
Преобразование таблиц из файлов PDF в формат CSV является частым требованием в рабочих процессах отчетности, аналитики и интеграции данных. Файлы CSV легковесны, широко поддерживаются и хорошо подходят для автоматизации, что делает их гораздо более полезными, чем статические PDF-файлы, когда табличные данные необходимо использовать повторно.
Однако на практике преобразование таблицы PDF в CSV редко бывает простым. Файлы PDF предназначены для сохранения внешнего вида, а не логической структуры. Таблица, которая выглядит идеально выровненной на экране, может не существовать внутри как строки и столбцы, поэтому наивные методы преобразования часто терпят неудачу.
Эта статья посвящена практическим методам преобразования таблиц PDF в CSV. Вместо того чтобы рассматривать все теоретические варианты, в ней объясняются наиболее часто используемые подходы, их поведение на практике и случаи, когда каждый метод является подходящим.
Содержание
- Распространенные практические способы преобразования таблиц PDF в CSV
- Метод 1: Экспорт PDF в электронную таблицу с помощью Acrobat
- Метод 2: Онлайн-преобразование таблиц PDF в CSV
- Метод 3: Программное извлечение таблиц PDF с помощью Python
- Обработка реальных сценариев с таблицами PDF
- Основные выводы: преобразование таблиц PDF в CSV
- Часто задаваемые вопросы
Распространенные практические способы преобразования таблиц PDF в CSV
В большинстве реальных рабочих процессов преобразование таблицы PDF в CSV подпадает под одну из следующих категорий:
- Экспорт таблиц с помощью инструментов для преобразования PDF в электронные таблицы (например, Acrobat)
- Использование онлайн-конвертеров таблиц PDF в CSV
- Извлечение таблиц программно с использованием кода Python
Простые методы копирования и вставки намеренно исключены, так как они обычно преобразуют таблицы в обычный текст и требуют значительной ручной реконструкции.
Метод 1: Экспорт PDF в электронную таблицу с помощью Acrobat
Экспорт PDF в формат электронной таблицы с последующим сохранением в виде CSV — это распространенный выбор для пользователей, предпочитающих настольные инструменты и визуальный контроль.
Когда этот метод хорошо работает
- PDF является текстовым и хорошо структурированным
- Таблицы имеют четкие границы строк и столбцов
- Допустимы ручная проверка и исправление
Типичный рабочий процесс на основе Acrobat
-
Откройте файл PDF в Acrobat
-
Выберите Экспорт PDF и укажите Электронная таблица в качестве формата вывода
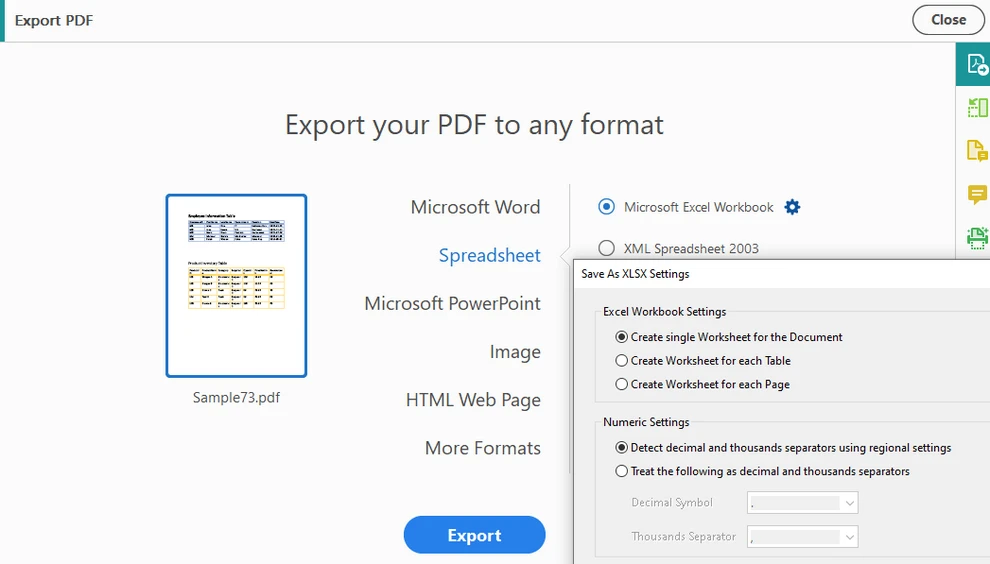
-
Экспортируйте документ в формат Excel
-
При необходимости просмотрите и скорректируйте структуру таблицы
-
Сохраните или экспортируйте электронную таблицу как файл CSV
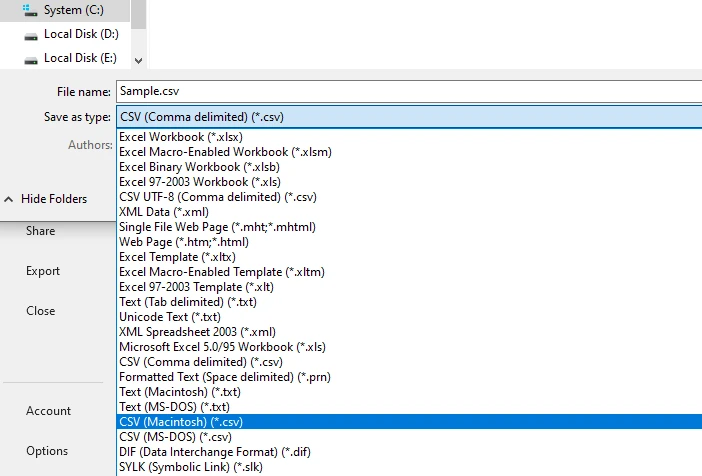
Этот рабочий процесс часто дает лучшие структурные результаты, чем прямое копирование, особенно для одностраничных или единообразно отформатированных таблиц.
