
이것을 상상해 보십시오: 마침내 필요한 정확한 연구 보고서, 비즈니스 계약 또는 데이터로 가득 찬 백서를 찾았지만 PDF에 갇혀 있습니다. 내용을 복사하여 붙여넣으려고 하면 뒤죽박죽된 서식, 선택할 수 없는 텍스트 또는 답답한 콘텐츠 보호 블록이 나타납니다. 질문은 보편적입니다: 수동으로 다시 입력하거나 값비싼 소프트웨어 없이 PDF에서 텍스트를 추출하는 방법은 무엇입니까?
이 포괄적인 가이드에서는 (OCR이 포함된 스캔된 PDF 포함) 무료로 PDF에서 텍스트를 추출하는 가장 좋은 방법을 살펴보겠습니다. 학생, 비즈니스 전문가 또는 개발자이든 관계없이 PDF 텍스트를 정확하고 효율적으로 추출하는 완벽한 방법을 찾을 수 있습니다.
- PDF 텍스트 추출이 까다로울 수 있는 이유는 무엇입니까?
- 가장 간단한 방법 – 복사하여 붙여넣기
- PDF에서 텍스트를 추출하는 최고의 무료 온라인 도구
- PDF24 Creator 무료 데스크톱 PDF 텍스트 추출 도구
- C#에서 PDF 텍스트를 추출하는 무료 개발자 도구
- 자주 묻는 질문(FAQ)
PDF 텍스트 추출이 까다로울 수 있는 이유는 무엇입니까?
PDF는 시각적 일관성을 우선시하는 방식으로 텍스트를 저장합니다. 즉, 텍스트가 조각난 블록으로, 특이한 순서로 또는 더 나쁘게는 이미지의 일부로 저장될 수 있습니다. 각각 고유한 추출 과제가 있는 두 가지 주요 유형의 PDF가 있습니다.
- 디지털 PDF: 선택 가능한 텍스트가 포함되어 있지만 다중 열 기사나 표와 같은 복잡한 레이아웃은 간단한 복사-붙여넣기 작업을 혼동시킬 수 있습니다.
- 스캔된 PDF: 본질적으로 페이지의 이미지입니다. 스캔된 PDF에서 텍스트를 추출하려면 이미지의 문자 모양을 분석하고 인식하는 OCR(광학 문자 인식) 기술이 필요합니다.
고맙게도 아래의 무료 도구는 두 가지 유형을 모두 쉽게 처리합니다.
가장 간단한 방법 – 복사하여 붙여넣기
간단한 디지털 PDF가 있고 작은 텍스트 섹션만 필요한 경우 기본 사항을 간과하지 마십시오. 작은 작업의 경우 PDF에서 텍스트를 가져오는 가장 빠른 방법입니다.
- PDF 열기: Adobe Acrobat Reader, 웹 브라우저(Chrome 또는 Edge 등) 또는 미리보기 앱과 같은 표준 뷰어를 사용합니다.
- 선택 및 복사: 원하는 텍스트를 강조 표시하고 마우스 오른쪽 버튼을 클릭하여 "복사"를 선택하거나 키보드 단축키 "Ctrl+C"(Windows) 또는 "Command+C"(Mac)를 사용합니다.
- 붙여넣기: 텍스트 편집기(메모장 또는 TextEdit 등) 또는 Word 문서를 열고 "Ctrl+V" 또는 "Command+V"로 텍스트를 붙여넣습니다.
