
Python에서 Excel 파일을 만드는 것은 데이터 기반 애플리케이션에서 일반적인 요구 사항입니다. 애플리케이션 데이터를 비즈니스 사용자가 쉽게 검토하고 공유할 수 있는 형식으로 전달해야 할 때 Excel은 여전히 가장 실용적이고 널리 사용되는 선택 중 하나입니다.
실제 프로젝트에서 Python으로 Excel 파일 생성은 자동화된 프로세스의 시작점인 경우가 많습니다. 데이터는 데이터베이스, API 또는 내부 서비스에서 가져올 수 있으며 Python은 해당 데이터를 일관된 레이아웃과 명명 규칙을 따르는 구조화된 Excel 파일로 변환하는 역할을 합니다.
이 문서에서는 처음부터 통합 문서를 생성하는 것부터 데이터 작성, 기본 서식 적용, 필요할 때 기존 파일 업데이트에 이르기까지 Python에서 Excel 파일을 만드는 방법을 보여줍니다. 모든 예제는 실제 자동화 시나리오에서 Excel 파일이 어떻게 생성되고 사용되는지에 초점을 맞춰 실용적인 관점에서 제시됩니다.
목차
- Python에서 Excel 파일을 생성하기 위한 일반적인 시나리오
- 환경 설정
- Python에서 처음부터 새 Excel 파일 만들기
- Python을 사용하여 구조화된 데이터를 XLSX 파일에 쓰기
- Python에서 실제 보고서를 위한 Excel 데이터 서식 지정
- Python에서 기존 Excel 파일 읽기 및 업데이트
- 단일 워크플로에서 읽기 및 쓰기 작업 결합
- Excel 파일 생성을 위한 올바른 Python 접근 방식 선택
- 일반적인 문제 및 해결 방법
- 자주 묻는 질문
1. Python으로 Excel 파일을 생성하기 위한 일반적인 시나리오
Python으로 Excel 파일을 만드는 것은 독립적인 작업이라기보다는 더 큰 시스템의 일부로 발생하는 경우가 많습니다. 일반적인 시나리오는 다음과 같습니다.
- 일별, 주별 또는 월별 비즈니스 보고서 생성
- 분석 또는 감사를 위해 데이터베이스 쿼리 결과 내보내기
- 백엔드 서비스 또는 배치 작업에서 Excel 파일 생성
- 내부 시스템 또는 외부 파트너 간의 데이터 교환 자동화
이러한 상황에서 Python은 종종 Excel 파일을 자동으로 생성하는 데 사용되어 팀이 수동 작업을 줄이면서 데이터 일관성과 반복성을 보장하는 데 도움이 됩니다.
2. 환경 설정: Python에서 Excel 파일을 생성하기 위한 준비
이 튜토리얼에서는 Free Spire.XLS for Python을 사용하여 Excel 파일 작업을 시연합니다. Python으로 Excel 파일을 생성하기 전에 개발 환경이 준비되었는지 확인하십시오.
Python 버전
최신 Python 3.x 버전이면 Excel 자동화 작업에 충분합니다.
Free Spire.XLS for Python은 pip를 통해 설치할 수 있습니다.
pip install spire.xls.freeFree Spire.XLS for Python을 다운로드하여 프로젝트에 수동으로 포함할 수도 있습니다.
이 라이브러리는 Microsoft Excel과 독립적으로 작동하므로 Excel이 설치되지 않은 서버 환경, 예약된 작업 및 자동화된 워크플로에 적합합니다.
3. Python에서 처음부터 새 Excel 파일 만들기
이 섹션에서는 Python을 사용하여 처음부터 Excel 파일을 만드는 데 중점을 둡니다. 목표는 데이터를 쓰기 전에 워크시트와 머리글 행을 포함한 기본 통합 문서 구조를 정의하는 것입니다.
초기 레이아웃을 프로그래밍 방식으로 생성하면 모든 출력 파일이 동일한 구조를 공유하고 나중에 데이터를 채울 준비가 되었는지 확인할 수 있습니다.
예: 빈 Excel 템플릿 만들기
from spire.xls import Workbook, FileFormat
# Initialize a new workbook
workbook = Workbook()
# Access the default worksheet
sheet = workbook.Worksheets[0]
sheet.Name = "Template"
# Add a placeholder title
sheet.Range["B2"].Text = "Monthly Report Template"
# Save the Excel file
workbook.SaveToFile("template.xlsx", FileFormat.Version2016)
workbook.Dispose()
템플릿 파일 미리보기:
이 예제에서는:
- Workbook()은 이미 세 개의 기본 워크시트를 포함하는 새 Excel 통합 문서를 만듭니다.
