I file PDF sono ampiamente utilizzati per la condivisione di documenti perché preservano il layout e la formattazione su tutti i dispositivi. Tuttavia, alcuni PDF includono autorizzazioni di sicurezza che impediscono agli utenti di copiare il testo. Quando si tenta di selezionare o copiare contenuto da questi file, è possibile che la copia sia disabilitata.
Questo tipo di file è spesso chiamato PDF protetto, sicuro o con restrizioni. A differenza dei PDF protetti da password che bloccano l'apertura del file, questi documenti possono comunque essere visualizzati normalmente, ma alcune azioni come la copia del testo sono limitate.
Fortunatamente, esistono diverse soluzioni alternative gratuite e pratiche che consentono di estrarre o copiare testo da PDF protetti. In questa guida, esploreremo cinque metodi semplici, inclusi strumenti online, funzionalità di sistema integrate e un approccio di automazione con Python.
Navigazione rapida
- Metodo 1 — Copiare testo da un PDF protetto utilizzando Google Docs
- Metodo 2 — Convertire un PDF con restrizioni in TXT online
- Metodo 3 — Screenshot + OCR per estrarre il testo
- Metodo 4 — Stampare un PDF protetto da copia in un nuovo PDF
- Metodo 5 — Estrarre testo da un PDF protetto utilizzando Python
Perché non è possibile copiare testo da alcuni PDF?
Molti creatori di PDF applicano restrizioni sulle autorizzazioni per controllare come il documento può essere utilizzato. Queste autorizzazioni sono impostate nelle impostazioni di sicurezza del PDF e possono disabilitare azioni come:
- Copia del testo
- Modifica del documento
- Stampa del file
- Aggiunta di annotazioni
Questo viene spesso definito protezione dalla copia o restrizione del contenuto. Sebbene il documento rimanga leggibile, il visualizzatore PDF impedisce la selezione o la copia del testo.
Queste restrizioni vengono generalmente utilizzate per proteggere la proprietà intellettuale o impedire il riutilizzo non autorizzato dei contenuti. Tuttavia, quando è legittimamente necessario riutilizzare il testo, ad esempio per scopi di ricerca, documentazione o accessibilità, potrebbero essere necessari modi alternativi per estrarre il contenuto.
Di seguito sono riportati cinque metodi che possono aiutare.
Metodo 1 — Copiare testo da un PDF protetto utilizzando Google Docs
Uno dei modi più semplici per copiare testo da un PDF protetto è aprirlo con Google Docs. Quando un PDF viene caricato su Google Drive e aperto in Google Docs, il servizio converte automaticamente il file in un documento modificabile.
Durante questo processo di conversione, il contenuto del PDF viene reinterpretato come testo e paragrafi, il che spesso aggira le restrizioni di copia di base. Una volta completata la conversione, è possibile selezionare e copiare facilmente il testo proprio come in un normale documento.
Passaggi
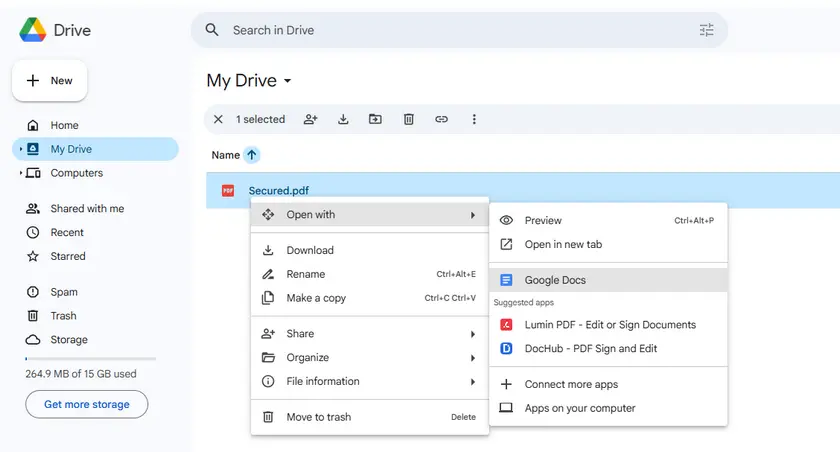
- Apri Google Drive.
- Carica il PDF protetto.
- Fai clic con il pulsante destro del mouse sul file e seleziona Apri con → Google Docs.
- Google Docs convertirà il PDF in un documento modificabile.
- Copia il testo estratto dal documento.
Vantaggi
- Gratuito e facile da usare.
- Nessuna installazione di software richiesta.
- Funziona bene con documenti basati su testo.
Limitazioni
- I PDF scansionati/basati su immagini non verranno convertiti in testo (senza OCR).
