
Leere Seiten sind ein häufiges Problem in PDF-Dokumenten. Sie treten oft beim Exportieren von Dateien aus Word oder Excel, beim Scannen von Papierdokumenten oder beim programmgesteuerten Erstellen von Berichten auf. Obwohl leere Seiten harmlos erscheinen mögen, können sie die Dokumentqualität negativ beeinflussen, die Dateigröße erhöhen, Druckressourcen verschwenden und Dokumente unprofessionell aussehen lassen.
Je nach Situation können leere Seiten aus einem PDF entweder manuell oder automatisch entfernt werden. Manuelle Methoden eignen sich für kleine Dokumente und einmalige Aufgaben, während automatisierte Lösungen für die Stapelverarbeitung, wiederkehrende Arbeitsabläufe oder systemweite Integrationen effizienter sind.
In diesem Artikel werden wir beide Ansätze im Detail untersuchen. Zuerst werden wir drei manuelle Methoden zum Löschen leerer Seiten aus PDFs durchgehen. Anschließend zeigen wir, wie man leere Seiten automatisch mit Python erkennt und entfernt, mit einer vollständigen und praktischen Lösung, die auf Spire.PDF for Python basiert.
Was ist eine „leere Seite“ in einem PDF?
Eine „leere Seite“ in einem PDF ist aus technischer Sicht nicht immer wirklich leer. Obwohl sie visuell leer aussehen mag, kann sie dennoch unsichtbare Objekte, leere Container oder weiße Bilder enthalten.
In der Praxis kann eine leere PDF-Seite:
- Keine Textobjekte enthalten
- Keine Bilder enthalten
- Visuell leer erscheinen, aber dennoch unsichtbare Elemente enthalten
- Layout-Artefakte enthalten, die bei der Konvertierung entstanden sind
Diese Unterscheidung ist besonders wichtig bei der Automatisierung des Entfernungsprozesses, da einfache textbasierte Prüfungen oft nicht ausreichen.
Teil 1: Leere Seiten manuell aus einem PDF löschen
Manuelle Methoden eignen sich am besten für kleine Dateien, bei denen Genauigkeit und visuelle Bestätigung wichtig sind. Sie erfordern keine Programmierkenntnisse und ermöglichen es den Benutzern, Seiten nach Überprüfung des Dokuments selektiv zu entfernen.
Methode 1: Leere Seiten mit Adobe Acrobat löschen
Adobe Acrobat bietet eine professionelle und hochpräzise Möglichkeit, PDF-Seiten zu verwalten. Die auf Miniaturansichten basierende Benutzeroberfläche ermöglicht es den Benutzern, alle Seiten visuell zu überprüfen und leere Seiten präzise zu entfernen.
Schritte
-
Öffnen Sie die PDF-Datei in Adobe Acrobat.
-
Öffnen Sie das Seitenminiaturen-Panel.
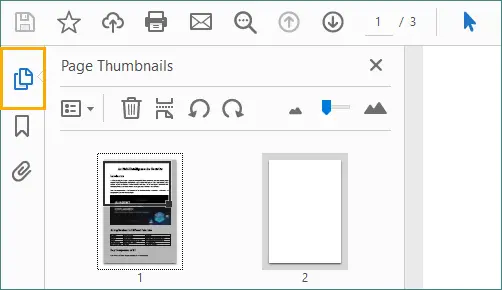
-
Wählen Sie die leere Seite aus, die Sie entfernen möchten, und klicken Sie dann auf das „Papierkorb“-Symbol.
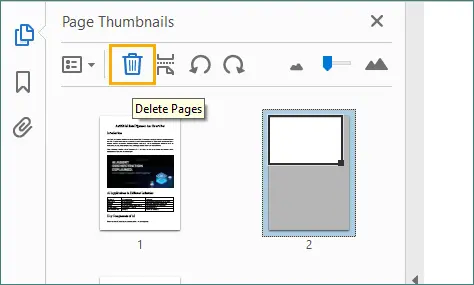 Alternativ können Sie mit der rechten Maustaste auf die ausgewählte Seite klicken und „Seiten löschen…“ wählen, wodurch Sie die aktuelle Seite oder einen Bereich von aufeinanderfolgenden Seiten löschen können.
