Convert Word to TIFF (Adobe, Online & Python)
Table of Contents
Install with Pypi
pip install Spire.Doc pip install pillow
Related Links

Converting Word to TIFF might seem like a niche task, but it's surprisingly essential for many professionals. TIFF (Tagged Image File Format) is prized for its high quality, lossless compression, and compatibility with graphic design, printing, and legal industries. Whether you need to preserve formatting for a contract, share a document with high-resolution images, or meet specific submission requirements, knowing how to convert Word to TIFF correctly is key.
This guide explores three efficient methods to convert Word DOC/DOCX to TIFF - using Adobe Acrobat, online tools, and Python automation.
- What is TIFF? Key Features
- Reliable Tools for Word to TIFF Conversion
- How to Convert Word to TIFF: 3 Easy Methods
- Final Thoughts
What is TIFF? Key Features
TIFF isn't your average image format like JPEG or PNG. It's a robust, flexible, lossless raster format designed for high-quality, detail preservation, and versatility. Key characteristics include:
- Lossless Compression: Unlike JPEG, TIFF (especially with LZW or ZIP compression) retains all original image data without degrading quality, crucial for archival or reproduction.
- High Fidelity: Perfectly preserves intricate details like text, line art, diagrams, and scanned images.
- Multi-Page Support: A single TIFF file can contain multiple pages (like a scanned document), making it ideal for multi-page Word docs.
- Metadata Rich: Supports embedding extensive metadata (like author, copyright, keywords).
- Color Depth: Handles various color modes (1-bit B&W, Grayscale, RGB, CMYK) essential for professional printing and archiving.
Reliable Tools for Word to TIFF Conversion
Choosing the right tool depends on your needs - whether you want a quick desktop workflow, online convenience, or a programmable solution. Here's a breakdown of the best options:
| Tool Type | Tool Name | Key Features |
| Desktop | Adobe Acrobat | Word → PDF → TIFF conversion, high-quality output, advanced settings. |
| Online | Zamzar | Batch conversion, drag-and-drop interface, no software needed. |
| Code-Based | Python (Spire.Doc + Pillow) | Automates bulk conversions, integrates with workflows. |
How to Convert Word to TIFF: 3 Easy Methods
Method 1: Adobe Acrobat Pro (Professional Conversion)
Adobe Acrobat supports converting Word to PDF and then exporting as TIFF. This method is perfect for complex documents with images, tables, or custom layouts, as Acrobat's advanced rendering minimizes formatting errors.
Steps:
1. Open your Word document in Acrobat:
- Go to "File -> Create -> PDF from File" .
- Select a .docx or .doc document and click "Open". Acrobat will automatically convert the Word to a PDF in the background.
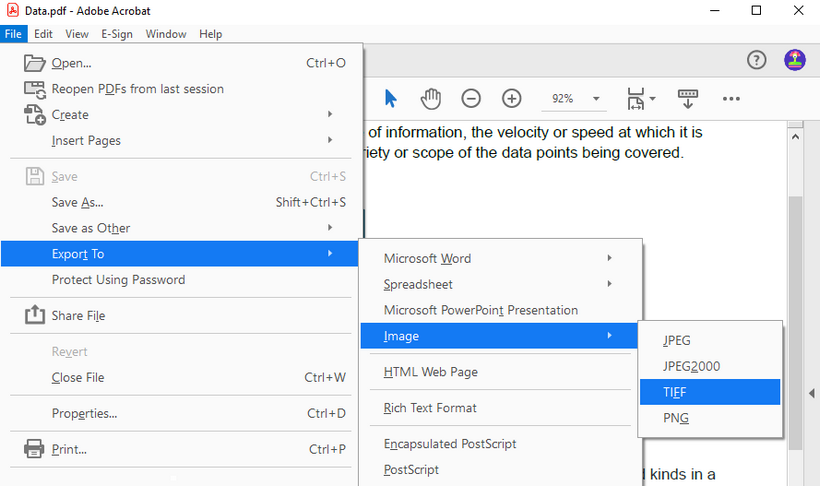
2. Convert the PDF to TIFF:
- Once the PDF is open in Acrobat, go to "File -> Export To -> Image -> TIFF".
- Select the settings icon to change the export preferences, such as customizing resolution, color space, and compression.
Pros: High accuracy for complex docs, secure, preserves formatting well.
Cons: Requires paid subscription, offline access requires desktop installation.
Method 2: Free Online Converters (Quick, for Small Files)
For one-off conversions without installing software, online tools offer a convenient solution for converting simple documents like single-page letters or basic resumes.
Steps:
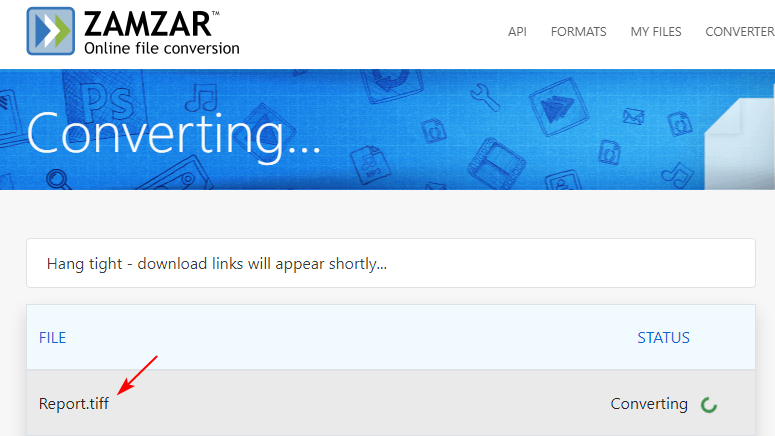
- Go to the free converter's website (e.g.,Zamzar/ Convertio).
- Upload your Word file (from your computer, Google Drive, or Dropbox).
- Select TIFF as the output format.
- Click "Convert" and download the output TIFF.
Pros: Free (for basic use), no software installation, cross-platform accessibility.
Cons: File size limits (usually 100MB or less), slower for large files, potential privacy risks with sensitive documents.
Method 3: Python Script (Spire.Doc + Pillow) for Automation
For developers needing to automate bulk conversions, this Python method is an ideal solution. It uses Spire.Doc for Python to handle Word files and Pillow (PIL) to create multi-page TIFFs programmatically.
Steps:
1. Install Required Libraries
First, install the necessary tools via pip:
pip install Spire.Doc
pip install pillow
2. Run the Word to TIFF Conversion Script
Use the below Python code to convert a Word document to a multi-page TIFF:
from spire.doc import *
from spire.doc.common import *
from PIL import Image
from io import BytesIO
# Create a Document object
doc = Document()
# Load a Word document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.docx")
# Create an empty list to store PIL Images
images = []
# Iterate through pages in the document
for i in range(doc.GetPageCount()):
# Convert a specific page to image stream
with doc.SaveImageToStreams(i, ImageType.Bitmap) as imageData:
# Open a specific image stream as a PIL image
img = Image.open(BytesIO(imageData.ToArray()))
# Append the PIL image to list
images.append(img)
# Save the PIL Images as a multi-page TIFF file
images[0].save("Output/ToTIFF.tiff", save_all=True, append_images=images[1:])
# Dispose resources
doc.Dispose()
Bulk Processing: Wrap the script in a loop to convert all Word files in a folder:
import os
for file in os.listdir("F:\\Reports"):
if file.endswith((".docx", ".doc")):
doc.LoadFromFile(os.path.join("F:\\Reports", file))
# Insert word to tiff conversion code here
Pros: Full programmatic control, automates bulk conversions, no dependency on Adobe.
Cons: Needs basic coding skills, requires library setup, not ideal for non-technical users.

Tip: Request a free trial license here to remove the watermark.
Final Thoughts
Converting Word to TIFF is essential for long-term preservation of documents. This article provides three actionable Word-to-TIFF conversion methods, tailored to different needs. Whether you're a professional needing precision (Adobe Acrobat), a casual user seeking speed (online tools), or a developer automating bulk tasks (Python scripts), you now know the best method to choose. By breaking down pros, cons, and step-by-step processes, it eliminates confusion, helping you secure sensitive files and get high-quality TIFF outputs.
See Also
Spire.PDF for Android via Java 10.6.8 supports extracting text from PDF
We’re excited to announce the release of Spire.PDF for Android via Java 10.6.8. This update supports extracting text from PDFs, finding and highlighting text, and finding and replacing text. Additionally, an issue related to PDF encryption has been fixed. More details are provided below.
Here is a list of changes made in this release:
| Category | ID | Description |
| Adjustment | - | Adjusted the license applying method to “com.spire.pdf.license.LicenseProvider.setLicenseKey("");”. |
| New feature | - | Added support for 'text extraction' functionality using the 'PdfTextExtractor' class.
for (PdfPageBase page : (Iterable<PdfPageBase>) doc.getPages()) {
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
PdfTextExtractOptions option = new PdfTextExtractOptions();
buffer.append(textExtractor.extract(option));
}
|
| New feature | - | Added support for 'finding and highlighting' functionality using the 'PdfTextFinder' class.
for (PdfPageBase pageObj :(Iterable<PdfPageBase>) pdf.getPages()) {
PdfTextFinder finds = new PdfTextFinder(pageObj);
PdfTextFindOptions Options = new PdfTextFindOptions();
Options.setTextFindParameter(EnumSet.of(TextFindParameter.None));
List<PdfTextFragment> result = finds.find("science",Options);
for (PdfTextFragment find : result)
{
find.highLight();
}
}
|
| New feature | - | Added support for 'finding and replacing' functionality using the 'PdfTextFinder' class.
