Como inserir quebras de página no Excel: 3 formas práticas
Sumário
- O que são quebras de página no Excel
- Abra a Visualização da Quebra de Página antes de começar
- Adicionar ou mover uma quebra de página no Excel manualmente
- Inserir quebras de página a cada N linhas automaticamente com VBA
- Adicionar quebras de página a vários arquivos Excel com C#
- Comparação rápida de todos os métodos de inserção de quebra de página
- Por que as quebras de página não estão funcionando no Excel
- Perguntas Frequentes
- Resumo

Quando uma planilha do Excel contém várias seções, tabelas longas ou muitas linhas de dados, o Excel pode dividir automaticamente o conteúdo entre as páginas em locais inconvenientes. Um cabeçalho pode aparecer na parte inferior de uma página, uma tabela pode ser dividida ao meio ou colunas relacionadas podem ser separadas em páginas diferentes. Adicionar quebras de página permite que você controle onde uma nova página impressa começa e torna os relatórios mais fáceis de ler.
Neste artigo, abordaremos 3 maneiras práticas de inserir quebras de página no Excel:
- Adicionar ou mover uma quebra de página no Excel manualmente
- Inserir quebras de página a cada N linhas usando VBA
- Adicionar quebras de página a vários arquivos Excel com C#
O que são quebras de página no Excel?
Uma quebra de página marca o ponto onde uma página impressa termina e a próxima começa.
As quebras de página afetam apenas o layout de impressão. Elas não movem células, alteram fórmulas, dividem uma planilha em folhas separadas nem modificam os dados subjacentes.
O Excel usa dois tipos de quebras de página:
- Quebras de página automáticas são criadas pelo Excel com base no tamanho do papel, margens, escala, alturas de linha e larguras de coluna.
- Quebras de página manuais são inseridas pelo usuário para controlar onde uma nova página impressa começa.
Você pode inserir dois tipos de quebras de página manuais:
- Quebra de página horizontal: Inicia uma nova página impressa em uma linha específica.
- Quebra de página vertical: Inicia uma nova página impressa em uma coluna específica.
Abra a Visualização da Quebra de Página antes de começar
A Visualização da Quebra de Página mostra como o Excel divide atualmente a planilha em páginas impressas. Embora você não precise abrir esta visualização antes de inserir uma quebra de página, ela torna os limites da página mais fáceis de ver e ajuda a verificar o resultado.
Para abrir a Visualização da Quebra de Página:
-
Vá para a guia Exibir na faixa de opções do Excel.
-
Selecione Visualização da Quebra de Página.
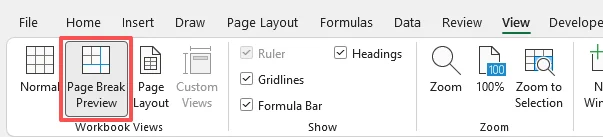
O Excel exibirá os limites da página diretamente na planilha.
Dica: Linhas tracejadas indicam quebras de página automáticas criadas pelo Excel. Linhas sólidas indicam quebras de página manuais, incluindo quebras de página automáticas que você moveu manualmente.
Adicionar ou mover uma quebra de página no Excel manualmente
Ideal para: Usuários que precisam ajustar o layout de impressão de uma única planilha ou inserir apenas algumas quebras de página manualmente.
Inserir uma quebra de página horizontal
- Selecione a linha diretamente abaixo de onde você deseja que a página seja dividida (por exemplo, clique no número da linha 10 para inserir uma quebra entre as linhas 9 e 10).
- Vá para a guia Layout da Página.
- Clique em Quebras.
- Selecione Inserir Quebra de Página.
Resultado: O Excel insere uma quebra de página horizontal acima da linha selecionada.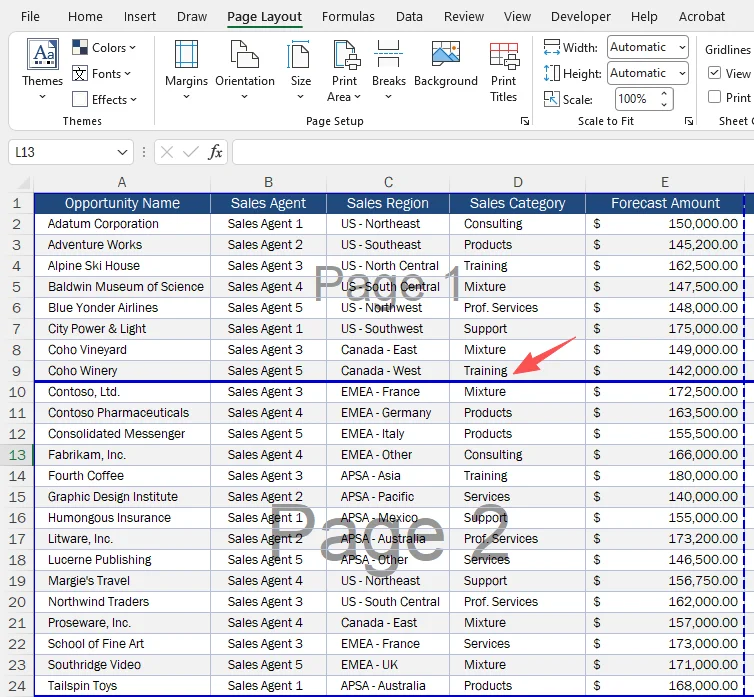
Inserir uma quebra de página vertical
- Selecione a coluna diretamente à direita de onde você deseja a divisão (por exemplo, clique na coluna D para inserir uma quebra entre as colunas C e D).
- Vá para a guia Layout da Página.
- Clique em Quebras.
- Escolha Inserir Quebra de Página.
Resultado: O Excel insere a quebra de página à esquerda da coluna selecionada.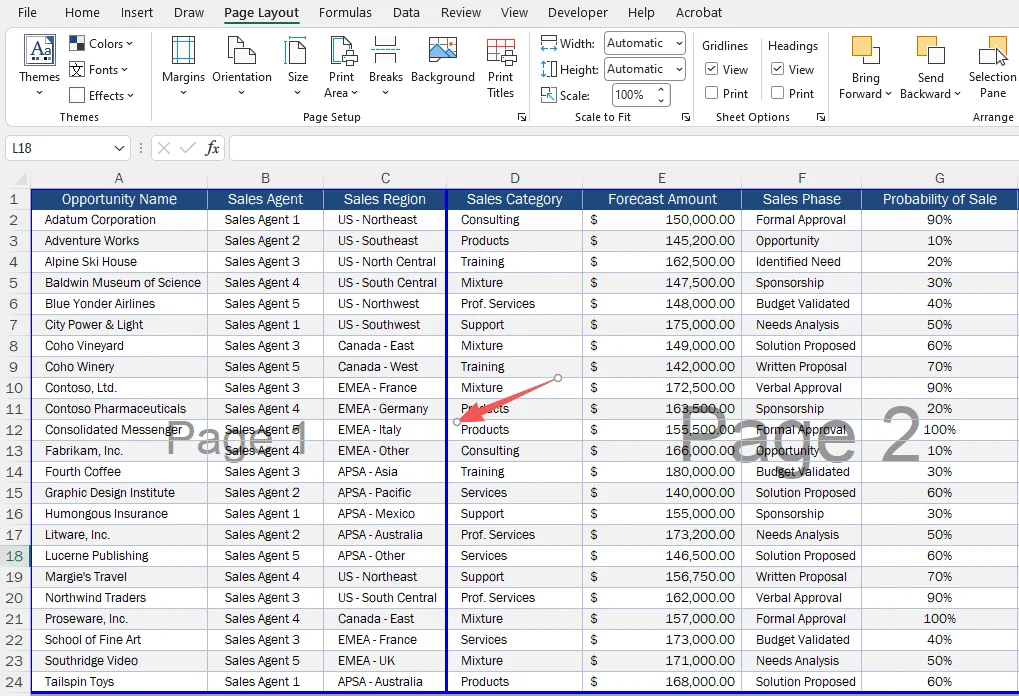
Mover uma quebra de página existente
Você pode mover uma quebra de página sem excluí-la e recriá-la:
- Certifique-se de estar na Visualização da Quebra de Página.
- Arraste a linha da quebra de página para a posição desejada. Se a linha não puder ser arrastada, verifique se o recurso de arrastar e soltar células está ativado nas Opções do Excel. Mover uma quebra de página automática a transforma em uma quebra de página manual.
Nota: Para planilhas largas, as configurações de orientação da página, margens e escala podem afetar o layout impresso final. Revise a Visualização de Impressão se as colunas não aparecerem como esperado.
Vantagens e Limitações
| Vantagens | Limitações |
|---|---|
| Rápido e fácil para pequenos ajustes | Requer repetição manual para cada quebra |
Inserir quebras de página a cada N linhas automaticamente com VBA
Ideal para: Usuários do aplicativo de desktop do Excel que precisam inserir quebras de página em intervalos de linha regulares, como a cada 10 linhas.
O Excel não fornece um botão simples integrado para inserir quebras de página a cada N linhas. Se você precisar apenas de algumas quebras de página, a inserção manual geralmente é suficiente.
No entanto, quando uma planilha contém centenas ou milhares de linhas, adicionar quebras de página uma a uma torna-se demorado e sujeito a erros. Uma pequena macro VBA pode automatizar esse processo e aplicar a mesma regra de quebra de página de forma consistente.
⚠️ Aviso: As alterações feitas por uma macro VBA geralmente não podem ser desfeitas com Ctrl + Z. Salve uma cópia de backup da pasta de trabalho antes de executar o código e execute macros apenas de fontes em que você confia!
Guia passo a passo
-
Pressione Alt + F11 para abrir o editor VBA.
-
Clique em Inserir > Módulo para criar um novo módulo.
-
Cole o seguinte código VBA no módulo:
Sub InsertPageBreaksEveryNRows() Dim ws As Worksheet Dim intervalRows As Long Dim lastRow As Long Dim rowIndex As Long Set ws = ActiveSheet intervalRows = 10 ' Altere este valor para o intervalo desejado lastRow = ws.Cells(ws.Rows.Count, "A").End(xlUp).Row For rowIndex = intervalRows + 1 To lastRow Step intervalRows If Not HasHorizontalPageBreak(ws, rowIndex) Then ws.HPageBreaks.Add Before:=ws.Rows(rowIndex) End If Next rowIndex End Sub Private Function HasHorizontalPageBreak(ws As Worksheet, breakRow As Long) As Boolean Dim pb As HPageBreak HasHorizontalPageBreak = False For Each pb In ws.HPageBreaks If pb.Location.Row = breakRow Then HasHorizontalPageBreak = True Exit Function End If Next pb End Function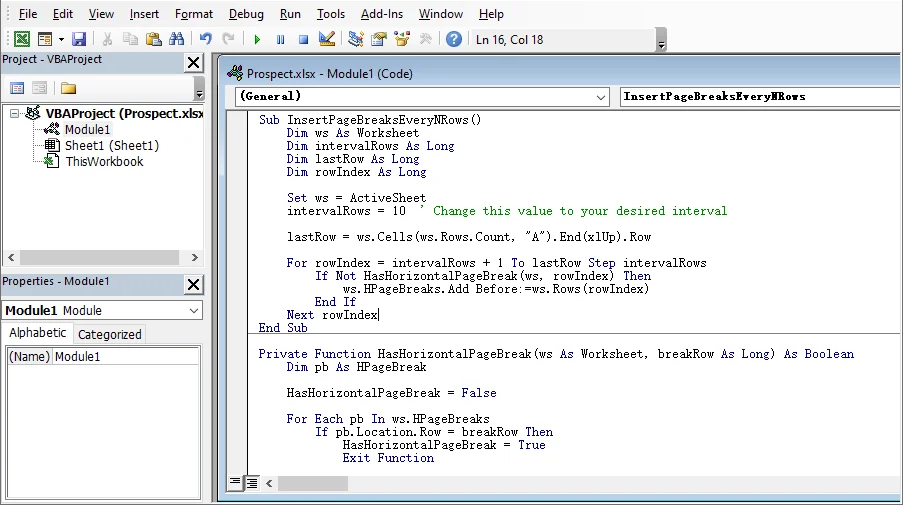
-
Altere
intervalRows = 10para o número de linhas da planilha que você deseja entre as quebras de página. -
Pressione F5 para executar a macro.
Dicas importantes:
- A macro assume que a coluna A contém dados para determinar a última linha. Se seus dados começarem em uma coluna diferente, altere "A" para a letra da coluna apropriada.
- A macro não remove nenhuma quebra de página existente. Se você quiser redefinir todas as quebras antes de inserir novas, adicione
ActiveSheet.ResetAllPageBreaksno início da macro. - O Excel permite até 1.026 quebras de página horizontais e verticais em uma planilha. Intervalos muito pequenos em planilhas extremamente grandes podem exceder esse limite.
- Para manter a macro na pasta de trabalho, salve o arquivo como Pasta de Trabalho Habilitada para Macro do Excel (.xlsm).
Vantagens e Limitações
| Vantagens | Limitações |
|---|---|
| Automatiza a inserção repetida de quebras de página | Requer conhecimento de VBA |
| Suporta intervalos de linha personalizados | Funciona apenas no aplicativo de desktop do Excel |
Precisa remover quebras de página existentes? Veja Como remover quebras de página no Excel.
Adicionar quebras de página a vários arquivos Excel com C#
Ideal para: Desenvolvedores ou usuários avançados que precisam inserir quebras de página em lote em vários arquivos Excel ou automatizar a geração de relatórios Excel dentro de software corporativo sem interagir com a interface gráfica do Microsoft Excel.
Embora o VBA seja excelente para automação de desktop, os fluxos de trabalho de automação corporativa geralmente exigem o processamento de documentos Excel no lado do servidor. No ecossistema .NET, os desenvolvedores podem utilizar bibliotecas como o Free Spire.XLS for .NET para inserir quebras de página horizontais ou verticais em C# sem abrir o Excel.
Siga as etapas abaixo para adicionar quebras de página a várias pastas de trabalho do Excel com C# e Free Spire.XLS for .NET.
Etapas
-
Instale a biblioteca necessária.
Instale a biblioteca através do Gerenciador de Pacotes NuGet:
Install-Package FreeSpire.XLS -
Adicione o código C# para inserir quebras de página em lote.
O exemplo a seguir percorre vários arquivos Excel, insere quebras de página horizontais e verticais e salva as pastas de trabalho processadas.
using System; using System.IO; using Spire.Xls; namespace ExcelPageBreak { internal class Program { private static void Main() { // Pasta contendo os arquivos Excel a serem processados string inputFolder = @"C:\ExcelFiles"; // Salvar arquivos processados em uma subpasta separada string outputFolder = Path.Combine(inputFolder, "Processed"); Directory.CreateDirectory(outputFolder); // Encontrar todos os arquivos .xlsx na pasta de entrada string[] files = Directory.GetFiles( inputFolder, "*.xlsx", SearchOption.TopDirectoryOnly ); foreach (string filePath in files) { using (Workbook workbook = new Workbook()) { // Carregar o arquivo Excel workbook.LoadFromFile(filePath); // Obter a primeira planilha Worksheet sheet = workbook.Worksheets[0]; // Inserir uma quebra de página horizontal acima da linha 10 sheet.HPageBreaks.Add(sheet.Range["A10"]); // Inserir uma quebra de página vertical antes da coluna D sheet.VPageBreaks.Add(sheet.Range["D1"]); // Construir o caminho do arquivo de saída string outputPath = Path.Combine( outputFolder, Path.GetFileName(filePath) ); // Salvar a pasta de trabalho processada workbook.SaveToFile( outputPath, FileFormat.Version2016 ); } } Console.WriteLine( $"{files.Length} pasta(s) de trabalho processada(s). " + $"Os arquivos foram salvos em: {outputFolder}" ); } } }
Como o código funciona:
O código usa Directory.GetFiles() para encontrar todos os arquivos .xlsx na pasta de entrada especificada. Para cada pasta de trabalho, ele:
- Abre o arquivo e seleciona a primeira planilha.
- Adiciona uma quebra de página horizontal acima da linha 10.
- Adiciona uma quebra de página vertical antes da coluna D.
- Salva a pasta de trabalho atualizada em uma pasta
Processedseparada.
Altere C:\ExcelFiles para a pasta que contém suas pastas de trabalho. Você também pode substituir A10 e D1 pela linha e coluna onde deseja que cada nova página impressa comece.
Notas:
- O exemplo processa arquivos apenas na pasta selecionada. Para incluir arquivos em suas subpastas, altere
SearchOption.TopDirectoryOnlyparaSearchOption.AllDirectories. - O Free Spire.XLS limita arquivos .xls a 5 planilhas por pasta de trabalho e 200 linhas por planilha. Esses limites não se aplicam a arquivos .xlsx, portanto, o exemplo acima processa apenas arquivos .xlsx. Para pastas de trabalho .xls maiores, converta-as para .xlsx antes de processar.
Vantagens e Limitações
| Vantagens | Limitações |
|---|---|
| Automatiza a inserção de quebras de página para vários arquivos Excel | Requer conhecimento de programação .NET |
| Não requer instalação do Microsoft Excel | Não é adequado para ajustes manuais simples |
Comparação rápida de todos os métodos de inserção de quebra de página
| Método | Melhor caso de uso | Suporte multiplataforma? | Processamento em lote? |
|---|---|---|---|
| Inserção Manual | Conjuntos de dados pequenos e únicos | Limitado (apenas desktop) | Não |
| Macro VBA | Regras repetidas ou baseadas em intervalos | Limitado (apenas desktop) | Limitado |
| C# + Free Spire.XLS | Processamento em lote e fluxos de trabalho automatizados | Sim (.NET multiplataforma) | Sim |
Por que as quebras de página não estão funcionando no Excel?
Se uma quebra de página não aparecer onde esperado, verifique as seguintes configurações:
-
A linha ou coluna errada está selecionada.
O Excel insere uma quebra de página horizontal acima da linha selecionada e uma quebra de página vertical à esquerda da coluna selecionada. Selecione a linha ou coluna onde a próxima página impressa deve começar. -
A quebra de página não está visível na visualização atual.
Abra Exibir > Visualização da Quebra de Página para exibir quebras de página automáticas e manuais diretamente na planilha. -
A escala "Ajustar para" está substituindo as quebras de página manuais.
Quando a planilha usa a opção de escala Ajustar para, o Excel pode ignorar quebras de página manuais. Abra a caixa de diálogo Configurar Página e selecione Ajustar para em vez disso. -
A área de impressão não inclui o conteúdo esperado.
Verifique Layout da Página > Área de Impressão e confirme se o intervalo correto está incluído. Você também pode limpar a área de impressão existente e defini-la novamente. -
A planilha está protegida.
Uma planilha protegida pode impedir alterações nas configurações de layout da página. Desproteja a planilha, insira ou mova a quebra de página e, em seguida, proteja-a novamente, se necessário.
Após fazer as alterações, abra Arquivo > Imprimir para verificar o layout final da página antes de imprimir ou exportar a planilha.
Perguntas Frequentes
P1: Existe um atalho para inserir uma quebra de página no Excel?
R1: O Excel não possui um atalho universal para inserir quebras de página. Em versões do Windows, você pode usar Alt → P → B → I para acessar o comando Inserir Quebra de Página. A sequência de teclas pode variar de acordo com a versão do Excel e o idioma de exibição.
P2: Posso inserir quebras de página a cada N linhas?
R2: Sim. O Excel não fornece uma opção integrada para inserir quebras de página em intervalos de linha fixos. Você pode adicioná-las manualmente uma a uma ou usar VBA para automatizar o processo.
P3: Como faço para remover uma quebra de página no Excel?
R3: Selecione a linha abaixo de uma quebra horizontal ou a coluna à direita de uma quebra vertical, depois vá para Layout da Página > Quebras > Remover Quebra de Página. Para remover todas as quebras de página manuais, selecione Redefinir Todas as Quebras de Página. As quebras de página automáticas não podem ser removidas diretamente.
P4: As quebras de página afetam os dados da minha planilha?
R4: Não. As quebras de página controlam apenas como uma planilha é dividida quando impressa ou exportada para PDF. Elas não alteram valores de células, fórmulas, formatação ou estrutura da planilha.
Resumo
Neste artigo, discutimos três maneiras práticas de inserir quebras de página no Excel, juntamente com dicas úteis para evitar problemas comuns de layout de impressão. Escolha o método que melhor se adapta à sua tarefa e revise o resultado final na Visualização de Impressão antes de imprimir ou exportar a planilha para PDF.
Excel에서 페이지 나누기를 삽입하는 방법: 3가지 실용적인 방법
Excel 워크시트에 여러 섹션, 긴 표 또는 많은 행의 데이터가 포함되어 있으면, Excel이 의도치 않은 위치에서 자동으로 콘텐츠를 페이지별로 나눌 수 있습니다. 제목이 페이지 하단에 나타나거나, 표가 중간에 잘리거나, 관련 열이 서로 다른 페이지로 분리될 수 있습니다. 페이지 나누기를 추가하면 인쇄된 페이지가 시작되는 위치를 제어하여 보고서를 더 읽기 쉽게 만들 수 있습니다.
이 문서에서는 Excel에서 페이지 나누기를 삽입하는 3가지 실용적인 방법을 다룹니다.
- Excel에서 수동으로 페이지 나누기 추가 또는 이동
- VBA를 사용하여 N행마다 페이지 나누기 삽입
- C#으로 여러 Excel 파일에 페이지 나누기 추가
Excel의 페이지 나누기란 무엇인가?
페이지 나누기는 인쇄된 한 페이지가 끝나고 다음 페이지가 시작되는 지점을 표시합니다.
페이지 나누기는 인쇄 레이아웃에만 영향을 미칩니다. 셀을 이동하거나, 수식을 변경하거나, 워크시트를 별도의 시트로 분할하거나, 기본 데이터를 수정하지 않습니다.
Excel은 두 가지 종류의 페이지 나누기를 사용합니다.
- 자동 페이지 나누기: 용지 크기, 여백, 배율, 행 높이 및 열 너비를 기준으로 Excel이 생성합니다.
- 수동 페이지 나누기: 사용자가 인쇄된 페이지가 시작되는 위치를 제어하기 위해 삽입합니다.
사용자는 두 가지 유형의 수동 페이지 나누기를 삽입할 수 있습니다.
- 가로 페이지 나누기: 특정 행에서 새로운 인쇄 페이지를 시작합니다.
- 세로 페이지 나누기: 특정 열에서 새로운 인쇄 페이지를 시작합니다.
시작하기 전에 페이지 나누기 미리 보기 열기
페이지 나누기 미리 보기는 현재 Excel이 워크시트를 인쇄된 페이지로 어떻게 나누고 있는지 보여줍니다. 페이지 나누기를 삽입하기 전에 이 보기를 열 필요는 없지만, 페이지 경계를 더 쉽게 확인하고 결과를 검토하는 데 도움이 됩니다.
페이지 나누기 미리 보기를 여는 방법:
-
Excel 리본 메뉴에서 보기 탭으로 이동합니다.
-
페이지 나누기 미리 보기를 선택합니다.
Excel이 워크시트에 페이지 경계를 직접 표시합니다.
팁: 점선은 Excel에서 생성한 자동 페이지 나누기를 나타냅니다. 실선은 수동 페이지 나누기를 나타내며, 사용자가 수동으로 이동한 자동 페이지 나누기도 포함됩니다.
Excel에서 수동으로 페이지 나누기 추가 또는 이동하기
대상: 단일 워크시트의 인쇄 레이아웃을 조정하거나 수동으로 몇 개의 페이지 나누기만 삽입하려는 사용자.
가로 페이지 나누기 삽입
- 페이지가 나뉘기를 원하는 행 바로 아래의 행을 선택합니다(예: 9행과 10행 사이에 나누기를 삽입하려면 10행 번호를 클릭).
- 페이지 레이아웃 탭으로 이동합니다.
- 나누기를 클릭합니다.
- 페이지 나누기 삽입을 선택합니다.
결과: Excel이 선택한 행 위에 가로 페이지 나누기를 삽입합니다.
세로 페이지 나누기 삽입
- 나누기를 원하는 열 바로 오른쪽의 열을 선택합니다(예: C열과 D열 사이에 나누기를 삽입하려면 D열을 클릭).
- 페이지 레이아웃 탭으로 이동합니다.
- 나누기를 클릭합니다.
- 페이지 나누기 삽입을 선택합니다.
결과: Excel이 선택한 열 왼쪽에 페이지 나누기를 삽입합니다.
기존 페이지 나누기 이동
페이지 나누기를 삭제하고 다시 만들지 않고도 이동할 수 있습니다.
- 페이지 나누기 미리 보기 상태인지 확인합니다.
- 페이지 나누기 선을 원하는 위치로 드래그합니다. 선을 드래그할 수 없는 경우, Excel 옵션에서 '셀 끌어서 놓기'가 활성화되어 있는지 확인하십시오. 자동 페이지 나누기를 이동하면 수동 페이지 나누기로 변경됩니다.
참고: 넓은 워크시트의 경우 페이지 방향, 여백 및 배율 설정이 최종 인쇄 레이아웃에 영향을 줄 수 있습니다. 열이 예상대로 나타나지 않으면 인쇄 미리 보기를 검토하십시오.
장점 및 제한 사항
| 장점 | 제한 사항 |
|---|---|
| 작은 조정에 빠르고 쉬움 | 각 나누기마다 수동 반복 작업 필요 |
VBA를 사용하여 N행마다 자동으로 페이지 나누기 삽입하기
대상: 10행마다와 같이 일정한 행 간격으로 페이지 나누기를 삽입해야 하는 Excel 데스크톱 앱 사용자.
Excel은 N행마다 페이지 나누기를 삽입하는 간단한 기본 버튼을 제공하지 않습니다. 페이지 나누기가 몇 개만 필요하다면 수동 삽입으로 충분합니다.
그러나 워크시트에 수백 또는 수천 개의 행이 포함된 경우, 하나씩 페이지 나누기를 추가하는 것은 시간이 많이 걸리고 오류가 발생하기 쉽습니다. 간단한 VBA 매크로를 사용하면 이 과정을 자동화하고 동일한 페이지 나누기 규칙을 일관되게 적용할 수 있습니다.
⚠️ 경고: VBA 매크로로 변경한 내용은 일반적으로 Ctrl + Z로 되돌릴 수 없습니다. 코드를 실행하기 전에 통합 문서의 백업 복사본을 저장하고, 신뢰할 수 있는 출처의 매크로만 실행하십시오!
단계별 가이드
-
Alt + F11을 눌러 VBA 편집기를 엽니다.
-
삽입 > 모듈을 클릭하여 새 모듈을 만듭니다.
-
다음 VBA 코드를 모듈에 붙여넣습니다:
Sub InsertPageBreaksEveryNRows() Dim ws As Worksheet Dim intervalRows As Long Dim lastRow As Long Dim rowIndex As Long Set ws = ActiveSheet intervalRows = 10 ' 원하는 간격으로 이 값을 변경하세요 lastRow = ws.Cells(ws.Rows.Count, "A").End(xlUp).Row For rowIndex = intervalRows + 1 To lastRow Step intervalRows If Not HasHorizontalPageBreak(ws, rowIndex) Then ws.HPageBreaks.Add Before:=ws.Rows(rowIndex) End If Next rowIndex End Sub Private Function HasHorizontalPageBreak(ws As Worksheet, breakRow As Long) As Boolean Dim pb As HPageBreak HasHorizontalPageBreak = False For Each pb In ws.HPageBreaks If pb.Location.Row = breakRow Then HasHorizontalPageBreak = True Exit Function End If Next pb End Function -
intervalRows = 10을 페이지 나누기 사이에 원하는 워크시트 행 수로 변경합니다. -
F5를 눌러 매크로를 실행합니다.
중요 팁:
- 이 매크로는 A열에 데이터가 있다고 가정하고 마지막 행을 결정합니다. 데이터가 다른 열에서 시작되면 "A"를 해당 열 문자로 변경하십시오.
- 이 매크로는 기존 페이지 나누기를 제거하지 않습니다. 새로운 나누기를 삽입하기 전에 모든 나누기를 초기화하려면 매크로 시작 부분에
ActiveSheet.ResetAllPageBreaks를 추가하십시오. - Excel은 한 워크시트에 최대 1,026개의 가로 및 세로 페이지 나누기를 허용합니다. 매우 큰 워크시트에서 간격이 너무 작으면 이 제한을 초과할 수 있습니다.
- 매크로를 통합 문서에 유지하려면 파일을 Excel 매크로 사용 통합 문서(.xlsm)로 저장하십시오.
장점 및 제한 사항
| 장점 | 제한 사항 |
|---|---|
| 반복적인 페이지 나누기 삽입 자동화 | VBA 지식 필요 |
| 사용자 지정 행 간격 지원 | Excel 데스크톱 앱에서만 작동 |
기존 페이지 나누기를 제거해야 하나요? Excel에서 페이지 나누기 제거하는 방법을 참조하십시오.
C#으로 여러 Excel 파일에 페이지 나누기 추가하기
대상: 여러 Excel 파일에 페이지 나누기를 일괄 삽입하거나, Microsoft Excel GUI와 상호 작용하지 않고 엔터프라이즈 소프트웨어 내에서 Excel 보고서 생성을 자동화해야 하는 개발자 또는 고급 사용자.
VBA는 데스크톱 자동화에 뛰어나지만, 기업 자동화 워크플로는 종종 서버 측에서 Excel 문서를 처리해야 합니다. .NET 생태계에서 개발자는 Free Spire.XLS for .NET과 같은 라이브러리를 활용하여 Excel을 열지 않고도 C#에서 가로 또는 세로 페이지 나누기를 삽입할 수 있습니다.
아래 단계에 따라 C# 및 Free Spire.XLS for .NET을 사용하여 여러 Excel 통합 문서에 페이지 나누기를 추가하십시오.
단계
-
필요한 라이브러리를 설치합니다.
NuGet 패키지 관리자를 통해 라이브러리를 설치합니다:
Install-Package FreeSpire.XLS -
페이지 나누기를 일괄 삽입하는 C# 코드를 추가합니다.
다음 예제는 여러 Excel 파일을 반복하고, 가로 및 세로 페이지 나누기를 삽입한 다음, 처리된 통합 문서를 저장합니다.
using System; using System.IO; using Spire.Xls; namespace ExcelPageBreak { internal class Program { private static void Main() { // 처리할 Excel 파일이 포함된 폴더 string inputFolder = @"C:\ExcelFiles"; // 처리된 파일을 별도의 하위 폴더에 저장 string outputFolder = Path.Combine(inputFolder, "Processed"); Directory.CreateDirectory(outputFolder); // 입력 폴더에서 모든 .xlsx 파일 찾기 string[] files = Directory.GetFiles( inputFolder, "*.xlsx", SearchOption.TopDirectoryOnly ); foreach (string filePath in files) { using (Workbook workbook = new Workbook()) { // Excel 파일 로드 workbook.LoadFromFile(filePath); // 첫 번째 워크시트 가져오기 Worksheet sheet = workbook.Worksheets[0]; // 10행 위에 가로 페이지 나누기 삽입 sheet.HPageBreaks.Add(sheet.Range["A10"]); // D열 앞에 세로 페이지 나누기 삽입 sheet.VPageBreaks.Add(sheet.Range["D1"]); // 출력 파일 경로 작성 string outputPath = Path.Combine( outputFolder, Path.GetFileName(filePath) ); // 처리된 통합 문서 저장 workbook.SaveToFile( outputPath, FileFormat.Version2016 ); } } Console.WriteLine( $"{files.Length}개의 통합 문서가 처리되었습니다. " + $"파일 저장 위치: {outputFolder}" ); } } }
코드 작동 방식:
이 코드는 Directory.GetFiles()를 사용하여 지정된 입력 폴더에서 모든 .xlsx 파일을 찾습니다. 각 통합 문서에 대해 다음을 수행합니다:
- 파일을 열고 첫 번째 워크시트를 선택합니다.
- 10행 위에 가로 페이지 나누기를 추가합니다.
- D열 앞에 세로 페이지 나누기를 추가합니다.
- 업데이트된 통합 문서를 별도의
Processed폴더에 저장합니다.
C:\ExcelFiles를 통합 문서가 포함된 폴더로 변경하십시오. 또한 A10 및 D1을 각 새 인쇄 페이지가 시작되기를 원하는 행과 열로 바꿀 수 있습니다.
참고:
- 이 예제는 선택한 폴더의 파일만 처리합니다. 하위 폴더의 파일을 포함하려면
SearchOption.TopDirectoryOnly를SearchOption.AllDirectories로 변경하십시오. - Free Spire.XLS는 .xls 파일의 경우 통합 문서당 5개 워크시트, 워크시트당 200행으로 제한합니다. 이러한 제한은 .xlsx 파일에는 적용되지 않으므로 위의 예제는 .xlsx 파일만 처리합니다. 더 큰 .xls 통합 문서의 경우 .xlsx로 변환한 후 처리하십시오.
장점 및 제한 사항
| 장점 | 제한 사항 |
|---|---|
| 여러 Excel 파일에 대한 페이지 나누기 삽입 자동화 | .NET 프로그래밍 지식 필요 |
| Microsoft Excel 설치 불필요 | 간단한 수동 조정에는 부적합 |
모든 페이지 나누기 삽입 방법 빠르게 비교하기
| 방법 | 최적의 사용 사례 | 크로스 플랫폼 지원? | 일괄 처리? |
|---|---|---|---|
| 수동 삽입 | 일회성, 작은 데이터 세트 | 제한적 (데스크톱 전용) | 아니요 |
| VBA 매크로 | 반복 또는 간격 기반 규칙 | 제한적 (데스크톱 전용) | 제한적 |
| C# + Free Spire.XLS | 일괄 처리 및 자동화된 워크플로 | 예 (크로스 플랫폼 .NET) | 예 |
Excel에서 페이지 나누기가 작동하지 않는 이유
페이지 나누기가 예상한 위치에 나타나지 않으면 다음 설정을 확인하십시오:
-
잘못된 행이나 열이 선택되었습니다.
Excel은 선택한 행 위에 가로 페이지 나누기를, 선택한 열 왼쪽에 세로 페이지 나누기를 삽입합니다. 다음 인쇄 페이지가 시작되어야 하는 행이나 열을 선택하십시오. -
현재 보기에서 페이지 나누기가 보이지 않습니다.
보기 > 페이지 나누기 미리 보기를 열어 워크시트에 자동 및 수동 페이지 나누기를 직접 표시하십시오. -
'자동 맞춤' 배율이 수동 페이지 나누기를 무시하고 있습니다.
워크시트가 자동 맞춤 배율 옵션을 사용하는 경우, Excel이 수동 페이지 나누기를 무시할 수 있습니다. 페이지 설정 대화 상자를 열고 확대/축소 배율을 대신 선택하십시오. -
인쇄 영역에 예상한 콘텐츠가 포함되어 있지 않습니다.
페이지 레이아웃 > 인쇄 영역을 확인하고 올바른 범위가 포함되어 있는지 확인하십시오. 기존 인쇄 영역을 지우고 다시 설정할 수도 있습니다. -
워크시트가 보호되어 있습니다.
보호된 워크시트는 페이지 레이아웃 설정 변경을 방지할 수 있습니다. 시트 보호를 해제하고 페이지 나누기를 삽입하거나 이동한 다음, 필요한 경우 다시 보호하십시오.
변경 후 파일 > 인쇄를 열어 워크시트를 인쇄하거나 내보내기 전에 최종 페이지 레이아웃을 확인하십시오.
자주 묻는 질문(FAQ)
Q1: Excel에서 페이지 나누기를 삽입하는 단축키가 있나요?
A1: Excel에는 페이지 나누기를 삽입하는 범용 단축키가 없습니다. Windows 버전에서는 Alt → P → B → I를 사용하여 '페이지 나누기 삽입' 명령에 액세스할 수 있습니다. 키 시퀀스는 Excel 버전 및 표시 언어에 따라 다를 수 있습니다.
Q2: N행마다 페이지 나누기를 삽입할 수 있나요?
A2: 네. Excel은 고정된 행 간격으로 페이지 나누기를 삽입하는 기본 옵션을 제공하지 않습니다. 하나씩 수동으로 추가하거나 VBA를 사용하여 과정을 자동화할 수 있습니다.
Q3: Excel에서 페이지 나누기를 제거하려면 어떻게 하나요?
A3: 가로 나누기 아래의 행이나 세로 나누기 오른쪽의 열을 선택한 다음, 페이지 레이아웃 > 나누기 > 페이지 나누기 제거로 이동합니다. 모든 수동 페이지 나누기를 제거하려면 모든 페이지 나누기 원래대로를 선택합니다. 자동 페이지 나누기는 직접 제거할 수 없습니다.
Q4: 페이지 나누기가 워크시트 데이터에 영향을 주나요?
A4: 아니요. 페이지 나누기는 인쇄되거나 PDF로 내보낼 때 워크시트가 어떻게 나뉘는지 제어할 뿐입니다. 셀 값, 수식, 서식 또는 워크시트 구조를 변경하지 않습니다.
요약
이 문서에서는 Excel에서 페이지 나누기를 삽입하는 세 가지 실용적인 방법과 일반적인 인쇄 레이아웃 문제를 방지하기 위한 유용한 팁을 논의했습니다. 작업에 가장 적합한 방법을 선택하고, 워크시트를 인쇄하거나 PDF로 내보내기 전에 인쇄 미리 보기에서 최종 결과를 검토하십시오.
Come inserire interruzioni di pagina in Excel: 3 metodi pratici
Indice
- Cosa sono le interruzioni di pagina in Excel
- Aprire l'anteprima interruzioni di pagina prima di iniziare
- Aggiungere o spostare manualmente un'interruzione di pagina in Excel
- Inserire automaticamente interruzioni di pagina ogni N righe con VBA
- Aggiungere interruzioni di pagina a più file Excel con C#
- Confronto rapido di tutti i metodi di inserimento
- Perché le interruzioni di pagina non funzionano in Excel
- Domande frequenti
- Riepilogo
Quando un foglio di lavoro Excel contiene più sezioni, tabelle lunghe o molte righe di dati, Excel potrebbe dividere automaticamente il contenuto tra le pagine in punti poco convenienti. Un'intestazione potrebbe apparire in fondo a una pagina, una tabella potrebbe essere divisa a metà o colonne correlate potrebbero essere separate su pagine diverse. L'aggiunta di interruzioni di pagina ti consente di controllare dove inizia una nuova pagina stampata e rende i report più facili da leggere.
In questo articolo, vedremo 3 modi pratici per inserire interruzioni di pagina in Excel:
- Aggiungere o spostare manualmente un'interruzione di pagina in Excel
- Inserire interruzioni di pagina ogni N righe usando VBA
- Aggiungere interruzioni di pagina a più file Excel con C#
Cosa sono le interruzioni di pagina in Excel?