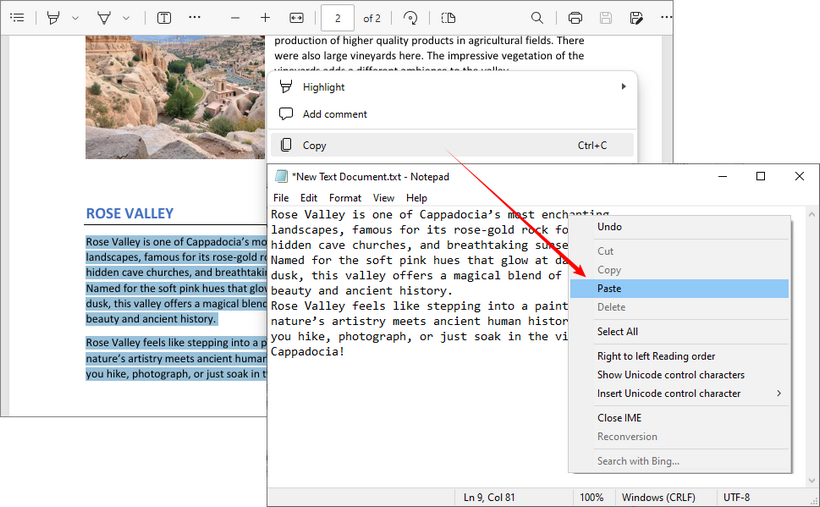
문제점: 이 방법은 스캔된 문서, 보호된 PDF 또는 복잡한 서식을 보존해야 하는 경우 실패합니다. 이러한 경우 아래의 전용 무료 도구를 사용하거나 보호된 PDF에서 텍스트를 복사하는 방법에 대한 가이드를 참조하십시오.
PDF에서 텍스트를 추출하는 최고의 무료 온라인 도구
대부분의 사용자에게 무료 온라인 도구는 무료로 PDF에서 텍스트를 추출하는 가장 빠르고 쉬운 방법입니다. 브라우저에서 직접 작동하며 설치가 필요 없으며 이제 많은 도구에 강력한 OCR 기능이 포함되어 있습니다. 다음은 기본 텍스트 추출에서 다국어 OCR에 이르기까지 다양한 사용 사례에 대한 두 가지 최고의 선택입니다.
CLOUDXDOCS - 디지털 PDF를 위한 가장 간단한 무료 도구
스캔되지 않은 텍스트 기반 PDF에서 텍스트를 추출하기 위한 군더더기 없고 광고 없는 도구가 필요한 경우 CLOUDXDOCS가 이상적입니다. 100% 무료이며 등록이 필요 없으며 한 번의 클릭으로 작동하므로 몇 초 만에 PDF 파일에서 텍스트를 가져오는 데 적합합니다.
온라인에서 PDF 텍스트를 추출하는 단계:
- CLOUDXDOCS 무료 PDF를 텍스트로 변환기를 방문하십시오.
- 끌어서 놓거나 클릭하여 찾아보기로 PDF 파일을 업로드합니다.
- 도구가 파일을 처리할 때까지 기다립니다.
- 추출된 텍스트를 TXT 파일로 다운로드합니다.
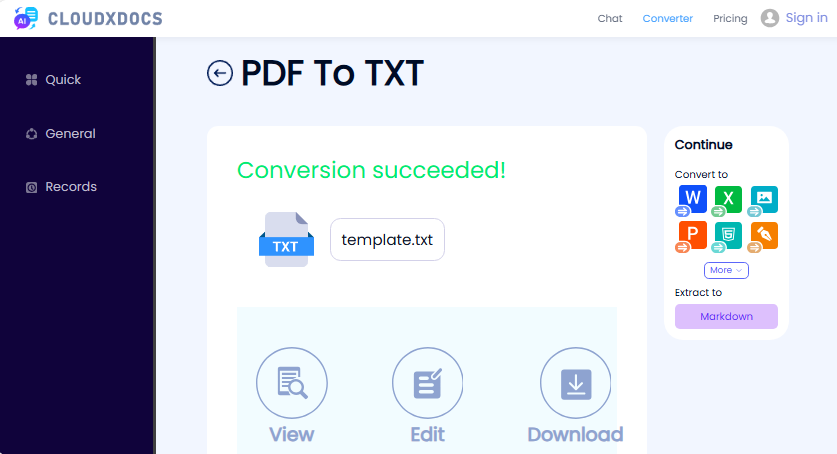
✔ 장점: 가입 없음, 광고 없음, 간단한 인터페이스.
