
빈 셀 및 null 값
빈 셀은 null로 표시되거나, 완전히 생략되거나, 빈 문자열로 내보내질 수 있습니다. 데이터 의도를 유지하기 위해 누락된 값에는 null을, 명시적으로 빈 셀에는 빈 문자열을 사용합니다.
어떤 방법을 선택해야 할까요?
| 시나리오 | 권장 방법 | 이유 |
|---|---|---|
| 빠른 일회성 변환 | 온라인 변환기 | 설정 불필요, 가끔 사용 시 가장 빠름 |
| 데이터 분석 워크플로 | Pandas | 분석 파이프라인과 통합 |
| 여러 시트가 있는 복잡한 통합 문서 | Spire.XLS | 구조 유지, 수식 처리 |
| 대용량 파일 (>100MB) | Spire.XLS | 메모리 효율적인 처리 |
| 민감/기밀 데이터 | Spire.XLS (로컬) | 외부 서버 전송 없음 |
자주 묻는 질문
Excel을 직접 JSON으로 저장할 수 있나요?
아니요. Excel의 "다른 이름으로 저장" 대화 상자는 XLSX, XLS, CSV, PDF 및 XML은 지원하지만 JSON은 지원하지 않습니다. Excel 데이터를 JSON으로 내보내려면 온라인 변환기, Python 라이브러리 또는 사용자 지정 스크립트가 필요합니다.
Excel 데이터를 JSON 파일로 내보내려면 어떻게 해야 하나요?
도구를 선택하고, Excel 파일을 로드하고, 워크시트 데이터를 추출하고, 행을 열 헤더를 키로 하는 JSON 객체로 변환하고, 출력을 .json 파일에 씁니다.
Pandas 사용:
import pandas as pd
df = pd.read_excel("data.xlsx")
df.to_json("data.json", orient="records", indent=4)
Excel을 JSON으로 변환하는 데 가장 좋은 Python 라이브러리는 무엇인가요?
- Pandas: 강력한 변환 기능을 갖춘 데이터 분석 워크플로에 가장 적합하지만, 전체 파일을 메모리로 로드하고 수식을 유지할 수 없습니다.
- Spire.XLS: 대용량 파일, 여러 워크시트 및 수식 처리가 필요한 엔터프라이즈 시나리오에 가장 적합합니다.
여러 워크시트를 JSON으로 내보내려면 어떻게 해야 하나요?
Spire.XLS를 사용하여 워크시트를 반복하고 시트 이름을 키로 하는 사전으로 구성합니다.
from spire.xls import Workbook
import json
workbook = Workbook()
workbook.LoadFromFile("multi_sheet.xlsx")
result = {}
for sheet in workbook.Worksheets:
sheet_data = [] # 시트 데이터 추출
# ... 추출 로직 ...
result[sheet.Name] = sheet_data
with open("output.json", "w") as f:
json.dump(result, f, indent=4)
Excel-to-JSON 변환 중에 수식을 유지할 수 있나요?
JSON은 정적 데이터 형식이므로 수식 자체는 JSON으로 유지할 수 없습니다. 그러나 수식의 계산된 결과를 내보낼 수 있습니다. Spire.XLS의 FormulaValue 속성을 사용하여 수식 문자열 대신 계산된 값을 가져옵니다.
JSON으로 내보낼 때 대용량 Excel 파일을 어떻게 처리하나요?
대용량 파일의 경우 Pandas를 피하세요. 모든 것을 메모리로 로드합니다. 메모리 효율적인 셀별 액세스를 위해 Spire.XLS를 사용합니다. 매우 큰 데이터 세트의 경우 각 줄이 별도의 JSON 객체인 줄 구분 JSON(JSONL) 형식을 고려하여 스트리밍 처리를 가능하게 합니다.
결론
Excel을 JSON으로 내보내는 것은 스프레드시트 데이터와 최신 애플리케이션 간의 간극을 연결합니다. 빠른 변환의 경우 온라인 도구를 사용하면 설정 없이 작업을 완료할 수 있습니다. 데이터 분석 기능이 필요한 경우 Pandas는 강력한 변환 기능을 제공합니다. 대용량 파일, 여러 워크시트 또는 수식 처리가 필요한 엔터프라이즈 시나리오의 경우 Spire.XLS는 필요한 제어력과 정확성을 제공합니다. 파일 크기, 복잡성 및 워크플로 요구 사항에 따라 선택하십시오.
추가 자료: