
La conversion de tableaux de fichiers PDF au format CSV est une exigence courante dans les flux de travail de reporting, d'analyse et d'intégration de données. Les fichiers CSV sont légers, largement pris en charge et bien adaptés à l'automatisation, ce qui les rend beaucoup plus utiles que les PDF statiques une fois que les données tabulaires doivent être réutilisées.
En pratique, cependant, la conversion d'un tableau PDF en CSV est rarement simple. Les fichiers PDF sont conçus pour préserver l'apparence visuelle plutôt que la structure logique. Un tableau qui semble parfaitement aligné à l'écran peut ne pas exister en tant que lignes et colonnes en interne, c'est pourquoi les méthodes de conversion naïves échouent souvent.
Cet article se concentre sur les méthodes pratiques de conversion de tableaux PDF en CSV. Au lieu de couvrir toutes les options théoriques, il explique les approches les plus couramment utilisées, leur comportement en pratique et quand chaque méthode est appropriée.
Table des matières
- Méthodes pratiques courantes pour convertir des tableaux PDF en CSV
- Méthode 1 : Exporter un PDF vers une feuille de calcul à l'aide d'Acrobat
- Méthode 2 : Conversion en ligne de tableaux PDF en CSV
- Méthode 3 : Extraction programmatique de tableaux PDF avec Python
- Gestion des scénarios de tableaux PDF réels
- Points clés à retenir : Conversion de tableaux PDF en CSV
- FAQ
Méthodes pratiques courantes pour convertir des tableaux PDF en CSV
Dans la plupart des flux de travail réels, la conversion d'un tableau PDF en CSV entre dans l'une des catégories suivantes :
- Exportation de tableaux via des outils de conversion de PDF en feuille de calcul (tels qu'Acrobat)
- Utilisation de convertisseurs en ligne de tableaux PDF en CSV
- Extraction de tableaux par programmation à l'aide de code Python
Les techniques simples de copier-coller sont intentionnellement exclues, car elles aplatissent généralement les tableaux en texte brut et nécessitent une reconstruction manuelle approfondie.
