Файлы PDF широко используются для обмена документами, поскольку они сохраняют макет и форматирование на разных устройствах. Однако некоторые PDF-файлы содержат разрешения безопасности, которые запрещают пользователям копировать текст. При попытке выделить или скопировать содержимое из этих файлов вы можете увидеть, что копирование отключено.
Этот тип файлов часто называют защищенным, охраняемым или ограниченным PDF. В отличие от PDF-файлов, защищенных паролем, которые блокируют открытие файла, эти документы можно просматривать в обычном режиме, но некоторые действия, такие как копирование текста, ограничены.
К счастью, существует несколько бесплатных и практичных обходных путей, которые позволяют извлекать или копировать текст из защищенных PDF-файлов. В этом руководстве мы рассмотрим пять простых методов, включая онлайн-инструменты, встроенные системные функции и подход с использованием автоматизации на Python.
Быстрая навигация
- Метод 1 — Копирование текста из защищенного PDF с помощью Google Docs
- Метод 2 — Преобразование ограниченного PDF в TXT онлайн
- Метод 3 — Скриншот + OCR для извлечения текста
- Метод 4 — Печать защищенного от копирования PDF в новый PDF
- Метод 5 — Извлечение текста из защищенного PDF с помощью Python
Почему нельзя скопировать текст из некоторых PDF-файлов?
Многие создатели PDF применяют ограничения разрешений, чтобы контролировать, как можно использовать документ. Эти разрешения устанавливаются в настройках безопасности PDF и могут отключать такие действия, как:
- Копирование текста
- Редактирование документа
- Печать файла
- Добавление аннотаций
Это часто называют защитой от копирования или ограничением содержимого. Хотя документ остается читаемым, программа для просмотра PDF предотвращает выделение или копирование текста.
Эти ограничения обычно используются для защиты интеллектуальной собственности или предотвращения несанкционированного повторного использования контента. Однако, когда вам законно необходимо повторно использовать текст — например, для исследований, документации или для целей доступности — вам могут понадобиться альтернативные способы извлечения содержимого.
Ниже приведены пять методов, которые могут помочь.
Метод 1 — Копирование текста из защищенного PDF с помощью Google Docs
Один из самых простых способов скопировать текст из защищенного PDF — открыть его с помощью Google Docs. Когда PDF-файл загружается на Google Диск и открывается в Google Docs, сервис автоматически преобразует файл в редактируемый документ.
В процессе этого преобразования содержимое PDF переинтерпретируется как текст и абзацы, что часто обходит основные ограничения на копирование. После завершения преобразования вы можете легко выделить и скопировать текст, как в обычном документе.
Шаги
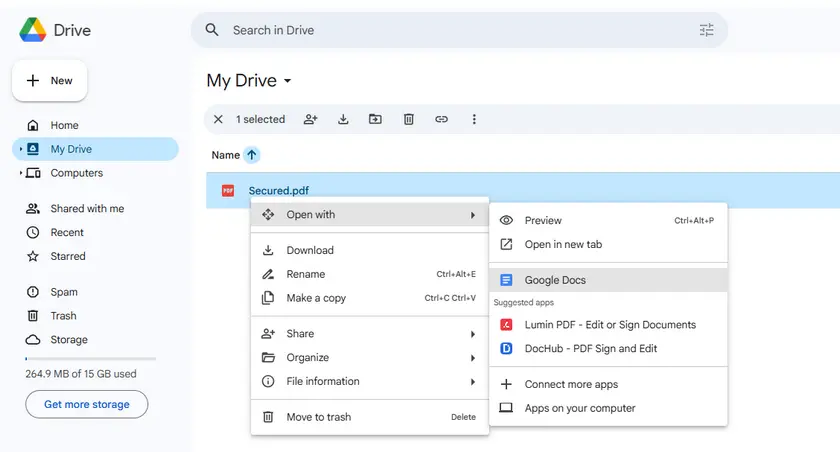
- Откройте Google Диск.
- Загрузите защищенный PDF.
- Щелкните файл правой кнопкой мыши и выберите Открыть с помощью → Google Docs.
- Google Docs преобразует PDF в редактируемый документ.
- Скопируйте извлеченный текст из документа.
Плюсы
- Бесплатно и просто в использовании.
- Не требуется установка программного обеспечения.
- Хорошо работает с текстовыми документами.
Ограничения
- Отсканированные/основанные на изображениях PDF-файлы не будут преобразованы в текст (нет OCR).
- Форматирование может нарушиться при сложных макетах.
- Требуется учетная запись Google и подключение к Интернету.
