
A conversão de tabelas de arquivos PDF para o formato CSV é um requisito comum em fluxos de trabalho de relatórios, análises e integração de dados. Os arquivos CSV são leves, amplamente suportados e adequados para automação, tornando-os muito mais úteis do que PDFs estáticos quando os dados tabulares precisam ser reutilizados.
Na prática, no entanto, converter uma tabela de PDF para CSV raramente é simples. Os arquivos PDF são projetados para preservar a aparência visual em vez da estrutura lógica. Uma tabela que parece perfeitamente alinhada na tela pode não existir como linhas e colunas internamente, e é por isso que os métodos de conversão ingênuos geralmente falham.
Este artigo foca em métodos práticos de conversão de tabelas de PDF para CSV. Em vez de cobrir todas as opções teóricas, ele explica as abordagens mais comumente usadas, como elas se comportam na prática e quando cada método é apropriado.
Índice
- Formas Práticas Comuns de Converter Tabelas de PDF para CSV
- Método 1: Exportar PDF para Planilha Usando o Acrobat
- Método 2: Conversão Online de Tabela de PDF para CSV
- Método 3: Extração Programática de Tabela de PDF com Python
- Lidando com Cenários de Tabelas de PDF do Mundo Real
- Principais Conclusões: Convertendo Tabelas de PDF para CSV
- Perguntas Frequentes
Formas Práticas Comuns de Converter Tabelas de PDF para CSV
Na maioria dos fluxos de trabalho reais, a conversão de uma tabela de PDF para CSV se enquadra em uma das seguintes categorias:
- Exportar tabelas via ferramentas de PDF para planilha (como o Acrobat)
- Usando conversores online de tabela de PDF para CSV
- Extraindo tabelas programaticamente usando código Python
Técnicas simples de copiar e colar são intencionalmente excluídas, pois geralmente achatam as tabelas em texto simples e exigem uma reconstrução manual extensa.
Método 1: Exportar PDF para Planilha Usando o Acrobat
Exportar um PDF para um formato de planilha e depois salvá-lo como CSV é uma escolha comum para usuários que preferem ferramentas de desktop e inspeção visual.
Quando Este Método Funciona Bem
- O PDF é baseado em texto e bem estruturado
- As tabelas têm limites claros de linha e coluna
- A revisão e correção manual são aceitáveis
Fluxo de Trabalho Típico Baseado no Acrobat
-
Abra o arquivo PDF no Acrobat
-
Escolha Exportar PDF e selecione Planilha como o formato de saída
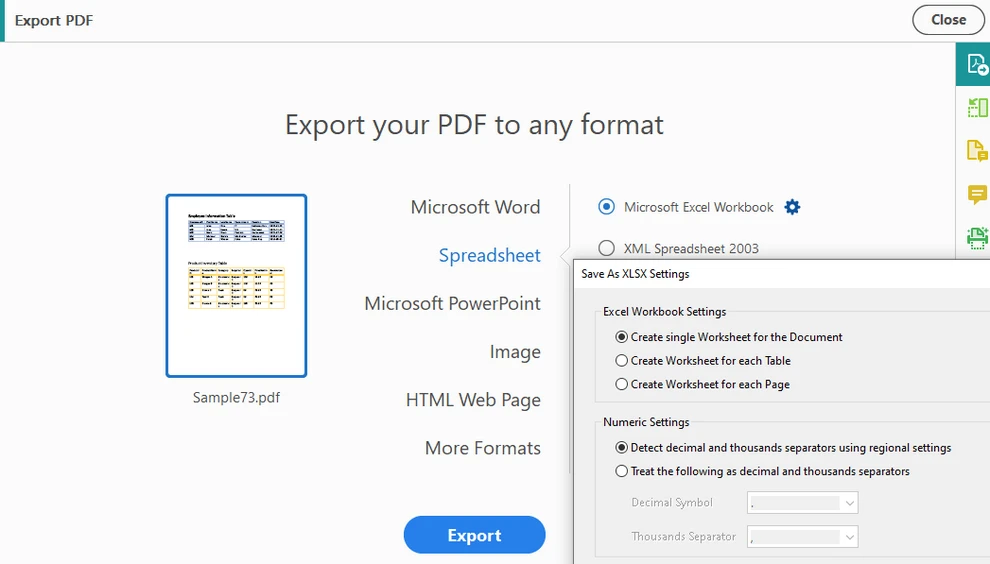
-
Exporte o documento para o formato Excel
-
Revise e ajuste a estrutura da tabela, se necessário
-
Salve ou exporte a planilha como um arquivo CSV
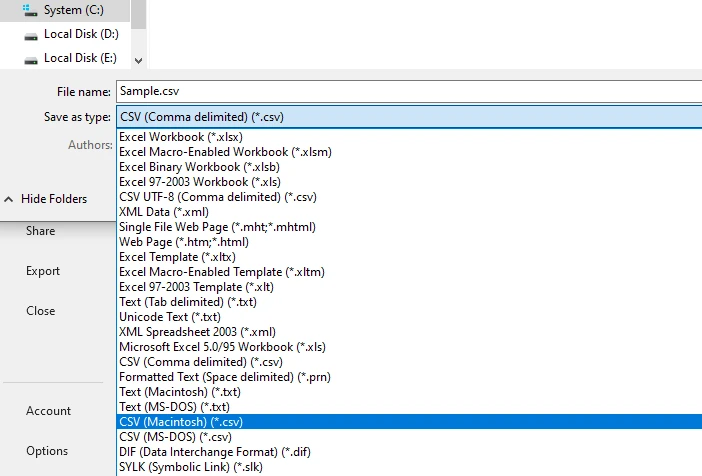
Este fluxo de trabalho geralmente produz melhores resultados estruturais do que a cópia direta, especialmente para tabelas de página única ou formatadas de forma consistente.