PdfTextFinder finds = new PdfTextFinder(page);
PdfTextFindOptions Options = new PdfTextFindOptions();
Options.setTextFindParameter(EnumSet.of(TextFindParameter.None));
List<PdfTextFragment> result = finds.find("Spire.PDF for Java",Options);
for (PdfTextFragment find : result)
{
RectF rec = new RectF();
rec.set(find.getPositions()[0].x, find.getPositions()[0].y, find.getSizes()[0].getWidth()+find.getPositions()[0].x, find.getSizes()[0].getHeight()+find.getPositions()[0].y);
page.getCanvas().drawRectangle(PdfBrushes.getWhite(), rec);
// Draws new text as defined font and color
page.getCanvas().drawString(newText, font, brush, rec);
}
|
| Bug | SPIREPDF-7550 | Fixed the issue where the field names of text boxes were garbled when encrypting PDF documents. |
Spire.Office for Java 10.7.0 is released
We're pleased to announce the release of Spire.Office for Java 10.7.0. In this version, the Spire.Doc for Java supports the "Two Lines in One" function. Spire.XLS for Java supports Array data binding in MarkerDesigner. Spire.PDF for Java supports converting PDF to Markdown. Spire.OCR for Java supports automatically rotating images. In addition, many known issues that occurred when converting and processing Word/ Excel/ PDF/PowerPoint files have been successfully fixed. More details are listed below.
Here is a list of changes made in this release
Spire.Doc for Java
| Category | ID | Description |
| New feature | SPIREDOC-11113 SPIREDOC-11320 SPIREDOC-11338 |
Supports the "Two Lines in One" function. |
| Bug | SPIREDOC-11280 | Fixes the issue where MailMerge.executeWidthRegion(dataSource) incorrectly reads image paths from XML. |
| Bug | SPIREDOC-11283 | Fixes the issue that Word document comparison results were incorrect. |
| Bug | SPIREDOC-11296 | Fixes the issue that the program threw the "java.lang.ClassCastException" when loading Word documents. |
| Bug | SPIREDOC-11297 | Fixes the issue where the program would hang for extended periods when loading Word documents. |
| Bug | SPIREDOC-11300 | Fixes the issue that page numbers were incorrect when converting Word to PDF. |
| Bug | SPIREDOC-11304 | Fixes the issue that output file sizes were excessively large when converting Word to PDF. |
| Bug | SPIREDOC-11306 | Fixes the issue that content was missing during Word to PDF conversion. |
| Bug | SPIREDOC-11337 | Fixes the issue that the program threw "Culture Name: - is not a supported culture" when loading .odt documents. |
| Bug | SPIREDOC-11276 | Fixes the issue where accepting revisions did not affect the content in content controls. |
| Bug | SPIREDOC-11314 | Fixes the issue where converting Word to PDF caused a "NullPointerException" to be thrown. |
| Bug | SPIREDOC-11325 | Fixes the issue where retrieving Word document properties was incorrect. |
| Bug | SPIREDOC-11333 | Fixes the issue where converting Word to Markdown resulted in disorganized bullet points. |
| Bug | SPIREDOC-11360 | Fixes the issue where converting Word to PDF caused vertically oriented text in tables to be incorrect. |
| Bug | SPIREDOC-11364 | Fixes the issue where replacing bookmark content caused an "IllegalArgumentException" to be thrown. |
| Bug | SPIREDOC-11389 | Fixes the issue where loading a Word document caused an "IllegalArgumentException: List level must be less than 8 and greater than 0" to be thrown. |
| Bug | SPIREDOC-11390 | Fixes the issue where accepting revisions did not produce the correct effect. |
| Bug | SPIREDOC-11398 | Fixes the issue where using "pictureWatermark.setPicture(bufferedImage)" caused a "java.lang.NullPointerException" to be thrown. |
Spire.XLS for Java
| Category | ID | Description |
| New feature | SPIREXLS-5874 | Supports Array data binding in MarkerDesigner.
Workbook workbook = new Workbook();
// Get the first worksheet from the workbook
Worksheet sheet = workbook.getWorksheets().get(0);
// Set the value of cell range A1 to "&=Array"
sheet.getCellRange("A1").setValue("&=Array");
// Add a parameter named "Array" with an array of strings as its value
workbook.getMarkerDesigner().addArray("Array", new String[] { "Spire.Xls", "Spire.Doc", "Spire.PDF", "Spire.Presentation", "Spire.Email" });
// Apply the marker design to the workbook
workbook.getMarkerDesigner().apply();
// Calculate all the values in the workbook
workbook.calculateAllValue();
// Auto-fit the rows and columns in the allocated range of the worksheet
sheet.getAllocatedRange().autoFitRows();
sheet.getAllocatedRange().autoFitColumns();
// Save the workbook to the specified file path using Excel 2013 format
workbook.saveToFile(outputFile, ExcelVersion.Version2013);
// Clean up and release resources used by the workbook
workbook.dispose();
|
| Bug | SPIREXLS-5861 SPIREXLS-5873 |
Fixes the issue that font rendering was incorrect when converting Excel to PDF in Linux environments. |
| Bug | SPIREXLS-5869 | Fixes the issue that the behavior of isWriteUnMergedColSpan(false) was incorrect when converting Excel to HTML. |
| Bug | SPIREXLS-5870 | Fixes the issue that "Invalid formula: =#REF!" error happened when loading Excel documents. |
| Bug | SPIREXLS-5875 | Fixes the issue that the layout rendering was incorrect when converting Excel to PDF. |
| Bug | SPIREXLS-5876 | Fixes the issue that the program threw a java.lang.NullPointerException error when loading Excel files. |
| Bug | SPIREXLS-5877 | Removed dependencies on sun.misc.BASE64Decoder. |
Spire.PDF for Java
| Category | ID | Description |
| New feature | SPIREPDF-5995 | Added support for converting PDF files to Markdown format.
PdfDocument doc = new PdfDocument("input.pdf");
doc.saveToFile("output.md", FileFormat.Markdown);
|
| Adjustment | SPIREPDF-7597 | Internal adjustments were made to references of "sun.misc.BASE64Decoder". |
| Bug | SPIREPDF-7405 | Fixed the issue where text became garbled when converting PDF to images. |
| Bug | SPIREPDF-7546 | Fixed the issue that caused the program to throw a "NegativeArraySizeException" when converting PDF to images. |
| Bug | SPIREPDF-7563 | Fixed the issue where the CSS directory name was incorrect when converting PDF to HTML on Linux systems. |
| Bug | SPIREPDF-7564 | Fixed the issue where content was rotated when converting OFD to PDF. |
| Bug | SPIREPDF-7596 | Fixed the issue that caused the program to throw a "NegativeArraySizeException" when using pdfGrayConverter.toGrayPdf. |
| Bug | SPIREPDF-7599 | Fixed the issue where bookmark navigation positions were incorrect when merging PDFs. |
| Bug | SPIREPDF-7622 | Fixed the issue where LicenseProvider.setLicense(path) would throw an error if the path contained backslashes (""). |
| Bug | SPIREPDF-7513 | Fixed the issue where text search was failing. |
| Bug | SPIREPDF-7532 | Fixed the issue where the printed PDF content was scaled down when the system DPI was set to 150%. |
| Bug | SPIREPDF-7548 | Fixed the issue where SVG-to-PDF conversion produced incorrect results. |
Spire.Presentation for Java
| Category | ID | Description |
| Bug | SPIREPPT-2922 | Fixed the issue where the program threw 'java. lang. OutOfCacheError: Java heap space' when splitting PowerPoint documents. |
Spire.OCR for Java
| Category | ID | Description |
| New feature | - | Added support for Linux-ARM platform. |
| New feature | SPIREOCR-84 | Added support for automatically rotating images when necessary.
ConfigureOptions configureOptions = new ConfigureOptions(); configureOptions.SetAutoRotate(true); |
| New feature | SPIREOCR-107 | Added support for preserving the original image layout in text output.
VisualTextAligner visualTextAligner = new VisualTextAligner(scanner.getText()); String scannedText = visualTextAligner.toString(); |
| Bug | SPIREOCR-103 | Fixed the issue where the cleanup of the temporary folder "temp" was not functioning correctly. |
| Bug | SPIREOCR-104 | Fixed the issue where an "Error occurred during ConfigureDependencies" message appeared when the path contained Chinese characters. |
| Bug | SPIREOCR-108 | Fixed the issue where the content extraction order was incorrect. |
Read Email in C# via IMAP and POP3 (Outlook Example Included)

Reading emails using C# is a common task in enterprise applications where automatic email processing is needed. For example, customer support systems retrieve tickets from email inboxes, financial platforms extract PDF invoices from attachments, and workflow tools react to notification emails. These applications require access to message content, metadata (sender, subject, timestamp), and attachments.
In this article, we’ll walk through how to read emails in C# using IMAP and POP3, and access Gmail or Outlook mailboxes securely with OAuth 2.0. We'll use Spire.Email for .NET, a library that simplifies email client implementation by providing a unified API for IMAP, POP3, and SMTP. It supports both OAuth and password-based authentication, and allows parsing full MIME messages including headers, bodies, and attachments.
This article covers:
- Environment Setup
- Authenticate Email Access via OAuth
- Read Emails Using IMAP in C#
- Read Emails via POP3 in C#
- Extract Attachments and Plain Text
- Summary
- Frequently Asked Questions
Environment Setup
To follow this tutorial, you’ll need the following:
- A .NET development environment (e.g., Visual Studio)
- Spire.Email for .NET (Install via NuGet: Install-Package Spire.Email)
- Access to a Gmail or Outlook account with OAuth 2.0 enabled
Spire.Email for .NET supports standard email protocols—IMAP, POP3, and SMTP—and provides built-in functionality for MIME parsing, attachments, HTML rendering, and encoding handling.
