
Convertir tablas de archivos PDF a formato CSV es un requisito común en los flujos de trabajo de informes, análisis e integración de datos. Los archivos CSV son ligeros, ampliamente compatibles y adecuados para la automatización, lo que los hace mucho más útiles que los PDF estáticos una vez que los datos tabulares necesitan ser reutilizados.
En la práctica, sin embargo, convertir una tabla de PDF a CSV rara vez es sencillo. Los archivos PDF están diseñados para preservar la apariencia visual en lugar de la estructura lógica. Una tabla que parece perfectamente alineada en la pantalla puede no existir como filas y columnas internamente, razón por la cual los métodos de conversión ingenuos a menudo fallan.
Este artículo se centra en prácticos métodos de conversión de tablas de PDF a CSV. En lugar de cubrir todas las opciones teóricas, explica los enfoques más utilizados, cómo se comportan en la práctica y cuándo cada método es apropiado.
Tabla de Contenidos
- Formas Prácticas Comunes de Convertir Tablas de PDF a CSV
- Método 1: Exportar PDF a Hoja de Cálculo Usando Acrobat
- Método 2: Conversión en Línea de Tablas de PDF a CSV
- Método 3: Extracción Programática de Tablas de PDF con Python
- Manejo de Escenarios de Tablas de PDF del Mundo Real
- Puntos Clave: Convertir Tablas de PDF a CSV
- Preguntas Frecuentes
Formas Prácticas Comunes de Convertir Tablas de PDF a CSV
En la mayoría de los flujos de trabajo reales, la conversión de una tabla de PDF a CSV se clasifica en una de las siguientes categorías:
- Exportar tablas a través de herramientas de PDF a hoja de cálculo (como Acrobat)
- Usando conversores en línea de tablas de PDF a CSV
- Extrayendo tablas programáticamente usando código Python
Las técnicas simples de copiar y pegar se excluyen intencionadamente, ya que generalmente aplanan las tablas en texto plano y requieren una reconstrucción manual extensa.
Método 1: Exportar PDF a Hoja de Cálculo Usando Acrobat
Exportar un PDF a un formato de hoja de cálculo y luego guardarlo como CSV es una opción común para los usuarios que prefieren herramientas de escritorio e inspección visual.
Cuándo Funciona Bien Este Método
- El PDF está basado en texto y bien estructurado
- Las tablas tienen límites claros de filas y columnas
- La revisión y corrección manual son aceptables
Flujo de Trabajo Típico Basado en Acrobat
-
Abra el archivo PDF en Acrobat
-
Elija Exportar PDF y seleccione Hoja de cálculo como formato de salida
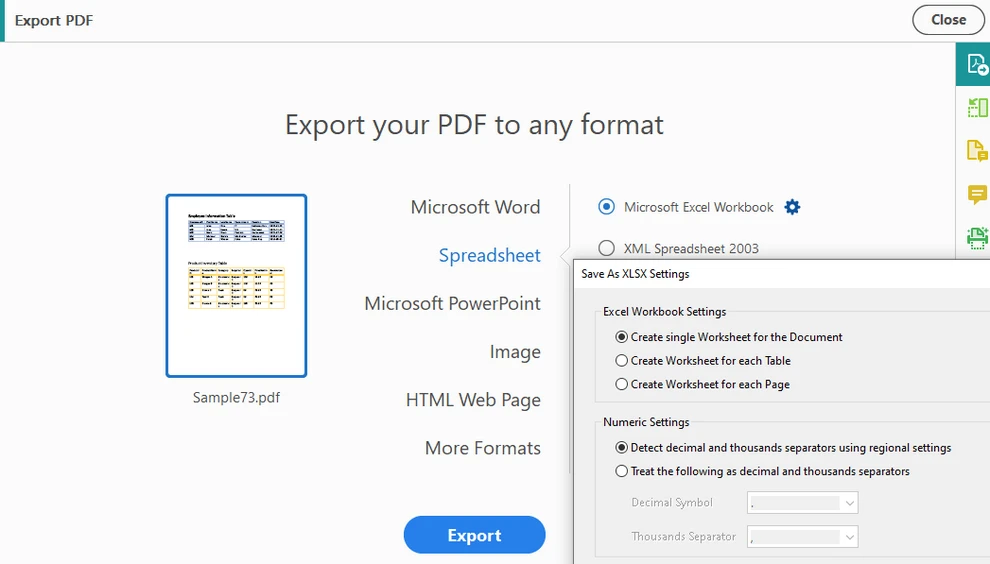
-
Exporte el documento a formato Excel
-
Revise y ajuste la estructura de la tabla si es necesario
-
Guarde o exporte la hoja de cálculo como un archivo CSV
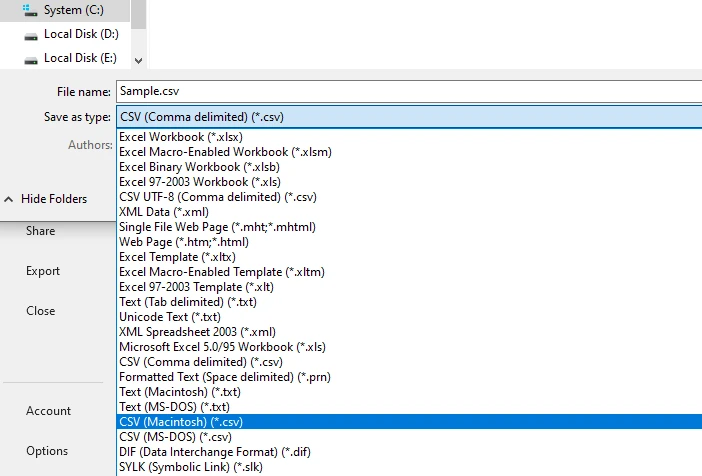
Este flujo de trabajo a menudo produce mejores resultados estructurales que la copia directa, especialmente para tablas de una sola página o con formato consistente.