Un'interruzione di pagina segna il punto in cui termina una pagina stampata e ne inizia un'altra.
Le interruzioni di pagina influiscono solo sul layout di stampa. Non spostano le celle, non modificano le formule, non dividono un foglio di lavoro in fogli separati né modificano i dati sottostanti.
Excel utilizza due tipi di interruzioni di pagina:
- Interruzioni di pagina automatiche: create da Excel in base al formato carta, ai margini, al ridimensionamento, all'altezza delle righe e alla larghezza delle colonne.
- Interruzioni di pagina manuali: inserite dall'utente per controllare dove inizia una nuova pagina stampata.
Puoi inserire due tipi di interruzioni di pagina manuali:
- Interruzione di pagina orizzontale: avvia una nuova pagina stampata in corrispondenza di una riga specifica.
- Interruzione di pagina verticale: avvia una nuova pagina stampata in corrispondenza di una colonna specifica.
Aprire l'anteprima interruzioni di pagina prima di iniziare
L'anteprima interruzioni di pagina mostra come Excel divide attualmente il foglio di lavoro in pagine stampate. Sebbene non sia necessario aprire questa vista prima di inserire un'interruzione, rende i confini di pagina più facili da vedere e ti aiuta a controllare il risultato.
Per aprire l'anteprima interruzioni di pagina:
-
Vai alla scheda Visualizza sulla barra multifunzione di Excel.
-
Seleziona Anteprima interruzioni di pagina.
Excel visualizzerà i confini di pagina direttamente sul foglio di lavoro.
Suggerimento: Le linee tratteggiate indicano le interruzioni di pagina automatiche create da Excel. Le linee continue indicano le interruzioni di pagina manuali, incluse quelle automatiche che hai spostato manualmente.
Aggiungere o spostare manualmente un'interruzione di pagina in Excel
Ideale per: utenti che devono regolare il layout di stampa di un singolo foglio di lavoro o inserire solo poche interruzioni di pagina manualmente.
Inserire un'interruzione di pagina orizzontale
- Seleziona la riga direttamente sotto il punto in cui vuoi dividere la pagina (ad esempio, fai clic sul numero di riga 10 per inserire un'interruzione tra le righe 9 e 10).
- Vai alla scheda Layout di pagina.
- Fai clic su Interruzioni.
- Seleziona Inserisci interruzione di pagina.
Risultato: Excel inserisce un'interruzione di pagina orizzontale sopra la riga selezionata.
Inserire un'interruzione di pagina verticale
- Seleziona la colonna direttamente a destra del punto in cui vuoi la divisione (ad esempio, fai clic sulla colonna D per inserire un'interruzione tra le colonne C e D).
- Vai alla scheda Layout di pagina.
- Fai clic su Interruzioni.
- Scegli Inserisci interruzione di pagina.
Risultato: Excel inserisce l'interruzione di pagina a sinistra della colonna selezionata.
Spostare un'interruzione di pagina esistente
Puoi spostare un'interruzione di pagina senza eliminarla e ricrearla:
- Assicurati di essere in Anteprima interruzioni di pagina.
- Trascina la linea di interruzione di pagina nella posizione desiderata. Se la linea non può essere trascinata, assicurati che il trascinamento delle celle sia abilitato nelle Opzioni di Excel. Spostare un'interruzione di pagina automatica la trasforma in un'interruzione manuale.
Nota: Per fogli di lavoro ampi, l'orientamento della pagina, i margini e le impostazioni di ridimensionamento possono influire sul layout di stampa finale. Controlla l'Anteprima di stampa se le colonne non appaiono come previsto.
Vantaggi e limitazioni
| Vantaggi | Limitazioni |
|---|---|
| Rapido e semplice per piccole regolazioni | Richiede la ripetizione manuale per ogni interruzione |
Inserire automaticamente interruzioni di pagina ogni N righe con VBA
Ideale per: utenti dell'app desktop Excel che devono inserire interruzioni di pagina a intervalli di riga regolari, ad esempio ogni 10 righe.
Excel non fornisce un semplice pulsante integrato per inserire interruzioni di pagina ogni N righe. Se ti servono solo poche interruzioni, l'inserimento manuale è solitamente sufficiente.
Tuttavia, quando un foglio di lavoro contiene centinaia o migliaia di righe, aggiungere interruzioni di pagina una per una diventa dispendioso in termini di tempo e soggetto a errori. Una breve macro VBA può automatizzare questo processo e applicare la stessa regola di interruzione in modo coerente.
⚠️ Attenzione: Le modifiche apportate da una macro VBA solitamente non possono essere annullate con Ctrl + Z. Salva una copia di backup della cartella di lavoro prima di eseguire il codice ed esegui macro solo da fonti attendibili!
Guida passo-passo
-
Premi Alt + F11 per aprire l'editor VBA.
-
Fai clic su Inserisci > Modulo per creare un nuovo modulo.
-
Incolla il seguente codice VBA nel modulo:
Sub InsertPageBreaksEveryNRows() Dim ws As Worksheet Dim intervalRows As Long Dim lastRow As Long Dim rowIndex As Long Set ws = ActiveSheet intervalRows = 10 ' Cambia questo valore con l'intervallo desiderato lastRow = ws.Cells(ws.Rows.Count, "A").End(xlUp).Row For rowIndex = intervalRows + 1 To lastRow Step intervalRows If Not HasHorizontalPageBreak(ws, rowIndex) Then ws.HPageBreaks.Add Before:=ws.Rows(rowIndex) End If Next rowIndex End Sub Private Function HasHorizontalPageBreak(ws As Worksheet, breakRow As Long) As Boolean Dim pb As HPageBreak HasHorizontalPageBreak = False For Each pb In ws.HPageBreaks If pb.Location.Row = breakRow Then HasHorizontalPageBreak = True Exit Function End If Next pb End Function -
Cambia
intervalRows = 10con il numero di righe del foglio di lavoro che desideri tra le interruzioni di pagina. -
Premi F5 per eseguire la macro.
Suggerimenti importanti:
- La macro presuppone che la colonna A contenga dati per determinare l'ultima riga. Se i tuoi dati iniziano in una colonna diversa, cambia "A" con la lettera della colonna appropriata.
- La macro non rimuove le interruzioni di pagina esistenti. Se vuoi reimpostare tutte le interruzioni prima di inserirne di nuove, aggiungi
ActiveSheet.ResetAllPageBreaksall'inizio della macro. - Excel consente fino a 1.026 interruzioni di pagina orizzontali e verticali su un foglio di lavoro. Intervalli molto piccoli su fogli di lavoro estremamente grandi potrebbero superare questo limite.
- Per mantenere la macro nella cartella di lavoro, salva il file come Cartella di lavoro con attivazione macro di Excel (.xlsm).
Vantaggi e limitazioni
| Vantaggi | Limitazioni |
|---|---|
| Automatizza l'inserimento ripetuto di interruzioni di pagina | Richiede conoscenze di VBA |
| Supporta intervalli di riga personalizzati | Funziona solo nell'app desktop Excel |
Devi invece rimuovere le interruzioni di pagina esistenti? Vedi Come rimuovere le interruzioni di pagina in Excel.
Aggiungere interruzioni di pagina a più file Excel con C#
Ideale per: sviluppatori o utenti avanzati che devono inserire in batch interruzioni di pagina in più file Excel o automatizzare la generazione di report Excel all'interno di software aziendali senza interagire con l'interfaccia grafica di Microsoft Excel.
Mentre VBA è eccellente per l'automazione desktop, i flussi di lavoro aziendali spesso richiedono l'elaborazione di documenti Excel lato server. Nell'ecosistema .NET, gli sviluppatori possono utilizzare librerie come Free Spire.XLS for .NET per inserire interruzioni di pagina orizzontali o verticali in C# senza aprire Excel.
Segui i passaggi seguenti per aggiungere interruzioni di pagina a più cartelle di lavoro Excel con C# e Free Spire.XLS for .NET.
Passaggi
-
Installa la libreria richiesta.
Installa la libreria tramite NuGet Package Manager:
Install-Package FreeSpire.XLS -
Aggiungi il codice C# per inserire in batch le interruzioni di pagina.
L'esempio seguente esegue un ciclo attraverso più file Excel, inserisce interruzioni di pagina orizzontali e verticali e salva le cartelle di lavoro elaborate.
using System; using System.IO; using Spire.Xls; namespace ExcelPageBreak { internal class Program { private static void Main() { // Cartella contenente i file Excel da elaborare string inputFolder = @"C:\ExcelFiles"; // Salva i file elaborati in una sottocartella separata string outputFolder = Path.Combine(inputFolder, "Processed"); Directory.CreateDirectory(outputFolder); // Trova tutti i file .xlsx nella cartella di input string[] files = Directory.GetFiles( inputFolder, "*.xlsx", SearchOption.TopDirectoryOnly ); foreach (string filePath in files) { using (Workbook workbook = new Workbook()) { // Carica il file Excel workbook.LoadFromFile(filePath); // Ottieni il primo foglio di lavoro Worksheet sheet = workbook.Worksheets[0]; // Inserisci un'interruzione di pagina orizzontale sopra la riga 10 sheet.HPageBreaks.Add(sheet.Range["A10"]); // Inserisci un'interruzione di pagina verticale prima della colonna D sheet.VPageBreaks.Add(sheet.Range["D1"]); // Crea il percorso del file di output string outputPath = Path.Combine( outputFolder, Path.GetFileName(filePath) ); // Salva la cartella di lavoro elaborata workbook.SaveToFile( outputPath, FileFormat.Version2016 ); } } Console.WriteLine( $"{files.Length} cartella/e di lavoro elaborata/e. " + $"I file sono stati salvati in: {outputFolder}" ); } } }
Come funziona il codice:
Il codice utilizza Directory.GetFiles() per trovare tutti i file .xlsx nella cartella di input specificata. Per ogni cartella di lavoro:
- Apre il file e seleziona il primo foglio di lavoro.
- Aggiunge un'interruzione di pagina orizzontale sopra la riga 10.
- Aggiunge un'interruzione di pagina verticale prima della colonna D.
- Salva la cartella di lavoro aggiornata in una cartella
Processedseparata.
Cambia C:\ExcelFiles con la cartella che contiene le tue cartelle di lavoro. Puoi anche sostituire A10 e D1 con la riga e la colonna in cui vuoi che inizi ogni nuova pagina stampata.
Note:
- L'esempio elabora i file solo nella cartella selezionata. Per includere i file nelle sue sottocartelle, cambia
SearchOption.TopDirectoryOnlyinSearchOption.AllDirectories. - Free Spire.XLS limita i file .xls a 5 fogli di lavoro per cartella e 200 righe per foglio. Questi limiti non si applicano ai file .xlsx, quindi l'esempio sopra elabora solo file .xlsx. Per cartelle di lavoro .xls più grandi, convertile in .xlsx prima dell'elaborazione.
Vantaggi e limitazioni
| Vantaggi | Limitazioni |
|---|---|
| Automatizza l'inserimento di interruzioni di pagina per più file Excel | Richiede conoscenze di programmazione .NET |
| Non richiede l'installazione di Microsoft Excel | Non adatto a semplici regolazioni manuali |
Confronto rapido di tutti i metodi di inserimento
| Metodo | Caso d'uso migliore | Supporto multipiattaforma? | Elaborazione batch? |
|---|---|---|---|
| Inserimento manuale | Dataset piccoli e occasionali | Limitato (solo desktop) | No |
| Macro VBA | Regole ripetute o basate su intervalli | Limitato (solo desktop) | Limitato |
| C# + Free Spire.XLS | Elaborazione batch e flussi di lavoro automatizzati | Sì (.NET multipiattaforma) | Sì |
Perché le interruzioni di pagina non funzionano in Excel?
Se un'interruzione di pagina non appare dove previsto, controlla le seguenti impostazioni:
-
È selezionata la riga o la colonna sbagliata.
Excel inserisce un'interruzione di pagina orizzontale sopra la riga selezionata e un'interruzione di pagina verticale a sinistra della colonna selezionata. Seleziona la riga o la colonna in cui dovrebbe iniziare la pagina stampata successiva. -
L'interruzione di pagina non è visibile nella vista corrente.
Apri Visualizza > Anteprima interruzioni di pagina per visualizzare le interruzioni di pagina automatiche e manuali direttamente sul foglio di lavoro. -
Il ridimensionamento "Adatta a" sta sovrascrivendo le interruzioni di pagina manuali.
Quando il foglio di lavoro utilizza l'opzione di ridimensionamento Adatta a, Excel potrebbe ignorare le interruzioni di pagina manuali. Apri la finestra di dialogo Imposta pagina e seleziona invece Regola in. -
L'area di stampa non include il contenuto previsto.
Controlla Layout di pagina > Area di stampa e conferma che sia incluso l'intervallo corretto. Puoi anche cancellare l'area di stampa esistente e impostarla di nuovo. -
Il foglio di lavoro è protetto.
Un foglio di lavoro protetto potrebbe impedire modifiche alle impostazioni del layout di pagina. Rimuovi la protezione dal foglio, inserisci o sposta l'interruzione di pagina, quindi proteggilo di nuovo se necessario.
Dopo aver apportato le modifiche, apri File > Stampa per controllare il layout di pagina finale prima di stampare o esportare il foglio di lavoro.
Domande frequenti
D1: Esiste una scorciatoia per inserire un'interruzione di pagina in Excel?
R1: Excel non ha una scorciatoia universale per inserire interruzioni di pagina. Nelle versioni Windows, puoi usare Alt → P → B → I per accedere al comando Inserisci interruzione di pagina. La sequenza di tasti può variare in base alla versione di Excel e alla lingua di visualizzazione.
D2: Posso inserire interruzioni di pagina ogni N righe?
R2: Sì. Excel non fornisce un'opzione integrata per inserire interruzioni di pagina a intervalli di riga fissi. Puoi aggiungerle manualmente una per una o usare VBA per automatizzare il processo.
D3: Come rimuovo un'interruzione di pagina in Excel?
R3: Seleziona la riga sotto un'interruzione orizzontale o la colonna a destra di un'interruzione verticale, quindi vai su Layout di pagina > Interruzioni > Rimuovi interruzione di pagina. Per rimuovere tutte le interruzioni di pagina manuali, seleziona Reimposta tutte le interruzioni di pagina. Le interruzioni di pagina automatiche non possono essere rimosse direttamente.
D4: Le interruzioni di pagina influiscono sui dati del mio foglio di lavoro?
R4: No. Le interruzioni di pagina controllano solo come un foglio di lavoro viene diviso quando stampato o esportato in PDF. Non modificano i valori delle celle, le formule, la formattazione o la struttura del foglio di lavoro.
Riepilogo
In questo articolo, abbiamo discusso tre modi pratici per inserire interruzioni di pagina in Excel, insieme a suggerimenti utili per evitare comuni problemi di layout di stampa. Scegli il metodo più adatto al tuo compito e controlla il risultato finale nell'Anteprima di stampa prima di stampare o esportare il foglio di lavoro in PDF.
Comment insérer des sauts de page dans Excel : 3 méthodes pratiques
Table des matières
- Que sont les sauts de page dans Excel
- Ouvrir l'aperçu des sauts de page avant de commencer
- Ajouter ou déplacer manuellement un saut de page dans Excel
- Insérer automatiquement des sauts de page toutes les N lignes avec VBA
- Ajouter des sauts de page à plusieurs fichiers Excel avec C#
- Comparaison rapide de toutes les méthodes d'insertion de sauts de page
- Pourquoi les sauts de page ne fonctionnent-ils pas dans Excel
- Questions fréquemment posées
- Résumé
Lorsqu'une feuille de calcul Excel contient plusieurs sections, de longs tableaux ou de nombreuses lignes de données, Excel peut diviser automatiquement le contenu sur plusieurs pages à des endroits inopportuns. Un en-tête peut apparaître au bas d'une page, un tableau peut être coupé en deux, ou des colonnes liées peuvent être séparées sur des pages différentes. L'ajout de sauts de page vous permet de contrôler l'endroit où commence une nouvelle page imprimée et facilite la lecture des rapports.
Dans cet article, nous aborderons 3 méthodes pratiques pour insérer des sauts de page dans Excel :
- Ajouter ou déplacer manuellement un saut de page dans Excel
- Insérer des sauts de page toutes les N lignes en utilisant VBA
- Ajouter des sauts de page à plusieurs fichiers Excel avec C#
Que sont les sauts de page dans Excel ?
Un saut de page marque le point où une page imprimée se termine et où la suivante commence.
Les sauts de page n'affectent que la mise en page d'impression. Ils ne déplacent pas les cellules, ne modifient pas les formules, ne divisent pas une feuille de calcul en feuilles distinctes et ne modifient pas les données sous-jacentes.
Excel utilise deux types de sauts de page :
- Les sauts de page automatiques sont créés par Excel en fonction de la taille du papier, des marges, de la mise à l'échelle, de la hauteur des lignes et de la largeur des colonnes.
- Les sauts de page manuels sont insérés par l'utilisateur pour contrôler l'endroit où commence une nouvelle page imprimée.
Vous pouvez insérer deux types de sauts de page manuels :
- Saut de page horizontal : Commence une nouvelle page imprimée à une ligne spécifique.
- Saut de page vertical : Commence une nouvelle page imprimée à une colonne spécifique.
Ouvrir l'aperçu des sauts de page avant de commencer
L'aperçu des sauts de page montre comment Excel divise actuellement la feuille de calcul en pages imprimées. Bien qu'il ne soit pas nécessaire d'ouvrir cette vue avant d'insérer un saut de page, elle facilite la visualisation des limites de page et vous aide à vérifier le résultat.
Pour ouvrir l'aperçu des sauts de page :
-
Allez dans l'onglet Affichage du ruban Excel.
-
Sélectionnez Aperçu des sauts de page.
Excel affichera les limites de page directement sur la feuille de calcul.
Conseil : Les lignes en pointillés indiquent les sauts de page automatiques créés par Excel. Les lignes pleines indiquent les sauts de page manuels, y compris les sauts de page automatiques que vous avez déplacés manuellement.
Ajouter ou déplacer manuellement un saut de page dans Excel
Idéal pour : Les utilisateurs qui ont besoin d'ajuster la mise en page d'impression d'une seule feuille de calcul ou d'insérer manuellement seulement quelques sauts de page.
Insérer un saut de page horizontal
- Sélectionnez la ligne située juste en dessous de l'endroit où vous souhaitez diviser la page (par exemple, cliquez sur le numéro de ligne 10 pour insérer un saut entre les lignes 9 et 10).
- Allez dans l'onglet Mise en page.
- Cliquez sur Sauts de page.
- Sélectionnez Insérer un saut de page.
Résultat : Excel insère un saut de page horizontal au-dessus de la ligne sélectionnée.
Insérer un saut de page vertical
- Sélectionnez la colonne située juste à droite de l'endroit où vous souhaitez effectuer la division (par exemple, cliquez sur la colonne D pour insérer un saut entre les colonnes C et D).
- Allez dans l'onglet Mise en page.
- Cliquez sur Sauts de page.
- Choisissez Insérer un saut de page.
Résultat : Excel insère le saut de page à gauche de la colonne sélectionnée.
Déplacer un saut de page existant
Vous pouvez déplacer un saut de page sans le supprimer et le recréer :
- Assurez-vous d'être dans l'Aperçu des sauts de page.
