
Spire.XLS for Python (113)
How to Convert Excel to Markdown in Python (Files, Sheets & Ranges)
2026-06-08 07:16:12 Written by alice yang
Excel files are commonly used to store structured data, while Markdown is widely used in technical documentation, static websites, and Git-based publishing workflows. When you need to reuse spreadsheet data in Markdown documents, manually copying and reformatting Excel tables can be time-consuming and error-prone. A more reliable approach is to automate the conversion with Python.
This tutorial demonstrates how to convert Excel to Markdown in Python using Spire.XLS for Python. You will learn how to convert entire workbooks, export specific sheets or cell ranges, as well as batch processing with simple code examples.
In This Article
- Why Convert Excel to Markdown?
- Install Python Excel to Markdown Library
- Basic Excel to Markdown Conversion in Python
- Advanced Excel to Markdown Conversion Scenarios
- Best Practices for Converting Excel to Markdown
- Conclusion
- FAQs
Why Convert Excel to Markdown?
Converting Excel tables to Markdown can be useful in several scenarios:
- Create documentation: Add Excel tables to README files and wikis.
- Use with Git: Markdown is text-based and easier to track than Excel files.
- Publish online: Use Excel data in blogs or docs sites.
- Share data easily: Markdown tables are lightweight and widely compatible across platforms.
Install Python Excel to Markdown Library
To convert Excel files to Markdown in Python, install Spire.XLS for Python from PyPI:
pip install spire.xls
Markdown conversion is supported in Spire.XLS for Python 16.4.0 and later versions. If you are using an earlier version, upgrade the package first:
pip install --upgrade spire.xls
Basic Excel to Markdown Conversion in Python
The simplest way to convert an Excel file to Markdown is to load the workbook and save it as a .md file.
The process only requires three main steps:
- Create a Workbook object.
- Load the Excel file using the Workbook.LoadFromFile() method.
- Save the workbook as a Markdown file using the Workbook.SaveToMarkdown() method.
from spire.xls import Workbook
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("report.xlsx")
# Save the workbook as a Markdown file
workbook.SaveToMarkdown("output.md")
# Release resources
workbook.Dispose()
Output:
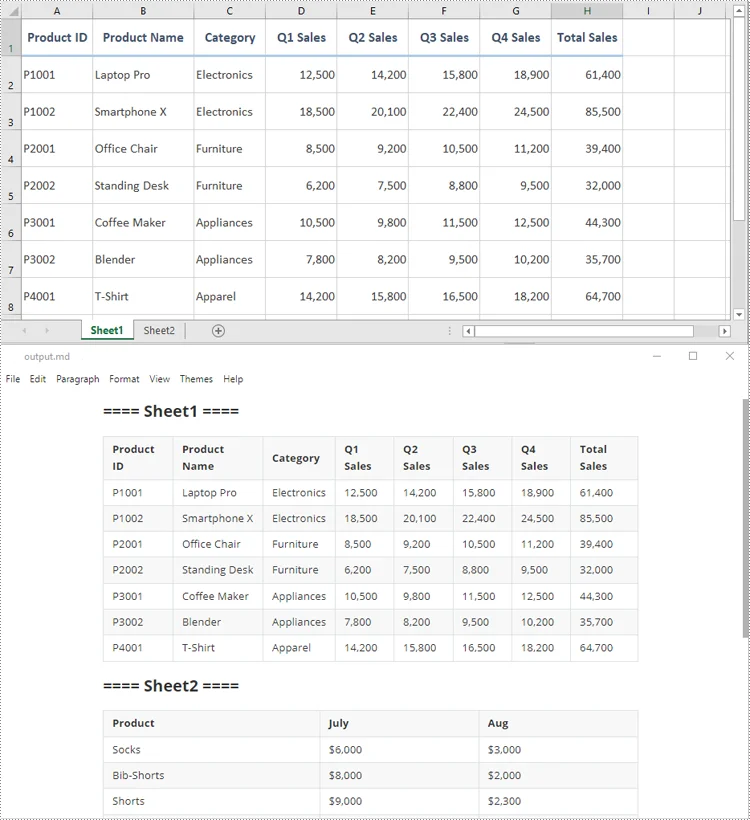
Advanced Excel to Markdown Conversion Scenarios
In many real-world projects, you may not always need to convert the entire workbook. You may want to customize how images and hyperlinks are exported, convert only one worksheet, export a selected range, or process a folder of Excel files automatically.
The following sections show how to implement these conversions in Python.
1. Customize Image and Hyperlink Export Options
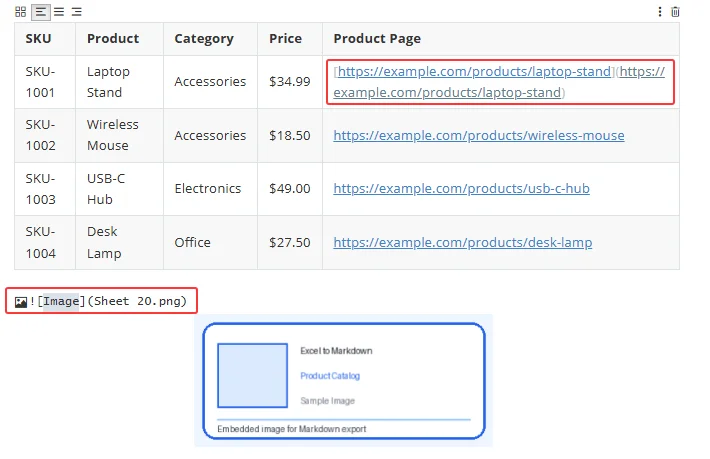
When exporting Excel to Markdown, images and hyperlinks are written as Markdown syntax. You can use the properties of the MarkdownOptions class to control how image paths and hyperlinks are saved in the output file.
| Property | When Set to True | When Set to False |
|---|---|---|
| SavePicInRelativePath | Images are saved with relative paths, such as  . |
Images are saved with absolute paths, such as  . |
| SaveHyperlinkAsRef | Hyperlinks are saved as reference-style links, such as [Link Text][ref1] . |
Hyperlinks are saved as inline links, such as [Link Text](https://example.com) . |
Using relative image paths is usually better for documentation projects because the Markdown file and image folder can be moved together. Inline links are often easier to read and maintain in smaller Markdown files.
The following example shows how to convert an Excel workbook to Markdown with custom image and hyperlink options:
from spire.xls import Workbook, MarkdownOptions
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("sample.xlsx")
# Create a MarkdownOptions object
markdown_options = MarkdownOptions()
# Save images with relative paths
markdown_options.SavePicInRelativePath = True
# Save hyperlinks as inline links
markdown_options.SaveHyperlinkAsRef = False
# Save the workbook as a Markdown file
workbook.SaveToMarkdown("custom_options.md", markdown_options)
# Release resources
workbook.Dispose()
Output:
2. Convert a Specific Sheet to Markdown
If an Excel workbook contains multiple worksheets, but you only need to export one sheet, you can copy the target worksheet to a new workbook with the AddCopy method, and then save that new workbook as a .md file.
This approach helps avoid exporting unnecessary sheets into the same Markdown document.
from spire.xls import Workbook
def convert_specific_sheet(excel_file, sheet_name, output_md):
"""
Convert a specific worksheet in an Excel file to Markdown.
"""
workbook = Workbook()
new_workbook = None
try:
# Load the Excel file
workbook.LoadFromFile(excel_file)
# Find the target worksheet by name
worksheet = None
for ws in workbook.Worksheets:
if ws.Name == sheet_name:
worksheet = ws
break
if worksheet is None:
print(f"Worksheet '{sheet_name}' was not found.")
return
# Create a new workbook that contains only the target worksheet
new_workbook = Workbook()
new_workbook.Worksheets.Clear()
new_workbook.Worksheets.AddCopy(worksheet)
# Save the new workbook as Markdown
new_workbook.SaveToMarkdown(output_md)
print(f"Worksheet '{sheet_name}' converted successfully to {output_md}.")
finally:
# Release resources
if new_workbook is not None:
new_workbook.Dispose()
workbook.Dispose()
# Usage
convert_specific_sheet("report.xlsx", "Sheet 1", "sheet1.md")
3. Export a Selected Cell Range to Markdown
Sometimes, you may only need to export part of a worksheet, such as a summary table, a data range, or a report section. In this case, you can copy the required cell range to a new workbook and save it as a Markdown file.
The following example converts a selected range from a specific worksheet to a Markdown file:
from spire.xls import Workbook, CopyRangeOptions
def convert_cell_range_to_markdown(excel_file, sheet_name, cell_range, output_md):
"""Convert a specific cell range from an Excel worksheet to Markdown.
Example cell range: "A1:C5"
"""
workbook = Workbook()
new_workbook = Workbook()
try:
# Load the original Excel file
workbook.LoadFromFile(excel_file)
# Get the target worksheet by name
worksheet = workbook.Worksheets[sheet_name]
if worksheet is None:
print(f"Worksheet '{sheet_name}' was not found.")
return
# Get the specific source cell range (e.g., "A1:C5")
src_range = worksheet.Range[cell_range]
# Initialize the new workbook with a single blank sheet
new_workbook.CreateEmptySheets(1)
new_sheet = new_workbook.Worksheets[0]
# Define the destination range starting at cell A1 in the new sheet.
# We use the row and column count of the source range to match the size perfectly.
dest_range = new_sheet.Range[
1, 1, src_range.Rows.Count, src_range.Columns.Count
]
# Copy ONLY the selected range (all data, formulas, and formatting)
src_range.Copy(dest_range, CopyRangeOptions.All)
# Save the new isolated workbook as Markdown
new_workbook.SaveToMarkdown(output_md)
print(
f"Cell range '{cell_range}' from worksheet '{sheet_name}' "
f"converted successfully to {output_md}."
)
except Exception as e:
print(f"An error occurred: {e}")
finally:
# Release resources
new_workbook.Dispose()
workbook.Dispose()
# Usage
convert_cell_range_to_markdown(
"report.xlsx", "Sheet 1", "A1:C5", "cell_range.md"
)
This method is useful when you want to reuse only the key part of a worksheet in documentation, instead of exporting the entire sheet.
4. Batch Convert Multiple Excel Files to Markdown
For large-scale conversion tasks, you can loop through a folder and convert all .xlsx and .xls files to Markdown automatically.
This is especially useful when you need to generate documentation from multiple reports, export datasets regularly, or integrate Excel-to-Markdown conversion into a publishing workflow.
from pathlib import Path
from spire.xls import Workbook
def batch_convert_excel_to_markdown(input_folder, output_folder):
"""
Convert all Excel files in a folder to Markdown files.
Supported formats: .xlsx and .xls
"""
input_dir = Path(input_folder)
output_dir = Path(output_folder)
# Create the output folder if it does not exist
output_dir.mkdir(parents=True, exist_ok=True)
# Supported Excel file extensions
excel_extensions = {".xlsx", ".xls"}
converted_count = 0
for input_file in input_dir.iterdir():
# Skip folders, temporary Excel files, and unsupported files
if not input_file.is_file():
continue
if input_file.name.startswith("~$"):
continue
if input_file.suffix.lower() not in excel_extensions:
continue
output_file = output_dir / f"{input_file.stem}.md"
workbook = Workbook()
try:
# Load the Excel file
workbook.LoadFromFile(str(input_file))
# Save as Markdown
workbook.SaveToMarkdown(str(output_file))
converted_count += 1
print(f"Converted: {input_file.name} -> {output_file.name}")
except Exception as e:
print(f"Failed to convert {input_file.name}: {e}")
finally:
workbook.Dispose()
print(f"\nBatch conversion complete. {converted_count} file(s) converted.")
# Usage
batch_convert_excel_to_markdown("./excel_files", "./markdown_output")
Best Practices for Converting Excel to Markdown
To get cleaner Markdown output, keep the following tips in mind:
- Use simple table structures whenever possible.
- Unmerge merged cells if the output is intended for Markdown tables.
- Remove unused rows and columns before conversion.
- Use relative image paths for portable documentation projects.
- Review the generated Markdown file before publishing it to GitHub, a wiki, or a static website.
Conclusion
Converting Excel to Markdown in Python with Spire.XLS for Python makes it easy to generate Markdown files from workbook data with minimal code. It is a practical solution for developers who need to add Excel data export to documentation, reporting, or publishing workflows.
FAQs
Q1: What Excel formats can be converted to Markdown?
A1: Common Excel formats such as .xlsx and .xls can be loaded and saved as Markdown files.
Q2: Are images preserved when converting Excel to Markdown?
A2: Yes. By default, images can be embedded in the Markdown output as Base64 strings. You can also configure the export options to save images with relative or absolute file paths.
Q3: Do I need Microsoft Office to convert Excel to Markdown in Python?
A3: No. Spire.XLS for Python works independently and does not require Microsoft Excel or Microsoft Office to be installed.
Get a Free License
To fully experience the capabilities of Spire.XLS for .NET without any evaluation limitations, you can request a free 30-day trial license.
See Also

Importing an Excel file in Python typically involves more than just reading the file. In most cases, the data needs to be converted into Python structures such as lists, dictionaries, or other formats that can be directly used in your application.
This transformation step is important because Excel data is usually stored in a tabular format, while Python applications often require structured data for processing, integration, or storage. Depending on how the data will be used, it may be represented as a list for sequential processing, a dictionary for field-based access, custom objects for structured modeling, or a database for persistent storage.
This guide demonstrates how to import Excel file in Python and convert the data into multiple structures using Spire.XLS for Python, with practical examples for each approach.
Overall Implementation Approach and Quick Example
Importing Excel data into Python is essentially a two-step process:
- Load Excel file – Load the Excel file and access its raw data
- Transform data – Convert the data into Python structures such as lists, dictionaries, or objects
This separation is important because in real-world applications, simply reading Excel is not enough—the data must be transformed into a format that can be processed, stored, or integrated into systems.
Key Components
When importing Excel data using Spire.XLS for Python, the following components are involved:
- Workbook – Represents the entire Excel file and is responsible for loading data from disk
- Worksheet – Represents a single sheet within the Excel file
- CellRange – Represents a group of cells that contain actual data
- Data Transformation Layer – Your Python logic that converts cell values into target structures
Data Flow Overview
The typical workflow looks like this:
Excel File → Workbook → Worksheet → CellRange → Python Data Structure
Understanding this pipeline helps you design flexible import logic for different scenarios.
