PDF-Dateien sind weit verbreitet zum Teilen von Dokumenten, da sie das Layout und die Formatierung auf allen Geräten beibehalten. Einige PDFs enthalten jedoch Sicherheitsberechtigungen, die Benutzer am Kopieren von Text hindern. Wenn Sie versuchen, Inhalte aus diesen Dateien auszuwählen oder zu kopieren, stellen Sie möglicherweise fest, dass das Kopieren deaktiviert ist.
Diese Art von Datei wird oft als gesichertes, geschütztes oder eingeschränktes PDF bezeichnet. Im Gegensatz zu passwortgeschützten PDFs, die das Öffnen der Datei blockieren, können diese Dokumente normal angezeigt werden – aber bestimmte Aktionen wie das Kopieren von Text sind eingeschränkt.
Glücklicherweise gibt es mehrere kostenlose und praktische Umgehungslösungen, mit denen Sie Text aus geschützten PDFs extrahieren oder kopieren können. In diesem Leitfaden werden wir fünf einfache Methoden untersuchen, darunter Online-Tools, integrierte Systemfunktionen und einen Python-Automatisierungsansatz.
Schnellnavigation
- Methode 1 – Text aus einem gesicherten PDF mit Google Docs kopieren
- Methode 2 – Ein eingeschränktes PDF online in TXT umwandeln
- Methode 3 – Screenshot + OCR zum Extrahieren von Text
- Methode 4 – Ein kopiergeschütztes PDF in ein neues PDF drucken
- Methode 5 – Text aus einem gesicherten PDF mit Python extrahieren
Warum kann man aus manchen PDFs keinen Text kopieren?
Viele PDF-Ersteller wenden Berechtigungseinschränkungen an, um zu steuern, wie das Dokument verwendet werden kann. Diese Berechtigungen werden in den Sicherheitseinstellungen des PDFs festgelegt und können Aktionen wie die folgenden deaktivieren:
- Text kopieren
- Das Dokument bearbeiten
- Die Datei drucken
- Anmerkungen hinzufügen
Dies wird oft als Kopierschutz oder Inhaltseinschränkung bezeichnet. Während das Dokument lesbar bleibt, verhindert der PDF-Viewer die Auswahl oder das Kopieren von Text.
Diese Einschränkungen werden in der Regel verwendet, um geistiges Eigentum zu schützen oder die unbefugte Wiederverwendung von Inhalten zu verhindern. Wenn Sie jedoch Text rechtmäßig wiederverwenden müssen – zum Beispiel für Forschung, Dokumentation oder Barrierefreiheitszwecke – benötigen Sie möglicherweise alternative Wege, um den Inhalt zu extrahieren.
Nachfolgend finden Sie fünf Methoden, die helfen können.
Methode 1 – Text aus einem gesicherten PDF mit Google Docs kopieren
Eine der einfachsten Möglichkeiten, Text aus einem geschützten PDF zu kopieren, besteht darin, es mit Google Docs zu öffnen. Wenn ein PDF in Google Drive hochgeladen und in Google Docs geöffnet wird, konvertiert der Dienst die Datei automatisch in ein bearbeitbares Dokument.
Während dieses Konvertierungsprozesses wird der Inhalt des PDFs als Text und Absätze neu interpretiert, was oft grundlegende Kopierbeschränkungen umgeht. Nach Abschluss der Konvertierung können Sie den Text einfach wie in einem normalen Dokument auswählen und kopieren.
Schritte
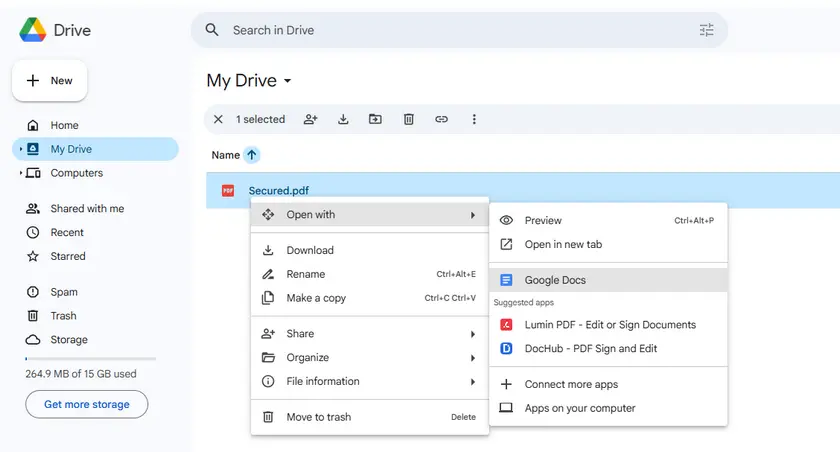
- Öffnen Sie Google Drive.