You can also try Free Spire.Email for .NET if your project is small or for evaluation.
Authenticate Email Access via OAuth
Modern email providers such as Gmail and Outlook require OAuth 2.0 for secure and token-based access to IMAP and POP3 services. Gmail still supports app passwords for POP3 in some cases, but OAuth is the preferred and more secure method.
Here’s how to use MSAL.NET to acquire an access token for Outlook:
var app = PublicClientApplicationBuilder
.Create("your-client-id")
.WithDefaultRedirectUri()
.Build();
string[] scopes = new[] { "https://outlook.office365.com/IMAP.AccessAsUser.All" };
AuthenticationResult result = await app
.AcquireTokenInteractive(scopes)
.ExecuteAsync();
string accessToken = result.AccessToken;
For Gmail, you can use Google.Apis.Auth or any OAuth 2.0 compliant method to retrieve a token with the https://mail.google.com/ scope. This token can then be passed to Spire.Email for authentication.
Read Emails Using IMAP in C# from Outlook and Gmail
To read emails from Outlook or Gmail in C#, IMAP is a widely used protocol that allows access to mailbox folders, message flags, and full message content. With Spire.Email for .NET, you can use the ImapClient class to connect securely to IMAP servers using OAuth tokens.
The following C# example demonstrates how to read emails from Outlook's IMAP server:
using Spire.Email;
using Spire.Email.IMap;
using System.Text;
class Program
{
static void Main()
{
ImapClient client = new ImapClient();
// Connect to IMAP server (Outlook)
client.Host = "outlook.office365.com";
client.Port = 993;
client.ConnectionProtocols = ConnectionProtocols.Ssl;
// Use OAuth 2.0
client.UseOAuth = true;
client.Username = "your-email@outlook.com";
client.AccessToken = "your-access-token";
client.Connect();
client.Login();
// Retrieve message count in the Inbox
int messageCount = client.GetMessageCount("Inbox");
StringBuilder messageDetails = new StringBuilder();
for (int i = 0; i <= messageCount; i++)
{
MailMessage message = client.GetFullMessage(i);
messageDetails.AppendLine("Message: " + i);
messageDetails.AppendLine("Subject: " + message.Subject);
messageDetails.AppendLine("From: " + message.From.Address);
messageDetails.AppendLine("Date: " + message.Date);
messageDetails.AppendLine("Body (HTML): " + message.BodyHtml);
}
File.WriteAllText("MessageInfo.txt", messageDetails.ToString());
client.Disconnect();
}
}
Technical Details
- ImapClient: Represents an IMAP client connection. It handles server communication and supports OAuth-based authentication via the UseOAuth property.
- Host and Port: Set the server address and port number. For Outlook, you can use "outlook.office365.com" and port 993 with SSL.
- AccessToken: Replace "your-access-token" with a valid token obtained via Microsoft or Google OAuth 2.0 flow.
- GetMessageCount("Inbox"): Retrieves the number of emails in the specified folder.
- GetFullMessage(i): Retrieves the full content of the message at the specified index as a MailMessage object.
- MailMessage: Represents an email message. Properties like Subject, From, Date, and BodyHtml allow structured access to message details.
The following screenshot shows the extracted email subject, sender, and HTML body saved from Outlook using IMAP:

By combining Spire.Email’s IMAP interface with OAuth security and flexible MIME parsing, you can reliably automate email reading in C# with full access to both content and context.
If you need examples of how to send emails, please refer to How to Send Emails Using C#.
Read Emails via POP3 in C#
If folder management and server-side search are not required, POP3 offers a simpler alternative to IMAP. The following example demonstrates how to read emails using POP3 with Spire.Email.
using Spire.Email;
using Spire.Email.Pop3;
Pop3Client popClient = new Pop3Client();
popClient.Host = "pop.gmail.com";
popClient.Port = 995;
popClient.EnableSsl = true;
popClient.Username = "your-address@gmail.com";
popClient.Password = "your-password";
// Or use OAuth
// popClient.UseOAuth = true;
// popClient.AccessToken = "your-access-token";
popClient.Connect();
popClient.Login();
for (int i = 1; i < popClient.GetMessageCount(); i++)
{
MailMessage msg = popClient.GetMessage(i);
Console.WriteLine("Message - " + i);
Console.WriteLine("Subject: " + msg.Subject);
Console.WriteLine("From: " + msg.From.Address);
}
popClient.Disconnect();
This screenshot displays the console output after fetching messages via POP3 from Gmail:
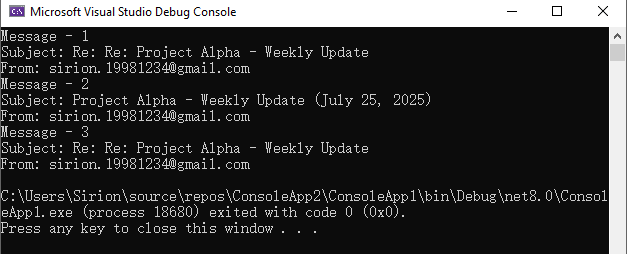
Unlike IMAP, POP3 downloads messages but does not maintain folder structure or message states on the server. Choose POP3 for simple retrieval scenarios.
Advanced Email Parsing in C#: Extract Attachments and Plain Text
In many cases, it's necessary to extract the plain-text content of an email for further processing, or to retrieve attachments for downstream use such as storage, analysis, or forwarding. The following C# example demonstrates how to access and save both the plain-text body and attachments using the MailMessage object.
MailMessage message = client.GetFullMessage(index);
// Retrieve plain text content
string plainText = message.BodyText;
// Extract attachments
foreach (Attachment attachment in message.Attachments)
{
string path = Path.Combine("Attachments", attachment.ContentType.Name);
Directory.CreateDirectory("Attachments");
using (var fileStream = new FileStream(path, FileMode.Create, FileAccess.Write))
{
attachment.Data.Position = 0;
attachment.Data.CopyTo(fileStream);
}
}
Notes:
- Most emails contain both HTML and plain text bodies; use the format appropriate for your application.
- To skip embedded images (like inline logos), check that attachment.ContentDisposition.DispositionType != "Inline".
Below is a sample output showing saved attachments and extracted plain text from the retrieved email:
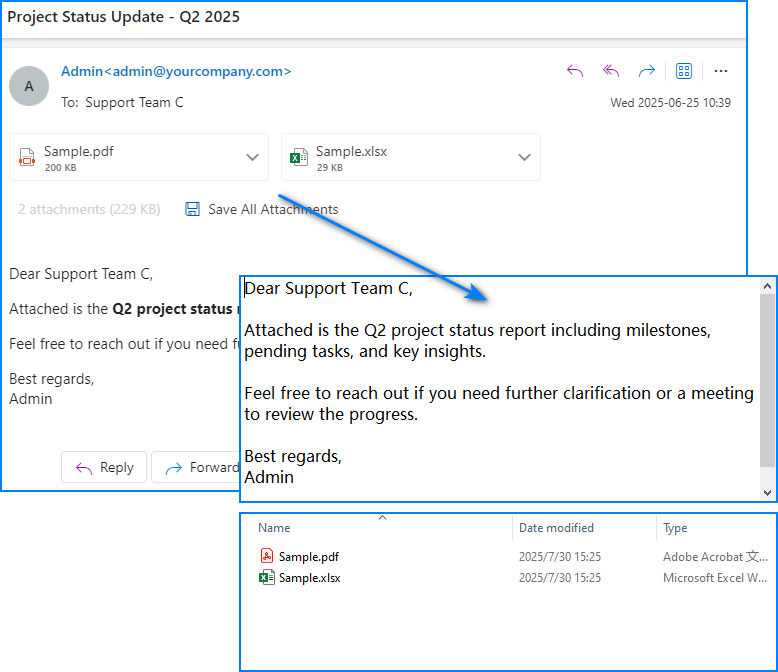
For more detailed operations such as managing email folders—creating, deleting, or moving messages—please refer to our guide on Email Folder Management in C#.
Summary
With Spire.Email for .NET, you can programmatically access Gmail or Outlook inboxes in C# using either IMAP or POP3. The library supports OAuth 2.0 authentication, parses both HTML and plain-text email bodies, and enables attachment extraction for downstream processing. Whether you're building an internal automation tool, an alerting system, or an email parser, Spire.Email provides the essential components for email integration in .NET applications.
If you'd like to explore all features without limitations, you can apply for a free temporary license.
Frequently Asked Questions
Can I use Spire.Email for sending emails too?
Yes. Spire.Email for .NET includes support for SMTP as well, allowing you to send HTML-formatted emails, add attachments, and configure encoding and headers.
Does Spire.Email work with other email providers?
Yes. As long as the provider supports standard IMAP, POP3, or SMTP protocols, and offers compatible authentication (OAuth or basic), it will work with Spire.Email.
How do I get the access token programmatically?
For Outlook, you can use Microsoft’s MSAL.NET; for Gmail, use Google.Apis.Auth or any other OAuth library that retrieves a valid token with mail access scopes. These tokens can then be passed to the email client for secure login.
Come eliminare pagine da un PDF con o senza Adobe Acrobat
Installa con Nuget
PM> Install-Package Spire.PDF
Link correlati

Introduzione:
I PDF sono ottimi per condividere e preservare la formattazione dei documenti, ma a volte contengono pagine non necessarie di cui non hai bisogno. Che si tratti di una pagina bianca alla fine di un report o di contenuti obsoleti in un contratto, sapere come eliminare pagine da un PDF in modo rapido ed efficiente può farti risparmiare tempo e migliorare il tuo flusso di lavoro.