Метод 2 — Преобразование ограниченного PDF в TXT онлайн
Еще одно быстрое решение — преобразовать ограниченный PDF в обычный текстовый файл с помощью онлайн-конвертера. После преобразования документа в формат TXT текст становится полностью редактируемым и его можно копировать без ограничений.
Удобным бесплатным инструментом для этой цели является PDF24 Tools, который предоставляет браузерный конвертер PDF в TXT. Этот метод хорошо работает, когда вам нужно быстро извлечь текст без установки дополнительного программного обеспечения.
Шаги
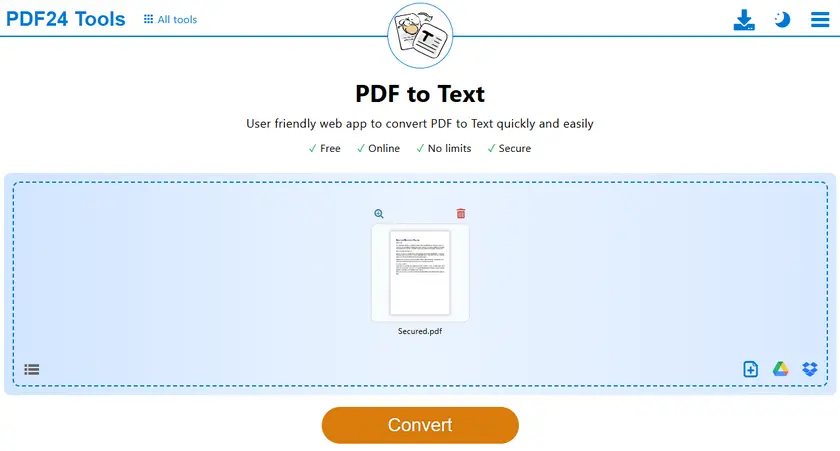
- Откройте инструмент PDF-в-TXT.
- Загрузите ваш защищенный PDF-файл.
- Начните процесс преобразования.
- Загрузите сгенерированный TXT-файл.
- Откройте TXT-файл и свободно копируйте текст.
Плюсы
- Быстрый и простой рабочий процесс.
- Не требуется установка.
Ограничения
- Риск конфиденциальности — конфиденциальные документы загружаются на сторонние серверы.
- Часто ограничено несколькими бесплатными преобразованиями в день.
- В большинстве бесплатных инструментов нет поддержки OCR (PDF-файлы на основе изображений не будут работать).
Метод 3 — Скриншот + OCR для извлечения текста
Если в PDF установлены строгие ограничения на копирование или он содержит отсканированные страницы, OCR (оптическое распознавание символов) все равно может извлечь видимый текст. Технология OCR анализирует изображение документа и преобразует обнаруженные символы в редактируемый текст.
Windows 11 включает встроенную функцию OCR в инструменте "Ножницы", что позволяет захватывать часть экрана и мгновенно извлекать текст из изображения.
Шаги
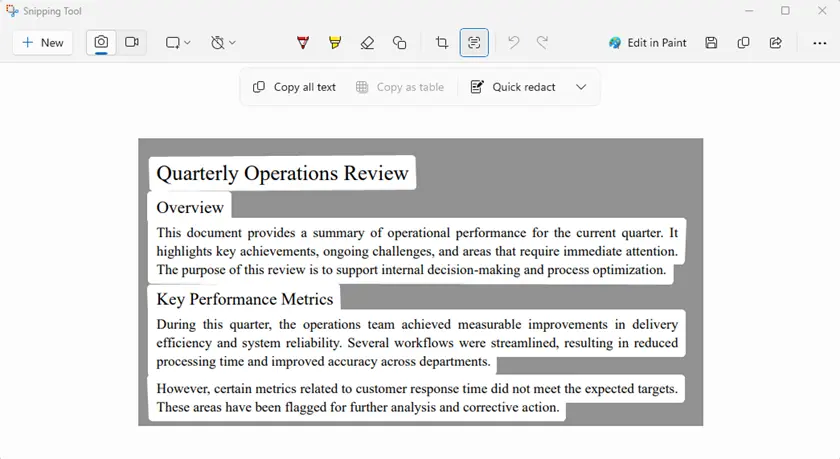
- Откройте защищенный PDF на вашем экране.
- Запустите инструмент "Ножницы".
- Захватите область, содержащую текст.
- Используйте Действия с текстом → Копировать весь текст.
- Вставьте извлеченный текст в документ.
Плюсы
- Обходит почти всю защиту от копирования, так как захватывает экран.
- Работает с отсканированными/основанными на изображениях PDF-файлами.
