
La conversione di tabelle da file PDF in formato CSV è un requisito comune nei flussi di lavoro di reporting, analisi e integrazione dei dati. I file CSV sono leggeri, ampiamente supportati e adatti all'automazione, rendendoli molto più utili dei PDF statici una volta che i dati tabulari devono essere riutilizzati.
In pratica, tuttavia, la conversione di una tabella PDF in CSV è raramente semplice. I file PDF sono progettati per preservare l'aspetto visivo piuttosto che la struttura logica. Una tabella che appare perfettamente allineata sullo schermo potrebbe non esistere internamente come righe e colonne, motivo per cui i metodi di conversione ingenui spesso falliscono.
Questo articolo si concentra su metodi pratici di conversione da tabella PDF a CSV. Invece di coprire ogni opzione teorica, spiega gli approcci più comunemente usati, come si comportano in pratica e quando ogni metodo è appropriato.
Indice
- Modi Pratici Comuni per Convertire Tabelle PDF in CSV
- Metodo 1: Esportare PDF in Foglio di Calcolo Usando Acrobat
- Metodo 2: Conversione Online di Tabelle PDF in CSV
- Metodo 3: Estrazione Programmatica di Tabelle PDF con Python
- Gestione di Scenari Reali di Tabelle PDF
- Punti Chiave: Convertire Tabelle PDF in CSV
- FAQ
Modi Pratici Comuni per Convertire Tabelle PDF in CSV
Nella maggior parte dei flussi di lavoro reali, la conversione di una tabella PDF in CSV rientra in una delle seguenti categorie:
- Esportazione di tabelle tramite strumenti da PDF a foglio di calcolo (come Acrobat)
- Utilizzo di convertitori online da tabella PDF a CSV
- Estrazione di tabelle programmaticamente utilizzando codice Python
Le semplici tecniche di copia e incolla sono intenzionalmente escluse, poiché di solito appiattiscono le tabelle in testo semplice e richiedono una ricostruzione manuale estesa.
Metodo 1: Esportare PDF in Foglio di Calcolo Usando Acrobat
Esportare un PDF in un formato di foglio di calcolo e poi salvarlo come CSV è una scelta comune per gli utenti che preferiscono strumenti desktop e l'ispezione visiva.
Quando Questo Metodo Funziona Bene
- Il PDF è basato su testo e ben strutturato
- Le tabelle hanno confini chiari tra righe e colonne