In questa guida, ti illustreremo tre semplici metodi per rimuovere pagine da un PDF su Windows e Mac utilizzando Adobe Acrobat, uno strumento online e persino soluzioni di codice automatizzate per sviluppatori o attività in batch. La tabella seguente contiene alcune informazioni di base sui tre metodi. Puoi avere un'anteprima e passare al tutorial corrispondente.
| Metodo | Ideale per | Vantaggi | Svantaggi |
| Adobe Acrobat | Utenti occasionali con un abbonamento | Affidabile, preciso | metodo a pagamento |
| Strumento online | Modifiche rapide e una tantum | Nessuna installazione, facile da usare | Nessuna idea sulla sicurezza dei file |
| Codice (Spire.PDF) | Sviluppatori e aziende | Completamente automatizzato, scalabile | Richiede conoscenze di programmazione |
Metodo 1. Eliminare pagine da PDF su Windows e Mac con Adobe Acrobat
Se hai già installato Adobe Acrobat, è uno degli strumenti più affidabili e professionali per la gestione dei file PDF. Che tu stia lavorando con documenti di grandi dimensioni o abbia bisogno di rimuovere solo alcune pagine indesiderate, Acrobat offre una soluzione semplice.
Iniziamo esplorando come eliminare pagine da un PDF utilizzando Adobe Acrobat.
Per utenti Windows:
- Passaggio 1. Apri il tuo file PDF con Adobe Acrobat.
- Passaggio 2. Vai alla scheda "Strumenti" e seleziona "Organizza pagine".
- Passaggio 3. Appariranno le miniature di tutte le pagine: fai clic sulla/e pagina/e che desideri eliminare.
- Passaggio 4. Fai clic sull'icona del cestino o fai clic con il pulsante destro del mouse e scegli "Elimina pagine".
- Passaggio 5. Salva il tuo file PDF aggiornato.
Per utenti Mac:
- Passaggio 1. Avvia Adobe Acrobat e apri il tuo PDF.
- Passaggio 2. Fai clic su "Visualizza" > "Strumenti" > "Organizza pagine".
- Passaggio 3. Seleziona le pagine che desideri rimuovere.
- Passaggio 4. Premi l'icona di eliminazione o fai clic con il pulsante destro del mouse e scegli "Elimina pagine".
- Passaggio 5. Salva le modifiche e puoi scegliere di salvare il file PDF come nuovo.
Metodo 2. Eliminare pagine PDF con uno strumento online
Se non hai un abbonamento ad Adobe Acrobat e l'eliminazione è urgente, come puoi eliminare pagine da un file PDF senza Adobe Acrobat? Cerca su Google e prova uno strumento online per eliminare le tue pagine PDF. Il vantaggio di utilizzare uno strumento online è che non sono necessari download e installazioni aggiuntive. È molto comodo e gratuito se devi eliminare solo poche pagine.
In questa sezione, prenderò SmallPDF come esempio per mostrarti come fare.
Segui i passaggi seguenti e scopri come utilizzare uno strumento online per eliminare pagine da un file PDF:
Passaggio 1. Cerca su Google e vai al sito ufficiale di SmallPDF. Trova la parte "Strumenti" dal menu in alto e vai alla funzione "Elimina pagine PDF".
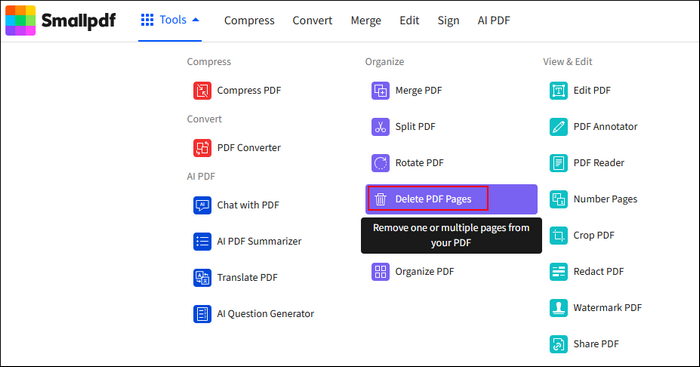
Passaggio 2. Puoi caricare i tuoi file PDF tramite la funzione di navigazione o trascinare direttamente il file nell'interfaccia principale.
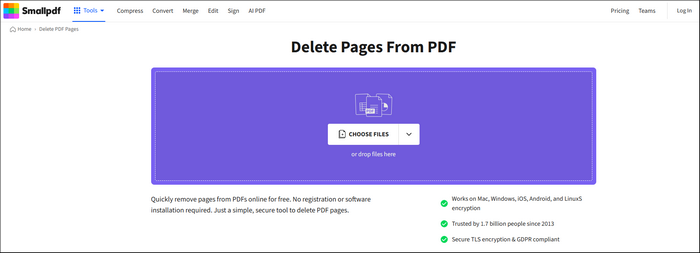
Passaggio 3. SmallPDF inizierà automaticamente ad analizzare il tuo file PDF. Vedrai il file PDF nel formato seguente. C'è un pulsante del cestino per ogni pagina. Trova semplicemente la pagina che desideri eliminare e fai clic sul pulsante del cestino.
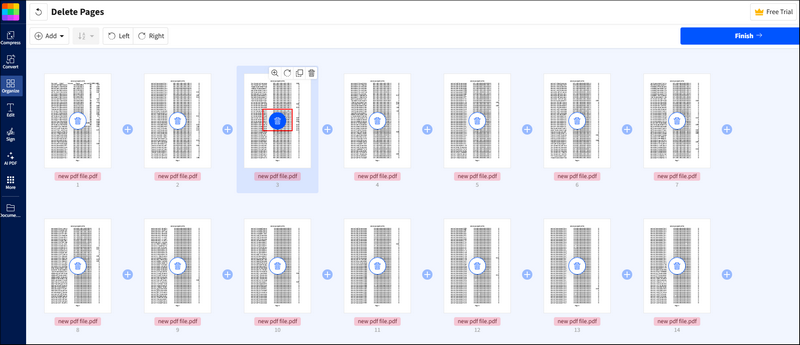
Passaggio 4. Quindi, fai clic sul pulsante Fine e attendi il processo.
Passaggio 5. Dopo l'eliminazione, puoi fare clic sul pulsante "Scarica" per salvare il tuo file PDF.
Metodo 3. Eliminare pagine da un file PDF automaticamente con il codice
Per gli sviluppatori o gli utenti avanzati che devono eliminare un gran numero di pagine da più file PDF a livello di codice, l'uso del codice è l'opzione più efficiente. Con la potente API del codice, non è necessario eliminare manualmente le pagine una per una.
Prima di fornire il codice di esempio, dovresti anche sapere che la scelta di una potente libreria di codice gioca un ruolo importante per un processo fluido. Lascia che ti presenti Spire.PDF for .NET, una versatile libreria PDF progettata per gli sviluppatori .NET per creare, leggere, modificare, convertire e proteggere facilmente i documenti PDF all'interno delle loro applicazioni. È completamente indipendente e non richiede Adobe Acrobat o strumenti esterni, supportando una vasta gamma di attività PDF, dalla generazione di report PDF dinamici alla conversione di PDF in Word, Excel, HTML e formati di immagine.
Ecco i passaggi per utilizzare Spire.PDF for .NET per eliminare pagine da un file PDF:
Passaggio 1. Installa Spire.PDF for .NET nel tuo ambiente C#. Puoi scaricare l'API del codice dalla pagina di download ufficiale o installarla con NuGet con il seguente codice:
PM> Install-Package Spire.PDF
- Suggerimento: Se desideri rimuovere il messaggio di valutazione dai documenti generati o eliminare le limitazioni delle funzioni, richiedi una licenza di prova di 30 giorni per te.
Passaggio 2. Copia il codice di esempio qui sotto e non dimenticare di configurare la posizione e il nome del file in base alla tua situazione specifica.
Codice di esempio in C# con Spire.PDF for .NET:
using Spire.Pdf;
namespace RemovePage
{
class Program
{
static void Main(string[] args)
{
//Crea un oggetto PdfDocument
PdfDocument document = new PdfDocument();
//Carica un documento PDF di esempio
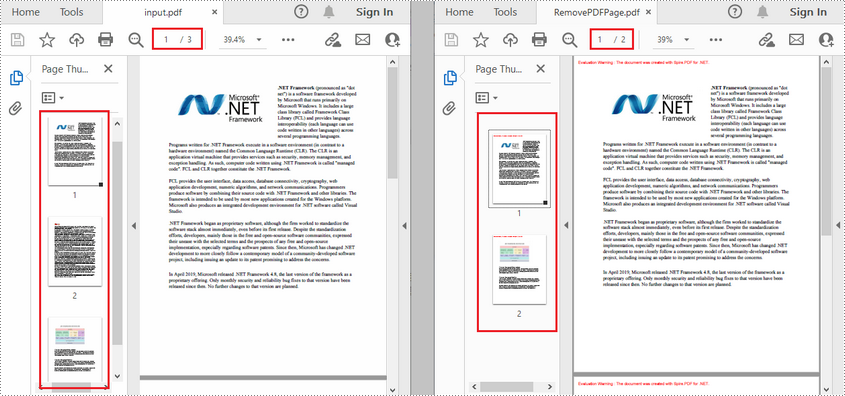
document.LoadFromFile(@"E:\Files\input.pdf");
//Rimuovi la seconda pagina
document.Pages.RemoveAt(1);
//Salva il documento risultante
document.SaveToFile("RemovePDFPage.pdf");
}
}
}
RISULTATO:
Cerchi un tutorial più dettagliato? Il seguente post ti sarà d'aiuto:
C#/VB.NET: Eliminare pagine da un PDF
Riepilogo
Non esiste un metodo unico per eliminare le pagine da un PDF. La soluzione migliore dipende dalle tue esigenze specifiche, dai dispositivi e dal tuo livello di comfort tecnico.