Limitações Práticas
- Tabelas complexas ou de várias páginas podem ser divididas em várias planilhas
- Células mescladas podem levar a colunas desalinhadas na saída CSV
- A limpeza manual é frequentemente necessária antes da exportação
- Não é adequado para processamento em lote ou automatizado
Esta abordagem é eficaz para conversões ocasionais onde a validação visual é importante, mas não escala bem.
Para usuários que procuram uma alternativa gratuita ao Acrobat para converter tabelas de PDF para Excel antes de salvar como CSV, consulte Como Converter PDF para Excel Gratuitamente.
Método 2: Conversão Online de Tabela de PDF para CSV
Conversores online são amplamente utilizados porque não exigem instalação e fornecem resultados rápidos.
Quando a Conversão Online é uma Boa Opção
- O PDF contém texto selecionável (não digitalizado)
- Os layouts das tabelas são relativamente simples
- Apenas um pequeno número de arquivos precisa de conversão
Fluxo de Trabalho Típico de Conversão Online de Tabela de PDF para CSV
A maioria das ferramentas online segue um processo semelhante (exemplo do Zamzar):
-
Abra um conversor online de PDF para CSV
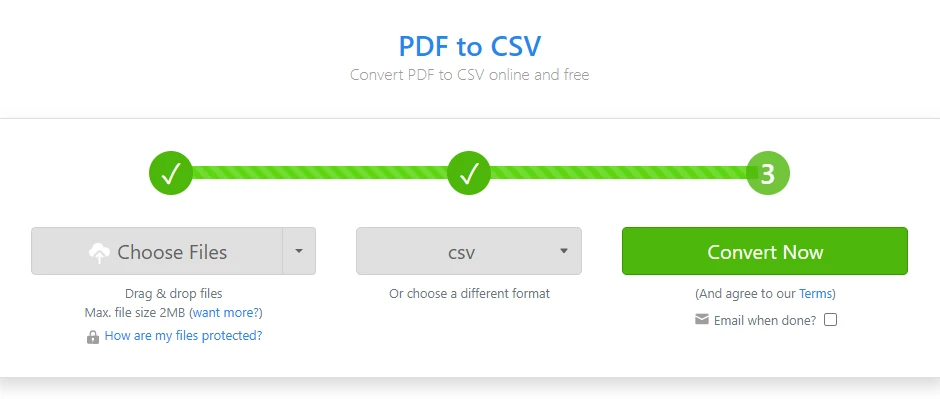
-
Carregue o arquivo PDF que contém a tabela
-
Configure o intervalo de páginas ou as opções de detecção de tabela, se disponíveis
-
Inicie o processo de conversão
-
Baixe o arquivo CSV gerado
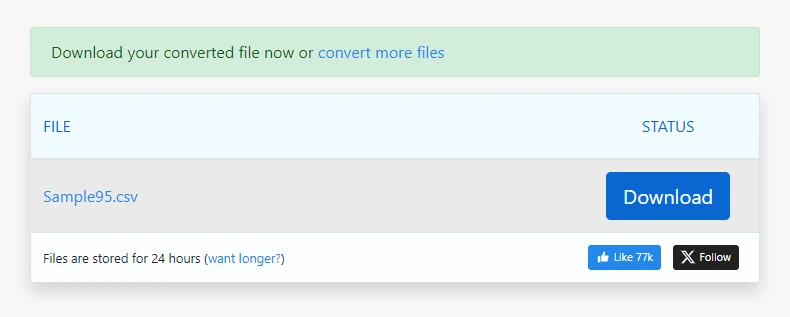
Para PDFs simples, este processo pode gerar uma saída CSV utilizável em segundos.
