
Java (485)

JSON is widely used for data exchange in REST APIs, web services, and enterprise applications. However, business users often prefer Excel for reporting, filtering, and data analysis. As a result, developers frequently need to convert JSON to Excel in Java when exporting API responses, generating reports, or sharing structured data with non-technical users.
While Java provides several JSON libraries, transforming data into a well-structured Excel file requires handling column headers, cell types, row iteration, and output formats — all of which become tedious without the right tool. Spire.XLS for Java simplifies this with a clean API that creates Excel workbooks without relying on Microsoft Office.
In this article, you'll learn how to convert JSON to Excel in Java using Spire.XLS for Java and Jackson. We'll cover JSON array conversion, nested JSON handling, JSON file processing, XLSX and XLS export, auto-fitting, formatting, and best practices for working with large datasets.
Quick Navigation
- Why Convert JSON to Excel in Java
- Install Spire.XLS for Java
- Prepare JSON Data
- Convert JSON to Excel in Java — Step by Step
- Complete Java Code to Convert JSON to Excel
- Export JSON to XLSX in Java
- Convert Nested JSON to Excel in Java
- Convert a JSON File to Excel
- Auto-Fit Rows and Columns in Excel
- Apply Formatting to the Exported Excel File
- Common Challenges When Converting JSON to Excel
- Why Use Spire.XLS for Java
- Conclusion
- FAQ
1. Why Convert JSON to Excel in Java
JSON is widely used for data exchange in REST APIs, web services, and enterprise applications because it is lightweight and easy for machines to process. However, business users often need Excel files for reporting, filtering, visualization, and further analysis.
Converting JSON to Excel in Java helps bridge the gap between backend systems and business workflows. Common use cases include:
Export API Data
Many REST APIs return JSON responses. Converting these responses into Excel allows users to review, filter, and analyze data without manually processing raw JSON.
Generate Reports
Java applications can transform JSON data from APIs, databases, or other sources into structured Excel reports with headers, formatting, and organized tables.
Share Structured Data
Excel files are easier to distribute and analyze using tools such as charts, formulas, and pivot tables. Exporting JSON data to Excel gives non-technical users direct access to these features.
2. Install Spire.XLS for Java
Before converting JSON to Excel in Java, set up the following dependencies in your project.
Maven Dependency
Spire.XLS for Java is available through the e-iceblue Maven repository. Add the repository and dependency to your pom.xml:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>16.6.5</version>
</dependency>
You can also download Spire.XLS for Java and add the JAR to your project manually.
Add a JSON Library
Java does not include built-in JSON support. This guide uses Jackson, the most widely adopted JSON processing library in the Java ecosystem:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.17.2</version>
</dependency>
Import Required Classes
Include the following imports in your Java source file:
import com.spire.xls.*;
import com.spire.xls.core.spreadsheet.collections.AutoFitType;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.node.ArrayNode;
import com.fasterxml.jackson.databind.node.ObjectNode;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
3. Prepare JSON Data
To illustrate the conversion process, we will use a simple JSON array where each object represents a row and each property represents a column. This is the most common JSON structure encountered in REST API responses and data export workflows.
Example: Simple JSON Array
[
{
"ID": 1,
"Name": "Alice",
"Department": "Sales",
"Salary": 75000,
"HireDate": "2022-03-15"
},
{
"ID": 2,
"Name": "Bob",
"Department": "Marketing",
"Salary": 68000,
"HireDate": "2021-07-01"
},
{
"ID": 3,
"Name": "Carol",
"Department": "Engineering",
"Salary": 92000,
"HireDate": "2023-01-10"
}
]
The mapping between JSON and Excel is straightforward:
- Each JSON object becomes a row in the spreadsheet
- Each property key becomes a column header
- Each property value becomes a cell value in the corresponding row and column
Understanding this mapping is essential for following the code examples in the next sections.
4. Convert JSON to Excel in Java — Step by Step
The conversion process involves five steps: creating a workbook, accessing a worksheet, parsing JSON data, writing column headers, and populating cell values. This section walks through each step individually before presenting the complete code.
Step 1: Create a Workbook
The Workbook class represents an Excel file. Instantiate it to create a new, empty workbook:
Workbook workbook = new Workbook();
Step 2: Create a Worksheet
A workbook contains one or more worksheets. Access the first worksheet (created by default) and optionally rename it:
Worksheet sheet = workbook.getWorksheets().get(0);
sheet.setName("EmployeeData");
Step 3: Read JSON Data
Use Jackson's ObjectMapper to parse the JSON string into a JsonNode tree. If the root element is a JSON array, cast it to ArrayNode for iteration:
ObjectMapper mapper = new ObjectMapper();
JsonNode rootNode = mapper.readTree(jsonString);
if (!rootNode.isArray()) {
throw new IllegalArgumentException("Expected a JSON array at the root level");
}
ArrayNode jsonArray = (ArrayNode) rootNode;
Step 4: Write JSON Keys as Column Headers
Extract the field names from the first JSON object and write them to the first row of the worksheet. Spire.XLS uses 1-based row and column indices:
JsonNode firstObject = jsonArray.get(0);
int col = 1;
for (Iterator<Map.Entry<String, JsonNode>> it = firstObject.fields(); it.hasNext(); ) {
Map.Entry<String, JsonNode> entry = it.next();
sheet.get(1, col).setValue(entry.getKey());
col++;
}
Step 5: Write JSON Values to Excel Cells
Iterate through each JSON object in the array and write its values to the corresponding row. Start from row 2 since row 1 contains the headers:
for (int i = 0; i < jsonArray.size(); i++) {
JsonNode record = jsonArray.get(i);
int dataRow = i + 2;
int dataCol = 1;
for (Iterator<Map.Entry<String, JsonNode>> it = record.fields(); it.hasNext(); ) {
Map.Entry<String, JsonNode> entry = it.next();
JsonNode value = entry.getValue();
if (value.isNumber()) {
sheet.get(dataRow, dataCol).setNumberValue(value.doubleValue());
} else if (value.isBoolean()) {
sheet.get(dataRow, dataCol).setBooleanValue(value.booleanValue());
} else {
sheet.get(dataRow, dataCol).setValue(value.asText());
}
dataCol++;
}
}
This approach preserves data types — numbers and booleans are written as typed cell values rather than strings, which ensures that numeric sorting, filtering, and formula calculations work correctly in the generated Excel file.
5. Complete Java Code to Convert JSON to Excel
Here is the full, runnable program that reads a JSON string and converts it to an Excel file. This example demonstrates the complete Java code to convert JSON to Excel from start to finish:
import com.spire.xls.*;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.node.ArrayNode;
import java.io.File;
import java.util.Iterator;
import java.util.Map;
public class JsonToExcelConverter {
public static void main(String[] args) {
// Sample JSON data — an array of employee records
String jsonString = "["
+ "{\"ID\":1,\"Name\":\"Alice\",\"Department\":\"Sales\",\"Salary\":75000,\"HireDate\":\"2022-03-15\"},"
+ "{\"ID\":2,\"Name\":\"Bob\",\"Department\":\"Marketing\",\"Salary\":68000,\"HireDate\":\"2021-07-01\"},"
+ "{\"ID\":3,\"Name\":\"Carol\",\"Department\":\"Engineering\",\"Salary\":92000,\"HireDate\":\"2023-01-10\"}"
+ "]";
try {
// Parse the JSON string into a JsonNode tree
ObjectMapper mapper = new ObjectMapper();
JsonNode rootNode = mapper.readTree(jsonString);
if (!rootNode.isArray()) {
throw new IllegalArgumentException("Expected a JSON array at the root level");
}
ArrayNode jsonArray = (ArrayNode) rootNode;
// Create a new workbook and access the first worksheet
Workbook workbook = new Workbook();
Worksheet sheet = workbook.getWorksheets().get(0);
sheet.setName("EmployeeData");
// Write column headers from the first JSON object's keys
JsonNode firstObject = jsonArray.get(0);
int col = 1;
for (Iterator<Map.Entry<String, JsonNode>> it = firstObject.fields(); it.hasNext(); ) {
Map.Entry<String, JsonNode> entry = it.next();
sheet.get(1, col).setValue(entry.getKey());
col++;
}
// Write data rows from JSON values
for (int i = 0; i < jsonArray.size(); i++) {
JsonNode record = jsonArray.get(i);
int dataRow = i + 2;
int dataCol = 1;
for (Iterator<Map.Entry<String, JsonNode>> it = record.fields(); it.hasNext(); ) {
Map.Entry<String, JsonNode> entry = it.next();
JsonNode value = entry.getValue();
// Preserve data types: numbers and booleans as typed cells
if (value.isNumber()) {
sheet.get(dataRow, dataCol).setNumberValue(value.doubleValue());
} else if (value.isBoolean()) {
sheet.get(dataRow, dataCol).setBooleanValue(value.booleanValue());
} else {
sheet.get(dataRow, dataCol).setValue(value.asText());
}
dataCol++;
}
}
// Auto-fit columns for readability
sheet.getAllocatedRange().autoFitColumns();
// Save the workbook as an XLSX file
workbook.saveToFile("EmployeeData.xlsx", ExcelVersion.Version2016);
System.out.println("JSON converted to Excel successfully.");
// Release resources
workbook.dispose();
} catch (Exception e) {
System.err.println("Error during JSON to Excel conversion: " + e.getMessage());
e.printStackTrace();
}
}
}
After running the program, the JSON data is converted into an Excel worksheet. The generated EmployeeData.xlsx file contains the employee records with preserved data types and automatically adjusted column widths:
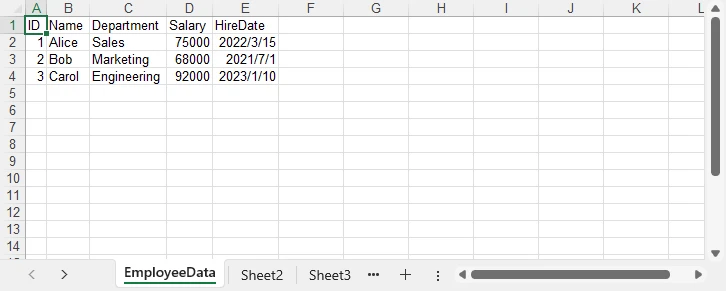
Key Spire.XLS Classes and Methods
- Workbook — Represents an Excel file. Handles creation, worksheet management, and file saving.