Quick Example: Import Excel File in Python
Before running the example, install Spire.XLS for Python using pip:
pip install spire.xls
If needed, you can also download Spire.XLS for Python manually and include it in your project.
The following example shows the simplest way to import Excel data into Python:
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
data = []
sheet = workbook.Worksheets[0]
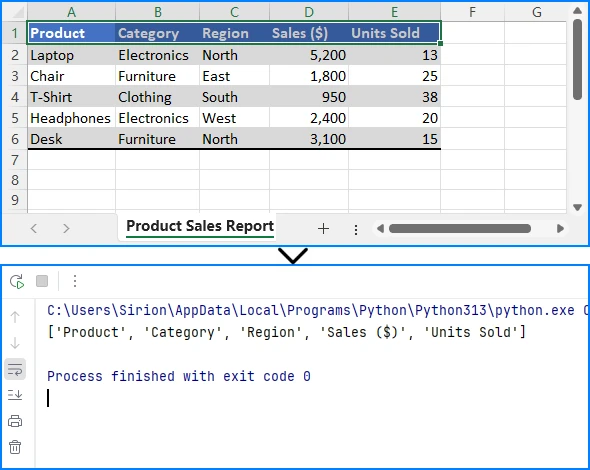
# Get the used cell range
cellRange = sheet.AllocatedRange
# Get the data from the first row
for col in range(cellRange.Columns.Count):
data.append(sheet.Range[1, col +1].Value)
print(data)
workbook.Dispose()
Below is a preview of the data imported from the Excel file:
This minimal example demonstrates the fundamental workflow: initialize a workbook, load the Excel file, access the worksheet and cell data, and then dispose of the workbook to release resources.
For more advanced scenarios, such as reading Excel files from memory or handling file streams, see how to import Excel data from a stream in Python.
Import Excel Data in Python as a List
One of the simplest ways to import Excel data in Python is to convert it into a list of rows. This structure is useful for iteration and basic data processing.
Example
from spire.xls import *
# Load the Workbook
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
# Get the used range in the first worksheet
sheet = workbook.Worksheets[0]
cellRange = sheet.AllocatedRange
# Create a list to store the data
data = []
for row_index in range(cellRange.RowCount):
row_data = []
for cell_index in range(cellRange.ColumnCount):
row_data.append(cellRange[row_index + 1, cell_index + 1].Value)
data.append(row_data)
workbook.Dispose()
Technical Explanation
Importing Excel data as a list treats each row in the worksheet as a Python list, preserving the original row order.
How the code works:
- A nested loop is used to traverse the worksheet in a row-first (row-major) pattern
- The outer loop iterates through rows, while the inner loop accesses each cell
- Index offsets (
+1) are applied because Spire.XLS uses 1-based indexing
Why this design works:
- AllocatedRange limits iteration to only populated cells, improving efficiency
- Row-by-row extraction keeps the structure consistent with Excel’s layout
- The intermediate row_data list ensures clean aggregation before appending
This structure is ideal for sequential processing, simple transformations, or as a base format before converting into dictionaries or objects.
If you want to load more than just text and numeric data, see How to Read Excel Files in Python for more data types.
Import Excel Data as a Dictionary in Python
If your Excel file contains headers, importing it as a dictionary provides better data organization and access by column names.
Example
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
sheet = workbook.Worksheets[0]
cellRange = sheet.AllocatedRange
rows = list(cellRange.Rows)
headers = [cellRange[1, cell_index + 1].Value for cell_index in range(cellRange.ColumnCount)]
data_dict = []
for row in rows[1:]:
row_dict = {}
for i, cell in enumerate(row.Cells):
row_dict[headers[i]] = cell.Value
data_dict.append(row_dict)
workbook.Dispose()
Technical Explanation
Importing Excel data as a dictionary converts each row into a key-value structure using column headers.
How the code works:
- The first row is extracted as headers
- Each subsequent row is iterated and processed
- Cell values are mapped to headers using their column index
Why this design works:
- Both headers and row cells follow the same column order, enabling simple index-based mapping
- This removes reliance on fixed column positions
- The result is a self-descriptive structure with named fields
This method is useful when you need structured data access, such as working with JSON, APIs, or labeled datasets.
Import Excel Data into Custom Objects
For structured applications, you may need to import Excel data into Python objects to maintain type safety and encapsulate business logic.
Example
class Employee:
def __init__(self, name, age, department):
self.name = name
self.age = age
self.department = department
from spire.xls import *
from spire.xls.common import *
workbook = Workbook()
workbook.LoadFromFile("EmployeeData.xlsx")
sheet = workbook.Worksheets[0]
cellRange = sheet.AllocatedRange
employees = []
for row in list(cellRange.Rows)[1:]:
name = row.Cells[0].Value
age = int(row.Cells[1].Value) if row.Cells[1].Value else None
department = row.Cells[2].Value
emp = Employee(name, age, department)
employees.append(emp)
workbook.Dispose()
Technical Explanation
Importing Excel data into objects maps each row to a structured class instance.
How the code works:
- A class is defined to represent the data model
- Each row is read and its values are extracted
- Values are passed into the class constructor to create objects
Why this design works:
- The constructor acts as a controlled transformation point
- It allows validation, type conversion, or preprocessing
- Data is no longer loosely structured, but aligned with domain logic
This is ideal for applications with clear data models, such as backend systems or business logic layers.
Import Excel Data to Database in Python
In many applications, Excel data needs to be stored in a database for persistent storage and querying.
Example
import sqlite3
from spire.xls import *
# Connect to SQLite database
conn = sqlite3.connect("sales.db")
cursor = conn.cursor()
# Create table matching the Excel structure
cursor.execute("""
CREATE TABLE IF NOT EXISTS sales (
product TEXT,
category TEXT,
region TEXT,
sales REAL,
units_sold INTEGER
)
""")
# Load the Excel file
workbook = Workbook()
workbook.LoadFromFile("Sales.xlsx")
# Access the first worksheet
sheet = workbook.Worksheets[0]
rows = list(sheet.AllocatedRange.Rows)
# Iterate through rows (skip header row)
for row in rows[1:]:
product = row.Cells[0].Value
category = row.Cells[1].Value
region = row.Cells[2].Value
# Remove thousand-separators and convert to float
sales_text = row.Cells[3].Value
sales = float(str(sales_text).replace(",", "")) if sales_text else 0
# Convert units sold to integer
units_text = row.Cells[4].Value
units_sold = int(units_text) if units_text else 0
# Insert data into the database
cursor.execute(
"INSERT INTO sales VALUES (?, ?, ?, ?, ?)",
(product, category, region, sales, units_sold)
)
# Commit changes and close connection
conn.commit()
conn.close()
# Release Excel resources
workbook.Dispose()
Here is a preview of the Excel data and the SQLite database structure:
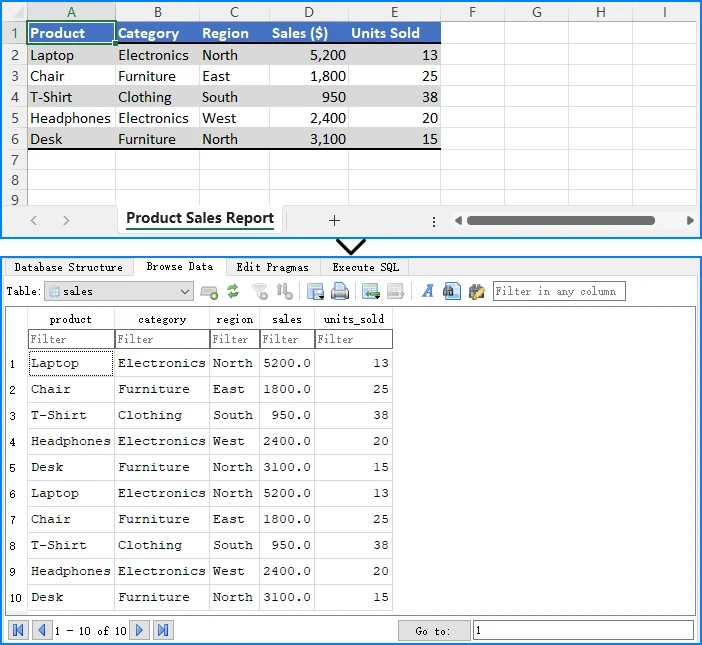
Technical Explanation
Importing Excel data into a database converts each row into a persistent record.
How the code works:
- A database connection is established and a table is created
- The table schema is aligned with the Excel structure
- Each row is read and inserted using parameterized SQL queries
Why this design works:
- Schema alignment ensures consistent data mapping
- Data normalization (e.g., numeric conversion) improves compatibility
- Parameterized queries provide safety and proper type handling
When to use this approach:
This approach is suitable for data storage, querying, and integration into larger data pipelines.
For a more detailed guide on importing Excel data into Databases, check out How to Transfer Data Between Excel Files and Databases.
Why Use Spire.XLS for Importing Excel Data
The examples in this guide use Spire.XLS for Python because it provides a clear and consistent way to access and transform Excel data. The main advantages in this context include:
-
Structured Object Model The library exposes components such as Workbook, Worksheet, and CellRange, which align directly with how Excel data is organized. This makes the data flow easier to understand and implement. See more details on Spire.XLS for Python API Reference.
-
Focused Data Access Layer Instead of handling low-level file parsing, you can work directly with cell values and ranges, allowing the import logic to focus on data transformation rather than file structure.
-
Format Compatibility It supports common Excel formats, such as XLS and XLSX, and other spreadsheet formats, such as CSV, ODS, and OOXML, enabling the same import logic to be applied across different file types.
-
No External Dependencies Excel files can be processed without requiring Microsoft Excel to be installed, which is important for backend services and automated environments.
Common Pitfalls
Incorrect File Path
Ensure the Excel file path is correct and accessible from your script. Use absolute paths or verify the current working directory.
import os
print(os.getcwd()) # Check current directory
Missing Headers
When importing as a dictionary, verify that your Excel file has headers in the first row. Otherwise, the keys will be incorrect.
Memory Management
Always dispose of the workbook object after processing to release resources, especially when processing large files.
workbook.Dispose()
Data Type Conversion
Excel cells may return different data types than expected. Validate and convert data types as needed for your application.
Import vs Read Excel in Python
In Python, "reading" and "importing" Excel files refer to related but distinct steps in data processing.
Read Excel focuses on accessing raw file content. This typically involves retrieving cell values, rows, or specific ranges without changing how the data is structured.
Import Excel includes both reading and transformation. After extracting the data, it is converted into structures such as lists, dictionaries, objects, or database records so that it can be used directly within an application.
In practice, reading is a subset of importing. The distinction lies in the goal—reading retrieves data, while importing prepares it for use.
Conclusion
Importing Excel file in Python is not just about reading data—it's about converting it into structures that your application can use effectively. In this guide, you learned how to import Excel file in Python as a list, convert Excel data into dictionaries, map Excel data into Python objects, and import Excel data into a database.
With Spire.XLS for Python, you can easily import Excel data into different structures with minimal code. The library provides a consistent API for handling various Excel formats and complex content, making it suitable for a wide range of data processing scenarios.
To evaluate the full performance of Spire.XLS for Python, you can apply for a 30 day trial license.
FAQ
What does it mean to import Excel file in Python?
Importing Excel means converting Excel data into Python structures such as lists, dictionaries, or databases for further processing and integration into your applications.
How do I import Excel data into Python?
You can use libraries like Spire.XLS for Python to load Excel files and convert their content into usable Python data structures. The process involves loading the workbook, accessing the worksheet, and iterating through cells to extract data.
Can I import Excel data into a database using Python?
Yes, you can read Excel data and insert it into databases like SQLite, MySQL, or PostgreSQL using Python. This approach is commonly used for data migration and backend system integration.
What is the best structure for importing Excel data?
The best structure depends on your use case. Lists are suitable for simple iteration, dictionaries for structured data access by column names, objects for type safety and business logic, and databases for persistent storage and querying.
Do I need Microsoft Excel installed to import Excel files in Python?
No, libraries like Spire.XLS for Python work independently and do not require Microsoft Excel to be installed on the system.

CSV (Comma-Separated Values) files are the backbone of data exchange across industries—from data analysis to backend systems. They’re lightweight, human-readable, and compatible with almost every tool (Excel, Google Sheets, databases). If you’re a developer seeking a reliable way to create a CSV file in Python, Spire.XLS for Python is a powerful library that simplifies the process.
In this comprehensive guide, we'll explore how to generate a CSV file in Python with Spire.XLS, covering basic CSV creation and advanced use cases like list to CSV and Excel to CSV conversion.
What You’ll Learn
- Installation and Setup
- Basic: Create a Simple CSV File in Python
- Dynamic Data: Generate CSV from a List of Dictionaries in Python
- Excel-to-CSV: Generate CSV From an Excel File in Python
- Best Practices for CSV Creation
- FAQ: Create CSV in Python
Installation and Setup
Getting started with Spire.XLS for Python is straightforward. Follow these steps to set up your environment:
Step 1: Ensure Python 3.6 or higher is installed.
Step 2: Install the library via pip (the official package manager for Python):
pip install Spire.XLS
Step 3 (Optional): Request a temporary free license to test full features without any limitations.
Basic: Create a Simple CSV File in Python
Let’s start with a simple scenario: creating a CSV file from scratch with static data (e.g., a sales report). The code below creates a new workbook, populates it with data, and saves it as a CSV file.
from spire.xls import *
from spire.xls.common import *
# 1. Create a new workbook
workbook = Workbook()
# 2. Get the first worksheet (default sheet)
worksheet = workbook.Worksheets[0]
# 3. Populate data into cells
# Header row
worksheet.Range["A1"].Text = "ProductID"
worksheet.Range["B1"].Text = "ProductName"
worksheet.Range["C1"].Text = "Price"
worksheet.Range["D1"].Text = "QuantitySold"
worksheet.Range["A2"].NumberValue = 101
worksheet.Range["B2"].Text = "Wireless Headphones"
worksheet.Range["C2"].NumberValue = 79.99
worksheet.Range["D2"].NumberValue = 250
worksheet.Range["A3"].NumberValue = 102
worksheet.Range["B3"].Text = "Bluetooth Speaker"
worksheet.Range["C3"].NumberValue = 49.99
worksheet.Range["D3"].NumberValue = 180
# Save the worksheet to CSV
worksheet.SaveToFile("BasicSalesReport.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
Core Workflow
- Initialize Core object: Workbook() creates a new Excel workbook, Worksheets[0] accesses the target sheet.
