HTML 테이블을 Excel로 추출하는 4가지 효과적인 방법 (수동 & 자동화)
목차
Pypi로 설치
pip install Spire.XLS
관련 링크
개요
HTML 표를 Excel로 추출하는 것은 구조화된 웹 데이터를 자주 다루는 데이터 분석가, 연구원, 개발자 및 비즈니스 전문가에게 일반적인 요구 사항입니다. HTML 표에는 재무 보고서, 제품 카탈로그, 연구 결과 또는 성과 통계와 같은 귀중한 정보가 포함되어 있는 경우가 많습니다. 그러나 해당 데이터를 깨끗하고 사용 가능한 형식으로 Excel로 전송하는 것은 까다로울 수 있으며, 특히 병합된 셀(rowspan, colspan), 중첩된 헤더 또는 대규모 데이터 세트가 포함된 복잡한 표를 처리할 때 그렇습니다.
다행히도 HTML 표를 Excel 파일로 변환하는 여러 가지 방법이 있습니다. 이러한 방법은 작은 작업에 적합한 빠른 수동 복사-붙여넣기 작업부터 대규모 또는 반복적인 작업을 위한 VBA 또는 Python을 사용한 완전 자동화된 스크립트에 이르기까지 다양합니다.
이 기사에서는 HTML 표를 Excel로 추출하는 네 가지 효과적인 방법을 살펴보겠습니다.
마지막으로, 사용 사례에 따라 최상의 방법을 선택하는 데 도움이 되도록 이러한 접근 방식을 요약 표에서 비교할 것입니다.
수동 복사-붙여넣기 (가장 간단한 방법)
작고 일회성인 추출의 경우 가장 간단한 옵션은 브라우저에서 Excel로 직접 복사하여 붙여넣는 것입니다.

단계:
- 브라우저(예: Chrome, Edge 또는 Firefox)에서 HTML 페이지를 엽니다.
- 추출하려는 표를 강조 표시합니다.
- Ctrl+C(또는 마우스 오른쪽 버튼 클릭 → 복사)로 복사합니다.
- Excel을 열고 Ctrl+V로 붙여넣습니다.
장점:
- 매우 간단함—설정이나 코딩이 필요 없음.
- 작고 깔끔한 표에 즉시 작동함.
단점:
- 수동 프로세스—잦거나 큰 데이터 세트에는 지루하고 비효율적임.
- 병합된 셀이나 서식을 항상 유지하지는 않음.
- 동적(JavaScript 렌더링) 표를 안정적으로 처리할 수 없음.
사용 시기: 작은 표, 임시 데이터 수집 또는 빠른 테스트에 가장 적합합니다.
Excel의 내장된 "웹에서" 기능
Excel에는 사용자가 웹 페이지에서 직접 표를 가져올 수 있는 강력한 "데이터 가져오기 및 변환" 도구(이전의 파워 쿼리)가 포함되어 있습니다.
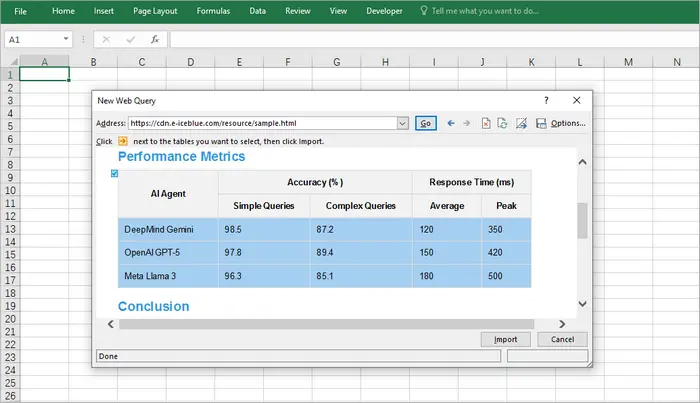
단계:
- Excel을 엽니다.
- 데이터 → 웹에서로 이동합니다.
- 표가 포함된 웹 페이지의 URL을 입력합니다.
- Excel이 감지된 표를 표시합니다. 원하는 표를 선택합니다.
- 워크시트에 데이터를 로드합니다.
장점:
- Excel에 직접 통합—외부 도구 필요 없음.
- 구조화된 HTML 표에 잘 작동함.
- 새로 고침 지원—동일한 소스에서 업데이트된 데이터를 다시 가져올 수 있음.
단점:
- 동적 또는 JavaScript 렌더링 콘텐츠에 대한 지원 제한.
- 때때로 복잡한 표를 감지하지 못함.
- 인터넷 액세스 및 유효한 URL 필요(수동으로 가져오지 않는 한 로컬 HTML 파일에는 해당되지 않음).
사용 시기: 정기적으로 업데이트되는 웹사이트에서 실시간 구조화된 데이터를 가져오는 분석가에게 가장 적합합니다.
VBA 매크로 (Excel 자동화)
HTML 표를 자주 추출하고 더 많은 제어를 원하는 사용자에게 VBA(Visual Basic for Applications)는 훌륭한 솔루션을 제공합니다. VBA를 사용하면 URL에서 표를 가져와 병합된 셀을 올바르게 처리할 수 있으며, 이는 기본 복사-붙여넣기로는 처리할 수 없습니다.
단계:
- Microsoft Excel을 시작합니다.
- Alt + F11을 눌러 VBA 편집기를 엽니다.
- 프로젝트 탐색기에서 마우스 오른쪽 버튼 클릭 → 삽입 → 모듈.
- 제공된 VBA 코드를 붙여넣습니다.
- VBA 편집기를 닫습니다.
- Alt + F8을 누르고 매크로 이름을 선택한 다음 실행을 클릭합니다.
샘플 VBA 코드:
Sub ExtractHTMLTableWithProperMerging()
Dim html As Object, tables As Object, table As Object, row As Object, cell As Object
Dim ws As Worksheet
Dim iRow As Long, iCol As Long, realCol As Long
Dim url As String
Dim colspan As Integer, rowspan As Integer
Dim cellTracker() As Boolean ' 차지된 셀 추적
' 대상 워크시트 설정
Set ws = ThisWorkbook.Sheets("Sheet1")
ws.Cells.ClearContents
ws.Cells.UnMerge ' 기존 병합된 셀 모두 지우기
' URL 입력 받기
url = InputBox("웹 페이지 URL 입력:", "HTML 표 추출기")
If url = "" Then Exit Sub
' HTML 로드
Set html = CreateObject("htmlfile")
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", url, False
.send
html.body.innerHTML = .responseText
End With
' 첫 번째 표 가져오기 (필요시 인덱스 변경)
Set tables = html.getElementsByTagName("table")
If tables.Length = 0 Then
MsgBox "표를 찾을 수 없습니다!", vbExclamation
Exit Sub
End If
Set table = tables(0)
' 셀 추적기 배열 초기화
Dim maxRows As Long, maxCols As Long
maxRows = table.Rows.Length
maxCols = 0
For Each row In table.Rows
If row.Cells.Length > maxCols Then maxCols = row.Cells.Length
Next
ReDim cellTracker(1 To maxRows, 1 To maxCols)
' 표 처리
iRow = 1
For Each row In table.Rows
realCol = 1 ' rowspan을 고려한 실제 열 위치 추적
' 이 행에서 첫 번째 사용 가능한 열 찾기
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
iCol = 1 ' 논리적 열 위치 추적
For Each cell In row.Cells
' 병합 속성 가져오기
colspan = 1
rowspan = 1
On Error Resume Next ' 속성이 없는 경우 대비
colspan = cell.colspan
rowspan = cell.rowspan
On Error GoTo 0
' 이미 차지된 셀 건너뛰기 (위의 rowspan으로 인해)
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
If realCol > maxCols Then Exit For
' 값 쓰기
ws.Cells(iRow, realCol).Value = cell.innerText
' 이 셀이 차지할 모든 셀 표시
Dim r As Long, c As Long
For r = iRow To iRow + rowspan - 1
For c = realCol To realCol + colspan - 1
If r <= maxRows And c <= maxCols Then
cellTracker(r, c) = True
End If
Next c
Next r
' 필요시 셀 병합
If colspan > 1 Or rowspan > 1 Then
With ws.Range(ws.Cells(iRow, realCol), ws.Cells(iRow + rowspan - 1, realCol + colspan - 1))
.Merge
.HorizontalAlignment = xlCenter
.VerticalAlignment = xlCenter
End With
End If
realCol = realCol + colspan
iCol = iCol + 1
Next cell
iRow = iRow + 1
Next row
' 서식 지정
ws.UsedRange.Columns.AutoFit
ws.UsedRange.Borders.Weight = xlThin
MsgBox "표가 올바른 병합으로 추출되었습니다!", vbInformation
End Sub
장점:
- 전적으로 Excel 내에서 실행—외부 도구 필요 없음.
- 병합된 셀이 있는 복잡한 표 처리.
- 여러 표 또는 예약된 실행에 맞게 사용자 지정 가능.
단점:
- 설정에 VBA 지식 필요.
- 추가 단계 없이 JavaScript 렌더링 데이터 처리 불가.
- Excel 데스크톱에서만 작동(Excel 온라인에서는 작동 안 함).
사용 시기: 유사한 표를 정기적으로 추출하고 원클릭 솔루션을 원하는 사용자에게 적합합니다.
Python (BeautifulSoup & Spire.XLS)
개발자나 고급 사용자에게 Python은 가장 유연하고 확장 가능하며 자동화된 솔루션을 제공합니다. HTML 파싱을 위한 BeautifulSoup 및 Excel 조작을 위한 Spire.XLS for Python과 같은 라이브러리를 사용하여 프로그래밍 방식으로 표를 가져오고, 정리하고, 완전한 제어로 내보낼 수 있습니다.
단계:
- Python 설치(3.8+ 권장).
- IDE(예: VS Code, PyCharm)에서 새 프로젝트 생성.
- 의존성 설치:
pip install requests beautifulsoup4 spire.xls
- 다음 스크립트를 복사하여 실행합니다.
Python 코드:
import requests
from bs4 import BeautifulSoup
from spire.xls import Workbook, ExcelVersion
# URL에서 HTML 문자열 가져오기
response = requests.get("https://cdn.e-iceblue.com/resource/sample.html")
html = response.text
# HTML 파싱
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table") # 첫 번째 표 가져오기
# Excel 초기화
workbook = Workbook()
sheet = workbook.Worksheets[0]
# 나중에 건너뛸 병합된 셀 추적
skip_cells = set()
# HTML 행 및 셀 반복
for row_idx, row in enumerate(table.find_all("tr")):
col_idx = 1 # Excel 열은 1부터 시작
for cell in row.find_all(["th", "td"]):
# 이미 병합된 셀 건너뛰기
while (row_idx + 1, col_idx) in skip_cells:
col_idx += 1
# colspan/rowspan 값 가져오기 (없는 경우 기본값 1)
colspan = int(cell.get("colspan", 1))
rowspan = int(cell.get("rowspan", 1))
# Excel에 셀 값 쓰기
sheet.Range[row_idx + 1, col_idx].Text = cell.get_text(strip=True)
# colspan/rowspan > 1인 경우 셀 병합
if colspan > 1 or rowspan > 1:
end_row = row_idx + rowspan
end_col = col_idx + colspan - 1
sheet.Range[row_idx + 1, col_idx, end_row, end_col].Merge()
# 건너뛸 병합된 셀 표시
for r in range(row_idx + 1, end_row + 1):
for c in range(col_idx, end_col + 1):
if r != row_idx + 1 or c != col_idx: # 주 셀 건너뛰기
skip_cells.add((r, c))
col_idx += colspan
# 사용된 모든 범위의 열 너비 자동 맞춤
sheet.AllocatedRange.AutoFitColumns()
# Excel에 저장
workbook.SaveToFile("TableToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
장점:
- 완전한 제어—데이터를 파싱, 정리 및 변환할 수 있음.
- 병합된 셀을 올바르게 처리함.
- 여러 표나 웹사이트로 쉽게 확장 가능.
- 예약된 작업이나 일괄 작업에 대해 자동화 가능.
단점:
- Python 설치 및 기본 프로그래밍 지식 필요.
- 내장된 Excel 솔루션보다 설정이 더 많음.
- 외부 의존성(BeautifulSoup, Spire.XLS).
사용 시기: 크거나 복잡한 표를 정기적으로 추출하는 개발자나 고급 사용자에게 가장 적합합니다.
출력:
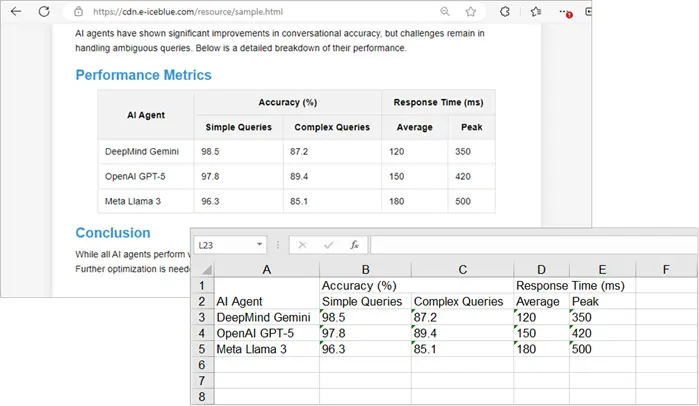
Python에서 생성된 Excel 워크시트의 시각적 매력을 향상시키려면 Excel의 셀 또는 워크시트에 스타일을 적용할 수 있습니다.
요약 표: 사용 사례별 최적의 방법
| 방법 | 가장 적합한 경우 | 장점 | 단점 | 자동화? |
|---|---|---|---|---|
| 수동 복사-붙여넣기 | 빠른, 일회성 사용 | 빠르고 설정 없음 | 자동화 불가, 서식 문제 | ❌아니요 |
| Excel 웹에서 | 실시간 구조화된 데이터 | 통합, 새로 고침 지원 | 동적 표에 제한적 | ❌아니요 |
| VBA 매크로 | Excel에서 반복 작업 | 추출 자동화, 병합 처리 | VBA 지식 필요 | ✅예 |
| Python (BeautifulSoup + Spire.XLS) | 개발자, 크거나 복잡한 표 | 완전한 제어, 확장 가능, 자동화 가능 | 코딩 및 의존성 필요 | ✅예 |
마지막 생각
선택하는 방법은 주로 사용 사례에 따라 다릅니다.
- 가끔 작은 표만 가져오면 되는 경우 수동 복사-붙여넣기가 가장 빠릅니다.
- 자주 업데이트되는 웹 페이지에서 구조화된 데이터를 가져오려면 Excel의 웹에서 기능이 편리합니다.
- 매일 Excel에서 작업하고 자동화를 원하는 비즈니스 사용자의 경우 VBA 매크로가 이상적입니다.
- 여러 데이터 세트나 복잡한 HTML 구조를 처리하는 개발자의 경우 BeautifulSoup와 Spire.XLS를 사용하는 Python이 가장 큰 유연성과 확장성을 제공합니다.
이러한 방법을 워크플로와 결합하면 수동 작업 시간을 절약하고 Excel로 더 깨끗하고 신뢰할 수 있는 데이터를 추출할 수 있습니다.
참고 항목
4 méthodes efficaces pour extraire des tableaux HTML vers Excel (manuel et automatisé)
Table des matières
Installer avec Pypi
pip install Spire.XLS
Liens connexes
Aperçu
L'extraction de tableaux HTML dans Excel est une exigence courante pour les analystes de données, les chercheurs, les développeurs et les professionnels qui travaillent fréquemment avec des données Web structurées. Les tableaux HTML contiennent souvent des informations précieuses telles que des rapports financiers, des catalogues de produits, des résultats de recherche ou des statistiques de performance. Cependant, transférer ces données dans Excel dans un format propre et utilisable peut être délicat, en particulier lorsqu'il s'agit de tableaux complexes comprenant des cellules fusionnées (rowspan, colspan), des en-têtes imbriqués ou de grands ensembles de données.
Heureusement, il existe plusieurs approches pour convertir des tableaux HTML en fichiers Excel. Ces méthodes vont des actions rapides et manuelles de copier-coller, adaptées aux petites tâches, aux scripts entièrement automatisés utilisant VBA ou Python pour des travaux à grande échelle ou récurrents.
Dans cet article, nous explorerons quatre méthodes efficaces pour extraire des tableaux HTML vers Excel :
- Copier-coller manuel (méthode la plus simple)
- Fonctionnalité intégrée « À partir du Web » d'Excel
- Macro VBA (Automatisation d'Excel)
- Python (BeautifulSoup + Spire.XLS)
Enfin, nous comparerons ces approches dans un tableau récapitulatif pour vous aider à choisir la meilleure méthode en fonction de votre cas d'utilisation.
Copier-coller manuel (Méthode la plus simple)
Pour les extractions ponctuelles et de petite taille, l'option la plus simple est d'utiliser le copier-coller directement depuis votre navigateur vers Excel.
Étapes :
- Ouvrez la page HTML dans un navigateur (par ex., Chrome, Edge ou Firefox).
- Surlignez le tableau que vous souhaitez extraire.
- Copiez-le avec Ctrl+C (ou clic droit → Copier).
- Ouvrez Excel et collez avec Ctrl+V.
Avantages :
- Extrêmement simple — aucune configuration ni codage requis.
- Fonctionne instantanément pour les petits tableaux propres.
Inconvénients :
- Processus manuel — fastidieux et inefficace pour les ensembles de données fréquents ou volumineux.
- Ne préserve pas toujours les cellules fusionnées ou la mise en forme.
- Ne peut pas gérer de manière fiable les tableaux dynamiques (rendus par JavaScript).
Quand l'utiliser : Idéal pour les petits tableaux, la collecte de données ad hoc ou des tests rapides.
Fonctionnalité intégrée « À partir du Web » d'Excel
Excel comprend un puissant outil « Obtenir et transformer des données » (anciennement Power Query) qui permet aux utilisateurs d'extraire des tableaux directement d'une page Web.
Étapes :
- Ouvrez Excel.
- Allez dans Données → À partir du Web.
- Entrez l'URL de la page Web contenant le tableau.
- Excel affichera les tableaux détectés ; sélectionnez celui que vous voulez.
- Chargez les données dans votre feuille de calcul.
Avantages :
- Intégration directe dans Excel — aucun outil externe requis.
- Fonctionne bien pour les tableaux HTML structurés.
- Prend en charge l'actualisation — peut extraire à nouveau les données mises à jour de la même source.
Inconvénients :
- Prise en charge limitée du contenu dynamique ou rendu par JavaScript.
- Échoue parfois à détecter les tableaux complexes.
- Nécessite un accès Internet et une URL valide (pas pour les fichiers HTML locaux, sauf s'ils sont importés manuellement).
Quand l'utiliser : Idéal pour les analystes qui extraient des données structurées en direct de sites Web régulièrement mis à jour.
Macro VBA (Automatisation d'Excel)
Pour les utilisateurs qui extraient fréquemment des tableaux HTML et souhaitent plus de contrôle, VBA (Visual Basic for Applications) offre une excellente solution. VBA vous permet de récupérer des tableaux à partir d'une URL et de traiter correctement les cellules fusionnées, ce que le simple copier-coller ne peut pas gérer.
Étapes :
- Lancez Microsoft Excel.
- Appuyez sur Alt + F11 pour ouvrir l'éditeur VBA.
- Cliquez avec le bouton droit sur l'explorateur de projets → Insérer → Module.
- Collez le code VBA fourni.
- Fermez l'éditeur VBA.
- Appuyez sur Alt + F8, sélectionnez le nom de la macro et cliquez sur Exécuter.
Exemple de code VBA :
Sub ExtractHTMLTableWithProperMerging()
Dim html As Object, tables As Object, table As Object, row As Object, cell As Object
Dim ws As Worksheet
Dim iRow As Long, iCol As Long, realCol As Long
Dim url As String
Dim colspan As Integer, rowspan As Integer
Dim cellTracker() As Boolean ' Suivre les cellules occupées
' Définir la feuille de calcul cible
Set ws = ThisWorkbook.Sheets("Sheet1")
ws.Cells.ClearContents
ws.Cells.UnMerge ' Effacer toutes les cellules fusionnées existantes
' Obtenir l'URL d'entrée
url = InputBox("Entrez l'URL de la page Web :", "Extracteur de tableau HTML")
If url = "" Then Exit Sub
' Charger le HTML
Set html = CreateObject("htmlfile")
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", url, False
.send
html.body.innerHTML = .responseText
End With
' Obtenir le premier tableau (changer l'index si nécessaire)
Set tables = html.getElementsByTagName("table")
If tables.Length = 0 Then
MsgBox "Aucun tableau trouvé !", vbExclamation
Exit Sub
End If
Set table = tables(0)
' Initialiser le tableau de suivi des cellules
Dim maxRows As Long, maxCols As Long
maxRows = table.Rows.Length
maxCols = 0
For Each row In table.Rows
If row.Cells.Length > maxCols Then maxCols = row.Cells.Length
Next
ReDim cellTracker(1 To maxRows, 1 To maxCols)
' Traiter le tableau
iRow = 1
For Each row In table.Rows
realCol = 1 ' Suivre la position réelle de la colonne en tenant compte des rowspans
' Trouver la première colonne disponible dans cette ligne
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
iCol = 1 ' Suivre la position logique de la colonne
For Each cell In row.Cells
' Obtenir les attributs de fusion
colspan = 1
rowspan = 1
On Error Resume Next ' Au cas où les attributs n'existeraient pas
colspan = cell.colspan
rowspan = cell.rowspan
On Error GoTo 0
' Sauter les cellules déjà occupées (par un rowspan ci-dessus)
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
If realCol > maxCols Then Exit For
' Écrire la valeur
ws.Cells(iRow, realCol).Value = cell.innerText
' Marquer toutes les cellules qui seront occupées par cette cellule
Dim r As Long, c As Long
For r = iRow To iRow + rowspan - 1
For c = realCol To realCol + colspan - 1
If r <= maxRows And c <= maxCols Then
cellTracker(r, c) = True
End If
Next c
Next r
' Fusionner les cellules si nécessaire
If colspan > 1 Or rowspan > 1 Then
With ws.Range(ws.Cells(iRow, realCol), ws.Cells(iRow + rowspan - 1, realCol + colspan - 1))
.Merge
.HorizontalAlignment = xlCenter
.VerticalAlignment = xlCenter
End With
End If
realCol = realCol + colspan
iCol = iCol + 1
Next cell
iRow = iRow + 1
Next row
' Mise en forme
ws.UsedRange.Columns.AutoFit
ws.UsedRange.Borders.Weight = xlThin
MsgBox "Tableau extrait avec fusion correcte !", vbInformation
End Sub
Avantages :
- S'exécute entièrement dans Excel — aucun outil externe requis.
- Gère les tableaux complexes avec des cellules fusionnées.
- Peut être personnalisé pour plusieurs tableaux ou une exécution planifiée.
Inconvénients :
- La configuration nécessite des connaissances en VBA.
- Ne peut pas gérer les données rendues par JavaScript sans étapes supplémentaires.
- Ne fonctionne que dans la version de bureau d'Excel (pas dans Excel Online).
Quand l'utiliser : Parfait pour les utilisateurs qui extraient régulièrement des tableaux similaires et souhaitent une solution en un clic.
Python (BeautifulSoup & Spire.XLS)
Pour les développeurs ou les utilisateurs expérimentés, Python offre la solution la plus flexible, évolutive et automatisée. Avec des bibliothèques comme BeautifulSoup pour l'analyse HTML et Spire.XLS for Python pour la manipulation d'Excel, vous pouvez récupérer, nettoyer et exporter des tableaux par programmation avec un contrôle total.
Étapes :
- Installez Python (3.8+ recommandé).
- Créez un nouveau projet dans votre IDE (par ex., VS Code, PyCharm).
- Installez les dépendances :
pip install requests beautifulsoup4 spire.xls
- Copiez et exécutez le script suivant.
Code Python :
import requests
from bs4 import BeautifulSoup
from spire.xls import Workbook, ExcelVersion
# Obtenir la chaîne HTML de l'URL
response = requests.get("https://cdn.e-iceblue.com/resource/sample.html")
html = response.text
# Analyser le HTML
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table") # Obtenir le premier tableau
# Initialiser Excel
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Suivre les cellules fusionnées pour les ignorer plus tard
skip_cells = set()
# Parcourir les lignes et les cellules HTML
for row_idx, row in enumerate(table.find_all("tr")):
col_idx = 1 # Les colonnes d'Excel commencent à 1
for cell in row.find_all(["th", "td"]):
# Ignorer les cellules déjà fusionnées
while (row_idx + 1, col_idx) in skip_cells:
col_idx += 1
# Obtenir les valeurs de colspan/rowspan (par défaut 1 si absentes)
colspan = int(cell.get("colspan", 1))
rowspan = int(cell.get("rowspan", 1))
# Écrire la valeur de la cellule dans Excel
sheet.Range[row_idx + 1, col_idx].Text = cell.get_text(strip=True)
# Fusionner les cellules si colspan/rowspan > 1
if colspan > 1 or rowspan > 1:
end_row = row_idx + rowspan
end_col = col_idx + colspan - 1
sheet.Range[row_idx + 1, col_idx, end_row, end_col].Merge()
# Marquer les cellules fusionnées pour les ignorer
for r in range(row_idx + 1, end_row + 1):
for c in range(col_idx, end_col + 1):
if r != row_idx + 1 or c != col_idx: # Ignorer la cellule principale
skip_cells.add((r, c))
col_idx += colspan
# Ajuster automatiquement la largeur des colonnes dans toute la plage utilisée
sheet.AllocatedRange.AutoFitColumns()
# Enregistrer dans Excel
workbook.SaveToFile("TableToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Avantages :
- Contrôle total — peut analyser, nettoyer et transformer les données.
- Gère correctement les cellules fusionnées.
- Facilement adaptable à plusieurs tableaux ou sites web.
- Automatisable pour des tâches planifiées ou des travaux par lots.
Inconvénients :
- Nécessite l'installation de Python et des connaissances de base en programmation.
- Plus de configuration que les solutions intégrées d'Excel.
- Dépendances externes (BeautifulSoup, Spire.XLS).
Quand l'utiliser : Idéal pour les développeurs ou les utilisateurs avancés qui extraient régulièrement des tableaux volumineux ou complexes.
Sortie :
Pour améliorer l'attrait visuel de la feuille de calcul Excel générée en Python, vous pouvez appliquer des styles aux cellules ou aux feuilles de calcul dans Excel.
Tableau récapitulatif : Meilleure méthode par cas d'utilisation
| Méthode | Idéal pour | Avantages | Inconvénients | Automatisation ? |
|---|---|---|---|---|
| Copier-coller manuel | Utilisation rapide et ponctuelle | Rapide, sans configuration | Pas d'automatisation, problèmes de formatage | ❌Non |
| Excel À partir du Web | Données structurées en direct | Intégré, prend en charge l'actualisation | Limité pour les tableaux dynamiques | ❌Non |
| Macro VBA | Tâches répétées dans Excel | Automatise l'extraction, gère les fusions | Nécessite des connaissances en VBA | ✅Oui |
| Python (BeautifulSoup + Spire.XLS) | Développeurs, tableaux volumineux/complexes | Contrôle total, évolutif, automatisable | Nécessite du codage et des dépendances | ✅Oui |
Réflexions finales
La méthode que vous choisissez dépend en grande partie de votre cas d'utilisation :
- Si vous n'avez besoin de récupérer qu'un petit tableau occasionnellement, le copier-coller manuel est le plus rapide.
- Si vous souhaitez extraire des données structurées d'une page Web qui se met à jour fréquemment, la fonction À partir du Web d'Excel est pratique.
- Pour les utilisateurs professionnels qui travaillent quotidiennement dans Excel et souhaitent une automatisation, une macro VBA est idéale.
- Pour les développeurs qui gèrent plusieurs ensembles de données ou des structures HTML complexes, Python avec BeautifulSoup et Spire.XLS offre la plus grande flexibilité et évolutivité.
En combinant ces méthodes avec votre flux de travail, vous pouvez économiser des heures d'efforts manuels et garantir une extraction de données plus propre et plus fiable dans Excel.
Voir aussi
4 métodos efectivos para extraer tablas HTML a Excel (manuales y automatizados)
Tabla de contenidos
Instalar con Pypi
pip install Spire.XLS
Enlaces relacionados
Descripción general
Extraer tablas HTML a Excel es un requisito común para analistas de datos, investigadores, desarrolladores y profesionales de negocios que trabajan frecuentemente con datos web estructurados. Las tablas HTML a menudo contienen información valiosa como informes financieros, catálogos de productos, resultados de investigación o estadísticas de rendimiento. Sin embargo, transferir esos datos a Excel en un formato limpio y utilizable puede ser complicado, especialmente cuando se trata de tablas complejas que incluyen celdas combinadas (rowspan, colspan), encabezados anidados o grandes conjuntos de datos.
Afortunadamente, existen múltiples enfoques para convertir tablas HTML en archivos de Excel. Estos métodos van desde acciones rápidas y manuales de copiar y pegar, adecuadas para tareas pequeñas, hasta scripts totalmente automatizados que utilizan VBA o Python para trabajos a gran escala o recurrentes.
En este artículo, exploraremos cuatro métodos efectivos para extraer tablas HTML a Excel:
- Copiar y pegar manualmente (método más simple)
- Función incorporada de Excel "Desde la Web"
- Macro de VBA (Automatización de Excel)
- Python (BeautifulSoup + Spire.XLS)
Finalmente, compararemos estos enfoques en una tabla de resumen para ayudarlo a elegir el mejor método según su caso de uso.
Copiar y pegar manualmente (Método más simple)
Para extracciones pequeñas y puntuales, la opción más sencilla es usar copiar y pegar directamente desde su navegador a Excel.
Pasos:
- Abra la página HTML en un navegador (por ejemplo, Chrome, Edge o Firefox).
- Resalte la tabla que desea extraer.
- Cópiela con Ctrl+C (o haga clic derecho → Copiar).
- Abra Excel y pegue con Ctrl+V.
Ventajas:
- Extremadamente simple: no se requiere configuración ni codificación.
- Funciona instantáneamente para tablas pequeñas и limpias.
Desventajas:
- Proceso manual: tedioso e ineficiente para conjuntos de datos frecuentes o grandes.
- No siempre conserva las celdas combinadas o el formato.
- No puede manejar tablas dinámicas (renderizadas con JavaScript) de manera confiable.
Cuándo usarlo: Ideal para tablas pequeñas, recopilación de datos ad-hoc o pruebas rápidas.
Función incorporada de Excel "Desde la Web"
Excel incluye una potente herramienta "Obtener y transformar datos" (anteriormente Power Query) que permite a los usuarios extraer tablas directamente de una página web.
Pasos:
- Abra Excel.
- Vaya a Datos → Desde la Web.
- Ingrese la URL de la página web que contiene la tabla.
- Excel mostrará las tablas detectadas; seleccione la que desee.
- Cargue los datos en su hoja de trabajo.
Ventajas:
- Integración directa en Excel: no se requieren herramientas externas.
- Funciona bien para tablas HTML estructuradas.
- Admite la actualización: puede volver a extraer datos actualizados de la misma fuente.
Desventajas:
- Soporte limitado para contenido dinámico o renderizado con JavaScript.
- A veces no detecta tablas complejas.
- Requiere acceso a Internet y una URL válida (no para archivos HTML locales a menos que se importen manualmente).
Cuándo usarlo: Ideal para analistas que extraen datos estructurados en vivo de sitios web que se actualizan regularmente.
Macro de VBA (Automatización de Excel)
Para los usuarios que extraen tablas HTML con frecuencia y desean más control, VBA (Visual Basic for Applications) ofrece una excelente solución. VBA le permite obtener tablas de una URL y procesar correctamente las celdas combinadas, algo que el simple copiar y pegar no puede manejar.
Pasos:
- Inicie Microsoft Excel.
- Presione Alt + F11 para abrir el editor de VBA.
- Haga clic derecho en el explorador de proyectos → Insertar → Módulo.
- Pegue el código VBA proporcionado.
- Cierre el editor de VBA.
- Presione Alt + F8, seleccione el nombre de la macro y haga clic en Ejecutar.
Código de muestra de VBA:
Sub ExtractHTMLTableWithProperMerging()
Dim html As Object, tables As Object, table As Object, row As Object, cell As Object
Dim ws As Worksheet
Dim iRow As Long, iCol As Long, realCol As Long
Dim url As String
Dim colspan As Integer, rowspan As Integer
Dim cellTracker() As Boolean ' Rastrear celdas ocupadas
' Establecer hoja de trabajo de destino
Set ws = ThisWorkbook.Sheets("Sheet1")
ws.Cells.ClearContents
ws.Cells.UnMerge ' Limpiar cualquier celda combinada existente
' Obtener la URL de entrada
url = InputBox("Ingrese la URL de la página web:", "Extractor de tablas HTML")
If url = "" Then Exit Sub
' Cargar HTML
Set html = CreateObject("htmlfile")
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", url, False
.send
html.body.innerHTML = .responseText
End With
' Obtener la primera tabla (cambiar el índice si es necesario)
Set tables = html.getElementsByTagName("table")
If tables.Length = 0 Then
MsgBox "No se encontraron tablas!", vbExclamation
Exit Sub
End If
Set table = tables(0)
' Inicializar la matriz de seguimiento de celdas
Dim maxRows As Long, maxCols As Long
maxRows = table.Rows.Length
maxCols = 0
For Each row In table.Rows
If row.Cells.Length > maxCols Then maxCols = row.Cells.Length
Next
ReDim cellTracker(1 To maxRows, 1 To maxCols)
' Procesar la tabla
iRow = 1
For Each row In table.Rows
realCol = 1 ' Rastrear la posición real de la columna teniendo en cuenta los rowspans
' Encontrar la primera columna disponible en esta fila
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
iCol = 1 ' Rastrear la posición lógica de la columna
For Each cell In row.Cells
' Obtener atributos de combinación
colspan = 1
rowspan = 1
On Error Resume Next ' En caso de que los atributos no existan
colspan = cell.colspan
rowspan = cell.rowspan
On Error GoTo 0
' Omitir celdas ya ocupadas (desde rowspan anterior)
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
If realCol > maxCols Then Exit For
' Escribir valor
ws.Cells(iRow, realCol).Value = cell.innerText
' Marcar todas las celdas que serán ocupadas por esta celda
Dim r As Long, c As Long
For r = iRow To iRow + rowspan - 1
For c = realCol To realCol + colspan - 1
If r <= maxRows And c <= maxCols Then
cellTracker(r, c) = True
End If
Next c
Next r
' Combinar celdas si es necesario
If colspan > 1 Or rowspan > 1 Then
With ws.Range(ws.Cells(iRow, realCol), ws.Cells(iRow + rowspan - 1, realCol + colspan - 1))
.Merge
.HorizontalAlignment = xlCenter
.VerticalAlignment = xlCenter
End With
End If
realCol = realCol + colspan
iCol = iCol + 1
Next cell
iRow = iRow + 1
Next row
' Formato
ws.UsedRange.Columns.AutoFit
ws.UsedRange.Borders.Weight = xlThin
MsgBox "¡Tabla extraída con la combinación correcta!", vbInformation
End Sub
Ventajas:
- Se ejecuta completamente dentro de Excel, sin necesidad de herramientas externas.
- Maneja tablas complejas con celdas combinadas.
- Se puede personalizar para múltiples tablas o ejecución programada.
Desventajas:
- La configuración requiere conocimientos de VBA.
- No puede manejar datos renderizados con JavaScript sin pasos adicionales.
- Solo funciona en el escritorio de Excel (no en Excel Online).
Cuándo usarlo: Perfecto para usuarios que extraen tablas similares regularmente y desean una solución de un solo clic.
Python (BeautifulSoup & Spire.XLS)
Para desarrolladores o usuarios avanzados, Python proporciona la solución más flexible, escalable y automatizada. Con bibliotecas como BeautifulSoup para analizar HTML y Spire.XLS for Python para la manipulación de Excel, puede obtener, limpiar y exportar tablas mediante programación con un control total.
Pasos:
- Instale Python (se recomienda 3.8+).
- Cree un nuevo proyecto en su IDE (por ejemplo, VS Code, PyCharm).
- Instale las dependencias:
pip install requests beautifulsoup4 spire.xls
- Copie y ejecute el siguiente script.
Código de Python:
import requests
from bs4 import BeautifulSoup
from spire.xls import Workbook, ExcelVersion
# Obtener la cadena HTML de la URL
response = requests.get("https://cdn.e-iceblue.com/resource/sample.html")
html = response.text
# Analizar HTML
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table") # Obtener la primera tabla
# Inicializar Excel
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Rastrear celdas combinadas para omitirlas más tarde
skip_cells = set()
# Recorrer filas y celdas HTML
for row_idx, row in enumerate(table.find_all("tr")):
col_idx = 1 # Las columnas de Excel comienzan en 1
for cell in row.find_all(["th", "td"]):
# Omitir celdas ya combinadas
while (row_idx + 1, col_idx) in skip_cells:
col_idx += 1
# Obtener valores de colspan/rowspan (por defecto 1 si no están presentes)
colspan = int(cell.get("colspan", 1))
rowspan = int(cell.get("rowspan", 1))
# Escribir el valor de la celda en Excel
sheet.Range[row_idx + 1, col_idx].Text = cell.get_text(strip=True)
# Combinar celdas si colspan/rowspan > 1
if colspan > 1 or rowspan > 1:
end_row = row_idx + rowspan
end_col = col_idx + colspan - 1
sheet.Range[row_idx + 1, col_idx, end_row, end_col].Merge()
# Marcar las celdas combinadas para omitirlas
for r in range(row_idx + 1, end_row + 1):
for c in range(col_idx, end_col + 1):
if r != row_idx + 1 or c != col_idx: # Omitir la celda principal
skip_cells.add((r, c))
col_idx += colspan
# Autoajustar el ancho de las columnas en todo el rango utilizado
sheet.AllocatedRange.AutoFitColumns()
# Guardar en Excel
workbook.SaveToFile("TableToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Ventajas:
- Control total: puede analizar, limpiar y transformar datos.
- Maneja correctamente las celdas combinadas.
- Fácilmente escalable a múltiples tablas o sitios web.
- Automatizable para tareas programadas o trabajos por lotes.
Desventajas:
- Requiere instalación de Python y conocimientos básicos de programación.
- Más configuración que las soluciones integradas de Excel.
- Dependencias externas (BeautifulSoup, Spire.XLS).
Cuándo usarlo: Ideal para desarrolladores o usuarios avanzados que extraen tablas grandes o complejas con regularidad.
Salida:
Para mejorar el atractivo visual de la hoja de trabajo de Excel generada en Python, puede aplicar estilos a celdas u hojas de trabajo en Excel.
Tabla de resumen: Mejor método por caso de uso
| Método | Ideal para | Ventajas | Desventajas | ¿Automatización? |
|---|---|---|---|---|
| Copiar y pegar manualmente | Uso rápido y puntual | Rápido, sin configuración | Sin automatización, problemas de formato | ❌No |
| Excel Desde la Web | Datos estructurados en vivo | Integrado, admite actualización | Limitado para tablas dinámicas | ❌No |
| Macro de VBA | Tareas repetidas en Excel | Automatiza la extracción, maneja combinaciones | Requiere conocimientos de VBA | ✅Sí |
| Python (BeautifulSoup + Spire.XLS) | Desarrolladores, tablas grandes/complejas | Control total, escalable, automatizable | Requiere codificación y dependencias | ✅Sí |
Consideraciones finales
El método que elija depende en gran medida de su caso de uso:
- Si solo necesita tomar una pequeña tabla ocasionalmente, copiar y pegar manualmente es lo más rápido.
- Si desea extraer datos estructurados de una página web que se actualiza con frecuencia, Excel Desde la Web es conveniente.
- Para los usuarios de negocios que trabajan en Excel a diario y desean automatización, una macro de VBA es ideal.
- Para los desarrolladores que manejan múltiples conjuntos de datos o estructuras HTML complejas, Python con BeautifulSoup y Spire.XLS proporciona la mayor flexibilidad y escalabilidad.
Al combinar estos métodos con su flujo de trabajo, puede ahorrar horas de esfuerzo manual y garantizar una extracción de datos más limpia y confiable en Excel.
Véase también
4 effektive Methoden, um HTML-Tabellen nach Excel zu extrahieren (manuell & automatisiert)
Inhaltsverzeichnis
Installation mit Pypi
pip install Spire.XLS
Verwandte Links
Überblick
Das Extrahieren von HTML-Tabellen in Excel ist eine häufige Anforderung für Datenanalysten, Forscher, Entwickler und Geschäftsleute, die häufig mit strukturierten Webdaten arbeiten. HTML-Tabellen enthalten oft wertvolle Informationen wie Finanzberichte, Produktkataloge, Forschungsergebnisse oder Leistungsstatistiken. Die Übertragung dieser Daten in ein sauberes und nutzbares Format in Excel kann jedoch knifflig sein – insbesondere bei komplexen Tabellen mit verbundenen Zellen (rowspan, colspan), verschachtelten Kopfzeilen oder großen Datenmengen.
Glücklicherweise gibt es mehrere Ansätze, um HTML-Tabellen in Excel-Dateien zu konvertieren. Diese Methoden reichen von schnellen, manuellen Kopier- und Einfügeaktionen, die für kleine Aufgaben geeignet sind, bis hin zu vollständig automatisierten Skripten mit VBA oder Python für große oder wiederkehrende Aufgaben.
In diesem Artikel werden wir vier effektive Methoden zur Extraktion von HTML-Tabellen nach Excel untersuchen:
- Manuelles Kopieren und Einfügen (einfachste Methode)
- Excel’s integrierte „Aus dem Web“-Funktion
- VBA-Makro (Excel-Automatisierung)
- Python (BeautifulSoup + Spire.XLS)
Schließlich vergleichen wir diese Ansätze in einer Zusammenfassungstabelle, um Ihnen bei der Auswahl der besten Methode für Ihren Anwendungsfall zu helfen.
Manuelles Kopieren und Einfügen (einfachste Methode)
Für kleine, einmalige Extraktionen ist die einfachste Option, direkt aus Ihrem Browser in Excel zu kopieren und einzufügen.
Schritte:
- Öffnen Sie die HTML-Seite in einem Browser (z. B. Chrome, Edge oder Firefox).
- Markieren Sie die Tabelle, die Sie extrahieren möchten.
- Kopieren Sie sie mit Strg+C (oder Rechtsklick → Kopieren).
- Öffnen Sie Excel und fügen Sie sie mit Strg+V ein.
Vorteile:
- Extrem einfach – keine Einrichtung oder Programmierung erforderlich.
- Funktioniert sofort für kleine, saubere Tabellen.
Nachteile:
- Manueller Prozess – mühsam und ineffizient bei häufigen oder großen Datenmengen.
- Behält nicht immer verbundene Zellen oder Formatierungen bei.
- Kann dynamische (JavaScript-gerenderte) Tabellen nicht zuverlässig handhaben.
Wann verwenden: Am besten geeignet für kleine Tabellen, Ad-hoc-Datenerfassung oder schnelle Tests.
Excel’s integrierte „Aus dem Web“-Funktion
Excel enthält ein leistungsstarkes „Daten abrufen und transformieren“-Tool (früher Power Query), mit dem Benutzer Tabellen direkt von einer Webseite abrufen können.