- Worksheet — Represents a single sheet within a workbook. Provides access to cells, rows, and columns.
get(int row, int column)— Returns aCellRangeobject for the specified cell. Row and column indices are 1-based.setValue(String)— Sets a cell's value as a string. Used for text and headers.setNumberValue(double)— Sets a cell's value as a number, preserving numeric type for calculations.setBooleanValue(boolean)— Sets a cell's value as a boolean (TRUE/FALSE).saveToFile(String, ExcelVersion)— Saves the workbook to a file in the specified Excel format.dispose()— Releases unmanaged resources held by the workbook.
If you also need to convert Excel files back to JSON format, see our guide on how to convert Excel to JSON in Java using Spire.XLS for Java.
6. Export JSON to XLSX in Java
Spire.XLS for Java supports both the modern XLSX format (Excel 2007 and later) and the legacy XLS format (Excel 97–2003). You can control the output format by passing the appropriate ExcelVersion enum to saveToFile().
Save as XLSX
// Export to modern Excel format (.xlsx)
workbook.saveToFile("EmployeeData.xlsx", ExcelVersion.Version2016);
Save as XLS
// Export to legacy Excel format (.xls)
workbook.saveToFile("EmployeeData.xls", ExcelVersion.Version97to2003);
| Format | Description | Use Case |
|---|---|---|
| XLSX | Modern Excel format (Excel 2007+) | Default choice; smaller file, full features |
| XLS | Legacy Excel format (Excel 97–2003) | Compatibility with older systems |
The same workbook object can be saved to either format — no code changes are needed beyond the file extension and version parameter. This is particularly useful when your application needs to support both modern and legacy environments.
You can also learn how to convert between XLS and XLSX formats in Java for scenarios where format migration or legacy upgrade is required.
7. Convert Nested JSON to Excel in Java
Real-world JSON data often contains nested objects and arrays. To write nested JSON to Excel, you need to flatten the hierarchical structure into a tabular format where each nested field becomes its own column.
Consider the following JSON containing employee records with nested contact information:
[
{
"ID": 1,
"Name": "Alice",
"Department": "Sales",
"Contact": {
"Email": "alice@company.com",
"Phone": "555-0101"
}
},
{
"ID": 2,
"Name": "Bob",
"Department": "Marketing",
"Contact": {
"Email": "bob@company.com",
"Phone": "555-0102"
}
}
]
The goal is to flatten the Contact object so that Email and Phone become individual columns:
| ID | Name | Department | Contact.Email | Contact.Phone |
|---|---|---|---|---|
| 1 | Alice | Sales | alice@company.com | 555-0101 |
| 2 | Bob | Marketing | bob@company.com | 555-0102 |
The following code uses a recursive flattening approach to handle arbitrary nesting depth:
import com.spire.xls.*;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.node.ArrayNode;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
public class NestedJsonToExcel {
public static void main(String[] args) {
String jsonString = "["
+ "{\"ID\":1,\"Name\":\"Alice\",\"Department\":\"Sales\","
+ "\"Contact\":{\"Email\":\"alice@company.com\",\"Phone\":\"555-0101\"}},"
+ "{\"ID\":2,\"Name\":\"Bob\",\"Department\":\"Marketing\","
+ "\"Contact\":{\"Email\":\"bob@company.com\",\"Phone\":\"555-0102\"}}"
+ "]";
try {
ObjectMapper mapper = new ObjectMapper();
ArrayNode jsonArray = (ArrayNode) mapper.readTree(jsonString);
Workbook workbook = new Workbook();
Worksheet sheet = workbook.getWorksheets().get(0);
sheet.setName("Employees");
// Flatten the first object to extract all column headers (including nested keys)
LinkedHashMap<String, String> firstFlat = flattenJson(jsonArray.get(0), "");
int col = 1;
for (String key : firstFlat.keySet()) {
sheet.get(1, col).setValue(key);
col++;
}
// Write data rows
for (int i = 0; i < jsonArray.size(); i++) {
LinkedHashMap<String, String> flat = flattenJson(jsonArray.get(i), "");
int dataRow = i + 2;
int dataCol = 1;
for (String key : firstFlat.keySet()) {
String value = flat.getOrDefault(key, "");
sheet.get(dataRow, dataCol).setValue(value);
dataCol++;
}
}
sheet.getAllocatedRange().autoFitColumns();
workbook.saveToFile("NestedEmployees.xlsx", ExcelVersion.Version2016);
System.out.println("Nested JSON converted to Excel successfully.");
workbook.dispose();
} catch (Exception e) {
System.err.println("Error: " + e.getMessage());
}
}
/**
* Recursively flattens a JSON object into key-value pairs.
* Nested keys are joined with a dot (e.g., "Contact.Email").
*/
private static LinkedHashMap<String, String> flattenJson(JsonNode node, String prefix) {
LinkedHashMap<String, String> flat = new LinkedHashMap<>();
if (node.isObject()) {
for (Iterator<Map.Entry<String, JsonNode>> it = node.fields(); it.hasNext(); ) {
Map.Entry<String, JsonNode> entry = it.next();
String newPrefix = prefix.isEmpty() ? entry.getKey() : prefix + "." + entry.getKey();
flat.putAll(flattenJson(entry.getValue(), newPrefix));
}
} else {
flat.put(prefix, node.asText());
}
return flat;
}
}
The flattenJson method recursively traverses each JSON object. When it encounters a nested object, it prepends the parent key with a dot separator (e.g., Contact.Email). When it reaches a leaf value, it stores the full dotted key and its value in the map. This ensures that all fields — at any nesting depth — are represented as columns in the resulting Excel sheet.