- La formattazione può diventare disordinata con layout complessi.
- Richiede un account Google e una connessione Internet.
Metodo 2 — Convertire un PDF con restrizioni in TXT online
Un'altra soluzione rapida è convertire il PDF con restrizioni in un file di testo semplice utilizzando un convertitore online. Una volta che il documento viene convertito in formato TXT, il testo diventa completamente modificabile e può essere copiato senza restrizioni.
Uno strumento gratuito e conveniente per questo scopo è PDF24 Tools, che fornisce un convertitore da PDF a TXT basato su browser. Questo metodo funziona bene quando è necessario estrarre rapidamente il testo senza installare software aggiuntivo.
Passaggi
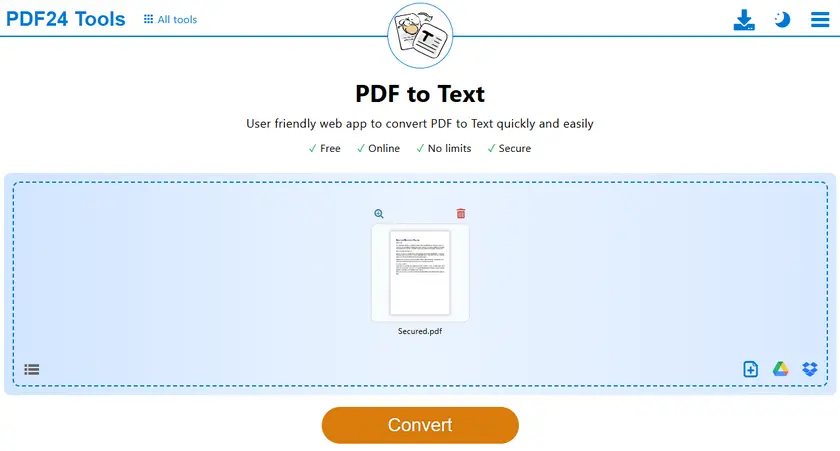
- Apri lo strumento da PDF a TXT.
- Carica il tuo file PDF protetto.
- Avvia il processo di conversione.
- Scarica il file TXT generato.
- Apri il file TXT e copia liberamente il testo.
Vantaggi
- Flusso di lavoro rapido e semplice.
- Nessuna installazione richiesta.
Limitazioni
- Rischio per la privacy: i documenti sensibili vengono caricati su server di terze parti.
- Spesso limitato a poche conversioni gratuite al giorno.
- Nessun supporto OCR nella maggior parte degli strumenti gratuiti (i PDF basati su immagini non funzioneranno).
Metodo 3 — Screenshot + OCR per estrarre il testo
Se il PDF ha forti restrizioni di copia o contiene pagine scansionate, l'OCR (Riconoscimento Ottico dei Caratteri) può comunque recuperare il testo visibile. La tecnologia OCR analizza l'immagine del documento e converte i caratteri rilevati in testo modificabile.
Windows 11 include una funzione OCR integrata nello Strumento di cattura, che consente di catturare parte dello schermo ed estrarre istantaneamente il testo dall'immagine.
Passaggi
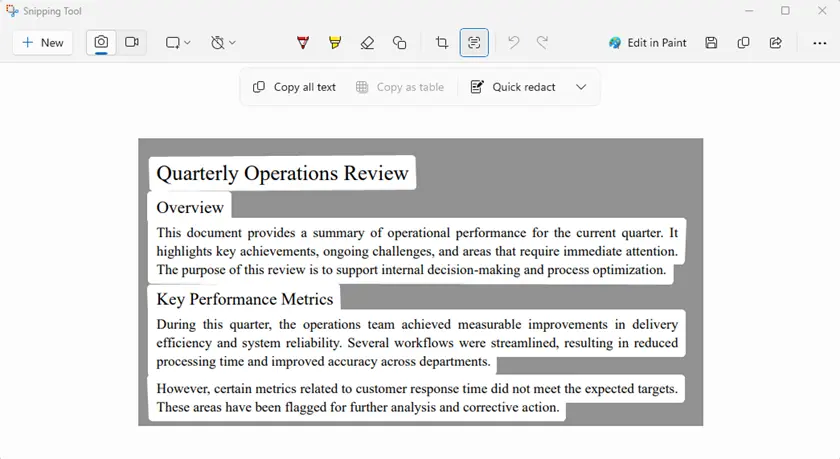
- Apri il PDF protetto sullo schermo.
- Avvia lo Strumento di cattura.
- Cattura l'area contenente il testo.
- Usa Azioni testo → Copia tutto il testo.
- Incolla il testo estratto in un documento.
Vantaggi
- Aggira quasi tutte le protezioni dalla copia poiché cattura lo schermo.
