
Die Konvertierung von Tabellen aus PDF-Dateien in das CSV-Format ist eine häufige Anforderung in Berichts-, Analyse- und Datenintegrations-Workflows. CSV-Dateien sind leichtgewichtig, werden weithin unterstützt und eignen sich gut für die Automatisierung, was sie weitaus nützlicher macht als statische PDFs, sobald tabellarische Daten wiederverwendet werden müssen.
In der Praxis ist die Konvertierung einer PDF-Tabelle in CSV jedoch selten einfach. PDF-Dateien sind darauf ausgelegt, das visuelle Erscheinungsbild zu erhalten und nicht die logische Struktur. Eine Tabelle, die auf dem Bildschirm perfekt ausgerichtet aussieht, existiert intern möglicherweise nicht als Zeilen und Spalten, weshalb naive Konvertierungsmethoden oft scheitern.
Dieser Artikel konzentriert sich auf praktische Methoden zur Konvertierung von PDF-Tabellen in CSV. Anstatt jede theoretische Option zu behandeln, werden die am häufigsten verwendeten Ansätze erläutert, wie sie sich in der Praxis verhalten und wann jede Methode geeignet ist.
Inhaltsverzeichnis
- Gängige praktische Wege zur Konvertierung von PDF-Tabellen in CSV
- Methode 1: PDF mit Acrobat in eine Tabelle exportieren
- Methode 2: Online-Konvertierung von PDF-Tabellen in CSV
- Methode 3: Programmatische Extraktion von PDF-Tabellen mit Python
- Umgang mit realen PDF-Tabellenszenarien
- Wichtige Erkenntnisse: Konvertierung von PDF-Tabellen in CSV
- FAQ
Gängige praktische Wege zur Konvertierung von PDF-Tabellen in CSV
In den meisten realen Arbeitsabläufen fällt die Konvertierung einer PDF-Tabelle in CSV in eine der folgenden Kategorien:
- Exportieren von Tabellen über PDF-zu-Tabellenkalkulations-Tools (wie Acrobat)
- Verwendung von Online-Konvertern für PDF-Tabellen in CSV
- Extrahieren von Tabellen programmatisch mit Python-Code
Einfache Kopier- und Einfügetechniken werden absichtlich ausgeschlossen, da sie Tabellen normalerweise in reinen Text umwandeln und eine umfangreiche manuelle Rekonstruktion erfordern.