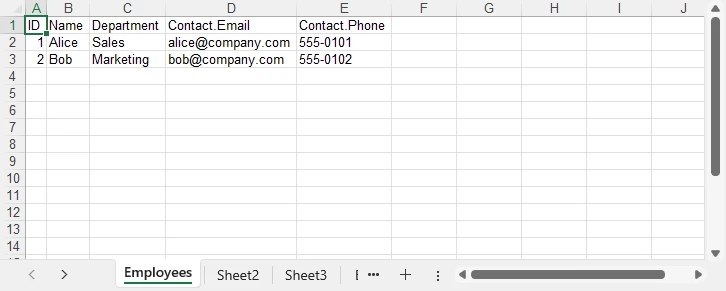
8. Convert a JSON File to Excel
In production applications, JSON data typically comes from a file on disk rather than an inline string. The conversion steps remain the same — only the JSON source changes. Jackson's ObjectMapper can read directly from a File object:
import com.spire.xls.*;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.node.ArrayNode;
import java.io.File;
import java.util.Iterator;
import java.util.Map;
public class JsonFileToExcel {
public static void main(String[] args) {
try {
// Step 1: Read and parse the JSON file
ObjectMapper mapper = new ObjectMapper();
JsonNode rootNode = mapper.readTree(new File("employees.json"));
if (!rootNode.isArray()) {
throw new IllegalArgumentException("Expected a JSON array at the root level");
}
ArrayNode jsonArray = (ArrayNode) rootNode;
// Step 2: Create a workbook
Workbook workbook = new Workbook();
Worksheet sheet = workbook.getWorksheets().get(0);
sheet.setName("Employees");
// Step 3: Write headers from the first object
JsonNode firstObject = jsonArray.get(0);
int col = 1;
for (Iterator<Map.Entry<String, JsonNode>> it = firstObject.fields(); it.hasNext(); ) {
Map.Entry<String, JsonNode> entry = it.next();
sheet.get(1, col).setValue(entry.getKey());
col++;
}
// Step 4: Write data rows
for (int i = 0; i < jsonArray.size(); i++) {
JsonNode record = jsonArray.get(i);
int dataRow = i + 2;
int dataCol = 1;
for (Iterator<Map.Entry<String, JsonNode>> it = record.fields(); it.hasNext(); ) {
Map.Entry<String, JsonNode> entry = it.next();
JsonNode value = entry.getValue();
if (value.isNumber()) {
sheet.get(dataRow, dataCol).setNumberValue(value.doubleValue());
} else if (value.isBoolean()) {
sheet.get(dataRow, dataCol).setBooleanValue(value.booleanValue());
} else {
sheet.get(dataRow, dataCol).setValue(value.asText());
}
dataCol++;
}
}
// Step 5: Export to Excel
sheet.getAllocatedRange().autoFitColumns();
workbook.saveToFile("EmployeesFromJson.xlsx", ExcelVersion.Version2016);
System.out.println("JSON file converted to Excel successfully.");
workbook.dispose();
} catch (Exception e) {
System.err.println("Error reading JSON file: " + e.getMessage());
e.printStackTrace();
}
}
}
This approach handles large JSON files efficiently because Jackson processes the file as a streaming tree model. For very large JSON files (hundreds of megabytes), consider using Jackson's JsonParser in streaming mode to read records incrementally rather than loading the entire tree into memory at once.
9. Auto-Fit Rows and Columns in Excel
When JSON data is written to Excel cells, the default column width may not be wide enough to display all content. Text values such as email addresses, URLs, or long descriptions get truncated visually. Spire.XLS provides auto-fit methods that adjust column widths and row heights to match their content:
// Auto-fit all columns and rows in the used range
sheet.getAllocatedRange().autoFitColumns();
sheet.getAllocatedRange().autoFitRows();
Add these lines after writing all data but before saving the workbook. The getAllocatedRange() method returns the range of cells that contain data, so only populated cells are affected.
For more granular control, you can auto-fit individual columns:
// Auto-fit a specific column (e.g., column 3)
sheet.getAllocatedRange().getColumns()[2].autoFitColumns();
Auto-fitting produces a more professional, readable spreadsheet — especially when the JSON data contains variable-length text fields. The screenshot below shows the difference between a raw export and one with auto-fit applied.
10. Apply Formatting to the Exported Excel File
Raw data exports often need formatting to meet business reporting standards. Spire.XLS for Java provides a rich set of cell formatting APIs that let you style the header row, format numbers, and apply date formats — all programmatically.
Format the Header Row
Apply bold text and a background color to the first row to distinguish headers from data:
import com.spire.xls.core.spreadsheet.styles.CellStyle;
import java.awt.Color;
// Apply formatting to the header row
CellRange headerRange = sheet.getAllocatedRange().getRows()[0];
headerRange.getStyle().setFont(new ExcelFont(true));
headerRange.getStyle().setColor(Color.decode("#4472C4"));
headerRange.getStyle().getFont().setColor(Color.WHITE);
headerRange.setStyle(headerRange.getStyle());
Format Numbers
Apply currency or percentage formatting to numeric columns:
// Format the Salary column (column 4) as currency
CellRange salaryColumn = sheet.getAllocatedRange().getColumns()[3];
salaryColumn.setNumberFormat("$#,##0.00");
Format Dates
If your JSON contains date strings, you can format the corresponding column to display them in a consistent format:
// Format the HireDate column (column 5) as a date
CellRange dateColumn = sheet.getAllocatedRange().getColumns()[4];
dateColumn.setNumberFormat("yyyy-mm-dd");
The formatting techniques above can be combined to create professional Excel reports. For a complete Java example covering advanced Excel formatting features, refer to How to Create and Format Excel Files in Java Using Spire.XLS.
11. Common Challenges When Converting JSON to Excel
Real-world JSON data is rarely as clean as tutorial examples. Here are the most common challenges developers face when converting JSON to Excel, along with practical solutions.
Missing Fields Across Objects
Different JSON objects in the same array may have inconsistent fields. One record might include a Phone field while another omits it entirely. If your code assumes all objects share the same keys, missing fields cause index misalignment in the Excel output.
Solution: Collect all unique keys across all objects first, then write each object's values using the unified key list:
// Collect all unique keys from all JSON objects
LinkedHashSet<String> allKeys = new LinkedHashSet<>();
for (JsonNode record : jsonArray) {
record.fieldNames().forEachRemaining(allKeys::add);
}
// Write headers from the complete key set
int col = 1;
for (String key : allKeys) {
sheet.get(1, col).setValue(key);
col++;
}
// Write values, using empty string for missing fields
for (int i = 0; i < jsonArray.size(); i++) {
JsonNode record = jsonArray.get(i);
int dataRow = i + 2;
int dataCol = 1;
for (String key : allKeys) {
JsonNode value = record.get(key);
String cellValue = (value != null && !value.isNull()) ? value.asText() : "";
sheet.get(dataRow, dataCol).setValue(cellValue);
dataCol++;
}
}
Nested Objects
JSON objects can contain arbitrarily deep nesting. Writing nested objects directly to cells produces unreadable output like [object Object] or serialized JSON strings.
Solution: Use the recursive flattening approach demonstrated in Section 7. The flattenJson method traverses the entire object tree and produces flat key-value pairs where nested keys are joined with dot notation.
Large JSON Files
Parsing very large JSON files (hundreds of megabytes or more) into a single in-memory tree can cause OutOfMemoryError in Java. Additionally, writing tens of thousands of rows one cell at a time can be slow.
Solution: Use Jackson's streaming API (JsonParser) to read JSON records one at a time, and write each record to Excel immediately before moving to the next. This keeps memory usage constant regardless of file size:
import com.fasterxml.jackson.core.JsonFactory;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.core.JsonToken;
JsonFactory factory = new JsonFactory();
try (JsonParser parser = factory.createParser(new File("large_data.json"))) {
int dataRow = 2;
while (parser.nextToken() != JsonToken.END_ARRAY) {
// Parse one object at a time
JsonNode record = mapper.readTree(parser);
// Write to Excel...
dataRow++;
}
}
Data Type Conversion
JSON supports strings, numbers, booleans, null values, arrays, and objects. Excel cells support text, numbers, booleans, dates, and errors. Mismatched types — for example, storing a numeric value as a string — prevent Excel sorting and formulas from working correctly.
Solution: Check each JSON value's type before writing it to a cell. Use setNumberValue() for numbers, setBooleanValue() for booleans, and setValue() for text. Handle null values by writing an empty string or a placeholder. For date strings, parse them into Date objects and use setDateTimeValue() to write them as Excel date cells:
if (value == null || value.isNull()) {
sheet.get(dataRow, dataCol).setValue("");
} else if (value.isNumber()) {
sheet.get(dataRow, dataCol).setNumberValue(value.doubleValue());
} else if (value.isBoolean()) {
sheet.get(dataRow, dataCol).setBooleanValue(value.booleanValue());
} else {
sheet.get(dataRow, dataCol).setValue(value.asText());
}
12. Why Use Spire.XLS for Java for JSON-to-Excel Conversion
Several characteristics make Spire.XLS for Java well-suited for JSON-to-Excel conversion in enterprise Java applications.