Considerações Comuns com Conversores Online
- As colunas podem se deslocar quando o espaçamento é inconsistente
- Os conversores geralmente exportam o PDF inteiro como CSV, não apenas as tabelas
- Quebras de linha dentro das células podem criar linhas extras
- A qualidade da saída varia de acordo com o layout do documento
- Limites de tamanho de arquivo e preocupações com a privacidade podem ser aplicados
As ferramentas online são melhores tratadas como uma opção de conveniência em vez de uma solução previsível ou reutilizável.
Método 3: Extração Programática de Tabela de PDF com Python
Quando precisão, consistência ou automação são necessárias, a extração programática é muitas vezes a maneira mais confiável de converter tabelas de PDF para CSV.
Por que a Extração Programática é Frequentemente Preferida
- As tabelas podem ser processadas página por página
- Tabelas de várias páginas podem ser tratadas de forma consistente
- A mesma lógica de extração pode ser reutilizada em trabalhos em lote
- A saída é reproduzível e mais fácil de validar
Esta abordagem é comum em pipelines de dados, sistemas de relatórios e serviços de backend que processam PDFs em escala. Com o Spire.PDF para Python, os desenvolvedores podem extrair tabelas de documentos PDF com precisão, lidar com layouts complexos e de várias páginas e automatizar a conversão para CSV com intervenção manual mínima.
Fluxo de Trabalho Programático Típico para PDF para CSV
A maioria das soluções programáticas segue um processo de alto nível semelhante:
- Carregue o documento PDF
- Itere por cada página
- Detecte estruturas de tabela em cada página
- Extraia linhas e colunas como dados estruturados
- Normalize o texto extraído quando necessário
- Escreva os dados estruturados em arquivos CSV
O Python é amplamente utilizado para esta tarefa porque combina legibilidade com fortes capacidades de processamento de dados.
Exemplo: Converter Tabelas de PDF para CSV Usando Python
Antes de executar o exemplo abaixo, certifique-se de que a biblioteca de processamento de PDF necessária esteja instalada.
Você pode instalar o Spire.PDF para Python usando pip:
pip install spire.pdf
Uma vez instalado, você pode prosseguir com o exemplo de extração de tabela.
O exemplo a seguir demonstra como converter tabelas de PDF para CSV usando o Spire.PDF para Python.
import os
import csv
from spire.pdf import PdfDocument, PdfTableExtractor
# Load the PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a table extractor
extractor = PdfTableExtractor(pdf)
# Normalize text to handle PDF ligatures and PUA characters
def normalize_text(text: str) -> str:
if not text:
return text
if not any('\uE000' <= ch <= '\uF8FF' for ch in text):
return text
ligatures = {
'\uE000': 'ff',
'\uE001': 'fi',
'\uE002': 'fl',
'\uE003': 'ffl',
'\uE004': 'ffi',
'\uE005': 'ft',
'\uE006': 'st',
}
for lig, repl in ligatures.items():
text = text.replace(lig, repl)
return text
# Extract tables page by page
for page_index in range(pdf.Pages.Count):
tables = extractor.ExtractTable(page_index)
if tables:
for table_index, table in enumerate(tables):
rows = []
for r in range(table.GetRowCount()):
row = []
for c in range(table.GetColumnCount()):
cell = normalize_text(table.GetText(r, c)).replace("\n", " ")
row.append(cell)
rows.append(row)
os.makedirs("output/Tables", exist_ok=True)
with open(
f"output/Tables/Page{page_index + 1}-Table{table_index + 1}.csv",
"w",
newline="",
encoding="utf-8",
) as f:
writer = csv.writer(f)
writer.writerows(rows)
pdf.Close()
Abaixo está uma prévia dos resultados da conversão de tabela de PDF para CSV:
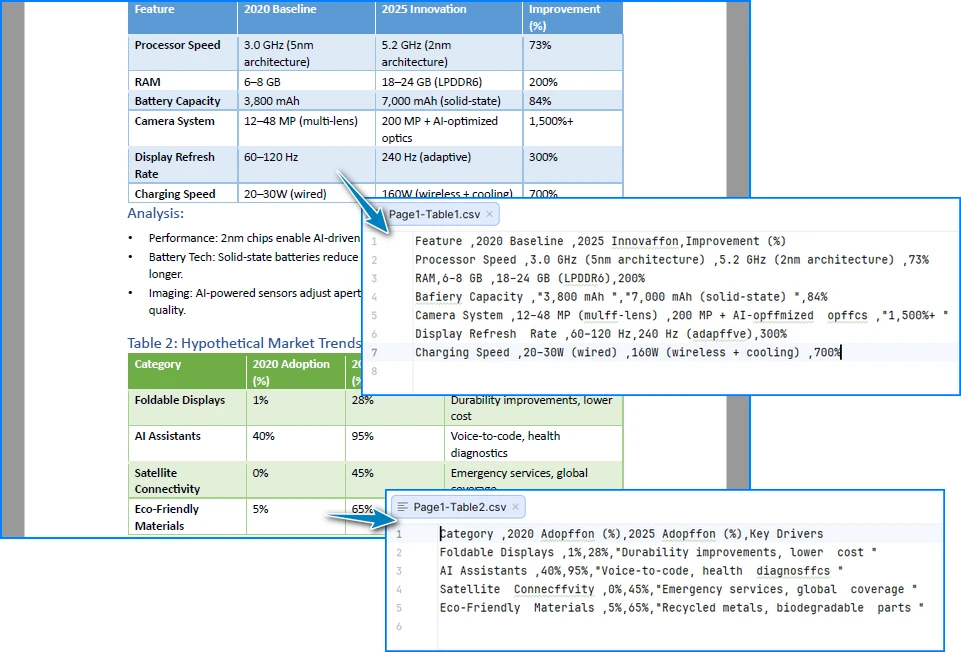
Como Esta Implementação Funciona