- Fill data into cells: Use .Text (for strings) and .NumberValue (for numbers) to ensure correct data types.
- Export & cleanup: SaveToFile() exports the worksheet to CSV , and Dispose() prevents memory leaks.
Output:
The resulting BasicSalesReport.csv will look like this:

Dynamic Data: Generate CSV from a List of Dictionaries in Python
In real-world scenarios, data is often stored in dictionaries (e.g., from APIs/databases). The code below converts a list of dictionaries to a CSV:
from spire.xls import *
from spire.xls.common import *
# Sample data (e.g., from a database/API)
customer_data = [
{"CustomerID": 1, "Name": "John Doe", "Email": "john@example.com", "Country": "USA"},
{"CustomerID": 2, "Name": "Maria Garcia", "Email": "maria@example.es", "Country": "Spain"},
{"CustomerID": 3, "Name": "Li Wei", "Email": "wei@example.cn", "Country": "China"}
]
# 1. Create workbook and worksheet
workbook = Workbook()
worksheet = workbook.Worksheets[0]
# 2. Write headers (extract keys from the first dictionary)
headers = list(customer_data[0].keys())
for col_idx, header in enumerate(headers, start=1):
worksheet.Range[1, col_idx].Text = header # Row 1 = headers
# 3. Write data rows
for row_idx, customer in enumerate(customer_data, start=2): # Start at row 2
for col_idx, key in enumerate(headers, start=1):
# Handle different data types (text/numbers)
value = customer[key]
if isinstance(value, (int, float)):
worksheet.Range[row_idx, col_idx].NumberValue = value
else:
worksheet.Range[row_idx, col_idx].Text = value
# 4. Save as CSV
worksheet.SaveToFile("CustomerData.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
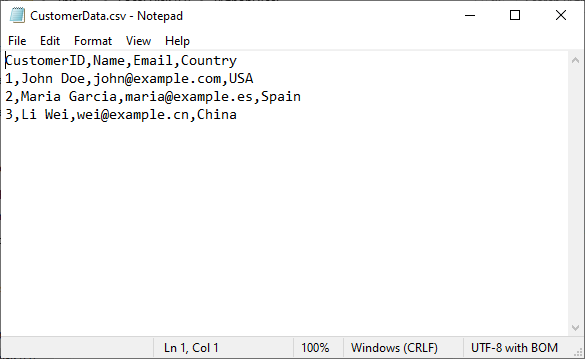
This example is ideal for JSON to CSV conversion, database dumps, and REST API data exports. Key advantages include:
- Dynamic Headers: Automatically extracts headers from the keys of the first dictionary in the dataset.
- Scalable: Seamlessly adapts to any volume of dictionaries or key-value pairs (perfect for dynamic data).
- Clean Output: Preserves the original order of dictionary keys for consistent CSV structure.
The generated CSV file:
Excel-to-CSV: Generate CSV From an Excel File in Python
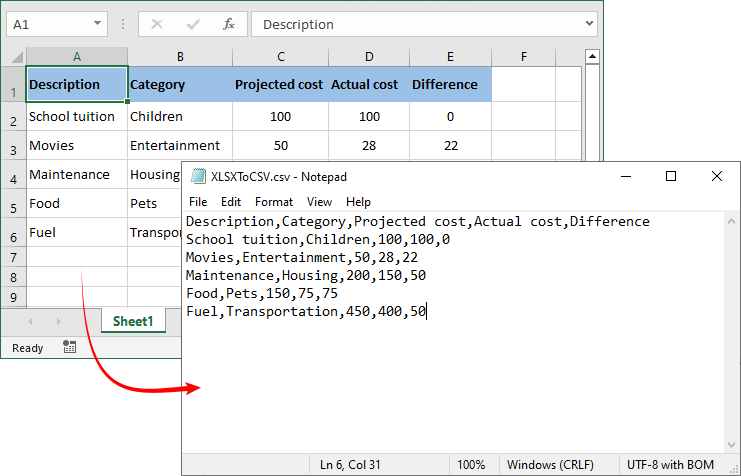
Spire.XLS excels at converting Excel (XLS/XLSX) to CSV in Python. This is useful if you have Excel reports and need to export them to CSV for data pipelines or third-party tools.
from spire.xls import *
# 1. Initialize a workbook instance
workbook = Workbook()
# 2. Load a xlsx file
workbook.LoadFromFile("Expenses.xlsx")
# 3. Save Excel as a CSV file
workbook.SaveToFile("XLSXToCSV.csv", FileFormat.CSV)
workbook.Dispose()
Conversion result:
Note: By default, SaveToFile() converts only the first worksheet. For converting multiple sheets to separate CSV files, refer to the comprehensive guide: Convert Excel (XLSX/XLS) to CSV in Python – Batch & Multi-Sheet
Best Practices for CSV Creation
Follow these guidelines to ensure robust and professional CSV output:
- Validate Data First: Clean empty rows/columns before exporting to CSV.
- Use UTF-8 Encoding: Always specify UTF-8 encoding (Encoding.get_UTF8()) to support international characters seamlessly.
- Batch Process Smartly: For 100k+ rows, process data in chunks (avoid loading all data into memory at once).
- Choose the Correct Delimiter: Be mindful of regional settings. For European users, use a semicolon (;) as the delimiter to avoid locale issues.
- Dispose Objects: Release workbook/worksheet resources with Dispose() to prevent memory leaks.
Conclusion
Spire.XLS simplifies the process of leveraging Python to generate CSV files. Whether you're creating reports from scratch, converting Excel workbooks, or handling dynamic data from APIs and databases, this library delivers a robust and flexible solution.
By following this guide, you can easily customize delimiters, specify encodings such as UTF-8, and manage data types—ensuring your CSV files are accurate, compatible, and ready for any application. For more advanced features, you can explore the Spire.XLS for Python tutorials.
FAQ: Create CSV in Python
Q1: Why choose Spire.XLS over Python’s built-in csv module?
A: While Python's csv module is excellent for basic read/write operations, Spire.XLS offers significant advantages:
- Better data type handling: Automatic distinction between text and numeric data.
- Excel Compatibility: Seamlessly converts between Excel (XLSX/XLS) and CSV—critical for teams using Excel as a data source.
- Advanced Customization: Supports customizing the delimiter and encoding of the generated CSV file.
- Batch processing: Efficient handling of large datasets and multiple files.
- Cross-Platform Support: Works on Windows, macOS, and Linux (no Excel installation required).
Q2: Can I use Spire.XLS for Python to read CSV files?
A: Yes. Spire.XLS supports parsing CSV files and extracting their data. Details refer to: How to Read CSV Files in Python: A Comprehensive Guide
Q3: Can Spire.XLS convert CSV files back to Excel format?
A: Yes! Spire.XLS supports bidirectional conversion. A quick example:
from spire.xls import *
# Create a workbook
workbook = Workbook()
# Load a CSV file
workbook.LoadFromFile("sample.csv", ",", 1, 1)
# Save CSV as Excel
workbook.SaveToFile("CSVToExcel.xlsx", ExcelVersion.Version2016)
Q4: How do I change the CSV delimiter?
A: The SaveToFile() method’s second parameter controls the delimiter:
# Semicolon (for European locales):
worksheet.SaveToFile("EU.csv", ";", Encoding.get_UTF8())
# Tab (for tab-separated values/TSV)
worksheet.SaveToFile("TSV_File.csv", "\t", Encoding.get_UTF8())

CSV (Comma-Separated Values) is a universal file format for storing tabular data, while lists are Python’s fundamental data structure for easy data manipulation. Converting CSV to lists in Python enables seamless data processing, analysis, and integration with other workflows. While Python’s built-in csv module works for basic cases, Spire.XLS for Python simplifies handling structured CSV data with its intuitive spreadsheet-like interface.
This article will guide you through how to use Python to read CSV into lists (and lists of dictionaries), covering basic to advanced scenarios with practical code examples.
Table of Contents:
- Why Choose Spire.XLS for CSV to List Conversion?
- Basic Conversion: CSV to Python List
- Advanced: Convert CSV to List of Dictionaries
- Handle Special Scenarios
- Conclusion
- Frequently Asked Questions
Why Choose Spire.XLS for CSV to List Conversion?
Spire.XLS is a powerful library designed for spreadsheet processing, and it excels at CSV handling for several reasons:
- Simplified Indexing: Uses intuitive 1-based row/column indexing (matching spreadsheet logic).
- Flexible Delimiters: Easily specify custom separators (commas, tabs, semicolons, etc.).
- Structured Access: Treats CSV data as a worksheet, making row/column traversal straightforward.
- Robust Data Handling: Automatically parses numbers, dates, and strings without extra code.
Installation
Before starting, install Spire.XLS for Python using pip:
pip install Spire.XLS
This command installs the latest stable version, enabling immediate use in your projects.
Basic Conversion: CSV to Python List
If your CSV file has no headers (pure data rows), Spire.XLS can directly read rows and convert them to a list of lists (each sublist represents a CSV row).
Step-by-Step Process:
- Import the Spire.XLS module.
- Create a Workbook object and load the CSV file.
- Access the first worksheet (Spire.XLS parses CSV into a worksheet).
- Traverse rows and cells, extracting values into a Python list.
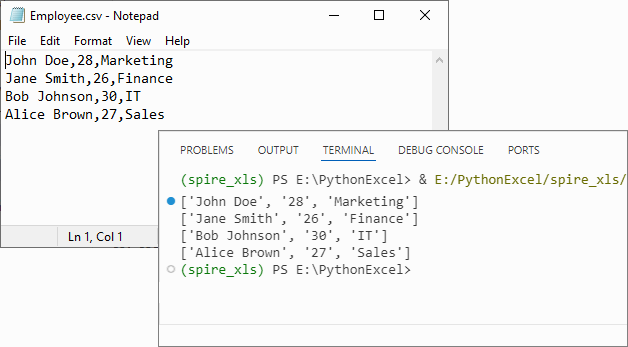
CSV to List Python Code Example:
from spire.xls import *
from spire.xls.common import *
# Initialize Workbook and load CSV
workbook = Workbook()
workbook.LoadFromFile("Employee.csv",",")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Convert sheet data to a list of lists
data_list = []
for i in range(sheet.Rows.Length):
row = []
for j in range(sheet.Columns.Length):
cell_value = sheet.Range[i + 1, j + 1].Value
row.append(cell_value)
data_list.append(row)
# Display the result
for row in data_list:
print(row)
# Dispose resources
workbook.Dispose()
Output:
If you need to convert the list back to CSV, refer to: Python List to CSV: 1D/2D/Dicts – Easy Tutorial
Advanced: Convert CSV to List of Dictionaries
For CSV files with headers (e.g., name,age,city), converting to a list of dictionaries (where keys are headers and values are row data) is more intuitive for data manipulation.
CSV to Dictionary Python Code Example:
from spire.xls import *
# Initialize Workbook and load CSV
workbook = Workbook()
workbook.LoadFromFile("Customer_Data.csv", ",")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Extract headers (first row)
headers = []
for j in range(sheet.Columns.Length):
headers.append(sheet.Range[1, j + 1].Value)
# Convert data rows to list of dictionaries
dict_list = []
for i in range(1, sheet.Rows.Length): # Skip header row
row_dict = {}
for j in range(sheet.Columns.Length):
key = headers[j]
value = sheet.Range[i + 1, j + 1].Value
row_dict[key] = value
dict_list.append(row_dict)
# Output the result
for record in dict_list:
print(record)
workbook.Dispose()
Explanation
- Load the CSV: Use LoadFromFile() method of Workbook class.
- Extracting Headers: Pull the first row of the worksheet to use as dictionary keys.
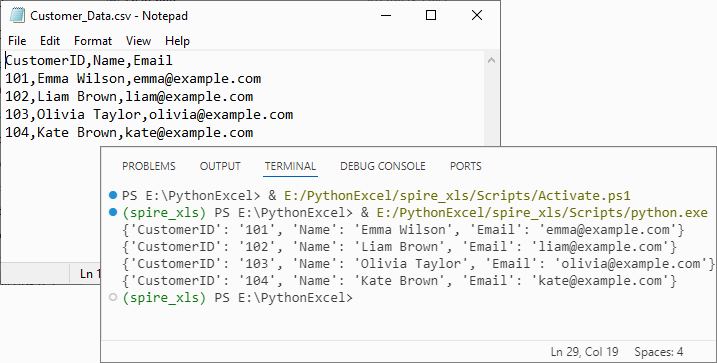
- Map Rows to Dictionaries: For each data row (skipping the header row), create a dictionary where keys are headers and values are cell contents.
Output:
Handle Special Scenarios
CSV with Custom Delimiters (e.g., Tabs, Semicolons)
To process CSV files with delimiters other than commas (e.g., tab-separated TSV files), specify the delimiter in LoadFromFile:
# Load a tab-separated file
workbook.LoadFromFile("data.tsv", "\t")
# Load a semicolon-separated file
workbook.LoadFromFile("data_eu.csv", ";")
Clean Empty Values
Empty cells in the CSV are preserved as empty strings ('') in the list. To replace empty strings with a custom value (e.g., "N/A"), modify the cell value extraction:
cell_value = sheet.Range[i + 1, j + 1].Value or "N/A"
Conclusion
Converting CSV to lists in Python using Spire.XLS is efficient, flexible, and beginner-friendly. Whether you need a list of lists for raw data or a list of dictionaries for structured analysis, this library handles parsing, indexing, and resource management efficiently. By following the examples above, you can integrate this conversion into data pipelines, analysis scripts, or applications with minimal effort.