Methode 1: PDF mit Acrobat in eine Tabelle exportieren
Das Exportieren einer PDF-Datei in ein Tabellenkalkulationsformat und das anschließende Speichern als CSV ist eine gängige Wahl für Benutzer, die Desktop-Tools und eine visuelle Überprüfung bevorzugen.
Wann diese Methode gut funktioniert
- Die PDF ist textbasiert und gut strukturiert
- Tabellen haben klare Zeilen- und Spaltengrenzen
- Manuelle Überprüfung und Korrektur sind akzeptabel
Typischer Acrobat-basierter Arbeitsablauf
-
Öffnen Sie die PDF-Datei in Acrobat
-
Wählen Sie PDF exportieren und wählen Sie Tabelle als Ausgabeformat
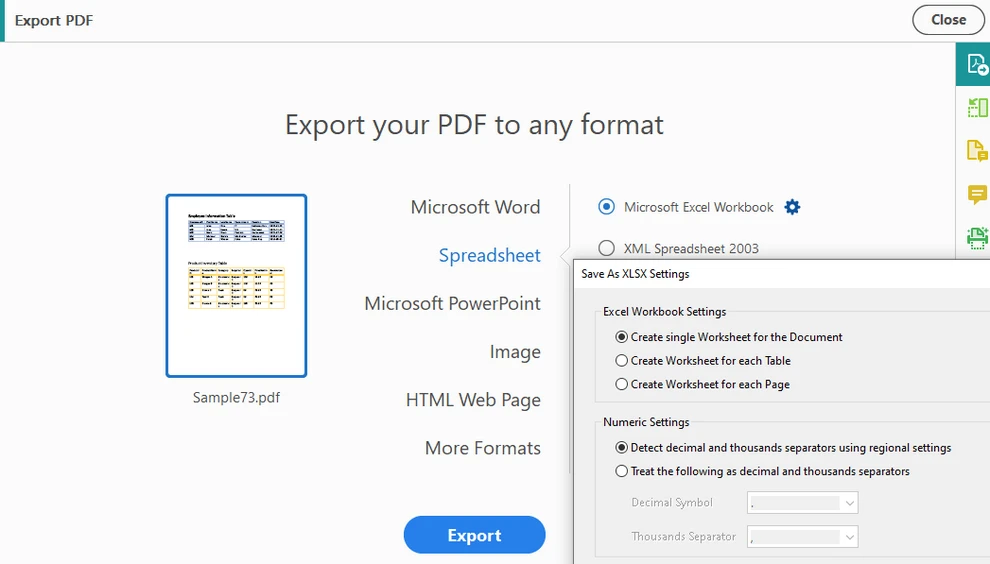
-
Exportieren Sie das Dokument in das Excel-Format
-
Überprüfen und passen Sie die Tabellenstruktur bei Bedarf an
-
Speichern oder exportieren Sie die Tabelle als CSV-Datei
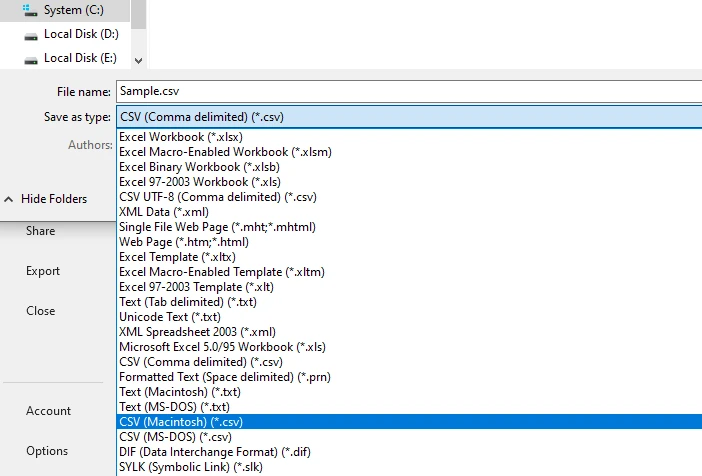
Dieser Arbeitsablauf liefert oft bessere strukturelle Ergebnisse als direktes Kopieren, insbesondere bei einseitigen oder einheitlich formatierten Tabellen.
Praktische Einschränkungen
- Komplexe oder mehrseitige Tabellen können auf mehrere Blätter aufgeteilt werden
- Verbundene Zellen können zu falsch ausgerichteten Spalten in der CSV-Ausgabe führen
- Eine manuelle Bereinigung ist oft vor dem Export erforderlich
- Nicht für die Stapel- oder automatisierte Verarbeitung geeignet
Dieser Ansatz ist effektiv für gelegentliche Konvertierungen, bei denen eine visuelle Validierung wichtig ist, aber er skaliert nicht gut.
Für Benutzer, die eine kostenlose Alternative zu Acrobat suchen, um PDF-Tabellen vor dem Speichern als CSV in Excel zu konvertieren, siehe Wie man PDF kostenlos in Excel konvertiert.
Methode 2: Online-Konvertierung von PDF-Tabellen in CSV
Online-Konverter sind weit verbreitet, da sie keine Installation erfordern und schnelle Ergebnisse liefern.