No Microsoft Excel Required
Spire.XLS for Java is a standalone library that does not depend on Microsoft Office or any other external software. It runs on any system with a Java Runtime Environment, including Linux servers, Docker containers, and cloud platforms where Office is not available.
Supports XLS and XLSX
The library handles both the legacy XLS format (Excel 97–2003) and the modern XLSX format (Excel 2007+). You can export to either format by changing a single parameter, making it easy to support diverse downstream environments.
Rich Formatting Features
Beyond basic cell value writing, Spire.XLS provides comprehensive formatting capabilities — cell styles, number formats, fonts, colors, borders, conditional formatting, charts, and pivot tables. This allows you to generate professional-grade Excel files directly from JSON data without any post-processing in Excel.
Easy API
The API follows an intuitive object model: Workbook contains Worksheets, each Worksheet contains CellRanges, and each CellRange supports value setting, styling, and formatting. Developers familiar with the Excel object model can become productive quickly.
Suitable for Enterprise Applications
Spire.XLS for Java is designed for server-side and enterprise use cases. It handles large files efficiently, supports multi-threaded access patterns, and integrates cleanly with Spring Boot, Jakarta EE, and other Java frameworks commonly used in enterprise environments.
You can apply for a 30-day free license to evaluate all features in your projects.
13. Conclusion
In this article, we explored how to convert JSON to Excel in Java using Spire.XLS for Java and Jackson. By parsing JSON data, writing values into Excel worksheets, and exporting the workbook as XLSX or XLS files, developers can efficiently transform structured JSON data into readable spreadsheets.
Spire.XLS for Java provides a simple and flexible way to generate Excel files from JSON data without requiring Microsoft Office or external dependencies. It also supports advanced features such as formatting, auto-fitting, and handling complex data structures for professional Excel reports.
14. FAQ
How do I convert JSON to Excel in Java?
Parse the JSON data using Jackson's ObjectMapper, create a Workbook and Worksheet using Spire.XLS for Java, write the JSON keys as column headers in the first row, then iterate through the JSON array to populate each data row. Save the workbook using saveToFile() with the desired ExcelVersion. The complete code example is shown in Section 5.
Can I convert JSON to XLSX in Java without Microsoft Excel installed?
Yes. Spire.XLS for Java is a standalone library that does not require Microsoft Office or any other software. It can create, read, and write XLSX files entirely in Java, making it suitable for server-side applications running on Linux, Docker, or cloud platforms.
How do I handle nested JSON objects when converting to Excel?
Use a recursive flattening function that traverses the JSON object tree and produces flat key-value pairs. Nested keys are joined with a dot separator (e.g., Contact.Email). The flattened keys become column headers in the Excel sheet. See Section 7 for the complete implementation.
What is the difference between setValue() and setNumberValue() in Spire.XLS?
setValue(String) writes a string value to a cell, while setNumberValue(double) writes a numeric value that Excel treats as a number. Using setNumberValue() for numeric JSON fields ensures that sorting, filtering, and formula calculations work correctly. Similarly, setBooleanValue(boolean) writes typed boolean values.
How do I convert a large JSON file to Excel without running out of memory?
For large JSON files, use Jackson's streaming API (JsonParser) to read and process one JSON record at a time instead of loading the entire file into memory. Write each record to the Excel worksheet immediately after parsing it. This keeps memory usage constant regardless of the file size.
Is Spire.XLS for Java free?
Spire.XLS for Java is a commercial library. A free version, Free Spire.XLS for Java, is available with limitations on worksheet count and features. You can also apply for a 30-day free license to evaluate the full feature set before purchasing.

Converting Excel to JSON in Java is a common requirement in backend development, especially when building APIs, ETL pipelines, or data integration workflows. In this guide, you will learn how to convert Excel to JSON in Java using Spire.XLS, a powerful library that supports both XLS and XLSX formats with minimal code.
Excel files are widely used for data storage and reporting, while JSON has become the standard format for data exchange in modern applications. However, converting Excel to JSON in Java is not trivial if done manually — developers need to handle file parsing, data type conversion, empty cells, and multi-sheet structures, which can quickly become complex and error-prone.
Using Spire.XLS for Java together with Jackson, developers can easily transform Excel spreadsheets into structured JSON data with clean and maintainable code. This article provides a complete step-by-step tutorial on Java Excel to JSON conversion, including single-sheet conversion, multi-sheet processing, and nested JSON structures.
Quick Navigation
- Why Convert Excel to JSON in Java
- Prerequisites
- Convert Excel to JSON in Java — Step by Step
- Convert XLS and XLSX Files to JSON
- Handling Multi-Sheet Workbooks and Nested JSON
- Handling Empty Cells and Data Types
- Common Pitfalls
- Conclusion
- FAQ
1. Why Convert Excel to JSON in Java
Excel and JSON are widely used in modern software systems but serve very different roles. Excel is designed for structured data entry, analysis, and reporting with support for formulas, formatting, and multi-sheet workbooks. JSON (JavaScript Object Notation), in contrast, is a lightweight data format used for machine-to-machine communication, REST APIs, configuration files, and NoSQL databases.
Because of this difference, Java developers often need to convert Excel to JSON when integrating spreadsheet-based data into backend systems.
Common use cases include:
- REST API integration — Converting Excel data uploaded by users into JSON for API responses
- ETL workflows — Extracting spreadsheet data and transforming it into JSON for databases or data lakes
- Configuration migration — Moving legacy Excel-based configs into JSON-based microservice systems
- Automated reporting — Turning Excel templates into structured JSON for downstream processing
In Java applications, converting Excel to JSON is more than just reading rows and mapping columns. Real-world files often include inconsistent data types, empty cells, date formatting issues, and multi-sheet structures, which make manual parsing complex and error-prone.
Spire.XLS for Java simplifies this process by providing a unified API for both XLS and XLSX formats. It allows developers to directly access cell values, data types, and formatting information, enabling clean and reliable Excel to JSON conversion logic without dealing with low-level file parsing.
2. Prerequisites
Before converting Excel to JSON in Java, set up the following dependencies in your project.
Install Spire.XLS for Java via Maven (Recommended)
Spire.XLS for Java is available through the e-iceblue Maven repository. Add the repository and dependency to your pom.xml:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>16.6.5</version>
</dependency>
You can also download Spire.XLS for Java and add it to your project manually.
Add a JSON Library
Java does not include built-in JSON support. This guide uses Jackson, the most widely adopted JSON processing library in the Java ecosystem:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.17.2</version>
</dependency>
Import Required Classes
Include the following imports in your Java source file:
import com.spire.xls.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.node.ObjectNode;
import com.fasterxml.jackson.databind.node.ArrayNode;
import java.io.File;
import java.io.IOException;
If you prefer manual installation, download the Spire.XLS for Java JAR from the e-iceblue website and add it to your project's classpath.
3. Convert Excel to JSON in Java — Step by Step
The conversion process involves four steps: loading the workbook, reading the header row, iterating through data rows, and assembling the JSON output. This section walks through each step and then presents the complete code.