For more advanced features (e.g., CSV to Excel conversion, batch processing), you can visit the Spire.XLS for Python documentation.
Frequently Asked Questions
Q1: Is Spire.XLS suitable for large CSV files?
A: Spire.XLS handles large files efficiently, but for very large datasets (millions of rows), consider processing in chunks or using specialized big data tools. For typical business datasets, it performs excellently.
Q2: How does this compare to using pandas for CSV to list conversion?
A: Spire.XLS offers more control over the parsing process and doesn't require additional data science dependencies. While pandas is great for analysis, Spire.XLS is ideal when you need precise control over CSV parsing or are working in environments without pandas.
Q3: How do I handle CSV files with headers when converting to lists?
A: For headers, use the dictionary conversion method. Extract the first row as headers, then map subsequent rows to dictionaries where keys are header values. This preserves column meaning and enables easy data access by column name.
Q4: How do I convert only specific columns from my CSV to a list?
A: Modify the inner loop to target specific columns:
# Convert only columns 1 and 3 (index 0 and 2)
target_columns = [0, 2]
for i in range(sheet.Rows.Length):
row = []
for j in target_columns:
cell_value = sheet.Range[i + 1, j + 1].Value
row.append(cell_value)
data_list.append(row)
Python TXT to CSV Tutorial | Convert TXT Files to CSV in Python
2025-10-15 07:42:33 Written by jie zou
When working with data in Python, converting TXT files to CSV is a common and essential task for data analysis, reporting, or sharing data between applications. TXT files often store unstructured plain text, which can be difficult to process, while CSV files organize data into rows and columns, making it easier to work with and prepare for analysis. This tutorial explains how to convert TXT to CSV in Python efficiently, covering single-file conversion, batch conversion, and tips for handling different delimiters.
Table of Contents
- What is a CSV File
- Python TXT to CSV Library - Installation
- Convert a TXT File to CSV in Python (Step-by-Step)
- Automate Batch Conversion of Multiple TXT Files
- Advanced Tips for Python TXT to CSV Conversion
- Conclusion
- FAQs: Python Text to CSV
What is a CSV File?
A CSV (Comma-Separated Values) file is a simple text-based file format used to store tabular data. Each line in a CSV file represents a row, and values within the row are separated by commas (or another delimiter such as tabs or semicolons).
CSV is widely supported by spreadsheet applications, databases, and programming languages like Python. Its simple format makes it easy to import, export, and use across platforms such as Excel, Google Sheets, R, and SQL for data analysis and automation.
An Example CSV File:
Name, Age, City
John, 28, New York
Alice, 34, Los Angeles
Bob, 25, Chicago
Python TXT to CSV Library - Installation
To perform TXT to CSV conversion in Python, we will use Spire.XLS for Python, a powerful library for creating and manipulating Excel and CSV files, without requiring Microsoft Excel to be installed.

You can install it directly from PyPI with the following command:
pip install Spire.XLS
If you need instructions for the installation, visit the guide on How to Install Spire.XLS for Python.
Convert a TXT File to CSV in Python (Step-by-Step)
Converting a text file to CSV in Python is straightforward. You can complete the task in just a few steps. Below is a basic outline of the process:
- Prepare and read the text file: Load your TXT file and read its content line by line.
- Split the text data: Separate each line into fields using a specific delimiter such as a space, tab, or comma.
- Write data to CSV: Use Spire.XLS to write the processed data into a new CSV file.
- Verify the output: Check the CSV in Excel, Google Sheets, or a text editor.
The following code demonstrates how to export a TXT file to CSV using Python:
from spire.xls import *
# Read the txt file
with open("data.txt", "r", encoding="utf-8") as file:
lines = file.readlines()
# Process each line by splitting based on spaces (you can change the delimiter if needed)
processed_data = [line.strip().split() for line in lines]
# Create an Excel workbook
workbook = Workbook()
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Write data from the processed list to the worksheet
for row_num, row_data in enumerate(processed_data):
for col_num, cell_data in enumerate(row_data):
# Write data into cells
sheet.Range[row_num + 1, col_num + 1].Value = cell_data
# Save the sheet as CSV file (UTF-8 encoded)
sheet.SaveToFile("TxtToCsv.csv", ",", Encoding.get_UTF8())
# Dispose the workbook to release resources
workbook.Dispose()
TXT to CSV Output:
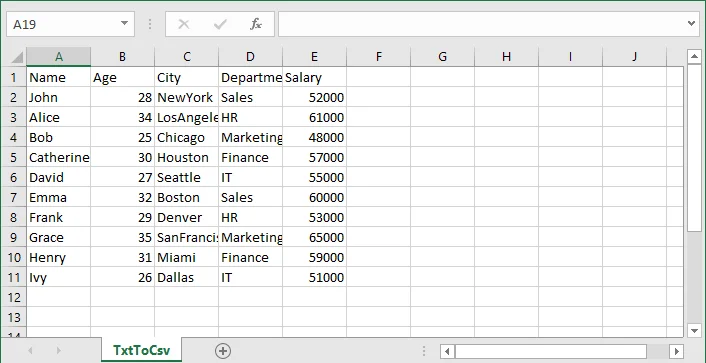
If you are also interested in converting a TXT file to Excel, see the guide on converting TXT to Excel in Python.
Automate Batch Conversion of Multiple TXT Files
If you have multiple text files that you want to convert to CSV automatically, you can loop through all .txt files in a folder and convert them one by one.
The following code demonstrates how to batch convert multiple TXT files to CSV in Python:
import os
from spire.xls import *
# Folder containing TXT files
input_folder = "txt_files"
output_folder = "csv_files"
# Create output folder if it doesn't exist
os.makedirs(output_folder, exist_ok=True)
# Function to process a single TXT file
def convert_txt_to_csv(file_path, output_path):
# Read the TXT file
with open(file_path, "r", encoding="utf-8") as f:
lines = f.readlines()
# Process each line (split by space, modify if your delimiter is different)
processed_data = [line.strip().split() for line in lines if line.strip()]
# Create workbook and access the first worksheet
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write processed data into the sheet
for row_num, row_data in enumerate(processed_data):
for col_num, cell_data in enumerate(row_data):
sheet.Range[row_num + 1, col_num + 1].Value = cell_data
# Save the sheet as CSV with UTF-8 encoding
sheet.SaveToFile(output_path, ",", Encoding.get_UTF8())
workbook.Dispose()
print(f"Converted '{file_path}' -> '{output_path}'")
# Loop through all TXT files in the folder and convert each to a CSV file with the same file name
for filename in os.listdir(input_folder):
if filename.lower().endswith(".txt"):
input_path = os.path.join(input_folder, filename)
output_name = os.path.splitext(filename)[0] + ".csv"
output_path = os.path.join(output_folder, output_name)
convert_txt_to_csv(input_path, output_path)
Advanced Tips for Python TXT to CSV Conversion
Converting text files to CSV can involve variations in text file layout and potential errors, so these tips will help you handle different scenarios more effectively.
1. Handle Different Delimiters
Not all text files use spaces to separate values. If your TXT file uses tabs, commas, or other characters, you can adjust the split() function to match the delimiter.
- For tab-separated files (.tsv):
processed_data = [line.strip().split('\t') for line in lines]
- For comma-separated files:
processed_data = [line.strip().split(',') for line in lines]
- For custom delimiters (e.g., |):
processed_data = [line.strip().split('|') for line in lines]
This ensures that your data is correctly split into columns before writing to CSV.
2. Add Error Handling
When reading or writing files, it's a good practice to use try-except blocks to catch potential errors. This makes your script more robust and prevents unexpected crashes.
try:
# your code here
except Exception as e:
print("Error:", e)
Tip: Use descriptive error messages to help understand the problem.
- Skip Empty Lines
Sometimes, text files may have empty lines. You can filter out the blank lines to avoid creating empty rows in CSV:
processed_data = [line.strip().split() for line in lines if line.strip()]
Conclusion
In this article, you learned how to convert a TXT file to CSV format in Python using Spire.XLS for Python. This conversion is an essential step in data preparation, helping organize raw text into a structured format suitable for analysis, reporting, and sharing. With Spire.XLS for Python, you can automate the text to CSV conversion, handle different delimiters, and efficiently manage multiple text files.
If you have any questions or need technical assistance about Python TXT to CSV conversion, visit our Support Forum for help.
FAQs: Python Text to CSV
Q1: Can I convert TXT files to CSV without Microsoft Excel installed?
A1: Yes. Spire.XLS for Python works independently of Microsoft Excel, allowing you to create and export CSV files directly.
Q2: How to batch convert multiple TXT files to CSV in Python?
A2: Use a loop to read all TXT files in a folder and apply the conversion function for each. The tutorial includes a ready-to-use Python example for batch conversion.
Q3: How do I handle empty lines or inconsistent rows in TXT files when converting to CSV?
A3: Filter out empty lines during processing and implement checks for consistent column counts to avoid errors or blank rows in the output CSV.
Q4: How do I convert TXT files with tabs or custom delimiters to CSV in Python?
A4: You can adjust the split() function in your Python script to match the delimiter in your TXT file-tabs (\t), commas, or custom characters-before writing to CSV.

In today's data-driven world, Python developers frequently need to convert lists (a fundamental Python data structure) into Excel spreadsheets. Excel remains the standard for data presentation, reporting, and sharing across industries. Whether you're generating reports, preparing data for analysis, or sharing information with non-technical stakeholders, the ability to efficiently export Python lists to Excel is a valuable skill.
While lightweight libraries like pandas can handle basic exports, Spire.XLS for Python gives you full control over Excel formatting, styles, and file generation – all without requiring Microsoft Excel. In this comprehensive guide, we'll explore how to use the library to convert diverse list structures into Excel in Python, complete with detailed examples and best practices.
- Why Convert Python Lists to Excel?
- Installation Guide
- Basic – Convert a Simple Python List to Excel
- Convert Nested Lists to Excel in Python
- Convert a List of Dictionaries to Excel
- 4 Tips to Optimize Your Excel Outputs
- Conclusion
- FAQs
Why Convert Python Lists to Excel?
Lists in Python are versatile for storing structured or unstructured data, but Excel offers advantages in:
- Collaboration: Excel is universally used, and stakeholders can edit, sort, or filter data without Python knowledge.
- Reporting: Add charts, pivot tables, or summaries to Excel after export.
- Compliance: Many industries require data in Excel for audits or record-keeping.
- Visualization: Excel’s formatting tools (colors, borders, headers) make data easier to read than raw Python lists.
Whether you’re working with sales data, user records, or survey results, writing lists to Excel in Python ensures your data is accessible and professional.
Installation Guide
To get started with Spire.XLS for Python, install it using pip:
pip install Spire.XLS
The Python Excel library supports Excel formats like .xls or .xlsx and lets you customize formatting (bold headers, column widths, colors), perfect for production-ready files.
To fully experience the capabilities of Spire.XLS for Python, you can request a free 30-day trial license here.
Basic – Convert a Simple Python List to Excel
For a basic one-dimensional list, iterate through the items and write them to consecutive cells in a single column.
This code example converts a list of text strings into a single column. If you need to convert a list of numeric values, you can set their number format before saving.
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Clear the default sheets
workbook.Worksheets.Clear()
# Add a new worksheet
worksheet = workbook.Worksheets.Add("Simple List")
# Sample list
data_list = ["Alexander", "Bob", "Charlie", "Diana", "Eve"]
# Write list data to Excel cells (starting from row 1, column 1)
for index, value in enumerate(data_list):
worksheet.Range[index + 1, 1].Value = value
# Set column width for better readability
worksheet.Range[1, 1].ColumnWidth = 15
# Save the workbook
workbook.SaveToFile("SimpleListToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
If you need to write the list in a single row, use the following:
for index, value in enumerate(data_list):
worksheet.Range[1, index + 1].Value = value
Output: A clean Excel file with one column of names, properly spaced.
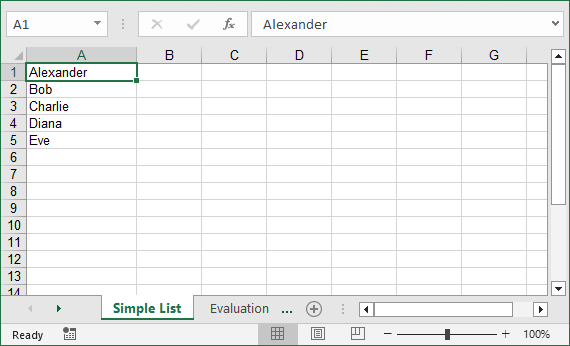
Convert Nested Lists to Excel in Python
Nested lists (2D Lists) represent tabular data with rows and columns, making them perfect for direct conversion to Excel tables. Let’s convert a nested list of employee data (name, age, department) to an Excel table.
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Clear the default sheets
workbook.Worksheets.Clear()
# Add a new worksheet
worksheet = workbook.Worksheets.Add("Employee Data")
# Nested list (rows: [Name, Age, Department])
employee_data = [
["Name", "Age", "Department"], # Header row
["Alexander", 30, "HR"],
["Bob", 28, "Engineering"],
["Charlie", 35, "Marketing"],
["Diana", 29, "Finance"]
]
# Write nested list to Excel
for row_idx, row_data in enumerate(employee_data):
for col_idx, value in enumerate(row_data):
if isinstance(value, int):
worksheet.Range[row_idx + 1, col_idx + 1].NumberValue = value
else:
worksheet.Range[row_idx + 1, col_idx + 1].Value = value
# Format header row
worksheet.Range["A1:C1"].Style.Font.IsBold = True
worksheet.Range["A1:C1"].Style.Color = Color.get_Yellow()
# Set column widths
worksheet.Range[1, 1].ColumnWidth = 10
worksheet.Range[1, 2].ColumnWidth = 6
worksheet.Range[1, 3].ColumnWidth = 15
# Save the workbook
workbook.SaveToFile("NestedListToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Explanation:
- Nested List Structure: The first sub-list acts as headers, and subsequent sub-lists are data rows.
- 2D Loop: We use nested loops to write each row and column to Excel cells.
Output: An Excel table with bold yellow headers and correctly typed data.