- Funziona con PDF scansionati/basati su immagini.
Limitazioni
- Richiede molto tempo se ci sono molte pagine.
- Errori OCR: la precisione dipende dalla qualità dell'immagine e dal carattere.
- Processo manuale a meno che non sia automatizzato con script.
Metodo 4 — Stampare un PDF protetto da copia in un nuovo PDF
Alcuni PDF protetti bloccano la copia ma consentono comunque la stampa. In tali casi, è possibile stampare il documento in un nuovo file PDF, che potrebbe rimuovere la restrizione di copia.
Questo può essere fatto facilmente utilizzando la funzione di stampa integrata in Google Chrome. Dopo aver salvato la versione stampata del file, il nuovo PDF potrebbe consentire la normale selezione e copia del testo.
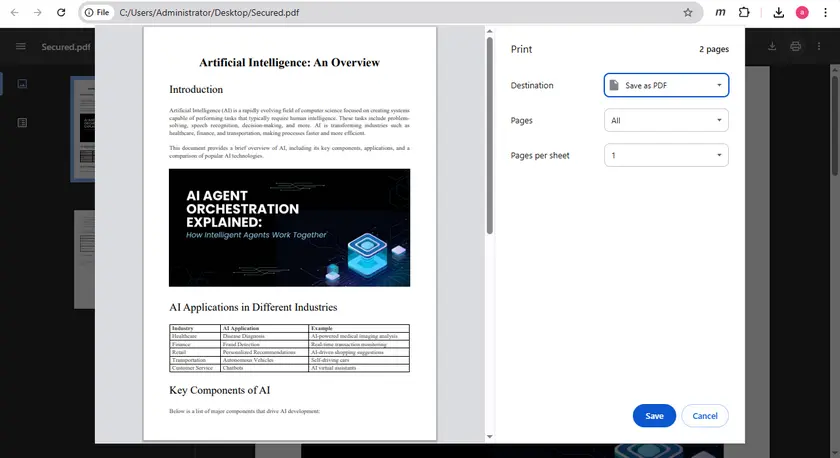
Passaggi
- Apri il PDF in Google Chrome.
- Premi Ctrl + P per aprire la finestra di dialogo di stampa.
- Imposta la destinazione su Salva come PDF.
- Salva il PDF appena generato.
- Apri il nuovo file e prova a copiare il testo.
Vantaggi
- Soluzione semplice.
- Nessuno strumento aggiuntivo richiesto.
Limitazioni
- Se la stampa è disabilitata nelle autorizzazioni del PDF, questo non funzionerà.
- Potrebbero apparire alcune differenze di formattazione.
Metodo 5 — Estrarre testo da un PDF protetto utilizzando Python
Per gli sviluppatori o gli utenti che devono elaborare più documenti, l'estrazione programmatica del testo può essere la soluzione più efficiente. Invece di copiare manualmente il contenuto, uno script può leggere automaticamente la struttura del PDF e recuperare il testo da ogni pagina.
Utilizzando Free Spire.PDF per Python, è possibile estrarre facilmente testo da documenti PDF con poche righe di codice. Questo approccio è particolarmente utile per l'automazione, l'elaborazione batch o la creazione di flussi di lavoro per l'elaborazione di documenti.
Se si lavora con documenti di piccole dimensioni (entro 10 pagine per documento) o si testano flussi di lavoro di estrazione, la versione gratuita funziona bene. Per file più grandi, è possibile dividere prima il documento o utilizzare la versione completa.
Installa la libreria
pip install spire.pdf.free
Esempio: estrarre testo da ogni pagina
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Secured.pdf")
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Create a PdfTextExtractor object
textExtractor = PdfTextExtractor(page)
# Create a PdfTextExtractOptions object
extractOptions = PdfTextExtractOptions()
# Set IsExtractAllText to True
extractOptions.IsExtractAllText = True
# Extract text from the page keeping white spaces
text = textExtractor.ExtractText(extractOptions)
# Write text to a txt file
with open('output/TextOfPage-{}.txt'.format(i + 1), 'w', encoding='utf-8') as file:
lines = text.split("\n")
for line in lines:
if line != '':
file.write(line)
doc.Close()
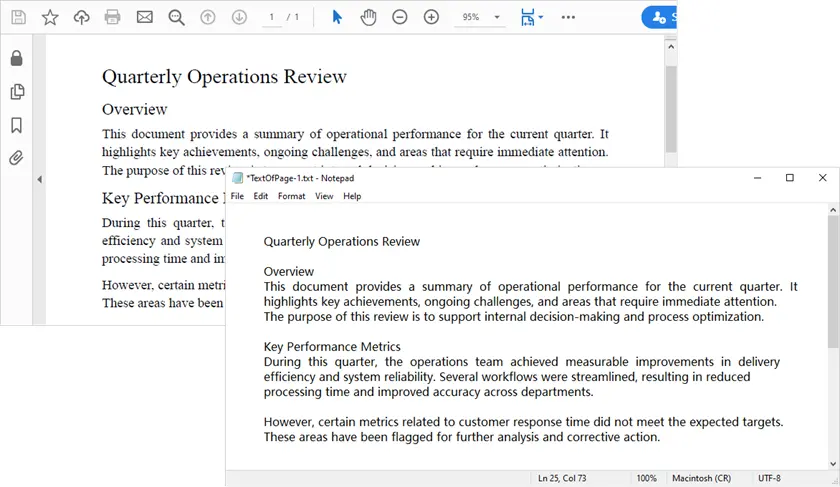
Cosa fa questo script
- Carica il documento PDF.