Schritte:
- Öffnen Sie Excel.
- Gehen Sie zu Daten → Aus dem Web.
- Geben Sie die URL der Webseite ein, die die Tabelle enthält.
- Excel zeigt die erkannten Tabellen an; wählen Sie die gewünschte aus.
- Laden Sie die Daten in Ihr Arbeitsblatt.
Vorteile:
- Direkte Integration in Excel – keine externen Tools erforderlich.
- Funktioniert gut für strukturierte HTML-Tabellen.
- Unterstützt die Aktualisierung – kann aktualisierte Daten aus derselben Quelle erneut abrufen.
Nachteile:
- Begrenzte Unterstützung für dynamische oder JavaScript-gerenderte Inhalte.
- Erkennt manchmal komplexe Tabellen nicht.
- Erfordert Internetzugang und eine gültige URL (nicht für lokale HTML-Dateien, es sei denn, sie werden manuell importiert).
Wann verwenden: Am besten für Analysten, die live strukturierte Daten von Websites abrufen, die regelmäßig aktualisiert werden.
VBA-Makro (Excel-Automatisierung)
Für Benutzer, die häufig HTML-Tabellen extrahieren und mehr Kontrolle wünschen, bietet VBA (Visual Basic for Applications) eine hervorragende Lösung. Mit VBA können Sie Tabellen von einer URL abrufen und verbundene Zellen korrekt verarbeiten, was mit einfachem Kopieren und Einfügen nicht möglich ist.
Schritte:
- Starten Sie Microsoft Excel.
- Drücken Sie Alt + F11, um den VBA-Editor zu öffnen.
- Klicken Sie mit der rechten Maustaste auf den Projektexplorer → Einfügen → Modul.
- Fügen Sie den bereitgestellten VBA-Code ein.
- Schließen Sie den VBA-Editor.
- Drücken Sie Alt + F8, wählen Sie den Makronamen aus und klicken Sie auf Ausführen.
Beispiel-VBA-Code:
Sub ExtractHTMLTableWithProperMerging()
Dim html As Object, tables As Object, table As Object, row As Object, cell As Object
Dim ws As Worksheet
Dim iRow As Long, iCol As Long, realCol As Long
Dim url As String
Dim colspan As Integer, rowspan As Integer
Dim cellTracker() As Boolean ' Belegte Zellen verfolgen
' Zielarbeitsblatt festlegen
Set ws = ThisWorkbook.Sheets("Sheet1")
ws.Cells.ClearContents
ws.Cells.UnMerge ' Alle vorhandenen verbundenen Zellen löschen
' URL-Eingabe abrufen
url = InputBox("Geben Sie die Webseiten-URL ein:", "HTML-Tabellen-Extraktor")
If url = "" Then Exit Sub
' HTML laden
Set html = CreateObject("htmlfile")
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", url, False
.send
html.body.innerHTML = .responseText
End With
' Erste Tabelle abrufen (Index bei Bedarf ändern)
Set tables = html.getElementsByTagName("table")
If tables.Length = 0 Then
MsgBox "Keine Tabellen gefunden!", vbExclamation
Exit Sub
End If
Set table = tables(0)
' Zell-Tracker-Array initialisieren
Dim maxRows As Long, maxCols As Long
maxRows = table.Rows.Length
maxCols = 0
For Each row In table.Rows
If row.Cells.Length > maxCols Then maxCols = row.Cells.Length
Next
ReDim cellTracker(1 To maxRows, 1 To maxCols)
' Tabelle verarbeiten
iRow = 1
For Each row In table.Rows
realCol = 1 ' Tatsächliche Spaltenposition unter Berücksichtigung von Rowspans verfolgen
' Erste verfügbare Spalte in dieser Zeile finden
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
iCol = 1 ' Logische Spaltenposition verfolgen
For Each cell In row.Cells
' Zusammenführungsattribute abrufen
colspan = 1
rowspan = 1
On Error Resume Next ' Falls Attribute nicht existieren
colspan = cell.colspan
rowspan = cell.rowspan
On Error GoTo 0
' Bereits belegte Zellen überspringen (durch Rowspan von oben)
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
If realCol > maxCols Then Exit For
' Wert schreiben
ws.Cells(iRow, realCol).Value = cell.innerText
' Alle Zellen markieren, die von dieser Zelle belegt werden
Dim r As Long, c As Long
For r = iRow To iRow + rowspan - 1
For c = realCol To realCol + colspan - 1
If r <= maxRows And c <= maxCols Then
cellTracker(r, c) = True
End If
Next c
Next r
' Zellen bei Bedarf verbinden
If colspan > 1 Or rowspan > 1 Then
With ws.Range(ws.Cells(iRow, realCol), ws.Cells(iRow + rowspan - 1, realCol + colspan - 1))
.Merge
.HorizontalAlignment = xlCenter
.VerticalAlignment = xlCenter
End With
End If
realCol = realCol + colspan
iCol = iCol + 1
Next cell
iRow = iRow + 1
Next row
' Formatierung
ws.UsedRange.Columns.AutoFit
ws.UsedRange.Borders.Weight = xlThin
MsgBox "Tabelle mit korrekter Zusammenführung extrahiert!", vbInformation
End Sub
Vorteile:
- Läuft vollständig in Excel – keine externen Tools erforderlich.
- Behandelt komplexe Tabellen mit verbundenen Zellen.
- Kann für mehrere Tabellen oder geplante Ausführungen angepasst werden.
Nachteile:
- Einrichtung erfordert Kenntnisse in VBA.
- Kann JavaScript-gerenderte Daten nicht ohne zusätzliche Schritte verarbeiten.
- Funktioniert nur in der Desktop-Version von Excel (nicht in Excel Online).
Wann verwenden: Perfekt für Benutzer, die regelmäßig ähnliche Tabellen extrahieren und eine Ein-Klick-Lösung wünschen.
Python (BeautifulSoup & Spire.XLS)
Für Entwickler oder Power-User bietet Python die flexibelste, skalierbarste und automatisierteste Lösung. Mit Bibliotheken wie BeautifulSoup zum Parsen von HTML und Spire.XLS for Python für die Excel-Bearbeitung können Sie Tabellen programmgesteuert abrufen, bereinigen und mit voller Kontrolle exportieren.
Schritte:
- Installieren Sie Python (3.8+ empfohlen).
- Erstellen Sie ein neues Projekt in Ihrer IDE (z. B. VS Code, PyCharm).
- Installieren Sie die Abhängigkeiten:
pip install requests beautifulsoup4 spire.xls
- Kopieren und führen Sie das folgende Skript aus.
Python-Code:
import requests
from bs4 import BeautifulSoup
from spire.xls import Workbook, ExcelVersion
# HTML-String von der URL abrufen
response = requests.get("https://cdn.e-iceblue.com/resource/sample.html")
html = response.text
# HTML parsen
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table") # Die erste Tabelle abrufen
# Excel initialisieren
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Verbundene Zellen verfolgen, um sie später zu überspringen
skip_cells = set()
# Durch HTML-Zeilen und -Zellen iterieren
for row_idx, row in enumerate(table.find_all("tr")):
col_idx = 1 # Excel-Spalten beginnen bei 1
for cell in row.find_all(["th", "td"]):
# Bereits verbundene Zellen überspringen
while (row_idx + 1, col_idx) in skip_cells:
col_idx += 1
# Colspan/Rowspan-Werte abrufen (Standardwert 1, falls nicht vorhanden)
colspan = int(cell.get("colspan", 1))
rowspan = int(cell.get("rowspan", 1))
# Zellenwert in Excel schreiben
sheet.Range[row_idx + 1, col_idx].Text = cell.get_text(strip=True)
# Zellen verbinden, wenn Colspan/Rowspan > 1
if colspan > 1 or rowspan > 1:
end_row = row_idx + rowspan
end_col = col_idx + colspan - 1
sheet.Range[row_idx + 1, col_idx, end_row, end_col].Merge()
# Verbundene Zellen zum Überspringen markieren
for r in range(row_idx + 1, end_row + 1):
for c in range(col_idx, end_col + 1):
if r != row_idx + 1 or c != col_idx: # Die Hauptzelle überspringen
skip_cells.add((r, c))
col_idx += colspan
# Spaltenbreite im gesamten genutzten Bereich automatisch anpassen
sheet.AllocatedRange.AutoFitColumns()
# In Excel speichern
workbook.SaveToFile("TableToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Vorteile:
- Volle Kontrolle – kann Daten parsen, bereinigen und transformieren.
- Behandelt verbundene Zellen korrekt.
- Leicht skalierbar für mehrere Tabellen oder Websites.
- Automatisierbar für geplante Aufgaben oder Stapelverarbeitungen.
Nachteile:
- Erfordert Python-Installation und grundlegende Programmierkenntnisse.
- Mehr Einrichtungsaufwand als bei integrierten Excel-Lösungen.
- Externe Abhängigkeiten (BeautifulSoup, Spire.XLS).
Wann verwenden: Am besten für Entwickler oder fortgeschrittene Benutzer, die regelmäßig große oder komplexe Tabellen extrahieren.
Ausgabe:
Um die visuelle Attraktivität des generierten Excel-Arbeitsblatts in Python zu verbessern, können Sie Stile auf Zellen oder Arbeitsblätter in Excel anwenden.
Zusammenfassungstabelle: Beste Methode nach Anwendungsfall
| Methode | Am besten geeignet für | Vorteile | Nachteile | Automatisierung? |
|---|---|---|---|---|
| Manuelles Kopieren & Einfügen | Schnelle, einmalige Verwendung | Schnell, keine Einrichtung | Keine Automatisierung, Formatierungsprobleme | ❌Nein |
| Excel aus dem Web | Live strukturierte Daten | Integriert, unterstützt Aktualisierung | Begrenzt für dynamische Tabellen | ❌Nein |
| VBA-Makro | Wiederholte Aufgaben in Excel | Automatisiert die Extraktion, behandelt Zusammenführungen | Erfordert VBA-Kenntnisse | ✅Ja |
| Python (BeautifulSoup + Spire.XLS) | Entwickler, große/komplexe Tabellen | Volle Kontrolle, skalierbar, automatisierbar | Erfordert Programmierung & Abhängigkeiten | ✅Ja |
Abschließende Gedanken
Die Methode, die Sie wählen, hängt stark von Ihrem Anwendungsfall ab:
- Wenn Sie nur gelegentlich eine kleine Tabelle benötigen, ist das manuelle Kopieren und Einfügen am schnellsten.
- Wenn Sie strukturierte Daten von einer Webseite abrufen möchten, die häufig aktualisiert wird, ist Excel aus dem Web praktisch.
- Für Geschäftsanwender, die täglich in Excel arbeiten und eine Automatisierung wünschen, ist ein VBA-Makro ideal.
- Für Entwickler, die mehrere Datensätze oder komplexe HTML-Strukturen verarbeiten, bietet Python mit BeautifulSoup und Spire.XLS die größte Flexibilität und Skalierbarkeit.
Durch die Kombination dieser Methoden mit Ihrem Arbeitsablauf können Sie Stunden manueller Arbeit sparen und eine sauberere, zuverlässigere Datenextraktion nach Excel gewährleisten.
Siehe auch
4 эффективных метода извлечения HTML-таблиц в Excel (вручную и автоматически)
Оглавление
Установка через Pypi
pip install Spire.XLS
Похожие ссылки
Обзор
Извлечение HTML-таблиц в Excel является частым требованием для аналитиков данных, исследователей, разработчиков и бизнес-профессионалов, которые часто работают со структурированными веб-данными. HTML-таблицы часто содержат ценную информацию, такую как финансовые отчеты, каталоги продуктов, результаты исследований или статистику производительности. Однако перенос этих данных в Excel в чистом и удобном для использования формате может быть сложной задачей, особенно при работе со сложными таблицами, которые включают объединенные ячейки (rowspan, colspan), вложенные заголовки или большие наборы данных.
К счастью, существует несколько подходов к преобразованию HTML-таблиц в файлы Excel. Эти методы варьируются от быстрых ручных действий копирования-вставки, подходящих для небольших задач, до полностью автоматизированных скриптов с использованием VBA или Python для крупномасштабных или повторяющихся задач.
В этой статье мы рассмотрим четыре эффективных метода извлечения HTML-таблиц в Excel:
- Ручное копирование и вставка (самый простой метод)
- Встроенная функция Excel «Из Интернета»
- Макрос VBA (автоматизация Excel)
- Python (BeautifulSoup + Spire.XLS)
Наконец, мы сравним эти подходы в сводной таблице, чтобы помочь вам выбрать лучший метод в зависимости от вашего варианта использования.
Ручное копирование и вставка (самый простой метод)
Для небольших, одноразовых извлечений самым простым вариантом является использование копирования и вставки непосредственно из браузера в Excel.
Шаги:
- Откройте HTML-страницу в браузере (например, Chrome, Edge или Firefox).
- Выделите таблицу, которую хотите извлечь.
- Скопируйте ее с помощью Ctrl+C (или щелкните правой кнопкой мыши → Копировать).
- Откройте Excel и вставьте с помощью Ctrl+V.
Плюсы:
- Чрезвычайно просто — не требуется настройка или программирование.
- Мгновенно работает для небольших, чистых таблиц.
Минусы:
- Ручной процесс — утомительный и неэффективный для частых или больших наборов данных.
- Не всегда сохраняет объединенные ячейки или форматирование.
- Не может надежно обрабатывать динамические (отрисованные с помощью JavaScript) таблицы.
Когда использовать: лучше всего подходит для небольших таблиц, сбора данных по запросу или быстрого тестирования.
Встроенная функция Excel «Из Интернета»
Excel включает мощный инструмент «Получить и преобразовать данные» (ранее Power Query), который позволяет пользователям извлекать таблицы непосредственно с веб-страницы.
Шаги:
- Откройте Excel.
- Перейдите в Данные → Из Интернета.
- Введите URL-адрес веб-страницы, содержащей таблицу.
- Excel отобразит обнаруженные таблицы; выберите ту, которая вам нужна.
- Загрузите данные на свой рабочий лист.
Плюсы:
- Прямая интеграция в Excel — не требуются внешние инструменты.
- Хорошо работает со структурированными HTML-таблицами.
- Поддерживает обновление — может повторно извлекать обновленные данные из того же источника.
Минусы:
- Ограниченная поддержка динамического или отрисованного с помощью JavaScript контента.
- Иногда не удается обнаружить сложные таблицы.
- Требуется доступ в Интернет и действительный URL-адрес (не для локальных HTML-файлов, если они не импортированы вручную).