Ora che sai come eliminare le pagine da un PDF, puoi scegliere il metodo che meglio si adatta al tuo flusso di lavoro. Che tu stia lavorando a una rapida correzione di un documento o costruendo un processo di automazione completo, questi strumenti rendono l'eliminazione delle pagine semplice e senza stress.
Leggi anche:
Como excluir páginas de um PDF com ou sem o Adobe Acrobat
Instalar com Nuget
PM> Install-Package Spire.PDF
Links Relacionados
Introdução:
Os PDFs são ótimos para compartilhar e preservar a formatação de documentos, mas às vezes eles contêm páginas desnecessárias que você не precisa. Seja uma página em branco no final de um relatório ou conteúdo desatualizado em um contrato, saber como excluir páginas de um PDF de forma rápida e eficiente pode economizar seu tempo e melhorar seu fluxo de trabalho.
Neste guia, mostraremos três métodos fáceis para remover páginas de um PDF no Windows e Mac usando o Adobe Acrobat, uma ferramenta online e até mesmo soluções de código automatizadas para desenvolvedores ou tarefas em lote. A tabela a seguir contém algumas informações básicas dos três métodos. Você pode obter uma prévia e pular para o tutorial correspondente.
| Método | Melhor Para | Prós | Contras |
| Adobe Acrobat | Usuários ocasionais com uma assinatura | Confiável, preciso | método pago |
| Ferramenta Online | Edições rápidas e únicas | Sem instalação, fácil de usar | Nenhuma ideia sobre a segurança do arquivo |
| Código (Spire.PDF) | Desenvolvedores e empresas | Totalmente automatizado, escalável | Requer conhecimento de programação |
Método 1. Excluir Páginas de PDF no Windows e Mac com o Adobe Acrobat
Se você já tem o Adobe Acrobat instalado, é uma das ferramentas mais confiáveis e profissionais para gerenciar arquivos PDF. Quer esteja trabalhando com documentos grandes ou precise remover apenas algumas páginas indesejadas, o Acrobat oferece uma solução direta.
Vamos começar explorando como excluir páginas de um PDF usando o Adobe Acrobat.
Para usuários do Windows:
- Passo 1. Abra seu arquivo PDF com o Adobe Acrobat.
- Passo 2. Vá para a guia "Ferramentas" e selecione "Organizar Páginas".
- Passo 3. Miniaturas de todas as páginas aparecerão — clique na(s) página(s) que deseja excluir.
- Passo 4. Clique no ícone da lixeira ou clique com o botão direito e escolha "Excluir Páginas".
- Passo 5. Salve seu arquivo PDF atualizado.
Para usuários de Mac:
- Passo 1. Inicie o Adobe Acrobat e abra seu PDF.
- Passo 2. Clique em "Visualizar" > "Ferramentas" > "Organizar Páginas".
- Passo 3. Selecione as páginas que deseja remover.
- Passo 4. Pressione o ícone de exclusão ou clique com o botão direito e escolha "Excluir Páginas".
- Passo 5. Salve suas alterações e você pode optar por salvar o arquivo PDF como um novo.
Método 2. Excluir Páginas de PDF com uma Ferramenta Online
Se você não tem uma assinatura do Adobe Acrobat e a exclusão é urgente, como pode excluir páginas de um arquivo PDF sem o Adobe Acrobat? Pesquise no Google e experimente uma ferramenta online para excluir suas páginas de PDF. O benefício de usar uma ferramenta online é que não há download e instalação extras. É bastante conveniente e gratuito se você tiver apenas algumas páginas para excluir.
Nesta seção, usarei o SmallPDF como exemplo para mostrar como fazer.
Siga os passos abaixo e veja como usar uma ferramenta online para excluir páginas de um arquivo PDF:
Passo 1. Pesquise no Google e acesse o site oficial do SmallPDF. Encontre a parte "Ferramentas" no menu superior e vá para a função "Excluir Páginas de PDF".
Passo 2. Você pode enviar seus arquivos PDF através da função de navegação ou arrastar diretamente o arquivo para a interface principal.
Passo 3. O SmallPDF começará a analisar seu arquivo PDF automaticamente. Você verá o arquivo PDF no formato abaixo. Há um botão de lixeira para cada página. Basta encontrar a página que você gostaria de excluir e clicar no botão da lixeira.
Passo 4. Em seguida, clique no botão de concluir e aguarde o processo.
Passo 5. Após a exclusão, você pode clicar no botão "Baixar" para salvar seu arquivo PDF.
Método 3. Excluir Páginas de um Arquivo PDF Automaticamente com Código
Para desenvolvedores ou usuários avançados que precisam excluir um grande número de páginas de vários arquivos PDF programaticamente, usar código é a opção mais eficiente. Com a poderosa API de código, você não precisa excluir manualmente as páginas uma por uma.
Antes de fornecer o código de exemplo, você também deve saber que a escolha de uma biblioteca de código poderosa também desempenha um papel importante para um processo tranquilo. Deixe-me apresentar o Spire.PDF for .NET, uma biblioteca de PDF versátil projetada para desenvolvedores .NET para criar, ler, editar, converter e proteger documentos PDF facilmente em suas aplicações. É totalmente independente e не requer o Adobe Acrobat ou ferramentas externas, suportando uma ampla gama de tarefas de PDF — desde a geração de relatórios dinâmicos em PDF até a conversão de PDFs para Word, Excel, HTML e formatos de imagem.
Aqui estão os passos para usar o Spire.PDF for .NET para excluir páginas de um arquivo PDF:
Passo 1. Instale o Spire.PDF for .NET em seu ambiente C#. Você pode baixar a API de código na página de download oficial ou instalar com o NuGet com o seguinte código:
PM> Install-Package Spire.PDF
- Dica: Se você quiser remover a mensagem de avaliação dos documentos gerados, ou se livrar das limitações de funções, por favor, solicite uma licença de teste de 30 dias para você.
Passo 2. Copie o código de exemplo abaixo e não se esqueça de configurar a localização e o nome do arquivo de acordo com sua situação específica.
Código de exemplo em C# com Spire.PDF for .NET:
using Spire.Pdf;
namespace RemovePage
{
class Program
{
static void Main(string[] args)
{
//Criar um objeto PdfDocument
PdfDocument document = new PdfDocument();
//Carregar um documento PDF de exemplo
document.LoadFromFile(@"E:\Files\input.pdf");
//Remover a segunda página
document.Pages.RemoveAt(1);
//Salvar o documento resultante
document.SaveToFile("RemovePDFPage.pdf");
}
}
}
RESULTADO:
Procurando um tutorial mais detalhado? A postagem a seguir lhe dará alguma ajuda:
C#/VB.NET: Excluir Páginas de PDF
Resumo
Não existe um método único para excluir páginas de um PDF. A melhor solução depende de suas necessidades específicas, dispositivos e nível de conforto técnico.
Agora que você sabe como excluir páginas de um PDF, pode escolher o método que melhor se adapta ao seu fluxo de trabalho. Esteja você trabalhando em uma correção rápida de um documento ou construindo um processo de automação completo, essas ferramentas tornam a exclusão de páginas simples e sem estresse.
Leia também:
Adobe Acrobat을 사용하거나 사용하지 않고 PDF 페이지를 삭제하는 방법
Nuget으로 설치
PM> Install-Package Spire.PDF
관련 링크
소개:
PDF는 문서 서식을 공유하고 보존하는 데 유용하지만 때로는 필요 없는 페이지가 포함되어 있습니다. 보고서 끝에 있는 빈 페이지이든 계약서의 오래된 내용이든 PDF에서 페이지를 삭제하는 방법을 빠르고 효율적으로 알면 시간을 절약하고 작업 흐름을 개선할 수 있습니다.
이 가이드에서는 Adobe Acrobat, 온라인 도구, 심지어 개발자나 일괄 작업을 위한 자동화된 코드 솔루션을 사용하여 Windows 및 Mac에서 PDF 페이지를 제거하는 세 가지 쉬운 방법을 안내합니다. 다음 표에는 세 가지 방법에 대한 기본 정보가 포함되어 있습니다. 미리 보고 해당 튜토리얼로 이동할 수 있습니다.
| 방법 | 가장 적합한 대상 | 장점 | 단점 |
| Adobe Acrobat | 구독이 있는 비정기 사용자 | 신뢰성, 정밀성 | 유료 방법 |
| 온라인 도구 | 빠른, 일회성 편집 | 설치 불필요, 사용하기 쉬움 | 파일 보안에 대해 알 수 없음 |
| 코드 (Spire.PDF) | 개발자 및 기업 | 완전 자동화, 확장 가능 | 프로그래밍 지식 필요 |
방법 1. Adobe Acrobat을 사용하여 Windows 및 Mac에서 PDF 페이지 삭제
Adobe Acrobat이 이미 설치되어 있다면 PDF 파일을 관리하는 가장 신뢰할 수 있고 전문적인 도구 중 하나입니다. 대용량 문서를 다루거나 몇 개의 불필요한 페이지만 제거해야 하는 경우 Acrobat은 간단한 솔루션을 제공합니다.
Adobe Acrobat을 사용하여 PDF에서 페이지를 삭제하는 방법을 살펴보겠습니다.
