
Представьте себе: вы наконец-то находите нужный вам исследовательский отчет, деловой контракт или технический документ с данными, но он заперт в PDF. Когда вы пытаетесь скопировать и вставить его содержимое, вы сталкиваетесь с искаженным форматированием, невыделяемым текстом или раздражающими блоками защиты контента. Вопрос универсален: как извлечь текст из PDF-файлов без ручного перепечатывания или дорогостоящего программного обеспечения?
В этом подробном руководстве мы рассмотрим лучшие способы бесплатного извлечения текста из PDF (включая сканированные PDF с OCR). Независимо от того, являетесь ли вы студентом, бизнес-профессионалом или разработчиком, вы найдете идеальный метод для точного и эффективного извлечения текста из PDF.
- Почему извлечение текста из PDF может быть сложным?
- Самый простой трюк – копирование и вставка
- Лучшие бесплатные онлайн-инструменты для извлечения текста из PDF
- Бесплатные настольные инструменты для извлечения текста из PDF от PDF24 Creator
- Бесплатный инструмент разработчика для извлечения текста из PDF на C#
- Часто задаваемые вопросы (FAQ)
Почему извлечение текста из PDF может быть сложным?
PDF-файлы хранят текст таким образом, чтобы обеспечить визуальную согласованность. Это означает, что текст может храниться в виде фрагментированных блоков, в необычном порядке или, что еще хуже, как часть изображения. Существует два основных типа PDF, каждый из которых имеет свои уникальные проблемы с извлечением:
- Цифровые PDF: Они содержат выделяемый текст, но сложные макеты, такие как многоколоночные статьи или таблицы, могут запутать простые действия копирования и вставки.
- Сканированные PDF: Это, по сути, изображения страниц. Чтобы извлечь текст из сканированного PDF, вам нужна технология OCR (оптическое распознавание символов), которая анализирует изображение и распознает формы букв.
К счастью, бесплатные инструменты, представленные ниже, легко справляются с обоими типами.
Самый простой трюк – копирование и вставка
Если у вас простой цифровой PDF и вам нужен лишь небольшой фрагмент текста, не пренебрегайте основами. Это самый быстрый способ получить текст из PDF для небольших задач.
- Откройте PDF: Используйте стандартный просмотрщик, такой как Adobe Acrobat Reader, веб-браузер (например, Chrome или Edge) или приложение для предварительного просмотра.
- Выделите и скопируйте: Выделите нужный текст, щелкните правой кнопкой мыши и выберите "Копировать" или используйте сочетания клавиш “Ctrl+C” (Windows) или “Command+C” (Mac).
- Вставьте: Откройте текстовый редактор (например, Блокнот или TextEdit) или документ Word и вставьте текст с помощью “Ctrl+V” или “Command+V”.
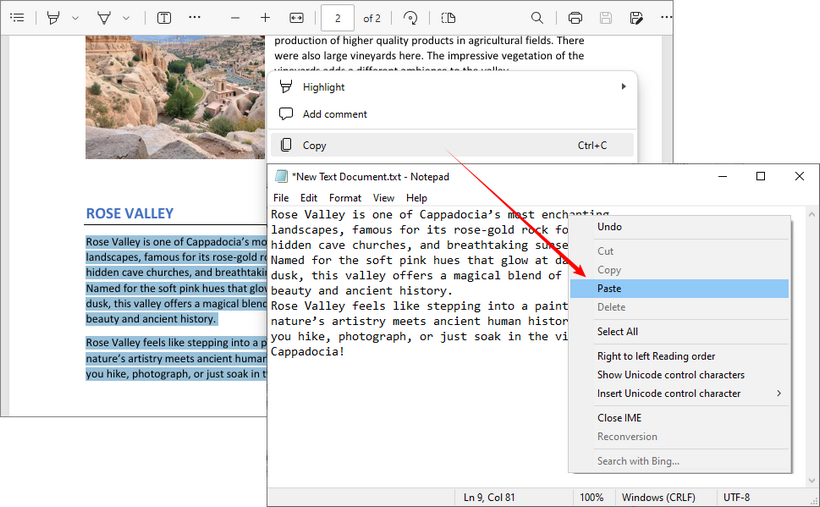
Подвох: Этот метод не работает для сканированных документов, защищенных PDF или когда вам нужно сохранить сложное форматирование. Для этого используйте специальные бесплатные инструменты, представленные ниже, или ознакомьтесь с нашим руководством о том, как копировать текст из защищенного PDF.
