Los archivos PDF son ampliamente utilizados para compartir documentos porque conservan el diseño y el formato en todos los dispositivos. Sin embargo, algunos PDF incluyen permisos de seguridad que impiden a los usuarios copiar texto. Cuando intentas seleccionar o copiar contenido de estos archivos, es posible que veas que la copia está deshabilitada.
Este tipo de archivo a menudo se denomina PDF asegurado, protegido o restringido. A diferencia de los PDF protegidos con contraseña que bloquean la apertura del archivo, estos documentos se pueden ver normalmente, pero ciertas acciones como copiar texto están restringidas.
Afortunadamente, existen varias soluciones gratuitas y prácticas que te permiten extraer o copiar texto de PDF protegidos. En esta guía, exploraremos cinco métodos sencillos, que incluyen herramientas en línea, funciones integradas del sistema y un enfoque de automatización con Python.
Navegación Rápida
- Método 1 — Copiar Texto de un PDF Asegurado Usando Google Docs
- Método 2 — Convertir un PDF Restringido a TXT en Línea
- Método 3 — Captura de Pantalla + OCR para Extraer Texto
- Método 4 — Imprimir un PDF Protegido contra Copia a un Nuevo PDF
- Método 5 — Extraer Texto de un PDF Asegurado Usando Python
¿Por Qué No Puedes Copiar Texto de Algunos PDF?
Muchos creadores de PDF aplican restricciones de permisos para controlar cómo se puede usar el documento. Estos permisos se establecen en la configuración de seguridad del PDF y pueden deshabilitar acciones como:
- Copiar texto
- Editar el documento
- Imprimir el archivo
- Añadir anotaciones
Esto a menudo se conoce como protección contra copia o restricción de contenido. Aunque el documento sigue siendo legible, el visor de PDF impide la selección o copia de texto.
Estas restricciones se utilizan normalmente para proteger la propiedad intelectual o evitar la reutilización no autorizada del contenido. Sin embargo, cuando necesitas reutilizar texto legítimamente, por ejemplo, para investigación, documentación o fines de accesibilidad, es posible que necesites formas alternativas de extraer el contenido.
A continuación se presentan cinco métodos que pueden ayudar.
Método 1 — Copiar Texto de un PDF Asegurado Usando Google Docs
Una de las formas más sencillas de copiar texto de un PDF protegido es abrirlo con Google Docs. Cuando se carga un PDF en Google Drive y se abre en Google Docs, el servicio convierte automáticamente el archivo en un documento editable.
Durante este proceso de conversión, el contenido del PDF se reinterpreta como texto y párrafos, lo que a menudo evita las restricciones básicas de copia. Una vez completada la conversión, puedes seleccionar y copiar fácilmente el texto como en un documento normal.
Pasos
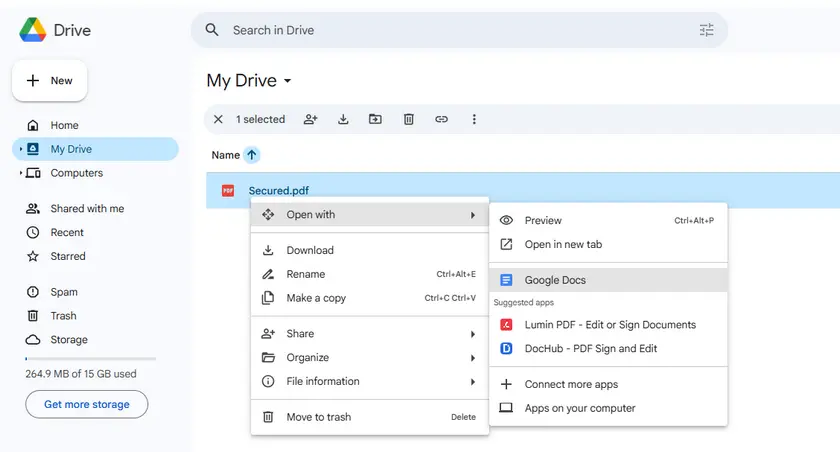
- Abre Google Drive.
- Sube el PDF protegido.
- Haz clic derecho en el archivo y selecciona Abrir con → Google Docs.
- Google Docs convertirá el PDF en un documento editable.
- Copia el texto extraído del documento.
Ventajas
- Gratis y fácil de usar.
- No requiere instalación de software.
- Funciona bien con documentos basados en texto.
Limitaciones
- Los PDF escaneados o basados en imágenes no se convertirán en texto (sin OCR).
- El formato puede desordenarse con diseños complejos.
- Requiere una cuenta de Google y conexión a internet.