Практические ограничения
- Сложные или многостраничные таблицы могут быть разделены на несколько листов
- Объединенные ячейки могут привести к смещению столбцов в выходном файле CSV
- Часто требуется ручная очистка перед экспортом
- Не подходит для пакетной или автоматизированной обработки
Этот подход эффективен для разовых преобразований, где важна визуальная проверка, но он плохо масштабируется.
Для пользователей, ищущих бесплатную альтернативу Acrobat для преобразования таблиц PDF в Excel перед сохранением в CSV, см. Как бесплатно преобразовать PDF в Excel.
Метод 2: Онлайн-преобразование таблиц PDF в CSV
Онлайн-конвертеры широко используются, поскольку не требуют установки и обеспечивают быстрые результаты.
Когда онлайн-преобразование является хорошим выбором
- PDF содержит выделяемый (несканированный) текст
- Макеты таблиц относительно просты
- Требуется преобразовать лишь небольшое количество файлов
Типичный рабочий процесс онлайн-преобразования таблиц PDF в CSV
Большинство онлайн-инструментов следуют схожему процессу (пример Zamzar):
-
Откройте онлайн-конвертер PDF в CSV
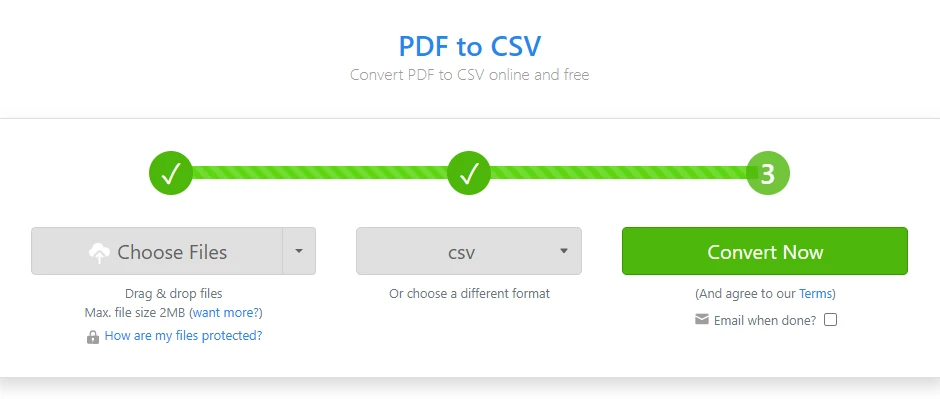
-
Загрузите файл PDF, содержащий таблицу
-
Настройте диапазон страниц или параметры обнаружения таблиц, если они доступны
-
Начните процесс преобразования
-
Загрузите сгенерированный файл CSV
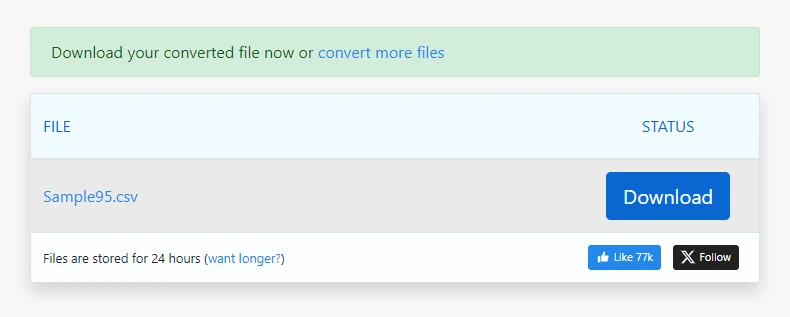
Для простых PDF-файлов этот процесс может сгенерировать пригодный для использования CSV-файл за считанные секунды.