Лучшие бесплатные онлайн-инструменты для извлечения текста из PDF
Для большинства пользователей бесплатные онлайн-инструменты — это самый быстрый и простой способ бесплатно извлечь текст из PDF. Они работают прямо в вашем браузере, не требуют установки, и многие из них теперь включают мощные функции OCR. Ниже приведены два лучших варианта для различных случаев использования — от базового извлечения текста до многоязычного OCR.
CLOUDXDOCS - Самый простой бесплатный инструмент для цифровых PDF
Если вам нужен простой, без рекламы инструмент для извлечения текста из текстовых PDF (не сканированных), CLOUDXDOCS — идеальный вариант. Он на 100% бесплатный, не требует регистрации и работает в один клик — идеально для извлечения текста из PDF-файлов за секунды.
Шаги для извлечения текста из PDF онлайн:
- Посетите бесплатный конвертер PDF в текст от CLOUDXDOCS.
- Загрузите свой PDF-файл, перетащив его или нажав для выбора.
- Подождите, пока инструмент обработает ваш файл.
- Загрузите извлеченный текст в виде файла TXT.
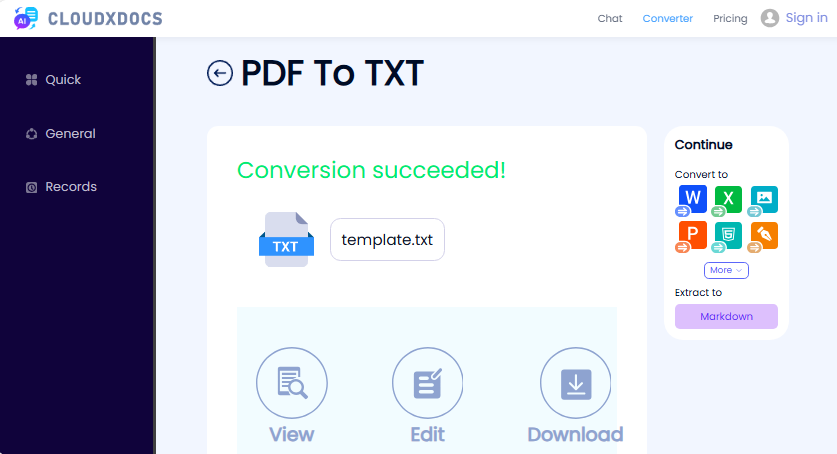
✔ Плюсы: Без регистрации, без рекламы, простой интерфейс.
✘ Минусы: Нет OCR (не работает для сканированных PDF).
i2OCR - Бесплатный инструмент OCR для сканированных PDF
i2OCR — это бесплатный онлайн-инструмент, который специализируется на OCR для изображений и сканированных PDF, поддерживая более 100 языков — идеально для PDF не на английском языке. Он бесплатен для одностраничного использования и предлагает несколько форматов вывода.
Шаги для бесплатного извлечения текста из сканированного PDF онлайн:
- Посетите инструмент i2OCR PDF OCR.
- Выберите язык распознавания и предпочтительный движок OCR.
- Нажмите “Выбрать PDF”, чтобы загрузить ваш сканированный PDF.
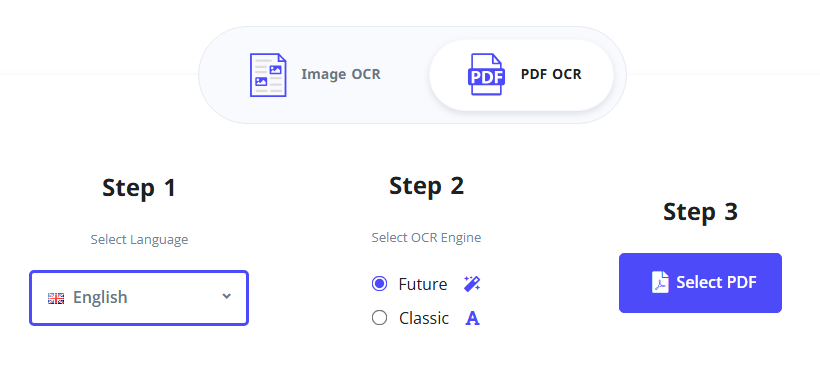
- Нажмите “Начать OCR” и подождите, пока инструмент обработает скан.