Método 2 — Convertir un PDF Restringido a TXT en Línea
Otra solución rápida es convertir el PDF restringido en un archivo de texto sin formato utilizando un convertidor en línea. Una vez que el documento se convierte al formato TXT, el texto se vuelve totalmente editable y se puede copiar sin restricciones.
Una herramienta gratuita y conveniente para este propósito es PDF24 Tools, que proporciona un convertidor de PDF a TXT basado en el navegador. Este método funciona bien cuando necesitas extraer texto rápidamente sin instalar software adicional.
Pasos
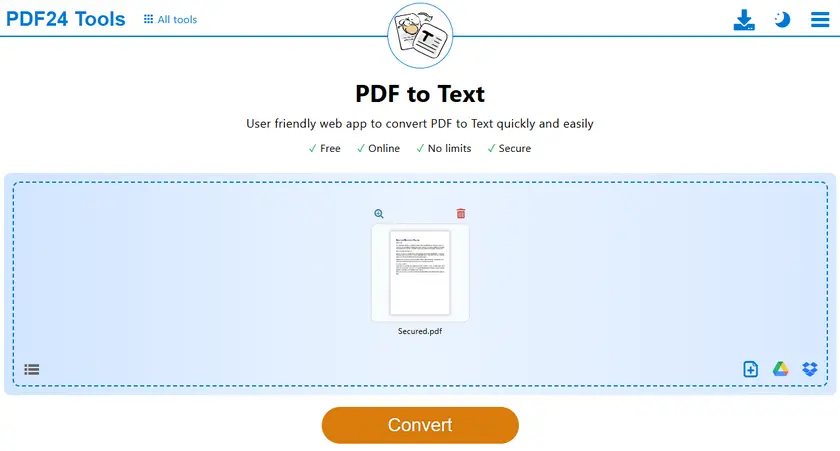
- Abre la herramienta de PDF a TXT.
- Sube tu archivo PDF protegido.
- Inicia el proceso de conversión.
- Descarga el archivo TXT generado.
- Abre el archivo TXT y copia el texto libremente.
Ventajas
- Flujo de trabajo rápido y sencillo.
- No requiere instalación.
Limitaciones
- Riesgo de privacidad: los documentos confidenciales se suben a servidores de terceros.
- A menudo limitado a unas pocas conversiones gratuitas por día.
- Sin soporte de OCR en la mayoría de las herramientas gratuitas (los PDF basados en imágenes no funcionarán).
Método 3 — Captura de Pantalla + OCR para Extraer Texto
Si el PDF tiene fuertes restricciones de copia o contiene páginas escaneadas, el OCR (Reconocimiento Óptico de Caracteres) aún puede recuperar el texto visible. La tecnología OCR analiza la imagen del documento y convierte los caracteres detectados en texto editable.
Windows 11 incluye una función de OCR integrada en la Herramienta de Recortes, que te permite capturar parte de la pantalla y extraer instantáneamente el texto de la imagen.
Pasos
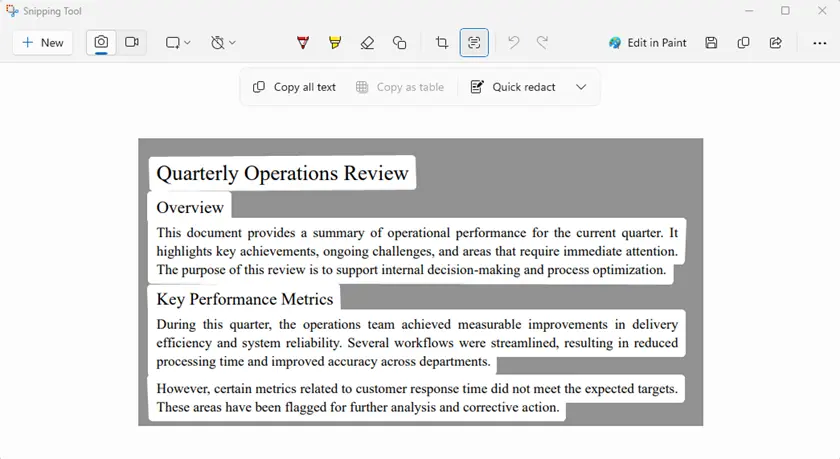
- Abre el PDF protegido en tu pantalla.
- Inicia la Herramienta de Recortes.
- Captura el área que contiene el texto.
- Usa Acciones de Texto → Copiar todo el texto.
- Pega el texto extraído en un documento.
Ventajas
- Evita casi toda la protección contra copia ya que captura la pantalla.
- Funciona con PDF escaneados o basados en imágenes.