- Faites glisser la ligne de saut de page vers la position souhaitée. Si la ligne ne peut pas être déplacée, assurez-vous que le glisser-déplacer des cellules est activé dans les Options Excel. Déplacer un saut de page automatique le transforme en saut de page manuel.
Remarque : Pour les feuilles de calcul larges, l'orientation de la page, les marges et les paramètres de mise à l'échelle peuvent affecter la mise en page imprimée finale. Vérifiez l'aperçu avant impression si les colonnes ne s'affichent pas comme prévu.
Avantages et limites
| Avantages | Limites |
|---|---|
| Rapide et facile pour les petits ajustements | Nécessite une répétition manuelle pour chaque saut |
Insérer automatiquement des sauts de page toutes les N lignes avec VBA
Idéal pour : Les utilisateurs de l'application de bureau Excel qui ont besoin d'insérer des sauts de page à intervalles réguliers, par exemple toutes les 10 lignes.
Excel ne fournit pas de bouton intégré simple pour insérer des sauts de page toutes les N lignes. Si vous n'avez besoin que de quelques sauts de page, l'insertion manuelle suffit généralement.
Cependant, lorsqu'une feuille de calcul contient des centaines ou des milliers de lignes, ajouter des sauts de page un par un devient fastidieux et source d'erreurs. Une courte macro VBA peut automatiser ce processus et appliquer la même règle de saut de page de manière cohérente.
⚠️ Avertissement : Les modifications effectuées par une macro VBA ne peuvent généralement pas être annulées avec Ctrl + Z. Enregistrez une copie de sauvegarde du classeur avant d'exécuter le code, et n'exécutez que des macros provenant de sources de confiance !
Guide étape par étape
-
Appuyez sur Alt + F11 pour ouvrir l'éditeur VBA.
-
Cliquez sur Insertion > Module pour créer un nouveau module.
-
Collez le code VBA suivant dans le module :
Sub InsertPageBreaksEveryNRows() Dim ws As Worksheet Dim intervalRows As Long Dim lastRow As Long Dim rowIndex As Long Set ws = ActiveSheet intervalRows = 10 ' Changez cette valeur pour votre intervalle souhaité lastRow = ws.Cells(ws.Rows.Count, "A").End(xlUp).Row For rowIndex = intervalRows + 1 To lastRow Step intervalRows If Not HasHorizontalPageBreak(ws, rowIndex) Then ws.HPageBreaks.Add Before:=ws.Rows(rowIndex) End If Next rowIndex End Sub Private Function HasHorizontalPageBreak(ws As Worksheet, breakRow As Long) As Boolean Dim pb As HPageBreak HasHorizontalPageBreak = False For Each pb In ws.HPageBreaks If pb.Location.Row = breakRow Then HasHorizontalPageBreak = True Exit Function End If Next pb End Function -
Modifiez
intervalRows = 10par le nombre de lignes de la feuille de calcul que vous souhaitez entre chaque saut de page. -
Appuyez sur F5 pour exécuter la macro.
Conseils importants :
- La macro suppose que la colonne A contient des données pour déterminer la dernière ligne. Si vos données commencent dans une autre colonne, remplacez "A" par la lettre de colonne appropriée.
- La macro ne supprime aucun saut de page existant. Si vous souhaitez réinitialiser tous les sauts avant d'en insérer de nouveaux, ajoutez
ActiveSheet.ResetAllPageBreaksau début de la macro. - Excel autorise jusqu'à 1 026 sauts de page horizontaux et verticaux sur une seule feuille de calcul. Des intervalles très petits sur des feuilles de calcul extrêmement grandes peuvent dépasser cette limite.
- Pour conserver la macro dans le classeur, enregistrez le fichier en tant que Classeur Excel prenant en charge les macros (.xlsm).
Avantages et limites
| Avantages | Limites |
|---|---|
| Automatise l'insertion répétée de sauts de page | Nécessite des connaissances en VBA |
| Prend en charge les intervalles de lignes personnalisés | Fonctionne uniquement dans l'application de bureau Excel |
Besoin de supprimer des sauts de page existants à la place ? Voir Comment supprimer des sauts de page dans Excel.
Ajouter des sauts de page à plusieurs fichiers Excel avec C#
Idéal pour : Les développeurs ou les utilisateurs avancés qui ont besoin d'insérer par lots des sauts de page dans plusieurs fichiers Excel ou d'automatiser la génération de rapports Excel au sein de logiciels d'entreprise sans interagir avec l'interface graphique de Microsoft Excel.
Bien que VBA soit excellent pour l'automatisation de bureau, les flux de travail d'automatisation en entreprise nécessitent souvent le traitement de documents Excel côté serveur. Dans l'écosystème .NET, les développeurs peuvent utiliser des bibliothèques telles que Free Spire.XLS for .NET pour insérer des sauts de page horizontaux ou verticaux en C# sans ouvrir Excel.
Suivez les étapes ci-dessous pour ajouter des sauts de page à plusieurs classeurs Excel avec C# et Free Spire.XLS for .NET.
Étapes
-
Installez la bibliothèque requise.
Installez la bibliothèque via le gestionnaire de paquets NuGet :
Install-Package FreeSpire.XLS -
Ajoutez le code C# pour insérer des sauts de page par lots.
L'exemple suivant parcourt plusieurs fichiers Excel, insère des sauts de page horizontaux et verticaux, et enregistre les classeurs traités.
using System; using System.IO; using Spire.Xls; namespace ExcelPageBreak { internal class Program { private static void Main() { // Dossier contenant les fichiers Excel à traiter string inputFolder = @"C:\ExcelFiles"; // Enregistrer les fichiers traités dans un sous-dossier séparé string outputFolder = Path.Combine(inputFolder, "Processed"); Directory.CreateDirectory(outputFolder); // Trouver tous les fichiers .xlsx dans le dossier d'entrée string[] files = Directory.GetFiles( inputFolder, "*.xlsx", SearchOption.TopDirectoryOnly ); foreach (string filePath in files) { using (Workbook workbook = new Workbook()) { // Charger le fichier Excel workbook.LoadFromFile(filePath); // Obtenir la première feuille de calcul Worksheet sheet = workbook.Worksheets[0]; // Insérer un saut de page horizontal au-dessus de la ligne 10 sheet.HPageBreaks.Add(sheet.Range["A10"]); // Insérer un saut de page vertical avant la colonne D sheet.VPageBreaks.Add(sheet.Range["D1"]); // Construire le chemin du fichier de sortie string outputPath = Path.Combine( outputFolder, Path.GetFileName(filePath) ); // Enregistrer le classeur traité workbook.SaveToFile( outputPath, FileFormat.Version2016 ); } } Console.WriteLine( $"{files.Length} classeur(s) traité(s). " + $"Les fichiers ont été enregistrés dans : {outputFolder}" ); } } }
Comment fonctionne le code :
Le code utilise Directory.GetFiles() pour trouver tous les fichiers .xlsx dans le dossier d'entrée spécifié. Pour chaque classeur, il :
- Ouvre le fichier et sélectionne la première feuille de calcul.
- Ajoute un saut de page horizontal au-dessus de la ligne 10.
- Ajoute un saut de page vertical avant la colonne D.
- Enregistre le classeur mis à jour dans un dossier
Processedséparé.
Remplacez C:\ExcelFiles par le dossier contenant vos classeurs. Vous pouvez également remplacer A10 et D1 par la ligne et la colonne où vous souhaitez que chaque nouvelle page imprimée commence.
Remarques :
- L'exemple traite uniquement les fichiers du dossier sélectionné. Pour inclure les fichiers de ses sous-dossiers, remplacez
SearchOption.TopDirectoryOnlyparSearchOption.AllDirectories. - Free Spire.XLS limite les fichiers .xls à 5 feuilles de calcul par classeur et 200 lignes par feuille de calcul. Ces limites ne s'appliquent pas aux fichiers .xlsx, l'exemple ci-dessus ne traite donc que les fichiers .xlsx. Pour les classeurs .xls plus volumineux, convertissez-les en .xlsx avant le traitement.
Avantages et limites
| Avantages | Limites |
|---|---|
| Automatise l'insertion de sauts de page pour plusieurs fichiers Excel | Nécessite des connaissances en programmation .NET |
| Ne nécessite pas l'installation de Microsoft Excel | Ne convient pas aux ajustements manuels simples |
Comparaison rapide de toutes les méthodes d'insertion de sauts de page
| Méthode | Meilleur cas d'utilisation | Prise en charge multiplateforme ? | Traitement par lots ? |
|---|---|---|---|
| Insertion manuelle | Ensembles de données ponctuels et petits | Limitée (Bureau uniquement) | Non |
| Macro VBA | Règles répétées ou basées sur des intervalles | Limitée (Bureau uniquement) | Limitée |
| C# + Free Spire.XLS | Traitement par lots et flux de travail automatisés | Oui (.NET multiplateforme) | Oui |
Pourquoi les sauts de page ne fonctionnent-ils pas dans Excel ?
Si un saut de page n'apparaît pas là où il est attendu, vérifiez les paramètres suivants :
-
La mauvaise ligne ou colonne est sélectionnée.
Excel insère un saut de page horizontal au-dessus de la ligne sélectionnée et un saut de page vertical à gauche de la colonne sélectionnée. Sélectionnez la ligne ou la colonne où la prochaine page imprimée doit commencer. -
Le saut de page n'est pas visible dans la vue actuelle.
Ouvrez Affichage > Aperçu des sauts de page pour afficher les sauts de page automatiques et manuels directement sur la feuille de calcul. -
La mise à l'échelle "Ajuster" remplace les sauts de page manuels.
Lorsque la feuille de calcul utilise l'option de mise à l'échelle Ajuster, Excel peut ignorer les sauts de page manuels. Ouvrez la boîte de dialogue Mise en page et sélectionnez Ajuster à à la place. -
La zone d'impression n'inclut pas le contenu attendu.
Vérifiez Mise en page > Zone d'impression et confirmez que la plage correcte est incluse. Vous pouvez également effacer la zone d'impression existante et la définir à nouveau. -
La feuille de calcul est protégée.
Une feuille de calcul protégée peut empêcher les modifications des paramètres de mise en page. Déprotégez la feuille, insérez ou déplacez le saut de page, puis protégez-la à nouveau si nécessaire.
Après avoir effectué des modifications, ouvrez Fichier > Imprimer pour vérifier la mise en page finale avant d'imprimer ou d'exporter la feuille de calcul.
Questions fréquemment posées
Q1 : Existe-t-il un raccourci pour insérer un saut de page dans Excel ?
A1 : Excel ne dispose pas de raccourci universel pour insérer des sauts de page. Dans les versions Windows, vous pouvez utiliser Alt → P → B → I pour accéder à la commande Insérer un saut de page. La séquence de touches peut varier selon la version d'Excel et la langue d'affichage.
Q2 : Puis-je insérer des sauts de page toutes les N lignes ?
A2 : Oui. Excel ne fournit pas d'option intégrée pour insérer des sauts de page à intervalles de lignes fixes. Vous pouvez les ajouter manuellement un par un ou utiliser VBA pour automatiser le processus.
Q3 : Comment supprimer un saut de page dans Excel ?
A3 : Sélectionnez la ligne en dessous d'un saut horizontal ou la colonne à droite d'un saut vertical, puis allez dans Mise en page > Sauts de page > Supprimer le saut de page. Pour supprimer tous les sauts de page manuels, sélectionnez Réinitialiser tous les sauts de page. Les sauts de page automatiques ne peuvent pas être supprimés directement.
Q4 : Les sauts de page affectent-ils les données de ma feuille de calcul ?
A4 : Non. Les sauts de page contrôlent uniquement la façon dont une feuille de calcul est divisée lors de l'impression ou de l'exportation au format PDF. Ils ne modifient pas les valeurs des cellules, les formules, la mise en forme ou la structure de la feuille de calcul.
Résumé
Dans cet article, nous avons discuté de trois méthodes pratiques pour insérer des sauts de page dans Excel, ainsi que de conseils utiles pour éviter les problèmes courants de mise en page d'impression. Choisissez la méthode qui correspond le mieux à votre tâche et vérifiez le résultat final dans l'aperçu avant impression avant d'imprimer ou d'exporter la feuille de calcul au format PDF.
Cómo insertar saltos de página en Excel: 3 formas prácticas
Tabla de contenidos
- Qué son los saltos de página en Excel
- Abrir la Vista previa de salto de página antes de empezar
- Agregar o mover un salto de página en Excel manualmente
- Insertar saltos de página cada N filas automáticamente con VBA
- Agregar saltos de página a múltiples archivos de Excel con C#
- Comparación rápida de todos los métodos de inserción de saltos de página
- Por qué no funcionan los saltos de página en Excel
- Preguntas frecuentes
- Resumen
Cuando una hoja de cálculo de Excel contiene múltiples secciones, tablas largas o muchas filas de datos, es posible que Excel divida automáticamente el contenido entre páginas en lugares inconvenientes. Un encabezado puede aparecer al final de una página, una tabla puede quedar dividida por la mitad o columnas relacionadas pueden quedar separadas en diferentes páginas. Agregar saltos de página le permite controlar dónde comienza una nueva página impresa y facilita la lectura de los informes.
En este artículo, cubriremos 3 formas prácticas de insertar saltos de página en Excel:
- Agregar o mover un salto de página en Excel manualmente
- Insertar saltos de página cada N filas usando VBA
- Agregar saltos de página a múltiples archivos de Excel con C#
¿Qué son los saltos de página en Excel?
Un salto de página marca el punto donde termina una página impresa y comienza la siguiente.
Los saltos de página afectan solo al diseño de impresión. No mueven celdas, no cambian fórmulas, no dividen una hoja de cálculo en hojas separadas ni modifican los datos subyacentes.
Excel utiliza dos tipos de saltos de página:
- Saltos de página automáticos: Son creados por Excel según el tamaño del papel, los márgenes, la escala, la altura de las filas y el ancho de las columnas.
- Saltos de página manuales: Son insertados por el usuario para controlar dónde comienza una nueva página impresa.
Puede insertar dos tipos de saltos de página manuales:
- Salto de página horizontal: Inicia una nueva página impresa en una fila específica.
- Salto de página vertical: Inicia una nueva página impresa en una columna específica.
Abrir la Vista previa de salto de página antes de empezar
La Vista previa de salto de página muestra cómo divide Excel actualmente la hoja de cálculo en páginas impresas. Aunque no es necesario abrir esta vista antes de insertar un salto de página, facilita la visualización de los límites de página y ayuda a verificar el resultado.
Para abrir la Vista previa de salto de página:
-
Vaya a la pestaña Vista en la cinta de opciones de Excel.
-
Seleccione Vista previa de salto de página.
Excel mostrará los límites de página directamente en la hoja de cálculo.
Consejo: Las líneas discontinuas indican saltos de página automáticos creados por Excel. Las líneas sólidas indican saltos de página manuales, incluidos los saltos de página automáticos que ha movido manualmente.
Agregar o mover un salto de página en Excel manualmente
Ideal para: Usuarios que necesitan ajustar el diseño de impresión de una sola hoja de cálculo o insertar solo unos pocos saltos de página manualmente.
Insertar un salto de página horizontal
- Seleccione la fila directamente debajo de donde desea que se divida la página (por ejemplo, haga clic en el número de fila 10 para insertar un salto entre las filas 9 y 10).
- Vaya a la pestaña Disposición de página (o Diseño de página).
- Haga clic en Saltos.
- Seleccione Insertar salto de página.
Resultado: Excel inserta un salto de página horizontal sobre la fila seleccionada.
Insertar un salto de página vertical
- Seleccione la columna directamente a la derecha de donde desea la división (por ejemplo, haga clic en la columna D para insertar un salto entre las columnas C y D).
- Vaya a la pestaña Disposición de página.
- Haga clic en Saltos.
- Elija Insertar salto de página.
Resultado: Excel inserta el salto de página a la izquierda de la columna seleccionada.
Mover un salto de página existente
Puede mover un salto de página sin eliminarlo y volver a crearlo:
- Asegúrese de estar en la Vista previa de salto de página.
- Arrastre la línea de salto de página a la posición deseada. Si la línea no se puede arrastrar, asegúrese de que la opción de arrastrar y colocar celdas esté habilitada en las Opciones de Excel. Mover un salto de página automático lo convierte en un salto de página manual.
Nota: Para hojas de cálculo anchas, la orientación de la página, los márgenes y la configuración de escala pueden afectar el diseño impreso final. Revise la Vista previa de impresión si las columnas no aparecen como se esperaba.
Ventajas y limitaciones
| Ventajas | Limitaciones |
|---|---|
| Rápido y fácil para ajustes pequeños | Requiere repetición manual para cada salto |
Insertar saltos de página cada N filas automáticamente con VBA
Ideal para: Usuarios de la aplicación de escritorio de Excel que necesitan insertar saltos de página a intervalos de filas regulares, como cada 10 filas.
Excel no proporciona un botón integrado simple para insertar saltos de página cada N filas. Si solo necesita unos pocos saltos de página, la inserción manual suele ser suficiente.
Sin embargo, cuando una hoja de cálculo contiene cientos o miles de filas, agregar saltos de página uno por uno se vuelve lento y propenso a errores. Una macro de VBA corta puede automatizar este proceso y aplicar la misma regla de salto de página de manera consistente.
⚠️ Advertencia: Los cambios realizados por una macro de VBA generalmente no se pueden deshacer con Ctrl + Z. ¡Guarde una copia de seguridad del libro antes de ejecutar el código y solo ejecute macros de fuentes en las que confíe!
Guía paso a paso
-
Presione Alt + F11 para abrir el editor de VBA.
-
Haga clic en Insertar > Módulo para crear un nuevo módulo.
-
Pegue el siguiente código VBA en el módulo:
Sub InsertPageBreaksEveryNRows() Dim ws As Worksheet Dim intervalRows As Long Dim lastRow As Long Dim rowIndex As Long Set ws = ActiveSheet intervalRows = 10 ' Cambie este valor a su intervalo deseado lastRow = ws.Cells(ws.Rows.Count, "A").End(xlUp).Row For rowIndex = intervalRows + 1 To lastRow Step intervalRows If Not HasHorizontalPageBreak(ws, rowIndex) Then ws.HPageBreaks.Add Before:=ws.Rows(rowIndex) End If Next rowIndex End Sub Private Function HasHorizontalPageBreak(ws As Worksheet, breakRow As Long) As Boolean Dim pb As HPageBreak HasHorizontalPageBreak = False For Each pb In ws.HPageBreaks If pb.Location.Row = breakRow Then HasHorizontalPageBreak = True Exit Function End If Next pb End Function -
Cambie
intervalRows = 10por el número de filas de la hoja de cálculo que desea entre los saltos de página. -
Presione F5 para ejecutar la macro.
Consejos importantes:
- La macro asume que la columna A contiene datos para determinar la última fila. Si sus datos comienzan en una columna diferente, cambie "A" por la letra de columna adecuada.
- La macro no elimina los saltos de página existentes. Si desea restablecer todos los saltos antes de insertar otros nuevos, agregue
ActiveSheet.ResetAllPageBreaksal principio de la macro. - Excel permite hasta 1,026 saltos de página horizontales y verticales en una hoja de cálculo. Los intervalos muy pequeños en hojas de cálculo extremadamente grandes pueden exceder este límite.
- Para mantener la macro en el libro, guarde el archivo como Libro de Excel habilitado para macros (.xlsm).
Ventajas y limitaciones
| Ventajas | Limitaciones |
|---|---|
| Automatiza la inserción repetida de saltos de página | Requiere conocimientos de VBA |
| Admite intervalos de fila personalizados | Solo funciona en la aplicación de escritorio de Excel |
¿Necesita eliminar los saltos de página existentes? Consulte Cómo eliminar saltos de página en Excel.