Wann die Online-Konvertierung eine gute Wahl ist
- Die PDF enthält auswählbaren (nicht gescannten) Text
- Tabellenlayouts sind relativ einfach
- Nur eine kleine Anzahl von Dateien muss konvertiert werden
Typischer Online-Workflow für die Konvertierung von PDF-Tabellen in CSV
Die meisten Online-Tools folgen einem ähnlichen Prozess (Beispiel Zamzar):
-
Öffnen Sie einen Online-Konverter für PDF in CSV
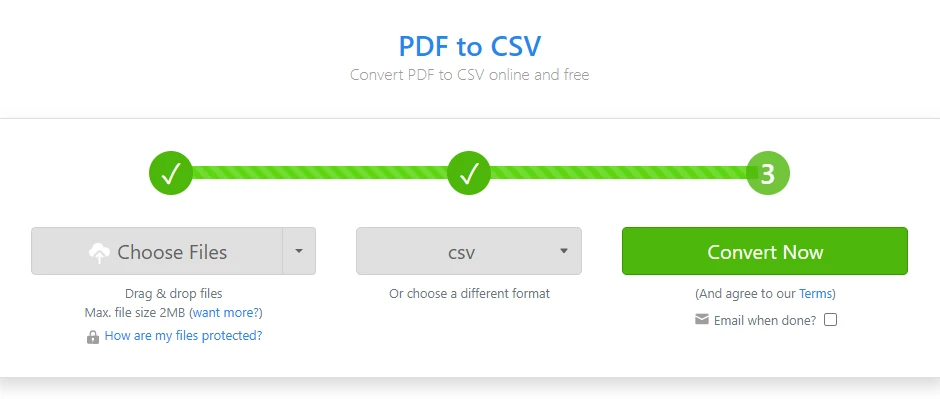
-
Laden Sie die PDF-Datei mit der Tabelle hoch
-
Konfigurieren Sie den Seitenbereich oder die Optionen zur Tabellenerkennung, falls verfügbar
-
Starten Sie den Konvertierungsprozess
-
Laden Sie die generierte CSV-Datei herunter
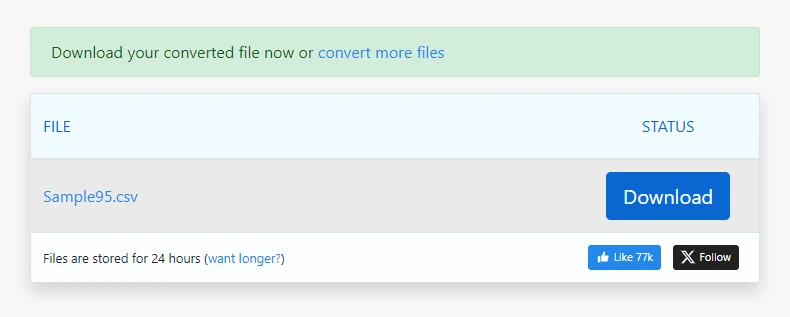
Bei einfachen PDFs kann dieser Prozess in Sekunden eine brauchbare CSV-Ausgabe erzeugen.
Häufige Überlegungen bei Online-Konvertern
- Spalten können sich bei inkonsistentem Abstand verschieben
- Konverter exportieren oft die gesamte PDF als CSV, nicht nur die Tabellen
- Zeilenumbrüche innerhalb von Zellen können zusätzliche Zeilen erzeugen
- Die Ausgabequalität variiert je nach Dokumentenlayout
- Dateigrößenbeschränkungen und Datenschutzbedenken können gelten
Online-Tools sollten eher als eine bequeme Option denn als eine vorhersagbare oder wiederverwendbare Lösung betrachtet werden.
Methode 3: Programmatische Extraktion von PDF-Tabellen mit Python
Wenn Genauigkeit, Konsistenz oder Automatisierung erforderlich sind, ist die programmatische Extraktion oft der zuverlässigste Weg, um PDF-Tabellen in CSV zu konvertieren.
Warum die programmatische Extraktion oft bevorzugt wird
- Tabellen können Seite für Seite verarbeitet werden
- Mehrseitige Tabellen können konsistent behandelt werden
- Dieselbe Extraktionslogik kann in Stapelverarbeitungsaufträgen wiederverwendet werden
- Die Ausgabe ist reproduzierbar und leichter zu validieren
Dieser Ansatz ist in Datenpipelines, Berichtssystemen und Backend-Diensten, die PDFs in großem Umfang verarbeiten, üblich. Mit Spire.PDF für Python können Entwickler Tabellen aus PDF-Dokumenten präzise extrahieren, mehrseitige und komplexe Layouts handhaben und die Konvertierung in CSV mit minimalem manuellem Eingriff automatisieren.
Typischer programmatischer Workflow für PDF-Tabelle zu CSV
Die meisten programmatischen Lösungen folgen einem ähnlichen übergeordneten Prozess:
- Laden Sie das PDF-Dokument
- Iterieren Sie durch jede Seite
- Erkennen Sie Tabellenstrukturen auf jeder Seite
- Extrahieren Sie Zeilen und Spalten als strukturierte Daten
- Normalisieren Sie extrahierten Text bei Bedarf
- Schreiben Sie die strukturierten Daten in CSV-Dateien
Python wird für diese Aufgabe häufig verwendet, da es Lesbarkeit mit starken Datenverarbeitungsfähigkeiten kombiniert.