✘ 단점: OCR 없음(스캔된 PDF에서는 작동하지 않음).
i2OCR - 스캔된 PDF를 위한 무료 OCR 도구
i2OCR은 이미지 및 스캔된 PDF용 OCR을 전문으로 하는 무료 온라인 도구로, 무려 100개 이상의 언어를 지원하여 영어가 아닌 PDF에 적합합니다. 단일 페이지 사용에 무료이며 여러 출력 형식을 제공합니다.
온라인에서 스캔된 PDF의 텍스트를 무료로 추출하는 단계:
- i2OCR PDF OCR 도구를 방문하십시오.
- 인식 언어와 선호하는 OCR 엔진을 선택합니다.
- "PDF 선택"을 클릭하여 스캔된 PDF를 업로드합니다.
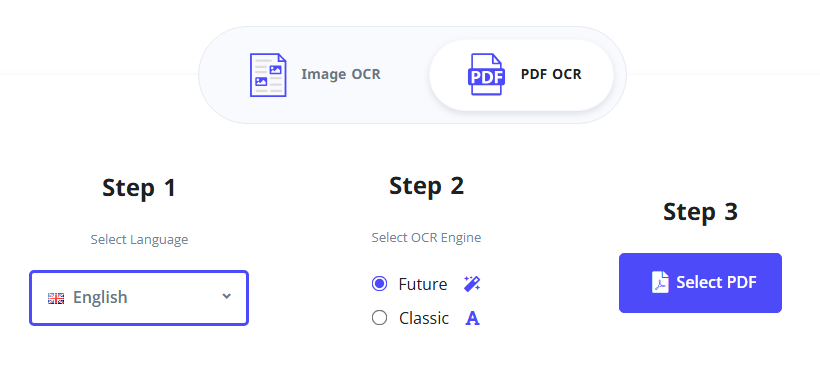
- "OCR 시작"을 클릭하고 도구가 스캔을 처리할 때까지 기다립니다.
- 추출된 텍스트를 복사하거나 TXT, Word 또는 HTML로 다운로드합니다.
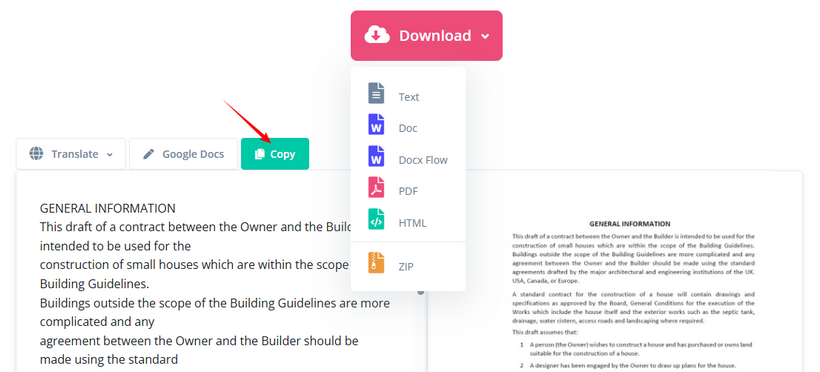
✔ 장점: 100개 이상의 언어 지원, 무료 OCR, 여러 출력 형식, 가입 없음.
✘ 단점: 무료 플랜은 한 번에 한 페이지만 지원합니다.
텍스트 외에도 PDF에는 종종 귀중한 이미지, 차트 또는 다이어그램이 포함되어 있습니다. PDF 문서에 포함된 이미지를 추출하는 방법을 알아보십시오.