Agregar saltos de página a múltiples archivos de Excel con C#
Ideal para: Desarrolladores o usuarios avanzados que necesitan insertar saltos de página por lotes en múltiples archivos de Excel o automatizar la generación de informes de Excel dentro de software empresarial sin interactuar con la interfaz gráfica de usuario de Microsoft Excel.
Si bien VBA es excelente para la automatización de escritorio, los flujos de trabajo de automatización corporativa a menudo requieren procesar documentos de Excel del lado del servidor. En el ecosistema .NET, los desarrolladores pueden utilizar bibliotecas como Free Spire.XLS for .NET para insertar saltos de página horizontales o verticales en C# sin abrir Excel.
Siga los pasos a continuación para agregar saltos de página a múltiples libros de Excel con C# y Free Spire.XLS for .NET.
Pasos
-
Instale la biblioteca requerida.
Instale la biblioteca a través del Administrador de paquetes NuGet:
Install-Package FreeSpire.XLS -
Agregue código C# para insertar saltos de página por lotes.
El siguiente ejemplo recorre múltiples archivos de Excel, inserta saltos de página horizontales y verticales, y guarda los libros procesados.
using System; using System.IO; using Spire.Xls; namespace ExcelPageBreak { internal class Program { private static void Main() { // Carpeta que contiene los archivos de Excel a procesar string inputFolder = @"C:\ExcelFiles"; // Guardar archivos procesados en una subcarpeta separada string outputFolder = Path.Combine(inputFolder, "Processed"); Directory.CreateDirectory(outputFolder); // Buscar todos los archivos .xlsx en la carpeta de entrada string[] files = Directory.GetFiles( inputFolder, "*.xlsx", SearchOption.TopDirectoryOnly ); foreach (string filePath in files) { using (Workbook workbook = new Workbook()) { // Cargar el archivo de Excel workbook.LoadFromFile(filePath); // Obtener la primera hoja de cálculo Worksheet sheet = workbook.Worksheets[0]; // Insertar un salto de página horizontal sobre la fila 10 sheet.HPageBreaks.Add(sheet.Range["A10"]); // Insertar un salto de página vertical antes de la columna D sheet.VPageBreaks.Add(sheet.Range["D1"]); // Construir la ruta del archivo de salida string outputPath = Path.Combine( outputFolder, Path.GetFileName(filePath) ); // Guardar el libro procesado workbook.SaveToFile( outputPath, FileFormat.Version2016 ); } } Console.WriteLine( $"{files.Length} libro(s) procesado(s). " + $"Los archivos se guardaron en: {outputFolder}" ); } } }
Cómo funciona el código:
El código utiliza Directory.GetFiles() para encontrar todos los archivos .xlsx en la carpeta de entrada especificada. Para cada libro, hace lo siguiente:
- Abre el archivo y selecciona la primera hoja de cálculo.
- Agrega un salto de página horizontal sobre la fila 10.
- Agrega un salto de página vertical antes de la columna D.
- Guarda el libro actualizado en una carpeta
Processedseparada.
Cambie C:\ExcelFiles por la carpeta que contiene sus libros. También puede reemplazar A10 y D1 por la fila y columna donde desea que comience cada nueva página impresa.
Notas:
- El ejemplo procesa archivos solo en la carpeta seleccionada. Para incluir archivos en sus subcarpetas, cambie
SearchOption.TopDirectoryOnlyporSearchOption.AllDirectories. - Free Spire.XLS limita los archivos .xls a 5 hojas de cálculo por libro y 200 filas por hoja de cálculo. Estos límites no se aplican a los archivos .xlsx, por lo que el ejemplo anterior procesa solo archivos .xlsx. Para libros .xls más grandes, conviértalos a .xlsx antes de procesarlos.
Ventajas y limitaciones
| Ventajas | Limitaciones |
|---|---|
| Automatiza la inserción de saltos de página para múltiples archivos de Excel | Requiere conocimientos de programación .NET |
| No requiere la instalación de Microsoft Excel | No es adecuado para ajustes manuales simples |
Comparación rápida de todos los métodos de inserción de saltos de página
| Método | Mejor caso de uso | ¿Soporte multiplataforma? | ¿Procesamiento por lotes? |
|---|---|---|---|
| Inserción manual | Conjuntos de datos pequeños y únicos | Limitado (solo escritorio) | No |
| Macro VBA | Reglas repetidas o basadas en intervalos | Limitado (solo escritorio) | Limitado |
| C# + Free Spire.XLS | Procesamiento por lotes y flujos de trabajo automatizados | Sí (.NET multiplataforma) | Sí |
¿Por qué no funcionan los saltos de página en Excel?
Si un salto de página no aparece donde se esperaba, verifique la siguiente configuración:
-
Se seleccionó la fila o columna incorrecta.
Excel inserta un salto de página horizontal sobre la fila seleccionada y un salto de página vertical a la izquierda de la columna seleccionada. Seleccione la fila o columna donde debe comenzar la siguiente página impresa. -
El salto de página no es visible en la vista actual.
Abra Vista > Vista previa de salto de página para mostrar los saltos de página automáticos y manuales directamente en la hoja de cálculo. -
La escala "Ajustar a" está anulando los saltos de página manuales.
Cuando la hoja de cálculo utiliza la opción de escala Ajustar a, es posible que Excel ignore los saltos de página manuales. Abra el cuadro de diálogo Configurar página y seleccione Ajustar a en su lugar. -
El área de impresión no incluye el contenido esperado.
Verifique Disposición de página > Área de impresión y confirme que se incluya el rango correcto. También puede borrar el área de impresión existente y establecerla nuevamente. -
La hoja de cálculo está protegida.
Una hoja de cálculo protegida puede impedir cambios en la configuración de diseño de página. Desproteja la hoja, inserte o mueva el salto de página y luego vuelva a protegerla si es necesario.
Después de realizar cambios, abra Archivo > Imprimir para verificar el diseño final de la página antes de imprimir o exportar la hoja de cálculo.
Preguntas frecuentes
P1: ¿Existe un atajo para insertar un salto de página en Excel?
R1: Excel no tiene un atajo universal para insertar saltos de página. En las versiones de Windows, puede usar Alt → P → B → I para acceder al comando Insertar salto de página. La secuencia de teclas puede variar según la versión de Excel y el idioma de visualización.
P2: ¿Puedo insertar saltos de página cada N filas?
R2: Sí. Excel no proporciona una opción integrada para insertar saltos de página a intervalos de filas fijos. Puede agregarlos manualmente uno por uno o usar VBA para automatizar el proceso.
P3: ¿Cómo elimino un salto de página en Excel?
R3: Seleccione la fila debajo de un salto horizontal o la columna a la derecha de un salto vertical, luego vaya a Disposición de página > Saltos > Eliminar salto de página. Para eliminar todos los saltos de página manuales, seleccione Restablecer todos los saltos de página. Los saltos de página automáticos no se pueden eliminar directamente.
P4: ¿Los saltos de página afectan los datos de mi hoja de cálculo?
R4: No. Los saltos de página solo controlan cómo se divide una hoja de cálculo cuando se imprime o se exporta a PDF. No cambian los valores de las celdas, las fórmulas, el formato ni la estructura de la hoja de cálculo.
Resumen
En este artículo, hemos analizado tres formas prácticas de insertar saltos de página en Excel, junto con consejos útiles para evitar problemas comunes de diseño de impresión. Elija el método que mejor se adapte a su tarea y revise el resultado final en la Vista previa de impresión antes de imprimir o exportar la hoja de cálculo a PDF.
So fügen Sie Seitenumbrüche in Excel ein: 3 praktische Methoden
Inhaltsverzeichnis
- Was sind Seitenumbrüche in Excel?
- Seitenumbruchvorschau vor dem Start öffnen
- Seitenumbruch in Excel manuell hinzufügen oder verschieben
- Seitenumbrüche automatisch alle N Zeilen mit VBA einfügen
- Seitenumbrüche in mehreren Excel-Dateien mit C# hinzufügen
- Kurzer Vergleich aller Methoden zum Einfügen von Seitenumbrüchen
- Warum funktionieren Seitenumbrüche in Excel nicht?
- Häufig gestellte Fragen (FAQs)
- Zusammenfassung
Wenn ein Excel-Arbeitsblatt mehrere Abschnitte, lange Tabellen oder viele Datenzeilen enthält, teilt Excel den Inhalt möglicherweise automatisch an ungünstigen Stellen auf. Eine Überschrift könnte am unteren Rand einer Seite erscheinen, eine Tabelle könnte mitten durchtrennt werden oder zusammengehörige Spalten könnten auf verschiedene Seiten verteilt werden. Durch das Hinzufügen von Seitenumbrüchen können Sie steuern, wo eine neue gedruckte Seite beginnt, und Berichte lesbarer gestalten.
In diesem Artikel behandeln wir 3 praktische Möglichkeiten, um Seitenumbrüche in Excel einzufügen:
- Manuelles Hinzufügen oder Verschieben eines Seitenumbruchs in Excel
- Automatisches Einfügen von Seitenumbrüchen alle N Zeilen mit VBA
- Hinzufügen von Seitenumbrüchen zu mehreren Excel-Dateien mit C#
Was sind Seitenumbrüche in Excel?
Ein Seitenumbruch markiert den Punkt, an dem eine gedruckte Seite endet und die nächste beginnt.
Seitenumbrüche wirken sich nur auf das Drucklayout aus. Sie verschieben keine Zellen, ändern keine Formeln, teilen ein Arbeitsblatt nicht in separate Blätter auf und verändern nicht die zugrunde liegenden Daten.
Excel verwendet zwei Arten von Seitenumbrüchen:
- Automatische Seitenumbrüche werden von Excel basierend auf Papiergröße, Rändern, Skalierung, Zeilenhöhe und Spaltenbreite erstellt.
- Manuelle Seitenumbrüche werden vom Benutzer eingefügt, um zu steuern, wo eine neue gedruckte Seite beginnt.
Sie können zwei Arten von manuellen Seitenumbrüchen einfügen:
- Horizontaler Seitenumbruch: Beginnt eine neue gedruckte Seite bei einer bestimmten Zeile.
- Vertikaler Seitenumbruch: Beginnt eine neue gedruckte Seite bei einer bestimmten Spalte.
Seitenumbruchvorschau vor dem Start öffnen
Die Seitenumbruchvorschau zeigt, wie Excel das Arbeitsblatt aktuell in gedruckte Seiten unterteilt. Obwohl Sie diese Ansicht nicht zwingend vor dem Einfügen eines Seitenumbruchs öffnen müssen, macht sie Seitenbegrenzungen leichter sichtbar und hilft Ihnen, das Ergebnis zu überprüfen.
So öffnen Sie die Seitenumbruchvorschau:
-
Gehen Sie im Excel-Menüband auf die Registerkarte Ansicht.
-
Wählen Sie Seitenumbruchvorschau.
Excel zeigt die Seitenbegrenzungen direkt auf dem Arbeitsblatt an.
Tipp: Gestrichelte Linien zeigen automatische Seitenumbrüche an, die von Excel erstellt wurden. Durchgezogene Linien zeigen manuelle Seitenumbrüche an, einschließlich automatischer Seitenumbrüche, die Sie manuell verschoben haben.
Seitenumbruch in Excel manuell hinzufügen oder verschieben
Am besten geeignet für: Benutzer, die das Drucklayout eines einzelnen Arbeitsblatts anpassen oder nur wenige Seitenumbrüche manuell einfügen müssen.
Einen horizontalen Seitenumbruch einfügen
- Wählen Sie die Zeile direkt unter der Stelle aus, an der die Seite geteilt werden soll (klicken Sie beispielsweise auf die Zeilennummer 10, um einen Umbruch zwischen Zeile 9 und 10 einzufügen).
- Gehen Sie auf die Registerkarte Seitenlayout.
- Klicken Sie auf Umbrüche.
- Wählen Sie Seitenumbruch einfügen.
Ergebnis: Excel fügt einen horizontalen Seitenumbruch oberhalb der ausgewählten Zeile ein.
Einen vertikalen Seitenumbruch einfügen
- Wählen Sie die Spalte direkt rechts neben der Stelle aus, an der die Teilung erfolgen soll (klicken Sie beispielsweise auf Spalte D, um einen Umbruch zwischen Spalte C und D einzufügen).
- Gehen Sie auf die Registerkarte Seitenlayout.
- Klicken Sie auf Umbrüche.
- Wählen Sie Seitenumbruch einfügen.
Ergebnis: Excel fügt den Seitenumbruch links neben der ausgewählten Spalte ein.
Einen vorhandenen Seitenumbruch verschieben
Sie können einen Seitenumbruch verschieben, ohne ihn zu löschen und neu zu erstellen:
- Stellen Sie sicher, dass Sie sich in der Seitenumbruchvorschau befinden.
- Ziehen Sie die Seitenumbruchlinie an die gewünschte Position. Wenn die Linie nicht gezogen werden kann, stellen Sie sicher, dass das Ziehen und Ablegen von Zellen in den Excel-Optionen aktiviert ist. Das Verschieben eines automatischen Seitenumbruchs wandelt diesen in einen manuellen Seitenumbruch um.
Hinweis: Bei breiten Arbeitsblättern können die Seitenausrichtung, Ränder und Skalierungseinstellungen das endgültige Drucklayout beeinflussen. Überprüfen Sie die Druckvorschau, wenn Spalten nicht wie erwartet erscheinen.
Vorteile und Einschränkungen
| Vorteile | Einschränkungen |
|---|---|
| Schnell und einfach für kleine Anpassungen | Erfordert manuelle Wiederholung für jeden Umbruch |
Seitenumbrüche automatisch alle N Zeilen mit VBA einfügen
Am besten geeignet für: Benutzer der Excel-Desktop-App, die Seitenumbrüche in regelmäßigen Zeilenabständen einfügen müssen, z. B. alle 10 Zeilen.
Excel bietet keine einfache integrierte Schaltfläche zum Einfügen von Seitenumbrüchen alle N Zeilen. Wenn Sie nur wenige Seitenumbrüche benötigen, reicht das manuelle Einfügen normalerweise aus.
Wenn ein Arbeitsblatt jedoch Hunderte oder Tausende von Zeilen enthält, wird das Hinzufügen von Seitenumbrüchen einzeln zeitaufwendig und fehleranfällig. Ein kurzes VBA-Makro kann diesen Prozess automatisieren und die gleiche Seitenumbruchregel konsistent anwenden.
⚠️ Warnung: Änderungen durch ein VBA-Makro können normalerweise nicht mit Strg + Z rückgängig gemacht werden. Speichern Sie eine Sicherungskopie der Arbeitsmappe, bevor Sie den Code ausführen, und führen Sie Makros nur aus vertrauenswürdigen Quellen aus!
Schritt-für-Schritt-Anleitung
-
Drücken Sie Alt + F11, um den VBA-Editor zu öffnen.
-
Klicken Sie auf Einfügen > Modul, um ein neues Modul zu erstellen.
-
Fügen Sie den folgenden VBA-Code in das Modul ein:
Sub InsertPageBreaksEveryNRows() Dim ws As Worksheet Dim intervalRows As Long Dim lastRow As Long Dim rowIndex As Long Set ws = ActiveSheet intervalRows = 10 ' Ändern Sie diesen Wert auf das gewünschte Intervall lastRow = ws.Cells(ws.Rows.Count, "A").End(xlUp).Row For rowIndex = intervalRows + 1 To lastRow Step intervalRows If Not HasHorizontalPageBreak(ws, rowIndex) Then ws.HPageBreaks.Add Before:=ws.Rows(rowIndex) End If Next rowIndex End Sub Private Function HasHorizontalPageBreak(ws As Worksheet, breakRow As Long) As Boolean Dim pb As HPageBreak HasHorizontalPageBreak = False For Each pb In ws.HPageBreaks If pb.Location.Row = breakRow Then HasHorizontalPageBreak = True Exit Function End If Next pb End Function -
Ändern Sie
intervalRows = 10in die Anzahl der Arbeitsblattzeilen, die Sie zwischen den Seitenumbrüchen haben möchten. -
Drücken Sie F5, um das Makro auszuführen.
Wichtige Tipps:
- Das Makro geht davon aus, dass Spalte A Daten enthält, um die letzte Zeile zu bestimmen. Wenn Ihre Daten in einer anderen Spalte beginnen, ändern Sie "A" in den entsprechenden Spaltenbuchstaben.
- Das Makro entfernt keine vorhandenen Seitenumbrüche. Wenn Sie alle Umbrüche zurücksetzen möchten, bevor Sie neue einfügen, fügen Sie
ActiveSheet.ResetAllPageBreaksam Anfang des Makros hinzu. - Excel erlaubt bis zu 1.026 horizontale und vertikale Seitenumbrüche auf einem Arbeitsblatt. Sehr kleine Intervalle auf extrem großen Arbeitsblättern können dieses Limit überschreiten.
- Um das Makro in der Arbeitsmappe zu behalten, speichern Sie die Datei als Excel-Arbeitsmappe mit Makros (.xlsm).
Vorteile und Einschränkungen
| Vorteile | Einschränkungen |
|---|---|
| Automatisiert wiederholtes Einfügen von Seitenumbrüchen | Erfordert VBA-Kenntnisse |
| Unterstützt benutzerdefinierte Zeilenintervalle | Funktioniert nur in der Excel-Desktop-App |
Müssen Sie stattdessen vorhandene Seitenumbrüche entfernen? Siehe So entfernen Sie Seitenumbrüche in Excel.
Seitenumbrüche in mehreren Excel-Dateien mit C# hinzufügen
Am besten geeignet für: Entwickler oder fortgeschrittene Benutzer, die Seitenumbrüche stapelweise in mehrere Excel-Dateien einfügen oder die Erstellung von Excel-Berichten innerhalb von Unternehmenssoftware automatisieren müssen, ohne mit der Microsoft Excel-GUI zu interagieren.
Während VBA hervorragend für die Desktop-Automatisierung geeignet ist, erfordern unternehmensweite Automatisierungs-Workflows oft die Verarbeitung von Excel-Dokumenten auf dem Server. Im .NET-Ökosystem können Entwickler Bibliotheken wie Free Spire.XLS for .NET verwenden, um horizontale oder vertikale Seitenumbrüche mit C# einzufügen, ohne Excel zu öffnen.
Befolgen Sie die unten stehenden Schritte, um mit C# und Free Spire.XLS for .NET Seitenumbrüche zu mehreren Excel-Arbeitsmappen hinzuzufügen.
Schritte
-
Installieren Sie die erforderliche Bibliothek.
Installieren Sie die Bibliothek über den NuGet Package Manager:
Install-Package FreeSpire.XLS -
Fügen Sie C#-Code zum stapelweisen Einfügen von Seitenumbrüchen hinzu.