Когда использовать: лучше всего для аналитиков, извлекающих живые, структурированные данные с веб-сайтов, которые регулярно обновляются.
Макрос VBA (автоматизация Excel)
Для пользователей, которые часто извлекают HTML-таблицы и хотят большего контроля, VBA (Visual Basic for Applications) предоставляет отличное решение. VBA позволяет извлекать таблицы с URL-адреса и правильно обрабатывать объединенные ячейки, с чем не справляется простое копирование-вставка.
Шаги:
- Запустите Microsoft Excel.
- Нажмите Alt + F11, чтобы открыть редактор VBA.
- Щелкните правой кнопкой мыши в проводнике проекта → Вставить → Модуль.
- Вставьте предоставленный код VBA.
- Закройте редактор VBA.
- Нажмите Alt + F8, выберите имя макроса и нажмите Выполнить.
Пример кода VBA:
Sub ExtractHTMLTableWithProperMerging()
Dim html As Object, tables As Object, table As Object, row As Object, cell As Object
Dim ws As Worksheet
Dim iRow As Long, iCol As Long, realCol As Long
Dim url As String
Dim colspan As Integer, rowspan As Integer
Dim cellTracker() As Boolean ' Отслеживание занятых ячеек
' Установить целевой рабочий лист
Set ws = ThisWorkbook.Sheets("Sheet1")
ws.Cells.ClearContents
ws.Cells.UnMerge ' Очистить все существующие объединенные ячейки
' Получить ввод URL
url = InputBox("Введите URL веб-страницы:", "Извлечение HTML-таблицы")
If url = "" Then Exit Sub
' Загрузить HTML
Set html = CreateObject("htmlfile")
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", url, False
.send
html.body.innerHTML = .responseText
End With
' Получить первую таблицу (измените индекс при необходимости)
Set tables = html.getElementsByTagName("table")
If tables.Length = 0 Then
MsgBox "Таблицы не найдены!", vbExclamation
Exit Sub
End If
Set table = tables(0)
' Инициализировать массив отслеживания ячеек
Dim maxRows As Long, maxCols As Long
maxRows = table.Rows.Length
maxCols = 0
For Each row In table.Rows
If row.Cells.Length > maxCols Then maxCols = row.Cells.Length
Next
ReDim cellTracker(1 To maxRows, 1 To maxCols)
' Обработать таблицу
iRow = 1
For Each row In table.Rows
realCol = 1 ' Отслеживать фактическую позицию столбца с учетом rowspan
' Найти первый доступный столбец в этой строке
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
iCol = 1 ' Отслеживать логическую позицию столбца
For Each cell In row.Cells
' Получить атрибуты объединения
colspan = 1
rowspan = 1
On Error Resume Next ' В случае, если атрибуты не существуют
colspan = cell.colspan
rowspan = cell.rowspan
On Error GoTo 0
' Пропустить уже занятые ячейки (из rowspan выше)
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
If realCol > maxCols Then Exit For
' Записать значение
ws.Cells(iRow, realCol).Value = cell.innerText
' Отметить все ячейки, которые будут заняты этой ячейкой
Dim r As Long, c As Long
For r = iRow To iRow + rowspan - 1
For c = realCol To realCol + colspan - 1
If r <= maxRows And c <= maxCols Then
cellTracker(r, c) = True
End If
Next c
Next r
' Объединить ячейки при необходимости
If colspan > 1 Or rowspan > 1 Then
With ws.Range(ws.Cells(iRow, realCol), ws.Cells(iRow + rowspan - 1, realCol + colspan - 1))
.Merge
.HorizontalAlignment = xlCenter
.VerticalAlignment = xlCenter
End With
End If
realCol = realCol + colspan
iCol = iCol + 1
Next cell
iRow = iRow + 1
Next row
' Форматирование
ws.UsedRange.Columns.AutoFit
ws.UsedRange.Borders.Weight = xlThin
MsgBox "Таблица извлечена с правильным объединением!", vbInformation
End Sub
Плюсы:
- Работает полностью в Excel — не требуются внешние инструменты.
- Обрабатывает сложные таблицы с объединенными ячейками.
- Может быть настроен для нескольких таблиц или запланированного выполнения.
Минусы:
- Настройка требует знания VBA.
- Не может обрабатывать данные, отрисованные с помощью JavaScript, без дополнительных шагов.
- Работает только в настольной версии Excel (не в Excel Online).
Когда использовать: идеально подходит для пользователей, которые регулярно извлекают похожие таблицы и хотят получить решение в один клик.
Python (BeautifulSoup и Spire.XLS)
Для разработчиков или опытных пользователей Python предоставляет наиболее гибкое, масштабируемое и автоматизированное решение. С помощью таких библиотек, как BeautifulSoup для парсинга HTML и Spire.XLS for Python для работы с Excel, вы можете программно извлекать, очищать и экспортировать таблицы с полным контролем.
Шаги:
- Установите Python (рекомендуется 3.8+).
- Создайте новый проект в вашей IDE (например, VS Code, PyCharm).
- Установите зависимости:
pip install requests beautifulsoup4 spire.xls
- Скопируйте и запустите следующий скрипт.
Код на Python:
import requests
from bs4 import BeautifulSoup
from spire.xls import Workbook, ExcelVersion
# Получить строку HTML с URL-адреса
response = requests.get("https://cdn.e-iceblue.com/resource/sample.html")
html = response.text
# Разобрать HTML
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table") # Получить первую таблицу
# Инициализировать Excel
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Отслеживать объединенные ячейки, чтобы пропустить их позже
skip_cells = set()
# Перебрать строки и ячейки HTML
for row_idx, row in enumerate(table.find_all("tr")):
col_idx = 1 # Столбцы Excel начинаются с 1
for cell in row.find_all(["th", "td"]):
# Пропустить уже объединенные ячейки
while (row_idx + 1, col_idx) in skip_cells:
col_idx += 1
# Получить значения colspan/rowspan (по умолчанию 1, если отсутствуют)
colspan = int(cell.get("colspan", 1))
rowspan = int(cell.get("rowspan", 1))
# Записать значение ячейки в Excel
sheet.Range[row_idx + 1, col_idx].Text = cell.get_text(strip=True)
# Объединить ячейки, если colspan/rowspan > 1
if colspan > 1 or rowspan > 1:
end_row = row_idx + rowspan
end_col = col_idx + colspan - 1
sheet.Range[row_idx + 1, col_idx, end_row, end_col].Merge()
# Отметить объединенные ячейки для пропуска
for r in range(row_idx + 1, end_row + 1):
for c in range(col_idx, end_col + 1):
if r != row_idx + 1 or c != col_idx: # Пропустить основную ячейку
skip_cells.add((r, c))
col_idx += colspan
# Автоматически подогнать ширину столбцов во всем используемом диапазоне
sheet.AllocatedRange.AutoFitColumns()
# Сохранить в Excel
workbook.SaveToFile("TableToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Плюсы:
- Полный контроль — можно анализировать, очищать и преобразовывать данные.
- Правильно обрабатывает объединенные ячейки.
- Легко масштабируется на несколько таблиц или веб-сайтов.
- Автоматизируется для запланированных задач или пакетных заданий.
Минусы:
- Требуется установка Python и базовые знания программирования.
- Больше настроек, чем у встроенных решений Excel.
- Внешние зависимости (BeautifulSoup, Spire.XLS).
Когда использовать: лучше всего для разработчиков или продвинутых пользователей, регулярно извлекающих большие или сложные таблицы.
Вывод:
Чтобы улучшить визуальную привлекательность созданного листа Excel на Python, вы можете применять стили к ячейкам или рабочим листам в Excel.
Сводная таблица: лучший метод в зависимости от варианта использования
| Метод | Лучше всего подходит для | Плюсы | Минусы | Автоматизация? |
|---|---|---|---|---|
| Ручное копирование и вставка | Быстрое, одноразовое использование | Быстро, без настроек | Нет автоматизации, проблемы с форматированием | ❌Нет |
| Excel из Интернета | Живые структурированные данные | Интегрировано, поддерживает обновление | Ограничено для динамических таблиц | ❌Нет |
| Макрос VBA | Повторяющиеся задачи в Excel | Автоматизирует извлечение, обрабатывает объединения | Требует знания VBA | ✅Да |
| Python (BeautifulSoup + Spire.XLS) | Разработчики, большие/сложные таблицы | Полный контроль, масштабируемость, автоматизация | Требует программирования и зависимостей | ✅Да |
Заключительные мысли
Метод, который вы выберете, во многом зависит от вашего варианта использования:
- Если вам нужно лишь изредка скопировать небольшую таблицу, ручное копирование и вставка — самый быстрый способ.
- Если вы хотите извлекать структурированные данные с веб-страницы, которая часто обновляется, удобен Excel из Интернета.
- Для бизнес-пользователей, которые ежедневно работают в Excel и хотят автоматизации, идеальным является макрос VBA.
- Для разработчиков, работающих с несколькими наборами данных или сложными структурами HTML, Python с BeautifulSoup и Spire.XLS обеспечивает наибольшую гибкость и масштабируемость.
Комбинируя эти методы с вашим рабочим процессом, вы можете сэкономить часы ручной работы и обеспечить более чистое и надежное извлечение данных в Excel.
Смотрите также
4 Effective Methods to Extract HTML Tables to Excel (Manual & Automated)
Table of Contents
Install with Pypi
pip install Spire.XLS
Related Links
Overview
Extracting HTML tables into Excel is a common requirement for data analysts, researchers, developers, and business professionals who frequently work with structured web data. HTML tables often contain valuable information such as financial reports, product catalogs, research results, or performance statistics. However, transferring that data into Excel in a clean and usable format can be tricky—especially when dealing with complex tables that include merged cells (rowspan, colspan), nested headers, or large datasets.
Fortunately, there are multiple approaches to convert HTML tables into Excel files. These methods range from quick, manual copy-paste actions suitable for small tasks to fully automated scripts using VBA or Python for large-scale or recurring jobs.
In this article, we’ll explore four effective methods for extracting HTML tables to Excel:
- Manual Copy-Paste (simplest method)
- Excel’s Built-in “From Web” Feature
- VBA Macro (Excel Automation)
- Python (BeautifulSoup + Spire.XLS)
Finally, we’ll compare these approaches in a summary table to help you choose the best method based on your use case.
Manual Copy-Paste (Simplest Method)
For small, one-off extractions, the simplest option is to use copy and paste directly from your browser into Excel.
Steps:
- Open the HTML page in a browser (e.g., Chrome, Edge, or Firefox).
- Highlight the table you want to extract.
- Copy it with Ctrl+C (or right-click → Copy).
- Open Excel and paste with Ctrl+V .
Pros:
- Extremely simple—no setup or coding required.
- Works instantly for small, clean tables.
Cons:
- Manual process—tedious and inefficient for frequent or large datasets.
- Doesn’t always preserve merged cells or formatting.
- Cannot handle dynamic (JavaScript-rendered) tables reliably.
When to use : Best suited for small tables, ad-hoc data collection, or quick testing.
Excel’s Built-in “From Web” Feature
Excel includes a powerful “Get & Transform Data” tool (formerly Power Query) that allows users to pull tables directly from a web page.
Steps:
- Open Excel.
- Go to Data → From Web .
- Enter the URL of the webpage containing the table.
- Excel will display detected tables; select the one you want.
- Load the data into your worksheet.
Pros:
- Direct integration into Excel—no external tools required.
- Works well for structured HTML tables.
- Supports refresh—can re-pull updated data from the same source.
Cons:
- Limited support for dynamic or JavaScript-rendered content.
- Sometimes fails to detect complex tables.
- Requires internet access and valid URL (not for local HTML files unless imported manually).
When to use : Best for analysts pulling live, structured data from websites that are updated regularly.
VBA Macro (Excel Automation)
For users who frequently extract HTML tables and want more control, VBA (Visual Basic for Applications) provides an excellent solution. VBA allows you to fetch tables from a URL and correctly process merged cells, something basic copy-paste cannot handle.
Steps:
- Launch Microsoft Excel.
- Press Alt + F11 to open the VBA editor.
- Right-click the project explorer → Insert→ Module .
- Paste the provided VBA code.
- Close the VBA editor.
- Press Alt + F8 , select the macro name, and click Run .
Sample VBA Code:
Sub ExtractHTMLTableWithProperMerging()
Dim html As Object, tables As Object, table As Object, row As Object, cell As Object
Dim ws As Worksheet
Dim iRow As Long, iCol As Long, realCol As Long
Dim url As String
Dim colspan As Integer, rowspan As Integer
Dim cellTracker() As Boolean ' Track occupied cells
' Set target worksheet
Set ws = ThisWorkbook.Sheets("Sheet1")
ws.Cells.ClearContents
ws.Cells.UnMerge ' Clear any existing merged cells
' Get URL input
url = InputBox("Enter webpage URL:", "HTML Table Extractor")
If url = "" Then Exit Sub
' Load HTML
Set html = CreateObject("htmlfile")
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", url, False
.send
html.body.innerHTML = .responseText
End With
' Get first table (change index if needed)
Set tables = html.getElementsByTagName("table")
If tables.Length = 0 Then
MsgBox "No tables found!", vbExclamation
Exit Sub
End If
Set table = tables(0)
' Initialize cell tracker array
Dim maxRows As Long, maxCols As Long
maxRows = table.Rows.Length
maxCols = 0
For Each row In table.Rows
If row.Cells.Length > maxCols Then maxCols = row.Cells.Length
Next
ReDim cellTracker(1 To maxRows, 1 To maxCols)
' Process table
iRow = 1
For Each row In table.Rows
realCol = 1 ' Track actual column position accounting for rowspans
' Find first available column in this row
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
iCol = 1 ' Track logical column position
For Each cell In row.Cells
' Get merge attributes
colspan = 1
rowspan = 1
On Error Resume Next ' In case attributes don't exist
colspan = cell.colspan
rowspan = cell.rowspan
On Error GoTo 0
' Skip already occupied cells (from rowspan above)
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
If realCol > maxCols Then Exit For
' Write value
ws.Cells(iRow, realCol).Value = cell.innerText
' Mark all cells that will be occupied by this cell
Dim r As Long, c As Long
For r = iRow To iRow + rowspan - 1
For c = realCol To realCol + colspan - 1
If r <= maxRows And c <= maxCols Then
cellTracker(r, c) = True
End If
Next c
Next r
' Merge cells if needed
If colspan > 1 Or rowspan > 1 Then
With ws.Range(ws.Cells(iRow, realCol), ws.Cells(iRow + rowspan - 1, realCol + colspan - 1))
.Merge
.HorizontalAlignment = xlCenter
.VerticalAlignment = xlCenter
End With
End If
realCol = realCol + colspan
iCol = iCol + 1
Next cell
iRow = iRow + 1
Next row
' Formatting
ws.UsedRange.Columns.AutoFit
ws.UsedRange.Borders.Weight = xlThin
MsgBox "Table extracted with proper merging!", vbInformation
End Sub
Pros:
- Runs entirely within Excel—no external tools required.