Alternativ können Sie mit der rechten Maustaste auf die ausgewählte Seite klicken und „Seiten löschen…“ wählen, wodurch Sie die aktuelle Seite oder einen Bereich von aufeinanderfolgenden Seiten löschen können.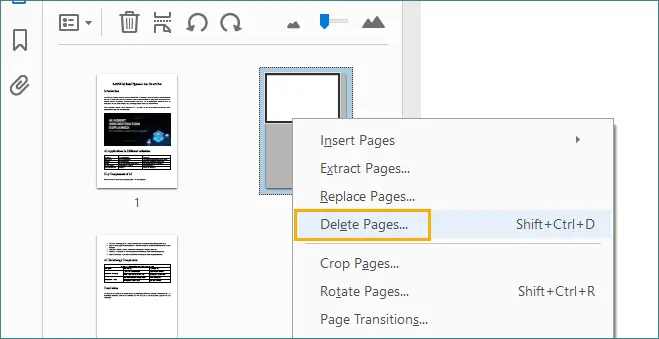
-
Speichern Sie das aktualisierte PDF.
Vorteile
- Hohe Genauigkeit mit visueller Bestätigung.
- Bewältigt komplexe Layouts und große PDFs gut.
- Geeignet für professionelle und kundenorientierte Dokumente.
Nachteile
- Erfordert eine kostenpflichtige Adobe Acrobat-Lizenz.
- Zeitaufwändig bei einer großen Anzahl von Dateien.
Methode 2: Leere Seiten mit Online-PDF-Tools löschen
Online-PDF-Tools bieten eine schnelle Lösung zum Löschen leerer Seiten, ohne Software installieren zu müssen. Die meisten Plattformen ermöglichen es den Benutzern, ein PDF hochzuladen, Seiten in der Vorschau anzuzeigen und unerwünschte Seiten direkt im Browser zu entfernen.
Schritte
-
Öffnen Sie eine Online-PDF-Bearbeitungswebsite (zum Beispiel, PDF24).
-
Klicken Sie auf „Dateien auswählen“ oder ziehen Sie Ihre PDF-Datei per Drag & Drop, um sie hochzuladen.

-
Wechseln Sie in den Vorschau- oder Seitenverwaltungsmodus, wählen Sie dann die leeren Seiten aus und löschen Sie sie.
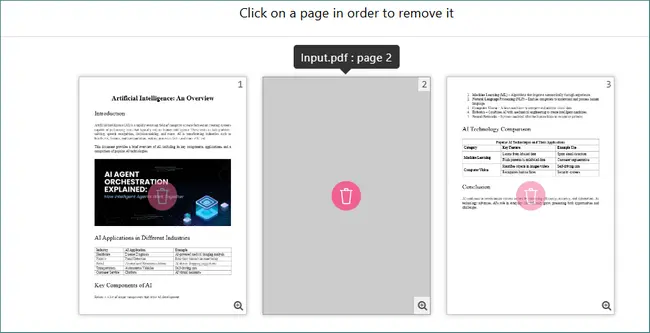
-
Wenden Sie die Änderungen an, indem Sie auf „PDF erstellen“ (oder eine ähnliche Bestätigungsschaltfläche) klicken.
-
Laden Sie die bereinigte PDF-Datei herunter.
Vorteile
- Keine Softwareinstallation erforderlich.
- Funktioniert auf jedem Betriebssystem.
- Praktisch für einmalige oder gelegentliche Aufgaben.
Nachteile
- Beschränkungen bei Dateigröße und Nutzung.
- Datenschutz- und Sicherheitsbedenken.
- Nicht geeignet für vertrauliche oder sensible Dokumente.
Methode 3: Leere Seiten über die PDF-Vorschau (macOS) löschen
macOS enthält eine integrierte Anwendung namens Vorschau, die grundlegende PDF-Bearbeitungsfunktionen wie das Löschen von Seiten unterstützt. Es ist eine einfache und kostenlose Option für macOS-Benutzer.
Schritte
-
Öffnen Sie die PDF-Datei mit der Vorschau.
-
Aktivieren Sie die Miniaturansichten-Seitenleiste, indem Sie Darstellung → Miniaturen auswählen.