- Скопируйте извлеченный текст или загрузите его в формате TXT, Word или HTML.
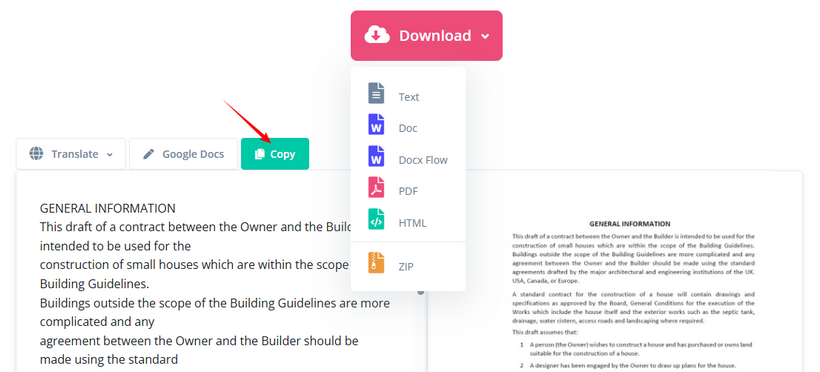
✔ Плюсы: Поддержка более 100 языков, бесплатный OCR, несколько форматов вывода, без регистрации.
✘ Минусы: Бесплатный план поддерживает только одну страницу за раз.
Помимо текста, PDF-файлы часто содержат ценные изображения, диаграммы или схемы — узнайте, как извлечь изображения, встроенные в ваш PDF-документ.
Бесплатные настольные инструменты для извлечения текста из PDF от PDF24 Creator
Если вы часто работаете с PDF, нуждаетесь в офлайн-доступе или у вас есть пакетные файлы для обработки, PDF24 Creator — идеальный выбор. Этот бесплатный эксклюзивный для Windows настольный инструмент предлагает комплексные возможности по работе с PDF, включая извлечение текста, OCR для сканированных PDF и пакетную обработку — все это при сохранении ваших файлов на локальном компьютере для максимальной конфиденциальности.
Извлечение текста из цифрового (выделяемого) PDF
- Перейдите на официальную страницу загрузки PDF24 Creator и загрузите соответствующую версию для вашей системы Windows.
- Установите и запустите PDF24. Вы увидите PDF24 Toolbox (панель инструментов с множеством утилит для PDF).
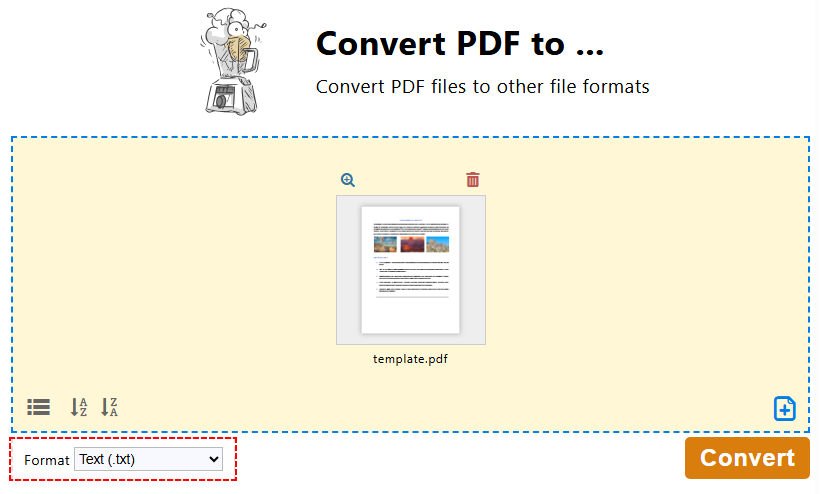
- В PDF24 Toolbox нажмите "Конвертировать PDF в…".
- Нажмите "Выбрать файлы" или перетащите, чтобы загрузить ваш PDF-файл.
- Выберите “Текст (.txt)” в качестве формата вывода и нажмите "Конвертировать".
- Сохраните извлеченный текстовый файл на вашем устройстве.