Общие соображения при работе с онлайн-конвертерами
- Столбцы могут смещаться при несогласованных интервалах
- Конвертеры часто экспортируют весь PDF-файл в CSV, а не только таблицы
- Разрывы строк внутри ячеек могут создавать дополнительные строки
- Качество вывода зависит от макета документа
- Могут применяться ограничения на размер файла и соображения конфиденциальности
Онлайн-инструменты лучше рассматривать как удобный вариант, а не как предсказуемое или многоразовое решение.
Метод 3: Программное извлечение таблиц PDF с помощью Python
Когда требуется точность, последовательность или автоматизация, программное извлечение часто является самым надежным способом преобразования таблиц PDF в CSV.
Почему программное извлечение часто предпочтительнее
- Таблицы можно обрабатывать постранично
- Многостраничные таблицы можно обрабатывать последовательно
- Одну и ту же логику извлечения можно повторно использовать в пакетных заданиях
- Вывод является воспроизводимым и его легче проверить
Этот подход распространен в конвейерах данных, системах отчетности и серверных службах, которые обрабатывают PDF-файлы в больших масштабах. С помощью Spire.PDF for Python разработчики могут точно извлекать таблицы из документов PDF, обрабатывать многостраничные и сложные макеты, а также автоматизировать преобразование в CSV с минимальным ручным вмешательством.
Типичный программный рабочий процесс для преобразования таблиц PDF в CSV
Большинство программных решений следуют схожему высокоуровневому процессу:
- Загрузить документ PDF
- Перебрать каждую страницу
- Обнаружить структуры таблиц на каждой странице
- Извлечь строки и столбцы как структурированные данные
- При необходимости нормализовать извлеченный текст
- Записать структурированные данные в файлы CSV
Python широко используется для этой задачи, поскольку он сочетает в себе удобочитаемость с мощными возможностями обработки данных.
Пример: преобразование таблиц PDF в CSV с помощью Python
Перед запуском приведенного ниже примера убедитесь, что установлена необходимая библиотека для обработки PDF.
Вы можете установить Spire.PDF for Python с помощью pip:
pip install spire.pdf
После установки вы можете перейти к примеру извлечения таблицы.
Следующий пример демонстрирует, как преобразовать таблицы PDF в CSV с помощью Spire.PDF for Python.
import os
import csv
from spire.pdf import PdfDocument, PdfTableExtractor
# Load the PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a table extractor
extractor = PdfTableExtractor(pdf)
# Normalize text to handle PDF ligatures and PUA characters
def normalize_text(text: str) -> str:
if not text:
return text
if not any('\uE000' <= ch <= '\uF8FF' for ch in text):
return text
ligatures = {
'\uE000': 'ff',
'\uE001': 'fi',
'\uE002': 'fl',
'\uE003': 'ffl',
'\uE004': 'ffi',
'\uE005': 'ft',
'\uE006': 'st',
}
for lig, repl in ligatures.items():
text = text.replace(lig, repl)
return text
# Extract tables page by page
for page_index in range(pdf.Pages.Count):
tables = extractor.ExtractTable(page_index)
if tables:
for table_index, table in enumerate(tables):
rows = []
for r in range(table.GetRowCount()):
row = []
for c in range(table.GetColumnCount()):
cell = normalize_text(table.GetText(r, c)).replace("\n", " ")
row.append(cell)
rows.append(row)
os.makedirs("output/Tables", exist_ok=True)
with open(
f"output/Tables/Page{page_index + 1}-Table{table_index + 1}.csv",
"w",
newline="",
encoding="utf-8",
) as f:
writer = csv.writer(f)
writer.writerows(rows)
pdf.Close()
Ниже приведен предварительный просмотр результатов преобразования таблицы PDF в CSV:
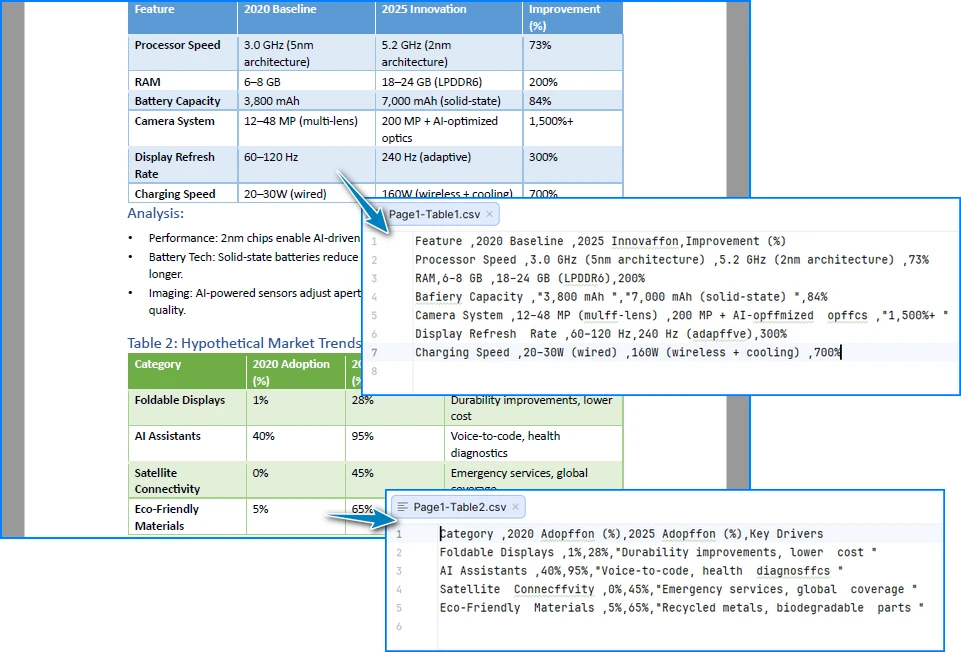