Step 1: Load the Excel File
Use the Workbook class to open an Excel file. Then retrieve the target worksheet by index:
Workbook workbook = new Workbook();
workbook.loadFromFile("EmployeeData.xlsx");
Worksheet worksheet = workbook.getWorksheets().get(0);
Step 2: Read the Header Row
The first row of the spreadsheet typically contains column headers. These headers become the JSON keys for each record. Read them into a String array:
int columnCount = worksheet.getLastColumn();
String[] headers = new String[columnCount];
for (int col = 1; col <= columnCount; col++) {
headers[col - 1] = worksheet.get(1, col).getValue();
}
Step 3: Iterate Data Rows and Build JSON Objects
Starting from row 2, loop through each row and create an ObjectNode for every record. Each cell value is mapped to the corresponding header key:
ObjectMapper mapper = new ObjectMapper();
ArrayNode arrayNode = mapper.createArrayNode();
for (int row = 2; row <= worksheet.getLastRow(); row++) {
ObjectNode record = mapper.createObjectNode();
for (int col = 1; col <= columnCount; col++) {
record.put(headers[col - 1], worksheet.get(row, col).getValue());
}
arrayNode.add(record);
}
Step 4: Export JSON Output
Use Jackson's ObjectMapper to write the ArrayNode to a file with pretty-print formatting:
try {
mapper.writerWithDefaultPrettyPrinter().writeValue(new File("EmployeeData.json"), arrayNode);
System.out.println("JSON exported successfully.");
} catch (IOException e) {
System.err.println("Failed to write JSON file: " + e.getMessage());
}
workbook.dispose();
Complete Code Example
Here is the full program that reads an Excel file and converts it to JSON:
import com.spire.xls.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.node.ObjectNode;
import com.fasterxml.jackson.databind.node.ArrayNode;
import java.io.File;
import java.io.IOException;
public class ExcelToJsonConverter {
public static void main(String[] args) {
// Load the Excel workbook
Workbook workbook = new Workbook();
workbook.loadFromFile("EmployeeData.xlsx");
// Access the first worksheet
Worksheet worksheet = workbook.getWorksheets().get(0);
// Read column headers from the first row
int columnCount = worksheet.getLastColumn();
String[] headers = new String[columnCount];
for (int col = 1; col <= columnCount; col++) {
headers[col - 1] = worksheet.get(1, col).getValue();
}
// Create Jackson ObjectMapper and ArrayNode
ObjectMapper mapper = new ObjectMapper();
ArrayNode arrayNode = mapper.createArrayNode();
// Convert each data row to a JSON object
for (int row = 2; row <= worksheet.getLastRow(); row++) {
ObjectNode record = mapper.createObjectNode();
for (int col = 1; col <= columnCount; col++) {
record.put(headers[col - 1], worksheet.get(row, col).getValue());
}
arrayNode.add(record);
}
// Write JSON output to file with pretty-print formatting
try {
mapper.writerWithDefaultPrettyPrinter().writeValue(new File("EmployeeData.json"), arrayNode);
System.out.println("Excel data converted to JSON successfully.");
} catch (IOException e) {
System.err.println("Error writing JSON file: " + e.getMessage());
}
// Release workbook resources
workbook.dispose();
}
}
Expected JSON output (for an Excel file with Name, Department, Email, and Salary columns):
[ {
"EmployeeID" : "E001",
"FirstName" : "John",
"LastName" : "Smith",
"Department" : "Engineering",
"Position" : "Software Engineer",
"Salary" : "85000",
"HireDate" : "2022/3/15 0:00:00"
} ]
The following diagram shows a visual comparison between the original Excel data and the converted JSON output for better understanding.
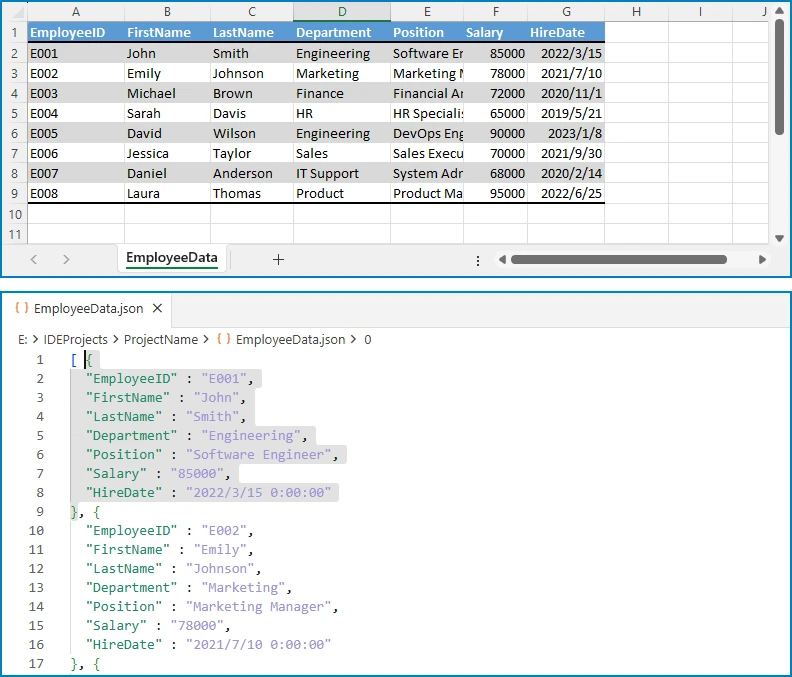
Key Spire.XLS Classes and Methods
- Workbook — Represents an Excel file. Handles loading, saving, and managing worksheets.
- Worksheet — Represents a single sheet within a workbook. Provides access to rows, columns, and cells.
get(int row, int column)— Returns aCellRangeobject for the specified cell. Row and column indices are 1-based.getValue()— Returns the cell's display value. UnlikegetText(), it correctly retrieves the value regardless of the cell's data type (text, number, date, etc.).getLastRow()/getLastColumn()— Return the last row and column numbers that contain data.
You can also learn how to convert Excel to CSV in Java for scenarios where a lightweight, tabular format is preferred for data exchange and storage.
4. Convert XLS and XLSX Files to JSON
Spire.XLS for Java supports both the legacy XLS format (Excel 97–2003) and the modern XLSX format (Excel 2007 and later). The library detects the file format automatically when you call loadFromFile(), so the same Java code converts XLS to JSON and XLSX to JSON without any modifications.
// Convert XLSX to JSON (modern format)
Workbook xlsxWorkbook = new Workbook();
xlsxWorkbook.loadFromFile("SalesReport.xlsx");
// Convert XLS to JSON (legacy format)
Workbook xlsWorkbook = new Workbook();
xlsWorkbook.loadFromFile("SalesReport.xls");
// Both workbooks are processed identically
Worksheet sheet = xlsxWorkbook.getWorksheets().get(0);
int rowCount = sheet.getLastRow();
int colCount = sheet.getLastColumn();
// ... same conversion logic as the basic example
No additional configuration, format flags, or separate code paths are needed. Whether you receive .xls files from legacy systems or .xlsx files from modern applications, Spire.XLS handles the parsing transparently. This is particularly useful in enterprise environments where Excel files may come from different sources and span multiple format generations.
You can also learn how to convert between XLS and XLSX formats in Java for scenarios where file format migration or legacy upgrade is required.
5. Handling Multi-Sheet Workbooks and Nested JSON
Real-world Excel workbooks often contain multiple worksheets. Converting each sheet to a separate JSON array produces a structured output that preserves the workbook's organization. In some cases, developers also need to build nested JSON objects that reflect hierarchical relationships within the data.
Convert Multiple Sheets to JSON
The following example reads all worksheets in a workbook and creates a JSON object where each key is the sheet name and each value is an array of records from that sheet:
import com.spire.xls.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.node.ObjectNode;
import com.fasterxml.jackson.databind.node.ArrayNode;
import java.io.File;
import java.io.IOException;
public class MultiSheetExcelToJson {
public static void main(String[] args) {
Workbook workbook = new Workbook();
workbook.loadFromFile("SalesReport.xlsx");
ObjectMapper mapper = new ObjectMapper();
ObjectNode fullReport = mapper.createObjectNode();
// Iterate through every worksheet in the workbook
for (int s = 0; s < workbook.getWorksheets().getCount(); s++) {
Worksheet worksheet = workbook.getWorksheets().get(s);
String sheetName = worksheet.getName();
// Read headers from the first row
int columnCount = worksheet.getLastColumn();
String[] headers = new String[columnCount];
for (int col = 1; col <= columnCount; col++) {
headers[col - 1] = worksheet.get(1, col).getValue();
}
// Convert data rows to JSON objects
ArrayNode sheetData = mapper.createArrayNode();
for (int row = 2; row <= worksheet.getLastRow(); row++) {
ObjectNode record = mapper.createObjectNode();
for (int col = 1; col <= columnCount; col++) {
record.put(headers[col - 1], worksheet.get(row, col).getValue());
}
sheetData.add(record);
}
// Add this sheet's data to the final output
fullReport.set(sheetName, sheetData);
}
// Write the combined JSON to file with pretty-print formatting
try {
mapper.writerWithDefaultPrettyPrinter().writeValue(new File("SalesReport.json"), fullReport);
System.out.println("Multi-sheet workbook converted to JSON.");
} catch (IOException e) {
System.err.println("Error writing JSON: " + e.getMessage());
}
workbook.dispose();
}
}
Output (for a workbook with "East Region" and "West Region" sheets):
{
"East Region": [
{"Employee": "Alice", "Product": "Laptop", "Amount": "1200"},
{"Employee": "Bob", "Product": "Monitor", "Amount": "450"}
],
"West Region": [
{"Employee": "Carol", "Product": "Keyboard", "Amount": "150"},
{"Employee": "Dave", "Product": "Mouse", "Amount": "75"}
]
}
The diagram below illustrates how multiple Excel sheets are mapped into a single JSON object structure.