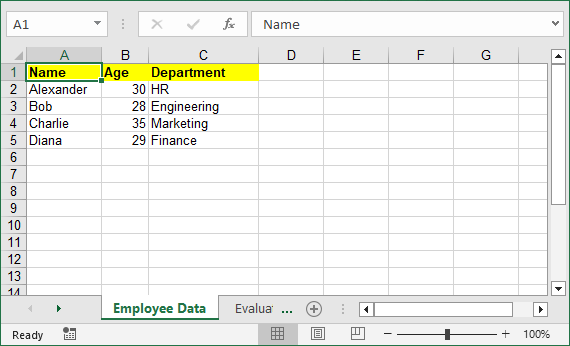
To make your Excel files more professional, you can add cell borders, set conditional formatting, or apply other formatting options with Spire.XLS for Python.
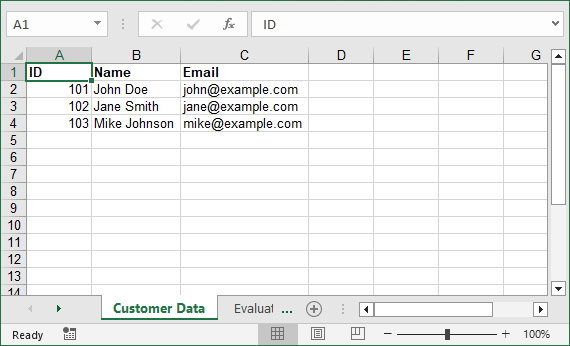
Convert a List of Dictionaries to Excel
Lists of dictionaries are common in Python for storing structured data with labeled fields. This example converts a list of dictionaries (e.g., customer records) to Excel and auto-extracts headers from dictionary keys.
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Clear the default sheets
workbook.Worksheets.Clear()
# Add a new worksheet
worksheet = workbook.Worksheets.Add("Customer Data")
# List of dictionaries
customers = [
{"ID": 101, "Name": "John Doe", "Email": "john@example.com"},
{"ID": 102, "Name": "Jane Smith", "Email": "jane@example.com"},
{"ID": 103, "Name": "Mike Johnson", "Email": "mike@example.com"}
]
# Extract headers from dictionary keys
headers = list(customers[0].keys())
# Write headers to row 1
for col, header in enumerate(headers):
worksheet.Range[1, col + 1].Value = header
worksheet.Range[1, col + 1].Style.Font.IsBold = True # Bold headers
# Write data rows
for row, customer in enumerate(customers, start=2): # Start from row 2
for col, key in enumerate(headers):
value = customer[key]
if isinstance(value, (int, float)):
worksheet.Range[row, col + 1].NumberValue = value
else:
worksheet.Range[row, col + 1].Value = value
# Adjust column widths
worksheet.AutoFitColumn(2)
worksheet.AutoFitColumn(3)
# Save the file
workbook.SaveToFile("CustomerDataToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Why This Is Useful:
- Auto-Extracted Headers: Saves time. No need to retype headers like “ID” or “Email”.
- Auto-Fit Columns: Excel automatically adjusts column width to fit the longest text.
- Scalable: Works for large lists of dictionaries (e.g., 1000+ customers).
Output: Excel file with headers auto-created, data types preserved, and columns automatically sized.
4 Tips to Optimize Your Excel Outputs
- Preserve Data Types: Always use NumberValue for numbers (avoids issues with Excel calculations later).
- Auto-Fit Columns: Use worksheet.AutoFitColumn() to skip manual width adjustments.
- Name Worksheets Clearly: Instead of “Sheet1”, use names like “Q3 Sales” to make files user-friendly.
- Dispose of Workbooks: Always call workbook.Dispose() to free memory (critical for large datasets).
Conclusion
Converting lists to Excel in Python is a critical skill for data professionals, and Spire.XLS makes it easy to create polished, production-ready files. Whether you’re working with simple lists, nested data, or dictionaries, the examples above can be adapted to your needs.
For even more flexibility (e.g., adding charts or formulas), explore Spire.XLS’s documentation.
FAQs for List to Excel Conversion
Q1: How is Spire.XLS different from pandas for converting lists to Excel?
A: Pandas is great for quick, basic exports, but it lacks fine-grained control over Excel formatting. Spire.XLS is better when you need:
- Custom styles (colors, fonts, borders).
- Advanced Excel features (freeze panes, conditional formatting, charts).
- Standalone functionality (no Excel installation required).
Q2: How do I save my Excel file in different formats?
A: Use the ExcelVersion parameter in SaveToFile:
workbook.SaveToFile("output.xlsx", ExcelVersion.Version2016)
workbook.SaveToFile("output.xls", ExcelVersion.Version97to2003)
Q3: How does Spire.XLS handle different data types?
A: Spire.XLS provides specific properties for different data types:
- Use .Text for strings
- Use .NumberValue for numerical data
- Use .DateTimeValue for dates
- Use .BooleanValue for True/False values
Q4: Why clear default worksheets before adding new ones?
A: Spire.XLS for Python creates default sheets when you create a Workbook. Therefore, if you don't clear it with the Workbook.Worksheets.Clear(), your file will have extra empty sheets.
Q5: My data isn't showing correctly in Excel. What's wrong?
A: Check that you're using 1-based indexing and that your data types match the expected format. Also, verify that you're saving the file before disposing of the workbook.
CSV (Comma-Separated Values) is one of the most widely used formats for data exchange between applications, databases, and programming languages. For Python developers, the need to convert Python lists to CSV format arises constantly - whether exporting application data, generating reports, or preparing datasets for analysis. Spire.XLS for Python streamlines this critical process with an intuitive, reliable approach that eliminates common conversion pitfalls.
This comprehensive guide will explore how to write lists to CSV in Python. You'll discover how to handle everything from simple one-dimensional lists to complex nested dictionaries, while maintaining data integrity and achieving professional-grade output.
Table of Contents:
- Getting Started with Spire.XLS for Python
- Convert 1D List to CSV in Python
- Convert 2D List to CSV in Python
- Convert List of Dictionaries to CSV in Python
- Advanced: Custom Delimiters and Encoding
- Conclusion
- FAQs
Getting Started with Spire.XLS for Python
Why Use Spire.XLS for List-to-CSV Conversion?
While Python's built-in csv module is excellent for simple CSV operations, Spire.XLS offers additional benefits:
- Handles various data types seamlessly
- Lets you customize CSV output (e.g., semicolon delimiters for European locales).
- Can save in multiple file formats (CSV, XLSX, XLS, etc.)
- Works well with both simple and complex data structures
Install via pip
The Spire.XLS for Python lets you create, modify, and save Excel/CSV files programmatically. To use it, run this command in your terminal or command prompt:
pip install Spire.XLS
This command downloads and installs the latest version, enabling you to start coding immediately.
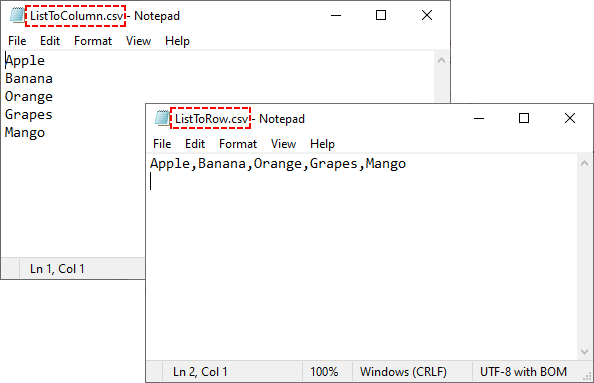
Convert 1D List to CSV in Python
A 1D (one-dimensional) list is a simple sequence of values (e.g., ["Apple", "Banana", "Cherry"]). The following are the steps to write these values to a single row or column in a CSV.
Step 1: Import Spire.XLS Modules
First, import the necessary classes from Spire.XLS:
from spire.xls import *
from spire.xls.common import *
Step 2: Create a Workbook and Worksheet
Spire.XLS uses workbooks and worksheets to organize data. We’ll create a new workbook and add a new worksheet:
# Create a workbook instance
workbook = Workbook()
# Remove the default worksheet and add a new one
workbook.Worksheets.Clear()
worksheet = workbook.Worksheets.Add()
Step 3: Write 1D List Data to the Worksheet
Choose to write the list to a single row (horizontal) or a single column (vertical).
Example 1: Write 1D List to a Single Row
# Sample 1D list
data_list = ["Apple", "Banana", "Orange", "Grapes", "Mango"]
# Write list to row 1
for i, item in enumerate(data_list):
worksheet.Range[1, i+1].Value = item
Example 2: Write 1D List to a Single Column
# Sample 1D list
data_list = ["Apple", "Banana", "Orange", "Grapes", "Mango"]
# Write list to column 1
for i, item in enumerate(data_list):
worksheet.Range[i + 1, 1].Value = item
Step 4: Save the Worksheet as CSV
Use SaveToFile() to export the workbook to a CSV file. Specify FileFormat.CSV to ensure proper formatting:
# Save as CSV file
workbook.SaveToFile("ListToCSV.csv", FileFormat.CSV)
# Close the workbook to free resources
workbook.Dispose()
Output:
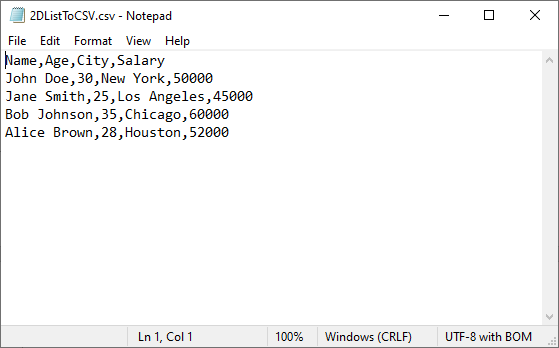
Convert 2D List to CSV in Python
A 2D (two-dimensional) list is a list of lists that represents tabular data. More commonly, you'll work with this type of list, where each inner list represents a row in the CSV file.
Python Code for 2D List to CSV:
from spire.xls import *
from spire.xls.common import *
# Create a workbook instance
workbook = Workbook()
# Remove the default worksheet and add a new one
workbook.Worksheets.Clear()
worksheet = workbook.Worksheets.Add()
# Sample 2D list (headers + data)
data = [
["Name", "Age", "City", "Salary"],
["John Doe", 30, "New York", 50000],
["Jane Smith", 25, "Los Angeles", 45000],
["Bob Johnson", 35, "Chicago", 60000],
["Alice Brown", 28, "Houston", 52000]
]
# Write 2D list to worksheet
for row_index, row_data in enumerate(data):
for col_index, cell_data in enumerate(row_data):
worksheet.Range[row_index + 1, col_index + 1].Value = str(cell_data)
# Save as a CSV file
workbook.SaveToFile("2DListToCSV.csv", FileFormat.CSV)
workbook.Dispose()
Key points:
- Ideal for structured tabular data with headers
- Nested loops handle both rows and columns
- Converting all values to strings ensures compatibility
Output:
The generated CSV can be converted to PDF for secure presentation, or converted to JSON for web/API data exchange.
Convert List of Dictionaries to CSV in Python
Lists of dictionaries are ideal when data has named fields (e.g., [{"Name": "Alice", "Age": 30}, {"Name": "Bob", "Age": 25}]). The dictionary keys become CSV headers, and values become rows.
Python Code for List of Dictionaries to CSV
from spire.xls import *
from spire.xls.common import *
# Create a workbook instance
workbook = Workbook()
# Remove the default worksheet and add a new one
workbook.Worksheets.Clear()
worksheet = workbook.Worksheets.Add()
# Sample 2D list (headers + data)
customer_list = [
{"CustomerID": 101, "Name": "Emma Wilson", "Email": "emma@example.com"},
{"CustomerID": 102, "Name": "Liam Brown", "Email": "liam@example.com"},
{"CustomerID": 103, "Name": "Olivia Taylor", "Email": "olivia@example.com"}
]
# Extract headers (dictionary keys) and write to row 1
if customer_list: # Ensure the list is not empty
headers = list(customer_list[0].keys())
# Write headers
for col_index, header in enumerate(headers):
worksheet.Range[1, col_index + 1].Value = str(header)
# Write dictionary values to rows 2 onwards
for row_index, record in enumerate(customer_list):
for col_index, header in enumerate(headers):
# Safely get value, use empty string if key doesn't exist
value = record.get(header, "")
worksheet.Range[row_index + 2, col_index + 1].Value = str(value)
# Save as CSV file
workbook.SaveToFile("Customer_Data.csv", FileFormat.CSV)
workbook.Dispose()
Key points:
- Extracts headers from the first dictionary's keys
- Uses .get() method to safely handle missing keys
- Maintains column order based on the header row
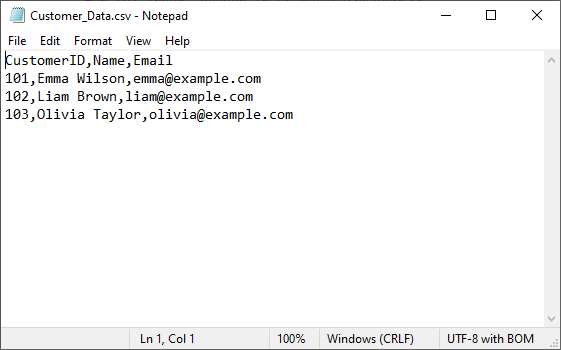
Output:
Advanced: Custom Delimiters and Encoding
One of the biggest advantages of using Spire.XLS for Python is its flexibility in saving CSV files with custom delimiters and encodings. This allows you to tailor your CSV output for different regions, applications, and data requirements.
To specify the delimiters and encoding, simply change the corresponding parameter in the SaveToFile() method of the Worksheet class. Example:
# Save with different delimiters and encodings
worksheet.SaveToFile("semicolon_delimited.csv", ";", Encoding.get_UTF8())
worksheet.SaveToFile("tab_delimited.csv", "\t", Encoding.get_UTF8())
worksheet.SaveToFile("unicode_encoded.csv", ",", Encoding.get_Unicode())
Conclusion
Converting Python lists to CSV is straightforward with the right approach. Whether you're working with simple 1D lists, structured 2D arrays, or more complex lists of dictionaries, Spire.XLS provides a robust solution. By choosing the appropriate method for your data structure, you can ensure efficient and accurate CSV generation in any application.