Méthode 1 : Exporter un PDF vers une feuille de calcul à l'aide d'Acrobat
L'exportation d'un PDF vers un format de feuille de calcul, puis son enregistrement au format CSV est un choix courant pour les utilisateurs qui préfèrent les outils de bureau et l'inspection visuelle.
Quand cette méthode fonctionne bien
- Le PDF est basé sur du texte et bien structuré
- Les tableaux ont des limites de lignes et de colonnes claires
- La révision et la correction manuelles sont acceptables
Flux de travail typique basé sur Acrobat
-
Ouvrez le fichier PDF dans Acrobat
-
Choisissez Exporter le PDF et sélectionnez Feuille de calcul comme format de sortie
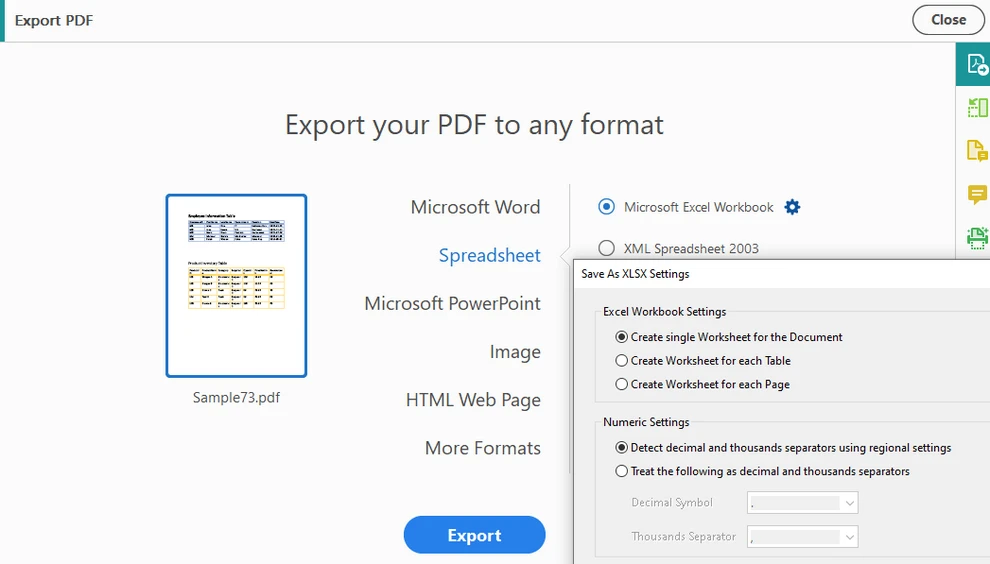
-
Exportez le document au format Excel
-
Révisez et ajustez la structure du tableau si nécessaire
-
Enregistrez ou exportez la feuille de calcul en tant que fichier CSV
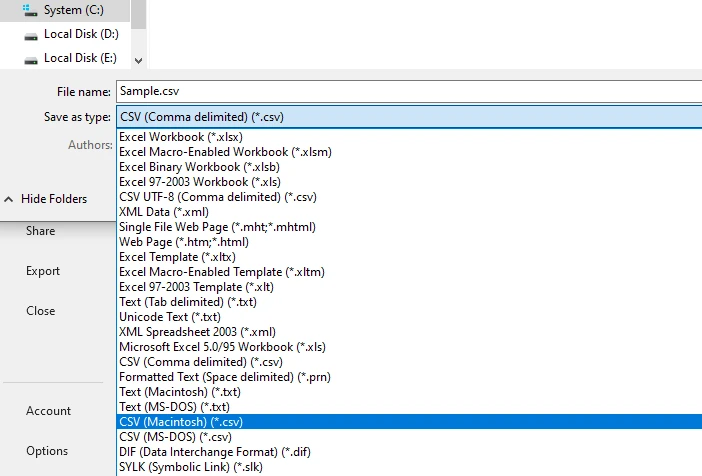
Ce flux de travail produit souvent de meilleurs résultats structurels que la copie directe, en particulier pour les tableaux d'une seule page ou formatés de manière cohérente.
Limites pratiques
- Les tableaux complexes ou de plusieurs pages peuvent être répartis sur plusieurs feuilles
- Les cellules fusionnées peuvent entraîner des colonnes mal alignées dans la sortie CSV
- Un nettoyage manuel est souvent nécessaire avant l'exportation
- Ne convient pas au traitement par lots ou automatisé
Cette approche est efficace pour les conversions occasionnelles où la validation visuelle est importante, mais elle ne s'adapte pas bien.
Pour les utilisateurs à la recherche d'une alternative gratuite à Acrobat pour convertir des tableaux PDF en Excel avant de les enregistrer en CSV, consultez Comment convertir un PDF en Excel gratuitement.
Méthode 2 : Conversion en ligne de tableaux PDF en CSV
Les convertisseurs en ligne sont largement utilisés car ils ne nécessitent aucune installation et fournissent des résultats rapides.
Quand la conversion en ligne est une bonne solution
- Le PDF contient du texte sélectionnable (non numérisé)
- Les mises en page des tableaux sont relativement simples
- Seul un petit nombre de fichiers nécessite une conversion
Flux de travail typique de conversion de tableau PDF en CSV en ligne
La plupart des outils en ligne suivent un processus similaire (exemple de Zamzar) :
-
Ouvrez un convertisseur PDF en CSV en ligne
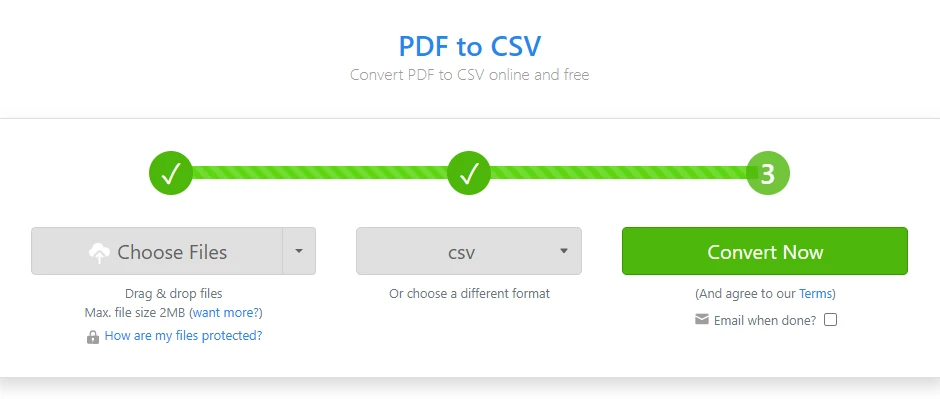
-
Téléchargez le fichier PDF contenant le tableau
-
Configurez la plage de pages ou les options de détection de tableau, si disponibles
-
Démarrez le processus de conversion
-
Téléchargez le fichier CSV généré
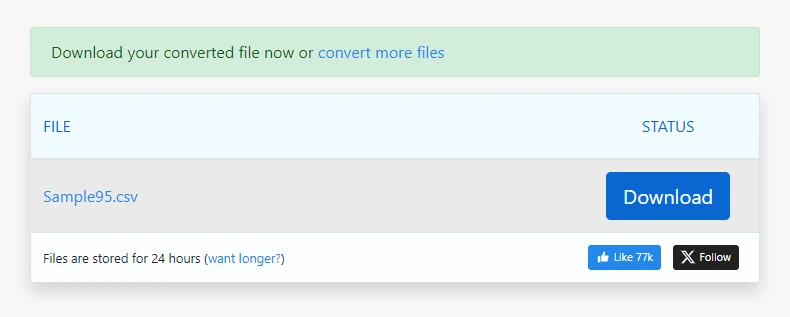
Pour les PDF simples, ce processus peut générer une sortie CSV utilisable en quelques secondes.
Considérations courantes avec les convertisseurs en ligne
- Les colonnes peuvent se décaler lorsque l'espacement est incohérent
- Les convertisseurs exportent souvent l'intégralité du PDF au format CSV, et pas seulement les tableaux
- Les sauts de ligne à l'intérieur des cellules peuvent créer des lignes supplémentaires
- La qualité de la sortie varie en fonction de la mise en page du document
- Des limites de taille de fichier et des problèmes de confidentialité peuvent s'appliquer
Les outils en ligne doivent être considérés comme une option pratique plutôt que comme une solution prévisible ou réutilisable.
Méthode 3 : Extraction programmatique de tableaux PDF avec Python
Lorsque la précision, la cohérence ou l'automatisation sont requises, l'extraction programmatique est souvent le moyen le plus fiable de convertir des tableaux PDF en CSV.
Pourquoi l'extraction programmatique est souvent préférée
- Les tableaux peuvent être traités page par page
- Les tableaux de plusieurs pages peuvent être traités de manière cohérente
- La même logique d'extraction peut être réutilisée dans des travaux par lots
- La sortie est reproductible et plus facile à valider
Cette approche est courante dans les pipelines de données, les systèmes de reporting et les services backend qui traitent les PDF à grande échelle. Avec Spire.PDF for Python, les développeurs peuvent extraire avec précision des tableaux de documents PDF, gérer des mises en page complexes et de plusieurs pages, et automatiser la conversion en CSV avec une intervention manuelle minimale.
Flux de travail programmatique typique pour la conversion de tableau PDF en CSV
La plupart des solutions programmatiques suivent un processus de haut niveau similaire :
- Charger le document PDF
- Parcourir chaque page
- Détecter les structures de tableau sur chaque page
- Extraire les lignes et les colonnes en tant que données structurées
- Normaliser le texte extrait si nécessaire
- Écrire les données structurées dans des fichiers CSV
Python est largement utilisé pour cette tâche car il combine la lisibilité avec de solides capacités de traitement de données.
Exemple : Convertir des tableaux PDF en CSV à l'aide de Python
Avant d'exécuter l'exemple ci-dessous, assurez-vous que la bibliothèque de traitement PDF requise est installée.
Vous pouvez installer Spire.PDF for Python à l'aide de pip :
pip install spire.pdf
Une fois installé, vous pouvez procéder à l'exemple d'extraction de tableau.
L'exemple suivant montre comment convertir des tableaux PDF en CSV à l'aide de Spire.PDF for Python.
import os
import csv
from spire.pdf import PdfDocument, PdfTableExtractor
# Load the PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a table extractor
extractor = PdfTableExtractor(pdf)
# Normalize text to handle PDF ligatures and PUA characters
def normalize_text(text: str) -> str:
if not text:
return text
if not any('\uE000' <= ch <= '\uF8FF' for ch in text):
return text
ligatures = {
'\uE000': 'ff',
'\uE001': 'fi',
'\uE002': 'fl',
'\uE003': 'ffl',
'\uE004': 'ffi',
'\uE005': 'ft',
'\uE006': 'st',
}
for lig, repl in ligatures.items():
text = text.replace(lig, repl)
return text
# Extract tables page by page
for page_index in range(pdf.Pages.Count):
tables = extractor.ExtractTable(page_index)
if tables:
for table_index, table in enumerate(tables):
rows = []
for r in range(table.GetRowCount()):
row = []
for c in range(table.GetColumnCount()):
cell = normalize_text(table.GetText(r, c)).replace("\n", " ")
row.append(cell)
rows.append(row)
os.makedirs("output/Tables", exist_ok=True)
with open(
f"output/Tables/Page{page_index + 1}-Table{table_index + 1}.csv",
"w",
newline="",
encoding="utf-8",
) as f:
writer = csv.writer(f)
writer.writerows(rows)
pdf.Close()
Voici un aperçu des résultats de la conversion du tableau PDF en CSV :
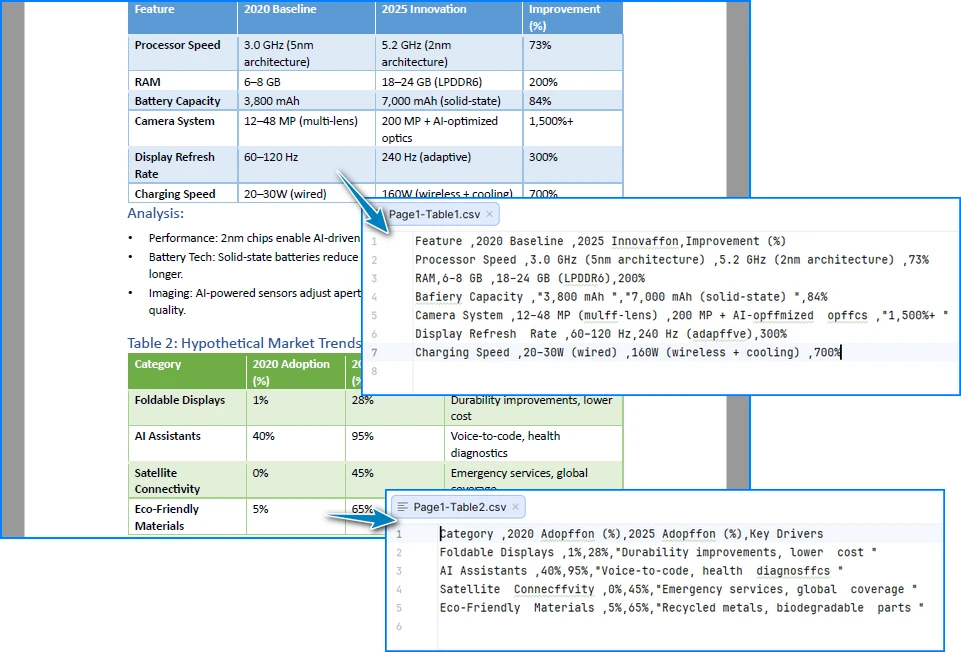
Comment cette implémentation fonctionne
Cette implémentation se concentre sur la préservation de la structure du tableau plutôt que sur l'inférence de la mise en page à partir des positions du texte :
- L'extraction au niveau de la cellule garantit que les lignes et les colonnes sont conservées en tant qu'unités logiques au lieu d'être reconstruites à partir de l'espacement
- Le traitement page par page empêche la fusion incorrecte des tableaux au-delà des limites de page
- La normalisation explicite du texte gère les problèmes courants des PDF tels que les ligatures et les caractères Unicode à usage privé, qui peuvent corrompre silencieusement la sortie CSV
- L'écriture directe en CSV évite les formats intermédiaires qui могут introduire des artefacts de formatage supplémentaires
En conséquence, les fichiers CSV générés sont plus stables et adaptés au traitement automatisé. Pour un guide étape par étape sur l'extraction de tableaux à partir de documents PDF, consultez Guide détaillé : Extraction de tableaux à partir de PDF.
