Os arquivos PDF são amplamente utilizados para compartilhar documentos porque preservam o layout e a formatação em todos os dispositivos. No entanto, alguns PDFs incluem permissões de segurança que impedem os usuários de copiar texto. Ao tentar selecionar ou copiar conteúdo desses arquivos, você pode ver que a cópia está desativada.
Este tipo de arquivo é frequentemente chamado de PDF seguro, protegido ou restrito. Ao contrário dos PDFs protegidos por senha que bloqueiam a abertura do arquivo, esses documentos ainda podem ser visualizados normalmente, mas certas ações, como copiar texto, são restritas.
Felizmente, existem várias soluções alternativas gratuitas e práticas que permitem extrair ou copiar texto de PDFs protegidos. Neste guia, exploraremos cinco métodos fáceis, incluindo ferramentas online, recursos integrados do sistema e uma abordagem de automação com Python.
Navegação Rápida
- Método 1 — Copiar texto de um PDF protegido usando o Google Docs
- Método 2 — Converter um PDF restrito para TXT online
- Método 3 — Captura de tela + OCR para extrair texto
- Método 4 — Imprimir um PDF protegido contra cópia para um novo PDF
- Método 5 — Extrair texto de um PDF protegido usando Python
Por que você não consegue copiar texto de alguns PDFs?
Muitos criadores de PDF aplicam restrições de permissão para controlar como o documento pode ser usado. Essas permissões são definidas nas configurações de segurança do PDF e podem desativar ações como:
- Copiar texto
- Editar o documento
- Imprimir o arquivo
- Adicionar anotações
Isso é frequentemente chamado de proteção contra cópia ou restrição de conteúdo. Embora o documento permaneça legível, o visualizador de PDF impede a seleção ou cópia de texto.
Essas restrições são normalmente usadas para proteger a propriedade intelectual ou impedir a reutilização não autorizada do conteúdo. No entanto, quando você precisa legitimamente reutilizar o texto — por exemplo, para pesquisa, documentação ou fins de acessibilidade — pode precisar de maneiras alternativas para extrair o conteúdo.
Abaixo estão cinco métodos que podem ajudar.
Método 1 — Copiar texto de um PDF protegido usando o Google Docs
Uma das maneiras mais simples de copiar texto de um PDF protegido é abri-lo com o Google Docs. Quando um PDF é carregado no Google Drive e aberto no Google Docs, o serviço converte automaticamente o arquivo em um documento editável.
Durante esse processo de conversão, o conteúdo do PDF é reinterpretado como texto e parágrafos, o que geralmente ignora as restrições básicas de cópia. Após a conclusão da conversão, você pode selecionar e copiar facilmente o texto como em um documento normal.
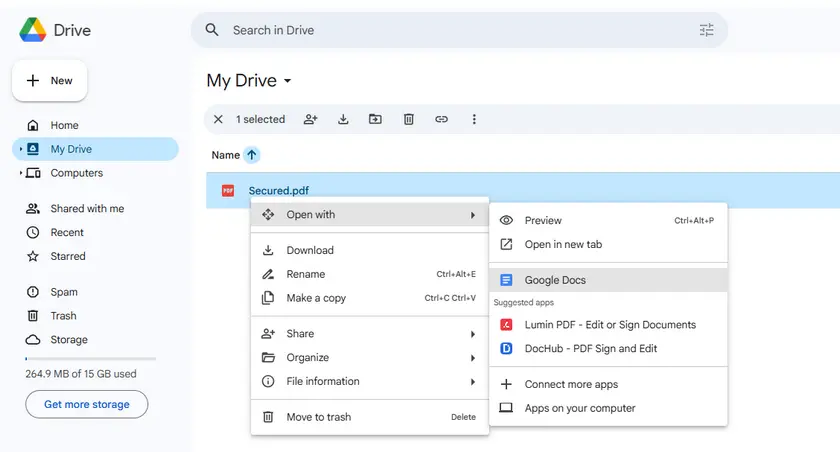
Passos
- Abra o Google Drive.
- Carregue o PDF protegido.
- Clique com o botão direito no arquivo e selecione Abrir com → Google Docs.
- O Google Docs converterá o PDF em um documento editável.
- Copie o texto extraído do documento.
Prós
- Gratuito e fácil de usar.
- Nenhuma instalação de software necessária.
- Funciona bem com documentos baseados em texto.
Limitações
- PDFs digitalizados/baseados em imagem não serão convertidos em texto (sem OCR).
- A formatação pode ficar bagunçada com layouts complexos.