For more advanced features and detailed documentation, you can visit the official Spire.XLS for Python documentation.
Frequently Asked Questions (FAQs)
Q1: What are the best practices for list to CSV conversion?
- Validate input data before processing
- Handle exceptions with try-catch blocks
- Test with sample data before processing large datasets
- Clean up resources using Dispose()
Q2: Can I export multiple lists into separate CSV files in one go?
Yes. Loop through your lists and save each as a separate CSV:
lists = {
"fruits": ["Apple", "Banana", "Cherry"],
"scores": [85, 92, 78]
}
for name, data in lists.items():
wb = Workbook()
wb.Worksheets.Clear()
ws = wb.Worksheets.Add(name)
for i, val in enumerate(data):
ws.Range[i + 1, 1].Value = str(val)
wb.SaveToFile(f"{name}.csv", FileFormat.CSV)
wb.Dispose()
Q3: How to format numbers (e.g., currency, decimals) in CSV?
CSV stores numbers as plain text, so formatting must be applied before saving:
ws.Range["A1:A10"].NumberFormat = "$#,##0.00"
This ensures numbers appear as $1,234.56 in the CSV. For more number formatting options, refer to: Set the Number Format in Python
Q4: Does Spire.XLS for Python work on all operating systems?
Yes! Spire.XLS for Python is cross-platform and supports Windows, macOS, and Linux systems.

CSV (Comma-Separated Values) is a widely used format for tabular data. It’s lightweight, easy to generate, and common in reports, logs, exports, and data feeds. However, modern web applications, APIs, and NoSQL databases prefer JSON for its hierarchical structure, flexibility, and compatibility with JavaScript.
Converting CSV to JSON in Python is a practical skill for developers who need to:
- Prepare CSV data for APIs and web services
- Migrate CSV exports into NoSQL databases like MongoDB
- Transform flat CSV tables into nested JSON objects
- Enable data exchange between systems that require hierarchical formats
This step-by-step tutorial shows you how to convert CSV files to JSON in Python, including flat JSON, nested JSON, JSON with grouped data, and JSON Lines (NDJSON). By the end, you’ll be able to transform raw CSV datasets into well-structured JSON ready for APIs, applications, or data pipelines.
Table of Contents
- Why Convert CSV to JSON
- Python CSV to JSON Converter - Installation
- Convert CSV to Flat JSON in Python
- Convert CSV to Nested JSON in Python
- Convert CSV to JSON with Grouped Data in Python
- Convert CSV to JSON Lines (NDJSON) in Python
- Handle Large CSV Files to JSON Conversion
- Best Practices for CSV to JSON Conversion
- Conclusion
- FAQs
Why Convert CSV to JSON?
CSV files are lightweight and tabular, but they lack hierarchy. JSON allows structured, nested data ideal for APIs and applications. Converting CSV to JSON enables:
- API Integration: Most APIs prefer JSON over CSV
- Flexible Data Structures: JSON supports nested objects
- Web Development: JSON works natively with JavaScript
- Database Migration: NoSQL and cloud databases often require JSON
- Automation: Python scripts can process JSON efficiently
Python CSV to JSON Converter – Installation
To convert CSV files to JSON in Python, this tutorial uses Spire.XLS for Python to read CSV files and Python’s built-in json module to handle JSON conversion.
Why Spire.XLS?
It simplifies working with CSV files by allowing you to:
- Load CSV files into a workbook structure for easy access to rows and columns
- Extract and manipulate data efficiently, cell by cell
- Convert CSV to JSON in flat, nested, or NDJSON formats
- Export CSV to Excel, PDF, and other formats if needed
Install Spire.XLS
You can install the library directly from PyPI using pip:
pip install spire.xls
If you need detailed guidance on the installation, refer to this tutorial: How to Install Spire.XLS for Python on Windows.
Once installed, you’re ready to convert CSV data into different JSON formats.
Convert CSV to Flat JSON in Python
Converting a CSV file to flat JSON turns each row into a separate JSON object and uses the first row as keys, making the data organized and easy to work with.
Steps to Convert CSV to Flat JSON
- Load the CSV file into a workbook using Workbook.LoadFromFile.
- Select the worksheet.
- Extract headers from the first row.
- Iterate through each subsequent row to map values to headers.
- Append each row dictionary to a list.
- Write the list to a JSON file using json.dump.
Code Example
from spire.xls import *
import json
# Load the CSV file into a workbook object
workbook = Workbook()
workbook.LoadFromFile("employee.csv", ",")
# Select the desired worksheet
sheet = workbook.Worksheets[0]
# Extract headers from the first row
headers = [sheet.Range[1, j].Text for j in range(1, sheet.LastColumn + 1)]
# Map the subsequent CSV rows to JSON objects
data = []
for i in range(2, sheet.LastRow + 1):
row = {headers[j-1]: sheet.Range[i, j].Text for j in range(1, sheet.LastColumn + 1)}
data.append(row)
# Write JSON to file
with open("output_flat.json", "w", encoding="utf-8") as f:
json.dump(data, f, indent=4, ensure_ascii=False)
# Clean up resources
workbook.Dispose()
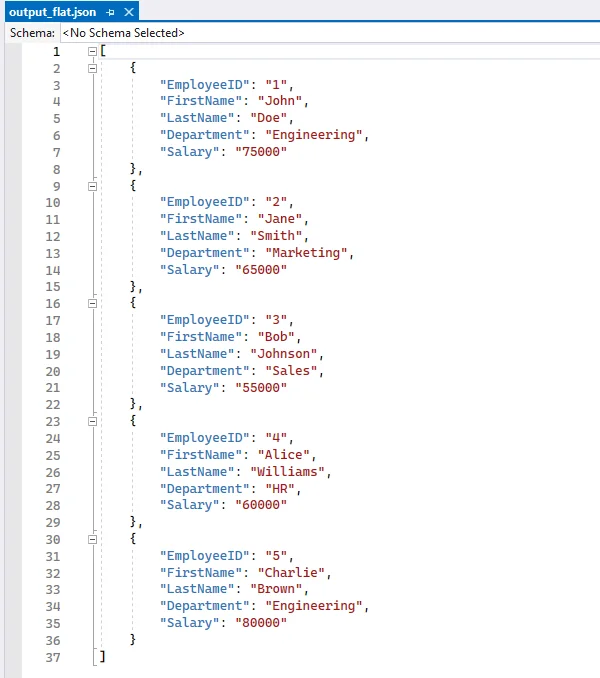
Output JSON
Convert CSV to Nested JSON in Python
When a single CSV row contains related columns, you can combine these columns into nested JSON objects. For example, merging the Street and City columns into an Address object. Each CSV row produces one JSON object, which can include one or more nested dictionaries. This approach is ideal for scenarios requiring hierarchical data within a single record, such as API responses or application configurations.
Steps to Convert CSV to Nested JSON
- Load the CSV file and select the worksheet.
- Decide which columns should form a nested object (e.g., street and city).
- Iterate over rows and construct each JSON object with a sub-object for nested fields.
- Append each nested object to a list.
- Write the list to a JSON file with json.dump.
Code Example
from spire.xls import *
import json
# Create a Workbook instance and load the CSV file (using comma as the delimiter)
workbook = Workbook()
workbook.LoadFromFile("data.csv", ",")
# Get the first worksheet from the workbook
sheet = workbook.Worksheets[0]
# List to store the converted JSON data
data = []
# Loop through rows starting from the second row (assuming the first row contains headers)
for i in range(2, sheet.LastRow + 1):
# Map each row into a JSON object, including a nested "Address" object
row = {
"ID": sheet.Range[i, 1].Text, # Column 1: ID
"Name": sheet.Range[i, 2].Text, # Column 2: Name
"Address": { # Nested object for address
"Street": sheet.Range[i, 3].Text, # Column 3: Street
"City": sheet.Range[i, 4].Text # Column 4: City
}
}
# Add the JSON object to the list
data.append(row)
# Write the JSON data to a file with indentation for readability
with open("output_nested.json", "w", encoding="utf-8") as f:
json.dump(data, f, indent=4, ensure_ascii=False)
# Release resources used by the workbook
workbook.Dispose()
Output Nested JSON

Convert CSV to JSON with Grouped Data
When multiple CSV rows belong to the same parent entity, you can group these rows under a single parent object. For example, an order with multiple items can store all items in an items array under one order object. Each parent object has a unique key (like order_id), and its child rows are aggregated into an array. This method is useful for e-commerce orders, data pipelines, or any scenario requiring grouped hierarchical data across multiple rows.
Steps to Convert CSV to JSON with Grouped Data
- Use defaultdict to group rows by a parent key (order_id).
- Iterate rows and append child items to the parent object.
- Convert the grouped dictionary to a list of objects.
- Write the JSON file.
Code Example
from collections import defaultdict
from spire.xls import *
import json
# Create a Workbook instance and load the CSV file (comma-separated)
workbook = Workbook()
workbook.LoadFromFile("orders.csv", ",")
# Get the first worksheet from the workbook
sheet = workbook.Worksheets[0]
# Use defaultdict to store grouped data
# Each order_id maps to a dictionary with customer name and a list of items
data = defaultdict(lambda: {"customer": "", "items": []})
# Loop through rows starting from the second row (skip header row)
for i in range(2, sheet.LastRow + 1):
order_id = sheet.Range[i, 1].Text # Column 1: Order ID
customer = sheet.Range[i, 2].Text # Column 2: Customer
item = sheet.Range[i, 3].Text # Column 3: Item
# Assign customer name (same for all rows with the same order_id)
data[order_id]["customer"] = customer
# Append item to the order's item list
data[order_id]["items"].append(item)
# Convert the grouped dictionary into a list of objects
# Each object contains order_id, customer, and items
result = [{"order_id": oid, **details} for oid, details in data.items()]
# Write the grouped data to a JSON file with indentation for readability
with open("output_grouped.json", "w", encoding="utf-8") as f:
json.dump(result, f, indent=4, ensure_ascii=False)
# Release resources used by the workbook
workbook.Dispose()
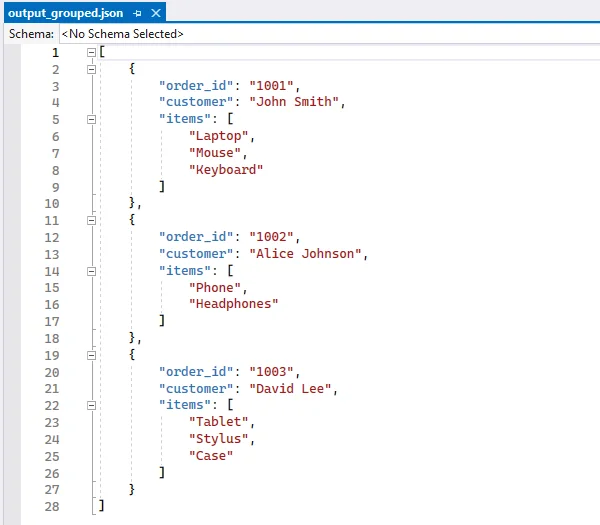
Output JSON with Grouped Data
If you're also interested in saving JSON back to CSV, follow our guide on converting JSON to CSV in Python.
Convert CSV to JSON Lines (NDJSON) in Python
JSON Lines (also called NDJSON – Newline Delimited JSON) is a format where each line is a separate JSON object. It is ideal for large datasets, streaming, and big data pipelines.
Why use NDJSON?
- Streaming-friendly: Process one record at a time without loading the entire file into memory.
- Big data compatibility: Tools like Elasticsearch, Logstash, and Hadoop natively support NDJSON.
- Error isolation: If one line is corrupted, the rest of the file remains valid.
Code Example
from spire.xls import *
import json
# Create a Workbook instance and load the CSV file (comma-separated)
workbook = Workbook()
workbook.LoadFromFile("employee.csv", ",")
# Get the first worksheet from the workbook
sheet = workbook.Worksheets[0]
# Extract headers from the first row to use as JSON keys
headers = [sheet.Range[1, j].Text for j in range(1, sheet.LastColumn + 1)]
# Open a file to write JSON Lines (NDJSON) format
with open("output.ndjson", "w", encoding="utf-8") as f:
# Loop through each row in the worksheet, starting from the second row
for i in range(2, sheet.LastRow + 1):
# Map each header to its corresponding cell value for the current row
row = {headers[j - 1]: sheet.Range[i, j].Text for j in range(1, sheet.LastColumn + 1)}
# Write the JSON object to the file followed by a newline
# Each line is a separate JSON object (NDJSON format)
f.write(json.dumps(row, ensure_ascii=False) + "\n")
# Release resources used by the workbook
workbook.Dispose()
Output NDJSON
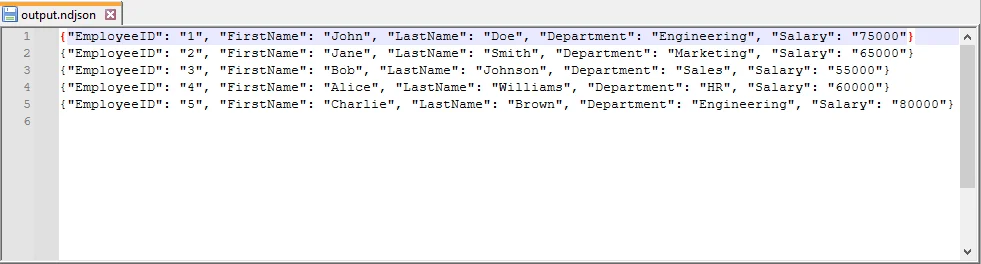
Handle Large CSV Files to JSON Conversion
For large CSV files, it’s not always efficient to load everything into memory at once. With Spire.XLS, you can still load the file as a worksheet, but instead of appending everything into a list, you can process rows in chunks and write them to JSON incrementally. This technique minimizes memory usage, making it suitable for big CSV to JSON conversion in Python.