Извлечение текста из сканированного PDF (с использованием OCR)
Для сканированных/основанных на изображениях PDF используйте встроенный OCR в PDF24 для распознавания текста из сканов PDF и преобразования их в редактируемый текст или PDF с возможностью поиска:
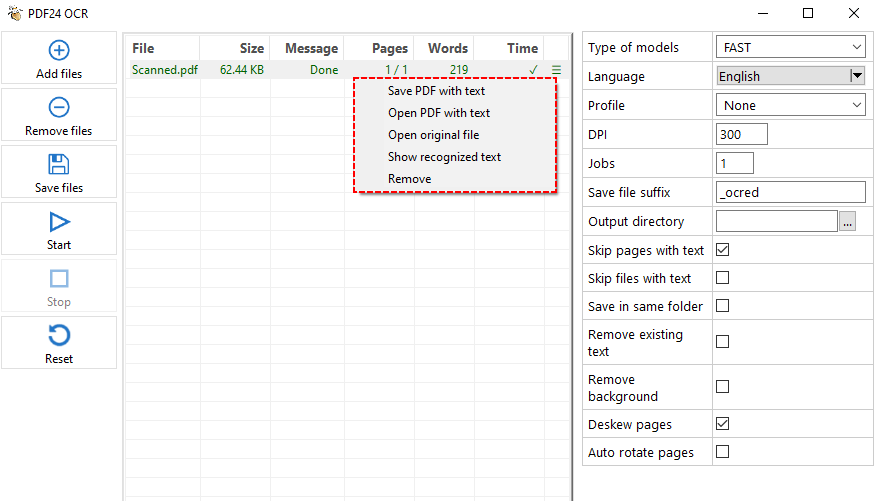
- В PDF24 Toolbox нажмите "PDF OCR".
- Нажмите "Добавить файл(ы)" и выберите ваш сканированный PDF.
- На правой панели настроек выберите режим распознавания текста, язык, DPI, выходной каталог и т.д.
- Нажмите кнопку "Старт", чтобы обработать PDF.
- PDF24 обработает каждую страницу, распознает текст и сохранит его в текстовый файл или PDF с возможностью поиска.
Совет для пользователей Adobe:
Если у вас есть Adobe Acrobat Pro (платная версия), вы можете извлечь текст, перейдя в инструмент “Экспорт PDF” и выбрав “Текст (простой)” в качестве формата вывода. Acrobat мгновенно сохранит файл в формате .txt.
Бесплатный инструмент разработчика для извлечения текста из PDF на C#
Если вы разработчик, Free Spire.PDF for .NET — это бесплатная библиотека без зависимостей для программного чтения текста из PDF. Она быстрая, легковесная и идеально подходит для интеграции извлечения текста из PDF в ваши проекты.
Код на C# для извлечения текста из PDF
Код перебирает каждую страницу в цифровом PDF-файле и извлекает весь текст из PDF. Основные классы и методы для извлечения текста включают:
- PdfTextExtractor: Специализированный служебный класс, который извлекает текст с одной страницы PDF (по одной странице за раз).
- PdfTextExtractOptions: Класс конфигурации для извлечения текста. Устанавливает правила, например, извлекать ли весь текст.
- ExtractText(): Выполняет извлечение текста на странице PDF и возвращает извлеченную текстовую строку.