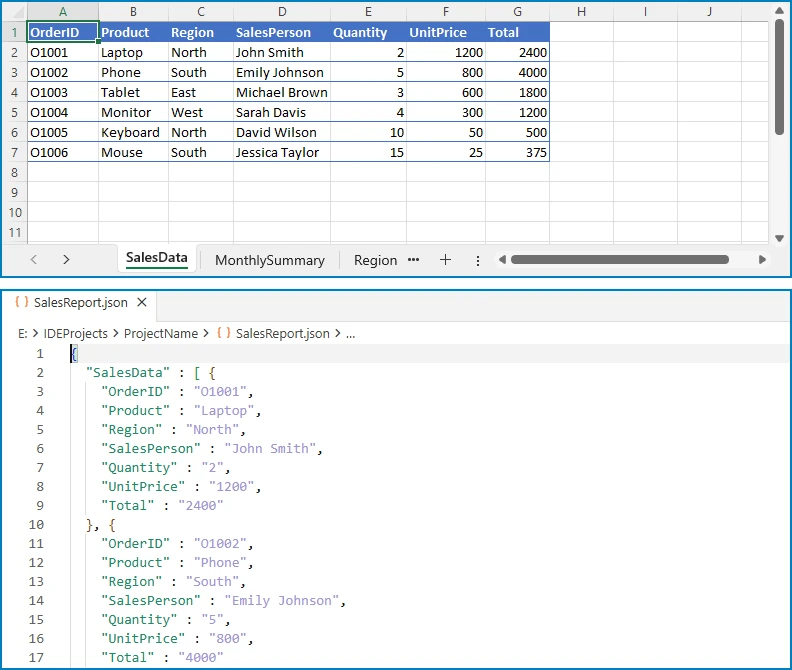
Build Nested JSON from Excel Data
Some scenarios require nested JSON structures rather than flat arrays. For example, a project management spreadsheet might list projects and their tasks in adjacent columns. The following code groups tasks under their parent projects:
import com.spire.xls.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.node.ObjectNode;
import com.fasterxml.jackson.databind.node.ArrayNode;
import java.util.LinkedHashMap;
import java.util.Map;
import java.io.File;
import java.io.IOException;
public class NestedExcelToJson {
public static void main(String[] args) {
Workbook workbook = new Workbook();
workbook.loadFromFile("ProjectTasks.xlsx");
Worksheet worksheet = workbook.getWorksheets().get(0);
ObjectMapper mapper = new ObjectMapper();
// Use a LinkedHashMap to preserve project insertion order
Map<String, ObjectNode> projectMap = new LinkedHashMap<>();
for (int row = 2; row <= worksheet.getLastRow(); row++) {
String projectName = worksheet.get(row, 1).getValue();
String taskName = worksheet.get(row, 2).getValue();
String assignee = worksheet.get(row, 3).getValue();
String status = worksheet.get(row, 4).getValue();
// Create project entry on first encounter
if (!projectMap.containsKey(projectName)) {
ObjectNode project = mapper.createObjectNode();
project.put("name", projectName);
project.set("tasks", mapper.createArrayNode());
projectMap.put(projectName, project);
}
// Build task object and add to the project's task array
ObjectNode task = mapper.createObjectNode();
task.put("task", taskName);
task.put("assignee", assignee);
task.put("status", status);
((ArrayNode) projectMap.get(projectName).get("tasks")).add(task);
}
// Assemble final JSON array
ArrayNode projectsJson = mapper.createArrayNode();
for (ObjectNode project : projectMap.values()) {
projectsJson.add(project);
}
try {
mapper.writerWithDefaultPrettyPrinter()
.writeValue(new File("ProjectTasks.json"), projectsJson);
System.out.println("Nested JSON file generated successfully.");
} catch (IOException e) {
System.err.println("Error writing JSON file: " + e.getMessage());
}
workbook.dispose();
}
}
Output (for a project-task spreadsheet):
[
{
"name": "Website Redesign",
"tasks": [
{"task": "Design mockups", "assignee": "Alice", "status": "Complete"},
{"task": "Frontend implementation", "assignee": "Bob", "status": "In Progress"}
]
},
{
"name": "Mobile App",
"tasks": [
{"task": "API integration", "assignee": "Carol", "status": "Pending"},
{"task": "UI testing", "assignee": "Dave", "status": "Not Started"}
]
}
]
The following diagram shows how flat Excel rows are transformed into a nested JSON structure grouped by project.
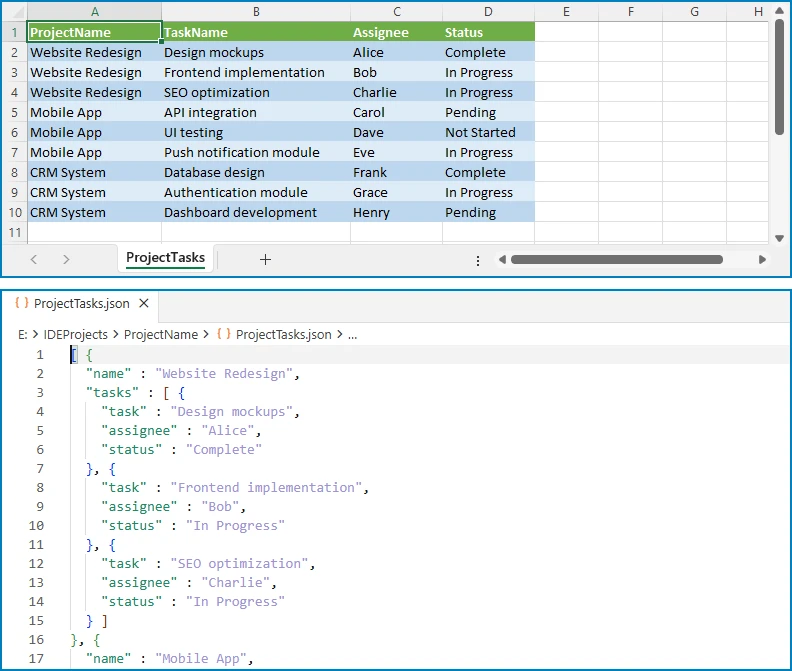
This pattern is useful when Excel data needs to be restructured into a hierarchical format that matches an API schema or a database document model.
You can also explore how to parse Excel files in Java for scenarios where you need to extract and process raw spreadsheet data before transformation.
6. Handling Empty Cells and Data Types
Production Excel files rarely contain clean, complete data. Empty cells, mixed data types, and formatting inconsistencies are common. A robust Java program to convert Excel to JSON must account for these variations.
Detect and Handle Empty Cells
Use CellRange.getType() to check whether a cell is empty before reading its value. Provide a default value to prevent null entries in the JSON output:
CellRange cell = worksheet.get(row, col);
String value;
if (cell.getType() == CellValueType.Empty) {
value = ""; // or a default value like "N/A"
} else {
value = cell.getValue();
}
record.put(headers[col - 1], value);
Note: In Jackson,
ObjectNode.put(String, String)is used for string values. For other types, useput(String, double),put(String, boolean), etc.
Preserve Data Types in JSON Output
The getValue() method returns the cell's display value as a string. For numeric data, use getNumberValue() to preserve the original type in the JSON output:
CellRange cell = worksheet.get(row, col);
if (cell.getType() == CellValueType.Number) {
record.put(headers[col - 1], cell.getNumberValue().doubleValue());
} else if (cell.getType() == CellValueType.Boolean) {
record.put(headers[col - 1], cell.getBooleanValue());
} else {
record.put(headers[col - 1], cell.getValue());
}
Handle Date-Formatted Cells
Excel stores dates as serial numbers internally. To output dates as ISO 8601 strings in JSON, detect date formatting and convert accordingly:
CellRange cell = worksheet.get(row, col);
if (cell.getType() == CellValueType.DateTime) {
java.util.Date date = cell.getDateTimeValue();
java.text.SimpleDateFormat iso = new java.text.SimpleDateFormat("yyyy-MM-dd");
record.put(headers[col - 1], iso.format(date));
} else {
record.put(headers[col - 1], cell.getValue());
}
This approach ensures that dates appear in a standard format (e.g., "2026-07-02") rather than Excel's internal numeric representation.