Как работает эта реализация
Эта реализация фокусируется на сохранении структуры таблицы, а не на выводе макета из позиций текста:
- Извлечение на уровне ячеек гарантирует, что строки и столбцы сохраняются как логические единицы, а не реконструируются из интервалов
- Постраничная обработка предотвращает неправильное слияние таблиц через границы страниц
- Явная нормализация текста решает распространенные проблемы PDF, такие как лигатуры и символы частного использования Unicode, которые могут незаметно повредить вывод CSV
- Прямая запись в CSV позволяет избежать промежуточных форматов, которые могут вносить дополнительные артефакты форматирования
В результате сгенерированные файлы CSV более стабильны и подходят для автоматизированной обработки. Пошаговое руководство по извлечению таблиц из документов PDF см. в разделе Подробное руководство: извлечение таблиц из PDF.
Обработка реальных сценариев с таблицами PDF
В реальных рабочих процессах таблицы PDF часто ведут себя иначе, чем выглядят на экране. Типичные проблемы включают:
- Таблицы, охватывающие несколько страниц с повторяющимися или отсутствующими заголовками
- Незначительные смещения позиций столбцов между страницами
- Строки с пустыми, перенесенными или неправильными ячейками
- Большие партии PDF-файлов с похожими, но не идентичными макетами
Именно из-за этих факторов универсальные инструменты экспорта и онлайн-конвертеры начинают производить несогласованный вывод CSV.
С практической точки зрения, программное извлечение лучше подходит для этих случаев, поскольку оно позволяет:
- Постраничная обработка без случайного слияния несвязанных таблиц
- Контролируемая обработка многостраничных таблиц
- Стабильное выравнивание столбцов даже при неидеально однородных макетах
Еще одна деталь юзабилити, на которую стоит обратить внимание, — это кодировка CSV:
- Когда извлеченные данные содержат символы, отличные от ASCII, файлы CSV, открытые непосредственно в Excel, могут отображать искаженный текст
- Сохранение вывода CSV в кодировке UTF-8 с BOM (UTF-8-SIG) помогает обеспечить правильное отображение символов без ручных шагов импорта
Эти соображения становятся особенно актуальными при работе с реальными PDF-файлами, а не с идеализированными примерами.
Основные выводы: преобразование таблиц PDF в CSV
На практике преобразование таблицы PDF в CSV обычно сводится к трем вариантам:
- Экспорт из Acrobat хорошо подходит для разовых, визуально проверяемых преобразований, таких как одностраничные счета или отчеты
- Онлайн-конвертеры удобны для простых, разовых задач с простыми таблицами
- Программное извлечение предлагает самые надежные результаты для сложных, многостраничных или повторяющихся рабочих процессов, особенно в автоматизированных конвейерах
Выбор правильного метода зависит не столько от самого инструмента, сколько от того, как будут использоваться извлеченные данные.
Часто задаваемые вопросы
Можно ли напрямую преобразовать отсканированные таблицы PDF в CSV?
Нет. Отсканированные PDF-файлы требуют распознавания текста (OCR) перед извлечением таблиц. Пошаговое руководство по извлечению текста из отсканированных PDF-файлов с помощью Python см. в статье Извлечение текста из отсканированных PDF-файлов с помощью Python.
Лучше ли CSV, чем Excel, для извлеченных таблиц PDF? CSV проще и лучше подходит для автоматизации, в то время как Excel часто предпочитают для ручной проверки.
Подходит ли Python для пакетного преобразования таблиц PDF? Да. Python широко используется для крупномасштабного и автоматизированного извлечения таблиц PDF благодаря своей гибкости и удобочитаемости.