Code Example
from spire.xls import *
import json
# Create a Workbook instance and load the CSV file (comma-separated)
workbook = Workbook()
workbook.LoadFromFile("large.csv", ",")
# Get the first worksheet from the workbook
sheet = workbook.Worksheets[0]
# Open a JSON file for writing, with UTF-8 encoding
with open("large.json", "w", encoding="utf-8") as json_file:
json_file.write("[\n") # Start the JSON array
first = True # Flag to handle commas between JSON objects
# Loop through each row in the worksheet, starting from the second row
# (skip the header row)
for i in range(2, sheet.LastRow + 1):
# Create a dictionary mapping each header to its corresponding cell value
row = {sheet.Range[1, j].Text: sheet.Range[i, j].Text
for j in range(1, sheet.LastColumn + 1)}
# Add a comma before the object if it is not the first row
if not first:
json_file.write(",\n")
# Write the JSON object to the file
json.dump(row, json_file, ensure_ascii=False)
first = False # After the first row, set the flag to False
json_file.write("\n]") # End the JSON array
# Release resources used by the workbook
workbook.Dispose()
Best Practices for CSV to JSON Conversion
When converting CSV to JSON in Python, follow these best practices can ensure data integrity and compatibility:
- Always Use CSV headers as JSON keys.
- Handle missing values with null or default values.
- Normalize data types (convert numeric strings to integers or floats).
- Use UTF-8 encoding for JSON files.
- Stream large CSV files row by row to reduce memory usage.
- Validate JSON structure after writing, especially for nested JSON.
Conclusion
Converting CSV to JSON in Python helps you work with data more efficiently and adapt it for modern applications. Using Python and libraries like Spire.XLS for Python, you can:
- Convert flat CSV files into structured JSON objects.
- Organize related CSV data into nested JSON structures.
- Group multiple CSV rows into coherent JSON objects for analysis or APIs.
- Create JSON Lines (NDJSON) for large datasets or streaming scenarios.
- Process large CSV files efficiently without loading everything into memory.
These approaches let you handle CSV data in a way that fits your workflow, making it easier to prepare, share, and analyze data for APIs, applications, or big data pipelines.
FAQs
Q1: How do I convert CSV to JSON with headers in Python?
A1: If your CSV has headers, use the first row as keys and map subsequent rows to dictionaries. With Spire.XLS, you can access sheet.Range[1, j].Text for headers.
Q2: How do I convert CSV to nested JSON in Python?
A2: Identify related columns (e.g., Street and City) and group them into a sub-object when building JSON. See the Nested JSON example above.
Q3: What’s the best way to handle large CSV files when converting to JSON?
A3: Use a streaming approach where each row is processed and written to JSON immediately, instead of storing everything in memory.
Q4: Can Spire.XLS handle CSV files with different delimiters?
A4: Yes, when loading the CSV with Spire.XLS’s LoadFromFile method, specify the delimiter (e.g., "," or ";").
Q5: How to convert JSON back to CSV in Python?
A5: Use Python’s json module to read the JSON file into a list of dictionaries, then write it back to CSV using Spire.XLS for Python for advanced formatting and export options.
Q6: How to convert CSV to JSON Lines (NDJSON) in Python?
A6: JSON Lines (NDJSON) writes each JSON object on a separate line. Stream each CSV row to the output file line by line, which is memory-efficient and compatible with big data pipelines like Elasticsearch or Logstash.
Automate Excel Writing in Python: Professional Reporting Practices
2025-09-18 09:49:49 Written by jie zou
Excel remains one of the most widely used tools for organizing, analyzing, and presenting data. From financial reports to operational dashboards, many workflows require exporting data into Excel for better readability and sharing. Instead of manually entering information, automating Excel file writing with Python makes it faster, more reliable, and more scalable.
This tutorial explains how to write data to Excel files with Python, covering structured data insertion, formatting, and exporting. The examples use a Python Excel library that allows programmatic creation and customization of workbooks.
What's Included in This Tutorial:
- Setting Up the Environment
- Writing Data into Excel Files
- Formatting While Writing
- Working with Multiple Worksheets
- Best Practices
- Conclusion
- FAQ
Setting Up the Environment
Before writing Excel files in Python, you need a library that supports creating, loading, and saving workbooks programmatically. Spire.XLS for Python provides a complete API for these operations, enabling automated report generation and data processing.
Install the package using pip:
pip install spire.xls
Once installed, you can handle Excel files using three core operations:
- Creating a new workbook – initialize a new Excel document with Workbook().
- Loading an existing workbook – open an existing Excel file using LoadFromFile().
- Saving a workbook – export the workbook to the desired format with SaveToFile(), supporting .xlsx, .xls, CSV, and more.
These operations form the foundation for further data writing, formatting, and multi-sheet management in Python.
Writing Data into Excel Files with Python
In real-world business scenarios, you may need to create new Excel files, update existing reports, or write different types of data—such as text, numbers, dates, and formulas. This section demonstrates how to efficiently write and manage data in Excel files with Python across these common use cases.
Appending Data to an Existing Excel File
When you need to update an existing Excel workbook with new information—such as adding recent sales records, inventory updates, or additional data rows—you can open the file, append the data programmatically, and save it without overwriting existing content:
from spire.xls import Workbook, ExcelVersion
workbook = Workbook()
workbook.LoadFromFile("Sample.xlsx")
sheet = workbook.Worksheets[0]
# Add new rows
sheet.Range["A4"].Value = "Laptop"
sheet.Range["B4"].NumberValue = 5
sheet.Range["C4"].NumberValue = 1200.00
sheet.Range["A5"].Value = "Monitor"
sheet.Range["B5"].NumberValue = 10
sheet.Range["C5"].NumberValue = 300.00
workbook.SaveToFile("output/updated_excel.xlsx", ExcelVersion.Version2016)
Key elements used:
- LoadFromFile() – loads an existing Excel file into the workbook object.
- Range["CellName"] – references a specific cell in the sheet using its name.
- Value / NumberValue – assigns text or numeric data to cells.
- SaveToFile() – saves the workbook to a file in the specified Excel format.
This method allows continuous updates to reports while preserving existing content.
Example showing appended data:
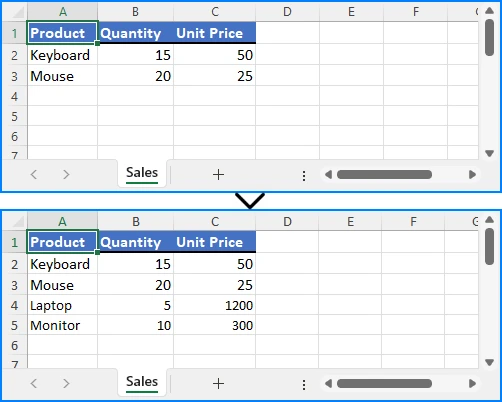
Writing Multiple Rows and Columns to a New Excel File
When dealing with larger datasets, writing multiple rows and columns at once is much more efficient than updating individual cells one by one. This approach not only saves time but also ensures consistent data insertion across the worksheet:
from spire.xls import Workbook, ExcelVersion
# Create a new Excel workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
orders = [
["OrderID", "Customer", "Product", "Quantity", "Price", "Status"],
[1001, "Alice", "Laptop", 2, 1200.00, "Shipped"],
[1002, "Bob", "Monitor", 1, 300.00, "Pending"],
[1003, "Charlie", "Keyboard", 5, 45.00, "Delivered"],
[1004, "David", "Mouse", 3, 25.00, "Shipped"],
[1005, "Eva", "Tablet", 1, 450.00, "Pending"]
]
for row_index, row_data in enumerate(orders, start=1):
for col_index, value in enumerate(row_data, start=1):
if isinstance(value, (int, float)):
sheet.Range[row_index, col_index].NumberValue = value
else:
sheet.Range[row_index, col_index].Value = value
workbook.SaveToFile("output/orders.xlsx", ExcelVersion.Version2016)
Important elements in this example:
- enumerate() – provides row and column indices for looping.
- Range[row, col] – references a cell in the worksheet by its row and column indexes.
Batch writing ensures efficiency, especially when exporting database query results or operational reports.
Example showing batch data insertion:
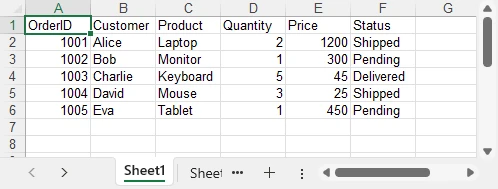
Writing Different Data Types
Excel cells can contain various types of data, such as text, numbers, dates, formulas, and more. Using the correct properties and methods ensures that each type is stored and displayed appropriately, allowing accurate calculations and proper formatting:
from spire.xls import Workbook, ExcelVersion, DateTime, TimeSpan
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Set general value
sheet.Range[2, 2].Text = "General Example"
sheet.Range[2, 3].Value = "General 123"
# Set number value
sheet.Range[3, 2].Text = "Number Example"
sheet.Range[3, 3].NumberValue = 1234.56
sheet.Range[3, 3].NumberFormat = "0.000"
# Set datetime value
sheet.Range[4, 2].Text = "Date Example"
sheet.Range[4, 3].DateTimeValue = DateTime.get_UtcNow()
# Set formula value
sheet.Range[5, 2].Text = "Formula Example"
sheet.Range[5, 5].NumberValue = 1234.56
sheet.Range[5, 6].NumberValue = 6543.21
sheet.Range[5, 3].Formula = "=SUM(E5:F5)"
# Set text
sheet.Range[6, 2].Text = "Text Example"
sheet.Range[6, 3].Text = "Text"
# Set boolean value
sheet.Range[7, 2].Text = "Boolean Example"
sheet.Range[7, 3].BooleanValue = True
sheet.AllocatedRange.AutoFitColumns()
workbook.SaveToFile("output/value_types.xlsx", ExcelVersion.Version2016)
Key functions and properties used:
- Value – assigns or retrieves the general value of a cell, suitable for text or mixed content.
- NumberValue – specifically handles numeric values in a cell, ensuring proper number formatting and calculations.
- DateTimeValue – used to input or obtain date and time values in a cell with correct formatting.
- Formula – sets or retrieves the formula expression in a cell to perform dynamic calculations.
- BooleanValue – stores or returns a Boolean (True/False) value in a cell.
- Text – retrieves the displayed text of a cell, including any applied formatting.
Proper handling of different data types is essential for accurate business calculations and reporting. For more details on supported data types, see the XlsRange API reference.
Example showing mixed data types:
Formatting Excel While Writing Data with Python
To make Excel reports clear and professional, it’s important to apply formatting while entering or updating data. This section demonstrates how to enhance readability and presentation by styling cells, setting number formats, and adjusting column widths and row heights as you write data into Excel.
Applying Cell Styles
You can enhance the readability and appearance of your Excel sheet by applying various styles to cells, such as fonts, borders, and background colors:
from spire.xls import Workbook, Color, FontUnderlineType, ExcelVersion
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Range["A1"].Value = "Product"
sheet.Range["B1"].Value = "Category"
sheet.Range["C1"].Value = "Price"
sheet.Range["D1"].Value = "Quantity"
sheet.Range["E1"].Value = "Total"
sheet.Range["A2"].Value = "MacBook Pro"
sheet.Range["B2"].Value = "Laptop"
sheet.Range["C2"].NumberValue = 999.99
sheet.Range["D2"].NumberValue = 1
sheet.Range["E2"].Formula = "=C2*D2"
sheet.Range["A3"].Value = "iPhone 16 Pro"
sheet.Range["B3"].Value = "Smartphone"
sheet.Range["C3"].NumberValue = 899.99
sheet.Range["D3"].NumberValue = 1
sheet.Range["E3"].Formula = "=C3*D3"
# Set header style
header = sheet.Range["A1:E1"]
header.Style.Font.FontName = "Arial"
header.Style.Font.Size = 14.0
header.Style.Font.IsBold = True
header.Style.Font.Underline = FontUnderlineType.Single
header.Style.Interior.Color = Color.get_LightGray()
header.Style.Borders[BordersLineType.EdgeRight].LineStyle = LineStyleType.Medium
Core components demonstrated:
- Style.Font – controls font-related settings such as bold, underline, and more (full list of supported properties can be found in the Style.Font API documentation).
- FontUnderlineType.Single – applies a single underline.
- Interior.Color – fills the cell background with a specified color.
- Borders.LineStyle – adds borders around cells.
Styled cells enhance readability and emphasize critical sections.
Setting Number Formats for Excel Cells
Numbers in Excel often require specific display formats to improve readability and presentation. Using CellRange.NumberFormat, you can control how numeric values appear, such as applying currency, percentage, or integer formats:
# Apply number formats
sheet.Range["C2:C3"].NumberFormat = "$#,##0.00" # Currency format
sheet.Range["D2:D3"].NumberFormat = "0" # Integer format
sheet.Range["E2:E3"].NumberFormat = "$#,##0.00"
Key highlights:
- NumberFormat – enables reading and setting Excel cell number formats, controlling how numbers are displayed while keeping the raw data intact.
- Format codes define display rules such as currency symbols, decimal places, or percentage styles, giving you flexibility in presenting numerical data.
With proper number formatting, financial data is easier to interpret and looks more professional. For more details and a full list of format codes, see our dedicated guide on Setting Excel Cell Number Format in Python.
Adjusting Column Widths and Row Heights
Properly adjusting column widths and row heights ensures that all content is clearly visible. You can set them manually or use automatic fitting to match the content:
# Auto-fit column widths and row heights
for col in range(1, 5):
sheet.AutoFitColumn(col)
for row in range(1, 3):
sheet.AutoFitRow(row)
# Auto-fit a specific range of cells
#sheet.Range["A1:E3"].AutoFitColumns()
#sheet.Range["A1:E3"].AutoFitRows()
# Set a fixed column width and row height
sheet.Columns[1].Width = 150
sheet.Rows[1].Height = 30
workbook.SaveToFile("output/formatted_excel.xlsx", ExcelVersion.Version2016)
Key highlights:
- AutoFitColumn(colIndex) / AutoFitRow(rowIndex) – automatically adjust a single column or row to fit its content.
- CellRange.AutoFitColumns() / AutoFitRows() – automatically adjust all columns or rows within a specified cell range.
- Columns[colIndex].Width / Rows[rowIndex].Height – manually set a fixed width or height for precise control.