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Text;
namespace ExtractAllTextFromPDF
{
internal class Program
{
static void Main(string[] args)
{
// Создаем экземпляр документа PDF
PdfDocument pdf = new PdfDocument();
// Загружаем PDF-файл
pdf.LoadFromFile("SamplePDF.pdf");
// Инициализируем StringBuilder для хранения извлеченного текста
StringBuilder extractedText = new StringBuilder();
// Проходим по каждой странице в PDF
foreach (PdfPageBase page in pdf.Pages)
{
// Создаем PdfTextExtractor для текущей страницы
PdfTextExtractor extractor = new PdfTextExtractor(page);
// Устанавливаем опции извлечения
PdfTextExtractOptions option = new PdfTextExtractOptions
{
IsExtractAllText = true
};
// Извлекаем текст с текущей страницы
string text = extractor.ExtractText(option);
// Добавляем извлеченный текст в StringBuilder
extractedText.AppendLine(text);
}
// Сохраняем извлеченный текст в текстовый файл
File.WriteAllText("ExtractedText.txt", extractedText.ToString());
// Закрываем документ PDF
pdf.Close();
}
}
}
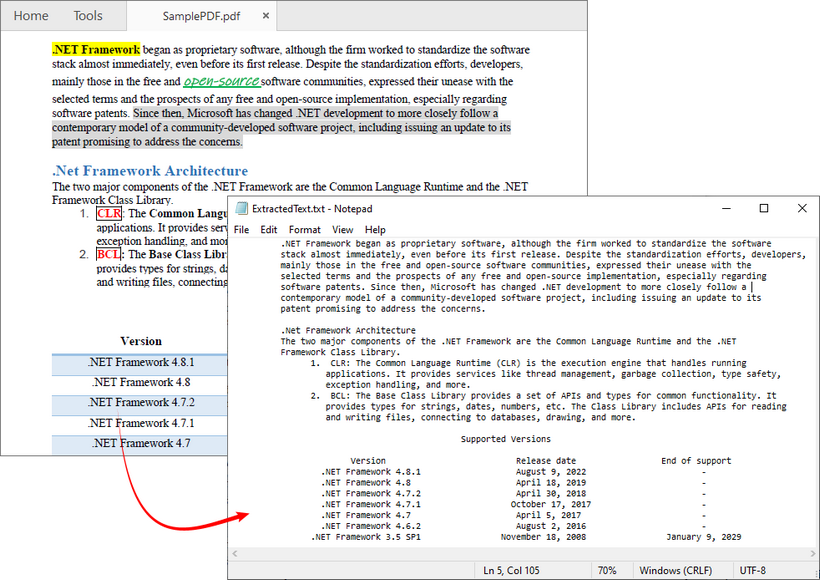
Помимо извлечения всего текста, Free Spire.PDF также позволяет извлекать текст с одной страницы или из указанной области. Результат извлечения показан ниже:
Профессиональный совет: Чтобы извлечь текст из сканированного PDF на C#, следуйте официальному руководству: Выполнение OCR на сканированных PDF на C# для извлечения текста
Часто задаваемые вопросы (FAQ)
В1: Как я могу бесплатно извлечь текст из сканированного PDF?
О: Инструменты, такие как i2OCR, PDF24, все предлагают бесплатные опции OCR. Просто загрузите ваш сканированный PDF и включите настройку OCR перед извлечением.
В2: Поддерживают ли бесплатные инструменты пакетное извлечение текста?
О: Да, но метод имеет значение. Большинство бесплатных онлайн-инструментов имеют ограничения на пакетную обработку, но вы можете использовать офлайн-настольный инструмент, такой как PDF24 Creator, или программное решение для пакетной обработки нескольких PDF.
В3: Какой лучший способ извлечь таблицы из PDF?
О: Извлечение таблиц в простой текст notoriously сложно, так как табличная структура теряется. Ваш лучший вариант — использовать инструмент, который может конвертировать PDF в Excel (XLSX) или CSV. Это попытается поместить данные в ячейки, сохраняя структуру.
В4: Как извлечь текст из PDF и сохранить форматирование?
О: Простой текст (.txt) не может сохранить форматирование, такое как жирный шрифт, курсив или размеры шрифта. Чтобы сохранить форматирование, вам следует конвертировать ваш PDF в документ Word (.docx).
Резюме
В этой статье представлены несколько надежных способов бесплатного извлечения текста из PDF, независимо от вашего технического уровня или сложности документа.
Для быстрой, одноразовой задачи надежный онлайн-инструмент, такой как CLOUDXDOCS, — ваш лучший выбор. Для повторяющейся работы или конфиденциальной информации обратитесь к офлайн-программному обеспечению, такому как PDF24. А если вы хотите создать передовой, автоматизированный конвейер контента, изучение программного решения, такого как Free Spire.PDF, может революционизировать ваш рабочий процесс.
С этим руководством вы теперь вооружены, чтобы разблокировать текст, скрытый в любом PDF, и заставить его работать на вас.
Смотрите также
- Конвертация таблиц PDF в CSV: вручную, онлайн и автоматически
- Как снять защиту с PDF (с паролем или без)
- Как бесплатно извлечь страницы из PDF — Adobe не нужен
- Извлечение текста из PDF на Python: полное руководство с практическими примерами кода
- PDF в текст на Java: извлечение текста из PDF (текстовых и сканированных)