Windows 사용자용:
- 1단계. Adobe Acrobat으로 PDF 파일을 엽니다.
- 2단계. "도구" 탭으로 이동하여 "페이지 구성"을 선택합니다.
- 3단계. 모든 페이지의 축소판이 나타납니다. 삭제하려는 페이지를 클릭합니다.
- 4단계. 휴지통 아이콘을 클릭하거나 마우스 오른쪽 버튼을 클릭하고 "페이지 삭제"를 선택합니다.
- 5단계. 업데이트된 PDF 파일을 저장합니다.
Mac 사용자용:
- 1단계. Adobe Acrobat을 실행하고 PDF를 엽니다.
- 2단계. "보기" > "도구" > "페이지 구성"을 클릭합니다.
- 3단계. 제거하려는 페이지를 선택합니다.
- 4단계. 삭제 아이콘을 누르거나 마우스 오른쪽 버튼을 클릭하고 "페이지 삭제"를 선택합니다.
- 5단계. 변경 사항을 저장하고 PDF 파일을 새 파일로 저장하도록 선택할 수 있습니다.
방법 2. 온라인 도구로 PDF 페이지 삭제
Adobe Acrobat 구독이 없고 삭제가 시급한 경우 Adobe Acrobat 없이 PDF 파일에서 페이지를 어떻게 삭제할 수 있을까요? Google에서 검색하여 PDF 페이지를 삭제할 수 있는 온라인 도구를 사용해 보십시오. 온라인 도구 사용의 이점은 추가 다운로드 및 설치가 없다는 것입니다. 몇 페이지만 삭제하면 되므로 매우 편리하고 비용이 들지 않습니다.
이 섹션에서는 SmallPDF를 예로 들어 방법을 보여 드리겠습니다.
아래 단계를 따르고 온라인 도구를 사용하여 PDF 파일에서 페이지를 삭제하는 방법을 확인하십시오.
1단계. Google에서 검색하여 SmallPDF 공식 사이트로 이동합니다. 상단 메뉴에서 "도구" 부분을 찾아 "PDF 페이지 삭제" 기능으로 이동합니다.
2단계. 탐색 기능을 통해 PDF 파일을 업로드하거나 파일을 주 인터페이스로 직접 드래그할 수 있습니다.
3단계. SmallPDF가 자동으로 PDF 파일 분석을 시작합니다. 아래 형식으로 PDF 파일이 표시됩니다. 각 페이지에는 휴지통 버튼이 있습니다. 삭제하려는 페이지를 찾아 휴지통 버튼을 클릭하기만 하면 됩니다.
4단계. 그런 다음 완료 버튼을 클릭하고 프로세스를 기다립니다.
5단계. 삭제 후 "다운로드" 버튼을 클릭하여 PDF 파일을 저장할 수 있습니다.
방법 3. 코드를 사용하여 PDF 파일에서 자동으로 페이지 삭제
프로그래밍 방식으로 여러 PDF 파일에서 많은 수의 페이지를 삭제해야 하는 개발자나 고급 사용자에게는 코드를 사용하는 것이 가장 효율적인 옵션입니다. 강력한 코드 API를 사용하면 페이지를 하나씩 수동으로 삭제할 필요가 없습니다.
샘플 코드를 제공하기 전에 강력한 코드 라이브러리를 선택하는 것도 원활한 프로세스를 위해 중요한 역할을 한다는 것을 알아야 합니다. .NET 개발자를 위해 설계된 다목적 PDF 라이브러리인 Spire.PDF for .NET을 소개합니다. 이 라이브러리를 사용하면 애플리케이션 내에서 PDF 문서를 쉽게 생성, 읽기, 편집, 변환 및 보호할 수 있습니다. 완전히 독립적이며 Adobe Acrobat이나 외부 도구가 필요 없으며 동적 PDF 보고서 생성부터 PDF를 Word로 변환, Excel, HTML 및 이미지 형식으로 변환하는 것까지 광범위한 PDF 작업을 지원합니다.
다음은 Spire.PDF for .NET을 사용하여 PDF 파일에서 페이지를 삭제하는 단계입니다.
1단계. C# 환경에 Spire.PDF for .NET을 설치합니다. 공식 다운로드 페이지에서 코드 API를 다운로드하거나 다음 코드를 사용하여 NuGet으로 설치할 수 있습니다.
PM> Install-Package Spire.PDF
- 팁: 생성된 문서에서 평가 메시지를 제거하거나 기능 제한을 없애려면 30일 평가판 라이선스를 요청하십시오.
2단계. 아래 샘플 코드를 복사하고 특정 상황에 맞게 파일 위치와 이름을 구성하는 것을 잊지 마십시오.
C#의 샘플 코드(Spire.PDF for .NET 사용):
using Spire.Pdf;
namespace RemovePage
{
class Program
{
static void Main(string[] args)
{
//PdfDocument 객체 생성
PdfDocument document = new PdfDocument();
//샘플 PDF 문서 로드
document.LoadFromFile(@"E:\Files\input.pdf");
//두 번째 페이지 제거
document.Pages.RemoveAt(1);
//결과 문서 저장
document.SaveToFile("RemovePDFPage.pdf");
}
}
}
결과:
더 자세한 튜토리얼을 찾고 계신가요? 다음 게시물이 도움이 될 것입니다.
요약
PDF에서 페이지를 삭제하는 데 만능인 방법은 없습니다. 최상의 솔루션은 특정 요구 사항, 장치 및 기술적 편의 수준에 따라 다릅니다.
이제 PDF에서 페이지를 삭제하는 방법을 알았으니 작업 흐름에 가장 적합한 방법을 선택할 수 있습니다. 빠른 문서 수정 작업을 하든 전체 자동화 프로세스를 구축하든 이 도구들은 페이지 삭제를 간단하고 스트레스 없이 만듭니다.
또한 읽기:
Comment supprimer des pages d’un PDF avec ou sans Adobe Acrobat
Table des matières
Installer avec Nuget
PM> Install-Package Spire.PDF
Liens connexes
Introduction :
Les PDF sont parfaits pour partager et préserver la mise en forme des documents, mais ils contiennent parfois des pages inutiles dont vous n'avez pas besoin. Qu'il s'agisse d'une page blanche à la fin d'un rapport ou d'un contenu obsolète dans un contrat, savoir comment supprimer des pages d'un PDF rapidement et efficacement peut vous faire gagner du temps et améliorer votre flux de travail.
Dans ce guide, nous vous présenterons trois méthodes simples pour supprimer des pages d'un PDF sur Windows et Mac en utilisant Adobe Acrobat, un outil en ligne, et même des solutions de code automatisées pour les développeurs ou les tâches par lots. Le tableau suivant contient quelques informations de base sur les trois méthodes. Vous pouvez obtenir un aperçu et accéder au tutoriel correspondant.
| Méthode | Idéal pour | Avantages | Inconvénients |
| Adobe Acrobat | Utilisateurs occasionnels avec un abonnement | Fiable, précis | méthode payante |
| Outil en ligne | Modifications rapides et ponctuelles | Aucune installation, facile à utiliser | Aucune idée de la sécurité des fichiers |
| Code (Spire.PDF) | Développeurs et entreprises | Entièrement automatisé, évolutif | Nécessite des connaissances en programmation |
Méthode 1. Supprimer des pages d'un PDF sur Windows et Mac avec Adobe Acrobat
Si vous avez déjà installé Adobe Acrobat, c'est l'un des outils les plus fiables et professionnels pour la gestion des fichiers PDF. Que vous travailliez avec de gros documents ou que vous ayez besoin de supprimer seulement quelques pages indésirables, Acrobat offre une solution simple.
Commençons par explorer comment supprimer des pages d'un PDF à l'aide d'Adobe Acrobat.
Pour les utilisateurs de Windows :
- Étape 1. Ouvrez votre fichier PDF avec Adobe Acrobat.
- Étape 2. Allez à l'onglet « Outils » et sélectionnez « Organiser les pages ».
- Étape 3. Des vignettes de toutes les pages apparaîtront — cliquez sur la ou les pages que vous souhaitez supprimer.
- Étape 4. Cliquez sur l'icône de la corbeille ou faites un clic droit et choisissez « Supprimer les pages ».
- Étape 5. Enregistrez votre fichier PDF mis à jour.
Pour les utilisateurs de Mac :
- Étape 1. Lancez Adobe Acrobat et ouvrez votre PDF.
- Étape 2. Cliquez sur « Affichage » > « Outils » > « Organiser les pages ».
- Étape 3. Sélectionnez les pages que vous souhaitez supprimer.
- Étape 4. Appuyez sur l'icône de suppression ou faites un clic droit et choisissez « Supprimer les pages ».
- Étape 5. Enregistrez vos modifications et vous pouvez choisir d'enregistrer le fichier PDF sous un nouveau nom.
Méthode 2. Supprimer des pages de PDF avec un outil en ligne
Si vous n'avez pas d'abonnement à Adobe Acrobat et que la suppression est urgente, comment pouvez-vous supprimer des pages d'un fichier PDF sans Adobe Acrobat ? Faites une recherche sur Google et essayez un outil en ligne pour supprimer vos pages PDF. L'avantage d'utiliser un outil en ligne est qu'il n'y a pas de téléchargement et d'installation supplémentaires. C'est très pratique et gratuit si vous n'avez que quelques pages à supprimer.
Dans cette section, je prendrai SmallPDF comme exemple pour vous montrer comment faire.
Suivez les étapes ci-dessous et découvrez comment utiliser un outil en ligne pour supprimer des pages d'un fichier PDF :
Étape 1. Faites une recherche sur Google et allez sur le site officiel de SmallPDF. Trouvez la partie « Outils » dans le menu supérieur et allez à la fonction « Supprimer des pages PDF ».