- 첫 번째 워크시트는 Worksheets[0]을 통해 액세스하고 기본 구조를 정의하기 위해 이름을 바꿉니다.
- Range[].Text 속성은 특정 셀에 텍스트를 써서 실제 데이터를 추가하기 전에 제목이나 자리 표시자를 설정할 수 있습니다.
- SaveToFile() 메서드는 통합 문서를 Excel 파일에 저장합니다. 그리고 FileFormat.Version2016은 사용할 Excel 버전 또는 형식을 지정합니다.
Python에서 여러 워크시트가 있는 Excel 파일 만들기
Python 기반 Excel 생성에서 단일 통합 문서는 관련 데이터를 논리적으로 구성하기 위해 여러 워크시트를 포함할 수 있습니다. 각 워크시트는 동일한 파일 내에 다른 데이터 세트, 요약 또는 처리 결과를 저장할 수 있습니다.
다음 예제는 여러 워크시트가 있는 Excel 파일을 만들고 각 워크시트에 데이터를 쓰는 방법을 보여줍니다.
from spire.xls import Workbook, FileFormat
workbook = Workbook()
# Default worksheet
data_sheet = workbook.Worksheets[0]
data_sheet.Name = "Raw Data"
# Remove the second default worksheet
workbook.Worksheets.RemoveAt(1)
# Add a summary worksheet
summary_sheet = workbook.Worksheets.Add("Summary")
summary_sheet.Range["A1"].Text = "Summary Report"
workbook.SaveToFile("multi_sheet_report.xlsx", FileFormat.Version2016)
workbook.Dispose()
이 패턴은 일반적으로 읽기/쓰기 워크플로와 결합되며, 원시 데이터는 한 워크시트로 가져오고 처리된 결과는 다른 워크시트에 씁니다.
Python 자동화의 Excel 파일 형식
Python에서 프로그래밍 방식으로 Excel 파일을 만들 때 XLSX는 가장 일반적으로 사용되는 형식이며 최신 버전의 Microsoft Excel에서 완벽하게 지원됩니다. 워크시트, 수식, 스타일을 지원하며 대부분의 자동화 시나리오에 적합합니다.
XLSX 외에도 Spire.XLS for Python은 다음을 포함하여 몇 가지 일반적인 Excel 형식 생성을 지원합니다.
- XLSX – 최신 Excel 자동화를 위한 기본 형식
- XLS – 이전 시스템과의 호환성을 위한 레거시 Excel 형식
- CSV – 데이터 교환 및 가져오기에 자주 사용되는 일반 텍스트 형식
이 문서의 모든 예제에서는 보고서 생성, 구조화된 데이터 내보내기 및 템플릿 기반 Excel 파일에 권장되는 XLSX 형식을 사용합니다. 지원되는 형식의 전체 목록은 FileFormat 열거형을 확인할 수 있습니다.
4. Python을 사용하여 구조화된 데이터를 XLSX 파일에 쓰기
실제 애플리케이션에서 Excel에 쓰는 데이터는 하드 코딩된 목록에서 거의 오지 않습니다. 데이터베이스 쿼리, API 응답 또는 중간 처리 결과에서 더 일반적으로 생성됩니다.
일반적인 패턴은 Excel을 이미 구조화된 데이터의 최종 전달 형식으로 처리하는 것입니다.
Python 예: 애플리케이션 데이터에서 월간 판매 보고서 생성
애플리케이션이 이미 각 레코드에 제품 정보와 계산된 합계가 포함된 판매 레코드 목록을 생성했다고 가정합니다. 이 예에서 판매 데이터는 애플리케이션 또는 서비스 계층에서 반환된 레코드를 시뮬레이션하는 사전 목록으로 표시됩니다.