7. Common Pitfalls
Skipping the Header Row
One of the most frequent mistakes is starting the data loop from row 1 instead of row 2. When the first row contains column headers, including it in the data loop produces a JSON object where the keys are duplicated as values.
Solution: Always read headers from row 1 first, then start the data loop from row 2.
Hardcoding Column Indices
Hardcoding column positions (e.g., worksheet.get(row, 1) for "Name") makes the code fragile. If the Excel template changes and columns are reordered, the JSON keys no longer match the intended data.
Solution: Read headers dynamically from the first row and use the header array to assign JSON keys. This way, column reordering does not break the conversion.
Number Precision Loss
Excel stores numbers as double-precision floating-point values. Using getValue() returns the display content of the cell, but the result is always a string. If the JSON output should contain raw numeric values (rather than strings), additional type conversion is needed.
Solution: Check the cell type with getType() and use getNumberValue() for numeric cells to get the actual numeric value instead of a string representation.
Ignoring Date Formatting
Excel represents dates as serial numbers (e.g., 45109 for June 15, 2023). While getValue() returns the display content of a date cell, the exact format depends on the cell's number format and may not be consistent across different workbooks.
Solution: Use getDateTimeValue() for cells with date formatting and convert the result to a standard ISO 8601 string (yyyy-MM-dd or yyyy-MM-dd'T'HH:mm:ss) for consistent JSON output.
Memory Leaks from Undisposed Workbooks
Spire.XLS workbook objects hold unmanaged resources. Failing to call dispose() after processing can lead to memory leaks, especially when converting multiple files in a batch.
Solution: Always call workbook.dispose() after the conversion is complete. Use a try-finally block to guarantee cleanup even if an exception occurs:
Workbook workbook = new Workbook();
try {
workbook.loadFromFile("EmployeeData.xlsx");
// ... conversion logic ...
} finally {
workbook.dispose();
}
8. Conclusion
In this article, we demonstrated how to convert Excel to JSON in Java using Spire.XLS for Java. Starting from a basic single-sheet conversion, we covered step-by-step workbook loading, header-based key mapping, and JSON output generation. We then extended the approach to handle XLS and XLSX formats, multi-sheet workbooks, nested JSON structures, empty cells, and data type preservation.
Spire.XLS for Java simplifies the entire process with a clean API that requires no Microsoft Office installation. Beyond Excel-to-JSON conversion, the library provides comprehensive spreadsheet capabilities including PDF export, chart creation, formula calculation, and data validation. You can apply for a 30-day free license to evaluate all features in your projects.
9. FAQ
How do I convert Excel to JSON in Java?
Load the Excel file using Spire.XLS for Java, read the header row to determine JSON keys, iterate through the data rows starting from row 2, and map each cell value to its corresponding key in a Jackson ObjectNode. Collect all objects into an ArrayNode and use ObjectMapper to write the result to a file or return it as a string. The complete code example is shown in Section 3.
Which Java library is best for Excel to JSON conversion?
Spire.XLS for Java provides a comprehensive API for reading Excel data with support for both XLS and XLSX formats. It handles cell types, formulas, and formatting natively, making it straightforward to extract structured data for JSON conversion without requiring Microsoft Office or any other external dependency.
Can Spire.XLS handle both XLS and XLSX formats?
Yes. Spire.XLS for Java automatically detects whether a file is in the legacy XLS format (Excel 97–2003) or the modern XLSX format (Excel 2007 and later). The same code works for both formats without any additional configuration. See Section 4 for details.
What is the difference between getValue() and getCellValue() in Spire.XLS?
getValue() returns the cell's display value — it works for all data types (text, number, date, boolean, etc.) and returns what the user sees in the cell. getCellValue() returns the raw underlying value as an Object. Use getValue() when the JSON output should match what users see in Excel, and use getNumberValue() or getBooleanValue() when you need typed values for numeric or boolean data.
How do I handle empty cells when converting Excel to JSON?
Check the cell type using CellRange.getType() before reading a value. If the type is CellValueType.Empty, assign a default value such as an empty string or "N/A". This prevents null entries and ensures consistent JSON structure across all records. See Section 6 for code examples.
Is Spire.XLS for Java free?
Spire.XLS for Java is a commercial library. A free version, Free Spire.XLS for Java, is available with limitations on worksheet count and features. You can also apply for a 30-day free license to evaluate the full feature set before purchasing.

CSV remains a ubiquitous, lightweight data format in Java development, powering report exports, data migration, and cross-platform data interchange. But despite its apparent simplicity, building production-grade CSV files requires handling special characters, encodings, and strict formatting rules – all of which add unnecessary development and testing overhead.
Spire.XLS for Java streamlines this workflow with a clean, robust API that automatically handles all low-level formatting and encoding details. This guide shows you how to use Java to create CSV files – covering basic CSV generation, structured batch exports, Excel-to-CSV conversion, special character support, and advanced delimiter configuration.
- Why Choose Spire.XLS for Java to Create CSV Files
- Creating CSV Files from Scratch with Java
- Create Structured CSV from Arrays in Java
- Create CSV from Excel in Java
- Advanced CSV Generation Techniques
- Frequently Asked Questions
Why Choose Spire.XLS for Java to Create CSV Files
Compared to native Java IO, Apache POI, or any other CSV Java library, Spire.XLS for Java offers distinct advantages:
- Simplified API: Create and write CSV files in just a few lines of code, with no manual stream operations or low-level formatting work.
- Automatic Format Handling: Automatically escapes special characters (commas, double quotes, line breaks) that break standard CSV syntax.
- Full Encoding Support: Natively supports UTF-8, UTF-16, GB2312, and other encodings to avoid Chinese and special text garbling.
- Dual Format Compatibility: Supports both Excel (XLS/XLSX) and CSV formats, enabling bidirectional conversion between spreadsheets and delimited text.
- No Dependencies Bloat: Lightweight library with no third-party dependency conflicts, suitable for Java web, desktop, and microservice projects.
Prerequisites: Install Spire.XLS for Java
To start using Java to write CSV files, you first need to integrate the library into your project. We provide Maven and manual JAR installation methods.
1. Maven Dependency Configuration (Recommended)
Add the following repository and dependency to your project’s pom.xml file:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>16.4.1</version>
</dependency>
2. Manual JAR Installation
For non-Maven projects, download the Spire.XLS for Java JAR file from the official website and add it to your project’s build path.
Create CSV Files from Scratch with Java
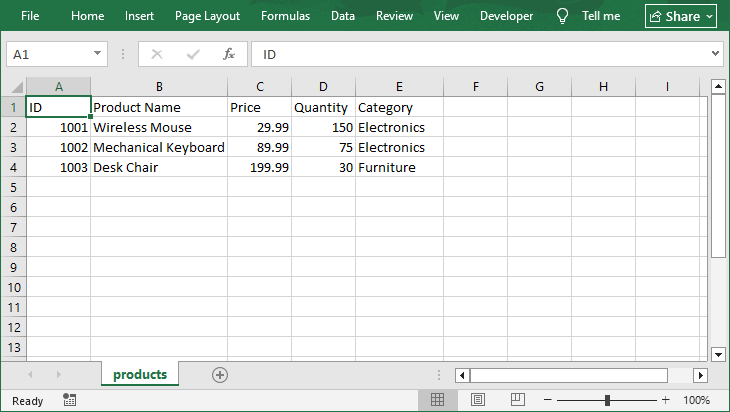
This example demonstrates how to create a blank CSV file from scratch, write custom row and column data, and save the file with standard comma delimiters and UTF-8 encoding. This is the most common basic scenario to generate CSV in Java.
import com.spire.xls.*;
import java.nio.charset.Charset;
public class CreateBasicCSV {
public static void main(String[] args) {
// Create Workbook instance
Workbook workbook = new Workbook();
// Get the first worksheet (index 0)
Worksheet sheet = workbook.getWorksheets().get(0);
// Write header row
sheet.getCellRange("A1").setValue("ID");
sheet.getCellRange("B1").setValue("Product Name");
sheet.getCellRange("C1").setValue("Price");
sheet.getCellRange("D1").setValue("Quantity");
sheet.getCellRange("E1").setValue("Category");
// Write data rows
sheet.getCellRange("A2").setNumberValue(1001);
sheet.getCellRange("B2").setValue("Wireless Mouse");
sheet.getCellRange("C2").setNumberValue(29.99);
sheet.getCellRange("D2").setNumberValue(150);
sheet.getCellRange("E2").setValue("Electronics");
sheet.getCellRange("A3").setNumberValue(1002);
sheet.getCellRange("B3").setValue("Mechanical Keyboard");
sheet.getCellRange("C3").setNumberValue(89.99);
sheet.getCellRange("D3").setNumberValue(75);
sheet.getCellRange("E3").setValue("Electronics");
sheet.getCellRange("A4").setNumberValue(1003);
sheet.getCellRange("B4").setValue("Desk Chair");
sheet.getCellRange("C4").setNumberValue(199.99);
sheet.getCellRange("D4").setNumberValue(30);
sheet.getCellRange("E4").setValue("Furniture");
// Save worksheet as CSV file (comma delimiter + UTF-8 encoding)
sheet.saveToFile("products.csv", ",", Charset.forName("UTF-8"));
// Release resources
workbook.dispose();
}
}
Key API Methods Explained
- setValue(): Writes text or string values into a cell.