Limitaciones Prácticas
- Las tablas complejas o de varias páginas pueden dividirse en varias hojas
- Las celdas combinadas pueden provocar columnas desalineadas en la salida CSV
- A menudo se requiere una limpieza manual antes de la exportación
- No es adecuado para el procesamiento por lotes o automatizado
Este enfoque es efectivo para conversiones ocasionales donde la validación visual es importante, pero no escala bien.
Para los usuarios que buscan una alternativa gratuita a Acrobat para convertir tablas de PDF a Excel antes de guardarlas como CSV, consulte Cómo Convertir PDF a Excel Gratis.
Método 2: Conversión en Línea de Tablas de PDF a CSV
Los conversores en línea son muy utilizados porque no requieren instalación y proporcionan resultados rápidos.
Cuándo es Adecuada la Conversión en Línea
- El PDF contiene texto seleccionable (no escaneado)
- Los diseños de las tablas son relativamente simples
- Solo se necesita convertir un número pequeño de archivos
Flujo de Trabajo Típico de Conversión de Tablas de PDF a CSV en Línea
La mayoría de las herramientas en línea siguen un proceso similar (Zamzar ejemplo):
-
Abra un conversor de PDF a CSV en línea
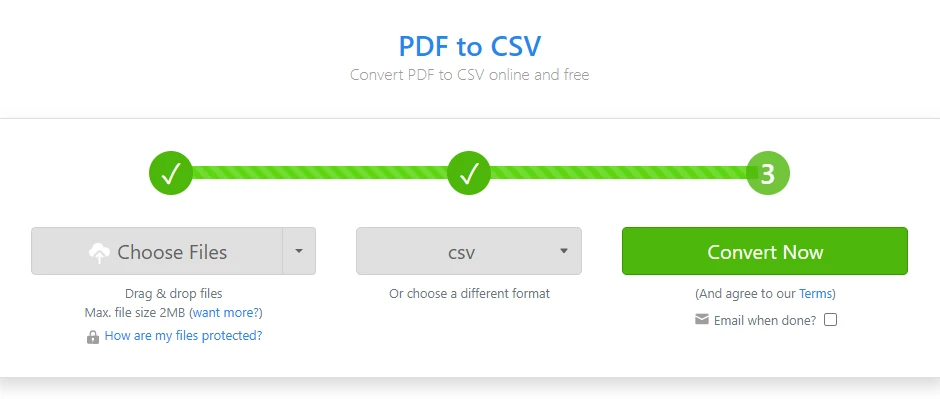
-
Suba el archivo PDF que contiene la tabla
-
Configure el rango de páginas o las opciones de detección de tablas, si están disponibles
-
Inicie el proceso de conversión
-
Descargue el archivo CSV generado
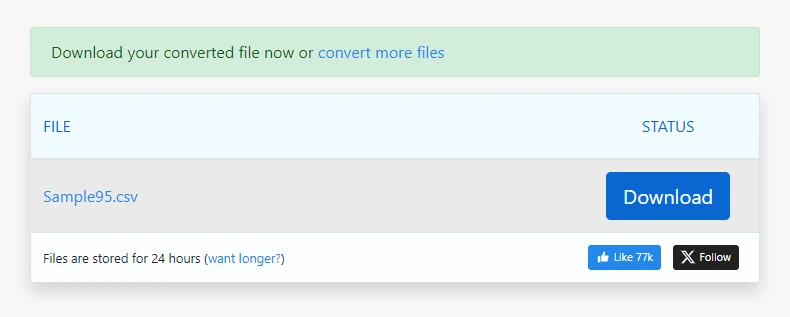
Para PDF sencillos, este proceso puede generar una salida CSV utilizable en segundos.
