
I PDF sono ottimi per preservare il layout dei documenti, ma estrarre dati tabellari da essi può essere frustrante. Il motivo principale è che i PDF sono progettati per una visualizzazione coerente su diversi dispositivi, non per l'estrazione di dati strutturati. Di conseguenza, le tabelle possono esistere come testo selezionabile nei PDF digitali o come immagini nei file scansionati, con strutture che variano ampiamente.
Fortunatamente, ci sono diversi modi pratici per estrarre tabelle dai PDF, a seconda delle tue esigenze e del tuo livello di comfort tecnico. In questa guida, ti illustreremo quattro metodi efficaci, da strumenti semplici senza codice come Excel e Google Documenti a una potente soluzione basata su Python per un controllo completo e l'automazione.
Panoramica dei metodi:
- Metodo 1: Microsoft Excel (Importazione PDF integrata)
- Metodo 2: Google Documenti (Gratuito e Semplice)
- Metodo 3: Adobe Acrobat Pro (Funzione di Esportazione)
- Metodo 4: Python (Controllo Completo e Automazione)
Metodo 1: Microsoft Excel (Importazione PDF integrata)
Ideale per: Utenti Windows con Microsoft Office 365 o Excel 2016+ (solo Windows).
Microsoft Excel dispone di una funzione di importazione PDF nativa che funziona sorprendentemente bene per i PDF digitali. Si collega direttamente al file e tenta di rilevare e convertire le tabelle.
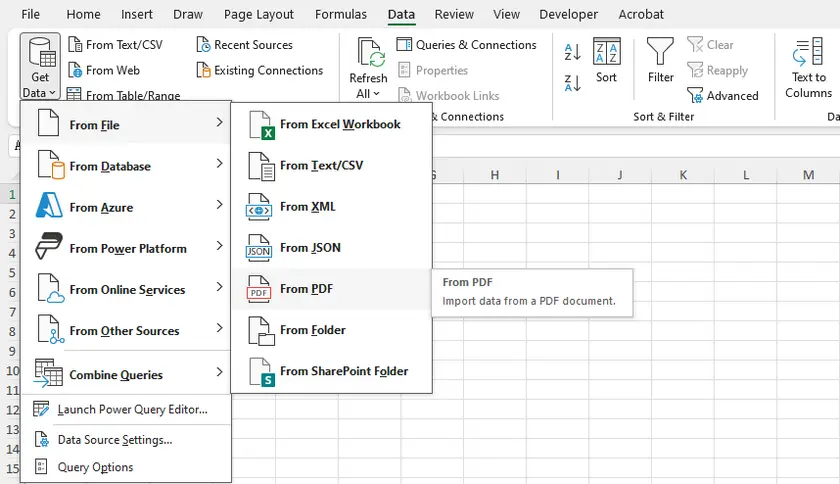
Istruzioni Passo-Passo
- Apri Microsoft Excel.
- Vai su Dati → Recupera dati → Da file → Da PDF.
- Sfoglia e seleziona il tuo file PDF.
- Apparirà una finestra di navigazione che mostra tutte le tabelle e le pagine rilevate.
- Seleziona le tabelle che desideri e fai clic su Carica (per importare direttamente) o Trasforma dati (per pulire prima del caricamento).
- Excel importerà la tabella in un foglio di lavoro, preservando la struttura di righe/colonne in modo ragionevolmente buono.
Pro e Contro
| Pro | Contro |
|---|---|
| Nessun software aggiuntivo necessario (con Office) | Solo per Windows |
| Preserva i formati numerici | Difficoltà con celle unite |
| Buono per PDF digitali basati su testo | Nessun OCR per PDF scansionati |
| Può aggiornare i dati se il PDF viene modificato | Può essere lento con PDF di grandi dimensioni |
Metodo 2: Google Documenti (Gratuito e Semplice)
Ideale per: Estrazioni rapide e occasionali quando non si dispone di Excel o di strumenti a pagamento.
Google Documenti offre un metodo nascosto ma gratuito per estrarre tabelle dai PDF. Funziona convertendo l'intero PDF in un Google Document modificabile, dove le tabelle diventano griglie basate su testo.