- Requer uma conta do Google e conexão com a internet.
Método 2 — Converter um PDF restrito para TXT online
Outra solução rápida é converter o PDF restrito em um arquivo de texto simples usando um conversor online. Uma vez que o documento é convertido para o formato TXT, o texto se torna totalmente editável e pode ser copiado sem restrições.
Uma ferramenta gratuita conveniente para esse fim é o PDF24 Tools, que fornece um conversor de PDF para TXT baseado em navegador. Este método funciona bem quando você precisa extrair texto rapidamente sem instalar software adicional.
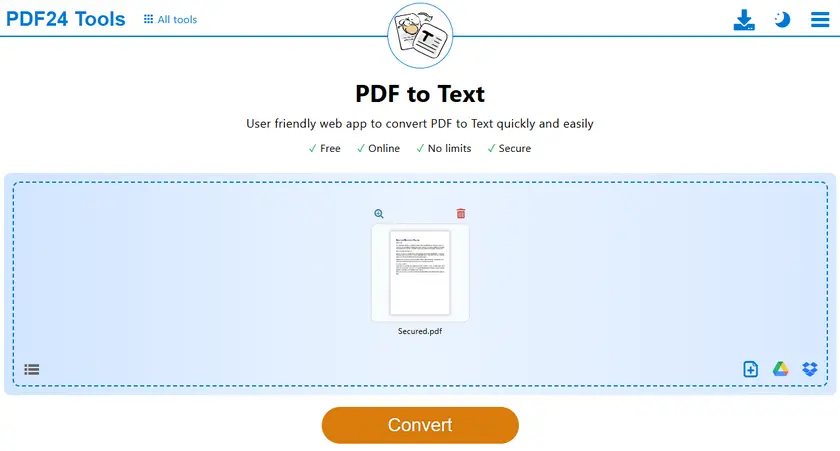
Passos
- Abra a ferramenta PDF para TXT.
- Carregue seu arquivo PDF protegido.
- Inicie o processo de conversão.
- Baixe o arquivo TXT gerado.
- Abra o arquivo TXT e copie o texto livremente.
Prós
- Fluxo de trabalho rápido e simples.
- Nenhuma instalação necessária.
Limitações
- Risco de privacidade — documentos confidenciais são carregados para servidores de terceiros.
- Muitas vezes limitado a algumas conversões gratuitas por dia.
- Sem suporte a OCR na maioria das ferramentas gratuitas (PDFs baseados em imagem não funcionarão).
Método 3 — Captura de tela + OCR para extrair texto
Se o PDF tiver fortes restrições de cópia ou contiver páginas digitalizadas, o OCR (Reconhecimento Óptico de Caracteres) ainda pode recuperar o texto visível. A tecnologia OCR analisa a imagem do documento e converte os caracteres detectados em texto editável.
O Windows 11 inclui um recurso de OCR integrado na Ferramenta de Recorte, permitindo que você capture parte da tela e extraia instantaneamente o texto da imagem.
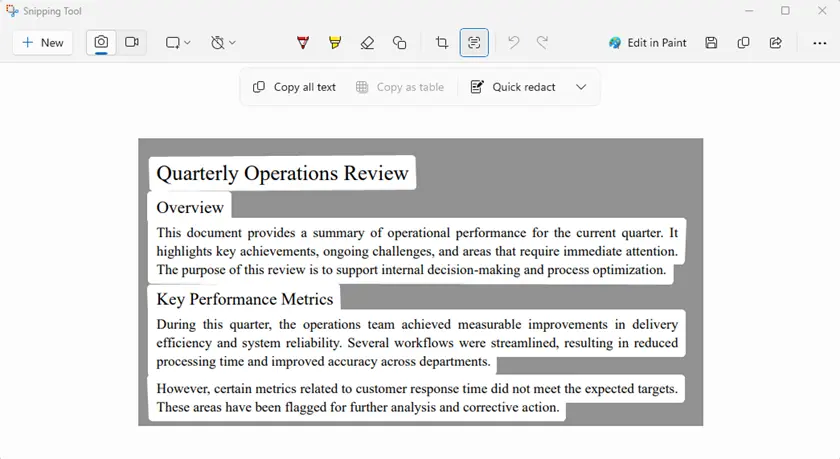
Passos
- Abra o PDF protegido na sua tela.
- Inicie a Ferramenta de Recorte.
- Capture a área que contém o texto.
- Use Ações de Texto → Copiar todo o texto.
- Cole o texto extraído em um documento.
Prós
- Ignora quase toda a proteção contra cópia, pois captura a tela.