- Handles complex tables with merged cells.
- Can be customized for multiple tables or scheduled execution.
Cons:
- Setup requires knowledge of VBA.
- Cannot handle JavaScript-rendered data without extra steps.
- Only works in Excel desktop (not Excel Online).
When to use : Perfect for users who regularly extract similar tables and want a one-click solution.
Python (BeautifulSoup & Spire.XLS)
For developers or power users, Python provides the most flexible, scalable, and automated solution. With libraries like BeautifulSoup for parsing HTML and Spire.XLS for Python for Excel manipulation, you can programmatically fetch, clean, and export tables with full control.
Steps:
- Install Python (3.8+ recommended).
- Create a new project in your IDE (e.g., VS Code, PyCharm).
- Install dependencies:
pip install requests beautifulsoup4 spire.xls
- Copy and run the following script.
Python Code:
import requests
from bs4 import BeautifulSoup
from spire.xls import Workbook, ExcelVersion
# Get HTML string from url
response = requests.get("https://cdn.e-iceblue.com/resource/sample.html")
html = response.text
# Parse HTML
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table") # Get the first table
# Initialize Excel
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Track merged cells to skip them later
skip_cells = set()
# Loop through HTML rows and cells
for row_idx, row in enumerate(table.find_all("tr")):
col_idx = 1 # Excel columns start at 1
for cell in row.find_all(["th", "td"]):
# Skip already merged cells
while (row_idx + 1, col_idx) in skip_cells:
col_idx += 1
# Get colspan/rowspan values (default to 1 if not present)
colspan = int(cell.get("colspan", 1))
rowspan = int(cell.get("rowspan", 1))
# Write cell value to Excel
sheet.Range[row_idx + 1, col_idx].Text = cell.get_text(strip=True)
# Merge cells if colspan/rowspan > 1
if colspan > 1 or rowspan > 1:
end_row = row_idx + rowspan
end_col = col_idx + colspan - 1
sheet.Range[row_idx + 1, col_idx, end_row, end_col].Merge()
# Mark merged cells to skip
for r in range(row_idx + 1, end_row + 1):
for c in range(col_idx, end_col + 1):
if r != row_idx + 1 or c != col_idx: # Skip the main cell
skip_cells.add((r, c))
col_idx += colspan
# Auto fit column width in all used range
sheet.AllocatedRange.AutoFitColumns()
# Save to Excel
workbook.SaveToFile("TableToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Pros:
- Full control—can parse, clean, and transform data.
- Handles merged cells properly.
- Easily scalable to multiple tables or websites.
- Automatable for scheduled tasks or batch jobs.
Cons:
- Requires Python installation and basic programming knowledge.
- More setup than built-in Excel solutions.
- External dependencies (BeautifulSoup, Spire.XLS).
When to use : Best for developers or advanced users extracting large or complex tables regularly.
Output:
To enhance the visual appeal of the generated Excel worksheet in Python, you can apply styles to cells or worksheets in Excel.
Summary Table: Best Method by Use Case
| Method | Best For | Pros | Cons | Automation? |
|---|---|---|---|---|
| Manual Copy-Paste | Quick, one-time use | Fast, no setup | No automation, formatting issues | ❌No |
| Excel From Web | Live structured data | Integrated, supports refresh | Limited for dynamic tables | ❌No |
| VBA Macro | Repeated tasks in Excel | Automates extraction, handles merges | Requires VBA knowledge | ✅Yes |
| Python (BeautifulSoup + Spire.XLS) | Developers, large/complex tables | Full control, scalable, automatable | Requires coding & dependencies | ✅Yes |
Final Thoughts
The method you choose depends largely on your use case :
- If you only need to grab a small table occasionally, manual copy-paste is the fastest.
- If you want to pull structured data from a webpage that updates frequently, Excel’s From Web is convenient.
- For business users who work in Excel daily and want automation, a VBA macro is ideal.
- For developers handling multiple datasets or complex HTML structures, Python with BeautifulSoup and Spire.XLS provides the most flexibility and scalability.
By combining these methods with your workflow, you can save hours of manual effort and ensure cleaner, more reliable data extraction into Excel.
See Also
How to Scan QR Codes and Barcodes in ASP.NET Core with C#

Many business applications today need the ability to scan barcodes and QR codes in ASP.NET environments. From ticket validation and payment processing to inventory management, an ASP.NET QR code scanner or barcode reading feature can greatly improve efficiency and accuracy for both web and enterprise systems.
This tutorial demonstrates how to build a complete solution to scan barcodes in ASP.NET with C# code using Spire.Barcode for .NET. We’ll create an ASP.NET Core web application that can read both QR codes and various barcode formats from uploaded images, delivering high recognition accuracy and easy integration into existing projects.
Guide Overview
- 1. Project Setup
- 2. Implementing QR Code and Barcode Scanning Feature with C# in ASP.NET
- 3. Testing and Troubleshooting
- 4. Extending to Other .NET Applications
- 5. Conclusion
1. Project Setup
Step 1: Create the Project
Create a new ASP.NET Core Razor Pages project, which will serve as the foundation for the scanning feature. Use the following command to create a new project or manually configure it in Visual Studio:
dotnet new webapp -n QrBarcodeScanner
cd QrBarcodeScanner
Step 2: Install Spire.Barcode for .NET
Install the Spire.Barcode for .NET NuGet package, which supports decoding a wide range of barcode types with a straightforward API. Search for the package in the NuGet Package Manager or use the command below to install it:
dotnet add package Spire.Barcode
Spire.Barcode for .NET offers built-in support for both QR codes and multiple barcode formats such as Code128, EAN-13, and Code39, making it suitable for ASP.NET Core integration without requiring additional image processing libraries. To find out all the supported barcode types, refer to the BarcodeType API reference.
You can also use Free Spire.Barcode for .NET for smaller projects.
2. Implementing QR Code and Barcode Scanning Feature with C# in ASP.NET
A reliable scanning feature involves two main parts:
- Backend logic that processes and decodes uploaded images.
- A simple web interface that lets users upload files for scanning.
We will first focus on the backend implementation to ensure the scanning process works correctly, then connect it to a minimal Razor Page frontend.
Backend: QR & Barcode Scanning Logic with Spire.Barcode
The backend code reads the uploaded file into memory and processes it with Spire.Barcode, using either a memory stream or a file path. The scanned result is then returned. This implementation supports QR codes and other barcode types without requiring format-specific logic.
Index.cshtml.cs
using Microsoft.AspNetCore.Mvc;
using Microsoft.AspNetCore.Mvc.RazorPages;
using Spire.Barcode;
public class IndexModel : PageModel
{
[BindProperty]
public IFormFile Upload { get; set; } // Uploaded file
public string Result { get; set; } // Scanning result
public string UploadedImageBase64 { get; set; } // Base64 string for preview
public void OnPost()
{
if (Upload != null && Upload.Length > 0)
{
using (var ms = new MemoryStream())
{
// Read the uploaded file into memory
Upload.CopyTo(ms);
// Convert the image to Base64 for displaying in HTML <img>
UploadedImageBase64 = "data:" + Upload.ContentType + ";base64," +
Convert.ToBase64String(ms.ToArray());
// Reset the stream position before scanning
ms.Position = 0;
// Scan the barcode or QR code from the stream
try
{
string[] scanned = BarcodeScanner.Scan(ms);
// Return the scanned result
Result = scanned != null && scanned.Length > 0
? string.Join(", ", scanned)
: "No code detected.";
}
catch (Exception ex)
{
Result = "Error while scanning: " + ex.Message;
}
}
}
}
}
Explanation of Key Classes and Methods
- BarcodeScanner: A static class in Spire.Barcode that decodes images containing QR codes or barcodes.
- BarcodeScanner.Scan(Stream imageStream): Scans an uploaded image directly from a memory stream and returns an array of decoded strings. This method scans all barcodes in the given image.
- Supplementary methods (optional):
- BarcodeScanner.Scan(string imagePath): Scans an image from a file path.
- BarcodeScanner.ScanInfo(string imagePath): Scans an image from a file path and returns additional barcode information such as type, location, and data.
These methods can be used in different ways, depending on the application requirements.
Frontend: QR & Barcode Upload & Scanning Result Interface
The following page design provides a simple upload form where users can submit an image containing a QR code or barcode. Once uploaded, the image is displayed along with the recognized result, which can be copied with a single click. The layout is intentionally kept minimal for fast testing, yet styled for a clear and polished presentation.
Index.cshtml
@page
@model IndexModel
@{
ViewData["Title"] = "QR & Barcode Scanner";
}
<div style="max-width:420px;margin:40px auto;padding:20px;border:1px solid #ccc;border-radius:8px;background:#f9f9f9;">
<h2>QR & Barcode Scanner</h2>
<form method="post" enctype="multipart/form-data" id="uploadForm">
<input type="file" name="upload" accept="image/*" required onchange="this.form.submit()" style="margin:10px 0;" />
</form>
@if (!string.IsNullOrEmpty(Model.UploadedImageBase64))
{
<div style="margin-top:15px;text-align:center;">
<img src="/@Model.UploadedImageBase64" style="width:300px;height:300px;object-fit:contain;border:1px solid #ddd;background:#fff;" />
</div>
}
@if (!string.IsNullOrEmpty(Model.Result))
{
<div style="margin-top:15px;padding:10px;background:#e8f5e9;border-radius:6px;">
<b>Scan Result:</b>
<p id="scanText">@Model.Result</p>
<button type="button" onclick="navigator.clipboard.writeText(scanText.innerText)" style="background:#28a745;color:#fff;padding:6px 10px;border:none;border-radius:4px;">Copy</button>
</div>
}
</div>
Below is a screenshot showing the scan page after successfully recognizing both a QR code and a Code128 barcode, with the results displayed and a one-click copy button available.
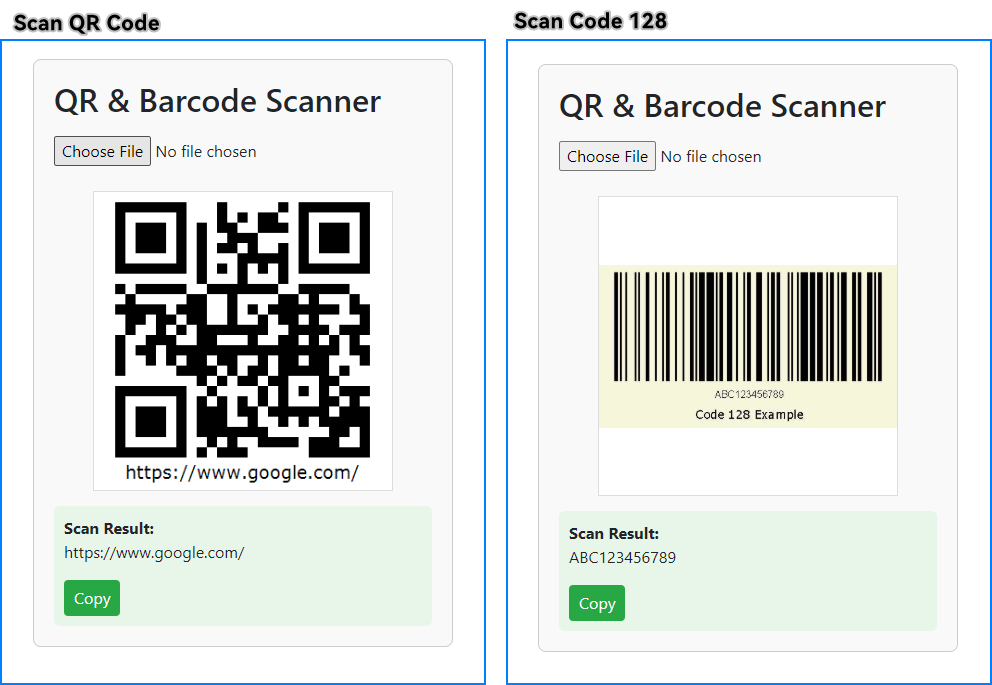
This ASP.NET Core application can scan QR codes and other barcodes from uploaded images. If you're looking to generate QR codes or barcodes, check out How to Generate QR Codes in ASP.NET Core.
3. Testing and Troubleshooting
After running the application, test the scanning feature with:
- A QR code image containing a URL or plain text.
- A barcode image such as Code128 or EAN-13.
If recognition fails:
- Ensure the image has good contrast and minimal distortion.
- Use images of reasonable resolution (not excessively large or pixelated).
- Test with different file formats such as JPG, PNG, or BMP.
- Avoid images with reflections, glare, or low lighting.
- When scanning multiple barcodes in one image, ensure each code is clearly separated to improve recognition accuracy.
A good practice is to maintain a small library of sample QR codes and barcodes to test regularly after making code changes.
4. Extending to Other .NET Applications
The barcode scanning logic in this tutorial works the same way across different .NET application types — only the way you supply the image file changes. This makes it easy to reuse the core decoding method, BarcodeScanner.Scan(), in various environments such as:
- ASP.NET Core MVC controllers or Web API endpoints
- Desktop applications like WinForms or WPF
- Console utilities for batch processing
Example: Minimal ASP.NET Core Web API Endpoint — receives an image file via HTTP POST and returns decoded results as JSON:
[ApiController]
[Route("api/[controller]")]
public class ScanController : ControllerBase
{
[HttpPost]
public IActionResult Scan(IFormFile file)
{
if (file == null) return BadRequest("No file uploaded");
using var ms = new MemoryStream();
file.CopyTo(ms);
ms.Position = 0;
string[] results = BarcodeScanner.Scan(ms);
return Ok(results);
}
}
Example: Console application — scans a local image file and prints the decoded text:
string[] result = BarcodeScanner.Scan(@"C:\path\to\image.png");
Console.WriteLine(string.Join(", ", result));
This flexibility makes it simple for developers to quickly add QR code and barcode scanning to new projects or extend existing .NET applications.
5. Conclusion
This tutorial has shown how to implement a complete QR code and barcode scanning solution in ASP.NET Core using Spire.Barcode for .NET. From receiving uploaded images to decoding and displaying the results, the process is straightforward and adaptable to a variety of application types. With this approach, developers can quickly integrate reliable scanning functionality into e-commerce platforms, ticketing systems, document verification tools, and other business-critical web applications.