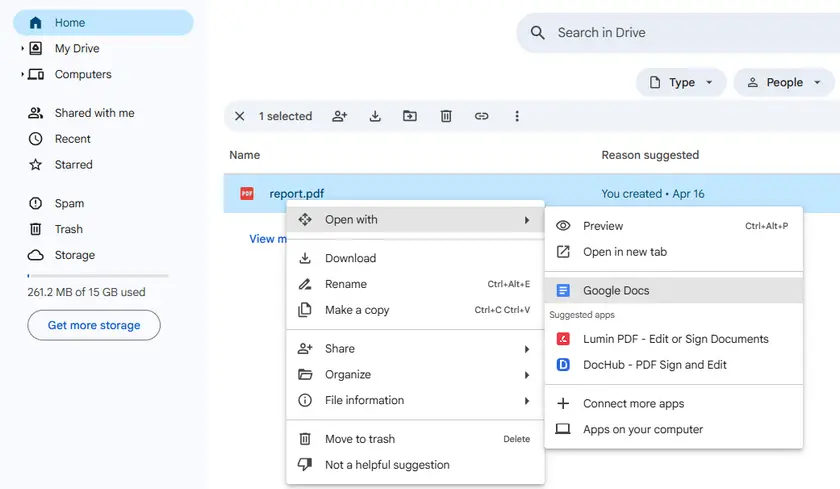
Istruzioni Passo-Passo
- Carica il PDF su Google Drive.
- Fai clic con il pulsante destro del mouse sul PDF → Apri con → Google Documenti.
- Attendi che Google Documenti elabori il file.
- Scorri per trovare la tabella. Apparirà come una griglia basata su testo (righe e colonne separate da spazi o tabulazioni).
- Copia l'area della tabella e incollala in Google Fogli o Microsoft Excel.
Pro e Contro
| Pro | Contro |
|---|---|
| Completamente gratuito | Nessun rilevamento di tabelle reale (solo allineamento del testo) |
| Nessuna installazione di software | Risultati disordinati con tabelle complesse |
| Funziona su qualsiasi sistema operativo con un browser | Scarsa gestione di celle unite o celle multilinea |
| Gestisce tabelle semplici in modo affidabile | Nessun OCR (i PDF scansionati appaiono come immagini) |
Metodo 3: Adobe Acrobat Pro (Funzione di Esportazione)
Ideale per: Professionisti che dispongono già di Acrobat Pro e necessitano di esportazioni affidabili da PDF digitali.
Adobe Acrobat Pro (non il Reader gratuito) dispone di una funzione di esportazione integrata che converte le tabelle PDF direttamente in Excel o CSV. Preserva più formattazione rispetto agli strumenti gratuiti.
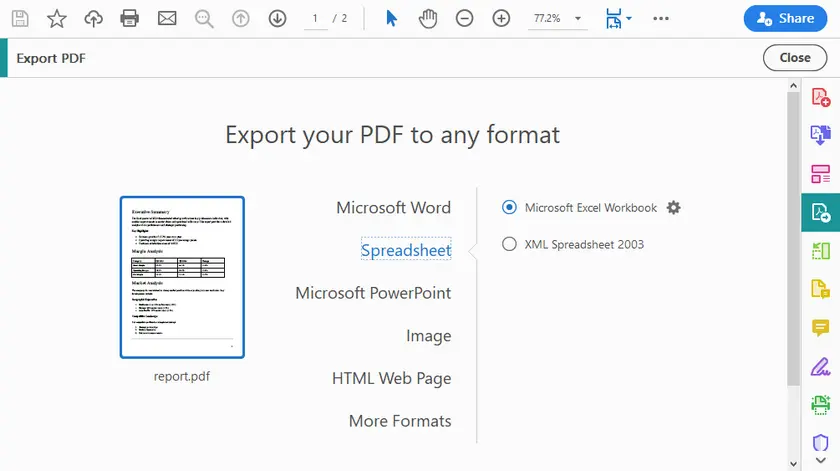
Istruzioni Passo-Passo
- Apri il PDF in Adobe Acrobat Pro.
- Fai clic su Esporta PDF (barra degli strumenti a destra).
- Seleziona Foglio di calcolo → Cartella di lavoro Microsoft Excel (o CSV).
- Fai clic su Esporta.
- Scegli una posizione e salva.