Das folgende Beispiel durchläuft mehrere Excel-Dateien, fügt horizontale und vertikale Seitenumbrüche ein und speichert die verarbeiteten Arbeitsmappen.
using System; using System.IO; using Spire.Xls; namespace ExcelPageBreak { internal class Program { private static void Main() { // Ordner mit den zu verarbeitenden Excel-Dateien string inputFolder = @"C:\ExcelFiles"; // Speichern der verarbeiteten Dateien in einem separaten Unterordner string outputFolder = Path.Combine(inputFolder, "Processed"); Directory.CreateDirectory(outputFolder); // Alle .xlsx-Dateien im Eingabeordner finden string[] files = Directory.GetFiles( inputFolder, "*.xlsx", SearchOption.TopDirectoryOnly ); foreach (string filePath in files) { using (Workbook workbook = new Workbook()) { // Excel-Datei laden workbook.LoadFromFile(filePath); // Erstes Arbeitsblatt abrufen Worksheet sheet = workbook.Worksheets[0]; // Horizontalen Seitenumbruch oberhalb von Zeile 10 einfügen sheet.HPageBreaks.Add(sheet.Range["A10"]); // Vertikalen Seitenumbruch vor Spalte D einfügen sheet.VPageBreaks.Add(sheet.Range["D1"]); // Ausgabedateipfad erstellen string outputPath = Path.Combine( outputFolder, Path.GetFileName(filePath) ); // Verarbeitete Arbeitsmappe speichern workbook.SaveToFile( outputPath, FileFormat.Version2016 ); } } Console.WriteLine( $"{files.Length} Arbeitsmappe(n) verarbeitet. " + $"Dateien wurden gespeichert unter: {outputFolder}" ); } } }
Wie der Code funktioniert:
Der Code verwendet Directory.GetFiles(), um alle .xlsx-Dateien im angegebenen Eingabeordner zu finden. Für jede Arbeitsmappe:
- Öffnet er die Datei und wählt das erste Arbeitsblatt aus.
- Fügt einen horizontalen Seitenumbruch oberhalb von Zeile 10 ein.
- Fügt einen vertikalen Seitenumbruch vor Spalte D ein.
- Speichert die aktualisierte Arbeitsmappe in einem separaten
Processed-Ordner.
Ändern Sie C:\ExcelFiles in den Ordner, der Ihre Arbeitsmappen enthält. Sie können auch A10 und D1 durch die Zeile und Spalte ersetzen, an der jede neue gedruckte Seite beginnen soll.
Hinweise:
- Das Beispiel verarbeitet Dateien nur im ausgewählten Ordner. Um Dateien in Unterordnern einzubeziehen, ändern Sie
SearchOption.TopDirectoryOnlyinSearchOption.AllDirectories. - Free Spire.XLS begrenzt .xls-Dateien auf 5 Arbeitsblätter pro Arbeitsmappe und 200 Zeilen pro Arbeitsblatt. Diese Einschränkungen gelten nicht für .xlsx-Dateien, daher verarbeitet das obige Beispiel nur .xlsx-Dateien. Für größere .xls-Arbeitsmappen konvertieren Sie diese vor der Verarbeitung in .xlsx.
Vorteile und Einschränkungen
| Vorteile | Einschränkungen |
|---|---|
| Automatisiert das Einfügen von Seitenumbrüchen für mehrere Excel-Dateien | Erfordert .NET-Programmierkenntnisse |
| Erfordert keine Microsoft Excel-Installation | Nicht für einfache manuelle Anpassungen geeignet |
Kurzer Vergleich aller Methoden zum Einfügen von Seitenumbrüchen
| Methode | Bester Anwendungsfall | Plattformübergreifend? | Stapelverarbeitung? |
|---|---|---|---|
| Manuelles Einfügen | Einmalige, kleine Datensätze | Begrenzt (nur Desktop) | Nein |
| VBA-Makro | Wiederholte oder intervallbasierte Regeln | Begrenzt (nur Desktop) | Begrenzt |
| C# + Free Spire.XLS | Stapelverarbeitung & automatisierte Workflows | Ja (Plattformübergreifendes .NET) | Ja |
Warum funktionieren Seitenumbrüche in Excel nicht?
Wenn ein Seitenumbruch nicht wie erwartet erscheint, überprüfen Sie die folgenden Einstellungen:
-
Die falsche Zeile oder Spalte ist ausgewählt.
Excel fügt einen horizontalen Seitenumbruch oberhalb der ausgewählten Zeile und einen vertikalen Seitenumbruch links neben der ausgewählten Spalte ein. Wählen Sie die Zeile oder Spalte aus, an der die nächste gedruckte Seite beginnen soll. -
Der Seitenumbruch ist in der aktuellen Ansicht nicht sichtbar.
Öffnen Sie Ansicht > Seitenumbruchvorschau, um automatische und manuelle Seitenumbrüche direkt auf dem Arbeitsblatt anzuzeigen. -
Die Skalierung "Anpassen" überschreibt manuelle Seitenumbrüche.
Wenn das Arbeitsblatt die Skalierungsoption Anpassen verwendet, ignoriert Excel möglicherweise manuelle Seitenumbrüche. Öffnen Sie das Dialogfeld "Seite einrichten" und wählen Sie stattdessen Anpassen an. -
Der Druckbereich enthält nicht den erwarteten Inhalt.
Überprüfen Sie Seitenlayout > Druckbereich und bestätigen Sie, dass der richtige Bereich enthalten ist. Sie können auch den vorhandenen Druckbereich löschen und erneut festlegen. -
Das Arbeitsblatt ist geschützt.
Ein geschütztes Arbeitsblatt kann Änderungen an den Seitenlayouteinstellungen verhindern. Heben Sie den Blattschutz auf, fügen Sie den Seitenumbruch ein oder verschieben Sie ihn, und schützen Sie das Blatt bei Bedarf anschließend wieder.
Öffnen Sie nach den Änderungen Datei > Drucken, um das endgültige Seitenlayout zu überprüfen, bevor Sie das Arbeitsblatt drucken oder exportieren.
Häufig gestellte Fragen (FAQs)
F1: Gibt es eine Tastenkombination zum Einfügen eines Seitenumbruchs in Excel?
A1: Excel hat keine universelle Tastenkombination zum Einfügen von Seitenumbrüchen. In Windows-Versionen können Sie Alt → P → B → I verwenden, um auf den Befehl "Seitenumbruch einfügen" zuzugreifen. Die Tastenfolge kann je nach Excel-Version und Anzeigesprache variieren.
F2: Kann ich alle N Zeilen Seitenumbrüche einfügen?
A2: Ja. Excel bietet keine integrierte Option zum Einfügen von Seitenumbrüchen in festen Zeilenabständen. Sie können diese manuell einzeln hinzufügen oder VBA verwenden, um den Prozess zu automatisieren.
F3: Wie entferne ich einen Seitenumbruch in Excel?
A3: Wählen Sie die Zeile unter einem horizontalen Umbruch oder die Spalte rechts neben einem vertikalen Umbruch aus und gehen Sie dann zu Seitenlayout > Umbrüche > Seitenumbruch entfernen. Um alle manuellen Seitenumbrüche zu entfernen, wählen Sie Alle Seitenumbrüche zurücksetzen. Automatische Seitenumbrüche können nicht direkt entfernt werden.
F4: Beeinflussen Seitenumbrüche meine Arbeitsblattdaten?
A4: Nein. Seitenumbrüche steuern nur, wie ein Arbeitsblatt beim Drucken oder Exportieren in PDF unterteilt wird. Sie ändern keine Zellwerte, Formeln, Formatierungen oder die Struktur des Arbeitsblatts.
Zusammenfassung
In diesem Artikel haben wir drei praktische Möglichkeiten zum Einfügen von Seitenumbrüchen in Excel sowie nützliche Tipps zur Vermeidung häufiger Probleme beim Drucklayout besprochen. Wählen Sie die Methode, die am besten zu Ihrer Aufgabe passt, und überprüfen Sie das Endergebnis in der Druckvorschau, bevor Sie das Arbeitsblatt drucken oder als PDF exportieren.
Как вставить разрывы страниц в Excel: 3 практических способа
Содержание
- Что такое разрывы страниц в Excel
- Открытие режима «Страничный режим» перед началом работы
- Добавление или перемещение разрыва страницы в Excel вручную
- Автоматическая вставка разрывов страниц каждые N строк с помощью VBA
- Добавление разрывов страниц в несколько файлов Excel с помощью C#
- Краткое сравнение всех методов вставки разрывов страниц
- Почему разрывы страниц не работают в Excel
- Часто задаваемые вопросы
- Заключение
Когда рабочий лист Excel содержит несколько разделов, длинные таблицы или множество строк данных, Excel может автоматически разбивать содержимое по страницам в неудобных местах. Заголовок может оказаться внизу страницы, таблица может быть разделена посередине, или связанные столбцы могут оказаться на разных страницах. Добавление разрывов страниц позволяет контролировать начало новой печатной страницы и упрощает чтение отчетов.
В этой статье мы рассмотрим 3 практических способа вставки разрывов страниц в Excel:
- Добавление или перемещение разрыва страницы в Excel вручную
- Вставка разрывов страниц каждые N строк с помощью VBA
- Добавление разрывов страниц в несколько файлов Excel с помощью C#
Что такое разрывы страниц в Excel?
Разрыв страницы отмечает точку, где заканчивается одна печатная страница и начинается следующая.
Разрывы страниц влияют только на макет печати. Они не перемещают ячейки, не меняют формулы, не разделяют рабочий лист на отдельные листы и не изменяют исходные данные.
Excel использует два вида разрывов страниц:
- Автоматические разрывы страниц создаются Excel на основе размера бумаги, полей, масштабирования, высоты строк и ширины столбцов.
- Ручные разрывы страниц вставляются пользователем для управления началом новой печатной страницы.
Вы можете вставить два типа ручных разрывов страниц:
- Горизонтальный разрыв страницы: начинает новую печатную страницу с определенной строки.
- Вертикальный разрыв страницы: начинает новую печатную страницу с определенного столбца.
Открытие режима «Страничный режим» перед началом работы
«Страничный режим» (Page Break Preview) показывает, как Excel в данный момент делит рабочий лист на печатные страницы. Хотя вам не обязательно открывать этот вид перед вставкой разрыва страницы, он позволяет лучше видеть границы страниц и проверять результат.
Чтобы открыть «Страничный режим»:
-
Перейдите на вкладку Вид на ленте Excel.
-
Выберите Страничный режим.
Excel отобразит границы страниц прямо на рабочем листе.
Совет: Пунктирные линии обозначают автоматические разрывы страниц, созданные Excel. Сплошные линии обозначают ручные разрывы страниц, включая автоматические разрывы, которые вы переместили вручную.
Добавление или перемещение разрыва страницы в Excel вручную
Лучше всего подходит для: пользователей, которым нужно настроить макет печати одного рабочего листа или вставить всего несколько разрывов страниц вручную.
Вставка горизонтального разрыва страницы
- Выберите строку непосредственно под тем местом, где вы хотите сделать разрыв (например, нажмите на номер строки 10, чтобы вставить разрыв между строками 9 и 10).
- Перейдите на вкладку Разметка страницы.
- Нажмите Разрывы.
- Выберите Вставить разрыв страницы.
Результат: Excel вставляет горизонтальный разрыв страницы над выбранной строкой.
Вставка вертикального разрыва страницы
- Выберите столбец непосредственно справа от места, где вы хотите сделать разрыв (например, нажмите на столбец D, чтобы вставить разрыв между столбцами C и D).
- Перейдите на вкладку Разметка страницы.
- Нажмите Разрывы.
- Выберите Вставить разрыв страницы.
Результат: Excel вставляет разрыв страницы слева от выбранного столбца.
Перемещение существующего разрыва страницы
Вы можете переместить разрыв страницы, не удаляя и не создавая его заново:
- Убедитесь, что вы находитесь в режиме Страничный режим.
- Перетащите линию разрыва страницы в нужное положение. Если линию нельзя перетащить, убедитесь, что в параметрах Excel включена функция перетаскивания ячеек. Перемещение автоматического разрыва страницы превращает его в ручной.
Примечание: Для широких рабочих листов ориентация страницы, поля и параметры масштабирования могут влиять на итоговый макет печати. Проверьте предварительный просмотр печати, если столбцы отображаются не так, как ожидалось.
Преимущества и ограничения
| Преимущества | Ограничения |
|---|---|
| Быстро и просто для небольших корректировок | Требует ручного повторения для каждого разрыва |
Автоматическая вставка разрывов страниц каждые N строк с помощью VBA
Лучше всего подходит для: пользователей настольного приложения Excel, которым нужно вставлять разрывы страниц через равные интервалы, например, каждые 10 строк.
В Excel нет простой встроенной кнопки для вставки разрывов страниц каждые N строк. Если вам нужно всего несколько разрывов, обычно достаточно ручной вставки.
Однако, когда рабочий лист содержит сотни или тысячи строк, добавление разрывов вручную становится трудоемким и чревато ошибками. Небольшой макрос VBA может автоматизировать этот процесс и последовательно применять правило разрыва страницы.
⚠️ Внимание: Изменения, внесенные макросом VBA, обычно нельзя отменить с помощью Ctrl + Z. Сохраните резервную копию книги перед запуском кода и запускайте макросы только из надежных источников!
Пошаговое руководство
-
Нажмите Alt + F11, чтобы открыть редактор VBA.
-
Нажмите Вставка > Модуль, чтобы создать новый модуль.
-
Вставьте следующий код VBA в модуль:
Sub InsertPageBreaksEveryNRows() Dim ws As Worksheet Dim intervalRows As Long Dim lastRow As Long Dim rowIndex As Long Set ws = ActiveSheet intervalRows = 10 ' Измените это значение на нужный интервал lastRow = ws.Cells(ws.Rows.Count, "A").End(xlUp).Row For rowIndex = intervalRows + 1 To lastRow Step intervalRows If Not HasHorizontalPageBreak(ws, rowIndex) Then ws.HPageBreaks.Add Before:=ws.Rows(rowIndex) End If Next rowIndex End Sub Private Function HasHorizontalPageBreak(ws As Worksheet, breakRow As Long) As Boolean Dim pb As HPageBreak HasHorizontalPageBreak = False For Each pb In ws.HPageBreaks If pb.Location.Row = breakRow Then HasHorizontalPageBreak = True Exit Function End If Next pb End Function -
Измените
intervalRows = 10на количество строк, которое должно быть между разрывами страниц. -
Нажмите F5 для запуска макроса.
Важные советы:
- Макрос предполагает, что столбец A содержит данные для определения последней строки. Если ваши данные начинаются в другом столбце, замените "A" на соответствующую букву столбца.
- Макрос не удаляет существующие разрывы страниц. Если вы хотите сбросить все разрывы перед вставкой новых, добавьте
ActiveSheet.ResetAllPageBreaksв начало макроса. - Excel позволяет разместить до 1026 горизонтальных и вертикальных разрывов страниц на одном листе. Слишком маленькие интервалы на очень больших листах могут превысить этот лимит.
- Чтобы сохранить макрос в книге, сохраните файл как книгу Excel с поддержкой макросов (.xlsm).
Преимущества и ограничения
| Преимущества | Ограничения |
|---|---|
| Автоматизирует повторную вставку разрывов | Требует знаний VBA |
| Поддерживает пользовательские интервалы строк | Работает только в настольном приложении Excel |
Нужно удалить существующие разрывы страниц? См. статью Как удалить разрывы страниц в Excel.
Добавление разрывов страниц в несколько файлов Excel с помощью C#
Лучше всего подходит для: разработчиков или продвинутых пользователей, которым нужно пакетно вставлять разрывы страниц в несколько файлов Excel или автоматизировать создание отчетов Excel в корпоративном ПО без взаимодействия с графическим интерфейсом Microsoft Excel.
Хотя VBA отлично подходит для автоматизации на рабочем столе, корпоративные рабочие процессы часто требуют обработки документов Excel на стороне сервера. В экосистеме .NET разработчики могут использовать библиотеки, такие как Free Spire.XLS for .NET, чтобы вставлять горизонтальные или вертикальные разрывы страниц с помощью C# без открытия Excel.
Выполните следующие действия, чтобы добавить разрывы страниц в несколько книг Excel с помощью C# и Free Spire.XLS for .NET.
Шаги
-
Установите необходимую библиотеку.
Установите библиотеку через диспетчер пакетов NuGet:
Install-Package FreeSpire.XLS -
Добавьте код C# для пакетной вставки разрывов страниц.
Следующий пример проходит по нескольким файлам Excel, вставляет горизонтальные и вертикальные разрывы страниц и сохраняет обработанные книги.
using System; using System.IO; using Spire.Xls; namespace ExcelPageBreak { internal class Program { private static void Main() { // Папка с файлами Excel для обработки string inputFolder = @"C:\ExcelFiles"; // Сохранение обработанных файлов в отдельную подпапку string outputFolder = Path.Combine(inputFolder, "Processed"); Directory.CreateDirectory(outputFolder); // Поиск всех файлов .xlsx в папке string[] files = Directory.GetFiles( inputFolder, "*.xlsx", SearchOption.TopDirectoryOnly ); foreach (string filePath in files) { using (Workbook workbook = new Workbook()) { // Загрузка файла Excel workbook.LoadFromFile(filePath); // Получение первого рабочего листа Worksheet sheet = workbook.Worksheets[0]; // Вставка горизонтального разрыва страницы над строкой 10 sheet.HPageBreaks.Add(sheet.Range["A10"]); // Вставка вертикального разрыва страницы перед столбцом D sheet.VPageBreaks.Add(sheet.Range["D1"]); // Формирование пути к выходному файлу string outputPath = Path.Combine( outputFolder, Path.GetFileName(filePath) ); // Сохранение обработанной книги workbook.SaveToFile( outputPath, FileFormat.Version2016 ); } } Console.WriteLine( $"Обработано книг: {files.Length}. " + $"Файлы сохранены в: {outputFolder}" ); } } }
Как работает код:
Код использует Directory.GetFiles() для поиска всех файлов .xlsx в указанной папке. Для каждой книги он:
- Открывает файл и выбирает первый рабочий лист.
- Добавляет горизонтальный разрыв страницы над строкой 10.
- Добавляет вертикальный разрыв страницы перед столбцом D.
- Сохраняет обновленную книгу в отдельную папку
Processed.
Замените C:\ExcelFiles на папку, содержащую ваши книги. Вы также можете заменить A10 и D1 на строку и столбец, где должна начинаться каждая новая печатная страница.
Примечания:
- Пример обрабатывает файлы только в выбранной папке. Чтобы включить файлы в подпапках, измените
SearchOption.TopDirectoryOnlyнаSearchOption.AllDirectories. - Free Spire.XLS ограничивает файлы .xls 5 рабочими листами в книге и 200 строками на листе. Эти ограничения не распространяются на файлы .xlsx, поэтому приведенный выше пример обрабатывает только файлы .xlsx. Для больших книг .xls преобразуйте их в .xlsx перед обработкой.
Преимущества и ограничения
| Преимущества | Ограничения |
|---|---|
| Автоматизирует вставку разрывов для множества файлов | Требует знаний программирования на .NET |
| Не требует установки Microsoft Excel | Не подходит для простых ручных корректировок |
Краткое сравнение всех методов вставки разрывов страниц
| Метод | Лучший сценарий использования | Кроссплатформенность? | Пакетная обработка? |
|---|---|---|---|
| Ручная вставка | Разовые задачи, небольшие наборы данных | Ограниченно (только настольный ПК) | Нет |
| Макрос VBA | Повторяющиеся или основанные на интервалах правила | Ограниченно (только настольный ПК) | Ограниченно |
| C# + Free Spire.XLS | Пакетная обработка и автоматизированные рабочие процессы | Да (кроссплатформенный .NET) | Да |
Почему разрывы страниц не работают в Excel?
Если разрыв страницы не появляется там, где ожидалось, проверьте следующие параметры:
-
Выбрана не та строка или столбец.
Excel вставляет горизонтальный разрыв страницы над выбранной строкой и вертикальный разрыв — слева от выбранного столбца. Выберите строку или столбец, с которых должна начинаться следующая печатная страница. -
Разрыв страницы не виден в текущем режиме.