PDF24 Creator 무료 데스크톱 PDF 텍스트 추출 도구
PDF를 자주 사용하거나 오프라인 액세스가 필요하거나 대량 파일을 처리해야 하는 경우 PDF24 Creator가 이상적인 선택입니다. 이 무료 Windows 전용 데스크톱 도구는 텍스트 추출, 스캔된 PDF용 OCR 및 대량 처리를 포함한 포괄적인 PDF 처리 기능을 제공하며 파일을 로컬에 보관하여 개인 정보를 최대한 보호합니다.
디지털(선택 가능) PDF에서 텍스트 추출
- 공식 PDF24 Creator 다운로드 페이지로 이동하여 Windows 시스템에 맞는 버전을 다운로드합니다.
- PDF24를 설치하고 실행합니다. PDF24 도구 상자(많은 PDF 도구가 있는 대시보드)가 표시됩니다.
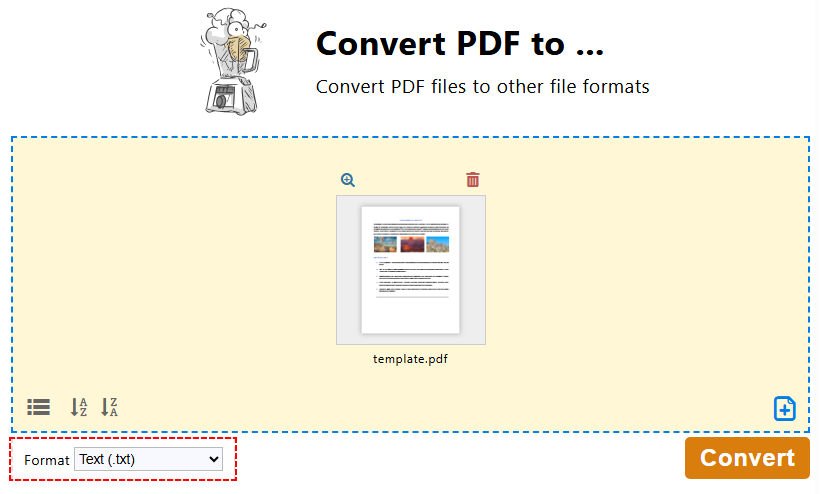
- PDF24 도구 상자에서 "PDF를 다음으로 변환..."을 클릭합니다.
- "파일 선택"을 클릭하거나 끌어서 놓아 PDF 파일을 업로드합니다.
- 출력 형식으로 "텍스트(.txt)"를 선택하고 "변환"을 클릭합니다.
- 추출된 텍스트 파일을 장치에 저장합니다.
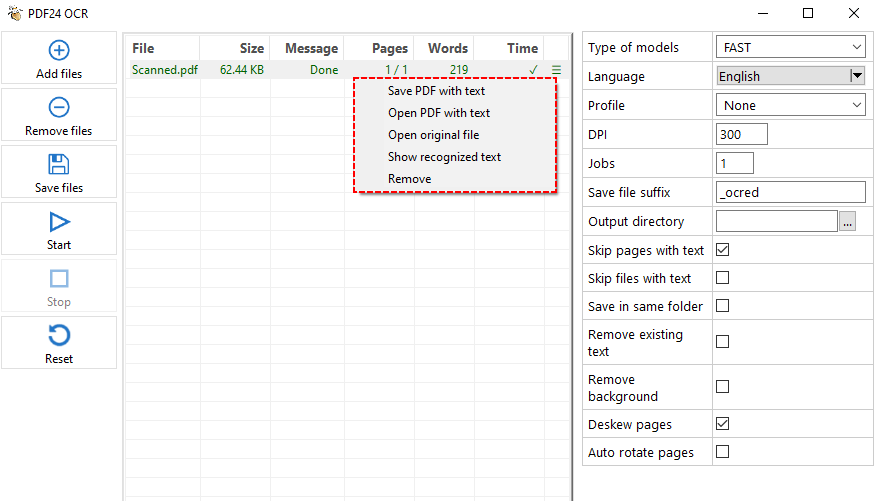
스캔된 PDF에서 텍스트 추출(OCR 사용)
스캔/이미지 기반 PDF의 경우 PDF24의 내장 OCR을 사용하여 PDF 스캔에서 텍스트를 인식하고 편집 가능한 텍스트 또는 검색 가능한 PDF로 변환합니다.