Étape 2. Vous pouvez télécharger vos fichiers PDF via la fonction de navigation ou faire glisser directement le fichier dans l'interface principale.
Étape 3. SmallPDF commencera automatiquement à analyser votre fichier PDF. Vous verrez le fichier PDF dans le format ci-dessous. Il y a un bouton de corbeille pour chaque page. Trouvez simplement la page que vous souhaitez supprimer et cliquez sur le bouton de la corbeille.
Étape 4. Ensuite, cliquez sur le bouton de fin et attendez le processus.
Étape 5. Après la suppression, vous pouvez cliquer sur le bouton « Télécharger » pour enregistrer votre fichier PDF.
Méthode 3. Supprimer des pages d'un fichier PDF automatiquement avec du code
Pour les développeurs ou les utilisateurs avancés qui ont besoin de supprimer un grand nombre de pages de plusieurs fichiers PDF par programmation, l'utilisation de code est l'option la plus efficace. Avec la puissante API de code, vous n'avez pas besoin de supprimer manuellement les pages une par une.
Avant de fournir l'exemple de code, vous devez également savoir que le choix d'une bibliothèque de code puissante joue également un rôle important pour un processus fluide. Laissez-moi vous présenter Spire.PDF for .NET, une bibliothèque PDF polyvalente conçue pour les développeurs .NET afin de créer, lire, modifier, convertir et sécuriser facilement des documents PDF dans leurs applications. Elle est entièrement indépendante et ne nécessite ni Adobe Acrobat ni d'outils externes, prenant en charge un large éventail de tâches PDF — de la génération de rapports PDF dynamiques à la conversion de PDF en Word, Excel, HTML et formats d'image.
Voici les étapes pour utiliser Spire.PDF for .NET pour supprimer des pages d'un fichier PDF :
Étape 1. Installez Spire.PDF for .NET dans votre environnement C#. Vous pouvez télécharger l'API de code depuis la page de téléchargement officielle ou l'installer avec NuGet avec le code suivant :
PM> Install-Package Spire.PDF
- Conseil : Si vous souhaitez supprimer le message d'évaluation des documents générés, ou vous débarrasser des limitations de fonctions, veuillez demander une licence d'essai de 30 jours pour vous-même.
Étape 2. Copiez l'exemple de code ci-dessous et n'oubliez pas de configurer l'emplacement et le nom du fichier en fonction de votre situation spécifique.
Exemple de code en C# avec Spire.PDF for .NET :
using Spire.Pdf;
namespace RemovePage
{
class Program
{
static void Main(string[] args)
{
//Créer un objet PdfDocument
PdfDocument document = new PdfDocument();
//Charger un exemple de document PDF
document.LoadFromFile(@"E:\Files\input.pdf");
//Supprimer la deuxième page
document.Pages.RemoveAt(1);
//Enregistrer le document résultant
document.SaveToFile("RemovePDFPage.pdf");
}
}
}
RÉSULTAT :
Vous cherchez un tutoriel plus détaillé ? Le post suivant vous aidera :
C#/VB.NET : Supprimer des pages d'un PDF
Résumé
Il n'existe pas de méthode universelle pour supprimer des pages d'un PDF. La meilleure solution dépend de vos besoins spécifiques, de vos appareils et de votre niveau de confort technique.
Maintenant que vous savez comment supprimer des pages d'un PDF, vous pouvez choisir la méthode qui correspond le mieux à votre flux de travail. Que vous travailliez sur une correction rapide de document ou que vous construisiez un processus d'automatisation complet, ces outils rendent la suppression de pages simple et sans stress.
Lisez aussi :
Cómo eliminar páginas de un PDF con o sin Adobe Acrobat
Tabla de contenidos
Instalar con Nuget
PM> Install-Package Spire.PDF
Enlaces relacionados
Introducción:
Los PDF son excelentes para compartir y preservar el formato de los documentos, pero a veces contienen páginas innecesarias que no necesita. Ya sea una página en blanco al final de un informe o contenido obsoleto en un contrato, saber cómo eliminar páginas de un PDF de manera rápida y eficiente puede ahorrarle tiempo y mejorar su flujo de trabajo.
En esta guía, le mostraremos tres métodos sencillos para eliminar páginas de un PDF en Windows y Mac usando Adobe Acrobat, una herramienta en línea e incluso soluciones de código automatizadas para desarrolladores o tareas por lotes. La siguiente tabla contiene información básica sobre los tres métodos. Puede obtener una vista previa y saltar al tutorial correspondiente.
| Método | Ideal para | Ventajas | Desventajas |
| Adobe Acrobat | Usuarios ocasionales con suscripción | Fiable, preciso | método de pago |
| Herramienta en línea | Ediciones rápidas y puntuales | Sin instalación, fácil de usar | Sin idea sobre la seguridad del archivo |
| Código (Spire.PDF) | Desarrolladores y empresas | Totalmente automatizado, escalable | Requiere conocimientos de programación |
Método 1. Eliminar páginas de un PDF en Windows y Mac con Adobe Acrobat
Si ya tiene instalado Adobe Acrobat, es una de las herramientas más fiables y profesionales para gestionar archivos PDF. Tanto si trabaja con documentos grandes como si solo necesita eliminar unas pocas páginas no deseadas, Acrobat ofrece una solución sencilla.
Comencemos explorando cómo eliminar páginas de un PDF usando Adobe Acrobat.
Para usuarios de Windows:
- Paso 1. Abra su archivo PDF con Adobe Acrobat.
- Paso 2. Vaya a la pestaña "Herramientas" y seleccione "Organizar páginas".
- Paso 3. Aparecerán miniaturas de todas las páginas; haga clic en la(s) página(s) que desea eliminar.
- Paso 4. Haga clic en el icono de la papelera o haga clic con el botón derecho y elija "Eliminar páginas".
- Paso 5. Guarde su archivo PDF actualizado.
Para usuarios de Mac:
- Paso 1. Inicie Adobe Acrobat y abra su PDF.
- Paso 2. Haga clic en "Ver" > "Herramientas" > "Organizar páginas".
- Paso 3. Seleccione las páginas que desea eliminar.
- Paso 4. Pulse el icono de eliminar o haga clic con el botón derecho y elija "Eliminar páginas".
- Paso 5. Guarde los cambios y puede optar por guardar el archivo PDF como uno nuevo.
Método 2. Eliminar páginas de un PDF con una herramienta en línea
Si no tiene una suscripción a Adobe Acrobat y la eliminación es urgente, ¿cómo puede eliminar páginas de un archivo PDF sin Adobe Acrobat? Busque en Google y pruebe una herramienta en línea para eliminar sus páginas PDF. El beneficio de usar una herramienta en línea es que no hay descargas e instalaciones adicionales. Es bastante conveniente y gratuito si solo tiene que eliminar unas pocas páginas.
En esta sección, tomaré SmallPDF como ejemplo para mostrarle cómo hacerlo.
Siga los pasos a continuación y vea cómo usar una herramienta en línea para eliminar páginas de un archivo PDF:
Paso 1. Busque en Google y vaya al sitio oficial de SmallPDF. Busque la parte "Herramientas" en el menú superior y vaya a la función "Eliminar páginas de PDF".
Paso 2. Puede cargar sus archivos PDF a través de la función de navegación o arrastrar directamente el archivo a la interfaz principal.
Paso 3. SmallPDF comenzará a analizar automáticamente su archivo PDF. Verá el archivo PDF en el siguiente formato. Hay un botón de papelera para cada página. Simplemente busque la página que desea eliminar y haga clic en el botón de la papelera.
Paso 4. Luego, haga clic en el botón de finalizar y espere a que se complete el proceso.
Paso 5. Después de la eliminación, puede hacer clic en el botón "Descargar" para guardar su archivo PDF.
Método 3. Eliminar páginas de un archivo PDF automáticamente con código
Para desarrolladores o usuarios avanzados que necesitan eliminar una gran cantidad de páginas de múltiples archivos PDF mediante programación, usar código es la opción más eficiente. Con la potente API de código, no necesita eliminar páginas manualmente una por una.
Antes de proporcionar el código de muestra, también debe saber que elegir una biblioteca de código potente también juega un papel importante para un proceso fluido. Permítame presentarle Spire.PDF for .NET, una biblioteca de PDF versátil diseñada para que los desarrolladores de .NET puedan crear, leer, editar, convertir y proteger documentos PDF fácilmente dentro de sus aplicaciones. Es totalmente independiente y no requiere Adobe Acrobat ni herramientas externas, y admite una amplia gama de tareas de PDF, desde la generación de informes PDF dinámicos hasta la conversión de PDF a Word, Excel, HTML y formatos de imagen.
Estos son los pasos para usar Spire.PDF for .NET para eliminar páginas de un archivo PDF:
Paso 1. Instale Spire.PDF for .NET en su entorno de C#. Puede descargar la API de código desde la página de descarga oficial o instalarla con NuGet con el siguiente código:
PM> Install-Package Spire.PDF
- Consejo: Si desea eliminar el mensaje de evaluación de los documentos generados o deshacerse de las limitaciones de funciones, solicite una licencia de prueba de 30 días para usted.
Paso 2. Copie el código de muestra a continuación y no olvide configurar la ubicación y el nombre del archivo de acuerdo con su situación específica.