- La revisione e la correzione manuale sono accettabili
Flusso di Lavoro Tipico Basato su Acrobat
-
Apri il file PDF in Acrobat
-
Scegli Esporta PDF e seleziona Foglio di calcolo come formato di output
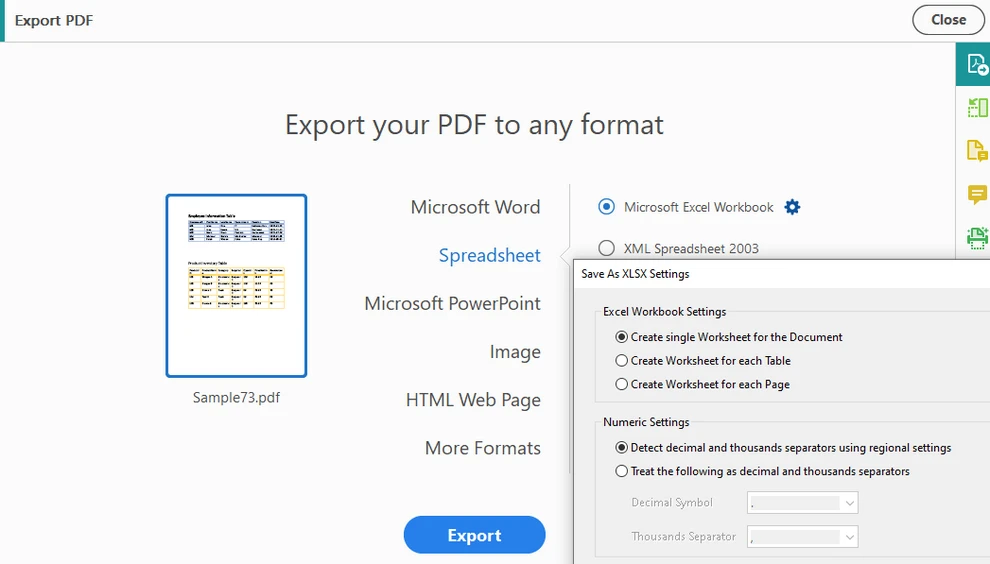
-
Esporta il documento in formato Excel
-
Rivedi e modifica la struttura della tabella se necessario
-
Salva o esporta il foglio di calcolo come file CSV
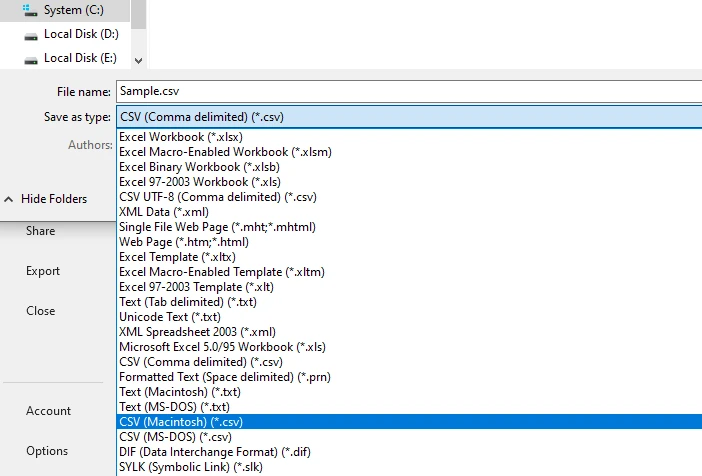
Questo flusso di lavoro produce spesso risultati strutturali migliori rispetto alla copia diretta, specialmente per tabelle a pagina singola o formattate in modo coerente.
Limitazioni Pratiche
- Tabelle complesse o su più pagine possono essere divise su più fogli
- Le celle unite possono portare a colonne disallineate nell'output CSV
- Spesso è necessaria una pulizia manuale prima dell'esportazione
- Non adatto per l'elaborazione batch o automatizzata
Questo approccio è efficace per conversioni occasionali in cui la validazione visiva è importante, ma non scala bene.
Per gli utenti che cercano un'alternativa gratuita ad Acrobat per convertire tabelle PDF in Excel prima di salvarle come CSV, vedere Come Convertire PDF in Excel Gratuitamente.
Metodo 2: Conversione Online di Tabelle PDF in CSV
I convertitori online sono ampiamente utilizzati perché non richiedono installazione e forniscono risultati rapidi.
Quando la Conversione Online è una Buona Scelta
- Il PDF contiene testo selezionabile (non scansionato)
- I layout delle tabelle sono relativamente semplici
- È necessario convertire solo un piccolo numero di file
Flusso di Lavoro Tipico per la Conversione Online di Tabelle PDF in CSV
La maggior parte degli strumenti online segue un processo simile (esempio con Zamzar):
-
Apri un convertitore online da PDF a CSV
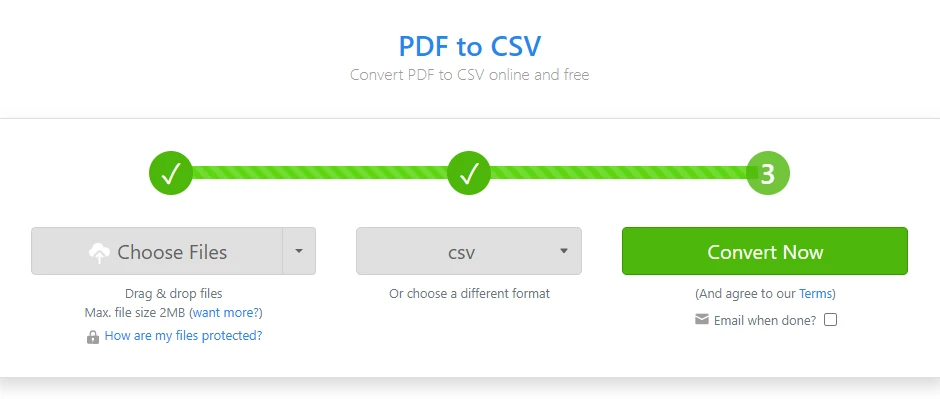
-
Carica il file PDF contenente la tabella
-
Configura l'intervallo di pagine o le opzioni di rilevamento della tabella, se disponibili
-
Avvia il processo di conversione
-
Scarica il file CSV generato
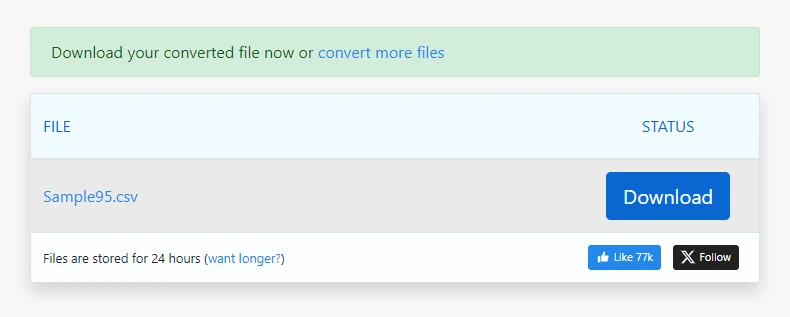
Per PDF semplici, questo processo può generare un output CSV utilizzabile in pochi secondi.