Limitaciones
- Consume mucho tiempo si hay muchas páginas.
- Errores de OCR: la precisión depende de la calidad de la imagen y la fuente.
- Proceso manual a menos que se automatice con scripts.
Método 4 — Imprimir un PDF Protegido contra Copia a un Nuevo PDF
Algunos PDF protegidos bloquean la copia pero aún permiten la impresión. En tales casos, puedes imprimir el documento en un nuevo archivo PDF, lo que puede eliminar la restricción de copia.
Esto se puede hacer fácilmente usando la función de impresión integrada en Google Chrome. Después de guardar la versión impresa del archivo, el nuevo PDF puede permitir la selección y copia de texto normal.
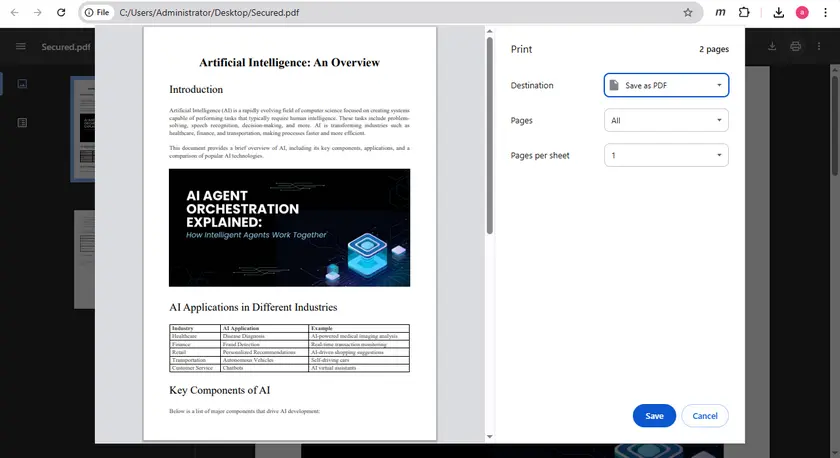
Pasos
- Abre el PDF en Google Chrome.
- Presiona Ctrl + P para abrir el diálogo de impresión.
- Establece el destino en Guardar como PDF.
- Guarda el PDF recién generado.
- Abre el nuevo archivo e intenta copiar el texto.
Ventajas
- Solución simple.
- No se requieren herramientas adicionales.
Limitaciones
- Si la impresión está deshabilitada en los permisos del PDF, esto no funcionará.
- Pueden aparecer algunas diferencias de formato.
Método 5 — Extraer Texto de un PDF Asegurado Usando Python
Para los desarrolladores o usuarios que necesitan procesar múltiples documentos, extraer texto mediante programación puede ser la solución más eficiente. En lugar de copiar contenido manualmente, un script puede leer automáticamente la estructura del PDF y recuperar el texto de cada página.
Usando Free Spire.PDF for Python, puedes extraer fácilmente texto de documentos PDF con solo unas pocas líneas de código. Este enfoque es particularmente útil para la automatización, el procesamiento por lotes o la creación de flujos de trabajo de procesamiento de documentos.
Si estás trabajando con documentos pequeños (dentro de 10 páginas por documento) o probando flujos de trabajo de extracción, la versión gratuita funciona bien. Para archivos más grandes, puedes dividir el documento primero o usar la versión completa.
Instala la biblioteca
pip install spire.pdf.free
Ejemplo: Extraer Texto de Cada Página
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Secured.pdf")
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Create a PdfTextExtractor object
textExtractor = PdfTextExtractor(page)
# Create a PdfTextExtractOptions object
extractOptions = PdfTextExtractOptions()
# Set IsExtractAllText to True
extractOptions.IsExtractAllText = True
# Extract text from the page keeping white spaces
text = textExtractor.ExtractText(extractOptions)
# Write text to a txt file
with open('output/TextOfPage-{}.txt'.format(i + 1), 'w', encoding='utf-8') as file:
lines = text.split("\n")
for line in lines:
if line != '':
file.write(line)
doc.Close()
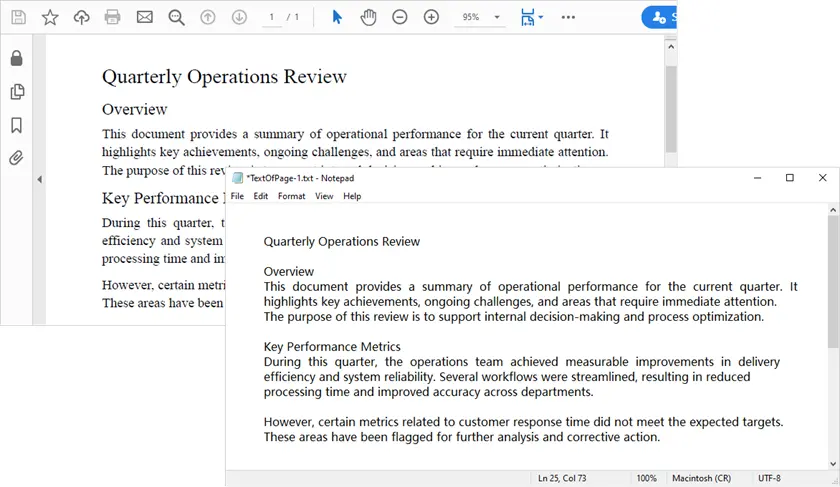
Qué Hace Este Script
- Carga el documento PDF.