Consideraciones Comunes con los Conversores en Línea
- Las columnas pueden desplazarse cuando el espaciado es inconsistente
- Los conversores a menudo exportan todo el PDF como CSV, no solo las tablas
- Los saltos de línea dentro de las celdas pueden crear filas adicionales
- La calidad de la salida varía según el diseño del documento
- Pueden aplicarse límites de tamaño de archivo y preocupaciones de privacidad
Las herramientas en línea se deben tratar como una opción de conveniencia en lugar de una solución predecible o reutilizable.
Método 3: Extracción Programática de Tablas de PDF con Python
Cuando se requiere precisión, consistencia o automatización, la extracción programática suele ser la forma más confiable de convertir tablas de PDF a CSV.
Por Qué a Menudo se Prefiere la Extracción Programática
- Las tablas se pueden procesar página por página
- Las tablas de varias páginas se pueden manejar de manera consistente
- La misma lógica de extracción se puede reutilizar en trabajos por lotes
- La salida es reproducible y más fácil de validar
Este enfoque es común en las canalizaciones de datos, los sistemas de informes y los servicios de backend que procesan PDF a escala. Con Spire.PDF for Python, los desarrolladores pueden extraer tablas con precisión de documentos PDF, manejar diseños complejos y de varias páginas, y automatizar la conversión a CSV con una mínima intervención manual.
Flujo de Trabajo Programático Típico para Convertir Tablas de PDF a CSV
La mayoría de las soluciones programáticas siguen un proceso similar de alto nivel:
- Cargar el documento PDF
- Iterar a través de cada página
- Detectar estructuras de tabla en cada página
- Extraer filas y columnas como datos estructurados
- Normalizar el texto extraído cuando sea necesario
- Escribir los datos estructurados en archivos CSV
Python es ampliamente utilizado para esta tarea porque combina legibilidad con potentes capacidades de procesamiento de datos.
Ejemplo: Convertir Tablas de PDF a CSV Usando Python
Antes de ejecutar el siguiente ejemplo, asegúrese de que la biblioteca de procesamiento de PDF requerida esté instalada.
Puede instalar Spire.PDF para Python usando pip:
pip install spire.pdf
Una vez instalado, puede continuar con el ejemplo de extracción de tablas.
El siguiente ejemplo demuestra cómo convertir tablas de PDF a CSV usando Spire.PDF for Python.
import os
import csv
from spire.pdf import PdfDocument, PdfTableExtractor
# Load the PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a table extractor
extractor = PdfTableExtractor(pdf)
# Normalize text to handle PDF ligatures and PUA characters
def normalize_text(text: str) -> str:
if not text:
return text
if not any('\uE000' <= ch <= '\uF8FF' for ch in text):
return text
ligatures = {
'\uE000': 'ff',
'\uE001': 'fi',
'\uE002': 'fl',
'\uE003': 'ffl',
'\uE004': 'ffi',
'\uE005': 'ft',
'\uE006': 'st',
}
for lig, repl in ligatures.items():
text = text.replace(lig, repl)
return text
# Extract tables page by page
for page_index in range(pdf.Pages.Count):
tables = extractor.ExtractTable(page_index)
if tables:
for table_index, table in enumerate(tables):
rows = []
for r in range(table.GetRowCount()):
row = []
for c in range(table.GetColumnCount()):
cell = normalize_text(table.GetText(r, c)).replace("\n", " ")
row.append(cell)
rows.append(row)
os.makedirs("output/Tables", exist_ok=True)
with open(
f"output/Tables/Page{page_index + 1}-Table{table_index + 1}.csv",
"w",
newline="",
encoding="utf-8",
) as f:
writer = csv.writer(f)
writer.writerows(rows)
pdf.Close()
A continuación se muestra una vista previa de los resultados de la conversión de tablas de PDF a CSV:
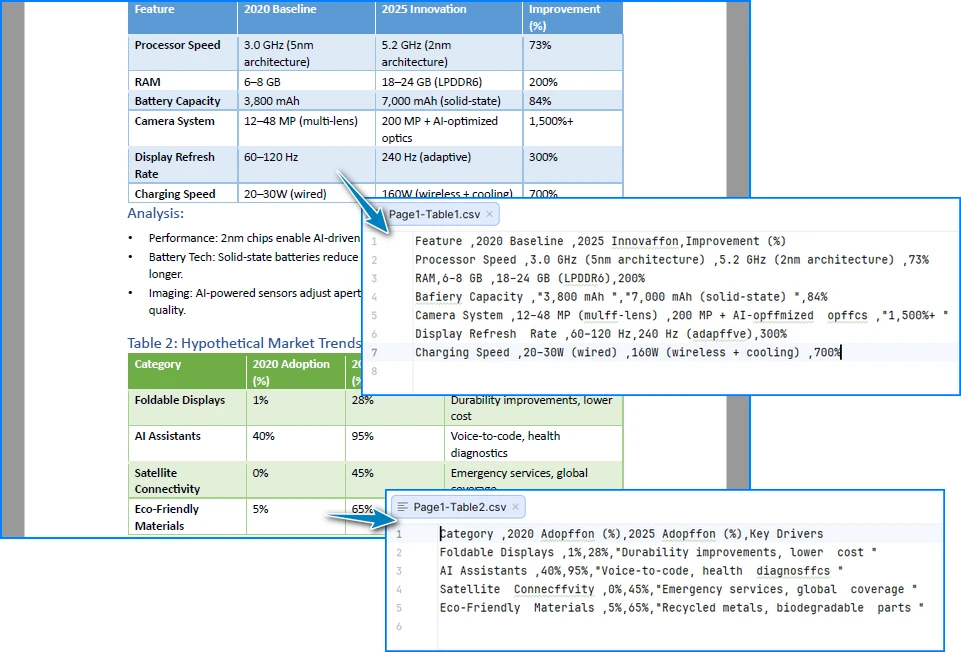
Cómo Funciona Esta Implementación