Considerazioni Comuni con i Convertitori Online
- Le colonne possono spostarsi quando la spaziatura è incoerente
- I convertitori spesso esportano l'intero PDF come CSV, non solo le tabelle
- Le interruzioni di riga all'interno delle celle possono creare righe aggiuntive
- La qualità dell'output varia in base al layout del documento
- Possono essere applicati limiti di dimensione dei file e problemi di privacy
Gli strumenti online sono da considerarsi un'opzione di comodo piuttosto che una soluzione prevedibile o riutilizzabile.
Metodo 3: Estrazione Programmatica di Tabelle PDF con Python
Quando sono richieste accuratezza, coerenza o automazione, l'estrazione programmatica è spesso il modo più affidabile per convertire tabelle PDF in CSV.
Perché l'Estrazione Programmatica è Spesso Preferita
- Le tabelle possono essere elaborate pagina per pagina
- Le tabelle su più pagine possono essere gestite in modo coerente
- La stessa logica di estrazione può essere riutilizzata in processi batch
- L'output è riproducibile e più facile da convalidare
Questo approccio è comune nelle pipeline di dati, nei sistemi di reporting e nei servizi di backend che elaborano PDF su larga scala. Con Spire.PDF for Python, gli sviluppatori possono estrarre accuratamente le tabelle dai documenti PDF, gestire layout complessi e multi-pagina e automatizzare la conversione in CSV con un intervento manuale minimo.
Flusso di Lavoro Programmatico Tipico per la Conversione da Tabella PDF a CSV
La maggior parte delle soluzioni programmatiche segue un processo di alto livello simile:
- Carica il documento PDF
- Itera attraverso ogni pagina
- Rileva le strutture delle tabelle su ogni pagina
- Estrai righe e colonne come dati strutturati
- Normalizza il testo estratto dove necessario
- Scrivi i dati strutturati in file CSV
Python è ampiamente utilizzato per questo compito perché combina leggibilità con potenti capacità di elaborazione dei dati.
Esempio: Convertire Tabelle PDF in CSV Usando Python
Prima di eseguire l'esempio seguente, assicurati che la libreria di elaborazione PDF richiesta sia installata.
Puoi installare Spire.PDF for Python usando pip:
pip install spire.pdf
Una volta installato, puoi procedere con l'esempio di estrazione della tabella.
L'esempio seguente dimostra come convertire tabelle PDF in CSV utilizzando Spire.PDF for Python.