- Laden Sie das geschützte PDF hoch.
- Klicken Sie mit der rechten Maustaste auf die Datei und wählen Sie Öffnen mit → Google Docs.
- Google Docs konvertiert das PDF in ein bearbeitbares Dokument.
- Kopieren Sie den extrahierten Text aus dem Dokument.
Vorteile
- Kostenlos und einfach zu bedienen.
- Keine Softwareinstallation erforderlich.
- Funktioniert gut mit textbasierten Dokumenten.
Einschränkungen
- Gescannte/bildbasierte PDFs werden nicht in Text umgewandelt (kein OCR).
- Die Formatierung kann bei komplexen Layouts unübersichtlich werden.
- Erfordert ein Google-Konto und eine Internetverbindung.
Methode 2 – Ein eingeschränktes PDF online in TXT umwandeln
Eine weitere schnelle Lösung besteht darin, das eingeschränkte PDF mit einem Online-Konverter in eine reine Textdatei umzuwandeln. Sobald das Dokument in das TXT-Format konvertiert ist, wird der Text vollständig bearbeitbar und kann ohne Einschränkungen kopiert werden.
Ein praktisches kostenloses Werkzeug für diesen Zweck sind PDF24 Tools, die einen browserbasierten PDF-zu-TXT-Konverter bereitstellen. Diese Methode funktioniert gut, wenn Sie Text schnell extrahieren müssen, ohne zusätzliche Software zu installieren.
Schritte
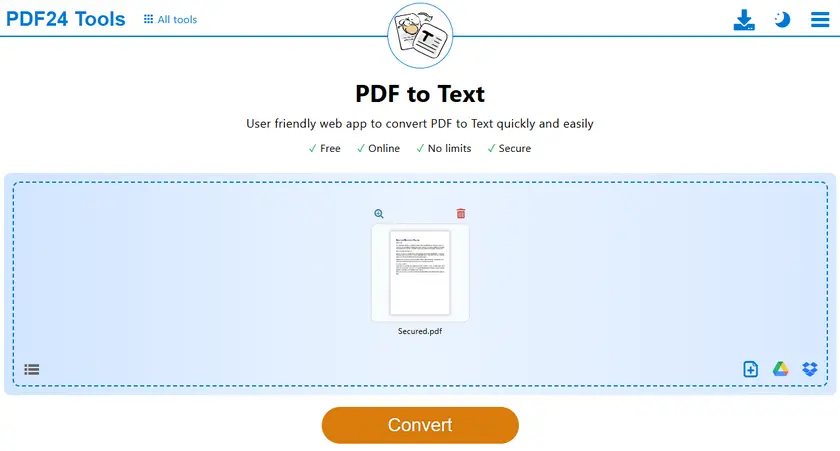
- Öffnen Sie das PDF-zu-TXT-Tool.
- Laden Sie Ihre geschützte PDF-Datei hoch.
- Starten Sie den Konvertierungsprozess.
- Laden Sie die generierte TXT-Datei herunter.
- Öffnen Sie die TXT-Datei und kopieren Sie den Text frei.
Vorteile
- Schneller und einfacher Arbeitsablauf.
- Keine Installation erforderlich.
Einschränkungen
- Datenschutzrisiko – sensible Dokumente werden auf Server von Drittanbietern hochgeladen.
- Oft auf wenige kostenlose Konvertierungen pro Tag beschränkt.
- Keine OCR-Unterstützung in den meisten kostenlosen Tools (bildbasierte PDFs funktionieren nicht).