- Itera a través de cada página.
- Extrae texto conservando los espacios en blanco.
- Guarda el texto extraído en archivos TXT.
Ventajas
- Control total sobre el proceso de extracción.
- Se puede automatizar para el procesamiento por lotes.
- Funciona bien con PDF basados en texto.
Limitaciones
- Requiere conocimientos de programación.
- No puede manejar PDF basados en imágenes a menos que se utilice una biblioteca de OCR adicional.
También te puede interesar: Realizar OCR en PDF con Python (Extraer Texto de PDF Escaneado)
Tabla Comparativa: ¿Qué Método Deberías Elegir?
| Método | Nivel de Habilidad | Facilidad de Uso | Ideal Para | Funciona con PDF Escaneados | Funciona Bajo Restricciones Fuertes | Procesamiento por Lotes |
|---|---|---|---|---|---|---|
| Google Docs | Principiante | Muy Fácil | Extracción rápida en el navegador | No | Sí | No |
| Convertidor en Línea | Principiante | Muy Fácil | Conversión rápida a TXT | No | Sí | No |
| Captura de Pantalla + OCR | Principiante | Fácil | PDF escaneados o basados en imágenes | Sí | Sí | No |
| Imprimir a PDF | Principiante | Fácil | Eliminar restricciones simples | No | Condicional (La impresión debe estar permitida) | No |
| Python (Spire.PDF) | Desarrollador | Moderado | Automatización y flujos de trabajo por lotes | Depende de bibliotecas de OCR adicionales | Sí | Sí |
Conclusión
Las restricciones de copia en los PDF pueden ser frustrantes, especialmente cuando solo necesitas reutilizar una porción de texto. Afortunadamente, varios métodos gratuitos pueden ayudar a extraer contenido de PDF protegidos.
Para tareas rápidas, herramientas como Google Docs o convertidores en línea pueden ser la solución más fácil. Si el documento contiene contenido escaneado o restricciones estrictas, los métodos basados en OCR aún pueden recuperar el texto. Para flujos de trabajo a gran escala o escenarios de automatización, el uso de bibliotecas de Python como Free Spire.PDF for Python proporciona un enfoque potente y flexible.
Al elegir el método que mejor se adapte a tus necesidades, puedes recuperar eficientemente el texto de los PDF restringidos mientras mantienes un flujo de trabajo eficiente.
Preguntas Frecuentes (FAQ)
P1: ¿Qué es un PDF asegurado o restringido?
Un PDF protegido o restringido es un documento que se puede abrir y ver normalmente pero que tiene configuraciones de seguridad que impiden copiar, imprimir o editar su contenido. Estos permisos son establecidos por el propietario del documento.
P2: ¿Puedo copiar texto de todos los PDF asegurados?
No siempre. Algunos PDF tienen un cifrado fuerte o DRM que impide la copia por completo. En tales casos, pueden ser necesarias herramientas de OCR o bibliotecas profesionales.
P3: ¿Qué método es mejor para los PDF escaneados?
Para los PDF escaneados, la extracción mediante captura de pantalla + OCR o la automatización con Python con bibliotecas de OCR suele ser la forma más confiable de recuperar el texto.
P4: ¿Puedo automatizar la extracción de texto para múltiples PDF?
Sí. Usando bibliotecas de Python como Spire.PDF, puedes extraer texto de múltiples archivos PDF automáticamente, lo que lo hace ideal para el procesamiento por lotes o la automatización de flujos de trabajo.
P5: ¿Necesito pagar por alguno de estos métodos?
Todos los métodos enumerados en el artículo son de uso gratuito. Sin embargo, algunas herramientas (como Spire.PDF) tienen versiones gratuitas con limitaciones, como una restricción en el número de páginas. Para archivos más grandes, es posible que necesites la versión completa.