Откройте Вид > Страничный режим, чтобы отобразить автоматические и ручные разрывы страниц прямо на рабочем листе. -
Масштабирование «Вписать» переопределяет ручные разрывы.
Когда рабочий лист использует параметр масштабирования Вписать, Excel может игнорировать ручные разрывы страниц. Откройте диалоговое окно «Параметры страницы» и выберите Установить масштаб. -
Область печати не включает ожидаемое содержимое.
Проверьте Разметка страницы > Область печати и убедитесь, что включен правильный диапазон. Вы также можете очистить существующую область печати и задать ее заново. -
Рабочий лист защищен.
Защищенный рабочий лист может препятствовать изменению параметров макета страницы. Снимите защиту с листа, вставьте или переместите разрыв страницы, а затем при необходимости защитите его снова.
После внесения изменений откройте Файл > Печать, чтобы проверить итоговый макет страницы перед печатью или экспортом рабочего листа.
Часто задаваемые вопросы
В1: Есть ли сочетание клавиш для вставки разрыва страницы в Excel?
О1: В Excel нет универсального сочетания клавиш для вставки разрывов страниц. В версиях для Windows вы можете использовать Alt → P → B → I для доступа к команде «Вставить разрыв страницы». Последовательность клавиш может отличаться в зависимости от версии Excel и языка интерфейса.
В2: Можно ли вставлять разрывы страниц каждые N строк?
О2: Да. В Excel нет встроенной опции для вставки разрывов страниц через фиксированные интервалы строк. Вы можете добавлять их вручную по одному или использовать VBA для автоматизации процесса.
В3: Как удалить разрыв страницы в Excel?
О3: Выберите строку под горизонтальным разрывом или столбец справа от вертикального разрыва, затем перейдите в Разметка страницы > Разрывы > Удалить разрыв страницы. Чтобы удалить все ручные разрывы страниц, выберите Сбросить все разрывы страниц. Автоматические разрывы страниц удалить напрямую нельзя.
В4: Влияют ли разрывы страниц на данные моего рабочего листа?
О4: Нет. Разрывы страниц управляют только тем, как рабочий лист делится при печати или экспорте в PDF. Они не меняют значения ячеек, формулы, форматирование или структуру рабочего листа.
Заключение
В этой статье мы обсудили три практических способа вставки разрывов страниц в Excel, а также полезные советы по предотвращению распространенных проблем с макетом печати. Выберите метод, который лучше всего соответствует вашей задаче, и проверьте итоговый результат в предварительном просмотре печати перед печатью или экспортом рабочего листа в PDF.
Como adicionar uma marca d'água no PowerPoint (guia detalhado)
Índice

Ao criar apresentações, adicionar marcas d'água, como um logotipo da empresa, slogan ou um rótulo de "CONFIDENCIAL", é uma maneira eficaz de manter um design consistente e indicar a propriedade do documento. No entanto, como o PowerPoint não possui um botão de marca d'água integrado de um clique, muitos usuários não sabem como adicionar uma marca d'água em apresentações do PowerPoint.
Este guia orienta você através de várias maneiras práticas de adicionar marcas d'água no PowerPoint, desde soluções manuais do Microsoft PowerPoint até processamento em lote com automação em Python, ajudando você a criar apresentações seguras e profissionais facilmente.
- Inserir marca d'água no PowerPoint via Slide Mestre
- Colocar marca d'água no PPT via código no Slide Mestre
- Adicionar uma marca d'água em slides do PowerPoint individualmente
- Melhores práticas
- Perguntas frequentes (FAQs)
Como inserir marca d'água no PowerPoint via Slide Mestre
Como o MS PowerPoint não possui uma ferramenta de marca d'água, a maneira mais eficaz é adicionar manualmente marcas d'água de texto ou imagem diretamente no Slide Mestre. Isso aplica a marca d'água a cada slide automaticamente, economizando tempo e mantendo sua formatação consistente em toda a apresentação.
Guia passo a passo
- Passo 1: Abra sua apresentação e navegue até Exibir > Slide Mestre na faixa de opções superior.
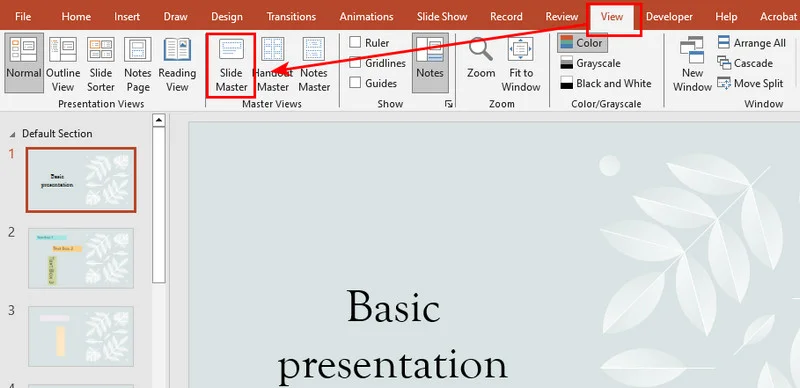
- Passo 2: Role até o topo do painel de miniaturas à esquerda e clique no slide mestre principal (a miniatura maior, no topo).
- Passo 3: Vá para a guia Inserir. Escolha Caixa de Texto para uma marca d'água de texto (por exemplo, "CONFIDENCIAL") ou clique em Imagens para carregar um logotipo PNG de baixa opacidade.
- Passo 4: Clique com o botão direito na sua imagem ou texto inserido e selecione Enviar para trás. Isso mantém sua marca d'água abaixo dos dados principais da apresentação.
- Passo 5: Clique em Fechar Modo de Exibição Mestre na guia Slide Mestre para retornar ao modo de edição normal.
Embora essa abordagem manual seja perfeita para tarefas de design únicas, por ser altamente visual e não exigir conhecimento técnico, ela se torna ineficiente quando se trata de várias apresentações. Depender de trabalho manual repetitivo deixa muito espaço para erro humano. Para lidar com a formatação de documentos em larga escala de forma eficaz, devemos recorrer à automação programática.
Como colocar marca d'água no PPT via código no Slide Mestre
Ao lidar com um grande lote de arquivos do PowerPoint, automatizar o fluxo de trabalho com código é a escolha mais eficiente. Nesta seção, demonstraremos como adicionar automaticamente marcas d'água em apresentações do PowerPoint usando o Free Spire.Presentation for Python. É uma biblioteca gratuita e independente que permite aos usuários criar e editar apresentações sem a necessidade de ter o Microsoft PowerPoint instalado.
Com a ajuda do Free Spire.Presentation, ainda podemos colocar marcas d'água no PPT inserindo uma imagem ou texto no Slide Mestre para aplicar a marca d'água em toda a apresentação.
Aqui está o exemplo de código:
from spire.presentation.common import *
from spire.presentation import *
# Inicializar e carregar o arquivo PPT
presentation = Presentation()
presentation.LoadFromFile("/input/pre1.pptx")
# Obter o slide mestre do primeiro slide
master = presentation.Masters[0]
# Calcular as coordenadas para centralizar a imagem da marca d'água
img_width = 350.0
img_height = 110.0
left = (presentation.SlideSize.Size.Width - img_width) / 2
top = (presentation.SlideSize.Size.Height - img_height) / 2
# Definir as coordenadas usando a classe RectangleF
rect = RectangleF(left, top, img_width, img_height)
# Adicionar a forma da imagem ao slide mestre como uma marca d'água
image_shape = master.Shapes.AppendEmbedImageByPath(ShapeType.Rectangle, "/Logo1.png", rect)
# Otimizar a aparência e enviar a forma para o plano de fundo
image_shape.Line.FillType = FillFormatType.none
image_shape.SetShapeArrange(ShapeArrange.SendToBack)
# Salvar a apresentação
presentation.SaveToFile("/output/MasterImageWatermark.pptx", FileFormat.Pptx2010)
presentation.Dispose()
Aqui está a prévia da apresentação do PowerPoint resultante:

Como visto nas miniaturas à esquerda, a mesma marca d'água de imagem agora é aplicada em todos os slides.
Como adicionar uma marca d'água em slides do PowerPoint individualmente
Embora criar marcas d'água no Slide Mestre seja ideal para proteger o documento completo, certos cenários exigem uma maneira mais precisa. Por exemplo, você pode querer carimbar uma marca d'água de texto "CONFIDENCIAL" apenas em slides de conteúdo específicos, mantendo a página de capa e o slide de encerramento limpos.
Adicionar uma marca d'água a um slide específico é praticamente o mesmo que o método do slide mestre. Você ainda insere formas retangulares e adiciona texto ou imagens. A única diferença é que você usa a propriedade presentation.Slides[index] para direcionar o slide específico em vez do modelo global.
Veja como aplicar marcas d'água de texto e imagem ao 8º slide:
from spire.presentation.common import *
from spire.presentation import *
# Inicializar e carregar o arquivo PPT
presentation = Presentation()
presentation.LoadFromFile("/input/pre1.pptx")
# Obter dimensões da apresentação e direcionar o 8º slide
slide_size = presentation.SlideSize.Size
first_slide = presentation.Slides[7]
# Carregar o fluxo do arquivo de imagem
stream = Stream("/Logo1.png")
image = presentation.Images.AppendStream(stream)
stream.Close()
# Obter a largura e altura originais da imagem
img_width = float(image.Width)
img_height = float(image.Height)
# Calcular as coordenadas para centralizar a imagem e definir o retângulo delimitador
img_left = (slide_size.Width - img_width) / 2
img_top = (slide_size.Height - img_height) / 2
img_rect = RectangleF(img_left, img_top, img_width, img_height)
# Adicionar uma forma de retângulo e preenchê-la com a imagem
img_shape = first_slide.Shapes.AppendShape(ShapeType.Rectangle, img_rect)
img_shape.Line.FillType = FillFormatType.none
img_shape.Locking.SelectionProtection = True # Habilitar bloqueio de seleção para evitar modificação acidental
img_shape.Fill.FillType = FillFormatType.Picture
img_shape.Fill.PictureFill.FillType = PictureFillType.Stretch
img_shape.Fill.PictureFill.Picture.EmbedImage = image
# Definir a largura, altura e coordenadas de centralização para a marca d'água de texto
txt_width = 350.0
txt_height = 110.0
txt_left = (slide_size.Width - txt_width) / 2
txt_top = (slide_size.Height - txt_height) / 2
txt_rect = RectangleF(txt_left, txt_top, txt_width, txt_height)
# Adicionar um contêiner de forma de retângulo para o texto
txt_shape = first_slide.Shapes.AppendShape(ShapeType.Rectangle, txt_rect)
txt_shape.Fill.FillType = FillFormatType.none
txt_shape.ShapeStyle.LineColor.Color = Color.get_Transparent()
txt_shape.Line.FillType = FillFormatType.none
txt_shape.Rotation = -35 # Rotacionar o texto em -35 graus
txt_shape.Locking.SelectionProtection = True # Habilitar bloqueio de seleção para evitar modificação acidental
# Configurar o conteúdo e a formatação do texto da marca d'água
txt_shape.TextFrame.Text = "CONFIDENCIAL"
text_range = txt_shape.TextFrame.TextRange
text_range.Fill.FillType = FillFormatType.Solid
text_range.Fill.SolidColor.Color = Color.FromArgb(120, Color.get_Black().R, Color.get_HotPink().G, Color.get_HotPink().B)
text_range.FontHeight = 45
text_range.LatinFont = TextFont("Times New Roman")
# Enviar as formas de imagem e texto para a camada de fundo para evitar bloquear o conteúdo
img_shape.SetShapeArrange(ShapeArrange.SendToBack)
txt_shape.SetShapeArrange(ShapeArrange.SendToBack)
# Salvar o arquivo de apresentação
presentation.SaveToFile("/output/WatermarkinSpecificSlide.pptx", FileFormat.Pptx2013)
presentation.Dispose()

O truque do bloqueio de seleção
Como essas formas são adicionadas diretamente na tela principal do slide em vez do Slide Mestre, os usuários poderiam tecnicamente clicar e movê-las. Para evitar isso, definir shape.Locking.SelectionProtection = True em ambas as formas de imagem e texto atua como uma proteção adicional. Isso ajuda a evitar edições acidentais.
Você pode gostar: 5 maneiras eficazes de proteger arquivos do PowerPoint com senha
Melhores práticas
Antes de executar scripts ou compartilhar apresentações do PowerPoint, tenha em mente estes princípios de design para manter sua apresentação limpa e fácil de ler:
- A transparência é fundamental: Recomenda-se um nível de opacidade de 15% a 20%. A marca d'água não deve cobrir o texto principal.
- Rotação estratégica: Incline seu texto em um ângulo de -35° ou -45°. Blocos de texto diagonais tornam as capturas de tela não autorizadas por smartphone ou vazamentos de fotos muito mais difíceis de recortar.
- Seleção de cores: Sugerem-se cores neutras. Use cinzas claros para fundos de slide claros e tons de ardósia profundos para temas de apresentação escuros. Evite cores vibrantes e de alto contraste, como vermelho puro ou preto.
Conclusão
Adicionar marcas d'água às suas apresentações do PowerPoint protege sua marca e protege dados confidenciais. Para um arquivo único e rápido, o modo de exibição Slide Mestre funciona perfeitamente. No entanto, a automação em Python é mais adequada para processamento em larga escala. Ao utilizar o Free Spire.Presentation for Python, você pode facilmente criar scripts tanto para atualizações globais do mestre quanto para bloqueios específicos de página, sem precisar do Microsoft PowerPoint instalado. Escolha o método que atende à sua necessidade atual e comece a proteger suas apresentações hoje mesmo.
Perguntas frequentes (FAQs) sobre como adicionar marcas d'água ao PPT
Q1: Os usuários podem remover a marca d'água gerada pelo Python?
Não durante a edição normal. Uma marca d'água adicionada via Slide Mestre não é clicável nativamente na exibição padrão. No entanto, os usuários ainda podem abrir o modo de exibição Slide Mestre para movê-la ou excluí-la manualmente. Se você deseja segurança absoluta e não removível, exporte a apresentação para um PDF.
Q2: Por que minha imagem de marca d'água parece pixelada?
A resolução da imagem de origem é muito baixa. Seja adicionando manualmente ou via código, sempre use um arquivo PNG de alta resolução com fundo transparente.
Q3: A marca d'água permanecerá intacta ao imprimir os slides?
Sim. As marcas d'água são incorporadas diretamente no slide mestre ou nas coordenadas da tela bloqueada. Elas geralmente preservarão a opacidade e a posição ao imprimir e exportar.
Leia também:
PowerPoint에 워터마크를 추가하는 방법 (상세 가이드)
프레젠테이션을 만들 때 회사 로고, 슬로건 또는 "대외비(CONFIDENTIAL)" 라벨과 같은 워터마크를 추가하는 것은 일관된 디자인을 유지하고 문서의 소유권을 표시하는 효과적인 방법입니다. 하지만 PowerPoint에는 워터마크를 한 번에 추가하는 내장 버튼이 없기 때문에, 많은 사용자가 PowerPoint에 워터마크를 추가하는 방법을 궁금해합니다.
이 가이드에서는 수동으로 작업하는 방법부터 Python 자동화를 통한 일괄 처리까지, PowerPoint에 워터마크를 추가하는 몇 가지 실용적인 방법을 안내하여 안전하고 전문적인 프레젠테이션을 쉽게 만들 수 있도록 도와드립니다.
- 슬라이드 마스터를 통해 PowerPoint에 워터마크 삽입하기
- 슬라이드 마스터 코드를 통해 PPT에 워터마크 넣기
- PowerPoint 슬라이드에 개별적으로 워터마크 추가하기
- 모범 사례
- 자주 묻는 질문(FAQ)
슬라이드 마스터를 통해 PowerPoint에 워터마크 삽입하는 방법
MS PowerPoint에는 워터마크 도구가 없으므로, 가장 효과적인 방법은 슬라이드 마스터에 텍스트나 이미지 워터마크를 직접 수동으로 추가하는 것입니다. 이렇게 하면 모든 슬라이드에 워터마크가 자동으로 적용되어 시간을 절약하고 프레젠테이션 전체의 서식을 일관되게 유지할 수 있습니다.
단계별 가이드
- 1단계: 프레젠테이션을 열고 상단 리본 메뉴에서 보기 > 슬라이드 마스터로 이동합니다.
- 2단계: 왼쪽 썸네일 창의 맨 위로 스크롤하여 기본 슬라이드 마스터(가장 크고 맨 위에 있는 썸네일)를 클릭합니다.
- 3단계: 삽입 탭으로 이동합니다. 텍스트 워터마크(예: "대외비")를 원하면 텍스트 상자를 선택하고, 투명도가 낮은 PNG 로고를 업로드하려면 그림을 클릭합니다.
- 4단계: 삽입한 텍스트나 이미지를 마우스 오른쪽 버튼으로 클릭하고 맨 뒤로 보내기를 선택합니다. 이렇게 하면 워터마크가 프레젠테이션의 주요 데이터 뒤에 배치됩니다.
- 5단계: 슬라이드 마스터 탭에서 마스터 보기 닫기를 클릭하여 일반 편집 모드로 돌아갑니다.
이 수동 방식은 시각적이고 기술적인 배경 지식이 필요 없기 때문에 일회성 디자인 작업에는 완벽하지만, 여러 프레젠테이션을 다룰 때는 비효율적입니다. 반복적인 수동 작업에 의존하면 사람의 실수로 인한 오류가 발생할 여지가 많습니다. 대규모 문서 서식을 효과적으로 처리하려면 프로그래밍 방식의 자동화를 고려해야 합니다.
슬라이드 마스터 코드를 통해 PPT에 워터마크 넣는 방법
대량의 PowerPoint 파일을 처리할 때는 코드를 사용하여 워크플로를 자동화하는 것이 더 효율적입니다. 이 섹션에서는 Free Spire.Presentation for Python을 사용하여 PowerPoint 프레젠테이션에 자동으로 워터마크를 추가하는 방법을 보여줍니다. 이는 Microsoft PowerPoint를 설치하지 않고도 프레젠테이션을 생성 및 편집할 수 있는 무료 독립형 라이브러리입니다.
Free Spire.Presentation을 사용하면 슬라이드 마스터에 이미지나 텍스트를 삽입하여 프레젠테이션 전체에 워터마크를 적용하는 방식으로 PPT에 워터마크를 넣을 수 있습니다.
코드 예시는 다음과 같습니다:
from spire.presentation.common import *
from spire.presentation import *
# PPT 파일 초기화 및 로드
presentation = Presentation()
presentation.LoadFromFile("/input/pre1.pptx")
# 첫 번째 슬라이드의 슬라이드 마스터 가져오기
master = presentation.Masters[0]
# 워터마크 이미지를 중앙에 배치하기 위한 좌표 계산
img_width = 350.0
img_height = 110.0
left = (presentation.SlideSize.Size.Width - img_width) / 2
top = (presentation.SlideSize.Size.Height - img_height) / 2
# RectangleF 클래스를 사용하여 좌표 정의
rect = RectangleF(left, top, img_width, img_height)
# 슬라이드 마스터에 이미지 도형을 워터마크로 추가
image_shape = master.Shapes.AppendEmbedImageByPath(ShapeType.Rectangle, "/Logo1.png", rect)
# 모양 최적화 및 도형을 배경으로 보내기
image_shape.Line.FillType = FillFormatType.none
image_shape.SetShapeArrange(ShapeArrange.SendToBack)
# 프레젠테이션 저장
presentation.SaveToFile("/output/MasterImageWatermark.pptx", FileFormat.Pptx2010)
presentation.Dispose()
출력된 PowerPoint 프레젠테이션의 미리보기는 다음과 같습니다:
왼쪽 썸네일에서 볼 수 있듯이, 동일한 이미지 워터마크가 모든 슬라이드에 적용되었습니다.