Methode 3 – Screenshot + OCR zum Extrahieren von Text
Wenn das PDF starke Kopierbeschränkungen aufweist oder gescannte Seiten enthält, kann OCR (Optical Character Recognition) den sichtbaren Text dennoch abrufen. Die OCR-Technologie analysiert das Bild des Dokuments und wandelt erkannte Zeichen in bearbeitbaren Text um.
Windows 11 enthält eine integrierte OCR-Funktion im Snipping Tool, mit der Sie einen Teil des Bildschirms erfassen und den Text sofort aus dem Bild extrahieren können.
Schritte
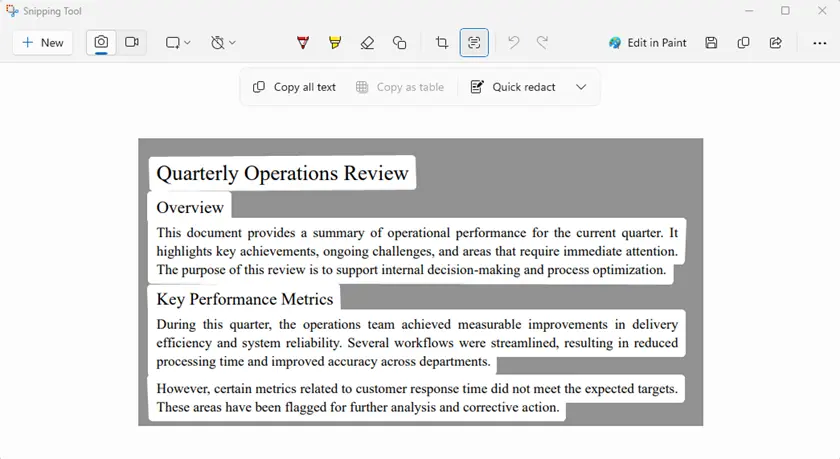
- Öffnen Sie das geschützte PDF auf Ihrem Bildschirm.
- Starten Sie Snipping Tool.
- Erfassen Sie den Bereich, der den Text enthält.
- Verwenden Sie Textaktionen → Gesamten Text kopieren.
- Fügen Sie den extrahierten Text in ein Dokument ein.
Vorteile
- Umschifft fast jeden Kopierschutz, da es den Bildschirm erfasst.
- Funktioniert mit gescannten/bildbasierten PDFs.
Einschränkungen
- Zeitaufwändig bei vielen Seiten.
- OCR-Fehler – die Genauigkeit hängt von der Bildqualität und der Schriftart ab.
- Manueller Prozess, es sei denn, er wird mit Skripten automatisiert.
Methode 4 – Ein kopiergeschütztes PDF in ein neues PDF drucken
Einige geschützte PDFs blockieren das Kopieren, erlauben aber dennoch das Drucken. In solchen Fällen können Sie das Dokument in eine neue PDF-Datei drucken, was die Kopierbeschränkung möglicherweise aufhebt.
Dies kann einfach mit der integrierten Druckfunktion in Google Chrome erfolgen. Nach dem Speichern der gedruckten Version der Datei kann das neue PDF möglicherweise die normale Textauswahl und das Kopieren zulassen.
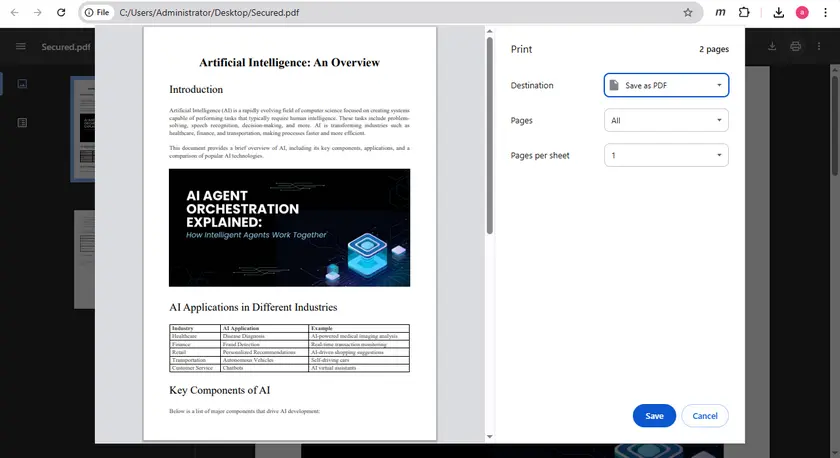
Schritte
- Öffnen Sie das PDF in Google Chrome.