-
Wählen Sie die leeren Seiten im Miniaturansichten-Panel aus.
-
Drücken Sie die Entfernen-Taste.
-
Speichern Sie das geänderte PDF.
Vorteile
- Kostenlos und auf macOS vorinstalliert.
- Offline und einfach zu bedienen.
- Keine Tools von Drittanbietern erforderlich.
Nachteile
- Nur für macOS verfügbare Lösung.
- Manueller Prozess, der nicht skaliert.
- Begrenzte erweiterte PDF-Funktionen.
Wenn manuelle Methoden nicht ausreichen
Manuelle Methoden werden ineffizient, wenn:
- Viele PDF-Dateien verarbeitet werden.
- Automatisch generierte Berichte bereinigt werden.
- Wiederkehrende Dokumentenwartung durchgeführt wird.
- Die PDF-Bereinigung in Anwendungen oder Dienste integriert wird.
In diesen Szenarien ist die Automatisierung der praktischste und zuverlässigste Ansatz.
Teil 2: Leere Seiten in PDF automatisch mit Python löschen
Die Automatisierung ermöglicht es Ihnen, leere Seiten konsistent und effizient ohne menschliches Eingreifen zu entfernen. Python eignet sich aufgrund seiner Einfachheit, plattformübergreifenden Unterstützung und seines umfangreichen Bibliotheks-Ökosystems besonders gut für diese Aufgabe.
Warum Python für die PDF-Automatisierung verwenden?
Mit Python können Sie:
- PDFs programmgesteuert verarbeiten.
- Große Dateien und Stapelverarbeitungen handhaben.
- Die PDF-Bereinigung in Backend-Systeme integrieren.
- Eine konsistente Erkennungslogik über Dokumente hinweg sicherstellen.
Die Automatisierung reduziert den manuellen Aufwand erheblich und minimiert das Risiko menschlicher Fehler.
Einführung in Spire.PDF for Python
Spire.PDF for Python ist eine robuste Bibliothek zum Erstellen, Bearbeiten und Verarbeiten von PDF-Dokumenten. Sie bietet eine feingranulare Kontrolle über die PDF-Struktur und den Inhalt und ist daher ideal für Aufgaben wie die Erkennung und Entfernung leerer Seiten.
Für diese Lösung bietet Spire.PDF:
- Zugriff auf Seitenebene
- Integrierte Erkennung leerer Seiten
- PDF-zu-Bild-Konvertierung
- Sicheres Entfernen von Seiten
Python-Code: Leere Seiten aus PDF automatisch erkennen und entfernen
Unten finden Sie ein vollständiges Python-Beispiel mit Spire.PDF for Python und Pillow (PIL).
import io
from spire.pdf import PdfDocument
from PIL import Image
# Custom function: Check if the image is blank (all pixels are white)
def is_blank_image(image):
# Convert the image to RGB mode
img = image.convert("RGB")
# Define a white pixel
white_pixel = (255, 255, 255)
# Check whether all pixels are white
return all(pixel == white_pixel for pixel in img.getdata())
# Load the PDF document
doc = PdfDocument()
doc.LoadFromFile("Input.pdf")
# Iterate through pages in reverse order
# This avoids index shifting issues when deleting pages
for i in range(doc.Pages.Count - 1, -1, -1):
page = doc.Pages[i]
# First check: built-in blank page detection
if page.IsBlank():
doc.Pages.RemoveAt(i)
else:
# Second check: convert the page to an image
with doc.SaveAsImage(i) as image_data:
image_bytes = image_data.ToArray()
pil_image = Image.open(io.BytesIO(image_bytes))
# Check whether the image is visually blank
if is_blank_image(pil_image):
doc.Pages.RemoveAt(i)
# Save the cleaned PDF file
doc.SaveToFile("RemoveBlankPages.pdf")
doc.Close()
Wie die Erkennung leerer Seiten in dieser Lösung funktioniert
Um die Genauigkeit zu verbessern, verwendet dieser Ansatz zwei komplementäre Erkennungsmethoden:
-
Logische Erkennung: Das Skript prüft zunächst mit page.IsBlank(), ob eine Seite logisch leer ist. Dies erkennt Seiten ohne Text- oder Bildobjekte.