- Apri il file Excel generato e verifica le tabelle.
Suggerimenti Aggiuntivi
- Utilizza prima l'opzione Riconosci testo (OCR) se stai lavorando con PDF scansionati.
- Per tabelle multipagina, Acrobat spesso le concatena in modo intelligente.
- Puoi esportare solo pagine selezionate per risparmiare tempo.
Pro e Contro
| Pro | Contro |
|---|---|
| Elevata accuratezza per PDF digitali | Costoso (richiede abbonamento) |
| Gestisce bene tabelle multipagina | Nessun controllo granulare sull'estrazione |
| Preserva formule e numeri | Ancora difficoltà con tabelle nidificate molto complesse |
| Elaborazione batch disponibile | Solo Windows/macOS (nessuna versione web) |
Metodo 4: Python (Controllo Completo e Automazione)
Ideale per: Sviluppatori, data scientist e utenti avanzati che necessitano della massima flessibilità, gestiscono PDF scansionati o elaborano file batch.
Python ti offre il controllo completo sul processo di estrazione. Puoi gestire PDF digitali con librerie come pdfplumber, camelot o Spire.PDF per Python (una libreria commerciale con una versione gratuita disponibile). Di seguito un esempio pratico che utilizza Spire.PDF per estrarre tabelle e salvarle come file di testo puliti.
Installazione
pip install spire.pdf
Esempio di Codice Completo (Estrai Tabelle in File TXT)
Il seguente codice estrae tutte le tabelle da una pagina PDF specifica e salva ogni tabella come un file di testo separato in formato simile a CSV:
from spire.pdf.common import *
from spire.pdf import *
# Crea un oggetto PdfDocument
doc = PdfDocument()
# Carica un file PDF
doc.LoadFromFile("report.pdf")
# Crea un oggetto PdfTableExtractor
extractor = PdfTableExtractor(doc)
# Estrai tabelle da una pagina specifica (l'indice della pagina parte da 0)
tableList = extractor.ExtractTable(0)
# Determina se la lista di tabelle non è vuota
if tableList is not None:
# Cicla attraverso le tabelle nella pagina
for i in range(len(tableList)):
# Crea una nuova lista per memorizzare i dati di questa tabella
builder = []
# Ottieni una tabella specifica
table = tableList[i]
# Ottieni il numero di righe e colonne
row = table.GetRowCount()
column = table.GetColumnCount()
# Cicla attraverso ogni riga e colonna
for m in range(row):
for n in range(column):
# Ottieni il testo dalla cella specifica
text = table.GetText(m, n)
# Aggiungi il testo seguito da una virgola (stile CSV)
builder.append(text + ",")
builder.append("\n") # Fine riga
builder.append("\n") # Riga vuota tra le tabelle
# Scrivi il contenuto in un file di testo
with open(f"output/Table-{i + 1}.txt", "w", encoding="utf-8") as file:
file.write("".join(builder))
# Chiudi il documento
doc.Close()
Output:
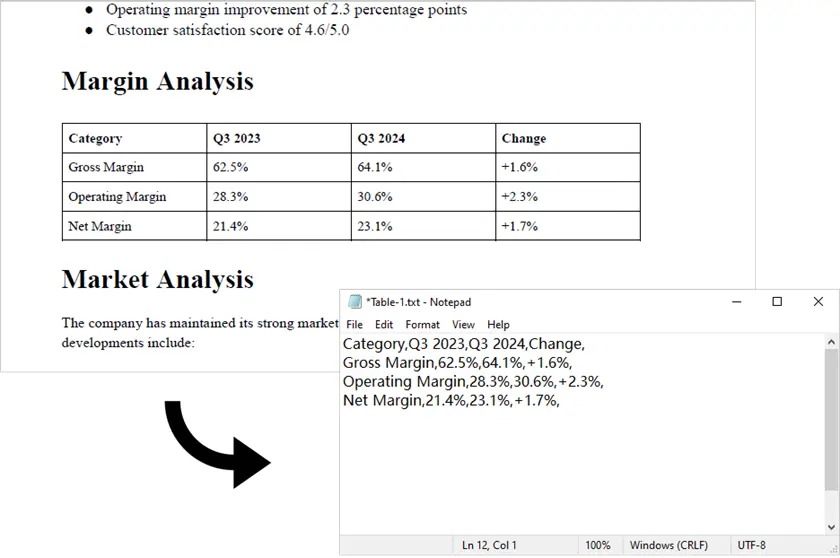
Nota: Questo script funziona solo con PDF generati digitalmente (basati su testo). Per i PDF scansionati, Spire.PDF da solo non è sufficiente. In tali casi, puoi prima convertire il PDF in immagini usando Spire.PDF, quindi applicare un motore OCR come pytesseract insieme a logica di elaborazione aggiuntiva per rilevare ed estrarre i dati tabellari.