- PDF24 도구 상자에서 "PDF OCR"을 클릭합니다.
- "파일 추가"를 클릭하고 스캔된 PDF를 선택합니다.
- 오른쪽 설정 패널에서 텍스트 인식 모드, 언어, DPI, 출력 디렉토리 등을 선택합니다.
- "시작" 버튼을 클릭하여 PDF를 처리합니다.
- PDF24는 각 페이지를 처리하고 텍스트를 인식하여 텍스트 파일 또는 검색 가능한 PDF에 저장합니다.
Adobe 사용자를 위한 전문가 팁:
Adobe Acrobat Pro(유료)가 있는 경우 "PDF 내보내기" 도구로 이동하여 출력 형식으로 "텍스트(일반)"를 선택하여 텍스트를 추출할 수 있습니다. Acrobat은 파일을 .txt 문서로 즉시 저장합니다.
C#에서 PDF 텍스트를 추출하는 무료 개발자 도구
개발자라면 Free Spire.PDF for .NET은 프로그래밍 방식으로 PDF에서 텍스트를 읽는 무료 제로 종속성 라이브러리입니다. 빠르고 가벼우며 PDF 텍스트 추출을 프로젝트에 통합하는 데 적합합니다.
PDF에서 텍스트를 추출하는 C# 코드
이 코드는 디지털 PDF 파일의 각 페이지를 반복하고 PDF에서 모든 텍스트를 추출합니다. 핵심 텍스트 추출 클래스 및 메서드는 다음과 같습니다.
- PdfTextExtractor: 단일 PDF 페이지에서 텍스트를 가져오는 특수 유틸리티 클래스(한 번에 한 페이지).
- PdfTextExtractOptions: 텍스트 추출을 위한 구성 클래스. 모든 텍스트를 추출할지 여부와 같은 규칙을 설정합니다.
- ExtractText(): PDF 페이지에서 텍스트 추출을 실행하고 추출된 텍스트 문자열을 반환합니다.
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Text;
namespace ExtractAllTextFromPDF
{
internal class Program
{
static void Main(string[] args)
{
// Create a PDF document instance
PdfDocument pdf = new PdfDocument();
// Load the PDF file
pdf.LoadFromFile("SamplePDF.pdf");
// Initialize a StringBuilder to hold the extracted text
StringBuilder extractedText = new StringBuilder();
// Loop through each page in the PDF
foreach (PdfPageBase page in pdf.Pages)
{
// Create a PdfTextExtractor for the current page
PdfTextExtractor extractor = new PdfTextExtractor(page);
// Set extraction options
PdfTextExtractOptions option = new PdfTextExtractOptions
{
IsExtractAllText = true
};
// Extract text from the current page
string text = extractor.ExtractText(option);
// Append the extracted text to the StringBuilder
extractedText.AppendLine(text);
}
// Save the extracted text to a text file
File.WriteAllText("ExtractedText.txt", extractedText.ToString());
// Close the PDF document
pdf.Close();
}
}
}
모든 텍스트를 추출하는 것 외에도 Free Spire.PDF를 사용하면 단일 페이지 또는 지정된 영역에서 텍스트를 추출할 수도 있습니다. 추출 결과는 다음과 같습니다.
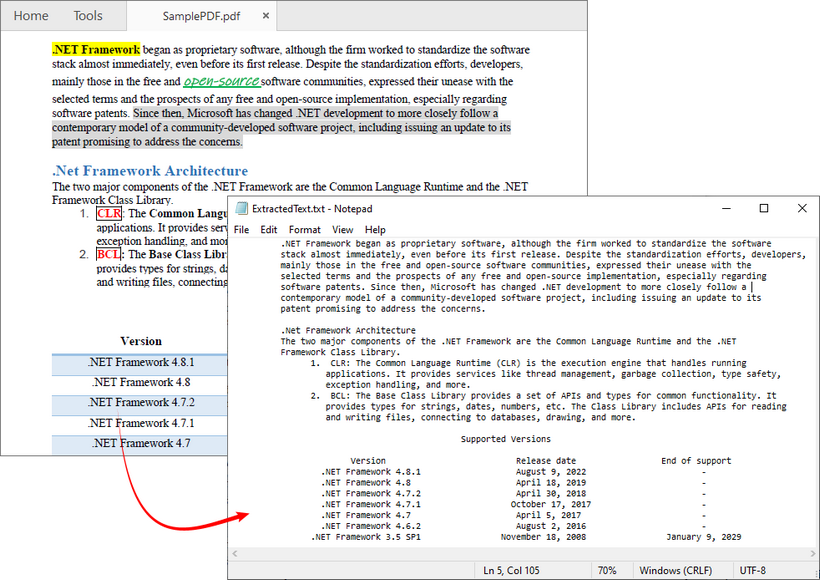
전문가 팁: C#에서 스캔된 PDF의 텍스트를 추출하려면 공식 가이드 C#에서 스캔된 PDF에 대한 OCR을 수행하여 텍스트 추출을 따르십시오.
자주 묻는 질문(FAQ)
Q1: 스캔된 PDF에서 텍스트를 무료로 추출하려면 어떻게 해야 합니까?
A: i2OCR, PDF24와 같은 도구는 모두 무료 OCR 옵션을 제공합니다. 스캔된 PDF를 업로드하고 추출하기 전에 OCR 설정을 활성화하기만 하면 됩니다.
Q2: 무료 도구는 대량 텍스트 추출을 지원합니까?
A: 예, 하지만 방법이 중요합니다. 대부분의 온라인 무료 도구에는 대량 제한이 있지만 PDF24 Creator와 같은 오프라인 데스크톱 도구나 프로그래밍 방식 솔루션을 사용하여 여러 PDF를 대량으로 처리할 수 있습니다.
Q3: PDF에서 표를 추출하는 가장 좋은 방법은 무엇입니까?
A: 표 구조가 손실되므로 표를 일반 텍스트로 추출하는 것은 매우 어렵습니다. 가장 좋은 방법은 PDF를 Excel(XLSX) 또는 CSV로 변환할 수 있는 도구를 사용하는 것입니다. 이렇게 하면 데이터를 셀에 배치하여 구조를 보존하려고 시도합니다.
Q4: PDF에서 텍스트를 추출하고 서식을 유지하려면 어떻게 해야 합니까?
A: 일반 텍스트(.txt)는 굵게, 기울임꼴 또는 글꼴 크기와 같은 서식을 보존할 수 없습니다. 서식을 유지하려면 PDF를 Word 문서(.docx)로 변환해야 합니다.
요약
이 기사에서는 기술 수준이나 문서의 복잡성에 관계없이 무료로 PDF에서 텍스트를 추출하는 몇 가지 신뢰할 수 있는 방법을 제시합니다.
빠른 일회성 작업의 경우 CLOUDXDOCS와 같은 신뢰할 수 있는 온라인 도구가 가장 좋습니다. 반복적인 작업이나 민감한 정보의 경우 PDF24와 같은 오프라인 소프트웨어를 사용하십시오. 그리고 최첨단 자동화된 콘텐츠 파이프라인을 구축하려는 경우 Free Spire.PDF와 같은 코드 솔루션을 탐색하면 워크플로를 혁신할 수 있습니다.
이 가이드를 통해 이제 모든 PDF에 숨겨진 텍스트를 잠금 해제하고 이를 활용할 수 있습니다.