- Funciona com PDFs digitalizados/baseados em imagem.
Limitações
- Demorado se houver muitas páginas.
- Erros de OCR — a precisão depende da qualidade da imagem e da fonte.
- Processo manual, a menos que automatizado com scripts.
Método 4 — Imprimir um PDF protegido contra cópia para um novo PDF
Alguns PDFs protegidos bloqueiam a cópia, mas ainda permitem a impressão. Nesses casos, você pode imprimir o documento em um novo arquivo PDF, o que pode remover a restrição de cópia.
Isso pode ser feito facilmente usando o recurso de impressão integrado no Google Chrome. Depois de salvar a versão impressa do arquivo, o novo PDF pode permitir a seleção e cópia normal de texto.
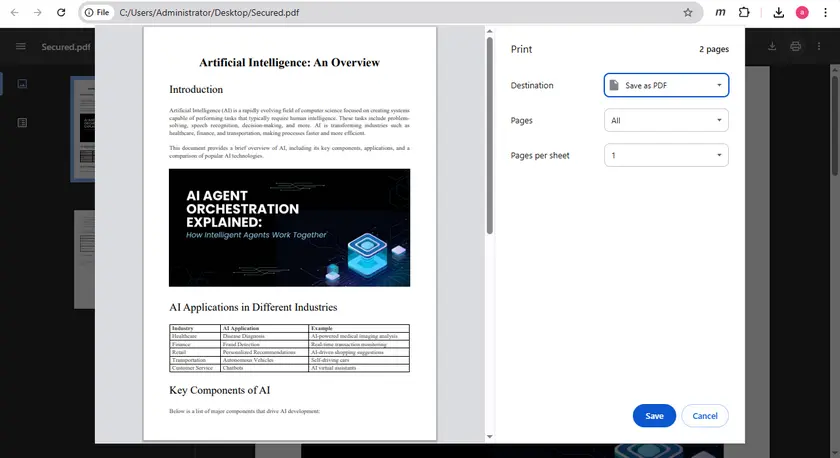
Passos
- Abra o PDF no Google Chrome.
- Pressione Ctrl + P para abrir a caixa de diálogo de impressão.
- Defina o destino como Salvar como PDF.
- Salve o PDF recém-gerado.
- Abra o novo arquivo e tente copiar o texto.
Prós
- Solução alternativa simples.
- Nenhuma ferramenta adicional necessária.
Limitações
- Se a impressão estiver desativada nas permissões do PDF, isso não funcionará.
- Algumas diferenças de formatação podem aparecer.
Método 5 — Extrair texto de um PDF protegido usando Python
Para desenvolvedores ou usuários que precisam processar vários documentos, extrair texto programaticamente pode ser a solução mais eficiente. Em vez de copiar o conteúdo manualmente, um script pode ler automaticamente a estrutura do PDF e recuperar o texto de cada página.
Usando o Free Spire.PDF for Python, você pode extrair facilmente texto de documentos PDF com apenas algumas linhas de código. Essa abordagem é particularmente útil para automação, processamento em lote ou criação de fluxos de trabalho de processamento de documentos.
Se você estiver trabalhando com documentos pequenos (até 10 páginas por documento) ou testando fluxos de trabalho de extração, a versão gratuita funciona bem. Para arquivos maiores, você pode dividir o documento primeiro ou usar a versão completa.
Instale a biblioteca
pip install spire.pdf.free
Exemplo: Extrair texto de cada página
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Secured.pdf")
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Create a PdfTextExtractor object
textExtractor = PdfTextExtractor(page)
# Create a PdfTextExtractOptions object
extractOptions = PdfTextExtractOptions()
# Set IsExtractAllText to True
extractOptions.IsExtractAllText = True
# Extract text from the page keeping white spaces
text = textExtractor.ExtractText(extractOptions)
# Write text to a txt file
with open('output/TextOfPage-{}.txt'.format(i + 1), 'w', encoding='utf-8') as file:
lines = text.split("\n")
for line in lines:
if line != '':
file.write(line)
doc.Close()
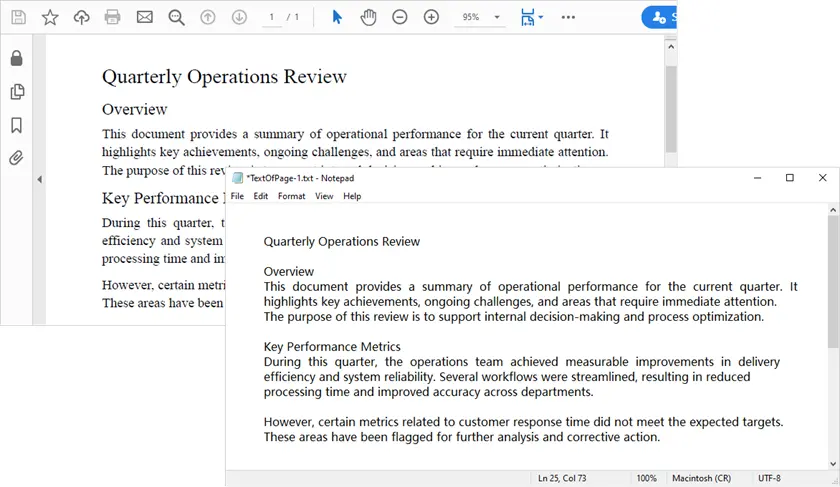
O que este script faz
- Carrega o documento PDF.
- Itera através de cada página.
- Extrai texto preservando os espaços em branco.
- Salva o texto extraído em arquivos TXT.
Prós
- Controle total sobre o processo de extração.
- Pode ser automatizado para processamento em lote.
- Funciona bem com PDFs baseados em texto.
Limitações
- Requer conhecimento de programação.
- Não pode lidar com PDFs baseados em imagem, a menos que uma biblioteca de OCR adicional seja usada.
Você também pode gostar: Realizar OCR em PDF com Python (Extrair texto de PDF digitalizado)
Tabela de comparação: Qual método você deve escolher?
| Método | Nível de Habilidade | Facilidade de uso | Melhor para | Funciona com PDFs digitalizados | Funciona sob fortes restrições | Processamento em lote |
|---|---|---|---|---|---|---|
| Google Docs | Iniciante | Muito fácil | Extração rápida no navegador | Não | Sim | Não |
| Conversor Online | Iniciante | Muito fácil | Conversão rápida para TXT | Não | Sim | Não |
| Captura de tela + OCR | Iniciante | Fácil | PDFs digitalizados ou baseados em imagem | Sim | Sim | Não |
| Imprimir para PDF | Iniciante | Fácil | Removendo restrições simples | Não | Condicional (a impressão deve ser permitida) | Não |
| Python (Spire.PDF) | Desenvolvedor | Moderado | Automação e fluxos de trabalho em lote | Depende de bibliotecas de OCR extras | Sim | Sim |
Conclusão
As restrições de cópia em PDFs podem ser frustrantes, especialmente quando você só precisa reutilizar uma parte do texto. Felizmente, vários métodos gratuitos podem ajudar a extrair conteúdo de PDFs protegidos.
Para tarefas rápidas, ferramentas como o Google Docs ou conversores online podem ser a solução mais fácil. Se o documento contiver conteúdo digitalizado ou restrições rígidas, os métodos baseados em OCR ainda podem recuperar o texto. Para fluxos de trabalho em grande escala ou cenários de automação, o uso de bibliotecas Python, como o Free Spire.PDF for Python, oferece uma abordagem poderosa e flexível.
Ao escolher o método que melhor se adapta às suas necessidades, você pode recuperar eficientemente o texto de PDFs restritos, mantendo um fluxo de trabalho eficiente.
FAQs (Perguntas Frequentes)
P1: O que é um PDF seguro ou restrito?
Um PDF protegido ou restrito é um documento que pode ser aberto e visualizado normalmente, mas possui configurações de segurança que impedem a cópia, impressão ou edição de seu conteúdo. Essas permissões são definidas pelo proprietário do documento.
P2: Posso copiar texto de todos os PDFs protegidos?
Nem sempre. Alguns PDFs possuem criptografia forte ou DRM que impede totalmente a cópia. Nesses casos, ferramentas de OCR ou bibliotecas profissionais podem ser necessárias.
P3: Qual é o melhor método para PDFs digitalizados?
Para PDFs digitalizados, a extração por captura de tela + OCR ou a automação com Python com bibliotecas de OCR geralmente é a maneira mais confiável de recuperar o texto.
P4: Posso automatizar a extração de texto para vários PDFs?
Sim. Usando bibliotecas Python como o Spire.PDF, você pode extrair texto de vários arquivos PDF automaticamente, tornando-o ideal para processamento em lote ou automação de fluxo de trabalho.
P5: Preciso pagar por algum desses métodos?
Todos os métodos listados no artigo são de uso gratuito. No entanto, algumas ferramentas (como o Spire.PDF) têm versões gratuitas com limitações, como uma restrição de contagem de páginas. Para arquivos maiores, você pode precisar da versão completa.