Esta implementación se centra en preservar la estructura de la tabla en lugar de inferir el diseño a partir de las posiciones del texto:
- Extracción a nivel de celda asegura que las filas y columnas se conserven como unidades lógicas en lugar de ser reconstruidas a partir del espaciado
- Procesamiento página por página evita que las tablas se fusionen incorrectamente a través de los límites de las páginas
- Normalización explícita del texto maneja problemas comunes de PDF como ligaduras y caracteres Unicode de uso privado, que pueden corromper silenciosamente la salida CSV
- Escritura directa a CSV evita formatos intermedios que pueden introducir artefactos de formato adicionales
Como resultado, los archivos CSV generados son más estables y adecuados para el procesamiento automatizado. Para una guía paso a paso sobre cómo extraer tablas de documentos PDF, consulte Guía Detallada: Extracción de Tablas de PDF.
Manejo de Escenarios de Tablas de PDF del Mundo Real
En los flujos de trabajo del mundo real, las tablas de PDF a menudo se comportan de manera diferente a como se ven en la pantalla. Los problemas típicos incluyen:
- Tablas que abarcan varias páginas con encabezados repetidos o faltantes
- Ligeros desplazamientos de la posición de las columnas entre páginas
- Filas con celdas vacías, ajustadas o irregulares
- Grandes lotes de PDF con diseños similares pero no idénticos
Estos factores suelen ser donde las herramientas de exportación genéricas y los conversores en línea comienzan a producir una salida CSV inconsistente.
Desde una perspectiva práctica, la extracción programática es más adecuada para estos casos porque permite:
- Procesamiento página por página sin fusionar accidentalmente tablas no relacionadas
- Manejo controlado de tablas de varias páginas
- Alineación de columna estable incluso cuando los diseños no son perfectamente uniformes
Un detalle adicional de usabilidad que vale la pena señalar es la codificación CSV:
- Cuando los datos extraídos incluyen caracteres no ASCII, los archivos CSV abiertos directamente en Excel pueden mostrar texto ilegible
- Guardar la salida CSV como UTF-8 con BOM (UTF-8-SIG) ayuda a garantizar la visualización correcta de los caracteres sin pasos de importación manual
Estas consideraciones se vuelven especialmente relevantes cuando se trabaja con PDF del mundo real en lugar de ejemplos idealizados.
Puntos Clave: Convertir Tablas de PDF a CSV
En la práctica, la conversión de una tabla de PDF a CSV generalmente se reduce a tres opciones:
- Exportación de Acrobat funciona bien para conversiones ocasionales y verificadas visualmente, como facturas o informes de una sola página
- Conversores en línea son convenientes para tareas simples y únicas con tablas sencillas
- Extracción programática ofrece los resultados más confiables para flujos de trabajo complejos, de varias páginas o repetidos, especialmente en canalizaciones automatizadas
Elegir el método correcto depende menos de la herramienta en sí y más de cómo se utilizarán los datos extraídos.
Preguntas Frecuentes
¿Se pueden convertir las tablas de PDF escaneadas a CSV directamente?
No. Los PDF escaneados requieren OCR antes de que sea posible la extracción de tablas. Para una guía paso a paso sobre cómo extraer texto de PDF escaneados usando Python, consulte Extracción de Texto de PDF Escaneados con Python.
¿Es CSV mejor que Excel para las tablas de PDF extraídas? CSV es más simple y más adecuado para la automatización, mientras que Excel a menudo se prefiere para la revisión manual.
¿Es Python adecuado para la conversión por lotes de tablas de PDF? Sí. Python es ampliamente utilizado para la extracción de tablas de PDF a gran escala y automatizada debido a su flexibilidad y legibilidad.