For more advanced scenarios, Spire.Barcode for .NET provides additional features such as customizing the recognition process, handling multiple image formats and barcode types, and more. Apply for a free trial license to unlock all the advanced features.
Download Spire.Barcode for .NET today and start building your own ASP.NET barcode scanning solution.
Perform OCR on Scanned PDFs in C# for Text Extraction

Optical Character Recognition (OCR) technology has become essential for developers working with scanned documents and image-based PDFs. In this tutorial, you learn how to perform OCR on PDFs in C# to extract text from scanned documents or images within a PDF using the Spire.PDF for .NET and Spire.OCR for .NET libraries. By transferring scanned PDFs into editable and searchable formats, you can significantly improve your document management processes.
Table of Contents :
- Why OCR is Needed for Scanned PDFs?
- Setting Up: Installing Required Libraries
- Performing OCR on Scanned PDFs
- Extracting Text from Images within PDFs
- Wrapping Up
- FAQs
Why OCR is Needed for Scanned PDFs?
Scanned PDFs are essentially image files —they contain pictures of text rather than actual selectable and searchable text content. When you scan a paper document or receive an image-based PDF, the text exists only as pixels , making it impossible to edit, search, or extract. This creates significant limitations for businesses and individuals who need to work with these documents digitally.
OCR technology solves this problem by analyzing the shapes of letters and numbers in scanned images and converting them into machine-readable text. This process transforms static PDFs into usable, searchable, and editable documents—enabling text extraction, keyword searches, and seamless integration with databases and workflow automation tools.
In fields such as legal, healthcare, and education, where large volumes of scanned documents are common, OCR plays a crucial role in document digitization, making important data easily accessible and actionable.
Setting Up: Installing Required Libraries
Before we dive into the code, let's first set up our development environment with the necessary components: Spire.PDF and Spire.OCR . Spire.PDF handles PDF operations, while Spire.OCR performs the actual text recognition.
Step 1. Install Spire.PDF and Spire.OCR via NuGet
To begin, open the NuGet Package Manager in Visual Studio, and search for "Spire.PDF" and "Spire.OCR" to install them in your project. Alternatively, you can use the Package Manager Console :
Install-Package Spire.PDF
Install-Package Spire.OCR
Step 2. Download OCR Models:
Spire.OCR requires pre-trained language models for text recognition. Download the appropriate model files for your operating system (Windows, Linux, or MacOS) and extract them to a directory (e.g., D:\win-x64).
Important Note : Ensure your project targets x64 platform (Project Properties > Build > Platform target) as Spire.OCR only supports 64-bit systems.
Performing OCR on Scanned PDFs in C#
With the necessary libraries installed, we can now perform OCR on scanned PDFs. Below is a sample code snippet demonstrating this process.
using Spire.OCR;
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace OCRPDF
{
class Program
{
static void Main(string[] args)
{
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Configure the scanner
ConfigureOptions configureOptions = new ConfigureOptions
{
ModelPath = @"D:\win-x64", // Set model path
Language = "English" // Set language
};
// Apply the configuration options
scanner.ConfigureDependencies(configureOptions);
// Load a PDF document
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Input5.pdf");
// Iterate through all pages
for (int i = 0; i < doc.Pages.Count; i++)
{
// Convert page to image
Image image = doc.SaveAsImage(i, PdfImageType.Bitmap);
// Convert the image to a MemoryStream
using (MemoryStream stream = new MemoryStream())
{
image.Save(stream, System.Drawing.Imaging.ImageFormat.Png);
stream.Position = 0; // Reset the stream position
// Perform OCR on the image stream
scanner.Scan(stream, OCRImageFormat.Png);
string pageText = scanner.Text.ToString();
// Save extracted text to a separate file
string outputTxtPath = Path.Combine(@"C:\Users\Administrator\Desktop\Output", $"Page-{i + 1}.txt");
File.WriteAllText(outputTxtPath, pageText);
}
}
// Close the document
doc.Close();
}
}
}
Key Components Explained :
- OcrScanner Class : This class is crucial for performing OCR. It provides methods to configure and execute the scanning operation.
- ConfigureOptions Class : This class is used to set up the OCR scanner's configurations. The ModelPath property specifies the path to the OCR model files, and the Language property allows you to specify the language for text recognition.
- PdfDocument Class : This class represents the PDF document. The LoadFromFile method loads the PDF file that you want to process.
- Image Conversion : Each PDF page is converted to an image using the SaveAsImage method. This is essential because OCR works on image files.
- MemoryStream : The image is saved into a MemoryStream , allowing us to perform OCR without saving the image to disk.
- OCR Processing : The Scan method performs OCR on the image stream. The recognized text can be accessed using the Text property of the OcrScanner instance.
- Output : The extracted text is saved to a text file for each page.
Output :
To extract text from searchable PDFs, refer to this guide: Automate PDF Text Extraction Using C#
Extracting Text from Images within PDFs in C#
In addition to processing entire PDF pages, you can also extract text from images embedded within PDFs. Here’s how:
using Spire.OCR;
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace OCRPDF
{
class Program
{
static void Main(string[] args)
{
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Configure the scanner
ConfigureOptions configureOptions = new ConfigureOptions
{
ModelPath = @"D:\win-x64", // Set model path
Language = "English" // Set language
};
// Apply the configuration options
scanner.ConfigureDependencies(configureOptions);
// Load a PDF document
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Input5.pdf");
// Iterate through all pages
for (int i = 0; i < doc.Pages.Count; i++)
{
// Convert page to image
Image image = doc.SaveAsImage(i, PdfImageType.Bitmap);
// Convert the image to a MemoryStream
using (MemoryStream stream = new MemoryStream())
{
image.Save(stream, System.Drawing.Imaging.ImageFormat.Png);
stream.Position = 0; // Reset the stream position
// Perform OCR on the image stream
scanner.Scan(stream, OCRImageFormat.Png);
string pageText = scanner.Text.ToString();
// Save extracted text to a separate file
string outputTxtPath = Path.Combine(@"C:\Users\Administrator\Desktop\Output", $"Page-{i + 1}.txt");
File.WriteAllText(outputTxtPath, pageText);
}
}
// Close the document
doc.Close();
}
}
}
Key Components Explained :
- PdfImageHelper Class : This class is essential for extracting images from a PDF page. It provides methods to retrieve image information such as GetImagesInfo , which returns an array of PdfImageInfo objects.
- PdfImageInfo Class : Each PdfImageInfo object contains properties related to an image, including the actual Image object that can be processed further.
- Image Processing : Similar to the previous example, each image is saved to a MemoryStream for OCR processing.
- Output : The extracted text from each image is saved to a separate text file.
Output:
Wrapping Up
By combining Spire.PDF with Spire.OCR , you can seamlessly transform scanned PDFs and image-based documents into fully searchable and editable text. Whether you need to process entire pages or extract text from specific embedded images, the approach is straightforward and flexible.
This OCR integration not only streamlines document digitization but also enhances productivity by enabling search, copy, and automated data extraction. In industries where large volumes of scanned documents are the norm, implementing OCR with C# can significantly improve accessibility, compliance, and information retrieval speed.
FAQs
Q1. Can I perform OCR on non-English PDFs?
Yes, Spire.OCR supports multiple languages. You can set the Language property in ConfigureOptions to the desired language.
Q2. What should I do if the output is garbled or incorrect?
Check the quality of the input PDF images. If the images are blurry or have low contrast, OCR may struggle to recognize text accurately. Consider enhancing the image quality before processing.
Q3. Can I extract text from images embedded within a PDF?
Yes, you can. Use a helper class to extract images from each page and then apply OCR to recognize text.
Q4. Can Spire.OCR handle handwritten text in PDFs?
Spire.OCR is primarily optimized for printed text. Handwriting recognition typically has lower accuracy.
Q5. Do I need to install additional language models for OCR?
Yes, Spire.OCR requires pre-trained language model files. Download and configure the appropriate models for your target language before performing OCR.
Get a Free License
To fully experience the capabilities of Spire.PDF for .NET and Spire.OCR for .NET without any evaluation limitations, you can request a free 30-day trial license.
Convert Excel to JSON and JSON to Excel in C# .NET – Step-by-Step Guide

Converting between Excel and JSON formats is a valuable skill for developers dealing with data exchange, API integration, and modern web applications.
Excel files (.xls, .xlsx) are excellent for organizing and analyzing tabular data, while JSON (JavaScript Object Notation) is lightweight, human-readable, and ideal for transmitting data across platforms.
In this step-by-step tutorial, you’ll learn how to seamlessly convert Excel to JSON and JSON to Excel in C# using the Spire.XLS for .NET library. Whether you’re exporting Excel data for frontend apps, feeding structured datasets into APIs, or importing JSON into spreadsheets, this guide provides clear explanations, complete code samples, and tips to help you get started quickly.
What You Will Learn
- Why Convert Between Excel and JSON Formats
- Prerequisites
- Installing Required Packages
- How to Convert Excel to JSON in C# .NET (Step-by-Step)
- How to Convert JSON to Excel in C# .NET (Step-by-Step)
- Tips and Best Practices
- Conclusion
- Further Reading
- FAQs
Why Convert Between Excel and JSON Formats?
Converting between Excel and JSON can be beneficial for several reasons:
- Data Exchange: JSON is a standard format for data interchange in web applications, making it easier to share data across platforms.
- Integration with APIs: Many web APIs require data in JSON format, necessitating conversion from Excel for seamless integration.
- Lightweight and Compact: JSON files are generally smaller in size compared to Excel files, leading to faster data transfer and reduced storage needs.
- Readability: JSON is human-readable and easier to understand, which can simplify data analysis and troubleshooting.
- Compatibility with NoSQL Databases: JSON format is commonly used in NoSQL databases, facilitating easy data migration and storage.
Prerequisites
Before we start, ensure you have the following:
- Visual Studio or any C# development IDE installed.
- .NET Framework or .NET Core installed.
- Spire.XLS package installed for handling Excel files.
- Newtonsoft.Json package installed for handling JSON serialization and deserialization.
Installing Required Packages
You can install the required packages using NuGet Package Manager in Visual Studio:
Install-Package Spire.XLS
Install-Package Newtonsoft.Json
How to Convert Excel to JSON in C# .NET (Step-by-Step)
Exporting Excel files to JSON format in C# involves extracting data from Excel spreadsheets and transforming it into a structured JSON string. This process is particularly useful for applications that require data interchange between web services or databases. Below are detailed steps to guide you through the conversion process.
Steps to Export Excel to JSON
- Load the Excel File:
- Begin by creating a Workbook object that will hold the Excel file's content using the Spire.XLS library. Load the Excel file into this object.
- Access the Desired Worksheet:
- Identify and access the specific worksheet from which you want to extract data. This is done by referencing the appropriate index of the Worksheets collection.
- Export to DataTable:
- Utilize the ExportDataTable() method to convert the worksheet's content into a DataTable. This provides a structured representation of the data, making it easier to manipulate.
- Serialize to JSON:
- Use the Newtonsoft.Json library to serialize the DataTable into a JSON string. This step involves converting the structured data into a JSON format, which is human-readable and suitable for web applications.
- Save the JSON to a File:
- Finally, write the generated JSON string to a file. This allows for easy access and reuse of the data in future applications or processes.
Complete Code Example: Excel to JSON
Here’s a complete code example demonstrating the process:
using Newtonsoft.Json;
using Spire.Xls;
using System.Data;
using System.IO;
namespace ConvertExcelToJSON
{
class Program
{
static void Main(string[] args)
{
// Path to the Excel file
string excelFilePath = @"Sample.xlsx";
// Create a new Workbook instance
Workbook workbook = new Workbook();
// Load the Excel file
workbook.LoadFromFile(excelFilePath);
// Get the first worksheet
Worksheet worksheet = workbook.Worksheets[0];
// Export the worksheet content to a DataTable
DataTable dataTable = worksheet.ExportDataTable();
// Convert the DataTable to a JSON string
string jsonResult = JsonConvert.SerializeObject(dataTable, Formatting.Indented);
// Save JSON string to a text file
File.WriteAllText("output.txt", jsonResult);
}
}
}
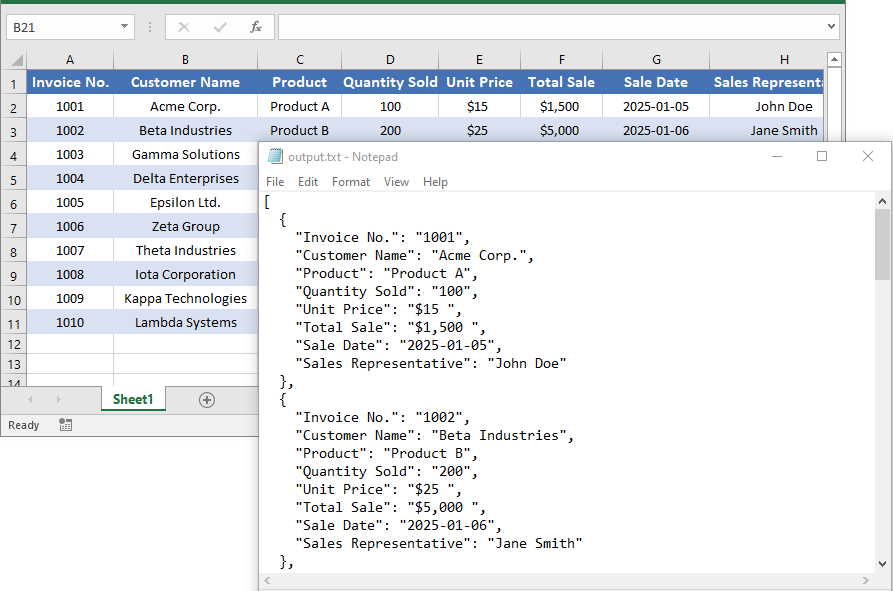
How to Convert JSON to Excel in C# .NET (Step-by-Step)
Importing JSON data into an Excel file is a valuable process, especially when you need to analyze or present data in a more user-friendly format. JSON is easy for humans to read and write, and easy for machines to parse and generate. However, for many users, Excel remains the preferred tool for data analysis, reporting, and visualization.
In the following steps, we will outline the process of importing JSON into Excel, enabling you to effectively utilize your JSON data within Excel for further analysis and reporting.
Steps to Import JSON into Excel
- Read the JSON String:
- Start by reading the JSON data from a file or other sources. This could include API responses, local files, or even hardcoded strings for testing purposes.