Beispiel: PDF-Tabellen mit Python in CSV konvertieren
Stellen Sie vor dem Ausführen des folgenden Beispiels sicher, dass die erforderliche PDF-Verarbeitungsbibliothek installiert ist.
Sie können Spire.PDF für Python mit pip installieren:
pip install spire.pdf
Nach der Installation können Sie mit dem Beispiel zur Tabellenextraktion fortfahren.
Das folgende Beispiel zeigt, wie Sie PDF-Tabellen mit Spire.PDF für Python in CSV konvertieren.
import os
import csv
from spire.pdf import PdfDocument, PdfTableExtractor
# Load the PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a table extractor
extractor = PdfTableExtractor(pdf)
# Normalize text to handle PDF ligatures and PUA characters
def normalize_text(text: str) -> str:
if not text:
return text
if not any('\uE000' <= ch <= '\uF8FF' for ch in text):
return text
ligatures = {
'\uE000': 'ff',
'\uE001': 'fi',
'\uE002': 'fl',
'\uE003': 'ffl',
'\uE004': 'ffi',
'\uE005': 'ft',
'\uE006': 'st',
}
for lig, repl in ligatures.items():
text = text.replace(lig, repl)
return text
# Extract tables page by page
for page_index in range(pdf.Pages.Count):
tables = extractor.ExtractTable(page_index)
if tables:
for table_index, table in enumerate(tables):
rows = []
for r in range(table.GetRowCount()):
row = []
for c in range(table.GetColumnCount()):
cell = normalize_text(table.GetText(r, c)).replace("\n", " ")
row.append(cell)
rows.append(row)
os.makedirs("output/Tables", exist_ok=True)
with open(
f"output/Tables/Page{page_index + 1}-Table{table_index + 1}.csv",
"w",
newline="",
encoding="utf-8",
) as f:
writer = csv.writer(f)
writer.writerows(rows)
pdf.Close()
Unten sehen Sie eine Vorschau der Konvertierungsergebnisse von PDF-Tabelle zu CSV:
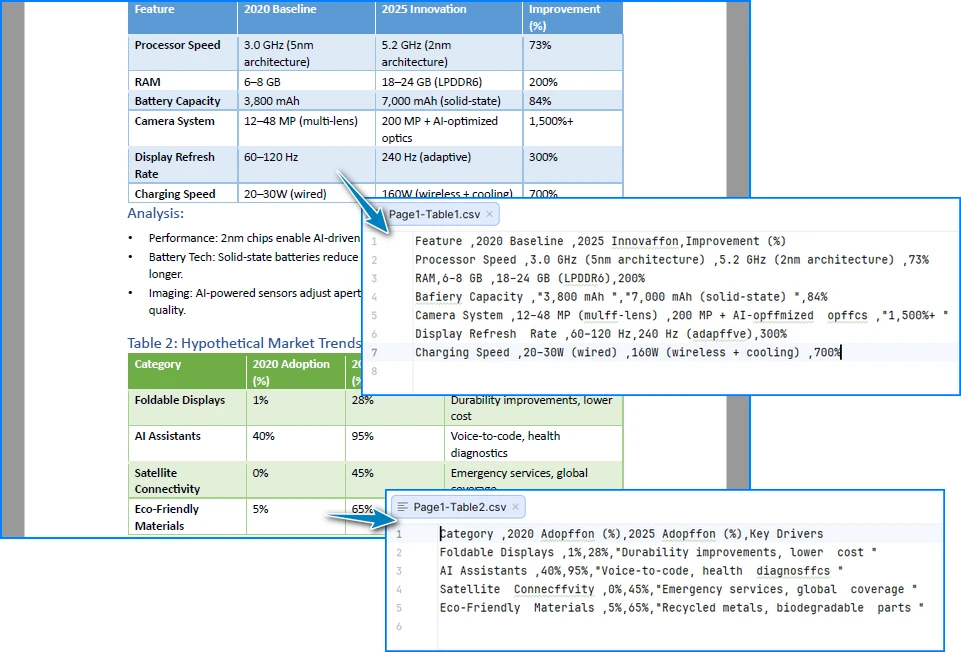
Wie diese Implementierung funktioniert
Diese Implementierung konzentriert sich auf die Beibehaltung der Tabellenstruktur anstatt das Layout aus Textpositionen abzuleiten:
- Extraktion auf Zellenebene stellt sicher, dass Zeilen und Spalten als logische Einheiten erhalten bleiben, anstatt aus Abständen rekonstruiert zu werden
- Seitenweise Verarbeitung verhindert, dass Tabellen über Seitengrenzen hinweg falsch zusammengeführt werden
- Explizite Textnormalisierung behandelt häufige PDF-Probleme wie Ligaturen und privat genutzte Unicode-Zeichen, die die CSV-Ausgabe unbemerkt beschädigen können
- Direktes Schreiben von CSV vermeidet Zwischenformate, die zusätzliche Formatierungsartefakte einführen können
Dadurch sind die generierten CSV-Dateien stabiler und für die automatisierte Verarbeitung besser geeignet. Eine schrittweise Anleitung zum Extrahieren von Tabellen aus PDF-Dokumenten finden Sie unter Detaillierte Anleitung: Tabellen aus PDF extrahieren.