- Drücken Sie Strg + P, um den Druckdialog zu öffnen.
- Stellen Sie das Ziel auf Als PDF speichern ein.
- Speichern Sie das neu generierte PDF.
- Öffnen Sie die neue Datei und versuchen Sie, den Text zu kopieren.
Vorteile
- Einfache Umgehungslösung.
- Keine zusätzlichen Werkzeuge erforderlich.
Einschränkungen
- Wenn das Drucken in den PDF-Berechtigungen deaktiviert ist, funktioniert dies nicht.
- Es können einige Formatierungsunterschiede auftreten.
Methode 5 – Text aus einem gesicherten PDF mit Python extrahieren
Für Entwickler oder Benutzer, die mehrere Dokumente verarbeiten müssen, kann das programmgesteuerte Extrahieren von Text die effizienteste Lösung sein. Anstatt Inhalte manuell zu kopieren, kann ein Skript die PDF-Struktur automatisch lesen und den Text von jeder Seite abrufen.
Mit Free Spire.PDF for Python können Sie mit nur wenigen Codezeilen ganz einfach Text aus PDF-Dokumenten extrahieren. Dieser Ansatz ist besonders nützlich für Automatisierung, die Stapelverarbeitung oder die Erstellung von Dokumentenverarbeitungs-Workflows.
Wenn Sie mit kleinen Dokumenten (innerhalb von 10 Seiten pro Dokument) arbeiten oder Extraktions-Workflows testen, funktioniert die kostenlose Version gut. Bei größeren Dateien können Sie entweder das Dokument zuerst aufteilen oder die Vollversion verwenden.
Installieren Sie die Bibliothek
pip install spire.pdf.free
Beispiel: Text von jeder Seite extrahieren
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Secured.pdf")
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Create a PdfTextExtractor object
textExtractor = PdfTextExtractor(page)
# Create a PdfTextExtractOptions object
extractOptions = PdfTextExtractOptions()
# Set IsExtractAllText to True
extractOptions.IsExtractAllText = True
# Extract text from the page keeping white spaces
text = textExtractor.ExtractText(extractOptions)
# Write text to a txt file
with open('output/TextOfPage-{}.txt'.format(i + 1), 'w', encoding='utf-8') as file:
lines = text.split("\n")
for line in lines:
if line != '':
file.write(line)
doc.Close()
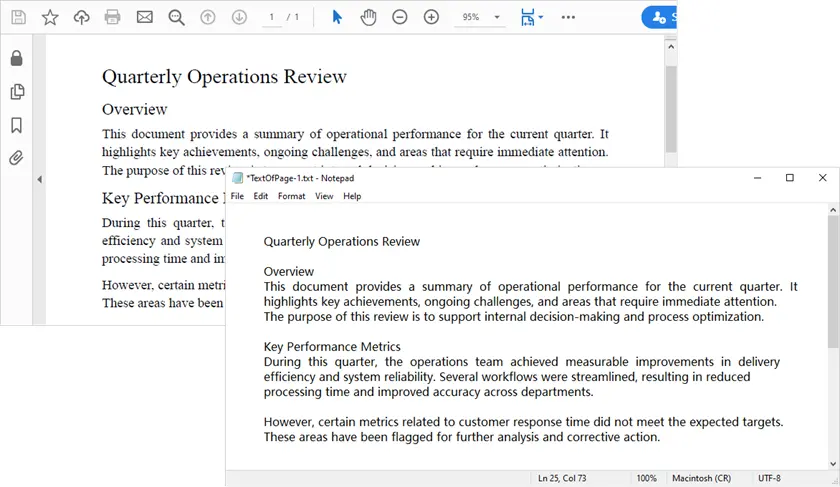
Was dieses Skript tut
- Lädt das PDF-Dokument.
- Iteriert durch jede Seite.
- Extrahiert Text unter Beibehaltung von Leerzeichen.
- Speichert den extrahierten Text in TXT-Dateien.
Vorteile
- Volle Kontrolle über den Extraktionsprozess.