With these options, you can choose between automatic fitting for dynamic data or fixed dimensions for consistent layout, ensuring your Excel worksheets remain both readable and professionally formatted.
Example showing styled and auto-fitted headers:
To explore more advanced techniques for formatting Excel sheets in Python, including fonts, colors, borders, and conditional formatting, check out our dedicated guide on Formatting Excel in Python for detailed instructions.
Managing Multiple Worksheets in Excel with Python
In Excel, organizing data into multiple worksheets helps keep related information separated and easy to manage. For example, you can maintain separate sheets for sales, purchases, inventory, or other categories within the same workbook. This section demonstrates how to create, access, and manage multiple worksheets using Python.
from spire.xls import Workbook, ExcelVersion
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Name = "Sales"
sheet1 = workbook.Worksheets["Sheet2"]
sheet1.Name = "Purchases"
sheet2 = workbook.Worksheets.Add("Inventory")
sheet2.Range["A1"].Value = "ProductID"
sheet2.Range["B1"].Value = "Stock"
workbook.SaveToFile("output/multi_sheet.xlsx", ExcelVersion.Version2016)
Main features highlighted:
- Worksheets[Index] – access a worksheet by its position in the workbook (useful for iterating over all sheets or referencing the first/last sheet).
- Worksheets["SheetName"] – access a worksheet by its name, which is more readable and reliable if the sheet order might change.
- Worksheets.Add("SheetName") – create a new worksheet to organize different categories of data such as departments, sales regions, or product lines.
These methods allow you to structure your Excel file efficiently, keeping related data on separate sheets for clarity and easier management.
Example showing multiple worksheets:
Best Practices for Writing Excel Files with Python
When writing Excel files with Python, follow best practices to maintain efficiency, consistency, and usability:
- Use descriptive sheet names like “Sales_2024” instead of “Sheet1.”
- Batch write large datasets instead of individual cell updates to improve performance.
- Apply consistent formatting for headers, totals, and key columns.
- Leverage Excel formulas to maintain dynamic calculations.
- Validate data types to prevent misinterpretation in charts or formulas.
- Choose file formats suited to the audience: .xlsx for modern users, .xls only for legacy compatibility.
- Organize worksheets logically, grouping related datasets for easy navigation.
Implementing these practices avoids common pitfalls and produces professional, reusable reports.
Conclusion
Automating Excel writing in Python significantly streamlines reporting. By creating workbooks, writing data efficiently, applying styles, managing worksheets, and handling diverse data types, developers can ensure consistent, accurate, and professional Excel reports. To explore the library further, you can request a free temporary license or try the Free Spire.XLS for Python edition.
Python Excel Writing FAQ
Q1: Can Python write to an existing Excel file?
Yes, Python can load an existing workbook, append or modify data, and save it while preserving all previously entered content.
Q2: How to efficiently handle large datasets in Python?
Batch writing multiple rows and minimizing formatting during data insertion helps maintain high performance even with thousands of rows.
Q3: Can formulas be included in Excel files?
Yes, you can insert formulas, including =SUM() and more complex calculations, to keep your Excel reports dynamic and automatically updated.
Q4: Which Excel formats are supported?
Spire.XLS for Python can save files in .xlsx, .xls, CSV, and even export to PDF, covering most common use cases and compatibility needs.

CSV is one of the most common formats for exchanging tabular data because of its simplicity and wide support across platforms. However, when working with structured applications, configurations, or hierarchical data, XML often becomes the preferred choice due to its ability to represent nested relationships and enforce stricter data validation.
In this guide, we’ll explore how to convert CSV files into XML using Spire.XLS for Python. You’ll learn how to convert CSV into both Excel XML format (SpreadsheetML) and standard XML for general use. We’ll also cover how to clean and preprocess real-world CSV files—handling issues like invalid headers, missing values, special characters, and nested fields—so that your XML output is always valid and structured correctly.
Table of Contents:
- Why Convert CSV to XML
- Prerequisites
- Convert CSV to Excel XML Format
- Convert CSV to Standard XML
- Handle Real-World CSV Challenges
- Wrap Up
- FAQs
Why Convert CSV to XML
So why should developers care about converting CSV to XML? Here are some real-world use cases:
- Enterprise Data Migration: Many enterprise applications like ERP or CRM systems require XML input for bulk data import.
- Configuration & Metadata: XML is often used to store structured metadata, while raw data may come in CSV form.
- Interoperability: Some APIs, especially in finance, healthcare, and government sectors, still rely heavily on XML payloads.
- Readable Reports: XML can represent hierarchical data, making it more descriptive compared to flat CSV files.
- Validation: XML can be validated against schemas (XSD), ensuring data integrity—something CSV cannot provide out-of-the-box.
CSV is great for simplicity . XML is great for structure . By converting between them, you get the best of both worlds.
Prerequisites
Before diving into the code, let’s ensure we have the right tools:
- Python 3.7+
- Spire.XLS for Python → A professional library that provides powerful Excel manipulation capabilities.
- Standard Python Libraries → xml.etree.ElementTree, csv, and re.
You can install Spire.XLS via pip (assuming you have Python and pip installed on your system):
pip install spire.xls
Additionally, make sure you have a CSV file ready to test. A simple one might look like this:
ID,FirstName,LastName,Age,Department,Salary
1,John,Doe,30,Sales,5000
2,Jane,Smith,28,Marketing,4500
3,Mike,Johnson,35,IT,6000
4,Emily,Brown,32,HR,4800
Convert CSV to Excel XML Format in Python
The first approach is to convert CSV into Excel-compatible XML . This format is sometimes called SpreadsheetML , introduced in Excel 2003. It allows CSV data to be transformed into a fully structured XML file that Excel can open directly.
With Spire.XLS, this process is straightforward:
from spire.xls import *
# Create a Workbook
workbook = Workbook()
# Load CSV into the first worksheet
workbook.LoadFromFile("input.csv", ",", 1, 1)
# Save as XML Spreadsheet format
workbook.SaveAsXml("output.xml")
# Dispose resources
workbook.Dispose()
How it Works
- LoadFromFile() – Reads the CSV file into the workbook.
- SaveAsXml() – Saves it as SpreadsheetML XML format.
This approach is best if your end goal is Excel compatibility rather than pure XML processing.
Output:
You may also like: Convert Excel to Excel-Compatible XML in Python
Convert CSV to Standard XML in Python
Sometimes, you need a custom XML format rather than Excel-compatible XML. For instance, you may need an XML structure like:
<Employees>
<Employee>
<ID>1</ID>
<FirstName>John</FirstName>
<LastName>Doe</LastName>
<Department>Sales</Department>
<Salary>5000</Salary>
</Employee>
</Employees>
Here’s how you can achieve that:
from spire.xls import *
import xml.etree.ElementTree as ET
# Step 1: Load CSV into workbook
workbook = Workbook()
workbook.LoadFromFile("input.csv", ",", 1, 1)
sheet = workbook.Worksheets[0]
# Step 2: Create root element
root = ET.Element("Root")
# Step 3: Loop through rows and build XML
# Assume first row is header
headers = []
for col in range(1, sheet.Columns.Count + 1):
cell_value = sheet.Range[1, col].Value
if not cell_value:
break
headers.append(cell_value)
# Add data rows
for row in range(2, sheet.Rows.Count + 1):
# Stop if row is empty
if not sheet.Range[row, 1].Value:
break
record = ET.SubElement(root, "Record")
for col, header in enumerate(headers, start=1):
cell_value = sheet.Range[row, col].Value
field = ET.SubElement(record, header)
field.text = cell_value if cell_value else ""
# Step 4: Save to XML file
tree = ET.ElementTree(root)
tree.write("output.xml", encoding="utf-8", xml_declaration=True)
# Cleanup
workbook.Dispose()
Explanation
- Step 1: Load the CSV into a worksheet.
- Step 2: Create a root <Root> element for the XML tree.
- Step 3: Extract headers from the first row and use them as XML tags.
- Step 4: Loop through rows and add <Record> elements with child fields.
- Step 5: Save the XML to a file.
This approach is flexible because you can customize the XML schema however you like (e.g., change <Record> to <Employee>).
Output:
You may also like: How to Convert XML to CSV in Python
Handle Real-World CSV Challenges
Converting a “perfect” CSV to XML is easy. But real-world CSVs are rarely perfect. Let’s discuss common issues developers face and how to fix them.
-
Headers with Invalid XML Names
- Problem: CSV headers like Employee ID or 123Name are invalid XML tags since XML element names cannot have spaces, start with numbers, or include special characters.
- Fix: Clean headers by replacing spaces with underscores (_) or prefixing numeric headers with a safe string.
-
Empty or Missing Values
- Problem: Real-world CSVs often have missing cells. When converted to XML, missing cells may create malformed structures.
- Fix: Replace blanks with placeholders (NULL, Unknown, or 0).
-
Special Characters in Data
- Problem: Characters like <, >, & inside CSV values can break XML if not escaped.
- Fix: Always escape XML entities properly (<, >, &).
-
Nested / Hierarchical Data in Flat CSV
- Problem: Some CSV cells contain multiple values or hierarchical information (e.g., lists of products) within a single field. Converting directly to XML will flatten the data, losing the intended hierarchy.
Example:
OrderID,Customer,Products
1001,John,"Laptop;Mouse;Keyboard"
Flattened XML (bad):
<Products>Laptop;Mouse;Keyboard</Products>
- Fix: Detect list-like or nested values and expand them into child XML elements or multiple rows, preserving the structure in XML.
Hierarchical XML (fixed):
<Products>
<Product>Laptop</Product>
<Product>Mouse</Product>
<Product>Keyboard</Product>
</Products>
Automating Fixes with clean_csv
Instead of cleaning data manually, you can automate preprocessing with the following helper function:
import csv
import re
def clean_csv(input_file, output_file, nested_columns=None, nested_delimiter=";"):
if nested_columns is None:
nested_columns = []
cleaned_rows = []
# Escape special characters for XML
def escape_xml(text):
return (text.replace("&", "&")
.replace("<", "<")
.replace(">", ">")
.replace('"', """)
.replace("'", "'"))
with open(input_file, "r", encoding="utf-8") as infile:
reader = csv.reader(infile)
headers = next(reader)
# Clean headers
cleaned_headers = []
for h in headers:
h = h.strip()
h = re.sub(r"\s+", "_", h) # Replace spaces with _
h = re.sub(r"[^a-zA-Z0-9_]", "", h) # Remove invalid chars
if re.match(r"^\d", h): # Cannot start with digit
h = "Field_" + h
cleaned_headers.append(h)
cleaned_rows.append(cleaned_headers)
# Read all rows first
raw_rows = []
for row in reader:
# Handle empty cells
row = [cell if cell.strip() != "" else "NULL" for cell in row]
raw_rows.append(row)
# Expand nested columns
if nested_columns:
expanded_rows = [cleaned_headers] # include header
for row in raw_rows:
row_variants = [row]
for col_name in nested_columns:
if col_name not in cleaned_headers:
continue
col_index = cleaned_headers.index(col_name)
temp = []
for variant in row_variants:
cell_value = variant[col_index]
# Only split on the nested delimiter, not on XML special chars
if nested_delimiter in cell_value:
items = [item.strip() for item in cell_value.split(nested_delimiter)]
for item in items:
new_variant = variant.copy()
new_variant[col_index] = item
temp.append(new_variant)
else:
temp.append(variant)
row_variants = temp
expanded_rows.extend(row_variants)
cleaned_rows = expanded_rows
else:
cleaned_rows.extend(raw_rows)
# Escape special characters after expansion
final_rows = [cleaned_rows[0]] # header
for row in cleaned_rows[1:]:
final_row = [escape_xml(cell) for cell in row]
final_rows.append(final_row)
# Write cleaned CSV
with open(output_file, "w", newline="", encoding="utf-8") as outfile:
writer = csv.writer(outfile)
writer.writerows(final_rows)
print(f"Cleaned CSV saved to {output_file}")
You can invoke the clean_csv function by passing the input CSV file path, output CSV file path, and optionally the columns to expand for nested values.
# File paths
input_file = r"C:\Users\Administrator\Desktop\input.csv"
output_file = r"C:\Users\Administrator\Desktop\cleaned_output.csv"
# Specify columns that may contain nested values
nested_columns = ["Products"] # you can add more, e.g., ["Products", "Reviews"]
# Call the clean_csv function
clean_csv(input_file, output_file, nested_columns=nested_columns, nested_delimiter=";")
This function ensures your CSV is safe and clean before converting it to XML.
It helps:
- Clean headers (valid XML names)
- Handle empty cells
- Expand nested values in any specified column(s)
- Escape special characters for XML
- Write a clean, UTF-8 CSV ready for XML conversion
Wrap Up
Converting CSV to XML in Python with Spire.XLS is both powerful and flexible. If you only need Excel-readable XML, saving directly to SpreadsheetML is the quickest option. If you need custom XML structures for APIs, migrations, or reporting, you can build standard XML using xml.etree.ElementTree.
Real-world CSVs are messy. They may have missing values, invalid headers, special characters, or nested lists. By integrating a preprocessing step (like the clean_csv function), you ensure that your XML output is both valid and meaningful.
Whether you’re preparing data for enterprise integration, creating structured reports, or exchanging information with legacy systems, this workflow gives you the best of both worlds: the simplicity of CSV and the structure of XML.
FAQs
Q1: Can I convert very large CSV files to XML?
Yes, but for very large files, you should use a streaming approach (processing rows one by one) to avoid memory issues.
Q2: Does Spire.XLS support direct conversion to XML without custom code?
Yes. Saving as SpreadsheetML is built-in. But for custom XML, you’ll need to write Python code as shown.
Q3: How do I handle special characters automatically?
Use the escape_xml helper or Python’s built-in xml.sax.saxutils.escape().
Q4: What if my CSV has nested data in multiple columns?
You can pass multiple column names into nested_columns when calling clean_csv.
Q5: Can I validate the generated XML?
Yes. After generating XML, validate it against an XSD schema if your system requires strict formatting.
Get a Free License
To fully experience the capabilities of Spire.XLS for Python without any evaluation limitations, you can request a free 30-day trial license.