Ограничения
- Занимает много времени, если страниц много.
- Ошибки OCR — точность зависит от качества изображения и шрифта.
- Ручной процесс, если не автоматизирован с помощью скриптов.
Метод 4 — Печать защищенного от копирования PDF в новый PDF
Некоторые защищенные PDF-файлы блокируют копирование, но разрешают печать. В таких случаях вы можете распечатать документ в новый PDF-файл, что может снять ограничение на копирование.
Это можно легко сделать с помощью встроенной функции печати в Google Chrome. После сохранения распечатанной версии файла новый PDF может разрешить обычное выделение и копирование текста.
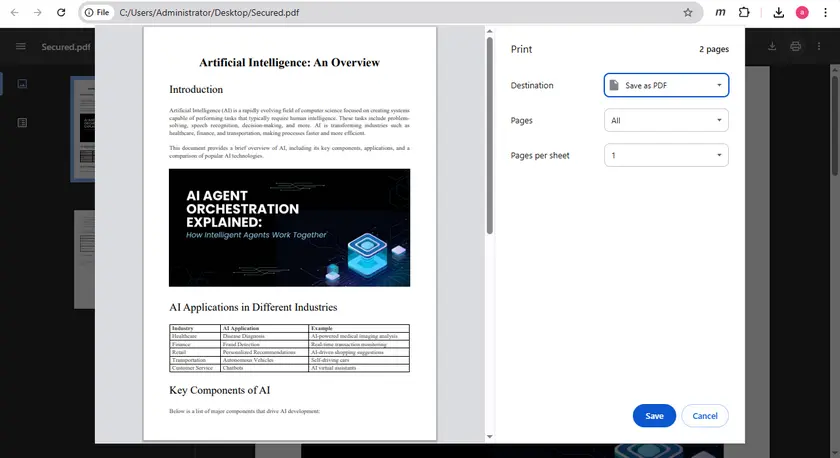
Шаги
- Откройте PDF в Google Chrome.
- Нажмите Ctrl + P, чтобы открыть диалоговое окно печати.
- Установите место назначения как Сохранить как PDF.
- Сохраните вновь созданный PDF.
- Откройте новый файл и попробуйте скопировать текст.
Плюсы
- Простой обходной путь.
- Не требуется дополнительных инструментов.
Ограничения
- Если печать отключена в разрешениях PDF, это не сработает.
- Могут появиться некоторые различия в форматировании.
Метод 5 — Извлечение текста из защищенного PDF с помощью Python
Для разработчиков или пользователей, которым необходимо обрабатывать несколько документов, программное извлечение текста может быть наиболее эффективным решением. Вместо ручного копирования содержимого скрипт может автоматически считывать структуру PDF и извлекать текст с каждой страницы.
Используя Free Spire.PDF for Python, вы можете легко извлекать текст из PDF-документов всего несколькими строками кода. Этот подход особенно полезен для автоматизации, пакетной обработки или создания рабочих процессов обработки документов.
Если вы работаете с небольшими документами (до 10 страниц на документ) или тестируете рабочие процессы извлечения, бесплатная версия работает хорошо. Для больших файлов вы можете либо разделить документ сначала, либо использовать полную версию.
Установите библиотеку
pip install spire.pdf.free
Пример: извлечение текста с каждой страницы
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("Secured.pdf")
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages[i]
# Create a PdfTextExtractor object
textExtractor = PdfTextExtractor(page)
# Create a PdfTextExtractOptions object
extractOptions = PdfTextExtractOptions()
# Set IsExtractAllText to True
extractOptions.IsExtractAllText = True
# Extract text from the page keeping white spaces
text = textExtractor.ExtractText(extractOptions)
# Write text to a txt file
with open('output/TextOfPage-{}.txt'.format(i + 1), 'w', encoding='utf-8') as file:
lines = text.split("\n")
for line in lines:
if line != '':
file.write(line)
doc.Close()
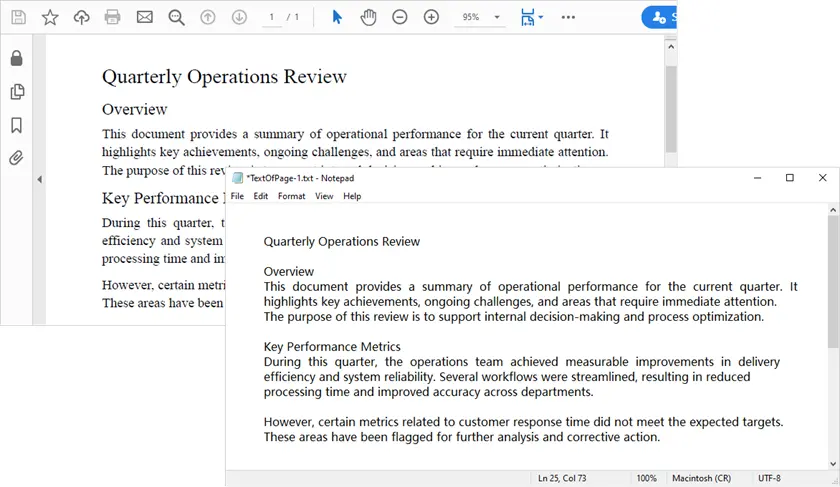
Что делает этот скрипт
- Загружает PDF-документ.