- Kann für die Stapelverarbeitung automatisiert werden.
- Funktioniert gut mit textbasierten PDFs.
Einschränkungen
- Erfordert Programmierkenntnisse.
- Kann bildbasierte PDFs nicht verarbeiten, es sei denn, es wird eine zusätzliche OCR-Bibliothek verwendet.
Das könnte Ihnen auch gefallen: PDF-OCR mit Python durchführen (Text aus gescanntem PDF extrahieren)
Vergleichstabelle: Welche Methode sollten Sie wählen?
| Methode | Fähigkeitslevel | Benutzerfreundlichkeit | Am besten für | Funktioniert mit gescannten PDFs | Funktioniert bei starken Einschränkungen | Stapelverarbeitung |
|---|---|---|---|---|---|---|
| Google Docs | Anfänger | Sehr einfach | Schnelle Extraktion im Browser | Nein | Ja | Nein |
| Online-Konverter | Anfänger | Sehr einfach | Schnelle TXT-Konvertierung | Nein | Ja | Nein |
| Screenshot + OCR | Anfänger | Einfach | Gescannte oder bildbasierte PDFs | Ja | Ja | Nein |
| In PDF drucken | Anfänger | Einfach | Entfernen einfacher Einschränkungen | Nein | Bedingt (Drucken muss erlaubt sein) | Nein |
| Python (Spire.PDF) | Entwickler | Mäßig | Automatisierung & Stapel-Workflows | Basiert auf zusätzlichen OCR-Bibliotheken | Ja | Ja |
Fazit
Kopierbeschränkungen in PDFs können frustrierend sein, besonders wenn Sie nur einen Teil des Textes wiederverwenden müssen. Glücklicherweise können mehrere kostenlose Methoden helfen, Inhalte aus geschützten PDFs zu extrahieren.
Für schnelle Aufgaben sind Tools wie Google Docs oder Online-Konverter möglicherweise die einfachste Lösung. Wenn das Dokument gescannten Inhalt oder strenge Einschränkungen enthält, können OCR-basierte Methoden den Text dennoch wiederherstellen. Für groß angelegte Workflows oder Automatisierungsszenarien bietet die Verwendung von Python-Bibliotheken wie Free Spire.PDF for Python einen leistungsstarken und flexiblen Ansatz.
Indem Sie die Methode wählen, die Ihren Anforderungen am besten entspricht, können Sie Text aus eingeschränkten PDFs effizient abrufen und gleichzeitig einen effizienten Arbeitsablauf beibehalten.
FAQs (Häufig gestellte Fragen)
F1: Was ist ein gesichertes oder eingeschränktes PDF?
Ein geschütztes oder eingeschränktes PDF ist ein Dokument, das normal geöffnet und angezeigt werden kann, aber Sicherheitseinstellungen hat, die das Kopieren, Drucken oder Bearbeiten seines Inhalts verhindern. Diese Berechtigungen werden vom Dokumentbesitzer festgelegt.
F2: Kann ich Text aus allen gesicherten PDFs kopieren?
Nicht immer. Einige PDFs haben eine starke Verschlüsselung oder DRM, die das Kopieren vollständig verhindert. In solchen Fällen können OCR-Tools oder professionelle Bibliotheken erforderlich sein.
F3: Welche Methode ist am besten für gescannte PDFs geeignet?
Für gescannte PDFs ist die Extraktion per Screenshot + OCR oder die Python-Automatisierung mit OCR-Bibliotheken in der Regel der zuverlässigste Weg, um Text abzurufen.
F4: Kann ich die Textextraktion für mehrere PDFs automatisieren?
Ja. Mit Python-Bibliotheken wie Spire.PDF können Sie Text aus mehreren PDF-Dateien automatisch extrahieren, was es ideal für die Stapelverarbeitung oder die Workflow-Automatisierung macht.
F5: Muss ich für eine dieser Methoden bezahlen?
Alle im Artikel aufgeführten Methoden sind kostenlos. Einige Tools (wie Spire.PDF) haben jedoch kostenlose Versionen mit Einschränkungen, wie z. B. einer Seitenzahnbeschränkung. Für größere Dateien benötigen Sie möglicherweise die Vollversion.