- Deserialize to DataTable:
- Use the Newtonsoft.Json library to deserialize the JSON string into a DataTable. This structured format makes it easy to manipulate data before inserting it into Excel.
- Create a New Excel Workbook:
- Initialize a new Workbook instance using the Spire.XLS library. This workbook will serve as the container for your Excel data.
- Insert the DataTable into the Worksheet:
- Use the InsertDataTable() method to transfer the contents of the DataTable into the first worksheet of the workbook. This method allows you to include column headers and organize the data neatly.
- Apply Optional Formatting:
- Enhance the visual appeal of your Excel file by applying formatting to headers and data cells. This step involves defining styles for fonts, background colors, and borders, making the data easier to read.
- Save the Workbook:
- Finally, save the populated workbook as an Excel file. Choose an appropriate file format (e.g., .xlsx) to ensure compatibility with modern Excel versions.
Complete Code Example: JSON to Excel
Here’s a complete code snippet demonstrating the conversion process:
using Newtonsoft.Json;
using Spire.Xls;
using System.Data;
using System.Drawing;
namespace ConvertJSONToExcel
{
class Program
{
static void Main(string[] args)
{
// Sample JSON data
string json = @"
[
{""Name"":""John Smith"",""Age"":30,""Department"":""Sales"",""StartDate"":""2020-05-12"",""FullTime"":true},
{""Name"":""Jane Doe"",""Age"":25,""Department"":""Marketing"",""StartDate"":""2021-09-01"",""FullTime"":false},
{""Name"":""Michael Lee"",""Age"":40,""Department"":""IT"",""StartDate"":""2018-03-15"",""FullTime"":true},
{""Name"":""Emily Davis"",""Age"":35,""Department"":""Finance"",""StartDate"":""2019-07-20"",""FullTime"":true}
]";
// Deserialize JSON into DataTable
DataTable dataTable = JsonConvert.DeserializeObject<DataTable>(json);
// Create a new Excel workbook
Workbook workbook = new Workbook();
// Get the first worksheet
Worksheet worksheet = workbook.Worksheets[0];
// Insert DataTable into worksheet with column headers
worksheet.InsertDataTable(dataTable, true, 1, 1);
// (Optional) Applying formatting to Excel data
// Set style for heading row
CellStyle headerStyle = workbook.Styles.Add("HeaderStyle");
headerStyle.Font.IsBold = true;
headerStyle.Font.Size = 12;
headerStyle.Font.Color = Color.White;
headerStyle.HorizontalAlignment = HorizontalAlignType.Center;
headerStyle.VerticalAlignment = VerticalAlignType.Center;
headerStyle.Color = Color.DarkBlue;
int colCount = dataTable.Columns.Count;
for (int c = 1; c <= colCount; c++)
{
worksheet.Range[1, c].CellStyleName = "HeaderStyle";
}
// Set style for data cells
CellStyle dataStyle = workbook.Styles.Add("DataStyle");
dataStyle.HorizontalAlignment = HorizontalAlignType.Center;
dataStyle.VerticalAlignment = VerticalAlignType.Center;
dataStyle.Borders[BordersLineType.EdgeLeft].LineStyle = LineStyleType.Thin;
dataStyle.Borders[BordersLineType.EdgeRight].LineStyle = LineStyleType.Thin;
dataStyle.Borders[BordersLineType.EdgeTop].LineStyle = LineStyleType.Thin;
dataStyle.Borders[BordersLineType.EdgeBottom].LineStyle = LineStyleType.Thin;
int rowCount = dataTable.Rows.Count;
worksheet.Range[2, 1, rowCount + 1, colCount].CellStyleName = "DataStyle";
// Auto-fit column widths
worksheet.AllocatedRange.AutoFitColumns();
// Save Excel file
workbook.SaveToFile("output.xlsx", ExcelVersion.Version2013);
// Release resources
workbook.Dispose();
}
}
}
Tips and Best Practices
When converting between Excel and JSON, following best practices can help ensure data integrity and usability. Here are some key tips to keep in mind:
- Validate Data Types: Ensure that data types (e.g., dates, numbers) are correctly formatted to avoid issues during conversion.
- Handle Empty Cells: Decide how to treat empty cells (e.g., convert to null or omit) to maintain data integrity.
- Use Consistent Naming Conventions: Standardize column names in Excel for clear and consistent JSON keys.
- Test Thoroughly: Always test the conversion processes to ensure valid JSON output and accurate Excel representation.
- Include Headers: When converting JSON to Excel, always insert headers for improved readability and usability.
Conclusion
Converting Excel to JSON and JSON to Excel is a common but critical operation in modern C# development, especially for applications involving data exchange and API integration. Using Spire.XLS together with Newtonsoft.Json simplifies this process with intuitive APIs and robust functionality.
This guide has walked you through every step—from installing necessary packages to implementing complete converters—with clear explanations and sample code. With these tools and knowledge, you can confidently integrate Excel-JSON conversion into your applications, improving flexibility and interoperability.
Further Reading
FAQs
Q1: How to convert multiple worksheets to JSON at once?
You can iterate through the Workbook.Worksheets collection and export each worksheet’s data individually, supporting batch Excel to JSON conversion.
Q2: How to customize JSON output formatting?
JsonConvert.SerializeObject allows you to set indentation, camelCase naming, or ignore null values. You can also use custom converters for more control.
Q3: How to improve readability when converting JSON to Excel?
Keep column headers, set alignment, apply borders and styles to generate a clear and easy-to-read Excel report.
Q4: Is this method compatible with .NET Core?
Yes, it is fully compatible. Both Spire.XLS and Newtonsoft.Json support .NET Core and .NET Framework, making it usable in various C# projects.
How to Generate & Create QR Code in ASP.NET C# (Full Example)

QR codes have become a standard feature in modern web applications, widely used for user authentication, contactless transactions, and sharing data like URLs or contact information. For developers working with ASP.NET, implementing QR code generation using C# is a practical requirement in many real-world scenarios.
In this article, you’ll learn how to generate QR codes in ASP.NET using Spire.Barcode for .NET. We’ll walk through a complete example based on an ASP.NET Core Web App (Razor Pages) project, including backend logic and a simple UI to display the generated code. The same approach can be easily adapted to MVC, Web API, and Web Forms applications.
Article Overview
- 1. Project Setup and Dependencies
- 2. Generate QR Code in ASP.NET Using C#
- 3. Customize QR Code Output
- 4. Apply Logic in MVC, Web API, and Web Forms
- 5. Conclusion
- FAQs
1. Project Setup and Dependencies
Prerequisites
To follow along, make sure you have:
- Visual Studio 2019 or newer
- .NET 6 or later
- ASP.NET Core Web App (Razor Pages Template)
- NuGet package: Spire.Barcode for .NET
Install Spire.Barcode for .NET
Install the required library using NuGet Package Manager Console:
Install-Package Spire.Barcode
Spire.Barcode is a fully self-contained .NET barcode library that supports in-memory generation of QR codes without external APIs. You can also use Free Spire.Barcode for .NET for smaller projects.
2. Generate QR Code in ASP.NET Using C#
This section describes how to implement QR code generation in an ASP.NET Core Web App (Razor Pages) project. The example includes a backend C# handler that generates the QR code using Spire.Barcode for .NET, and a simple Razor Page frontend for user input and real-time display.
Step 1: Add QR Code Generation Logic in PageModel
The backend logic resides in the Index.cshtml.cs file. It processes the form input, generates a QR code using Spire.Barcode, and returns the result as a Base64-encoded image string that can be directly embedded in HTML.
using Microsoft.AspNetCore.Mvc;
using Microsoft.AspNetCore.Mvc.RazorPages;
using Spire.Barcode;
public class IndexModel : PageModel
{
[BindProperty]
public string InputData { get; set; }
public string QrCodeBase64 { get; set; }
public void OnPost()
{
if (!string.IsNullOrWhiteSpace(InputData))
{
QrCodeBase64 = GenerateQrCodeBase64(InputData);
}
}
private string GenerateQrCodeBase64(string input)
{
var settings = new BarcodeSettings
{
Type = BarCodeType.QRCode, // QR code type
Data = input, // Main encoded data
Data2D = input, // Required for 2D barcode, usually same as Data
QRCodeDataMode = QRCodeDataMode.Byte, // Byte mode (supports multilingual content)
QRCodeECL = QRCodeECL.M, // Medium error correction (15%)
X = 3, // Module size (affects image dimensions)
ShowText = false, // Hide default barcode text
ShowBottomText = true, // Show custom bottom text
BottomText = input // Bottom text to display under the QR code
};
var generator = new BarCodeGenerator(settings);
using var ms = new MemoryStream();
var qrImage = generator.GenerateImage();
qrImage.Save(ms, System.Drawing.Imaging.ImageFormat.Png);
return Convert.ToBase64String(ms.ToArray());
}
}
Key Components:
-
BarcodeSettings: Specifies the QR code's core configuration, such as type (QRCode), data content, encoding mode, and error correction level.
-
BarCodeGenerator: Takes the settings and generates the QR code image as a System.Drawing.Image object using the GenerateImage() method.
-
Base64 Conversion: Converts the image to a Base64 string so it can be directly embedded into the HTML page without saving to disk.
This approach keeps the entire process in memory, making it fast, portable, and suitable for serverless or cloud-hosted applications.
Step 2: Create the Razor Page for User Input and QR Code Display and Download
The following Razor markup in the Index.cshtml file defines a form for entering text or URLs, displays the generated QR code upon submission, and provides a button to download the QR code image.
@page
@model IndexModel
@{
ViewData["Title"] = "QR Code Generator";
}
<h2>QR Code Generator</h2>
<form method="post">
<label for="InputData">Enter text or URL:</label>
<input type="text" id="InputData" name="InputData" style="width:300px;" required />
<button type="submit">Generate QR Code</button>
</form>
@if (!string.IsNullOrEmpty(Model.QrCodeBase64))
{
<div style="margin-top:20px">
<img src="data:image/png;base64,@Model.QrCodeBase64" alt="QR Code" />
<br />
<a href="data:image/png;base64,@Model.QrCodeBase64" download="qrcode.png">Download QR Code</a>
</div>
}
The Base64-encoded image is displayed directly in the browser using a data: URI. This eliminates the need for file storage and allows for immediate rendering and download.
The following screenshot shows the result after submitting text input.
If you need to scan QR codes instead, please refer to How to Scan QR Codes in C#.
3. Customize QR Code Output
Spire.Barcode provides several customization options through the BarcodeSettings class to control the appearance and behavior of the generated QR code:
| Property | Function | Example |
|---|---|---|
| QRCodeDataMode | Text encoding mode | QRCodeDataMode.Byte |
| QRCodeECL | Error correction level | QRCodeECL.H (high redundancy) |
| X | Module size (resolution) | settings.X = 6 |
| ImageWidth/Height | Control dimensions of QR image | settings.ImageWidth = 300 |
| ForeColor | Set QR code color | settings.ForeColor = Color.Blue |
| ShowText | Show or hide text below barcode | settings.ShowText = false |
| BottomText | Custom text to display below barcode | settings.BottomText = "Scan Me" |
| ShowBottomText | Show or hide the custom bottom text | settings.ShowBottomText = true |
| QRCodeLogoImage | Add a logo image to overlay at QR code center | settings.QRCodeLogoImage = System.Drawing.Image.FromFile("logo.png"); |
These properties help you tailor the appearance of your QR code for branding, readability, or user interaction purposes.
To explore more QR code settings, refer to the BarcodeSettings API reference.
4. Apply Logic in MVC, Web API, and Web Forms
The same QR code generation logic used in Razor Pages can also be reused in other ASP.NET frameworks such as MVC, Web API, and Web Forms.
MVC Controller Action
In an MVC project, you can add a Generate action in a controller (e.g., QrController.cs) to generate and return the QR code image directly:
public class QrController : Controller
{
public ActionResult Generate(string data)
{
var settings = new BarcodeSettings
{
Type = BarCodeType.QRCode,
Data = data,
QRCodeDataMode = QRCodeDataMode.Byte,
QRCodeECL = QRCodeECL.M,
X = 5
};
var generator = new BarCodeGenerator(settings);
using var ms = new MemoryStream();
generator.GenerateImage().Save(ms, System.Drawing.Imaging.ImageFormat.Png);
return File(ms.ToArray(), "image/png");
}
}
This method returns the QR code as a downloadable PNG file, ideal for server-side rendering.
Web API Endpoint
For Web API, you can define a GET endpoint in a controller such as QrApiController.cs that responds with the generated image stream:
[ApiController]
[Route("api/[controller]")]
public class QrApiController : ControllerBase
{
[HttpGet("generate")]
public IActionResult GetQr(string data)
{
var settings = new BarcodeSettings
{
Type = BarCodeType.QRCode,
Data = data
};
var generator = new BarCodeGenerator(settings);
using var ms = new MemoryStream();
generator.GenerateImage().Save(ms, System.Drawing.Imaging.ImageFormat.Png);
return File(ms.ToArray(), "image/png");
}
}
This approach is suitable for frontends built with React, Vue, Angular, or any JavaScript framework.
Web Forms Code-Behind
In ASP.NET Web Forms, you can handle QR code generation in the code-behind of a page like Default.aspx.cs:
protected void btnGenerate_Click(object sender, EventArgs e)
{
var settings = new BarcodeSettings
{
Type = BarCodeType.QRCode,
Data = txtInput.Text
};
var generator = new BarCodeGenerator(settings);
using var ms = new MemoryStream();
generator.GenerateImage().Save(ms, System.Drawing.Imaging.ImageFormat.Png);
imgQR.ImageUrl = "data:image/png;base64," + Convert.ToBase64String(ms.ToArray());
}
The generated image is embedded directly into an asp:Image control using a Base64 data URI.
5. Conclusion
With Spire.Barcode for .NET, you can seamlessly generate and customize QR codes across all ASP.NET project types — Razor Pages, MVC, Web API, or Web Forms. The solution is fully offline, fast, and requires no third-party API.
Returning images as Base64 strings simplifies deployment and avoids file management. Whether you're building authentication tools, ticketing systems, or contact sharing, this approach is reliable and production-ready.
FAQs
Q: Does Spire.Barcode support Unicode characters like Chinese or Arabic?
A: Yes. Use QRCodeDataMode.Byte for full Unicode support.
Q: Can I adjust QR code size and color?
A: Absolutely. Use properties like X, ForeColor, and ImageWidth.
Q: Is this solution fully offline?
A: Yes. It works without any external API calls or services.
Q: Can I expose this QR logic via API?
A: Yes. Use ASP.NET Web API to serve generated images to client apps.