- Проходит по каждой странице.
- Извлекает текст, сохраняя пробелы.
- Сохраняет извлеченный текст в TXT-файлы.
Плюсы
- Полный контроль над процессом извлечения.
- Может быть автоматизирован для пакетной обработки.
- Хорошо работает с текстовыми PDF-файлами.
Ограничения
- Требуются знания в области программирования.
- Не может обрабатывать PDF-файлы на основе изображений, если не используется дополнительная библиотека OCR.
Вам также может понравиться: Выполнение OCR PDF с помощью Python (извлечение текста из отсканированного PDF)
Сравнительная таблица: какой метод выбрать?
| Метод | Уровень навыков | Простота использования | Лучше всего для | Работает с отсканированными PDF | Работает при строгих ограничениях | Пакетная обработка |
|---|---|---|---|---|---|---|
| Google Docs | Начинающий | Очень просто | Быстрое извлечение в браузере | Нет | Да | Нет |
| Онлайн-конвертер | Начинающий | Очень просто | Быстрое преобразование в TXT | Нет | Да | Нет |
| Скриншот + OCR | Начинающий | Просто | Отсканированные или основанные на изображениях PDF | Да | Да | Нет |
| Печать в PDF | Начинающий | Просто | Снятие простых ограничений | Нет | Условно (печать должна быть разрешена) | Нет |
| Python (Spire.PDF) | Разработчик | Умеренно | Автоматизация и пакетные рабочие процессы | Зависит от дополнительных библиотек OCR | Да | Да |
Заключение
Ограничения на копирование в PDF-файлах могут вызывать разочарование, особенно когда вам нужно повторно использовать только часть текста. К счастью, несколько бесплатных методов могут помочь извлечь содержимое из защищенных PDF-файлов.
Для быстрых задач инструменты, такие как Google Docs или онлайн-конвертеры, могут быть самым простым решением. Если документ содержит отсканированное содержимое или строгие ограничения, методы на основе OCR все равно могут восстановить текст. Для крупномасштабных рабочих процессов или сценариев автоматизации использование библиотек Python, таких как Free Spire.PDF for Python, предоставляет мощный и гибкий подход.
Выбрав метод, который наилучшим образом соответствует вашим потребностям, вы можете эффективно извлекать текст из ограниченных PDF-файлов, поддерживая при этом эффективный рабочий процесс.
Часто задаваемые вопросы (FAQ)
В1: Что такое защищенный или ограниченный PDF?
Защищенный или ограниченный PDF — это документ, который можно открывать и просматривать в обычном режиме, но в котором установлены параметры безопасности, запрещающие копирование, печать или редактирование его содержимого. Эти разрешения устанавливаются владельцем документа.
В2: Могу ли я копировать текст из всех защищенных PDF-файлов?
Не всегда. Некоторые PDF-файлы имеют сильное шифрование или DRM, которые полностью предотвращают копирование. В таких случаях могут потребоваться инструменты OCR или профессиональные библиотеки.
В3: Какой метод лучше всего подходит для отсканированных PDF-файлов?
Для отсканированных PDF-файлов извлечение с помощью скриншота + OCR или автоматизация на Python с библиотеками OCR обычно является самым надежным способом извлечения текста.
В4: Могу ли я автоматизировать извлечение текста для нескольких PDF-файлов?
Да. Используя библиотеки Python, такие как Spire.PDF, вы можете автоматически извлекать текст из нескольких PDF-файлов, что делает его идеальным для пакетной обработки или автоматизации рабочих процессов.
В5: Нужно ли мне платить за какой-либо из этих методов?
Все методы, перечисленные в статье, бесплатны для использования. Однако некоторые инструменты (например, Spire.PDF) имеют бесплатные версии с ограничениями, такими как ограничение на количество страниц. Для больших файлов вам может понадобиться полная версия.