PowerPoint 슬라이드에 개별적으로 워터마크 추가하는 방법
슬라이드 마스터에서 워터마크를 만드는 것은 전체 문서를 보호하는 데 이상적이지만, 특정 상황에서는 더 정밀한 방법이 필요합니다. 예를 들어, 표지와 마지막 슬라이드는 깔끔하게 유지하면서 특정 내용 슬라이드에만 "대외비" 텍스트 워터마크를 찍고 싶을 수 있습니다.
특정 슬라이드에 워터마크를 추가하는 것은 슬라이드 마스터 방식과 거의 동일합니다. 여전히 사각형 도형을 삽입하고 텍스트나 이미지를 추가합니다. 유일한 차이점은 전역 템플릿 대신 presentation.Slides[index] 속성을 사용하여 특정 슬라이드를 대상으로 한다는 점입니다.
다음은 8번째 슬라이드에 텍스트와 이미지 워터마크를 모두 적용하는 방법입니다:
from spire.presentation.common import *
from spire.presentation import *
# PPT 파일 초기화 및 로드
presentation = Presentation()
presentation.LoadFromFile("/input/pre1.pptx")
# 프레젠테이션 크기 가져오기 및 8번째 슬라이드 타겟팅
slide_size = presentation.SlideSize.Size
first_slide = presentation.Slides[7]
# 이미지 파일 스트림 로드
stream = Stream("/Logo1.png")
image = presentation.Images.AppendStream(stream)
stream.Close()
# 이미지의 원래 너비와 높이 가져오기
img_width = float(image.Width)
img_height = float(image.Height)
# 이미지를 중앙에 배치하기 위한 좌표 계산 및 경계 사각형 정의
img_left = (slide_size.Width - img_width) / 2
img_top = (slide_size.Height - img_height) / 2
img_rect = RectangleF(img_left, img_top, img_width, img_height)
# 사각형 도형을 추가하고 이미지로 채우기
img_shape = first_slide.Shapes.AppendShape(ShapeType.Rectangle, img_rect)
img_shape.Line.FillType = FillFormatType.none
img_shape.Locking.SelectionProtection = True # 실수로 수정되는 것을 방지하기 위해 선택 잠금 활성화
img_shape.Fill.FillType = FillFormatType.Picture
img_shape.Fill.PictureFill.FillType = PictureFillType.Stretch
img_shape.Fill.PictureFill.Picture.EmbedImage = image
# 텍스트 워터마크를 위한 너비, 높이 및 중앙 좌표 정의
txt_width = 350.0
txt_height = 110.0
txt_left = (slide_size.Width - txt_width) / 2
txt_top = (slide_size.Height - txt_height) / 2
txt_rect = RectangleF(txt_left, txt_top, txt_width, txt_height)
# 텍스트를 위한 사각형 도형 컨테이너 추가
txt_shape = first_slide.Shapes.AppendShape(ShapeType.Rectangle, txt_rect)
txt_shape.Fill.FillType = FillFormatType.none
txt_shape.ShapeStyle.LineColor.Color = Color.get_Transparent()
txt_shape.Line.FillType = FillFormatType.none
txt_shape.Rotation = -35 # 텍스트를 -35도 회전
txt_shape.Locking.SelectionProtection = True # 실수로 수정되는 것을 방지하기 위해 선택 잠금 활성화
# 워터마크 텍스트 내용 및 서식 구성
txt_shape.TextFrame.Text = "CONFIDENTIAL"
text_range = txt_shape.TextFrame.TextRange
text_range.Fill.FillType = FillFormatType.Solid
text_range.Fill.SolidColor.Color = Color.FromArgb(120, Color.get_Black().R, Color.get_HotPink().G, Color.get_HotPink().B)
text_range.FontHeight = 45
text_range.LatinFont = TextFont("Times New Roman")
# 콘텐츠를 가리지 않도록 이미지와 텍스트 도형을 모두 배경 레이어로 보내기
img_shape.SetShapeArrange(ShapeArrange.SendToBack)
txt_shape.SetShapeArrange(ShapeArrange.SendToBack)
# 프레젠테이션 파일 저장
presentation.SaveToFile("/output/WatermarkinSpecificSlide.pptx", FileFormat.Pptx2013)
presentation.Dispose()
선택 잠금 팁
이러한 도형은 슬라이드 마스터가 아닌 메인 슬라이드 캔버스에 직접 추가되기 때문에 사용자가 클릭하여 이동할 수 있습니다. 이를 방지하려면 이미지와 텍스트 도형 모두에 shape.Locking.SelectionProtection = True를 설정하는 것이 추가적인 안전장치가 됩니다. 이는 실수로 편집되는 것을 방지하는 데 도움이 됩니다.
추천 콘텐츠: PowerPoint 파일을 암호로 보호하는 5가지 효과적인 방법
모범 사례
스크립트를 실행하거나 PowerPoint 프레젠테이션을 공유하기 전에, 프레젠테이션을 깔끔하고 읽기 쉽게 유지하기 위해 다음 디자인 원칙을 염두에 두십시오:
- 투명도가 핵심: 15%~20%의 불투명도 수준을 권장합니다. 워터마크가 본문을 가려서는 안 됩니다.
- 전략적 회전: 텍스트를 -35도 또는 -45도 각도로 기울이십시오. 대각선 텍스트 블록은 무단 스마트폰 스크린샷이나 사진 유출 시 잘라내기를 훨씬 어렵게 만듭니다.
- 색상 선택: 중립적인 색상을 제안합니다. 밝은 슬라이드 배경에는 밝은 회색을, 어두운 프레젠테이션 테마에는 짙은 슬레이트 톤을 사용하십시오. 순수한 빨간색이나 검은색과 같이 눈에 띄는 고대비 색상은 피하십시오.
결론
PowerPoint 프레젠테이션에 워터마크를 추가하면 브랜드를 보호하고 민감한 데이터를 안전하게 지킬 수 있습니다. 빠르고 일회성인 파일의 경우 수동 슬라이드 마스터 보기가 완벽하게 작동합니다. 그러나 대규모 처리에는 Python 자동화가 더 적합합니다. Free Spire.Presentation for Python을 활용하면 Microsoft PowerPoint를 설치할 필요 없이 전역 마스터 업데이트와 페이지별 잠금을 모두 쉽게 스크립트로 작성할 수 있습니다. 현재 필요에 맞는 방법을 선택하여 지금 바로 프레젠테이션을 보호하세요.
PPT에 워터마크 추가에 관한 자주 묻는 질문(FAQ)
Q1: 사용자가 Python으로 생성된 워터마크를 제거할 수 있나요?
일반 편집 중에는 불가능합니다. 슬라이드 마스터를 통해 추가된 워터마크는 표준 보기에서 기본적으로 클릭할 수 없습니다. 그러나 사용자가 슬라이드 마스터 보기를 열어 수동으로 이동하거나 삭제할 수는 있습니다. 완벽하고 제거 불가능한 보안을 원한다면 프레젠테이션을 PDF로 내보내십시오.
Q2: 워터마크 이미지가 왜 픽셀화되어 보이나요?
소스 이미지 해상도가 너무 낮기 때문입니다. 수동으로 추가하든 코드를 통해 추가하든, 항상 투명한 배경의 고해상도 PNG 파일을 사용하십시오.
Q3: 슬라이드를 인쇄할 때 워터마크가 그대로 유지되나요?
네. 워터마크는 슬라이드 마스터나 잠긴 캔버스 좌표에 직접 포함됩니다. 인쇄하거나 내보낼 때 일반적으로 불투명도와 위치가 유지됩니다.
함께 읽어보기:
Come aggiungere una filigrana in PowerPoint (guida dettagliata)
Indice
Durante la creazione di presentazioni, l'aggiunta di filigrane, come il logo aziendale, uno slogan o l'etichetta "RISERVATO", è un modo efficace per mantenere un design coerente e indicare la proprietà del documento. Tuttavia, poiché PowerPoint non dispone di un pulsante integrato per aggiungere filigrane con un solo clic, molti utenti non sanno come aggiungere una filigrana nelle presentazioni PowerPoint.
Questa guida ti illustra diversi modi pratici per aggiungere filigrane in PowerPoint, dalle soluzioni manuali di Microsoft PowerPoint all'elaborazione in batch con l'automazione Python, aiutandoti a creare presentazioni sicure e professionali con facilità.
- Inserire una filigrana in PowerPoint tramite lo Schema diapositiva
- Inserire una filigrana in PPT tramite codice nello Schema diapositiva
- Aggiungere una filigrana alle singole diapositive di PowerPoint
- Best practice
- Domande frequenti (FAQ)
Come inserire una filigrana in PowerPoint tramite lo Schema diapositiva
Poiché MS PowerPoint non dispone di uno strumento dedicato alle filigrane, il modo più efficace consiste nell'aggiungere manualmente filigrane di testo o immagini direttamente nello Schema diapositiva. Questo applica automaticamente la filigrana a ogni diapositiva, risparmiando tempo e mantenendo la formattazione coerente in tutta la presentazione.
Guida passo dopo passo
- Passaggio 1: Apri la presentazione e vai su Visualizza > Schema diapositiva nella barra multifunzione in alto.
- Passaggio 2: Scorri fino alla parte superiore del riquadro delle miniature a sinistra e fai clic sullo schema diapositiva principale (la miniatura più grande in alto).
- Passaggio 3: Vai alla scheda Inserisci. Scegli Casella di testo per una filigrana di testo (ad esempio, "RISERVATO") o fai clic su Immagini per caricare un logo PNG a bassa opacità.
- Passaggio 4: Fai clic con il tasto destro del mouse sul testo o sull'immagine inserita e seleziona Porta in secondo piano. In questo modo la filigrana rimarrà sotto i dati principali della presentazione.
- Passaggio 5: Fai clic su Chiudi visualizzazione schema nella scheda Schema diapositiva per tornare alla modalità di modifica normale.
Sebbene questo approccio manuale sia perfetto per attività di progettazione singole perché è altamente visivo e non richiede competenze tecniche, diventa inefficiente quando si tratta di gestire più presentazioni. Affidarsi a un lavoro manuale ripetitivo lascia troppo spazio all'errore umano. Per gestire efficacemente la formattazione di documenti su larga scala, dovremmo ricorrere all'automazione programmatica.
Come inserire una filigrana in PPT tramite codice nello Schema diapositiva
Quando si ha a che fare con un gran numero di file PowerPoint, automatizzare il flusso di lavoro con il codice è la scelta più efficiente. In questa sezione, mostreremo come aggiungere automaticamente filigrane nelle presentazioni PowerPoint utilizzando Free Spire.Presentation for Python. Si tratta di una libreria gratuita e autonoma che consente agli utenti di creare e modificare presentazioni senza dover installare Microsoft PowerPoint.
Con l'aiuto di Free Spire.Presentation, possiamo comunque inserire filigrane in PPT aggiungendo un'immagine o un testo nello Schema diapositiva per applicare la filigrana all'intera presentazione.
Ecco l'esempio di codice:
from spire.presentation.common import *
from spire.presentation import *
# Inizializza e carica il file PPT
presentation = Presentation()
presentation.LoadFromFile("/input/pre1.pptx")
# Ottieni lo schema diapositiva della prima diapositiva
master = presentation.Masters[0]
# Calcola le coordinate per centrare l'immagine della filigrana
img_width = 350.0
img_height = 110.0
left = (presentation.SlideSize.Size.Width - img_width) / 2
top = (presentation.SlideSize.Size.Height - img_height) / 2
# Definisci le coordinate usando la classe RectangleF
rect = RectangleF(left, top, img_width, img_height)
# Aggiungi la forma dell'immagine allo schema diapositiva come filigrana
image_shape = master.Shapes.AppendEmbedImageByPath(ShapeType.Rectangle, "/Logo1.png", rect)
# Ottimizza l'aspetto e porta la forma in secondo piano
image_shape.Line.FillType = FillFormatType.none
image_shape.SetShapeArrange(ShapeArrange.SendToBack)
# Salva la presentazione
presentation.SaveToFile("/output/MasterImageWatermark.pptx", FileFormat.Pptx2010)
presentation.Dispose()
Ecco un'anteprima della presentazione PowerPoint risultante:
Come si può vedere dalle miniature a sinistra, la stessa filigrana immagine è ora applicata a tutte le diapositive.
Come aggiungere una filigrana alle singole diapositive di PowerPoint
Sebbene la creazione di filigrane nello Schema diapositiva sia ideale per proteggere l'intero documento, alcuni scenari richiedono un metodo più preciso. Ad esempio, potresti voler stampare una filigrana di testo "RISERVATO" solo su specifiche diapositive di contenuto, lasciando pulite la copertina e la diapositiva di chiusura.
L'aggiunta di una filigrana a una diapositiva specifica è sostanzialmente identica al metodo dello schema diapositiva. Si inseriscono comunque forme rettangolari e si aggiungono testo o immagini. L'unica differenza è che si utilizza la proprietà presentation.Slides[index] per puntare alla diapositiva specifica invece che al modello globale.
Ecco come applicare filigrane sia di testo che di immagine all'ottava diapositiva:
from spire.presentation.common import *
from spire.presentation import *
# Inizializza e carica il file PPT
presentation = Presentation()
presentation.LoadFromFile("/input/pre1.pptx")
# Ottieni le dimensioni della presentazione e punta all'ottava diapositiva
slide_size = presentation.SlideSize.Size
first_slide = presentation.Slides[7]
# Carica lo stream del file immagine
stream = Stream("/Logo1.png")
image = presentation.Images.AppendStream(stream)
stream.Close()
# Ottieni larghezza e altezza originali dell'immagine
img_width = float(image.Width)
img_height = float(image.Height)
# Calcola le coordinate per centrare l'immagine e definisci il rettangolo di delimitazione
img_left = (slide_size.Width - img_width) / 2
img_top = (slide_size.Height - img_height) / 2
img_rect = RectangleF(img_left, img_top, img_width, img_height)
# Aggiungi una forma rettangolare e riempila con l'immagine
img_shape = first_slide.Shapes.AppendShape(ShapeType.Rectangle, img_rect)
img_shape.Line.FillType = FillFormatType.none
img_shape.Locking.SelectionProtection = True # Abilita il blocco della selezione per evitare modifiche accidentali
img_shape.Fill.FillType = FillFormatType.Picture
img_shape.Fill.PictureFill.FillType = PictureFillType.Stretch
img_shape.Fill.PictureFill.Picture.EmbedImage = image
# Definisci larghezza, altezza e coordinate di centraggio per la filigrana di testo
txt_width = 350.0
txt_height = 110.0
txt_left = (slide_size.Width - txt_width) / 2
txt_top = (slide_size.Height - txt_height) / 2
txt_rect = RectangleF(txt_left, txt_top, txt_width, txt_height)
# Aggiungi un contenitore di forma rettangolare per il testo
txt_shape = first_slide.Shapes.AppendShape(ShapeType.Rectangle, txt_rect)
txt_shape.Fill.FillType = FillFormatType.none
txt_shape.ShapeStyle.LineColor.Color = Color.get_Transparent()
txt_shape.Line.FillType = FillFormatType.none
txt_shape.Rotation = -35 # Ruota il testo di -35 gradi
txt_shape.Locking.SelectionProtection = True # Abilita il blocco della selezione per evitare modifiche accidentali
# Configura il contenuto e la formattazione del testo della filigrana
txt_shape.TextFrame.Text = "RISERVATO"
text_range = txt_shape.TextFrame.TextRange
text_range.Fill.FillType = FillFormatType.Solid
text_range.Fill.SolidColor.Color = Color.FromArgb(120, Color.get_Black().R, Color.get_HotPink().G, Color.get_HotPink().B)
text_range.FontHeight = 45
text_range.LatinFont = TextFont("Times New Roman")
# Porta sia le forme dell'immagine che del testo in secondo piano per evitare di bloccare il contenuto
img_shape.SetShapeArrange(ShapeArrange.SendToBack)
txt_shape.SetShapeArrange(ShapeArrange.SendToBack)
# Salva il file della presentazione
presentation.SaveToFile("/output/WatermarkinSpecificSlide.pptx", FileFormat.Pptx2013)
presentation.Dispose()
Il trucco del blocco della selezione
Poiché queste forme vengono aggiunte direttamente sull'area di disegno della diapositiva principale anziché sullo Schema diapositiva, gli utenti potrebbero tecnicamente fare clic su di esse e spostarle. Per evitare ciò, impostare shape.Locking.SelectionProtection = True sia sulla forma dell'immagine che su quella del testo funge da ulteriore salvaguardia. Aiuta a prevenire modifiche accidentali.
Potrebbe interessarti: 5 modi efficaci per proteggere con password i file PowerPoint
Best practice
Prima di eseguire script o condividere presentazioni PowerPoint, tieni a mente questi principi di progettazione per mantenere la tua presentazione pulita e facile da leggere:
- La trasparenza è fondamentale: si consiglia un livello di opacità dal 15% al 20%. La filigrana non dovrebbe coprire il testo principale.
- Rotazione strategica: inclina il testo con un angolo di -35° o -45°. I blocchi di testo diagonali rendono molto più difficile ritagliare screenshot non autorizzati da smartphone o fughe di notizie tramite foto.
- Selezione dei colori: si consigliano colori neutri. Usa grigi chiari per sfondi di diapositive chiari e toni ardesia profondi per temi di presentazione scuri. Evita colori accesi ad alto contrasto come il rosso puro o il nero.
Conclusione
L'aggiunta di filigrane alle tue presentazioni PowerPoint protegge il tuo marchio e mette al sicuro i dati sensibili. Per un file singolo e veloce, la visualizzazione Schema diapositiva manuale funziona perfettamente. Tuttavia, l'automazione Python è più adatta per l'elaborazione su larga scala. Utilizzando Free Spire.Presentation for Python, puoi facilmente creare script sia per aggiornamenti master globali che per blocchi specifici per pagina senza nemmeno aver bisogno di Microsoft PowerPoint installato. Scegli il metodo più adatto alle tue esigenze attuali e inizia a proteggere le tue presentazioni oggi stesso.
Domande frequenti (FAQ) sull'aggiunta di filigrane a PPT
D1: Gli utenti possono rimuovere la filigrana generata da Python?
Non durante la normale modifica. Una filigrana aggiunta tramite lo Schema diapositiva non è nativamente cliccabile nella visualizzazione standard. Tuttavia, gli utenti possono comunque aprire la visualizzazione Schema diapositiva per spostarla o eliminarla manualmente. Se desideri una sicurezza assoluta e non rimovibile, esporta la presentazione in PDF.
D2: Perché la mia immagine filigrana appare pixelata?
La risoluzione dell'immagine sorgente è troppo bassa. Che tu la aggiunga manualmente o tramite codice, usa sempre un file PNG ad alta risoluzione con uno sfondo trasparente.
D3: La filigrana rimarrà intatta durante la stampa delle diapositive?
Sì. Le filigrane sono incorporate direttamente nello schema diapositiva o nelle coordinate bloccate dell'area di disegno. Generalmente manterranno l'opacità e la posizione durante la stampa e l'esportazione.