Gestion des scénarios de tableaux PDF réels
Dans les flux de travail réels, les tableaux PDF se comportent souvent différemment de leur apparence à l'écran. Les problèmes typiques incluent :
- Tableaux s'étendant sur plusieurs pages avec des en-têtes répétés ou manquants
- Légers décalages de position des colonnes entre les pages
- Lignes avec des cellules vides, renvoyées à la ligne ou irrégulières
- Grands lots de PDF avec des mises en page similaires mais non identiques
Ces facteurs sont généralement là où les outils d'exportation génériques et les convertisseurs en ligne commencent à produire une sortie CSV incohérente.
D'un point de vue pratique, l'extraction programmatique est mieux adaptée à ces cas car elle permet :
- Traitement page par page sans fusionner accidentellement des tableaux non liés
- Gestion contrôlée des tableaux de plusieurs pages
- Alignement stable des colonnes même lorsque les mises en page ne sont pas parfaitement uniformes
Un détail d'utilisabilité supplémentaire à noter est l'encodage CSV :
- Lorsque les données extraites incluent des caractères non-ASCII, les fichiers CSV ouverts directement dans Excel peuvent afficher du texte brouillé
- L'enregistrement de la sortie CSV en tant que UTF-8 avec BOM (UTF-8-SIG) permet d'assurer un affichage correct des caractères sans étapes d'importation manuelles
Ces considérations deviennent particulièrement pertinentes lorsque l'on travaille avec des PDF du monde réel plutôt qu'avec des exemples idéalisés.
Points clés à retenir : Conversion de tableaux PDF en CSV
En pratique, la conversion d'un tableau PDF en CSV se résume généralement à trois options :
- L'exportation Acrobat fonctionne bien pour les conversions occasionnelles et vérifiées visuellement, telles que les factures ou les rapports d'une seule page
- Les convertisseurs en ligne sont pratiques pour les tâches simples et ponctuelles avec des tableaux simples
- L'extraction programmatique offre les résultats les plus fiables pour les flux de travail complexes, de plusieurs pages ou répétés, en particulier dans les pipelines automatisés
Le choix de la bonne méthode dépend moins de l'outil lui-même que de la manière dont les données extraites seront utilisées.
FAQ
Les tableaux PDF numérisés peuvent-ils être convertis directement en CSV ?
Non. Les PDF numérisés nécessitent une OCR avant que l'extraction de tableau ne soit possible. Pour un guide étape par étape sur l'extraction de texte à partir de PDF numérisés à l'aide de Python, consultez Extraction de texte à partir de PDF numérisés avec Python.
Le CSV est-il meilleur qu'Excel pour les tableaux PDF extraits ? Le CSV est plus simple et mieux adapté à l'automatisation, tandis qu'Excel est souvent préféré pour la révision manuelle.
Python est-il adapté à la conversion par lots de tableaux PDF ? Oui. Python est largement utilisé pour l'extraction de tableaux PDF à grande échelle et automatisée en raison de sa flexibilité et de sa lisibilité.