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Name = "Sales Report"
headers = ["Product", "Quantity", "Unit Price", "Total Amount"]
for col, header in enumerate(headers, start=1):
sheet.Range[1, col].Text = header
# Data typically comes from a database or service layer
sales_data = [
{"product": "Laptop", "qty": 15, "price": 1200},
{"product": "Monitor", "qty": 30, "price": 250},
{"product": "Keyboard", "qty": 50, "price": 40},
{"product": "Mouse", "qty": 80, "price": 20},
{"product": "Headset", "qty": 100, "price": 10}
]
row = 2
for item in sales_data:
sheet.Range[row, 1].Text = item["product"]
sheet.Range[row, 2].NumberValue = item["qty"]
sheet.Range[row, 3].NumberValue = item["price"]
sheet.Range[row, 4].NumberValue = item["qty"] * item["price"]
row += 1
workbook.SaveToFile("monthly_sales_report.xlsx")
workbook.Dispose()
월간 판매 보고서 미리보기:

이 예에서 제품 이름과 같은 텍스트 값은 CellRange.Text 속성을 사용하여 작성되고 숫자 필드는 CellRange.NumberValue를 사용합니다. 이렇게 하면 수량과 가격이 Excel에 숫자로 저장되어 적절한 계산, 정렬 및 서식이 가능합니다.
이 접근 방식은 데이터 세트가 커짐에 따라 자연스럽게 확장되며 비즈니스 로직을 Excel 출력 로직과 분리합니다. 더 많은 Excel 쓰기 예제는 Python에서 Excel 쓰기를 자동화하는 방법을 참조하십시오.
5. Python에서 실제 보고서를 위한 Excel 데이터 서식 지정
실제 보고에서 Excel 파일은 종종 이해 관계자에게 직접 전달됩니다. 서식이 없는 원시 데이터는 읽거나 해석하기 어려울 수 있습니다.
일반적인 서식 지정 작업은 다음과 같습니다.
- 머리글 행을 시각적으로 구별되게 만들기
- 배경색 또는 테두리 적용
- 숫자 및 통화 서식 지정
- 열 너비 자동 조정
다음 예제는 이러한 일반적인 서식 지정 작업을 함께 적용하여 생성된 Excel 보고서의 전반적인 가독성을 향상시키는 방법을 보여줍니다.
Python 예: Excel 보고서 가독성 향상
from spire.xls import Workbook, Color, LineStyleType
# Load the created Excel file
workbook = Workbook()
workbook.LoadFromFile("monthly_sales_report.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Format header row
header_range = sheet.Range.Rows[0] # Get the first used row
header_range.Style.Font.IsBold = True
header_range.Style.Color = Color.get_LightBlue()
# Apply currency format
sheet.Range["C2:D6"].NumberFormat = "$#,##0.00"
# Format data rows
for i in range(1, sheet.Range.Rows.Count):
if i % 2 == 0:
row_range = sheet.Range[i, 1, i, sheet.Range.Columns.Count]
row_range.Style.Color = Color.get_LightGreen()
else:
row_range = sheet.Range[i, 1, i, sheet.Range.Columns.Count]
row_range.Style.Color = Color.get_LightYellow()
# Add borders to data rows
sheet.Range["A2:D6"].BorderAround(LineStyleType.Medium, Color.get_LightBlue())
# Auto-fit column widths
sheet.AllocatedRange.AutoFitColumns()
# Save the formatted Excel file
workbook.SaveToFile("monthly_sales_report_formatted.xlsx")
workbook.Dispose()
서식이 지정된 월간 판매 보고서 미리보기:

서식은 데이터 정확성을 위해 엄격하게 요구되지는 않지만 공유되거나 보관되는 비즈니스 보고서에서는 종종 기대됩니다. 더 고급 서식 지정 기술은 Python으로 Excel 워크시트 서식을 지정하는 방법을 확인하십시오.
6. Python 자동화에서 기존 Excel 파일 읽기 및 업데이트
기존 Excel 파일을 업데이트하려면 일반적으로 새 값을 쓰기 전에 올바른 행을 찾아야 합니다. 자동화 스크립트는 고정된 셀을 업데이트하는 대신 종종 행을 스캔하여 일치하는 레코드를 찾고 조건부로 업데이트를 적용합니다.
Python 예: Excel 파일 업데이트
from spire.xls import Workbook
workbook = Workbook()
workbook.LoadFromFile("monthly_sales_report.xlsx")
sheet = workbook.Worksheets[0]
# Locate the target row by product name
for row in range(2, sheet.LastRow + 1):
product_name = sheet.Range[row, 1].Text
if product_name == "Laptop":
sheet.Range[row, 5].Text = "Reviewed"
break
sheet.Range["E1"].Text = "Status"
workbook.SaveToFile("monthly_sales_report_updated.xlsx")
workbook.Dispose()
업데이트된 월간 판매 보고서 미리보기:

7. 단일 워크플로에서 읽기 및 쓰기 작업 결합
가져온 Excel 파일로 작업할 때 원시 데이터는 종종 보고나 추가 분석에 즉시 적합하지 않습니다. 일반적인 문제에는 중복된 레코드, 일관성 없는 값 또는 불완전한 행이 포함됩니다.
이 섹션에서는 기존 Excel 데이터를 읽고 정규화한 다음 처리된 결과를 Python을 사용하여 새 파일에 쓰는 방법을 보여줍니다.
실제 자동화 시스템에서 Excel 파일은 최종 결과물이라기보다는 중간 데이터 전달자로 사용되는 경우가 많습니다.
외부 플랫폼에서 가져오거나, 다른 팀에서 수동으로 편집하거나, 추가 처리되기 전에 레거시 시스템에서 생성될 수 있습니다.
결과적으로 원시 Excel 데이터에는 다음과 같은 문제가 자주 포함됩니다.
- 동일한 비즈니스 엔터티에 대한 여러 행
- 일관성 없거나 숫자가 아닌 값
- 비어 있거나 불완전한 레코드
- 보고나 분석에 적합하지 않은 데이터 구조
일반적인 요구 사항은 정제되지 않은 Excel 데이터를 읽고 Python에서 정규화 규칙을 적용한 다음 정리된 결과를 다운스트림 사용자가 신뢰할 수 있는 새 워크시트에 쓰는 것입니다.
Python 예: 가져온 판매 데이터 정규화 및 집계
이 예에서 원시 판매 Excel 파일에는 제품당 여러 행이 포함되어 있습니다.
목표는 각 제품이 한 번만 나타나고 총 판매 금액이 프로그래밍 방식으로 계산되는 깨끗한 요약 워크시트를 생성하는 것입니다.
from spire.xls import Workbook, Color
workbook = Workbook()
workbook.LoadFromFile("raw_sales_data.xlsx")
source = workbook.Worksheets[0]
summary = workbook.Worksheets.Add("Summary")
# Define headers for the normalized output
summary.Range["A1"].Text = "Product"
summary.Range["B1"].Text = "Total Sales"
product_totals = {}
# Read raw data and aggregate values by product
for row in range(2, source.LastRow + 1):
product = source.Range[row, 1].Text
value = source.Range[row, 4].Value
# Skip incomplete or invalid rows
if not product or value is None:
continue
try:
amount = float(value)
except ValueError:
continue
if product not in product_totals:
product_totals[product] = 0
product_totals[product] += amount
# Write aggregated results to the summary worksheet
target_row = 2
for product, total in product_totals.items():
summary.Range[target_row, 1].Text = product
summary.Range[target_row, 2].NumberValue = total
target_row += 1
# Create a total row
summary.Range[summary.LastRow, 1].Text = "Total"
summary.Range[summary.LastRow, 2].Formula = "=SUM(B2:B" + str(summary.LastRow - 1) + ")"
# Format the summary worksheet
summary.Range.Style.Font.FontName = "Arial"
summary.Range[1, 1, 1, summary.LastColumn].Style.Font.Size = 12
summary.Range[1, 1, 1, summary.LastColumn].Style.Font.IsBold = True
for row in range(2, summary.LastRow + 1):
for column in range(1, summary.LastColumn + 1):
summary.Range[row, column].Style.Font.Size = 10
summary.Range[summary.LastRow, 1, summary.LastRow, summary.LastColumn].Style.Color = Color.get_LightGray()
summary.Range.AutoFitColumns()
workbook.SaveToFile("normalized_sales_summary.xlsx")
workbook.Dispose()
정규화된 판매 요약 미리보기:
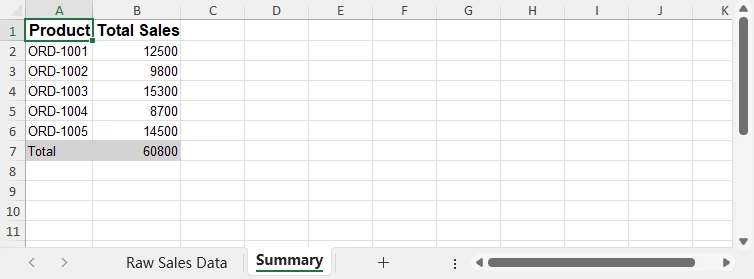
Python은 데이터 유효성 검사, 집계 및 정규화 로직을 처리하는 반면 Excel은 비즈니스 사용자를 위한 최종 전달 형식으로 남아 수동 정리나 복잡한 스프레드시트 수식이 필요하지 않습니다.
Excel 파일 생성을 위한 올바른 Python 접근 방식 선택
Python은 Excel 파일을 만드는 여러 가지 방법을 제공하며 최상의 접근 방식은 워크플로에서 Excel을 사용하는 방식에 따라 다릅니다.
Free Spire.XLS for Python은 다음과 같은 시나리오에 특히 적합합니다.
- Excel 파일이 Microsoft Excel이 설치되지 않은 상태에서 생성되거나 업데이트되는 경우
- 파일이 백엔드 서비스, 배치 작업 또는 예약된 작업에 의해 생성되는 경우
- 워크시트 구조, 서식 및 수식을 정밀하게 제어해야 하는 경우
- Excel이 대화형 분석 도구가 아닌 전달 또는 교환 형식으로 사용되는 경우
데이터 탐색 또는 통계 분석을 위해 Python 사용자는 다른 라이브러리를 업스트림으로 사용할 수 있으며, 최종 단계에서 구조화되고 프레젠테이션 준비가 된 파일을 생성하기 위해 Free Spire.XLS와 같은 Excel 생성 라이브러리를 사용할 수 있습니다.
이러한 분리는 데이터 처리 로직을 Python에, 프레젠테이션 로직을 Excel에 유지하여 유지 관리성과 안정성을 향상시킵니다.
자세한 지침과 예제는 Spire.XLS for Python 튜토리얼을 참조하십시오.
8. Python에서 Excel 파일을 만들고 쓸 때의 일반적인 문제
Excel 생성을 자동화할 때 몇 가지 실용적인 문제가 자주 발생합니다.
-
파일 경로 및 권한 오류
파일을 저장하기 전에 항상 대상 디렉터리가 존재하고 프로세스에 쓰기 액세스 권한이 있는지 확인하십시오.
-
예상치 못한 데이터 유형
Excel에서 계산 오류를 방지하기 위해 값이 텍스트로 작성되는지 숫자로 작성되는지 명시적으로 제어하십시오.
-
실수로 파일 덮어쓰기
기존 보고서를 덮어쓰지 않도록 타임스탬프가 있는 파일 이름이나 출력 디렉터리를 사용하십시오.
-
대규모 데이터 세트
대량의 데이터를 처리할 때는 행을 순차적으로 쓰고 루프 내에서 불필요한 서식 지정 작업을 피하십시오.
이러한 문제를 조기에 해결하면 데이터 크기와 복잡성이 증가함에 따라 Excel 자동화가 안정적으로 유지되도록 하는 데 도움이 됩니다.
9. 결론
Python에서 Excel 파일 만들기는 실제 비즈니스 환경에서 보고, 데이터 내보내기 및 문서 업데이트를 자동화하기 위한 실용적인 솔루션입니다. 파일 생성, 구조화된 데이터 쓰기, 서식 지정 및 업데이트 워크플로를 결합하여 Excel 자동화는 일회성 스크립트를 넘어 안정적인 시스템의 일부가 될 수 있습니다.
Spire.XLS for Python은 자동화, 일관성 및 유지 관리성이 필수적인 환경에서 이러한 작업을 구현하는 신뢰할 수 있는 방법을 제공합니다. Excel 파일 처리에서 Python 자동화의 잠재력을 최대한 활용하려면 임시 라이선스를 적용할 수 있습니다.
FAQ: Python에서 Excel 파일 만들기
Python이 Microsoft Excel을 설치하지 않고 Excel 파일을 만들 수 있습니까?
예. Spire.XLS for Python과 같은 라이브러리는 Microsoft Excel과 독립적으로 작동하므로 서버, 클라우드 환경 및 자동화된 워크플로에 적합합니다.
Python이 대용량 Excel 파일을 생성하는 데 적합합니까?
Python은 데이터가 순차적으로 작성되고 루프 내에서 불필요한 서식 지정 작업을 피하는 경우 대용량 Excel 파일을 효과적으로 생성할 수 있습니다.
기존 Excel 파일을 덮어쓰지 않으려면 어떻게 해야 합니까?
일반적인 접근 방식은 생성된 Excel 보고서를 저장할 때 타임스탬프가 있는 파일 이름이나 전용 출력 디렉터리를 사용하는 것입니다.
Python이 다른 시스템에서 만든 Excel 파일을 업데이트할 수 있습니까?
예. Python은 파일 형식이 지원되는 한 다른 애플리케이션에서 만든 Excel 파일을 읽고, 수정하고, 확장할 수 있습니다.