- setNumberValue(): Writes numeric values (integers and decimals) into a cell.
- saveToFile(filename, separator, charset): Exports the worksheet to CSV with specified delimiter and encoding.
Open the generated CSV in Excel:
Bonus Tip: Beyond generating CSV files from scratch, Spire.XLS also allows you to read a CSV file in Java, enabling full bidirectional data processing within a single library.
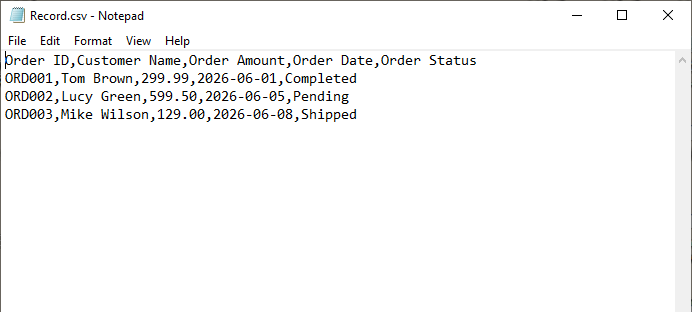
Create Structured CSV from Arrays in Java
For practical development, you usually need to batch write business data (e.g., user lists, order records) to CSV files. This example shows how to create a standardized CSV file with fixed headers and batch structured data from 1D & 2D arrays.
import com.spire.xls.*;
import java.nio.charset.Charset;
public class CreateStructuredCSV {
public static void main(String[] args) {
Workbook workbook = new Workbook();
Worksheet sheet = workbook.getWorksheets().get(0);
// Define CSV header row
String[] headers = {"Order ID", "Customer Name", "Order Amount", "Order Date", "Order Status"};
for (int i = 0; i < headers.length; i++) {
sheet.getCellRange(1, i + 1).setValue(headers[i]);
}
// Batch write order data
String[][] orderData = {
{"ORD001", "Tom Brown", "299.99", "2026-06-01", "Completed"},
{"ORD002", "Lucy Green", "599.50", "2026-06-05", "Pending"},
{"ORD003", "Mike Wilson", "129.00", "2026-06-08", "Shipped"}
};
// Traverse and write batch data
int rowNum = 2;
for (String[] rowData : orderData) {
for (int col = 0; col < rowData.length; col++) {
sheet.getCellRange(rowNum, col + 1).setValue(rowData[col]);
}
rowNum++;
}
// Save structured CSV file
sheet.saveToFile("Record.csv", ",", Charset.forName("UTF-8"));
workbook.dispose();
}
}
Unlike the previous example where we populated each cell individually, this approach loops through arrays or collections. And the same pattern can be easily adapted to List<List<String>> or other dynamic data sources.
Output:
Create CSV from Excel in Java
When you need to convert Excel to CSV in Java, Spire.XLS makes this process incredibly simple with only a few lines of code.
import com.spire.xls.*;
import java.nio.charset.Charset;
public class ExcelToCSV {
public static void main(String[] args) {
// Load Excel file
Workbook workbook = new Workbook();
workbook.loadFromFile("sample.xlsx");
// Get the first worksheet
Worksheet sheet = workbook.getWorksheets().get(0);
// Save worksheet as CSV
sheet.saveToFile("converted.csv", ",", Charset.forName("UTF-8"));
workbook.dispose();
}
}
The core logic is straightforward: load the Excel file → target the specific worksheet → call the conversion API to save as CSV.
Excel to CSV Result:
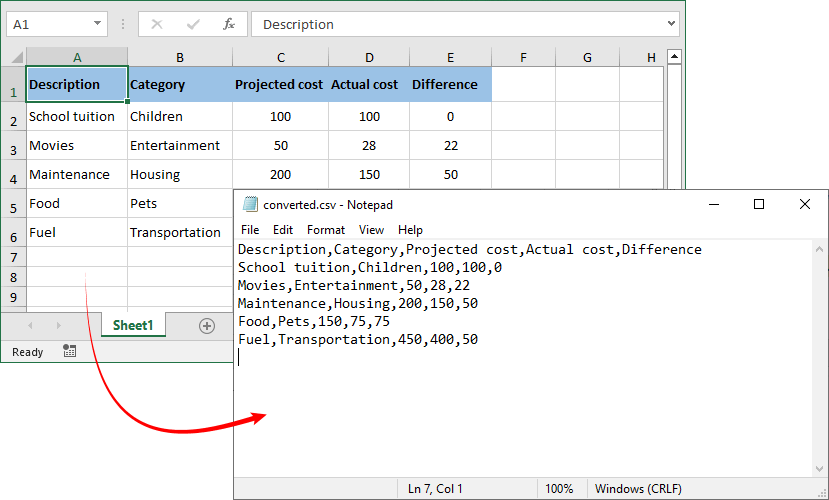
The reverse operation – turning a CSV file into an Excel workbook – is equally valuable when you need to apply styles, formulas, or multiple worksheets to raw exported data.
Advanced CSV Generation Techniques
1. Handle Special Characters
When your data contains commas or double quotes, proper escaping is critical. Spire.XLS automatically wraps affected fields in double quotes per RFC 4180 standards, ensuring compatibility with Excel, WPS, and all standard text editors.
Example:
sheet.getCellRange("A1").setValue("Ergonomic, silent design | \"2026 New Model\"");
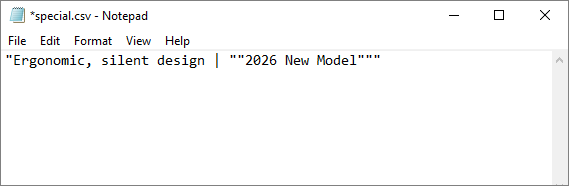
2. Custom Delimiters and Encoding
Spire.XLS for Java supports custom delimiters beyond the standard comma, accommodating regional and format-specific requirements.
// Using semicolon as delimiter and UTF-16 as encoding
sheet.saveToFile("european_data.csv", ";", Charset.forName("UTF-16"));
// Using tab as delimiter for TSV files
sheet.saveToFile("tab_separated.txt", "\t", Charset.forName("UTF-8"));
Frequently Asked Questions
Q1. Does Spire.XLS for Java require Microsoft Excel?
No. The library works completely independently without any Office dependencies.
Q2. Can I append data to the end of an existing CSV file?
Spire.XLS loads full CSV content into a worksheet for editing. To append data, load the existing file, locate the last used row, write new records starting from the next row index, then save the file back.
Q3. Can multiple worksheets be exported to a single CSV file?
No. CSV is a plain-text, single-sheet format by definition. Each saveToFile() call exports exactly one worksheet to one CSV file. To export multiple sheets, call the save method separately for each worksheet to output individual CSV files.
Q4. What about licensing?
Spire.XLS for Java offers both commercial and free versions. While the free version carries certain usage limitations, it fully supports fundamental CSV operations and lightweight spreadsheet processing tasks.
Conclusion
Generating CSV files is a routine yet critical task in Java development. The quality and reliability of your CSV output directly impact downstream processes such as reporting, system migration, and data analysis. To ensure error‑free CSV generation, you need a library that handles formatting, encoding, and special characters automatically.
Spire.XLS for Java provides exactly that. By following the step‑by‑step code examples in this article, you can quickly integrate robust CSV generation into your Java projects, improving development efficiency while eliminating common formatting flaws and encoding errors.
For more advanced features (e.g., converting CSV to PDF), explore the Spire.XLS for Java Documentation.