Esta implementação foca em preservar a estrutura da tabela em vez de inferir o layout a partir das posições do texto:
- A extração em nível de célula garante que linhas e colunas sejam preservadas como unidades lógicas em vez de serem reconstruídas a partir do espaçamento
- O processamento página por página impede que as tabelas sejam mescladas incorretamente entre os limites das páginas
- A normalização explícita de texto lida com problemas comuns de PDF, como ligaduras e caracteres Unicode de uso privado, que podem corromper silenciosamente a saída CSV
- A escrita direta em CSV evita formatos intermediários que podem introduzir artefatos de formatação adicionais
Como resultado, os arquivos CSV gerados são mais estáveis e adequados para processamento automatizado. Para um guia passo a passo sobre como extrair tabelas de documentos PDF, consulte Guia Detalhado: Extraindo Tabelas de PDF.
Lidando com Cenários de Tabelas de PDF do Mundo Real
Em fluxos de trabalho do mundo real, as tabelas de PDF geralmente se comportam de maneira diferente de como aparecem na tela. Os problemas típicos incluem:
- Tabelas que se estendem por várias páginas com cabeçalhos repetidos ou ausentes
- Ligeiros deslocamentos na posição das colunas entre as páginas
- Linhas com células vazias, com quebra de linha ou irregulares
- Grandes lotes de PDFs com layouts semelhantes, mas não idênticos
Esses fatores são geralmente onde as ferramentas de exportação genéricas e os conversores online começam a produzir saídas CSV inconsistentes.
De uma perspectiva prática, a extração programática é mais adequada para esses casos porque permite:
- Processamento página por página sem mesclar acidentalmente tabelas não relacionadas
- Manuseio controlado de tabelas de várias páginas
- Alinhamento estável de colunas mesmo quando os layouts não são perfeitamente uniformes
Um detalhe adicional de usabilidade que vale a pena notar é a codificação CSV:
- Quando os dados extraídos incluem caracteres não-ASCII, os arquivos CSV abertos diretamente no Excel podem exibir texto corrompido
- Salvar a saída CSV como UTF-8 com BOM (UTF-8-SIG) ajuda a garantir a exibição correta dos caracteres sem etapas de importação manual
Essas considerações tornam-se especialmente relevantes ao trabalhar com PDFs do mundo real em vez de exemplos idealizados.
Principais Conclusões: Convertendo Tabelas de PDF para CSV
Na prática, a conversão de uma tabela de PDF para CSV geralmente se resume a três opções:
- A exportação pelo Acrobat funciona bem para conversões ocasionais e verificadas visualmente, como faturas ou relatórios de página única
- Os conversores online são convenientes para tarefas simples e únicas com tabelas diretas
- A extração programática oferece os resultados mais confiáveis para fluxos de trabalho complexos, de várias páginas ou repetidos, especialmente em pipelines automatizados
A escolha do método certo depende menos da ferramenta em si e mais de como os dados extraídos serão usados.
Perguntas Frequentes
As tabelas de PDF digitalizadas podem ser convertidas diretamente para CSV?
Não. PDFs digitalizados exigem OCR antes que a extração da tabela seja possível. Para um guia passo a passo sobre como extrair texto de PDFs digitalizados usando Python, consulte Extraindo Texto de PDFs Digitalizados com Python.
O formato CSV é melhor que o Excel para tabelas extraídas de PDF? O CSV é mais simples e mais adequado para automação, enquanto o Excel é frequentemente preferido para revisão manual.
O Python é adequado para a conversão em lote de tabelas de PDF? Sim. O Python é amplamente utilizado para extração de tabelas de PDF em grande escala e automatizada devido à sua flexibilidade e legibilidade.