Umgang mit realen PDF-Tabellenszenarien
In realen Arbeitsabläufen verhalten sich PDF-Tabellen oft anders, als sie auf dem Bildschirm aussehen. Typische Probleme sind:
- Tabellen, die sich über mehrere Seiten erstrecken, mit wiederholten oder fehlenden Kopfzeilen
- Leichte Verschiebungen der Spaltenposition zwischen den Seiten
- Zeilen mit leeren, umgebrochenen oder unregelmäßigen Zellen
- Große Stapel von PDFs mit ähnlichen, aber nicht identischen Layouts
Diese Faktoren sind normalerweise der Punkt, an dem generische Export-Tools und Online-Konverter anfangen, inkonsistente CSV-Ausgaben zu produzieren.
Aus praktischer Sicht ist die programmatische Extraktion für diese Fälle besser geeignet, da sie Folgendes ermöglicht:
- Seitenweise Verarbeitung ohne versehentliches Zusammenführen nicht zusammengehöriger Tabellen
- Kontrollierte Handhabung von mehrseitigen Tabellen
- Stabile Spaltenausrichtung auch bei nicht perfekt einheitlichen Layouts
Ein zusätzliches erwähnenswertes Usability-Detail ist die CSV-Kodierung:
- Wenn extrahierte Daten Nicht-ASCII-Zeichen enthalten, können CSV-Dateien, die direkt in Excel geöffnet werden, verstümmelten Text anzeigen
- Das Speichern der CSV-Ausgabe als UTF-8 mit BOM (UTF-8-SIG) hilft, die korrekte Zeichenanzeige ohne manuelle Importschritte sicherzustellen
Diese Überlegungen werden besonders relevant, wenn man mit realen PDFs anstelle von idealisierten Beispielen arbeitet.
Wichtige Erkenntnisse: Konvertierung von PDF-Tabellen in CSV
In der Praxis läuft die Konvertierung einer PDF-Tabelle in CSV normalerweise auf drei Optionen hinaus:
- Der Acrobat-Export eignet sich gut für gelegentliche, visuell überprüfte Konvertierungen, wie z. B. einseitige Rechnungen oder Berichte
- Online-Konverter sind praktisch für einfache, einmalige Aufgaben mit unkomplizierten Tabellen
- Die programmatische Extraktion bietet die zuverlässigsten Ergebnisse für komplexe, mehrseitige oder wiederholte Arbeitsabläufe, insbesondere in automatisierten Pipelines
Die Wahl der richtigen Methode hängt weniger vom Werkzeug selbst ab, sondern mehr davon, wie die extrahierten Daten verwendet werden.
FAQ
Können gescannte PDF-Tabellen direkt in CSV konvertiert werden?
Nein. Gescannte PDFs erfordern OCR, bevor eine Tabellenextraktion möglich ist. Eine schrittweise Anleitung zum Extrahieren von Text aus gescannten PDFs mit Python finden Sie unter Text aus gescannten PDFs mit Python extrahieren.
Ist CSV besser als Excel für extrahierte PDF-Tabellen? CSV ist einfacher und besser für die Automatisierung geeignet, während Excel oft für die manuelle Überprüfung bevorzugt wird.
Ist Python für die Stapelkonvertierung von PDF-Tabellen geeignet? Ja. Python wird aufgrund seiner Flexibilität und Lesbarkeit häufig für die groß angelegte und automatisierte Extraktion von PDF-Tabellen verwendet.