Código de muestra en C# con Spire.PDF for .NET:
using Spire.Pdf;
namespace RemovePage
{
class Program
{
static void Main(string[] args)
{
//Crear un objeto PdfDocument
PdfDocument document = new PdfDocument();
//Cargar un documento PDF de muestra
document.LoadFromFile(@"E:\Files\input.pdf");
//Eliminar la segunda página
document.Pages.RemoveAt(1);
//Guardar el documento resultante
document.SaveToFile("RemovePDFPage.pdf");
}
}
}
RESULTADO:
¿Busca un tutorial más detallado? La siguiente publicación le ayudará:
C#/VB.NET: Eliminar páginas de un PDF
Resumen
No existe un método único para eliminar páginas de un PDF. La mejor solución depende de sus necesidades específicas, dispositivos y nivel de comodidad técnica.
Ahora que sabe cómo eliminar páginas de un PDF, puede elegir el método que mejor se adapte a su flujo de trabajo. Ya sea que esté trabajando en una solución rápida para un documento o construyendo un proceso de automatización completo, estas herramientas hacen que la eliminación de páginas sea sencilla y sin estrés.
Lea también:
So löschen Sie Seiten aus einer PDF – mit oder ohne Adobe Acrobat
Inhaltsverzeichnis
Installation mit Nuget
PM> Install-Package Spire.PDF
Verwandte Links
Einführung:
PDFs eignen sich hervorragend zum Teilen und Beibehalten der Dokumentformatierung – aber manchmal enthalten sie unnötige Seiten, die Sie nicht benötigen. Ob es sich um eine leere Seite am Ende eines Berichts oder um veraltete Inhalte in einem Vertrag handelt, das Wissen, wie man Seiten aus einem PDF schnell und effizient löscht, kann Ihnen Zeit sparen und Ihren Arbeitsablauf verbessern.
In diesem Leitfaden führen wir Sie durch drei einfache Methoden zum Entfernen von Seiten aus einem PDF unter Windows und Mac mit Adobe Acrobat, einem Online-Tool und sogar automatisierten Code-Lösungen für Entwickler oder Stapelverarbeitungsaufgaben. Die folgende Tabelle enthält einige grundlegende Informationen zu den drei Methoden. Sie können sich einen Überblick verschaffen und zum entsprechenden Tutorial springen.
| Methode | Am besten geeignet für | Vorteile | Nachteile |
| Adobe Acrobat | Gelegentliche Benutzer mit Abonnement | Zuverlässig, präzise | kostenpflichtige Methode |
| Online-Tool | Schnelle, einmalige Bearbeitungen | Keine Installation, einfach zu bedienen | Keine Ahnung von Dateisicherheit |
| Code (Spire.PDF) | Entwickler und Unternehmen | Vollautomatisch, skalierbar | Erfordert Programmierkenntnisse |
Methode 1. Seiten aus PDF unter Windows & Mac mit Adobe Acrobat löschen
Wenn Sie Adobe Acrobat bereits installiert haben, ist es eines der zuverlässigsten und professionellsten Werkzeuge zur Verwaltung von PDF-Dateien. Egal, ob Sie mit großen Dokumenten arbeiten или nur ein paar unerwünschte Seiten entfernen müssen, Acrobat bietet eine unkomplizierte Lösung.
Beginnen wir damit, wie man Seiten aus einem PDF mit Adobe Acrobat löscht.
Für Windows-Benutzer:
- Schritt 1. Öffnen Sie Ihre PDF-Datei mit Adobe Acrobat.
- Schritt 2. Gehen Sie zur Registerkarte „Werkzeuge“ und wählen Sie „Seiten organisieren“.
- Schritt 3. Es werden Miniaturansichten aller Seiten angezeigt – klicken Sie auf die Seite(n), die Sie löschen möchten.
- Schritt 4. Klicken Sie auf das Papierkorb-Symbol oder klicken Sie mit der rechten Maustaste und wählen Sie „Seiten löschen“.
- Schritt 5. Speichern Sie Ihre aktualisierte PDF-Datei.
Für Mac-Benutzer:
- Schritt 1. Starten Sie Adobe Acrobat und öffnen Sie Ihr PDF.
- Schritt 2. Klicken Sie auf „Anzeige“ > „Werkzeuge“ > „Seiten organisieren“.
- Schritt 3. Wählen Sie die Seiten aus, die Sie entfernen möchten.
- Schritt 4. Klicken Sie auf das Löschen-Symbol oder klicken Sie mit der rechten Maustaste und wählen Sie „Seiten löschen“.
- Schritt 5. Speichern Sie Ihre Änderungen, und Sie können die PDF-Datei als neue Datei speichern.
Methode 2. PDF-Seiten mit einem Online-Tool löschen
Wenn Sie kein Adobe Acrobat-Abonnement haben und das Löschen dringend ist, wie können Sie Seiten aus einer PDF-Datei ohne Adobe Acrobat löschen? Suchen Sie bei Google und probieren Sie ein Online-Tool aus, um Ihre PDF-Seiten zu löschen. Der Vorteil eines Online-Tools ist, dass kein zusätzlicher Download und keine Installation erforderlich ist. Es ist sehr bequem und kostenlos, wenn Sie nur wenige Seiten zu löschen haben.
In diesem Abschnitt nehme ich SmallPDF als Beispiel, um Ihnen zu zeigen, wie es geht.
Folgen Sie den nachstehenden Schritten und sehen Sie, wie Sie ein Online-Tool verwenden, um Seiten aus einer PDF-Datei zu löschen:
Schritt 1. Suchen Sie bei Google und gehen Sie zur offiziellen Website von SmallPDF. Finden Sie den Teil „Tools“ im oberen Menü und gehen Sie zur Funktion „PDF-Seiten löschen“.
Schritt 2. Sie können Ihre PDF-Dateien über die Suchfunktion hochladen oder die Datei direkt in die Hauptoberfläche ziehen.
Schritt 3. SmallPDF beginnt automatisch mit der Analyse Ihrer PDF-Datei. Sie sehen die PDF-Datei im folgenden Format. Für jede Seite gibt es eine Papierkorb-Schaltfläche. Finden Sie einfach die Seite, die Sie löschen möchten, und klicken Sie auf die Papierkorb-Schaltfläche.
Schritt 4. Klicken Sie dann auf die Schaltfläche „Fertigstellen“ und warten Sie auf den Prozess.
Schritt 5. Nach dem Löschen können Sie auf die Schaltfläche „Herunterladen“ klicken, um Ihre PDF-Datei zu speichern.
Methode 3. Seiten aus einer PDF-Datei automatisch mit Code löschen
Für Entwickler oder fortgeschrittene Benutzer, die eine große Anzahl von Seiten aus mehreren PDF-Dateien programmgesteuert löschen müssen, ist die Verwendung von Code die effizienteste Option. Mit der leistungsstarken Code-API müssen Sie Seiten nicht manuell einzeln löschen.
Bevor Sie den Beispielcode bereitstellen, sollten Sie auch wissen, dass die Wahl einer leistungsstarken Code-Bibliothek ebenfalls eine wichtige Rolle für einen reibungslosen Prozess spielt. Lassen Sie mich Ihnen Spire.PDF for .NET vorstellen, eine vielseitige PDF-Bibliothek, die für .NET-Entwickler entwickelt wurde, um PDF-Dokumente in ihren Anwendungen einfach zu erstellen, zu lesen, zu bearbeiten, zu konvertieren und zu sichern. Sie ist völlig unabhängig und erfordert kein Adobe Acrobat oder externe Tools und unterstützt eine breite Palette von PDF-Aufgaben – von der Erstellung dynamischer PDF-Berichte bis zur Konvertierung von PDFs in Word, Excel, HTML und Bildformate.
Hier sind die Schritte zur Verwendung von Spire.PDF for .NET zum Löschen von Seiten aus einer PDF-Datei:
Schritt 1. Installieren Sie Spire.PDF for .NET in Ihrer C#-Umgebung. Sie können die Code-API von der offiziellen Download-Seite herunterladen oder mit NuGet mit dem folgenden Code installieren:
PM> Install-Package Spire.PDF
- Tipp: Wenn Sie die Evaluierungsnachricht aus den generierten Dokumenten entfernen oder die Funktionseinschränkungen aufheben möchten, fordern Sie bitte eine 30-tägige Testlizenz für sich an.
Schritt 2. Kopieren Sie den folgenden Beispielcode und vergessen Sie nicht, den Dateispeicherort und den Namen entsprechend Ihrer spezifischen Situation zu konfigurieren.
Beispielcode in C# mit Spire.PDF for .NET:
using Spire.Pdf;
namespace RemovePage
{
class Program
{
static void Main(string[] args)
{
//Erstellen eines PdfDocument-Objekts
PdfDocument document = new PdfDocument();
//Laden eines Beispiel-PDF-Dokuments
document.LoadFromFile(@"E:\Files\input.pdf");
//Entfernen der zweiten Seite
document.Pages.RemoveAt(1);
//Speichern des Ergebnisdokuments
document.SaveToFile("RemovePDFPage.pdf");
}
}
}
ERGEBNIS:
Suchen Sie ein detaillierteres Tutorial? Der folgende Beitrag wird Ihnen helfen:
C#/VB.NET: Seiten aus PDF löschen
Zusammenfassung
Es gibt keine Einheitslösung zum Löschen von Seiten aus einem PDF. Die beste Lösung hängt von Ihren spezifischen Bedürfnissen, Geräten und Ihrem technischen Komfortniveau ab.
Jetzt, da Sie wissen, wie man Seiten aus einem PDF löscht, können Sie die Methode wählen, die am besten zu Ihrem Arbeitsablauf passt. Egal, ob Sie an einer schnellen Dokumentenkorrektur arbeiten oder einen vollständigen Automatisierungsprozess aufbauen, diese Tools machen das Löschen von Seiten unkompliziert und stressfrei.
Lesen Sie auch: