
PDF는 비즈니스 계약서, 학술 논문, 마케팅 브로셔, 법률 문서 등 어디에나 존재합니다. 하지만 눈에 보이는 텍스트와 이미지 외에도 모든 PDF에는 메타데이터라는 숨겨진 정보가 포함되어 있습니다. 이 이면의 데이터는 문서의 출처, 작성자, 생성 날짜 등에 대한 중요한 세부 정보를 제공합니다. 콘텐츠 제작자, 개발자, 법률 전문가 또는 단순히 파일을 정리하려는 사람이라면 누구나 PDF에서 메타데이터를 추출하는 방법을 아는 것은 가치 있는 기술입니다.
이 가이드에서는 간단한 내장 도구부터 고급 프로그래밍 라이브러리까지, PDF 메타데이터를 추출하는 가장 효과적인 방법을 안내합니다.
메타데이터 추출, 왜 중요할까요?
PDF 메타데이터는 생각보다 훨씬 유용하며 다양한 시나리오에서 핵심적인 가치를 제공합니다:
| 사용 사례 | 중요성 |
|---|---|
| 디지털 포렌식 | 문서 출처 및 변경 사항 추적; 위조 파일 감지 |
| 법률 전자 증거 개시 | 메타데이터 타임스탬프는 법정 증거로 인정됨 |
| 콘텐츠 관리 | 작성자, 날짜 또는 키워드로 수천 개의 PDF 자동 태그 지정 |
| SEO 및 검색 가시성 | Google은 검색 스니펫에 PDF 제목/주제를 사용 |
| 개인 정보 보호 | 공유 전 숨겨진 개인 데이터 찾기 및 제거 |
| 워크플로우 자동화 | 수동 읽기 없이 송장 번호 및 보고서 날짜 추출 |
| 라이브러리 아카이빙 | 연구를 위한 검색 가능한 PDF 데이터베이스 구축 |
단일 문서의 경우에도 PDF 메타데이터 읽는 방법을 알면 진위 여부를 확인하고 민감한 정보가 유출되는 것을 방지하는 데 도움이 됩니다.
함께 읽어보기: PDF 메타데이터 편집 방법 (4가지 방법)
PDF 메타데이터 추출을 위한 4가지 검증된 방법 (초보자부터 전문가까지)
도구 사용 편의성과 처리할 파일 수에 따라 PDF에서 메타데이터를 가져오는 데는 여러 가지 옵션이 있으며, 노코드, 온라인, 프로그래밍 및 명령줄 접근 방식을 모두 포함합니다.
1. Adobe Acrobat Pro (Windows/Mac)
Adobe Acrobat Pro는 PDF 작업의 업계 표준입니다. 깔끔한 그래픽 인터페이스를 통해 표준 및 고급 메타데이터를 모두 보고 내보낼 수 있습니다.
사용 방법:
- Adobe Acrobat Pro에서 PDF를 엽니다.
- “파일” > “속성”을 클릭합니다 (또는 Ctrl+D/Command+D를 누릅니다).
- “설명” 탭에는 표준 메타데이터(제목, 작성자, 주제 등)가 표시됩니다. “고급” 탭에는 더 깊은 XMP 데이터(예: PDF 생성 소프트웨어 버전)가 표시됩니다.
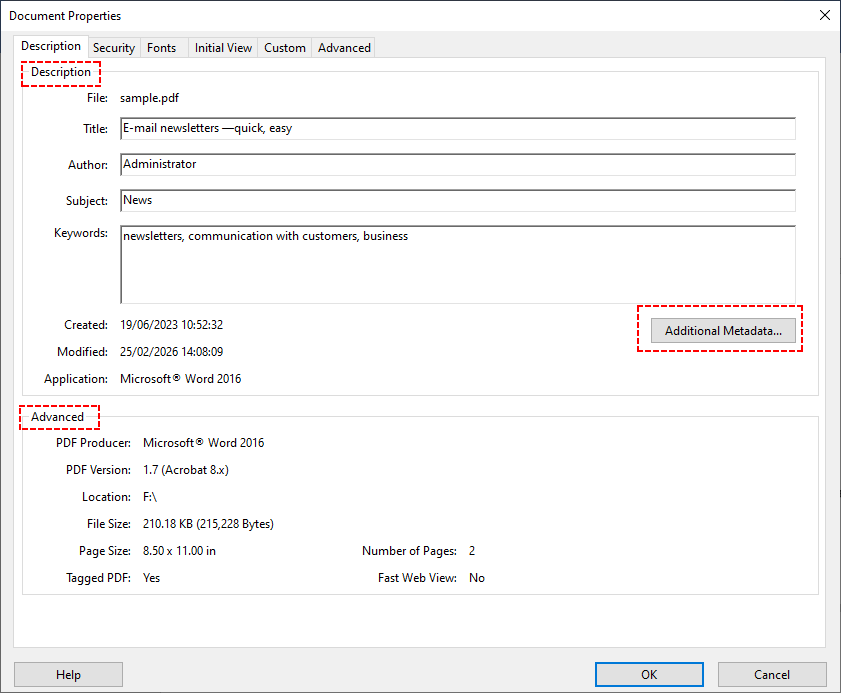
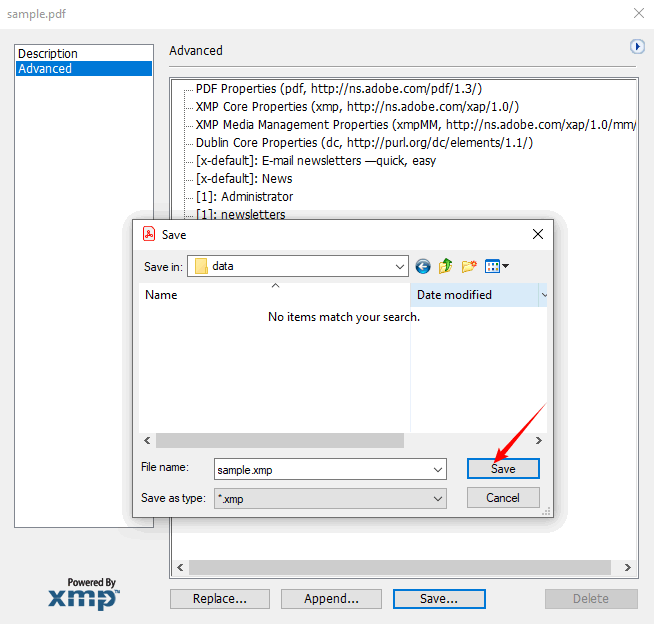
- 더 많은 사용자 지정 필드를 보려면 “추가 메타데이터”를 클릭하여 모든 XMP 속성을 탐색합니다.
- “내보내기”를 선택하여 XMP 파일로 저장합니다. 이 파일은 다른 Adobe 도구로 가져오거나 사용자 지정 스크립트로 읽을 수 있습니다.
단점: 구독이 필요합니다. 이미 Acrobat Pro를 사용하는 전문가에게 적합하지만, 빠른 파일 확인에는 과도합니다.
많은 보안 PDF는 메타데이터에 대한 액세스를 제한하므로, PDF 권한 제거는 메타데이터 및 문서 콘텐츠에 대한 전체 액세스를 잠금 해제하여 암호로 보호되거나 제한된 파일에서 메타데이터를 제한 없이 추출, 수정 또는 내보낼 수 있습니다.
2. 무료 온라인 메타데이터 추출기 (빠르고 쉬움)
Google에서 빠르게 검색하면 PDF를 업로드하고 메타데이터를 볼 수 있는 수십 개의 사이트가 나옵니다. Metadata2Go 및 GroupDocs PDF Metadata Extractor 와 같은 인기 있는 예는 설치나 비용 없이 모든 장치에서 작동하므로 매우 편리합니다.
Metadata2Go를 사용하여 온라인으로 PDF 메타데이터 가져오기:
- 도구의 메타데이터 보기 페이지로 이동합니다.
- 드래그 앤 드롭으로 PDF를 업로드하거나 “파일 선택”을 클릭합니다.
- 도구가 PDF 파일에서 메타데이터를 추출할 때까지 기다립니다.
- 필요에 따라 결과를 CSV/TXT/JSON/HTML로 내보냅니다.
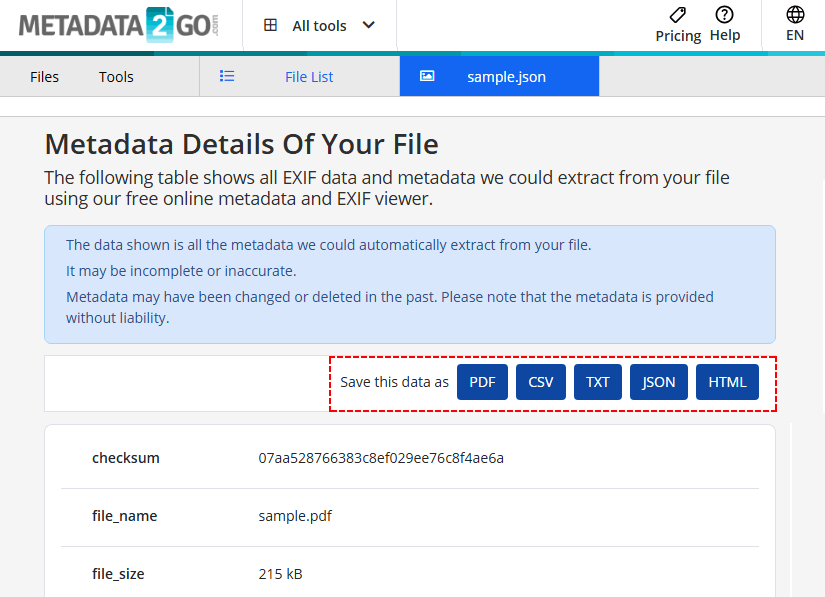
보안 위험: 민감하거나 기밀인 문서를 무료 온라인 도구에 업로드하지 마십시오.
3. 프로그래밍 방식으로 PDF 메타데이터 추출 (개발자용)
수백 개의 PDF에서 메타데이터를 추출하거나 자체 애플리케이션에 메타데이터 추출을 통합해야 하는 경우 프로그래밍이 최선의 방법입니다. 아래는 C# 과 Free Spire.PDF for .NET 라이브러리를 사용한 자세한 예입니다.
1단계 - NuGet을 통해 라이브러리 설치
Install-Package FreeSpire.PDF
2단계 – PDF 메타데이터를 읽는 C# 코드 작성
using Spire.Pdf;
using System.IO;
using System.Text;
namespace ExtractPDFMetadata
{
class Program
{
static void Main(string[] args)
{
// PdfDocument 객체 생성
PdfDocument pdf = new PdfDocument();
// PDF 파일 로드 (경로를 파일에 맞게 변경하세요)
pdf.LoadFromFile("F:\\sample.pdf");
// 문서 정보 액세스
PdfDocumentInformation info = pdf.DocumentInformation;
// 메타데이터 문자열 빌드
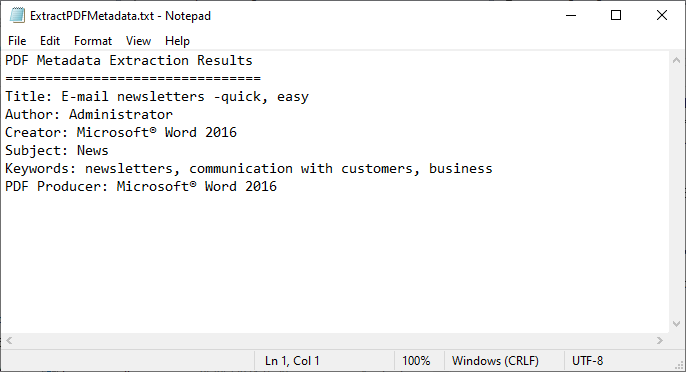
StringBuilder content = new StringBuilder();
content.AppendLine("PDF 메타데이터 추출 결과");
content.AppendLine("================================");
content.Append("제목: " + info.Title + "\r\n");
content.Append("작성자: " + info.Author + "\r\n");
content.Append("생성자: " + info.Creator + "\r\n");
content.Append("주제: " + info.Subject + "\r\n");
content.Append("키워드: " + info.Keywords + "\r\n");
content.Append("PDF 생성자: " + info.Producer + "\r\n");
// 결과를 TXT 파일에 쓰기
File.WriteAllText("ExtractPDFMetadata.txt", content.ToString());
}
}
}
이 코드는 PDF 파일을 로드하고 표준 메타데이터 필드를 가져와 텍스트 파일에 씁니다.
배치 처리: 여러 파일에서 메타데이터를 추출하려면 폴더의 모든 PDF를 반복합니다.
foreach (string file in Directory.GetFiles(@"C:\Invoices\", "*.pdf"))
{
// 각 파일 처리
}
전문가 팁: Free Spire.PDF는 기본 메타데이터 외에도 이미지 추출, 하이퍼링크, 양식 필드 값 *등 다른 요소 추출도 지원합니다.*
4. ExifTool을 사용한 명령줄 (고급 사용자용)
터미널 또는 명령 프롬프트에 익숙하다면 ExifTool 은 강력한 메타데이터 추출 도구입니다. 무료이며 크로스 플랫폼(Windows, macOS, Linux)이며 PDF뿐만 아니라 거의 모든 파일 형식에서 메타데이터를 읽습니다.
설치
Windows에서는 공식 사이트 에서 실행 파일을 다운로드합니다.
기본 사용법 – 단일 PDF의 메타데이터 보기:
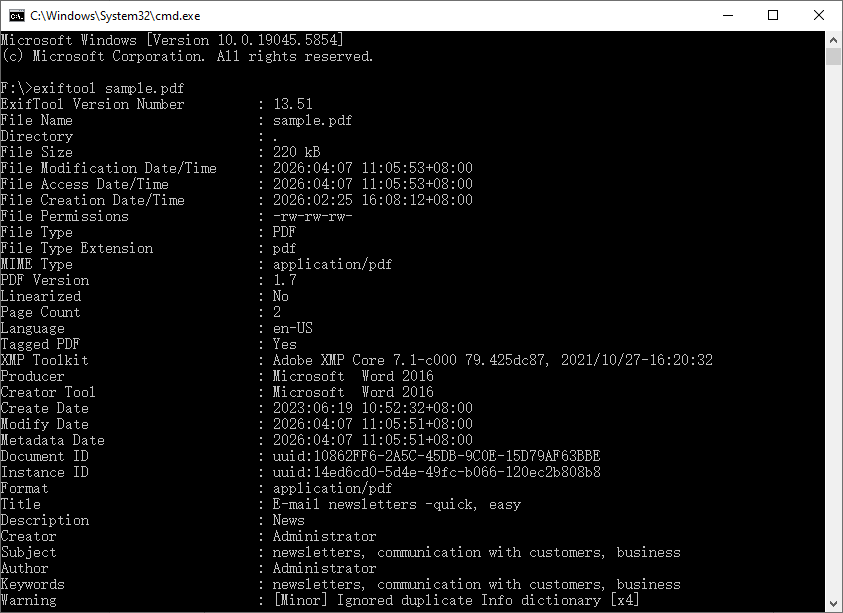
exiftool sample.pdf
이 명령은 태그-값 쌍의 긴 목록을 터미널에 직접 출력합니다.
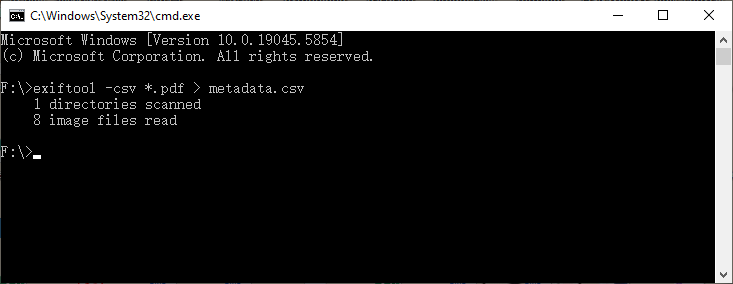
CSV로 배치 내보내기 (Excel에서 분석에 이상적):
exiftool -csv *.pdf > metadata.csv
이 명령은 수백 개의 PDF를 한 번에 감사하고 Excel 또는 Google 스프레드시트에서 열 수 있는 CSV를 생성하여 검색 가능한 카탈로그를 제공합니다.
언제 사용해야 할까요: 대규모 배치 감사, 포렌식 분석 또는 명령줄 효율성을 선호할 때.
메타데이터 제거는 추출과 함께 작동하는 중요한 보안 기능입니다. 추출된 메타데이터를 검토한 후, 외부에서 파일을 공유하기 전에 개인 정보 유출을 방지하기 위해 PDF에서 모든 숨겨진 민감한 메타데이터를 제거할 수 있습니다.
PDF 메타데이터 처리를 위한 중요 참고 사항
- 메타데이터는 편집되거나 위조될 수 있습니다.
PDF에 “작성자: John Doe”라고 표시된다고 해서 John Doe가 실제로 작성했다는 의미는 아닙니다. 심층 분석 없이는 결정적인 증거가 되지 않지만 유용한 맥락을 제공합니다.
- 스캔된 PDF는 다릅니다.
물리적 문서를 스캔하여 PDF로 저장한 경우, 일반적으로 얻을 수 있는 메타데이터는 스캐너 정보와 생성 날짜뿐입니다. 나중에 추가하지 않는 한 “작성자”나 “키워드”는 없습니다.
- SEO 팁.
웹사이트에 PDF를 게시하는 경우 제목 및 주제 필드를 채우세요. Google은 종종 검색 결과의 제목 및 설명에 이를 사용하므로 임의의 파일 이름이 표시되는 것보다 좋습니다.
마무리
PDF에서 메타데이터 추출은 시간을 절약하고, 개인 정보를 보호하며, 때로는 찾고 있던 정확한 세부 정보를 발견하는 실용적인 기술입니다. 빠른 확인을 위해 Acrobat의 속성 창을 사용하든, 공개 문서에 무료 온라인 도구를 사용하든, 수천 개의 송장을 처리하기 위해 C# 스크립트를 사용하든, 또는 대규모 명령줄 감사를 위해 ExifTool을 사용하든, 올바른 방법은 처리할 파일 수와 얼마나 깊이 들어가야 하는지에 따라 달라집니다.
다음에 PDF를 다운로드하거나 공유할 준비를 할 때 메타데이터를 잠시 살펴보세요. 무엇이 첨부되어 있는지 놀랄 수도 있고, 이제 그것을 추출하는 방법을 정확히 알게 될 것입니다.
자주 묻는 질문 (FAQ)
Q1: 스캔된 PDF에서 메타데이터를 추출할 수 있나요?
스캔된 PDF(이미지일 뿐인)는 일반적으로 메타데이터가 없습니다. 먼저 OCR 소프트웨어를 사용하여 이미지를 텍스트로 변환한 다음 메타데이터를 수동으로 추가해야 합니다.
Q2: 메타데이터는 파일 속성과 동일한가요?
정확히는 아닙니다. 파일 속성(파일 크기, 생성 날짜 등)은 운영 체제에서 관리합니다. PDF 메타데이터는 PDF 내부에 포함되어 문서와 함께 이동합니다.
Q3: PDF 메타데이터를 편집하거나 삭제할 수 있나요?
예. Adobe Acrobat Pro(그래픽) 또는 ExifTool(명령줄)을 사용하여 메타데이터를 편집/삭제할 수 있습니다. 프로그래밍 라이브러리도 수정 기능을 지원합니다.
Q4: 메타데이터가 PDF 파일 크기에 영향을 미치나요?
아니요. 메타데이터는 가벼운 텍스트 데이터이며 파일 크기에 눈에 띄는 영향을 미치지 않습니다.