import os
import csv
from spire.pdf import PdfDocument, PdfTableExtractor
# Load the PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a table extractor
extractor = PdfTableExtractor(pdf)
# Normalize text to handle PDF ligatures and PUA characters
def normalize_text(text: str) -> str:
if not text:
return text
if not any('\uE000' <= ch <= '\uF8FF' for ch in text):
return text
ligatures = {
'\uE000': 'ff',
'\uE001': 'fi',
'\uE002': 'fl',
'\uE003': 'ffl',
'\uE004': 'ffi',
'\uE005': 'ft',
'\uE006': 'st',
}
for lig, repl in ligatures.items():
text = text.replace(lig, repl)
return text
# Extract tables page by page
for page_index in range(pdf.Pages.Count):
tables = extractor.ExtractTable(page_index)
if tables:
for table_index, table in enumerate(tables):
rows = []
for r in range(table.GetRowCount()):
row = []
for c in range(table.GetColumnCount()):
cell = normalize_text(table.GetText(r, c)).replace("\n", " ")
row.append(cell)
rows.append(row)
os.makedirs("output/Tables", exist_ok=True)
with open(
f"output/Tables/Page{page_index + 1}-Table{table_index + 1}.csv",
"w",
newline="",
encoding="utf-8",
) as f:
writer = csv.writer(f)
writer.writerows(rows)
pdf.Close()
Di seguito è riportata un'anteprima dei risultati della conversione da tabella PDF a CSV:
Come Funziona Questa Implementazione
Questa implementazione si concentra sulla conservazione della struttura della tabella piuttosto che sull'inferenza del layout dalle posizioni del testo:
- L'estrazione a livello di cella assicura che righe e colonne siano conservate come unità logiche invece di essere ricostruite dalla spaziatura
- L'elaborazione pagina per pagina impedisce che le tabelle vengano unite in modo errato tra i confini delle pagine
- La normalizzazione esplicita del testo gestisce problemi comuni dei PDF come legature e caratteri Unicode di uso privato, che possono corrompere silenziosamente l'output CSV
- La scrittura diretta in CSV evita formati intermedi che potrebbero introdurre artefatti di formattazione aggiuntivi
Di conseguenza, i file CSV generati sono più stabili e adatti all'elaborazione automatizzata. Per una guida passo passo sull'estrazione di tabelle da documenti PDF, vedere Guida Dettagliata: Estrazione di Tabelle da PDF.
Gestione di Scenari Reali di Tabelle PDF
Nei flussi di lavoro del mondo reale, le tabelle PDF si comportano spesso in modo diverso da come appaiono sullo schermo. I problemi tipici includono:
- Tabelle che si estendono su più pagine con intestazioni ripetute o mancanti
- Lievi spostamenti della posizione delle colonne tra le pagine
- Righe con celle vuote, a capo o irregolari
- Grandi lotti di PDF con layout simili ma non identici
Questi fattori sono di solito il punto in cui gli strumenti di esportazione generici e i convertitori online iniziano a produrre un output CSV incoerente.
Da un punto di vista pratico, l'estrazione programmatica è più adatta a questi casi perché consente:
- Elaborazione pagina per pagina senza unire accidentalmente tabelle non correlate
- Gestione controllata di tabelle su più pagine
- Allineamento stabile delle colonne anche quando i layout non sono perfettamente uniformi
Un ulteriore dettaglio di usabilità degno di nota è la codifica CSV:
- Quando i dati estratti includono caratteri non-ASCII, i file CSV aperti direttamente in Excel potrebbero visualizzare testo illeggibile
- Salvare l'output CSV come UTF-8 con BOM (UTF-8-SIG) aiuta a garantire la corretta visualizzazione dei caratteri senza passaggi di importazione manuale
Queste considerazioni diventano particolarmente rilevanti quando si lavora con PDF del mondo reale piuttosto che con esempi idealizzati.
Punti Chiave: Convertire Tabelle PDF in CSV
In pratica, la conversione di una tabella PDF in CSV si riduce solitamente a tre opzioni:
- L'esportazione da Acrobat funziona bene per conversioni occasionali verificate visivamente, come fatture o report a pagina singola
- I convertitori online sono comodi per compiti semplici e una tantum con tabelle semplici
- L'estrazione programmatica offre i risultati più affidabili per flussi di lavoro complessi, multi-pagina o ripetuti, specialmente nelle pipeline automatizzate
La scelta del metodo giusto dipende meno dallo strumento stesso e più da come verranno utilizzati i dati estratti.
FAQ
Le tabelle di PDF scansionati possono essere convertite direttamente in CSV?
No. I PDF scansionati richiedono l'OCR prima che l'estrazione della tabella sia possibile. Per una guida passo passo sull'estrazione di testo da PDF scansionati usando Python, vedere Estrazione di Testo da PDF Scansionati con Python.
È meglio CSV o Excel per le tabelle estratte da PDF? CSV è più semplice e più adatto per l'automazione, mentre Excel è spesso preferito per la revisione manuale.
Python è adatto per la conversione batch di tabelle PDF? Sì. Python è ampiamente utilizzato per l'estrazione di tabelle PDF su larga scala e automatizzata grazie alla sua flessibilità e leggibilità.