- Scorre ogni pagina.
- Estrae il testo preservando gli spazi bianchi.
- Salva il testo estratto in file TXT.
Vantaggi
- Pieno controllo sul processo di estrazione.
- Può essere automatizzato per l'elaborazione batch.
- Funziona bene con i PDF basati su testo.
Limitazioni
- Richiede conoscenze di programmazione.
- Non è in grado di gestire PDF basati su immagini a meno che non venga utilizzata una libreria OCR aggiuntiva.
Potrebbe piacerti anche: Eseguire l'OCR di PDF con Python (estrarre testo da PDF scansionato)
Tabella di confronto: quale metodo scegliere?
| Metodo | Livello di abilità | Facilità d'uso | Ideale per | Funziona con PDF scansionati | Funziona con restrizioni forti | Elaborazione batch |
|---|---|---|---|---|---|---|
| Google Docs | Principiante | Molto facile | Estrazione rapida nel browser | No | Sì | No |
| Convertitore online | Principiante | Molto facile | Conversione TXT veloce | No | Sì | No |
| Screenshot + OCR | Principiante | Facile | PDF scansionati o basati su immagini | Sì | Sì | No |
| Stampa su PDF | Principiante | Facile | Rimozione di restrizioni semplici | No | Condizionale (la stampa deve essere consentita) | No |
| Python (Spire.PDF) | Sviluppatore | Moderato | Automazione e flussi di lavoro batch | Si basa su librerie OCR aggiuntive | Sì | Sì |
Conclusione
Le restrizioni di copia nei PDF possono essere frustranti, soprattutto quando è necessario riutilizzare solo una parte del testo. Fortunatamente, diversi metodi gratuiti possono aiutare a estrarre contenuto da PDF protetti.
Per attività rapide, strumenti come Google Docs o convertitori online possono essere la soluzione più semplice. Se il documento contiene contenuto scansionato o restrizioni rigide, i metodi basati su OCR possono comunque recuperare il testo. Per flussi di lavoro su larga scala o scenari di automazione, l'utilizzo di librerie Python come Free Spire.PDF per Python fornisce un approccio potente e flessibile.
Scegliendo il metodo che meglio si adatta alle tue esigenze, puoi recuperare in modo efficiente il testo da PDF con restrizioni mantenendo un flusso di lavoro efficiente.
Domande frequenti (FAQ)
D1: Cos'è un PDF protetto o con restrizioni?
Un PDF protetto o con restrizioni è un documento che può essere aperto e visualizzato normalmente ma ha impostazioni di sicurezza che impediscono la copia, la stampa o la modifica del suo contenuto. Queste autorizzazioni sono impostate dal proprietario del documento.
D2: Posso copiare testo da tutti i PDF protetti?
Non sempre. Alcuni PDF hanno una crittografia avanzata o DRM che impedisce completamente la copia. In tali casi, potrebbero essere necessari strumenti OCR o librerie professionali.
D3: Qual è il metodo migliore per i PDF scansionati?
Per i PDF scansionati, l'estrazione tramite screenshot + OCR o l'automazione con Python con librerie OCR è solitamente il modo più affidabile per recuperare il testo.
D4: Posso automatizzare l'estrazione del testo per più PDF?
Sì. Utilizzando librerie Python come Spire.PDF, è possibile estrarre automaticamente testo da più file PDF, rendendolo ideale per l'elaborazione batch o l'automazione del flusso di lavoro.
D5: Devo pagare per uno di questi metodi?
Tutti i metodi elencati nell'articolo sono gratuiti. Tuttavia, alcuni strumenti (come Spire.PDF) hanno versioni gratuite con limitazioni, come una restrizione sul numero di pagine. Per file più grandi, potrebbe essere necessaria la versione completa.