-
Visuelle Erkennung: Wenn eine Seite nicht logisch leer ist, wird sie in ein Bild konvertiert und Pixel für Pixel analysiert. Wenn alle Pixel weiß sind, wird die Seite als visuell leer betrachtet.
Diese kombinierte Strategie stellt sicher, dass sowohl technisch leere Seiten als auch visuell leere Seiten mit verstecktem Inhalt entfernt werden.
Erweiterung der Automatisierungslösung
Dieses Skript kann leicht erweitert werden, um:
- Alle PDFs in einem Verzeichnis zu verarbeiten
- Als geplante Bereinigungsaufgabe auszuführen
- In Dokumentenmanagementsysteme zu integrieren
- Entfernte Seiten für Auditing oder Debugging zu protokollieren
Mit geringfügigen Anpassungen kann es PDF-Workflows im Unternehmensmaßstab unterstützen. Für fortgeschrittenere PDF-Operationen verweisen wir auf den Spire.PDF-Programmierleitfaden, um Ihre Automatisierungslogik weiter auszubauen und anzupassen.
Manuelle vs. automatische Entfernung leerer Seiten
| Aspekt | Manuelle Methoden | Python-Automatisierung |
|---|---|---|
| Benutzerfreundlichkeit | Hoch | Mittel |
| Genauigkeit | Hoch | Hoch |
| Stapelverarbeitung | x | √ |
| Skalierbarkeit | x | √ |
| Bester Anwendungsfall | Kleine PDFs | Große oder wiederkehrende Aufgaben |
Best Practices zum Entfernen leerer Seiten aus PDFs
- Bewahren Sie immer eine Sicherungskopie der Originaldateien auf.
- Testen Sie die Erkennungslogik an Beispieldokumenten.
- Seien Sie vorsichtig bei gescannten PDFs.
- Kombinieren Sie Automatisierung mit manueller Überprüfung bei kritischen Dateien.
Abschließende Gedanken
Das Entfernen leerer Seiten aus PDFs ist ein kleiner, aber wichtiger Schritt zur Erstellung sauberer, professioneller Dokumente. Manuelle Methoden eignen sich gut für schnelle Bearbeitungen und kleine Dateien, skalieren aber nicht effizient.
Für größere oder wiederkehrende Aufgaben ist die Automatisierung die klare Lösung. Durch die Verwendung von Spire.PDF for Python und die Kombination von logischen und visuellen Erkennungstechniken können Sie sowohl technisch als auch visuell leere Seiten zuverlässig entfernen. Dieser Ansatz spart Zeit, verbessert die Konsistenz und lässt sich nahtlos in moderne Dokumenten-Workflows integrieren.
Häufig gestellte Fragen
F1: Warum erscheinen leere oder unerwünschte Seiten in PDF-Dateien?
Leere oder zusätzliche Seiten entstehen oft durch Formatierungsprobleme bei der Dokumentenkonvertierung, falsche Seitenumbrüche, Scan-Artefakte oder beim Exportieren von Dateien aus Word, Excel oder Berichtstools.
F2: Kann ich Seiten aus einem PDF löschen, ohne kostenpflichtige Software zu verwenden?
Ja. Sie können Seiten mit kostenlosen Optionen wie integrierten Tools wie der macOS-Vorschau, Online-PDF-Editoren oder kostenlosen Desktop-PDF-Readern, die eine grundlegende Seitenverwaltung unterstützen, löschen.
F3: Beeinflusst das Löschen von Seiten den Inhalt oder das Layout des restlichen PDFs?
Das Löschen von Seiten ändert nichts am Layout oder der Formatierung der verbleibenden Seiten. Es wird jedoch empfohlen, das endgültige Dokument zu überprüfen, um sicherzustellen, dass Seitennummerierung, Lesezeichen oder Verweise noch sinnvoll sind.
F4: Ist es sicher, Seiten aus einem PDF zu löschen?
Ja, solange Sie eine Sicherungskopie der Originaldatei aufbewahren. Das Löschen von Seiten ist ein nicht-destruktiver Vorgang, wenn es als neue Datei gespeichert wird, sodass das Original bei Bedarf leicht wiederhergestellt werden kann.