Perché Python?
- Gestisce sia PDF digitali che scansionati (con integrazione OCR)
- Elaborazione batch di centinaia di file
- Post-elaborazione personalizzabile (pulizia, unione, validazione)
- Può essere integrato in applicazioni web, API o pipeline ETL
- Controlli esattamente come le tabelle vengono formattate e salvate
Come libreria PDF completa, Spire.PDF per Python non solo estrae tabelle dai PDF, ma supporta anche l'estrazione di immagini, metadati e allegati. Inoltre, può esportare interi documenti in formati come Word, Excel e TXT.
Pro e Contro
| Pro | Contro |
|---|---|
| Controllo completo sulla logica di estrazione | Richiede conoscenze di programmazione |
| Gestisce tabelle complesse e multipagina | Curva di apprendimento più ripida |
| Elaborazione batch di migliaia di file | Spire.PDF richiede una licenza per uso commerciale (gratuito per uso personale) |
| Risultati puliti e riproducibili | Il rilevamento delle tabelle non è perfetto su tutti i PDF |
| Facile da integrare con pandas, Excel o database |
Tabella Comparativa: Scegliere il Metodo Giusto
| Metodo | Facilità d'uso | Gestisce PDF Scansionati | Elaborazione Batch | Costo | Ideale per |
|---|---|---|---|---|---|
| Excel | Medio | x | x | Richiede Office | Tabelle digitali rapide e occasionali |
| Google Documenti | Alto | x | x | Gratuito | Tabelle semplici, nessun software |
| Adobe Acrobat Pro | Alto | √ | x | A pagamento | Utenti professionali, non tecnici |
| Python | Basso | √ | √ | Gratuito / A pagamento | Massima flessibilità, su larga scala, PDF scansionati |
Conclusione
Estrarre tabelle dai PDF non deve essere un mal di testa. Il metodo giusto dipende interamente dalla tua situazione specifica:
- Per una tabella semplice e una tantum → Prova prima Google Documenti o uno strumento online.
- Per risultati professionali e curati → Usa Excel o Adobe Acrobat Pro se hai accesso.
- Per il massimo controllo, tabelle complesse o documenti scansionati → Python è la tua migliore opzione.
Inizia con il metodo più semplice che soddisfa le tue esigenze. Man mano che i tuoi requisiti aumentano (più file, documenti scansionati, pulizia personalizzata), puoi sempre passare a strumenti più potenti come Python. La chiave è riconoscere che l'estrazione di tabelle non è un problema "taglia unica" e ora hai quattro modi per risolverlo.
FAQ
D1. Perché è difficile estrarre tabelle dai PDF?
Perché i PDF memorizzano il contenuto come testo posizionato anziché tabelle di dati strutturati, rendendo l'estrazione meno diretta.
D2. Quale metodo fornisce i risultati più accurati?
Adobe Acrobat Pro generalmente fornisce la migliore accuratezza per tabelle complesse.
D3. Posso estrarre tabelle da PDF scansionati?
Sì, ma richiede OCR (Optical Character Recognition). Strumenti come Adobe Acrobat o Spire.PDF (con un componente OCR) possono convertire immagini scansionate in testo leggibile dalla macchina, dopodiché i dati tabellari possono essere rilevati ed estratti.
D4. Python è migliore di altri metodi?
Dipende. Python è il migliore per l'automazione e l'elaborazione su larga scala, ma è eccessivo per attività una tantum.
D5. Posso convertire tabelle estratte direttamente in Excel?
Sì. La maggior parte degli strumenti (Excel, Acrobat) supporta l'esportazione diretta in .xlsx, mentre Python può essere esteso per fare lo stesso.